新词分类技术
1.对相关申请的交叉引用
2.本技术援引35u.s.c.
§
119(e)要求于2019年8月19日提交的标题为“neologism classification techniques”的美国临时专利申请62/888,998的优先权,其全部内容出于所有目的通过引用并入本文。
技术领域
3.本公开一般而言涉及数据分析和处理。更具体地,公开了用于分析和处理新词的技术。
背景技术:
4.大数据用户可以具有关于他们的客户的大量数据(例如,数据集)。用户可以包括数据集的用户,诸如公司。数据集可以是电子表格和表格的形式,并且可以包括有关客户的信息,诸如客户id、名、姓氏、地址等。用户可以具有来自不同源的数据集。数据集可以包括姓名、人口统计和地理信息等。
5.如果可以根据数据集确定附加信息,那么数据集可以对用户更有用。例如,如果此类信息不容易获得,那么知道有关客户的附加信息(诸如性别、世代(generation)和其它人口统计信息)可能是有益的。
6.数据集可以包括以前从未见过的词语(例如,新词(neologism))。例如,客户的姓名可以是唯一的姓名或姓名的唯一拼写。另外,客户工作的公司的名字可以是未知的名字或编造的词语。确定从未见过的词语的附加信息是困难的,因为没有关于这些词语的可从中获得信息的现有信息(例如,属性、特点等)。
7.存在用于确定词语之间的相似性的技术。例如,给定未知的词语,可以找到包含在词语的语料库内的最相似的词语。但是,此类技术不提供准确的结果。例如,使用词语的训练语料库中包含的最相似的词语并不提供准确的结果,并且对未知的词语的推断出的属性是不准确的。具体而言,使用整个词语并不提供高度准确的结果。
8.因此,需要更准确的方法来识别未知的词语的特点。示例实施例解决了这些问题和其它问题。
9.其它实施例针对与本文描述的方法相关联的系统、设备和计算机可读介质。参考以下具体实施方式和附图可以获得对示例性实施例的性质和优点的更好理解。
技术实现要素:
10.示例实施例被配置为对从未见过的词语或名字(例如,新词)的现实世界特点进行预测。
11.给定文本的主体(例如,数据集、电子表格等),可以存在以前从未见过的词语。例如,数据集中可以包括新名字或不同拼写的名字。作为另一个示例,可以创建新词或者可以创建词语的新变体。从未见过的词语或名字是当前未知其含义和/或与该词语或名字相关
联的特点的词语或名字。从未见过的词语或名字可以被称为新词。未知的词语或名字将在描述中称为未知的词语。
12.示例实施例丰富(enrich)了数据集,使得数据集信息可以更有用。例如,用户可以具有大型数据集(例如,大数据)。如果可以基于数据集确定附加信息和特点,那么可以使数据集更有用。示例实施例可以从未知的词语确定含义,从而使数据集更有用。数据集可以是电子表格的形式,其包括数据的列和行。数据集可以包括数据的列,其包括一个或多个新词。例如,指向名字的数据集的列可以包括一些以前从未见过的名字。
13.示例实施例可以基于未知的词语来解密附加信息。例如,示例实施例可以基于未知的名字来确定诸如行业、语言、性别、世代等特点。行业、语言、性别和世代被描述为示例,但是,可以根据数据集中的数据的类型(例如,名、公司名字等)为数据集确定其它特点和属性。
14.另外,示例实施例可以以高准确率确定与未知的词语相关联的特点和附加信息。因此,用户不必猜测分类。
15.特定名字或词语可以具有已知特点。例如,诸如“alice”之类的名字可以关联为女性名字。具体而言,根据历史信息和先前的词语分析,诸如“爱丽丝”之类的名字已与女性相关联。但是,人可能会将他们的名字拼写为“allys”。这可以是这种名字的第一实例,或者可以与该名字没有任何关联。因此,名字“allys”可能不与特定特点相关联。除了名字,还可能存在以前从未见过的词语。可以创建新词或词语的新拼写,因此没有历史背景或关联。
16.示例实施例可以预测词语或名字来自哪种语言、基于名字(例如,公司名字)预测行业、以及基于人名预测性别。预测性别可能对市场细分分析中的聚合有用。
17.示例实施例可以基于未知的词语的拼写来推断含义。可以使用三元组来推断含义并且三元组可以用于提供关于未知的词语的信息。具体而言,可以通过将三字母三元组本身视为语言来确定未知的词语的含义。也就是说,可以基于词语内的三元组的次序来推断含义,与句子内的词语的次序传达含义的方式相似。例如,基于三元组和历史数据,可以确定以元音结尾的名字常常与女性相关联。
18.示例实施例通过神经网络(例如,word2vec)运行从训练集的词语中提取的三元组。另外,可以执行监督式学习以便对未知的词语的属性和特点进行预测。如上面所指示的,未知的词语的属性和特点(即,用于监督式学习的标签)可以包括词语所来自的语言、行业、性别、世代等。未知的词语的属性和特点包括可以为未知的词语确定的附加信息。因此,用户不仅具有例如名的数据集,而且用户还具有附加信息(例如,这些数据项的标签),诸如其客户的性别、其客户工作的行业等。从而使数据集对用户更有用。
附图说明
19.通过以下具体实施方式结合附图将容易理解本公开,其中相同的附图标记表示相同的元件,并且其中:
20.图1图示了根据一些示例实施例的分析环境的框图。
21.图2图示了根据一些示例实施例的数据丰富系统的新词分类服务器的框图。
22.图3图示了根据一些示例实施例的用于对新词进行分类的方法的流程图。
23.图4是根据一些示例实施例的用于对新词进行分类的变量的概览。
24.图5图示了根据一些示例实施例确定输入词语的三元组。
25.图6图示了根据一些示例实施例的具有三元组词语嵌入模型向量的矩阵。
26.图7图示了根据一些示例实施例的用于计算用于词语的向量的处理。
27.图8图示了根据一些示例实施例确定输入词语的最近(nearest)名字。
28.图9图示了根据一些示例实施例的表示队列的列表的表格。
29.图10图示了根据一些示例实施例的用于计算分类值的方法的流程图。
30.图11图示了根据一些示例实施例的用于计算分类值的方法的详细流程图。
31.图12图示了根据一些示例实施例的包括分类值的矩阵。
32.图13图示了根据一些示例实施例的卷积神经网络。
33.图14图示了根据一些示例实施例的用于执行新词分类的用户界面。
34.图15描绘了根据一些示例实施例的分布式系统的简化图。
35.图16图示了根据一些示例实施例的系统环境的一个或多个组件的简化框图,其中服务可以作为云服务被提供。
36.图17图示了根据一些示例实施例的可以被用于实现示例实施例的示例性计算机系统。
具体实施方式
37.在以下描述中,出于解释的目的,阐述了许多具体细节以提供对本发明的各种实施例的透彻理解。但是,对于本领域技术人员显而易见的是,可以在没有这些具体细节中的一些细节的情况下实践本发明的实施例。在其它情况下,众所周知的结构和设备以框图形式显示。
38.新词可以是新的词语或短语。新词可以是新创造的词语或不常用的词语。新词可以由文化和技术的改变驱动。另外,新词可以由社交媒体和流行文化驱动。新的词语和名字以及词语和名字的拼写不断被创造出来。示例实施例可以确定可以与新词相关联的属性或特点。
39.在描述中,用户是数据的用户,诸如公司。但是,用户可以包括新词分类对其有益的任何人或实体。如果数据包括附加信息,那么数据可以对用户更有意义。通过丰富数据,数据对用户变得更有用。例如,数据可以包括客户数据(例如,名、姓氏、id、社会安全号等)和购买数据(例如,商店名字、购买的物品等)。
40.示例实施例可以用于各种情况。例如,可以存在给定的词语,其中不清楚该词语属于哪种语言。作为另一个示例,给定诸如公司名字之类的词语,可以识别与该公司相关联的行业。作为另一个示例,例如给定名,示例实施例可以被用于预测性别。示例实施例可以被用于基于客户的名来预测他们的年龄或世代。这些仅仅是可以识别附加特点并且因此使数据对用户更有益的示例情况。
41.示例实施例可以在例如市场细分中有用。市场细分可以包括基于某种类型的共享特点将广泛的消费者或企业市场(诸如客户)划分为消费者的子组。
42.示例实施例提供了用于对词语进行分类的解决方案。例如,参考列表可以具有名和通常由名表示的性别的列表。例如,名字“david”可以与性别“男性”相关联。相关联的性别可以基于基于历史数据的关联的频率。
43.但是,可以创建新的名字和名字的新拼写。示例实施例可以为以前没有见过的名字提供性别。也就是说,对于尚未在名字或词语的字典中识别出的名字。例如,名字“chauna”可能不在名字的字典中。因此,尚不清楚该名字是与男性还是女性相关联。为了确定名字“chauna”的性别,可以执行二元分类。即,可以识别两个分类组。对于对个人进行预测可能带来伦理问题的用例,这种技术在人群被聚合的用例(诸如针对市场细分识别)中可能是有用的。但是,这是示例实施例并且可以基于期望的分类进行附加改变。示例实施例不限于两个分类。可以基于用户的需要进行附加分类。
44.i.分析环境
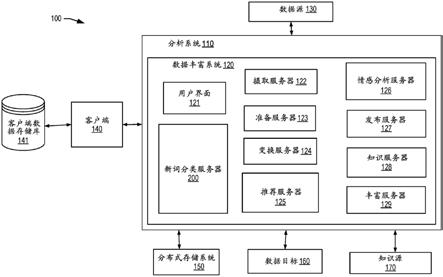
45.图1图示了根据一些示例实施例的分析环境100的框图。
46.数据分析环境100可以包括分析系统110、数据丰富系统120、数据源130、客户端140、客户端数据存储库141、分布式存储系统150、数据目标160和知识源170。数据丰富系统120可以包括用户界面121、摄取服务器122、准备服务器123、变换服务器124、推荐服务器125、情感分析服务器126、发布服务器127、知识服务器128、丰富服务器129和新词分类服务器200。关于图2更详细地解释新词分类服务器200。
47.分析环境100可以是基于云的环境。分析系统110提供单个统一平台,包括自助可视化、强大的内联数据准备、企业报告、高级分析和递送主动洞察力的自学习分析。分析系统110可以包括例如oracle分析云(oracle analytics cloud)。
48.客户端或用户140可以向分析系统110的数据丰富系统120提交数据丰富请求。客户端可以包括客户端数据存储库141以存储与客户端相关联的数据。数据丰富系统120可以识别数据源130中的一个或多个(或其部分,例如特定表格、数据集等)。数据丰富系统120然后可以从识别出的数据源130请求要处理的数据。
