1.本发明涉及图像处理领域,特别是一种产生循环影片的方法。
背景技术:
2.近年来,社群媒体蓬勃发展,通过网络分享影片已成为常态。随着云端服务的兴起,使用者不需要担心储存空间。使用者在拍摄影片后随意上传影片,而不用在乎这些影片是否被重复使用。每天都有如此多的新影片被拍摄并在人们之间共享,使得人们对于旧影片几乎没有兴趣。考虑到这些影片中的含义和文化成分未被重复使用,不免让人觉得是一种浪费。因此,目前亟需一种让这些影片重新获得关注的方法。
3.循环影片是介于影片与影像之间的媒体,他既能捕捉画面中的动态信息,又能将整个场景情境用循环播放的形式呈现。除了能让用户体验到场景的动态感,又不像会结束播放的一般影片而让使用者的体验被中断。在社群媒体快速发展的时代下,拍摄及分享短影片已经是生活中不可或缺的事情,譬如拍摄自学的一段小号演奏、跟朋友们跳的一段街舞、分享路过看到的一场街头艺人表演等等,这些包含人物的短影片最适合使用循环影片的形式呈现,然而近年来所提出的产生循环影片的方法大多没有考虑这类影片的特性,只有追求画面连续,而没有考虑到影片中的人物动作的多样性,也没有考虑到人物动作的连贯性。
技术实现要素:
4.有鉴于此,本发明基于人工智能或学习演算的方式提出一种从输入影片产生循环影片的方法,由此解决熟知方法产生的循环影片缺少语义一致性及视觉多样性的问题。
5.依据本发明一实施例的一种产生循环影片的方法,包括:取得一输入影片,该输入影片包含多个讯框,该些讯框中具有一第一讯框,该些讯框的每一者具有多个像素;撷取该输入影片中的一移动对象,该移动对象在该第一讯框中对应于一移动像素区域,该移动像素区域包含在该第一讯框中的该些像素中的至少二者;对于该移动像素区域的,以多个候选周期的每一者代入一目标函数计算一误差值;依据该些误差值决定该移动像素区域的一起始讯框及一循环周期,该循环周期关联于该些候选周期其中一者;依据该些起始讯框及该些循环周期产生多个输出讯框;依据一循环参数以从该些输出讯框中产生一输出讯框序列,该输出讯框序列对应于一循环影片。
6.综上所述,本发明基于人工智能或学习演算的方式所提出的产生循环影片的方法,基于时空一致性和语义约束来创建以内容感知分段组成的循环影片,确保了移动对象在循环影片中的完整性,更通过讯框熵值的设定及讯框反弹点的设置提高输出影片的视觉多样化以及输入影片的讯框利用率。
7.以上的关于本公开内容的说明及以下的实施方式的说明用以示范与解释本发明的精神与原理,并且提供本发明的专利申请范围更进一步的解释。
附图说明
8.图1为依据本发明一实施例的产生循环影片的方法示出的流程图;
9.图2为输入影片每个画面的示意图;
10.图3为图1中步骤s2的流程图;
11.图4为输出影片中的一个讯框;
12.图5示出依据图4找到的多个移动像素区域的示意图;
13.图6为一种输出讯框序列与讯框熵值的关系图;
14.图7为另一种输出讯框序列与讯框熵值的关系图;以及
15.图8为输出讯框序列中的反弹点及反弹长度的示意图。
16.附图标记如下:
17.s1~s6、s21~s25
…
步骤
18.f1~f3
…
讯框号
19.a1~a3、b1~b3、c1~c3、d1~d3、e1~e3
…
像素
20.mo
…
移动对象
21.c1
…
固定像素区域
22.c2~c4
…
移动像素区域
23.t
…
反弹点
24.l
…
反弹长度
具体实施方式
25.以下在实施方式中详细叙述本发明的详细特征以及优点,其内容足以使任何本领域普通技术人员了解本发明的技术内容并据以实施,且根据本说明书所公开的内容、申请专利范围及图式,任何本领域普通技术人员可轻易地理解本发明相关的目的及优点。以下的实施例进一步详细说明本发明的观点,但非以任何观点限制本发明的范畴。
26.请参考图1。图1为依据本发明一实施例的产生循环影片的方法示出的流程图。
