1.本公开涉及多个说话人在远程会议中使用的声音通信装置。
背景技术:
2.以往已知的是由多个说话人在远程会议中使用的声音通信装置(例如,参考专利文献1)。
3.(现有技术文献)
4.(专利文献)
5.专利文献1:日本特开2006-237841号公报
6.(非专利文献)
7.非专利文献1:耶恩斯
·
布伦艾鲁特,森本政之,后藤敏幸共著,“空间音响”,鹿岛出版会
8.在利用声音通信装置举行的远程会议、网络聚餐等中,希望能够提高参加者获得的临场感。
技术实现要素:
9.于是在本公开中,其目的在于提供一种声音通信装置,在利用该声音通信装置举行的远程会议、网络聚餐等中,能够比以往提高参加者获得的临场感。
10.本公开的一个方式涉及的声音通信装置,具备:n个输入部,用于输入声音信号,n为2以上的整数;声像位置决定部,针对从所述n个输入部输入的n个声音信号的每一个,决定具有第1墙壁和第2墙壁的虚拟空间中的声像定位位置;n个声像定位部,所述n个声像定位部的每一个与所述n个输入部的每一个对应,所述n个声像定位部的每一个,进行声像定位处理并输出声像定位声音信号,所述声像定位处理是使声像定位在声像定位位置的处理,所述声像定位位置是由所述声像位置决定部,针对与该声像定位部对应的输入部决定的位置;以及加法运算部,对从所述n个声像定位部输出的n个所述声像定位声音信号进行相加,输出相加声像定位声音信号,所述声像位置决定部,以如下的方式来决定所述n个声音信号的声像定位位置,使所述n个声音信号的声像定位位置位于所述第1墙壁与所述第2墙壁之间,且从所述第1墙壁与所述第2墙壁之间的收听者位置看时处于相互不重叠的位置,所述n个声像定位部的每一个,利用第1头部传递函数和第2头部传递函数,进行所述声像定位处理,所述第1头部传递函数是指,对从声像定位位置放出的声波,直接到达在所述收听者位置上虚拟存在的收听者的双耳进行了模拟的函数,该声像定位位置是由所述声像位置决定部针对该声像定位部决定的位置,所述第2头部传递函数是指,对从该声像定位位置放出的声波,在所述第1墙壁与所述第2墙壁之中的离该声像定位位置近的一方的墙壁反射而到达所述收听者的双耳进行了模拟的函数。
11.本公开的一个方式涉及的声音通信装置,具备:n个输入部,用于输入声音信号,n为2以上的整数;声像位置决定部,针对从所述n个输入部输入的n个声音信号的每一个,决
定虚拟空间中的声像定位位置;n个声像定位部,所述n个声像定位部的每一个与所述n个输入部的每一个对应,所述n个声像定位部的每一个,进行声像定位处理并输出声像定位声音信号,所述声像定位处理是使声像定位在声像定位位置的处理,所述声像定位位置是由所述声像位置决定部,针对与该声像定位部对应的输入部决定的位置;以及加法运算部,对从所述n个声像定位部输出的n个所述声像定位声音信号进行相加,输出相加声像定位声音信号,所述声像位置决定部,以如下的方式来决定所述n个声音信号的声像定位位置,使所述n个声音信号的声像定位位置位于,从收听者位置看时处于相互不重叠的位置,且将在所述收听者位置上虚拟存在的收听者的正面设为0度的情况下,包含0度或者夹着0度而相互邻接的声像定位位置的间隔,比不包含0度或者不夹着0度而相互邻接的声像定位位置的间隔窄,所述n个声像定位部的每一个,利用头部传递函数,进行所述声像定位处理,所述头部传递函数是对从声像定位位置放出的声波,直接到达在所述收听者位置上虚拟存在的收听者的双耳进行了模拟的函数,所述声像定位位置是由所述声像位置决定部针对该声像定位部决定的位置。