49.在一些实施例中,可以对数据源进行采样,并且对采样的数据进行分析以进行丰富,从而使大型数据集更易于管理。可以接收识别出的数据并将其添加到数据丰富服务可访问的分布式存储系统(诸如hadoop分布式存储(hdfs)系统)。数据可以由多个处理阶段(在本文被描述为管线或语义管线)在语义上进行处理。这些处理阶段可以包括经由准备服务器123的准备阶段、经由发布服务器127的发布阶段、经由丰富服务器129的丰富阶段。
50.在一些实施例中,准备阶段可以包括各种处理子阶段。这可以包括自动检测数据源格式并执行内容提取和/或修复。一旦识别出数据源格式,数据源就可以被自动归一化为数据丰富服务可以处理的格式。在一些实施例中,一旦已经准备好数据源,它就可以由丰富服务器129处理。在一些实施例中,入站数据源可以被加载到数据丰富系统120可访问的分布式存储系统150(诸如通信地耦合到数据丰富服务的hdfs系统)中。
51.分布式存储系统150为摄取的数据文件提供临时存储空间,并且还可以提供中间处理文件的存储,以及用于发布之前的结果的临时存储。在一些实施例中,增强或丰富的结果也可以存储在分布式存储系统中。在一些实施例中,在与摄取的数据源相关联的丰富期间捕获的元数据可以存储在分布式存储系统150中。系统级元数据(例如,其指示数据源的位置、结果、处理历史、用户会话、执行历史和配置等)可以存储在分布式存储系统中或存储在数据丰富服务可访问的单独的储存库中。
52.在一些实施例中,数据丰富系统120可以通过情绪分析服务器126提供情绪分析。情绪分析服务器126包括用于使用本文公开的技术分析来自不同数据源的数据的情绪的功
能。技术包括应用卷积神经网络(cnn)、词汇共现网络和二元组词语向量来执行情感分析,以提高分析的准确性。
53.在一些实施例中,经由发布服务器127的发布阶段可以向一个或多个可视化系统提供在丰富和任何数据源丰富或修复期间捕获的数据源元数据以供分析(例如,向用户显示推荐的数据变换、丰富和/或其它修改)。发布子系统可以将经处理的数据递送到一个或多个数据目标。数据目标可以与可以发送经处理的数据的地点对应。该地点可以是例如存储器、计算系统、数据库或提供服务的系统中的位置。例如,数据目标可以包括oracle存储云服务(oracle storage cloud service,oscs)、url、第三方存储服务、web服务和其它云服务(诸如oracle业务智能(oracle business intelligence,bi)、数据库即服务和数据库模式即服务)。在一些实施例中,联合引擎向客户提供api的集合以浏览、选择和订阅结果。一旦被订阅并且当产生新结果时,结果数据可以或者作为直接馈送提供给外部web服务端点或者作为批量文件下载提供。
54.如下文进一步描述的,可以丰富数据以包括未知的词语或新词的附加相关信息。新词分类服务器200可以分析新词并确定新词的属性或特点。数据可以从数据源130获得并且新词分类服务器200可以确定新词的属性和/或特点。属性可以包括具有特定词语或名字的人或事物所特有或固有的品质或特征。
55.示例实施例提供了使用机器学习的数据丰富系统,使得用户不必自己分析所有数据。另外,数据丰富系统可以在没有用户干预的情况下执行确定。因此,数据丰富系统可以为用户执行分析。
56.通过本公开,公开了图示根据一些实施例的处理的各种流程图和技术。各个实施例可以被描述为处理,其被描绘为流程图、流图、数据流图、结构图或框图。虽然流程图可以将操作描述为顺序处理,但许多操作可以并行或并发执行。此外,可以重新安排操作的次序。处理在其操作完成时终止,但可以具有图中未包括的附加步骤。处理可以与方法、函数、过程、子例程、子程序等对应。当处理与函数对应时,它的终止可以与函数返回到调用函数或主函数对应。
57.图中描绘的处理可以在由一个或多个处理单元(例如,处理器核)、硬件或其组合执行的软件(例如,代码、指令、程序)中实现。例如,对于参考任何附图描述的处理,数据丰富系统120可以由计算机系统实现。任何处理都可以被实现为服务。在一些实施例中,图中的任何元件都可以用比图中所示更多或更少的子系统和/或模块来实现,可以组合两个或更多个子系统和/或模块,或者可以具有子系统和/或模块的不同配置或布置。子系统和模块可以在软件(例如,处理器可执行的指令、程序代码)、固件、硬件或其组合中实现。在一些实施例中,软件可以存储在存储器(例如,非暂态计算机可读介质)中、存储器设备上或一些其它物理存储器中并且可以由一个或多个处理单元(例如,一个或多个处理器、一个或多个处理器核、一个或多个gpu等)执行。
58.图中的特定系列的处理步骤不旨在进行限制。根据替代实施例,也可以执行其它步骤序列。例如,替代实施例可以以不同的次序执行以上概述的步骤。而且,图中所示的各个步骤可以包括多个子步骤,这些子步骤可以对各个步骤适当地以各种次序执行。此外,可以根据特定应用添加或移除附加步骤。本领域的普通技术人员将认识到许多变化、修改和替代。
59.在一些实施例中,可以使用一个或多个数据结构来存储数据。数据结构可以根据数据的存储方式、存储内容和/或存储位置以多种方式组织。虽然每个数据结构被示为包括特定数据,但是可以实现更多或更少的数据结构来存储数据。数据结构可以包括对其它数据结构的引用。数据结构可以使用一种或多种类型的数据结构(包括但不限于链表、数组、散列表、映射、记录、图形或其它类型的数据结构)来实现。数据结构可以以分层方式实现。可以基于用户的输入以声明方式定义每个数据结构。数据结构可以基于模板(例如,基于诸如扩展标记语言(xml)之类的标记语言定义的模板)来定义。数据结构可以具有一种或多种格式,也称为文档格式。
60.ii.新词分类服务器
61.图2图示了根据一些示例实施例的数据丰富系统120的新词分类服务器200的框图。
62.新词分类服务器200可以包括新词分类系统210、三元组分析系统211、卷积神经网络(cnn)212、词语嵌入模型213、数据存储库214和字典215。
63.新词分类系统210可以对未知的词语或新词执行丰富。新词分类系统210可以基于从三元组分析系统211、卷积神经网络(cnn)212、词语嵌入模型213、数据存储库214和字典215接收的信息来提供对新词的分类。
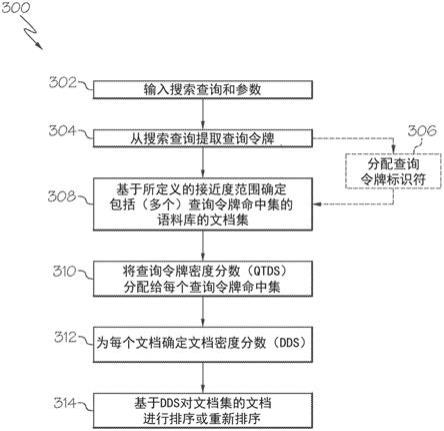
64.三元组分析系统211可以使用三元组对新词进行分析。三元组是由三个连续的书写单位(诸如字母、音节或词语)组成的组。在示例实施例中,三元组是三个连续的字母。三元组分析系统为给定的词语生成三元组。生成的三元组包括重叠的字母。例如,每个三元组的两个字母可以重叠。为给定词语生成的每个三元组都从前一个三元组右侧的一个字母开始。例如,对于名字“bob”,三元组将包括“^bo”、“bob”和“ob$”。关于图5更详细地解释三元组分析。
65.卷积神经网络(cnn)212是一类深度神经网络。cnn为值添加权重。例如,可以训练cnn在几分钟内分析名字的集合。关于图13更详细地解释卷积神经网络。
66.词语嵌入模型213是可以被用于产生词语嵌入向量的模型。词语嵌入可以包括自然语言处理(nlp),其中词汇表中的词语或短语被映射到实数的向量。可以在示例实施例中使用的示例词语嵌入模型是word2vec。word2vec可以使用mikolov等人在http://arxiv.org/pdf/1309.4168.pdf的“exploiting similarities between languages for machine translation”(2013)中公开的技术来实现,该文献出于所有目的通过引用并入本文。
67.词语嵌入模型可以包括被馈送词汇的语料库的算法。(例如,从文章、报纸)获得大量文本并将其馈送到词语嵌入模型的算法。词语嵌入模型向量包括权重变量(例如,三元组的300个方面)。权重变量向正被分析的三元组添加维度。
68.在名字的情况下,语料库词语可以包括来自人口普查局的名字。可以使用来自人口普查局的名字的三元组来训练词语嵌入模型。关于图7更详细地解释词语嵌入模型。
69.数据存储库214可以被用于存储来自要对其执行新词分类的数据集的数据。例如,客户端可以提供包括数据的列和行的数据的电子表格。要由新词分类服务器200分析的数据可以存储在数据存储库214中。数据存储库214还可以存储计数器值以及包括词语嵌入模型向量值和分类值的矩阵。
70.字典215可以包括深度学习库(例如,用于jvm的深度学习、微小神经网络(tinn)等)。深度学习库可以提供可以被用于为新词分类服务器200生成代码的模块和函数的库。深度学习库可以帮助促进新词分类服务器200的机器学习。
71.iii.用于执行新词分类的方法的概述
72.示例实施例针对新词分类。可以使用逻辑回归来执行分类。逻辑回归可以包括使用统计模型,该统计模型使用逻辑函数对变量建模。在所描述的示例中,使用二元分类(例如,两个分类),但是示例实施例不限于二元分类。例如,世代标识可以包括多于两个分类(例如,silent、boomer、x、millennial、z等)。分类可以基于多个可能的属性或特点。多个分类可以基于由用户输入的参数。
73.图3图示了根据一些示例实施例的用于对新词进行分类的方法300的流程图。图3是关于图4中所示的变量进行描述的。
74.图4是根据一些示例实施例的用于对新词进行分类的变量400的概览。图4中所示的变量可以是输入变量或输入值。变量“w”表示输入词语,它是新词或未知的词语或名字,变量“m”表示要用词语嵌入模型向量和分类值填充的矩阵,变量“k”表示已知最近邻(nearest neighbor)的数量的输入值,变量“s”表示包括已知最近名字的集合并且集合s中名字的数量将与输入值k中的数字对应,变量“wq”表示对于输入词语“w”的识别出的三元组并且变量“q”表示n个队列的列表,其中每个队列根据输入词语w和已知最近邻的集合s之间的最长公共子序列(lcs)进行初始化。n个队列的列表中的n表示队列数。每个队列都可以根据等式lcs(w,s[i])进行初始化。图4中的n的值是3,因为有三个最近邻。下面更详细地解释变量及其值。
[0075]
在步骤310处,接收初始输入。初始输入可以被称为新词或未知的词语或名字。新词由变量“w”表示。初始输入可以由用户选择以训练新词分类服务器对新词的属性进行分类。出于示例的目的,接收一个输入词语。但是,在示例实施例中,可以接收多个输入,诸如数据列(例如,电子表格中的数据列)中的多个词语。
[0076]