27.整体而言,本发明提出的产生循环影片的方法可分为两个阶段:分析阶段与渲染(rendering)阶段。
28.分析阶段包含图1的步骤s1~s5。大部分的计算发生在分析阶段。在分析阶段中,本发明一实施例计算多个循环参数。例如:依据语义约束(semantic constraint),将评估时空一致性(spatiotemproal consistency)的误差的目标函数(或称能量函数)最小化以获得内容感知分段(context-aware segmentation),换言之,在分析阶段中,本发明一实施例计算每个超像素(superpixel)的起始讯框与循环周期;通过比较讯框色差计算讯框转移成本;通过分析相邻讯框之间具有高对称性的动作以计算反弹点。在分析阶段完成后,将循环参数快取到具有特定格式的循环参数档中供渲染阶段使用。
29.渲染阶段包含图1的步骤s6。在渲染阶段中,本发明一实施例提出的产生循环影片的方法在每个时间点实时地依据循环参数选择适合播放的下个讯框,并执行多层混合以得到最后的循环影片。以下详述图1中每个步骤的实施细节。
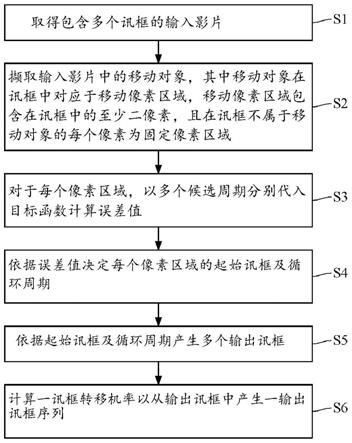
30.请参考步骤s1,取得包含多个讯框的输入影片。详言之,使用者提供的输入影片包含多个讯框(frame),这些讯框的每一者具有多个像素。输入影片可定义为v(x,t)的三维体
(3d volume),其中x为二维的像素坐标,t为讯框时间。
31.请参考步骤s2。撷取输入影片中的移动对象,其中移动对象在讯框中对应于移动像素区域,移动像素区域包含在讯框中的至少二像素,且在讯框中不属于移动对象的一或多个像素为固定像素区域。
32.举例来说,请参考图2。图2示出输入影片每个画面的示意图。输入影片只包含第一讯框f1、第二讯框f2及第三讯框f3,输入影片通过这三个讯框f1~f3呈现一个由画面左方移动到画面右方的移动对象mo。一般而言,移动对象mo之中所包含的像素个数超过两个。就第一讯框f1而言,在移动对象mo之中的所有像素(如图2中的像素a1及像素b1)组成一个移动像素区域,在移动对象mo之外的每一个像素(如图2中的像素c1、像素d1、像素e1)各自代表一个固定像素区域。在本发明另一实施例中,移动对象mo之外的所有像素(如图2中的像素c1、像素d1及像素e1)可代表一个固定像素区域。换言之,固定像素区域的大小可能由单一像素或多个像素组成,本发明对此不予限制。
33.请参考图3。图3示出图1中步骤s2的一种实施方式。请一并参考图2以理解图3的流程。需先理解的名词定义如下所述:在第一讯框f1中的每个像素(如图2中的像素a1~e1)称为第一像素。在第二讯框f2中的每个像素(如图2中的像素a2~e2)称为第二像素。
34.请参考步骤s21,取得第一讯框中每个第一像素的属性。例如:取得第一讯框f1中第一像素a1的颜色,以及第一像素b1的颜色。
35.请参考步骤s22,在第二讯框中,寻找对应于每个第一像素的属性的第二像素。例如,就属于移动对象mo的像素a1而言,假设移动对象mo整体为红色,非移动对象的部分均为白色。则依据第一讯框f1中的第一像素a1的rgb值,可在第二讯框f2中找到具有相同颜色的多个像素如a2及b2,进一步依据第一像素a1周围的其他像素的颜色或是依据第一像素a1本身的坐标,可判断出在第二讯框中对应的第二像素应为a2而非b2。就不属于移动对象mo的像素c1而言,也可按照上述方式找到对应的第二像素c2,其余像素b1、d1及e1也可按上述方式类推。
36.请参考步骤s23,计算在第一像素与对应于第一像素的属性的第二像素之间的一位移量。在其他实施例中,步骤s23也可改为计算第一像素a1及第二像素a2之间的光流(optical flow)信息。