12.本公开的一个方式涉及的声音通信装置,具备:n个输入部,用于输入声音信号,n为2以上的整数;声像位置决定部,针对从所述n个输入部输入的n个声音信号的每一个,决定虚拟空间中的声像定位位置;n个声像定位部,所述n个声像定位部的每一个与所述n个输入部的每一个对应,所述n个声像定位部的每一个,进行声像定位处理并输出声像定位声音信号,所述声像定位处理是使声像定位在声像定位位置的处理,所述声像定位位置是由所述声像位置决定部,针对与该声像定位部对应的输入部决定的位置;第1加法运算部,对从所述n个声像定位部输出的n个所述声像定位声音信号进行相加,输出第1相加声像定位声音信号;背景噪声信号存储部,存储示出所述虚拟空间中的背景噪声的背景噪声信号;以及第2加法运算部,对从所述第1相加声像定位声音信号与所述背景噪声信号进行相加,输出第2相加声像定位声音信号,所述声像位置决定部,将所述n个声音信号的声像定位位置决定为,在从收听者位置看时处于相互不重叠的位置,所述n个声像定位部的每一个,利用头部传递函数,进行所述声像定位处理,所述头部传递函数是对从声像定位位置放出的声波,直接到达在所述收听者位置上虚拟存在的收听者的双耳进行了模拟的函数,所述声像定位位置是由所述声像位置决定部针对该声像定位部决定的位置。
13.通过本公开涉及的声音通信装置,在利用声音通信装置举行的远程会议、网络聚餐等中,能够提高参加者获得的临场感。
附图说明
14.图1是示出实施方式1涉及的远程会议系统的构成的一例的模式图。
15.图2是示出实施方式1涉及的服务器装置的构成的一例的模式图。
16.图3是示出实施方式1涉及的声音通信装置的构成的一例的方框图。
17.图4是示出实施方式1涉及的声像位置决定部决定了声像定位位置的样子的一例的模式图。
18.图5是示出实施方式1涉及的声像定位部进行声像定位处理的样子的一例的模式图。
19.图6是示出实施方式2涉及的声音通信装置的构成的一例的方框图。
20.符号说明
21.1 远程会议系统
22.10,10a 声音通信装置
23.11 输入部
24.11a 第1输入部
25.11b 第2输入部
26.11c 第3输入部
27.11d 第4输入部
28.11e 第5输入部
29.12 声像位置决定部
30.13 声像定位部
31.13a 第1声像定位部
32.13b 第2声像定位部
33.13c 第3声像定位部
34.13d 第4声像定位部
35.13e 第5声像定位部
36.14 加法运算部
37.15,15a 输出部
38.16 第2加法运算部
39.17 背景噪声信号存储部
40.18 选择部
41.20,20a,20b,20c,20d,20e,20f 终端
42.21,21a,21b,21c,21d,21e,21f 麦克风
43.22,22a,22b,22c,22d,22e,22f 扬声器
44.23a,23b,23c,23d,23e,23f 用户
45.30 网络
46.41 第1墙壁
47.42 第2墙壁
48.50 收听者位置
49.51 第1声像位置
50.52 第2声像位置
51.53 第3声像位置
52.54 第4声像位置
53.55 第5声像位置
54.60 收听者
55.71,72,73,74,75 说话人
56.71a,74a 说话人的镜像
57.90 虚拟空间
58.100 服务器装置
59.101 输入装置
60.102 输出装置
61.103 cpu
62.104 内置存储器
63.105 ram
64.106 总线
具体实施方式
65.(获得本公开的一个方案的经过)
66.以往随着因特网的高速化、大容量化、服务器装置的高性能化等,实现了能够从多个地点同时参加的远程会议系统的声音通信装置被实用化。在这样的远程会议系统中,近几年由于新型冠状病毒感染症的影响,不仅用在商务用途上,而且还广泛用于网络聚餐等消费者用途。
67.随着利用声音通信装置的远程会议、网络聚餐等广泛举行,在这些远程会议、网络聚餐等希望提高参加者获得的临场感的要求越来越大。