可以在数据丰富系统的用户界面上接收初始输入。未知的词语可以由用户手动输入。例如,可以经由数据丰富系统的用户界面输入新词。可替代地,未知的词语可以由新词分类服务器自动输入。新词分类服务器可以获得由数据丰富系统生成的一个或多个未知的词语或者可以从数据源获得一个或多个未知的词语。
[0077]
在图4中所示的示例中,输入词语w是“joanna”。但是,这只是为了解释的目的并且任何名字或词语都可以被用于分析。出于示例和易于解释的目的,使用已知名字来演示如何执行分类。示例实施例还可以不被用于识别已知名字的属性。
[0078]
示例实施例可以为新词或未知的词语或名字提供高准确性分类结果。示例实施例的有益之处在于帮助用户确定以前从未见过或名字库中不存在的名字的属性。名字和词语的库可以存储在数据存储库214中。虽然描述了名字,但是示例实施例适用于任何词语并且不限于名字。另外,描述了单个词语,但是示例实施例可以应用于一组词语、表述或短语。
[0079]
在步骤320处,确定输入词语的三元组。识别出的三元组可以由变量“wq”表示。由于字母的次序具有含义,因此三字组用按次序的字母识别;并且三元组的次序具有附加含义。因此,三元组是针对基于输入次词语按次序的三(3)个字母。可以通过三元组分析系统211来确定三元组。
[0080]
图5图示了根据一些示例实施例的输入词语的三元组500。如图5中所示,为在步骤310输入的词语识别出六个三元组。三元组是一组三个连续的书写单位,诸如字母、音节、符号或词语。在图4中所示的示例中,三元组是字母和符号的组。为输入词语“joanna”识别出的六个三元组包括“^jo、joa、oan、ann、nna、na$”。在词语“joanna”中以连续次序找到被识别出的三元组。符号“^”表示字符串的开头并且字符“$”表示字符串的结尾。即,在“字符串的开头”和“字符串的结尾”中,幽灵字符(例如,^和$)参与将词语分解成三元组。在生成三元组时,两个字母与前一个三元组重叠。
[0081]
在步骤330处,为三元组计算词语嵌入向量值。对于每个三元组wq,词语嵌入向量值都是经过训练的。词语嵌入向量值可以使用词语嵌入模型(诸如word2vec)计算。词语嵌入模型专门针对正被分析的词语类型进行训练。因此,在所描述的示例中,词语嵌入模型专门针对名(更具体而言,针对名的三元组)进行训练。
[0082]
训练词语嵌入模型以分析词语的三元组而不是整个词语。因此,针对三元组训练根据示例实施例的词语嵌入模型。由于三元组形成语言,因此对三元组执行训练。词语中的三元组以类似于句子中的词语如何形成语言的方式来形成语言。字符串中字母和三元组的位置和次序可能影响输入词语的分类。例如,基于三元组分析,可以确定女性名字比男性名字更通常地以元音结尾。
[0083]
在所描述的示例中,词语类型是名。其它类型或类别的词语可以包括姓氏或企业名字等。但是,这些仅仅是示例并且可以使用不同类型的名字或词语。词语嵌入模型专门针对正被分析的词语类型进行训练并且没有使用针对一般词语训练的通用词语嵌入模型。具体而言,使用通用词语嵌入模型不会产生与使用专门针对正被分析的词语类型训练的词语嵌入模型一样准确的结果。
[0084]
在步骤340处,计算出的向量值被输入到矩阵m中。即,矩阵m被填充以包括与三元组wq相关联的向量值。虽然在步骤340执行用向量值填充矩阵m,但可以在通过卷积神经网络运行矩阵之前的稍后时间执行矩阵m中向量值的填充。
[0085]
图6图示了根据一些示例实施例的具有三元组词语嵌入模型向量的矩阵m 600。
[0086]
如图6中所示,矩阵m 600包括在步骤320生成的三元组610。因此,矩阵m 600包括为输入词语“joanna”识别出的六个三元组的六行。矩阵m 600的行数将基于为新词确定的三元组的数量而变化。矩阵m 600包括词语嵌入模型向量列620。在所示的示例中,使用了300列的词语嵌入模型向量。矩阵m用三元组词语嵌入模型向量620填充。因此,词语嵌入模型的维度是300。300是没有欠拟合或过拟合的词语嵌入模型的数量。在示例中使用300,但是可以基于用户的需要使用更多或更少的向量。
[0087]
矩阵m 600还包括分类列630。在示例中,要确定两个分类(例如,男性和女性)。分类列的数量将取决于可能的分类数量或用户所期望的分类数量。例如,对于世代标识,可以存在与五种不同的可能世代分类(例如,silent、boomer、x、millennial、z等)对应的五个分类列。分类的类型可以基于正被分析的数据或基于用户期望的分类信息而变化。分类也可以被称为标签。
[0088]
如图6中所示,存在用于第一分类列(例如,男性)的第一列631和用于第二分类(例如,女性)的第二列632。图6中示出了两个分类,但是示例实施例不限于两个分类。因此,分类列的数量可以基于用户想要确定的分类而变化。示例实施例提供了用于填充矩阵m的分
类列的技术。
[0089]
创建矩阵m,其中行是词语嵌入模型向量,按照它们出现的次序一个接一个放置,从而使矩阵的垂直轴成为时间维度的形式。在词语嵌入模型中建模的“词语”是(三个字母的)三元组而不是词语,就像在情感分析技术中所做的那样。情感分析技术可以包括在从无监督神经语言模型获得的词语向量之上使用一个卷积层来训练cnn。卷积神经网络可以建立在词语嵌入模型(例如,word2vec)之上。使用输入训练数据(例如,名的字典)来训练词语嵌入模型。可以使用kim在https://arxiv.org/pdf/1408.5882.pdf的“convolutional neural networks for sentence classification”(2014)中公开的技术来实现情感分析,该文献出于所有目的通过引用并入本文。
[0090]
下面关于图7更详细地解释用于计算词语嵌入模型向量620的处理。
[0091]
在步骤350处,为输入词语确定k个最近名字或k个最近邻。可以使用相似性度量来识别k个最近邻或最近名字。相似性度量可以包括语义相似性度量,诸如jaccard或dice。k个最近名字是具有与输入词语相似的三元组的名字。即,k个最近名字是具有与输入名字“joanna”相似的三元组的名。
[0092]
为了识别k个最近邻,可以执行模糊串匹配。给定以前从未见过的字符串,相似性度量可以从字典中找到最接近的匹配项,然后,以k个最近邻的方式,基于k个最近邻的分类对以前从未见过的字符串的分类做出预测。正在被预测其分类的词语(例如,以前从未见过的名字)被遍历(run through),例如,statsim k个最近邻和前k(例如,3)个匹配被使用。前k个匹配在集合s中。
[0093]
可以识别k个最近名字。输入参数k表示最近名字的数量。在集合s中识别所确定的k个最近名字。为了简化说明,识别出3个最近名字。因此,k的值是3。但是,可以基于用户期望的结果来改变k的值。例如,在替代实施例中,k的值可以是10。
[0094]
图6的元素640示出了由变量k识别的k个最近名字的数量是3。因此,已为输入词语识别出3个最近名字。
[0095]
图8图示了根据一些示例实施例的输入词语的最近名字的集合s800。输入词语“joanna”的最近邻的集合s包括三个最近名字“joanne”、“john”和“anna”。
[0096]
在步骤360处,确定最长公共子序列。具体而言,识别关于来自输入词语的三元组与来自k个最近邻(“joanne”、“john”和“anna”)的三元组的最长公共子序列。
[0097]
图9图示了根据一些示例实施例的表示n个队列的列表的表格q 900。每个队列根据输入词语w与k个最近邻的集合之间的最长公共子序列(lcs)进行初始化。每个队列都可以根据等式lcs(w,s[i])进行初始化。根据在步骤350中识别出的k个最近名字,识别出最长公共子序列。
[0098]
表格q 900包括表示输入词语的三元组wq共有的k个最近邻的三元组的列940、包括k个最近邻的列950、以及识别列950中的相应k个最近邻的分类(例如,性别)的列960。在所示的示例中,因为存在三个最近邻(k=3),所以k个最近邻中的每一个都有三行。但是,这仅仅是出于解释的目的,并且k个最近邻不限于三个。例如,可以使用十个最近邻。取决于k个最近邻的数量,表格q 900会更大。
[0099]
行910与k个最近邻中的名字“joanne”对应,行920与k个最近邻中的名字“john”对应,并且行930与k个最近邻中的名字“anna”对应。行910与输入词语“joanne”对应。与“joanne”对应的行910包括三元组911(例如,^jo、joa、oan、ann)。与名字“john”对应的行920包括三元组912(例如,^jo)。与名字“anna”对应的行930包括三元组913(例如,ann、nna、na$)。
[0100]
三元组911、912和913匹配输入词语w“joanna”的三元组wq中的三元组。表格q 900中不包括与输入词语w“joanna”的三元组wq不匹配的k个最近邻(joanne、anna、john)的三元组。例如,名字“john”包括三元组“ohn”。由于三元组“ohn”与输入词语w“joanna”的三元组wq中的三元组不匹配,因此三元组“ohn”不包括在k个最近邻之一“john”的三元组912中。因此,将k个最近邻与输入名字共有的三元组放在表格q 900中。
[0101]
使用最长公共子序列(lcs)来确定k个最近邻与输入名字共有的三元组。给定两个输入字符串(例如,输入名字和最近邻之一),可以使用lcs算法来查找两个三元组列表之间的最长公共子序列。lcs算法可以使用wagner在http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.367.5281&rep=rep1&type=pdf的“the string-to-string correction problem”(1974)中公开的技术来实现,该文献出于所有目的通过引用并入本文。
[0102]
在步骤370处,计算分类值。分类值的计算关于图10和11更详细地解释。
[0103]
图12图示了根据一些示例实施例的包括用于第一分类1231和第二分类1232的分类值的矩阵m 1200。图12图示了在已经确定分类值并将其填充在矩阵m中之后的矩阵m。
[0104]