37.请参考步骤s24,以位移量在指定范围内的至少二个第一像素作为移动像素区域。例如:因为移动对象mo从画面左方逐渐移动到画面右方,故可指定满足“y轴坐标变化量小于指定阈值”此一条件的所有第一像素(如图2中的像素a及b)作为移动像素区域。
38.请参考步骤s25,在第二讯框中依据位移量追踪移动像素区域的位置。详言之,在第一讯框f1中侦测出移动像素区域的所有第一像素(如图2中的像素a1及b1)之后,可利用位移量或是前述的光流信息,继续追踪后续讯框中的移动像素区域。
39.请参考图4及图5,图4为输入影片中的一个讯框。图5示出依据图4找到的多个移动像素区域的示意图。在步骤s2执行完成后,可在输入影片的讯框中找到如图5所示的固定像素区域c1及移动像素区域c2、c3及c4。
40.在本发明其他实施例中,移动像素区域也可称为动态的超像素(dynamic superpixel),固定像素区域也可称为静态的超像素(static superpixel),每个超像素代表一块对象区域。此外需注意的是,图3所叙述的侦测及追踪(detecting and tracking)的
流程并不用于限制本发明一实施例的步骤s2“撷取输入影片中的移动对象”。实务上,可采用其他光流算法以实现针对移动对象mo的侦测及追踪。也可以在步骤s2之前预先依据多个关联于移动对象mo的图片训练一对象辨识模型,并且在步骤s2执行时,依据对象辨识模型撷取输入影片中的每个讯框中的移动对象mo。
41.请参考步骤s3,对于每个像素区域,以多个候选周期分别代入目标函数计算误差值。所述的候选周期可为一基本候选周期的倍数,例如基本候选周期为4个讯框,则候选周期包含:4、8、12、16
…
等,然而本发明并不以上述范例为限制。本步骤s3针对移动像素区域及固定像素区域的每一者,即针对每个超像素(包含动态的超像素及静态的超像素),计算其结合多个候选周期时的多个误差值,用于计算这些误差值的目标函数(objective function)如下所示。
42.式一:e(p,s)=e
consistency
(p,s) e
static
(p,s)
43.其中,e(p,s)为目标函数,p为像素的循环周期,s为像素的起始讯框,e
consistency
(p,s)是用于判断像素的时空一致性的项,e
static
(p,s)是用于提高误差惩罚的项,对于在输入影片中并非恒为静态的那些像素,若是在后续的步骤中被指派为固定像素区域,则此项将大于0。下文着重于叙述e
consistency
(p,s)的计算方式。
44.在式一中的e
consistency
(p,s)项的计算如下方所示。
45.式二:e
consistency
(p,s)=e
spatial
(p,s) e
temporal
(p,s)
46.从式二可知:对于每个位置的超像素x,此超像素x在时空一致性的误差值由空间一致性的误差值及时间一致性的误差值所组成。在式二中反映空间一致性的误差值e
spatial
(p,s)的计算如下方所示。
47.式三:
48.式三代表的意义是:对于每个超像素x,同时考虑在空间上相邻于超像素x的超像素z。
49.式三中的γs(x,z)的计算如下方所示。
50.式四:
51.其中λs为常数,mad为绝对差中位数(median absolute deviation)。在输入影片中,若两个相邻的超像素x及z的颜色差异大,则式四降低这两个超像素x及z的一致性成本,因为这样就不容易察觉到不一致。
52.请参考式三,主要影响空间一致性的误差值的ψ
spatial
(x,z)项,其计算方式如下方所示。
53.式五:
54.其中v
out
(x,t)代表在时间为t时,输出影片在超像素x的位置的估测颜色,v
in
(x,t)代表在时间为t时,输入影片在超像素x的位置的颜色。式五中的φ(x,t)是时间映像(time mapping)函数,其计算如下方所示。
55.式六:φ(x,t)=s