68.于是,发明者们为了提高利用声音通信装置举行的远程会议、网络聚餐等中参加者获得的临场感,认真地进行实验和讨论。其结果,发明者们想出了下列声音通信装置。
69.本公开的一个方式涉及的声音通信装置,具备:n个输入部,用于输入声音信号,n为2以上的整数;声像位置决定部,针对从所述n个输入部输入的n个声音信号的每一个,决定具有第1墙壁和第2墙壁的虚拟空间中的声像定位位置;n个声像定位部,所述n个声像定位部的每一个与所述n个输入部的每一个对应,所述n个声像定位部的每一个,进行声像定位处理并输出声像定位声音信号,所述声像定位处理是使声像定位在声像定位位置的处理,所述声像定位位置是由所述声像位置决定部,针对与该声像定位部对应的输入部决定的位置;以及加法运算部,对从所述n个声像定位部输出的n个所述声像定位声音信号进行相加,输出相加声像定位声音信号,所述声像位置决定部,以如下的方式来决定所述n个声音信号的声像定位位置,使所述n个声音信号的声像定位位置位于所述第1墙壁与所述第2墙壁之间,且从所述第1墙壁与所述第2墙壁之间的收听者位置看时处于相互不重叠的位置,所述n个声像定位部的每一个,利用第1头部传递函数和第2头部传递函数,进行所述声像定位处理,所述第1头部传递函数是指,对从声像定位位置放出的声波,直接到达在所述收听者位置上虚拟存在的收听者的双耳进行了模拟的函数,该声像定位位置是由所述声像位置决定部针对该声像定位部决定的位置,所述第2头部传递函数是指,对从该声像定位位置放出的声波,在所述第1墙壁与所述第2墙壁之中的离该声像定位位置近的一方的墙壁反射而到达所述收听者的双耳进行了模拟的函数。
70.通过所述声音通信装置,能够提供这样的氛围,从n个输入部的各自输入的n名说话人的声音,好像是从具有第1墙壁和第2墙壁的虚拟空间中发出的声音一样。通过所述声音通信装置,听到n名说话人的声音的收听者,能够比较容易掌握在虚拟空间中的说话人与墙壁之间的位置关系。因此,该收听者能够比较容易区分n名说话人的声音的传来方向。从而,通过所述声音通信装置,能够比以往提高利用声音通信装置举行的远程会议、网络聚餐等中参加者获得的临场感。
71.此外可以是,所述n个声像定位部的每一个,以能够自由变更所述第1墙壁的声波的反射率与所述第2墙壁的声波的反射率的至少一方的方式,进行所述声像定位处理。
72.从而,能够自由变更虚拟空间中的说话人的声音的回声程度。
73.此外可以是,所述n个声像定位部的每一个,以能够自由变更所述第1墙壁的位置与所述第2墙壁的位置的至少一方的方式,进行所述声像定位处理。
74.从而,能够自由变更虚拟空间中的墙壁的位置。
75.本公开的一个方式涉及的声音通信装置,具备:n个输入部,用于输入声音信号,n为2以上的整数;声像位置决定部,针对从所述n个输入部输入的n个声音信号的每一个,决定虚拟空间中的声像定位位置;n个声像定位部,所述n个声像定位部的每一个与所述n个输入部的每一个对应,所述n个声像定位部的每一个,进行声像定位处理并输出声像定位声音信号,所述声像定位处理是使声像定位在声像定位位置的处理,所述声像定位位置是由所述声像位置决定部,针对与该声像定位部对应的输入部决定的位置;以及加法运算部,对从所述n个声像定位部输出的n个所述声像定位声音信号进行相加,输出相加声像定位声音信号,所述声像位置决定部,以如下的方式来决定所述n个声音信号的声像定位位置,使所述n个声音信号的声像定位位置位于,从收听者位置看时处于相互不重叠的位置,且将在所述收听者位置上虚拟存在的收听者的正面设为0度的情况下,包含0度或者夹着0度而相互邻接的声像定位位置的间隔,比不包含0度或者不夹着0度而相互邻接的声像定位位置的间隔窄,所述n个声像定位部的每一个,利用头部传递函数,进行所述声像定位处理,所述头部传递函数是对从声像定位位置放出的声波,直接到达在所述收听者位置上虚拟存在的收听者的双耳进行了模拟的函数,所述声像定位位置是由所述声像位置决定部针对该声像定位部决定的位置。