如图12中所示,矩阵m包括为输入词语w识别出的三元组wq中的每一个的6行1210。矩阵中的每一行表示三元组并且每个三元组与来自字典的n个statsim匹配词语中的一个或多个中的对应三元组匹配。矩阵m包括用于300列向量的词语嵌入向量值1220。
[0105]
矩阵m包括分类列1230。分类列包括第一分类列1231和第二分类列1232。描述了两个分类列,但是,分类或标签的数量可以基于由用户识别出的分类的类型而变化。分类的数量可以根据例如用户想要执行的营销的类型或用户想要定位的受众或用户的商业策略而变化。
[0106]
分类值表示有多少其它相似的名字包含该特定三元组。其它相似的名字是从已知名字的字典中获得的。在所描述的示例中,由于正在分析名字,因此字典是已知名字的字典。但是,如果正在分析不同类型的输入词语(例如,公司名字),那么将使用此类名字的字典进行三元组比较。
[0107]
如图12中所示,第一分类列1131包括分别三元组“^jo、joa、oan、ann、nna、na$”的值“0.3、0.1、0.0、0.0、0.0、0.0”。第二分类列1232包括分别三元组“^jo、joa、oan、ann、nna、na$”的值“0.1、0.4、0.3、0.5、0.3、0.3”。
[0108]
基于分类结果,第二分类列132产生比第一分类列1131更高的值。因此,输入词语“joanna”更有可能落入第二分类(例如,女性)。但是,因为矩阵被卷积神经网络(cnn)遍历,所以获得了更高的结果准确性。
[0109]
在步骤380处,矩阵m被卷积神经网络遍历。在已经用词语嵌入模型向量值和分类值来填充矩阵m之后,矩阵将遍历卷积神经网络。卷积神经网络可以识别输入词语更可能属于第一分类还是第二分类。
[0110]
示例实施例中的cnn分析包括来自词语嵌入模型的向量和使用三元组分析获得的分类值的矩阵。对于cnn可以使用修正线性单元(rectified linear unit,relu)权重初始
化,因为cnn中全局最大轮询层(global max-pooling layer)和密集层(dense layer)之间的激活是relu。下面关于图13更详细地解释卷积神经网络。
[0111]
iv.词语嵌入模型
[0112]
图7图示了根据一些示例实施例的用于计算词语的向量的一般处理700。但是,示例实施例将计算三元组的向量。
[0113]
在步骤710处,输入词语。在图7中所示的示例中,输入的词语集合可以包括“bridgestone”、“firestone”和“michelin”。但是,在示例实施例中,输入的词语集合可以包括为新词识别出的三元组。
[0114]
在步骤720处,分析输入数据集。可以通过使用机器学习技术(诸如word2vec)来分析数据,用以分析输入数据集。word2vec出于所有目的通过引用并入本文。word2vec可以使用mikolov等人在http://arxiv.org/pdf/1309.4168.pdf的“exploiting similarities between languages for machine translation”(2013)中公开的技术来实现,该文献出于所有目的通过引用并入本文。word2vec可以接收文本输入(例如,来自大型数据源的文本语料库)并生成每个输入词语的数据结构(例如,向量表示)作为词语的集合。数据结构在本文中可以被称为“模型”或“word2vec模型”。虽然描述了word2vec,但可以使用其它词语嵌入模型来执行数据分析。
[0115]
在步骤730处,词语的集合中的每个词语与多个属性相关联。属性也可以被称为特征、向量、成分和特征向量。例如,数据结构可以包括与词语的集合中的每个词语相关联的300个特征。特征可以包括例如描述词语的性别、国籍等。可以基于用于基于与情感的关联进行训练的机器学习(例如,监督式机器学习)的技术来确定每个特征。
[0116]
使用利用大型文本语料库(例如,新闻聚合器,或其它数据源(诸如google新闻语料库))构建的word2vec模型,可以为每个输入词语识别对应的数值向量值(例如,浮点数)。当分析这些向量时,可以确定向量在向量空间内(在欧几里得意义上)“接近”。如步骤740中所示,三个输入词语在向量空间内紧密地聚集在一起。
[0117]
在一些实施例中,word2vec模型可以由第三方提供者生成。word2vec模型可以经由提供者的应用编程接口(api)获得。api可以提供用于获得word2vec模型的函数,包括关于词语嵌入模型的信息,诸如模型中每个词语的成分的数量。
[0118]
步骤730可以包括基于训练数据生成数据结构(例如,向量数据结构)作为二维矩阵。矩阵中的每个轴(x轴和y轴)都有坐标或维度。对于训练数据,可以利用一个或多个应用(例如,lambda应用)基于最长文本字符串的长度来计算向量的高度。例如,为每条消息生成数据结构,其中高度是单个评论中的词语的最大数量。在构建二维矩阵时,每一行被定义为词语向量并且每一列可以被定义为特征向量。创建数据结构作为用于实现卷积神经网络(cnn)的api的输入。创建二维矩阵使得y轴针对单个消息中的每个词语都具有条目,并且x轴用于基线情感分析方法。x轴上的每个条目或维度与word2vec模型中的特征之一对应。可以为x轴上的词语列出多个特征。每个词语的每个特征都可以从基于训练数据生成的word2vec模型中获得。
[0119]
图6的词语嵌入模型向量列620图示了生成的数据结构(例如,向量数据结构)。
[0120]
v.计算分类值
[0121]
a.计算分类值的方法的概述
[0122]
图10图示了根据一些示例实施例的用于计算分类值的方法1000的流程图。图10中执行的步骤可以与图3的步骤370对应。
[0123]
在步骤1010处,识别来自输入词语的三元组。识别出的三元组wq可以是在图3的步骤320中识别出的三元组。
[0124]
在步骤1020处,识别与输入词语的三元组共有的k个最近邻的三元组。如图9中所示,列940表示与输入词语的三元组wq共有的k个最近邻的三元组。
[0125]
在步骤1030处,将来自输入词语的三元组与k个最近邻中的每一个的三元组进行比较。将来自输入词语的三元组之间的匹配频率与k个最近邻中的每一个的三元组进行比较。可以使用计数器来确定匹配频率。
[0126]
在步骤1040处,基于输入词语中的三元组与来自k个最近邻的三元组之间的匹配频率来计算分类值。
[0127]
在步骤1050处,未知的词语的三元组的分类值用计算出的分类值填充。分类值可以填充在矩阵中。
[0128]
在已经确定三元组的分类值并将其填充在矩阵中之后,矩阵可以被卷积神经网络遍历。
[0129]
b.计算分类值的详细方法
[0130]
图11图示了根据一些示例实施例的用于计算分类值的方法1100的详细流程图。图11中执行的步骤可以与图3的步骤370对应。图11更详细地描述了图10中执行的步骤。
[0131]
图11中所示的方法可以用下式表示:
[0132]
逐行循环遍历矩阵m
[0133]
循环遍历q
[0134]
如果wq[0]==q[i][0]
[0135]
弹出q[i]
[0136]
递增与s[i]相关联的c[j]
[0137]
用λ
·
c[j]/k填充矩阵m的附加列
[0138]
变量c表示计数器。可以为每个可能的分类发起计数器c。计数器可以是临时存储的临时计数器。例如,计数器可以存储在数据存储库214中。在所描述的示例中,要确定两个分类(例如,男性和女性),因此可以发起两个计数器。变量λ用于缩放附加特征列。出于示例的目的,变量λ由值.001表示。变量λ的值基于需要被缩放或使其更容易与词语嵌入模型向量值进行比较的数据的值。变量q表示n个队列的列表,如图9中所示。
[0139]
变量q[i]表示k个邻居之一。可以使用k最近邻(knn)算法获得k个邻居。因此,q[i]表示与三元组wq共有的k个邻居之一的三元组。c[j]中的变量j表示分类。因此,变量c[j]表示用于分类的计数器。
[0140]
在所描述的示例中,输入词语w的三元组wq是“^jo、joa、oan、ann、nna、na$”。用于k个邻居的q中的三元组是“^jo、joa、oan、ann”、“^jo”和“ann、nna、na$”。最近名字的集合s包括“joanne”、“john”和“anna”。这个示例中的q包括用于三个最近邻的n=3个队列的列表。
[0141]
在步骤1110处,为每个可能的分类发起计数器c。计数器可以由c[j]表示。j表示分类(例如,第一、第二、第三等)。在所描述的示例中,由于有两个分类(例如,男性和女性),因此发起两个计数器。第一计数器c[0]可以与第一分类(例如,男性)对应,并且第二计数器c
[1]可以与第二分类(例如,女性)对应。计数器可以存储在新词分类服务器的数据存储库上。在已经分析了wq的三元组之后,在每次迭代之后,可以移除计数器,并且可以发起新的计数器。
[0142]
在步骤1120处,识别或选择输入词语w的矩阵m中的三元组(例如,^jo)以用于分析。图11的方法将继续针对输入词语的每个三元组wq重复。用于分析的矩阵m中的三元组一次一个地被循环遍历。由于wq中有六个三元组“^jo、joa、oan、ann、nna、na$”,因此要分析的第一个三元组是“^jo”,最后一个要分析的三元组是“na$”。因此,对于包括六个三元组wq的示例,步骤1120-1170可以针对每个三元组重复六次。
[0143]
在步骤1130处,确定与在步骤1120处识别出的三元组匹配的用于k个最近邻(例如,joanne、john、anna)的n个队列的列表格q中的三元组(例如,^jo)。在这个示例中,三元组^jo出现了两次。确定与输入词语的第一个三元组匹配的k个最近名字的三元组。一次针对k个最近邻“joanne”,一次针对k个最近邻“john”。
[0144]
在步骤1140处,确定与来自输入词语的三元组匹配的特定最近邻的匹配三元组的分类。匹配三元组(例如,^jo)的分类是从例如列960中识别出来的,该列960指示相应最近邻的分类。因此,由于joanne和john两者都包括三元组“^jo”,因此识别出名字“joanne”的分类(例如,女性)并且识别出名字“john”的分类(例如,男性)。
[0145]
在步骤1150处,与分类相关联的计数器递增。用于与k个最近名字的一个或多个三元组的所确定的分类对应的多个分类中的每一个的计数器递增。由于特定最近邻“joanne”的分类是“女性”,因此用于第二个分类的第二个计数器c[2]递增。由于特定最近邻“john”的分类是“男性”,因此用于第一个分类的第一个计数器c[1]也递增。