x
((t s
x
)mod p
x
56.式六代表的意义是:对于一个时间区段较长的输入影片,将其映射到一个时间区段较短的输出影片,此输出影片以s
x
为起始讯框,以p
x
为循环周期。例如:起始讯框为7,循环周期为3,输入影片的时间序列为(0,1,2,3,4,5,6,7,8,9);则映射的时间序列为(7,8,9,7,8,9,7,8,9)。
57.请参考式五,式五代表的意义是:对于相邻的超像素x和超像素z,计算这两个超像素x及z在输出影片的色差与这两个超像素x及z在输入影片的色差之间的l2距离。例如,若输入影片中的移动对象为人体,通过式五计算出的数值大小,可反映此人体在输出影片中的一致程度。例如,若式五计算出的数值大于某数字,则在后续产生循环影片时,移动对象的某个部分可能在某个讯框中消失,导致观看影片时的不一致性。
58.请回顾式二,式二中反映时间一致性的误差值的项,e
temporal
(p,s)计算如下方所示。
59.式七:e
temporal
(x)=∑
x
ψ
temporal
(x)γ
t
(x)
60.主要影响时间一致性的误差值的ψ
temporal
(x)项,其计算方式如下方所示。
61.其中ψ
temporal
(x)的计算如下方所示。
62.式八:
63.式八代表的意义是:对于超像素x,计算此超像素x在输出影片的连续两个讯框之间的第一色差,计算此超像素x在循环结束后的下一个讯框及循环开始时的起始讯框之间的第二色差,计算此超像素x在循环结束时的讯框及到循环开始前的上一个讯框之间的第三色差,然后加总第一色差及第二色差的l2距离与第一色差及第三色差的l2距离。从视觉角度而言,时间一致性的误差值不仅反映了在循环影片的播放时,中间连续两个输出讯框的时间一致性,更反映了循环影片在本次播放结束到下次循环开始之间的时间一致性。
64.需注意的是,在前述关联于计算误差值的式一到式八,在一实施例中,这些算式都是以步骤s2中的移动像素区域及固定像素区域的每一者代入计算。在另一实施例中,这些
算式仅以移动像素区域代入计算。换言之,本发明一实施例在评估时空一致性的误差值时,以超像素为单位作为考虑。基于上述概念所产生的循环影片,在保有像素层级的时空一致性之外,更具有保留输入影片的语义一致性(semantic consistency)的效果。
65.请参考图1的步骤s4,依据误差值决定每个像素区域的起始讯框及循环周期。所决定的循环周期是多个候选周期的其中一者。例如,在步骤s3之后,对于每个超像素x,此超像素在起始讯框为si且候选周期为pj的情况下具有误差值e
i,j
,本步骤s4将考虑满足e
i,j
《e0的所有(si,pj)的组合,其中e0代表指定的误差容许上限。在一实施例中,从步骤s3到s4的流程相当于:对于每个符合语义约束的超像素x,找到最小化式一中的e
p,s
的起始讯框s及循环周期p,如下所示。
66.式九:
67.请参考图1的步骤s5,依据起始讯框及循环周期产生多个输出讯框。一般而言,在给定一个超像素的起始讯框设置值后,可得知此超像素应该从哪一个讯框开始撷取,并且也已知此超像素的循环周期,因此,可针对每一个步骤s4产生的超像素进行上述步骤以产生多个输出讯框。步骤s5的一种实施方式为:依据步骤s4产生的多个超像素所适用的起始讯框,从中挑选出起始讯框为1的一或数个超像素以组合成循环影片的第一个输出讯框。步骤s5的另一种实施方式为:对于步骤s4产生的多个循环周期,针对这些循环周期本身以及其倍数,寻找每个循环周期适用的起始讯框,然后以这些起始讯框组合出多个输出讯框。步骤s5的又一种实施方式为:依据步骤s4产生的所有起始讯框以及所有循环周期,寻找他们的所有组合情况,由此产生多个输出讯框。然而本发明并不以上述这些实施方式为限制。