76.关于通常的声像定位的听觉锐度,已知的是越是在收听者的正面越敏感,越是在左右侧越迟钝(例如参考非专利文献1)。通过所述声音通信装置,从收听者看时,比起位于正面方向的说话人之间的角度,位于左右方向的说话人之间的角度大。因此,该收听者,能够比较容易区分n名说话人的声音的传来方向。从而,通过所述声音通信装置,能够比以往提高利用声音通信装置举行的远程会议、网络聚餐等中参加者获得的临场感。
77.本公开的一个方式涉及的声音通信装置,具备:n个输入部,用于输入声音信号,n为2以上的整数;声像位置决定部,针对从所述n个输入部输入的n个声音信号的每一个,决定虚拟空间中的声像定位位置;n个声像定位部,所述n个声像定位部的每一个与所述n个输入部的每一个对应,所述n个声像定位部的每一个,进行声像定位处理并输出声像定位声音信号,所述声像定位处理是使声像定位在声像定位位置的处理,所述声像定位位置是由所述声像位置决定部,针对与该声像定位部对应的输入部决定的位置;第1加法运算部,对从所述n个声像定位部输出的n个所述声像定位声音信号进行相加,输出第1相加声像定位声音信号;背景噪声信号存储部,存储示出所述虚拟空间中的背景噪声的背景噪声信号;以及第2加法运算部,对从所述第1相加声像定位声音信号与所述背景噪声信号进行相加,输出第2相加声像定位声音信号,所述声像位置决定部,将所述n个声音信号的声像定位位置决定为,在从收听者位置看时处于相互不重叠的位置,所述n个声像定位部的每一个,利用头部传递函数,进行所述声像定位处理,所述头部传递函数是对从声像定位位置放出的声波,直接到达在所述收听者位置上虚拟存在的收听者的双耳进行了模拟的函数,所述声像定位
位置是由所述声像位置决定部针对该声像定位部决定的位置。
78.通过所述声音通信装置可以提供这样的氛围,将从n个输入部的各自输入的n名说话人的声音,好像是在充满背景噪声的虚拟空间内发出声音一样。从而,通过所述声音通信装置,能够比以往提高利用声音通信装置举行的远程会议、网络聚餐等中参加者获得的临场感。
79.此外可以是,所述背景噪声信号存储部存储的所述背景噪声信号为1个以上,所述声音通信装置还具备选择部,从所述背景噪声信号存储部存储的1个以上所述背景噪声信号中,选择1个以上的所述背景噪声信号,所述第2加法运算部,对所述第1相加声像定位声音信号与由所述选择部选择的所述背景噪声信号进行相加,输出所述第2相加声像定位声音信号。
80.从而,能够按照想呈现的虚拟空间的氛围,选择背景噪声。
81.此外可以是,所述选择部,随着时间的经过,变更选择的所述背景噪声信号。
82.从而,能够随着时间的经过,变更所呈现的虚拟空间的氛围。
83.以下针对本公开的一个方式涉及的声音通信装置的具体例子,参考附图进行说明。这里示出的实施方式,都是示出本公开的一个具体例子。以下的实施方式中示出的数值、形状、构成要素、构成要素的配置以及连接形式、以及步骤(工序)及步骤的顺序等是一个例子,主旨并非限定本公开。此外,各图是示意图,并非是严谨的图示。
84.另外,本公开的这些概括或者具体的方案,可以通过系统、方法、集成电路、计算机程序或者计算机可读取的cd-rom等记录介质来实现,也可以任意组合系统、方法、集成电路、计算机程序以及记录介质来实现。
85.(实施方式1)
86.以下针对在相互不同的地方的多个参加者进行会议的远程会议系统,参考附图进行说明。
87.图1是示出实施方式1涉及的远程会议系统1的构成的一例的模式图。