[0146]
在步骤1160处,可以更新n个队列的列表q。与输入词语三元组(例如,^jo)匹配的三元组(例如,^jo)可以从n个队列的列表q中移除(例如,对于名字“joanne”和名字“john”)。
[0147]
在步骤1170处,分类值可以被填充在识别出的三元组wq的矩阵m中。因此,图12的分类列1230中的行1233中所示的分类值将在步骤1170之后填充在矩阵中。
[0148]
在示例实施例中,在已经对每个三元组(例如,^jo、joa、oan、ann、nna、na$)进行分类之后填充分类值。但是,可以在已经分析了输入词语的所有三元组wq之后执行矩阵m中的分类值的填充。
[0149]
可以基于等式λ
·
c[j]/k来填充分类列。k是最近邻的数量或量。变量λ用于缩放。执行缩放以使得分类值与列1220中的词语嵌入模型值处于相同的数量级。上例中的词语嵌入值在小数点前有三个前导零。如果分类值没有被缩放,那么分类值中的额外列可能会淹没cnn。
[0150]
在1180处,确定是否存在用于要分析的输入词语的附加三元组wq。重复步骤1020、1030、1040、1050、1060和1070,直到输入词语的所有三元组wq都与k个最近邻的三元组进行了比较为止。也就是说,重复步骤1020、1030、1040、1050、1060和1070,直到输入词语w“joanna”的所有三元组wq都与用于k个最近邻的n个队列的列表q中的所有三元组进行了比较。
[0151]
当要分析的输入词语w存在附加的三元组wq时,对wq中的下一个三元组重复步骤1020。例如,wq中要分析的下一个三元组是“joa”。
[0152]
当在步骤1180确定输入词语w不存在要分析的附加三元组wq时,处理结束。
[0153]
c.用分类值填充的矩阵
[0154]
图12图示了根据一些示例实施例的被完成以包括分类值的矩阵m。图12中所示的矩阵m是执行图10和图11中所示的方法之后填充的矩阵。
[0155]
如图12中所示,第一分类列1231分别包括三元组“^jo、joa、oan、ann、nna、na$”的值“0.3、0.1、0.0、0.0、0.0、0.0”。第二分类列1232分别包括三元组“^jo、joa、oan、ann、nna、na$”的值“0.1、0.4、0.3、0.5、0.3、0.3”“。
[0156]
基于分类结果,第二分类列1232产生比第一分类列1231更高的值。因此,输入词语“joanna”更有可能落入第二分类(例如,女性)。
[0157]
但是,为了确保分类结果的准确性,矩阵m将被cnn遍历。来自cnn的输出是长度为n的softmax向量,其中n是可能的分类的数量。softmax函数是可以将k个实数的向量z取作输入并将输入归一化为由与输入数的指数成正比的k个概率组成的概率分布的函数。在softmax向量中,每个分量表示样本在该类中的概率(介于0.0和1.0之间)。通常选择概率最大的类作为预测,并且忽略其它概率。
[0158]
vi.卷积神经网络
[0159]
图13图示了根据一些示例实施例的卷积神经网络1300。
[0160]
图13图示了标准卷积神经网络的示例。用于对句子建模的卷积神经网络(cnn)可以使用kalchbrenner的“a convolutional neural network for modeling sentences”(2014)[http://www.aclweb.org/anthology/p14-1062]中的技术,该文献出于所有目的通过引用并入本文。cnn可以使用一维卷积层来实现。cnn可以使用由第三方(例如,github)提供的包或库来实现。该包可以是使用针对java和scala的deeplearning4j和/或python实现的keras。另外,cnn可以是例如三层或七层cnn。这些仅仅是示例,并且可以使用不同的cnn。另外,cnn可以由用户独立创建。
[0161]
在至少一个实施例中,参考用于每个消息的向量的阵列可以与cnn技术一起使用以确定情绪分析。技术的示例可以基于在http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/和https://github.com/fchollet/keras/blob/master/examples/imdb_cnn.py/找到的内容实现,这些文献出于所有目的通过引用并入本文。可以设置变量的值为filter length=3、cnndensedropout=0.2、dense_dims=20、batch_size=10、nb_epoch=5、validation_split=0.1,用以实现cnn技术。可以通过使用上面生成的数据结构执行以下函数调用来实现cnn。cnn可以基于词语的数据结构被实现为一维结构。
[0162]
通过基于函数调用执行cnn,执行训练数据以使用cnn进行测试以执行初始情感分析。
[0163]
vii.用户界面
[0164]
图14图示了根据一些示例实施例的用于执行新词分类的用户界面1400。
[0165]
用户界面1400可以显示在图1中所示的分析系统110的数据丰富系统120的显示器上。用户界面1400包括来自数据集的多列数据1420。数据集可以包括例如客户信息或电子表格中可用的其它类型的数据。在图14中所示的示例中,客户信息包括城市名称、州和邮政编码。但是,这仅仅是示例并且数据集可以包括各种类型的信息。
[0166]
用户可以输入要对其执行新词分类的数据集。例如,用户可以在数据丰富系统的交互式用户界面上选择数据集。用户界面可以显示可以从中获得数据集的多个数据源选项。用户可以上传他们想要丰富、分析或可视化的数据集。数据集可以采用列的形式,诸如电子表格。
[0167]
用户界面1400包括推荐面板1410。推荐面板为用户提供要应用于数据集的一个或多个操作推荐。例如,推荐可以包括通过确定用于一列数据的新词来丰富数据。推荐可以包括通过对数据集中的一列或多列数据执行新词分类来丰富数据。例如,用户可以通过执行新词分类来选择推荐1430以丰富数据集的城市列。
[0168]
数据丰富系统被配置为提供用于对数据集执行处理的推荐,诸如丰富数据。也就是说,数据丰富系统可以分析数据集并为用户提供针对数据集的推荐操作以丰富数据。数据丰富系统可以基于所提供的数据集来自动确定哪些丰富将对数据有益。
[0169]
给定数据集,其一部分在面板1410中示出,通过选择执行新词分类(元素1430)可以向用户提供丰富数据列的推荐。图14图示了用户界面的简化视图,用户可以在该界面上选择执行新词分类。在执行新词分类之前,可以提供附加显示或者可以提示用户提供附加信息。
[0170]
因此,在示例实施例中,如果数据集包括可以对其执行新词分类的数据,那么数据丰富系统可以建议用户执行新词分类。当用户选择执行新词分类时(例如,选择元素1430),可以对所选择的数据列实现新词分类。
[0171]
示例实施例提供具有提高的准确性的系统、方法和计算机可读介质。因此,示例实施例在确定新词的分类方面提供了改进。
[0172]
由于示例实施例提供高度准确的分类,因此提供给数据丰富系统的用户的数据可以更完整。从而使数据对用户更有用。
[0173]
示例实施例可以包括三元组、用于三元组的词语嵌入模型(例如,word2vec)、k个最近名字(例如,statsim)、具有计数器的附加分类(例如,男性/女性)以及卷积神经网络(cnn)的组合。
[0174]
三元组在准确确定与新词相关联的特点方面提供改进的结果。含义是从三元组的次序推断出来的,而不仅仅是三元组本身的值。
[0175]
另外,示例实施例对三元组使用词语嵌入模型cnn的组合。对于附加特征,附加列被添加到矩阵的右侧。
[0176]
viii.硬件概述
[0177]
图15描绘了用于实现实施例的分布式系统1500的简化图。在图示的实施例中,分布式系统1500包括经由一个或多个通信网络1510耦合到服务器1512的一个或多个客户端计算设备1502、1504、1506和1508。客户端计算设备1502、1504、1506和1508可以被配置为执行一个或多个应用。
[0178]
在各种实施例中,服务器1512可以适于运行一个或多个服务或软件应用,这些服务或软件应用使得能够自动生成正则表达式,如本公开中所描述的。例如,在某些实施例中,服务器1512可以接收从客户端设备传输的用户输入数据,其中用户输入数据是由客户端设备通过在客户端设备处显示的用户界面接收的。服务器1512然后可以将用户输入数据转换成正则表达式,该正则表达式被传输到客户端设备以通过用户界面显示。
[0179]
在某些实施例中,服务器1512还可以提供可以包括非虚拟和虚拟环境的其它服务或软件应用。在一些实施例中,这些服务可以作为基于web或基于云的服务(诸如在软件即服务(saas)模型下)被提供给客户端计算设备1502、1504、1506和/或1508的用户。操作客户端计算设备1502、1504、1506和/或1508的用户进而可以利用一个或多个客户端应用与服务器1512进行交互以利用由这些组件提供的服务。
[0180]
在图15所描绘的配置中,服务器1512可以包括实现由服务器1512执行的功能的一个或多个组件1518、1520和1522。这些组件可以包括可以由一个或多个处理器执行的软件组件、硬件组件或其组合。应当认识到的是,各种不同的系统配置是可能的,其可以与分布式系统1500不同。因此,图15中所示的实施例是用于实现实施例系统的分布式系统的一个示例,并且不旨在进行限制。
[0181]
用户可以使用客户端计算设备1502、1504、1506和/或1508来执行一个或多个应用,该一个或多个应用可以根据本公开的教导生成正则表达式。客户端设备可以提供使客户端设备的用户能够与客户端设备进行交互的接口。客户端设备还可以经由该接口向用户输出信息。虽然图15仅描绘了四个客户端计算设备,但可以支持任何数量的客户端计算设备。
[0182]
客户端设备可以包括各种类型的计算系统,诸如便携式手持式设备、通用计算机,诸如个人计算机和膝上型计算机、工作站计算机、可穿戴设备、游戏系统、瘦客户端、各种消息传送设备、传感器和其它感测设备等。这些计算设备可以运行各种类型和版本的软件应用和操作系统(例如,microsoftapple或类unix操作系统、linux或类linux操作系统(诸如google chrome