68.请参考步骤s6。计算一讯框转移机率以从输出讯框中产生一输出讯框序列。所述的输出讯框序列对应于一循环影片。详言之,在产生第一个讯框之后,选取下一个讯框的一种实施方式例如计算一机率方程式,如下所示。
69.式十:
70.其中,p
i,j
代表从第i个讯框转移到第j个讯框的机率,d
i,j
代表讯框转移成本,其计算方式如下所示。
71.式十一:d
i,j
=||v(
·
,i)-v(
·
,j)||
72.由式十一可知,讯框转移成本为累计第i个讯框中的每一个像素与第j个讯框对应的像素的色差。换言之,两个邻近的讯框色差愈大,代表讯框转移成本愈高。
73.在式十中,因子σ将像素差异映射到机率。一般而言,具有较高时间一致性的讯框被挑选到的机率较高。在输入影片包含人体时,选择较小的σ值代表只允许选择成本较低的讯框转移,然而可能导致奇怪的重复的人体动作;选择较大的σ值代表允许成本较高的讯框转移,如此较不容易选取到相同的讯框,可提高选取讯框时的多样性,然而可能导致在整个播放顺序中人体动作不具连续性。在本发明一实施例中,因子的值的设置可采用静态策略,即将因子设置为固定值。在本发明另一实施例中,考虑到多样性与时间一致性两者为权衡(trade-off)关系,因此,因子σ的值的设置可采用动态策略。当时间一致性降低时,设置较大的σ值,当讯框多样性降低时,设置较大的σ值。所述的动态策略种提出一个σ值的适应性
(adaptive)函数,如下所示。
74.式十二:
75.其中,为讯框熵(entropy)的估计值,为讯框熵(entropy)的估计值,为讯框熵(entropy)的趋势,其为连续两个h(t)的差值,为短期的平均像素转移误差,其为当前讯框与前面多个讯框的每一者的差的总和,所述前面多个讯框为已播放的输出影片的多个讯框,α
entropy
及α
entropy
皆为常数,前者控制输出讯框序列的多样性,后者控制讯框熵的趋势的敏感度。
76.讯框熵的计算方式如下所示。
77.式十三:
78.其中,h(t)为在量测时间为t时的讯框熵值;n是讯框熵的最大值,且关联于输入讯框的总数;p
x
(t)是讯框x的出现机率。式十三的意义是:讯框熵是累积在量测时间t之前的每个讯框的出现机率。讯框熵可实时地反映当前输出讯框的分散程度。
79.循环参数包括一讯框熵。在依据循环参数以从输出讯框中产生输出讯框序列之前,更包括:选择目标讯框及历史讯框,目标讯框在时域上为历史讯框的下一个讯框;加总目标讯框及历史讯框的每一者的出现机率以获得累计值;依据累计值及历史讯框熵值选择性地在历史讯框之后插入目标讯框至输出讯框序列。
80.请参考图6。图6示出一个输出讯框序列与讯框熵值的关系图,其中因子σ的值的设置采用静态策略。请参考右方纵轴数字,当输出讯框号从1逐渐递增150时,在这段期间未播放重复的讯框,因此讯框熵值也逐渐上升到约0.95(参考左方纵轴数字)。当输出讯框号从150返回至140时开始第一次的循环播放之后,因为在这段期间出现重复的讯框,因此讯框熵值逐渐下降。如图6中所示,同样的一组讯框的循环次数增加将导致讯框熵值持续下降。
81.请参考图7,图7示出一个输出讯框序列与讯框熵值的关系图,其中因子σ的值的设置采用动态策略。由图7可知,具有多样化的输出讯框序列可提升讯框熵值的整体趋势。反过来说,在步骤s4中,依据式十三计算的讯框熵值h(t)决定下一个输出讯框的讯框号,由此提升循环影片的视觉多样性。
82.须注意的是,上述计算讯框熵值的方式可独立于计算起始讯框及循环周期的步骤。换言之,对于一输出影片,可采用任何方式计算多个超像素各自的起始讯框及循环周期,并且结合本发明一实施例中的讯框熵值计算方式,由此提升所产生的循环影片的视觉多样性。
83.由于影片中的人物动作经常来回移动,例如来回拉动大提琴的弓。因此,为了进一步提升讯框利用率以及下一个输出讯框的选择多样性,可按照下文叙述的方式决定输出讯框的反弹点与反弹长度。