88.如图1所示,远程会议系统1具备:声音通信装置10、网络30、n 1(n为2以上的整数)个终端20(与图1中的终端20a~终端20f对应)、n 1个麦克风21(与图1中的麦克风21a~麦克风21f对应)、n 1个扬声器22(与图1中的扬声器22a~扬声器22f对应)。
89.麦克风21a~麦克风21f,分别与终端20a~终端20f连接,将利用终端20a~终端20f的用户23a~用户23f的声音转换为声音信号,输出给终端20a~终端20f,该声音信号是电信号。
90.麦克风21a~麦克风21f具有的功能可以是相同的。因此,在本说明书中,在不需要相互区分麦克风21a~麦克风21f来记载的情况下,称为麦克风21。
91.扬声器22a~扬声器22f,分别与终端20a~终端20f连接,从终端20a~终端20f输出的作为电信号的声音信号,转换为声音并输出给外部。
92.扬声器22a~扬声器22f具有的功能也可以是相同的。因此,在本说明书中,在不需要相互区分扬声器22a~扬声器22f来记载的情况下,称为扬声器22。扬声器22,只要具有将电信号转换为声音的功能就可以,不需要限定为所谓的扬声器,例如也可以是耳机、头戴式耳机等。
93.终端20a~终端20f,分别与麦克风21a~麦克风21f、扬声器22a~扬声器22f、以及
网络30连接,具有如下功能,将从被连接的麦克风21a~麦克风21f输出的声音信号,发送给与网络30连接的外部装置的功能,以及从与网络30连接的外部装置接收声音信号,将接收的声音信号输出给扬声器22a~扬声器22f的功能。与网络30连接的外部装置,包括声音通信装置10。
94.终端20a~终端20f具有的功能可以是相同的。因此,在本说明书中,在不需要相互区分终端20a~终端20f来记载的情况下,称为终端20。终端20,例如由计算机、智能手机等来实现。
95.终端20,例如可以具有麦克风21的功能。在这个情况下,在图1中图示出好像终端20与麦克风21连接,但是实际上麦克风21包括在终端20中。此外,终端20,可以具有扬声器22的功能。在这个情况下,在图1中示出好像终端20与扬声器22连接,但是实际上扬声器22包括在终端20中。此外终端20,例如还可以具备显示器、触摸板、键盘等输入输出装置。
96.相反,也可以是麦克风21具有终端20的功能。在这个情况下,在图1中示出好像终端20与麦克风21连接,但是实际上终端20包括在麦克风21中。此外也可以是扬声器22具有终端20的功能。在这个情况下,在图1中示出好像终端20与扬声器22连接,但是实际上终端20包括在扬声器22中。
97.网络30,与包括终端20a~终端20f和声音通信装置10的多个装置连接,在连接的多个装置之间传递信号。如后述,声音通信装置10由服务器装置100来实现。因此,网络30与实现声音通信装置10的服务器装置100连接。
98.声音通信装置10,与网络30连接,并且由服务器装置100来实现。
99.图2是示出实现声音通信装置10的服务器装置100的构成的一例的模式图。
100.如图2所示服务器装置100具备:输入装置101、输出装置102、cpu(central processing unit:中央处理器)103、内置存储104、ram(random access memory:随机存取存储器)105、以及总线106。
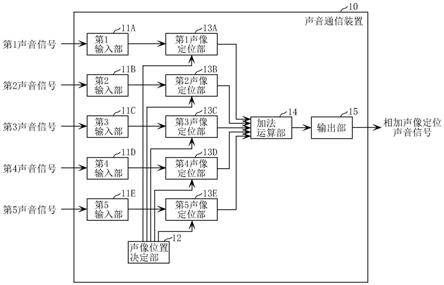
101.输入装置101是例如键盘、鼠标、触摸板等成为用户界面的装置,接受利用服务器装置100的用户的操作。输入装置101,除了接受用户的接触操作之外,也可以是接受通过声音的操作、遥控器等远程操作的构成。
102.输出装置102是显示器、扬声器、输出端子等成为用户界面的装置,将服务器装置100的信号输出给外部。