tm os)),包括各种移动操作系统(例如,microsoft windowswindowsandroid
tm
、palm)。便携式手持式设备可以包括蜂窝电话、智能电话(例如,)、平板电脑(例如,)、个人数字助理(pda)等。可穿戴设备可以包括google头戴式显示器和其它设备。游戏系统可以包括各种手持式游戏设备、互联网实现的游戏设备(例如,具有或不具有手势输入设备的microsoft游戏控制台、sony系统、由提供的各种游戏系统及其它)等。客户端设备可以能够执行各种不同的应用,诸如各种互联网相关的应用、通信应用(例如,电子邮件应用、短消息服务(sms)应用),并且可以使用各种通信协议。
[0183]
(一个或多个)网络1510可以是本领域技术人员熟悉的任何类型的网络,该(一个或多个)网络可以使用各种可用协议中的任何协议来支持数据通信,其中协议包括但不限于tcp/ip(传输控制协议/互联网协议)、sna(系统网络体系架构)、ipx(互联网分组交换)、等。仅仅作为示例,(一个或多个)网络1510可以是局域网(lan)、基于以太网的网络、令牌环、广域网(wan)、互联网、虚拟网络、虚拟专用网(vpn)、内联网、外联网、公共电话交换网(pstn)、红外网络、无线网络(例如,在电气和电子协会(ieee)1002.11协议套件、和/或任何其它无线协议中的任何一种下操作的网络)和/或这些网络和/或其它网络的任何组合。
[0184]
服务器1512可以包括一个或多个通用计算机、专用服务器计算机(作为示例,包括pc(个人计算机)服务器、服务器、中档服务器、大型计算机、机架安装的服务器等)、服务器场、服务器集群或任何其它适当的布置和/或组合。服务器1512可以包括运行虚拟操作系统的一个或多个虚拟机,或者涉及虚拟化的其它计算体系架构,诸如可以被虚拟化以维护服务器的虚拟存储设备的逻辑存储设备的一个或多个灵活池。在各种实施例中,服务器1512可以适于运行提供前述公开中描述的功能的一个或多个服务或软件应用。
[0185]
服务器1512中的计算系统可以运行一个或多个操作系统,包括以上讨论的任何操作系统以及任何商业可用的服务器操作系统。服务器1512还可以运行各种附加服务器应用和/或中间层应用中的任何一种,包括http(超文本传输协议)服务器、ftp(文件传输协议)服务器、cgi(通用网关接口)服务器、服务器、数据库服务器等。示例性数据库服务器包括但不限于可从器包括但不限于可从(国际商业机器)等商购获得的数据库服务器。
[0186]
在一些实施方式中,服务器1512可以包括一个或多个应用以分析和整合从客户端计算设备1502、1504、1506和1508的用户接收到的数据馈送和/或事件更新。作为示例,数据馈送和/或事件更新可以包括但不限于从一个或多个第三方信息源和连续数据流接收到的实时更新、馈送或更新,其可以包括与传感器数据应用、金融报价机、网络性能测量工具(例如,网络监视和流量管理应用)、点击流分析工具、汽车流量监视等相关的实时事件。服务器1512还可以包括经由客户端计算设备1502、1504、1506和1508的一个或多个显示设备显示数据馈送和/或实时事件的一个或多个应用。
[0187]
分布式系统1500还可以包括一个或多个数据储存库1514、1516。在某些实施例中,这些数据储存库可以用于存储数据和其它信息。例如,数据储存库1514、1516中的一个或多个可以用于存储诸如与系统生成的正则表达式匹配的新数据列之类的信息。数据储存库1514、1516可以驻留在各种位置。例如,由服务器1512使用的数据储存库可以在服务器1512本地,或者可以远离服务器1512并经由基于网络或专用的连接与服务器1512通信。数据储存库1514、1516可以是不同的类型。在某些实施例中,由服务器1512使用的数据储存库可以是数据库,例如关系数据库,诸如由oracle公司(oracle)和其它供应商提供的数据库。这些数据库中的一个或多个可以适于响应于sql格式的命令来实现去往和来自数据库的数据的存储、更新和检索。
[0188]
在某些实施例中,应用还可以使用数据储存库1514、1516中的一个或多个来存储应用数据。由应用使用的数据储存库可以具有不同的类型,诸如例如键-值存储储存库、对象存储储存库或由文件系统支持的通用存储储存库。
[0189]
在某些实施例中,本公开中描述的功能可以经由云环境作为服务来提供。图16是根据某些示例的基于云的系统环境1600的简化框图,其中各种服务可以作为云服务提供。在图16中描绘的示例中,云基础设施系统1602可以提供一种或多种云服务,这些服务可以由使用一个或多个客户端计算设备1604、1606和1608的用户请求。云基础设施系统1602可以包括一个或多个计算机和/或服务器,这些计算机和/或服务器可以包括上面针对服务器2112描述的那些计算机和/或服务器。云基础设施系统1602中的计算机可以被组织为通用计算机、专用服务器计算机、服务器群、服务器集群或任何其它适当的布置和/或组合。
[0190]
(一个或多个)网络1610可以促进客户端1604、1606和1608与云基础设施系统1602之间的通信和数据交换。(一个或多个)网络1610可以包括一个或多个网络。网络可以是相同或不同的类型。(一个或多个)网络1610可以支持一种或多种通信协议,包括有线和/或无线协议,用于促进通信。
[0191]
图16中描绘的示例仅仅是云基础设施系统的一个示例,并且不旨在进行限制。应该认识到的是,在一些其它示例中,云基础设施系统1602可以具有比图16所示的组件更多或更少的组件、可以组合两个或更多个组件、或者可以具有不同的组件配置或布置。例如,虽然图16描绘了三个客户端计算设备,但是在替代示例中可以支持任何数量的客户端计算设备。
[0192]
术语“云服务”通常用于指由服务提供商的系统(例如,云基础设施系统1602)根据需要并且经由诸如互联网之类的通信网络使得对用户可用的服务。通常,在公共云环境中,组成云服务提供商系统的服务器和系统与客户自己的本地服务器和系统不同。云服务提供商系统由云服务提供商管理。客户因此可以自己利用由云服务提供商提供的云服务,而不必为服务购买单独的许可证、支持或硬件和软件资源。例如,云服务提供商系统可以托管应用,并且用户可以经由互联网按需订购和使用应用,而用户不必购买用于执行应用的基础设施资源。云服务旨在提供对应用、资源和服务的轻松、可扩展的访问。若干提供商提供云服务。例如,由加利福尼亚州redwood shores的oracle公司(oracle )提供了若干云服务,诸如中间件服务、数据库服务、java云服务等。
[0193]
在某些实施例中,云基础设施系统1602可以使用不同模型(诸如软件即服务(saas)模型、平台即服务(paas)模型、基础设施即服务(iaas)模型以及包括混合服务模型的其它模型)来提供一个或多个云服务。云基础设施系统1602可以包括一套应用、中间件、数据库以及使得能够供应各种云服务的其它资源。
[0194]
saas模型使得应用或软件能够作为服务通过通信网络(如互联网)被递送给客户,而客户不必为底层应用购买硬件或软件。例如,saas模型可以用于为客户提供对由云基础设施系统1602托管的按需应用的访问。由oracle公司(oracle )提供的saas服务的示例包括但不限于用于人力资源/资本管理、客户关系管理(crm)、企业资源计划(erp)、供应链管理(scm)、企业绩效管理(epm)、分析服务、社交应用及其它的各种服务。
[0195]
iaas模型通常用于向客户提供基础设施资源(例如,服务器、存储装置、硬件和联网资源)作为云服务,以提供弹性计算和存储能力。公司提供了各种iaas服务。
[0196]
paas模型通常用于提供平台和环境资源作为服务,该平台和环境资源使得客户能够开发、运行和管理应用和服务,而客户不必采购、构建或维护此类资源。由oracle公司(oracle )提供的paas服务的示例包括但不限于oracle java云服务(jcs)、oracle数据库云服务(dbcs)、数据管理云服务、各种应用开发解决方案服务、以及其它服务。
[0197]
云服务通常基于按需自助服务、基于订阅、弹性可缩放、可靠、高度可用和安全的方式来提供。例如,客户可以经由订阅订单订购由云基础设施系统1602提供的一个或多个服务。云基础设施系统1602然后执行处理以提供客户的订购订单中所请求的服务。云基础设施系统1602可以被配置为提供一个或多个云服务。
[0198]
云基础设施系统1602可以经由不同的部署模型来提供云服务。在公共云模型中,云基础设施系统1602可以由第三方云服务提供商拥有,并且云服务被提供给任何普通公众客户,其中客户可以是个人或企业。在私有云模型下,可以在组织内(例如,在企业组织内)操作云基础设施系统1602,并向组织内的客户提供服务。例如,客户可以是企业的各个部门,诸如人力资源部门、工资部门等,甚至是企业内的个人。在社区云模型下,云基础设施系统1602和所提供的服务可以由相关社区中的若干组织共享。也可以使用各种其它模型,诸如上面提到的模型的混合。
[0199]
客户端设备1604、1606和1608可以是不同类型的(诸如图15中描绘的客户端设备1502、1504、1506和1508),并且可以能够操作一个或多个客户端应用。用户可以使用客户端设备与云基础设施系统1602进行交互,用以诸如请求由云基础设施系统1602提供的服务。
[0200]
在一些实施例中,由云基础设施系统1602执行的用于提供与管理相关的服务的处理可以涉及大数据分析。这种分析可能涉及使用、分析和操纵大型数据集,以检测和可视化数据内的各种趋势、行为、关系等。这种分析可以由一个或多个处理器执行、可能并行处理数据、使用数据执行仿真等。例如,大数据分析可以由云基础设施系统1602执行,用于以自动化方式确定正则表达式。用于这种分析的数据可以包括结构化数据(例如,存储在数据库中的数据或根据结构化模型进行结构化的数据)和/或非结构化数据(例如,数据blob(二进制大对象))。
[0201]
如图16的示例中所描绘的,云基础设施系统1602可以包括基础设施资源1630,该基础设施资源用于促进由云基础设施系统1602提供的各种云服务的供应。基础设施资源1630可以包括例如处理资源、存储或存储器资源、联网资源等。