84.请参考图8,其呈现一种具有反弹动作的播放顺序。输出讯框从讯框1连续地播放至讯框5,然后遇到反弹点t,因此倒回播放(playback reversely)曾播放过的讯框,直到倒回播放的总时间等于反弹长度l之后,才继续按原先顺序播放。如图8所示,l值为2,换言之,
在倒播讯框5及讯框4之后,继续正向地播放输出讯框。因此,图8的讯框号输出为:1
→2→3→4→5→5→4→4→5→6→
7。
85.最佳的反弹点是在两个彼此对称的动作中间。换言之,当前一个动作被倒回播放的版本与下一个动作的正常播放的版本两者相似时,则可以将下一个动作对应的输出讯框以前一个动作对应的输出讯框取而代之。例如,图8的讯框4及5呈现人物将琴弓拉到左边,讯框6及7呈现人物将琴弓拉到右边,因此可以在输出讯框序列中采用讯框5及4的子序列取代讯框6及7的子序列。
86.循环参数包括反弹点机率。在依据循环参数以从输出讯框中产生输出讯框序列之前,更包括:选择目标讯框、目标前讯框及目标后讯框,其中目标讯框在时域上为目标前讯框的下一个讯框,且目标后讯框在时域上为目标讯框的下一个讯框;计算从目标前讯框至目标讯框的第一动作向量,从目标讯框至目标后讯框的第二动作向量,及第一动作向量与第二动作向量的动作相似度;将动作相似度转换为反弹成本机率;以及依据反弹成本机率选择性地在目标讯框之后插入目标前讯框至输出讯框序列。
87.在一实施例中,在步骤s6决定下一个输出讯框的讯框号之前,本发明一实施例先计算动作的反弹成本(motion cost),再依据反弹成本值所对应的机率,决定在播放时间t之后,是否以反弹长度为l的反弹动作子序列作为输出。所述的反弹成本如下所示。反弹长度l的值为使用者根据其需求所决定的固定值。
88.式十四:
89.d
bounce
(t,l)是在两个对称动作的每一个讯框从时间t开始顺向播放及逆向播放时计算其相似度。motion(t1,t2)代表从讯框t1到讯框t2的密集动作向量(dense motion vector),此密集动作向量通常是通过光流法计算。计算两个相邻讯框的光流有多种方式,本发明对此不予限制。本发明一实施例采用多项式展开法(polynomial expansion method)计算讯框中所有超像素的光流信息。
90.反弹权重ω
bounce
的计算方式如下所示。
91.式十五:ω
bounce
=exp(l-l) exp(-l)
92.反弹权重ω
bounce
用于将计算重点放在靠近反弹点t的讯框,这是因为靠近反弹点t的讯框播放并不连续,因此,在邻近反弹点t的动作对称性相较于其他连续的部分更为重要。
93.式十四对应的反弹成本d
boumce
(t,l)的机率p
t
如下所示。
94.式十六:p
t
=exp(-d
bounce
(t)/σ
bounce
95.其中,因子σ
bounce
的值一般可设定为d
bounce
平均值的倍数,调整因子σ
bounce
的值可控制在某个讯框触发反弹点的可能性。
96.因此,步骤s6中所述的循环参数包括反弹成本的机率。在决定下一个讯框t 1时,同时考虑当前讯框t的反弹成本p
t
的机率是否大于某个默认值,进而决定是否以当前讯框t作为反弹点回放先前的讯框。
97.本发明一实施例提出的产生循环影片的方法在决定下一个输出讯框时,因为增加了选择当前讯框作为反弹点的可能性,因此可提升循环影片对于输入影片的讯框利用率。
98.综上所述,本发明基于人工智能或学习演算的方式提出的产生循环影片的方法,
基于时空一致性和语义约束来创建以内容感知分段组成的循环影片,确保了移动对象在循环影片中的完整性,更通过讯框熵值的设定及讯框反弹点的设置提高输出影片的视觉多样化以及输入影片的讯框利用率。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。