103.内置存储器104是称为闪存等的存储装置,用于存储服务器装置100执行的程序、服务器装置100利用的数据等。
104.ram105是称为sram(static ram:静态随机存取存储器),dram(dynamic ram:动态随机存取存储器)等的存储装置,用于执行程序时的暂时的存储区域等。
105.cpu103,将内置存储器104存储的程序复制到ram105,将复制的程序中包含的命令,从ram105依次读出并执行。
106.总线106与输入装置101、输出装置102、cpu103、内置存储器104、ram105连接,并且在连接的构成要素之间传递信号。
107.虽然在图2没有图示,服务器装置100具备通信功能。服务器装置100,通过该通信功能,与网络30连接。
108.声音通信装置10,例如通过由cpu103将内置存储器104存储的程序复制到ram105,
将复制的程序中包含的命令,从ram105依次读出并执行来实现。
109.图3是示出声音通信装置10的构成的一例的方框图。
110.如图3所示,声音通信装置10具备:n个输入部11(与图3中的第1输入部11a~第5输入部11e对应)、声像位置决定部12、n个声像定位部13(与图3中的第1声像定位部13a~第5声像定位部13e对应)、加法运算部14、以及输出部15。
111.第1输入部11a~第5输入部11e,分别与第1声像定位部13a~第5声像定位部13e连接,用于输入从终端20中的任一个输出的声音信号。这里说明为,从终端20a输出的第1声音信号输入到第1输入部11a,从终端20b输出的第2声音信号输入到第2输入部11b,从终端20c输出的第3声音信号输入到第3输入部11c,从终端20d输出的第4声音信号输入到第4输入部11d,从终端20e输出的第5声音信号输入到第5输入部11e。还有这里说明为,在第1声音信号中包括对第1终端20a的用户(这里是用户23a)发出的声音进行了变换的电信号,在第2声音信号中包括对第2终端20b的用户(这里是用户23b)发出的声音进行了变换的电信号,在第3声音信号中包括对第3终端20c的用户(这里是用户23c)发出的声音进行了变换的电信号,在第4声音信号中包括对第4终端20d的用户(这里是用户23d)发出的声音进行了变换的电信号,在第5声音信号中包括对第5终端20e的用户(这里是用户23e)发出的声音进行了变换的电信号。
112.第1输入部11a~第5输入部11e具有的功能相同。因此,在本说明书中,在不需要区分第1输入部11a~第5输入部11e的情况下,称为输入部11。
113.输出部15,与加法运算部14连接,将从加法运算部14输出的后述的相加声像定位声音信号,输出到终端20中的任一个。这里说明为,输出部15,将相加声像定位声音信号,输出到终端20f。
114.声像位置决定部12,与第1声像定位部13a~第5声像定位部13e连接,针对从n个输入部11输入的n个声音信号(与图3中的第1声音信号到第5声音信号对应)的每一个,决定具有第1墙壁41(参考后述的图4)和第2墙壁42(参考后述的图4)的虚拟空间中的声像定位位置。
115.图4是示出声像位置决定部12,针对n个声音信号的每一个,决定在虚拟空间中的声像定位位置的样子的模式图。
116.如图4所示虚拟空间90包括:第1墙壁41、第2墙壁42、第1声像位置51、第2声像位置52、第3声像位置53、第4声像位置54、第5声像位置55、以及收听者位置50。
117.第1墙壁41和第2墙壁42,分别是在虚拟空间内存在的、对声波进行反射的虚拟的墙壁。
118.收听者位置50是收听者的虚拟的位置,该收听者收听由第1声音信号~第5声音信号示出的声音。