[0202]
在某些实施例中,为了促进这些资源的高效供应以支持由云基础设施系统1602为不同客户提供的各种云服务,可以将资源捆绑成资源或资源模块的集合(也称为“群聚(pod)”)。每个资源模块或群聚可以包括一种或多种类型的资源的预先集成和优化组合。在某些实施例中,可以为不同类型的云服务预先供应不同的群聚。例如,可以为数据库服务供应第一群聚集合,可以为java服务供应第二群聚集合,其中第二群聚集合可以包括与第一群聚集合中的群聚不同的资源组合。对于一些服务,可以在服务之间共享为供应服务而分配的资源。
[0203]
云基础设施系统1602本身可以内部使用服务1632,服务1632由云基础设施系统1602的不同组件共享并且促进云基础设施系统1602的服务供应。这些内部共享的服务可以包括但不限于安全和身份服务、集成服务、企业储存库服务、企业管理器服务、病毒扫描和白名单服务、高可用性、备份和恢复服务、用于启用云支持的服务、电子邮件服务、通知服务、文件传输服务等。
[0204]
云基础设施系统1602可以包括多个子系统。这些子系统可以用软件或硬件或其组合来实现。如图16所示,子系统可以包括用户界面子系统1612,该用户界面子系统1612使得云基础设施系统1602的用户或客户能够与云基础设施系统1602进行交互。用户界面子系统1612可以包括各种不同的界面,诸如web界面1614、在线商店界面1616(其中由云基础设施系统1602提供的云服务被广告并且可由消费者购买)和其它界面1618。例如,客户可以使用客户端设备使用界面1614、1616和1618中的一个或多个来请求(服务请求1634)由云基础设施系统1602提供的一个或多个服务。例如,客户可以访问在线商店、浏览由云基础设施系统
1602提供的云服务、以及对由客户希望订阅的由云基础设施系统1602提供的一个或多个服务下订单。服务请求可以包括识别客户的信息以及客户期望订阅的一个或多个服务。例如,客户可以对于由云基础设施系统1602提供的正则表达式相关服务的自动化生成下订阅订单。
[0205]
在某些实施例(诸如图16描绘的示例)中,云基础设施系统1602可以包括被配置为处理新订单的订单管理子系统(oms)1620。作为这个处理的一部分,oms 1620可以被配置为:为客户创建账户(如果尚未创建);接收来自客户的账单和/或会计信息,该账单和/或会计信息将用于针对向客户提供所请求的服务对客户计费;验证客户信息;在验证后,为客户预订订单;以及编排各种工作流程以准备用于供应的订单。
[0206]
一旦被正确地验证,oms 1620就可以调用订单供应子系统(ops)1624,该订单供应子系统被配置为为订单供应资源,包括处理资源、存储器资源和联网资源。供应可以包括为订单分配资源,以及配置资源来促进客户订单所请求的服务。为订单供应资源的方式和供应资源的类型可以取决于客户已经订购的云服务的类型。例如,根据一个工作流程,ops 1624可以被配置为确定正在被请求的特定云服务,并且识别可能已经针对该特定云服务而被预先配置的多个群聚。为订单分配的群聚的数量可以取决于所请求的服务的大小/数量/级别/范围。例如,可以基于服务所支持的用户的数量、正在请求的服务的持续时间等来确定要分配的群聚的数量。然后,可以针对特定的请求客户定制所分配的群聚,用于提供所请求的服务。
[0207]
云基础设施系统1602可以向发出请求的客户发送响应或通知1644,以指示所请求的服务何时准备就绪。在一些情况下,可以将信息(例如,链接)发送给客户,使得客户能够开始使用和利用所请求的服务的益处。在某些实施例中,对于请求正则表达式相关服务的自动化生成的客户,响应可以包括在被执行时使得显示用户界面的指令。
[0208]
云基础设施系统1602可以向多个客户提供服务。对于每个客户,云基础设施系统1602负责管理与从客户接收到的一个或多个订阅订单相关的信息、维护与订单相关的客户数据、以及向客户提供所请求的服务。云基础设施系统1602还可以收集关于客户对已订阅的服务的使用的使用统计信息。例如,可以针对使用的存储量、传输的数据量、用户的数量以及系统正常运行时间和系统停机时间量等收集统计信息。该使用信息可以用于向客户计费。计费可以例如按月周期进行。
[0209]
云基础设施系统1602可以并行地向多个客户提供服务。云基础设施系统1602可以存储这些客户的信息,包括可能的专有信息。在某些实施例中,云基础设施系统1602包括身份管理子系统(ims)1628,该身份管理子系统被配置为管理客户信息并提供所管理的信息的分离,使得与一个客户相关的信息无法被另一个客户访问。ims 1628可以被配置为提供各种与安全相关的服务,诸如身份服务;信息访问管理、认证和授权服务;用于管理客户身份和角色及相关能力的服务等。
[0210]
图17图示了根据一些示例实施例的计算机系统1700的示例。在一些实施例中,计算机系统1700可以用于实现上述任何系统。如图17所示,计算机系统1700包括各种子系统,包括经由总线子系统1702与多个其它子系统通信的处理子系统1704。这些其它子系统可以包括处理加速单元1706、i/o子系统1708、存储子系统1718和通信子系统1724。存储子系统1718可以包括非暂态计算机可读存储介质,其包括存储介质1722和系统存储器1710。
[0211]
总线子系统1702提供用于使计算机系统1700的各种组件和子系统按照期望彼此通信的机制。虽然总线子系统1702被示意性地示为单条总线,但是总线子系统的替代示例可以利用多条总线。总线子系统1702可以是若干种类型的总线结构中的任何总线结构,包括存储器总线或存储器控制器、外围总线、使用各种总线体系架构中的任何总线体系架构的局部总线等。例如,此类体系架构可以包括工业标准体系架构(isa)总线、微通道体系架构(mca)总线、增强型isa(eisa)总线、视频电子标准协会(vesa)局部总线和外围组件互连(pci)总线,其可以实现为根据ieee p1386.1标准制造的夹层(mezzanine)总线等。
[0212]
处理子系统1704控制计算机系统1700的操作,并且可以包括一个或多个处理器、专用集成电路(asic)或现场可编程门阵列(fpga)。处理器可以包括单核或多核处理器。可以将计算机系统1700的处理资源组织成一个或多个处理单元1732、1734等。处理单元可以包括一个或多个处理器、来自相同或不同处理器的一个或多个核、核和处理器的组合、或者核和处理器的其它组合。在一些实施例中,处理子系统1704可以包括一个或多个专用协处理器,诸如图形处理器、数字信号处理器(dsp)等。在一些实施例中,处理子系统1704的一些或全部处理单元可以使用定制电路(诸如专用集成电路(asic)或现场可编程门阵列(fpga))来实现。
[0213]
在一些实施例中,处理子系统1704中的处理单元可以执行存储在系统存储器1710中或计算机可读存储介质1722上的指令。在各个示例中,处理单元可以执行各种程序或代码指令,并且可以维护多个并发执行的程序或进程。在任何给定的时间,要执行的程序代码中的一些或全部可以驻留在系统存储器1710中和/或计算机可读存储介质1722上,包括可能在一个或多个存储设备上。通过适当的编程,处理子系统1704可以提供上述各种功能。在计算机系统1700正在执行一个或多个虚拟机的情况下,可以将一个或多个处理单元分配给每个虚拟机。
[0214]
在某些实施例中,可以可选地提供处理加速单元1706,以用于执行定制的处理或用于卸载由处理子系统1704执行的一些处理,从而加速由计算机系统1700执行的整体处理。
[0215]
i/o子系统1708可以包括用于向计算机系统1700输入信息和/或用于从计算机系统1700或经由计算机系统1700输出信息的设备和机制。一般而言,术语“输入设备”的使用旨在包括用于向计算机系统1700输入信息的所有可能类型的设备和机制。用户界面输入设备可以包括例如键盘、诸如鼠标或轨迹球之类的指向设备、并入到显示器中的触摸板或触摸屏、滚轮、点击轮、拨盘、按钮、开关、小键盘、带有语音命令识别系统的音频输入设备、麦克风以及其它类型的输入设备。用户界面输入设备还可以包括使用户能够控制输入设备并与之交互的运动感测和/或姿势识别设备(诸如microsoft运动传感器)、microsoft360游戏控制器、提供用于接收使用姿势和口语命令的输入的界面的设备。用户界面输入设备还可以包括眼睛姿势识别设备,诸如从用户检测眼睛活动(例如,当拍摄图片和/或进行菜单选择时的“眨眼”)并将眼睛姿势转换为到输入设备(例如,google)的输入的google眨眼检测器。此外,用户界面输入设备可以包括使得用户能够通过语音命令与语音识别系统(例如,导航器)进行交互的语音识别感测设备。
[0216]
用户界面输入设备的其它示例包括但不限于:三维(3d)鼠标、操纵杆或指向杆、游戏板和图形平板、以及音频/视频设备,诸如扬声器、数字相机、数字摄录机、便携式媒体播放器、网络摄像机(webcam)、图像扫描仪、指纹扫描仪、条形码读取器3d扫描仪、3d打印机、激光测距仪、以及眼睛注视跟踪设备。此外,用户界面输入设备可以包括例如医疗成像输入设备,诸如计算机断层摄影、磁共振成像、位置发射断层摄影、以及医疗超声检查设备。用户界面输入设备也可以包括例如音频输入设备,诸如midi键盘、数字乐器等。
[0217]
一般而言,术语“输出设备”的使用旨在包括用于从计算机系统1700向用户或其它计算机输出信息的所有可能类型的设备和机制。用户界面输出设备可以包括显示子系统、指示器灯或诸如音频输出设备的非可视显示器等。显示子系统可以是阴极射线管(crt)、平面板设备(诸如使用液晶显示器(lcd)或等离子体显示器的平面板设备)、投影设备、触摸屏等。例如,用户界面输出设备可以包括但不限于:可视地传达文本、图形和音频/视频信息的各种显示设备,诸如监视器、打印机、扬声器、耳机、汽车导航系统、绘图仪、语音输出设备和调制解调器。
[0218]
存储子系统1718提供用于存储由计算机系统1700使用的信息和数据的储存库或数据存储库。存储子系统1718提供了用于存储提供某些示例的功能的基本编程和数据构造的有形非暂态计算机可读存储介质。存储子系统1718可以存储软件(例如,程序、代码模块、指令),该软件在由处理子系统1704执行时提供上述功能。软件可以由处理子系统1704的一个或多个处理单元执行。存储子系统1718还可以提供用于存储根据本公开的教导使用的数据的储存库。
[0219]
存储子系统1718可以包括一个或多个非暂态存储器设备,包括易失性和非易失性存储器设备。如图17所示,存储子系统1718包括系统存储器1710和计算机可读存储介质1722。系统存储器1710可以包括多个存储器,包括用于在程序执行期间存储指令和数据的易失性主随机存取存储器(ram)以及其中存储有固定指令的非易失性只读存储器(rom)或闪存。在一些实施方式中,基本输入/输出系统(bios)可以典型地存储在rom中,该基本输入/输出系统(bios)包含有助于例如在启动期间在计算机系统1700内的元件之间传输信息的基本例程。ram通常包含当前由处理子系统1704操作和执行的数据和/或程序模块。在一些实施方式中,系统存储器1710可以包括多种不同类型的存储器,诸如静态随机存取存储器(sram)、动态随机存取存储器(dram)等。
[0220]
作为示例而非限制,如图17所示,系统存储器1710可以加载正在被执行的可以包括各种应用(诸如web浏览器、中间层应用、关系型数据库管理系统(rdbms)等)的应用程序1712、程序数据1714和操作系统1716。作为示例,操作系统1716可以包括各种版本的microsoftapple和/或linux操作系统、各种商业可用或类unix操作系统(包括但不限于各种gnu/linux操作系统、googleos等)和/或移动操作系统(诸如ios、phone、os、os、os操作系统等)。
[0221]
计算机可读存储介质1722可以存储提供一些示例的功能的编程和数据构造。计算机可读存储介质1722可以为计算机系统1700提供计算机可读指令、数据结构、程序模块和其它数据的存储。当由处理子系统1704执行时,提供上述功能的软件(程序、代码模块、指
令)可以存储在存储子系统1718中。作为示例,计算机可读存储介质1722可以包括非易失性存储器,诸如硬盘驱动器、磁盘驱动器、光盘驱动器(诸如cd rom、dvd、(蓝光)盘或其它光学介质)。计算机可读存储介质1722可以包括但不限于:驱动器、闪存存储器卡、通用串行总线(usb)闪存驱动器、安全数字(sd)卡、dvd盘、数字视频带等。计算机可读存储介质1722也可以包括基于非易失性存储器的固态驱动器(ssd)(诸如基于闪存存储器的ssd、企业闪存驱动器、固态rom等)、基于易失性存储器的ssd(诸如基于固态ram、动态ram、静态ram、dram的ssd、磁阻ram(mram)ssd)、以及使用基于dram和基于闪存存储器的ssd的组合的混合ssd。
[0222]
在某些实施例中,存储子系统1718还可以包括计算机可读存储介质读取器1720,该计算机可读存储介质读取器1720还可以连接到计算机可读存储介质1722。读取器1720可以接收并被配置为从诸如盘、闪存驱动器等存储器设备中读取数据。
[0223]
在某些实施例中,计算机系统1700可以支持虚拟化技术,包括但不限于处理和存储器资源的虚拟化。例如,计算机系统1700可以提供支持用于执行一个或多个虚拟机。在某些实施例中,计算机系统1700可以执行诸如促进虚拟机的配置和管理的管理程序之类的程序。可以为每个虚拟机分配存储器、计算(例如,处理器、核)、i/o和联网资源。每个虚拟机通常独立于其它虚拟机运行。虚拟机通常运行其自己的操作系统,该操作系统可以与由计算机系统1700执行的其它虚拟机执行的操作系统相同或不同。因此,计算机系统1700可以潜在地同时运行多个操作系统。
[0224]
通信子系统1724提供到其它计算机系统和网络的接口。通信子系统1724用作用于从计算机系统1700接收数据以及向其它系统传输数据的接口。例如,通信子系统1724可以使得计算机系统1700能够经由互联网建立到一个或多个客户端设备的通信信道,以用于从客户端设备接收信息以及向客户端设备发送信息。
[0225]
通信子系统1724可以支持有线和/或无线通信协议两者。在某些实施例中,通信子系统1724可以包括用于(例如使用蜂窝电话技术、高级数据网络技术(诸如3g、4g或edge(全球演进的增强数据速率)、wifi(ieee 802.xx族标准)、或其它移动通信技术、或其任何组合)接入无线语音和/或数据网络的射频(rf)收发器组件、全球定位系统(gps)接收器组件和/或其它组件。在一些实施例中,作为无线接口的附加或替代,通信子系统1724可以提供有线网络连接(例如,以太网)。
[0226]
通信子系统1724可以以各种形式接收和传输数据。在一些实施例中,除了其它形式之外,通信子系统1724还可以以结构化和/或非结构化的数据馈送1726、事件流1728、事件更新1730等形式接收输入通信。例如,通信子系统1724可以被配置为实时地从社交媒体网络和/或其它通信服务的用户接收(或发送)数据馈送1726,诸如来自一个或多个第三方信息源的实时更新、馈送、更新、和/或诸如丰富站点摘要(rss)馈送的web馈送。
[0227]
在某些实施例中,通信子系统1724可以被配置为以连续数据流的形式接收本质上可能是连续的或无界的没有明确结束的数据,其中连续数据流可以包括实时事件的事件流1728和/或事件更新1730。生成连续数据的应用的示例可以包括例如传感器数据应用、金融报价机、网络性能测量工具(例如网络监视和流量管理应用)、点击流分析工具、汽车流量监
视等。
[0228]
通信子系统1724也可以被配置为将数据从计算机系统1700传送到其它计算机系统或网络。数据可以以各种不同的形式(诸如结构化和/或非结构化的数据馈送1726、事件流1728、事件更新1730等)传送给一个或多个数据库,该一个或多个数据库可以与耦合到计算机系统1700的一个或多个流传输数据源计算机进行通信。
[0229]
计算机系统1700可以是各种类型中的一种,包括手持便携式设备(例如,蜂窝电话、计算平板、pda)、可穿戴设备(例如,google头戴式显示器)、个人计算机、工作站、大型机、信息站、服务器机架或任何其它数据处理系统。由于计算机和网络不断变化的性质,对图17中描绘的计算机系统1700的描述旨在仅仅作为具体示例。具有比图17中所描绘的系统更多或更少组件的许多其它配置是可能的。基于本文所提供的公开内容和教导,本领域普通技术人员将理解实现各种示例的其它方式和/或方法。
[0230]
虽然已经描述了特定的示例,但是各种修改、变更、替代构造以及等同物都是可能的。示例不限于在某些特定数据处理环境内的操作,而是可以在多个数据处理环境内自由操作。此外,虽然已经使用一系列特定的事务和步骤描述了某些示例,但是对于本领域技术人员来说显而易见的是,这并不旨在进行限制。虽然一些流程图将操作描述为顺序处理,但是许多操作可以并行或同时执行。此外,操作的次序可以被重新布置。处理可能具有图中未包括的附加步骤。上述示例的各种特征和方面可以被单独使用或联合使用。
[0231]
另外,虽然已经使用硬件和软件的特定组合描述了某些示例,但是应该认识到的是,硬件和软件的其它组合也是可能的。某些示例可以仅用硬件或仅用软件或其组合来实现。本文描述的各种处理可以以任何组合在相同的处理器或不同的处理器上实现。
[0232]
在将设备、系统、组件或模块描述为被配置为执行某些操作或功能的情况下,这样的配置可以例如通过以下方式来实现,通过设计电子电路来执行操作、通过对可编程电子电路(诸如微处理器)进行编程来执行操作,诸如通过执行计算机指令或代码,或处理器或核被编程为执行存储在非暂态存储介质上的代码或指令,或其任何组合来执行操作。进程可以使用各种技术进行通信,技术包括但不限于用于进程间通信的常规技术,并且不同对的进程可以使用不同的技术,或者同一对进程可以在不同时间使用不同的技术。
[0233]
在本公开中给出了具体细节以提供对示例的透彻理解。但是,可以在没有这些具体细节的情况下实践示例。例如,在没有不必要的细节以避免使示例模糊的情况下,已经示出了众所周知的电路、处理、算法、结构和技术。本描述仅提供示例例子,并且不旨在限制其它示例的范围、适用性或配置。相反,示例的先前描述将为本领域技术人员提供用于实现各种示例的使能描述。可以对元件的功能和布置进行各种改变。
[0234]
因此,说明书和附图应被认为是说明性的而不是限制性的。但是,将显而易见的是,在不脱离权利要求书所阐述的更广泛的精神和范围的情况下,可以对其进行添加、减少、删除以及其它修改和改变。因此,虽然已经描述了具体的示例,但是这些示例并不旨在进行限制。各种修改和等同形式均在所附权利要求的范围内。
[0235]
在前述说明书中,参考其具体示例描述了本公开的方面,但是本领域技术人员将认识到本公开不限于此。上述公开的各种特征和方面可以单独或联合使用。此外,在不脱离本说明书的更广泛的精神和范围的情况下,可以在超出本文描述的环境和应用的任何数量的环境和应用中利用示例。因此,说明书和附图被认为是说明性的而不是限制性的。
[0236]
在前面的描述中,出于说明的目的,以特定次序描述了方法。应该认识到的是在替代示例中,可以以与所描述的次序不同的次序来执行这些方法。还应该认识到的是,上述方法可以由硬件组件来执行,或者可以在机器可执行指令的序列中实施,这些指令可以用于使机器(诸如通用或专用处理器或用指令编程的逻辑电路)执行方法。这些机器可执行指令可以存储在一种或多种机器可读介质上,其中机器可读介质诸如cd-rom或其它类型的光盘、软盘、rom、ram、eprom、eeprom、磁卡或光卡、闪存、或适用于存储电子指令的其它类型的机器可读介质。替代地,这些方法可以由硬件和软件的组合来执行。
[0237]
在组件被描述为被配置为执行某些操作的情况下,这种配置可以通过例如设计电子电路或其它硬件来执行操作、通过对可编程电子电路(例如,微处理器或其它合适的电子电路)进行编程来执行操作、或其任何组合来完成。
[0238]
虽然本文已经详细描述了本技术的说明性示例,但应该理解的是,本发明构思可以以其它方式被不同地实施和采用,并且所附权利要求旨在被解释为包括这样的变化,除了受现有技术的限制。
[0239]
在组件被描述为“被配置为”执行某些操作的情况下,这种配置可以例如通过设计电子电路或其它硬件来执行操作、通过对可编程电子电路(例如,微处理器,或其它合适的电子电路)进行编程来执行操作、或其任何组合来完成。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。