119.第1声像位置51是,由声像位置决定部12针对第1声音信号决定的声像位置。第2声像位置52是,由声像位置决定部12针对第2声音信号决定的声像位置。第3声像位置53是,由声像位置决定部12针对第3声音信号决定的声像位置。第4声像位置54是,由声像位置决定部12针对第4声音信号决定的声像位置。第5声像位置55是,由声像位置决定部12针对第5声音信号决定的声像位置。
120.如图4所示,声像位置决定部12,将n个声像信号的声像定位位置(这里是第1声像
位置51~第5声像位置55)决定为,位于第1墙壁41与第2墙壁42之间,且从收听者位置50看时处于相互不重叠的位置。更详细而言,声像位置决定部12,以如下的方式来决定n个声像信号的声像定位位置,将在收听者位置50上虚拟存在的收听者的正面设为0度的情况下,包含0度或者夹着0度而相互邻接的声像定位位置的间隔,比不包含0度或者不夹着0度而相互邻接的声像定位位置的间隔窄。
121.因此,如图4所示,将从收听者位置50看时的第1声像位置51与第2声像位置52之间的角度设为角度x,将从收听者位置50看时的第2声像位置52与第3声像位置53之间的角度设为角度y的情况下,成为x》y。
122.再回到图3,继续说明声音通信装置10。
123.第1声像定位部13a,与第1输入部11a和声像位置决定部12和加法运算部14连接,进行声像定位处理,输出声像定位声音信号,该声像定位处理是使声像定位在由声像位置决定部12决定的第1声像位置51的处理。第2声像定位部13b,与第2输入部11b和声像位置决定部12和加法运算部14连接,进行声像定位处理,输出声像定位声音信号,该声像定位处理是使声像定位在由声像位置决定部12决定的第2声像位置52的处理。第3声像定位部13c,与第3输入部11c和声像位置决定部12和加法运算部14连接,进行声像定位处理,输出声像定位声音信号,该声像定位处理是使声像定位在由声像位置决定部12决定的第3声像位置53的处理。第4声像定位部13d,与第4输入部11d和声像位置决定部12和加法运算部14连接,进行声像定位处理,输出声像定位声音信号,该声像定位处理是使声像定位在由声像位置决定部12决定的第4声像位置54的处理。第5声像定位部13e,与第5输入部11e和声像位置决定部12和加法运算部14连接,进行声像定位处理,输出声像定位声音信号,该声像定位处理是使声像定位在由声像位置决定部12决定的第5声像位置55的处理。
124.第1声像定位部13a~第5声像定位部13e具有的功能是相同的。因此,在本说明书中,在不需要区分第1声像定位部13a~第5声像定位部13e的情况下,称为声像定位部13。
125.声像定位部13,更详细而言,利用第1头部传递函数(head-related transfer function,hrtf)和第2头部传递函数,进行声像定位处理,所述第1头部传递函数是指,对从由声像位置决定部12决定的声像位置放出的声波,直接到达在收听者位置50虚拟存在的收听者的双耳进行了模拟的函数,所述第2头部传递函数是指,对从由声像位置决定部12决定的声像位置放出的声波,在第1墙壁与第2墙壁中的离该声像位置近的一方的墙壁反射而到达在收听者位置50上虚拟存在的收听者的双耳进行了模拟的函数。
126.图5是示出声像定位部13进行声像定位处理的样子的模式图。
127.在图5中,说话人71是在第1声像位置51上虚拟地存在的说话人,说话人72是在第2声像位置52上虚拟地存在的说话人,说话人73是在第3声像位置53上虚拟地存在的说话人,说话人74是在第4声像位置54上虚拟地存在的说话人,说话人75是在第5声像位置55上虚拟地存在的说话人。收听者60是,在收听者位置50上虚拟地存在的收听者。
128.说话人71例如是用户23a的图标,说话人72例如是用户23b的图标,说话人73例如是用户23c的图标,说话人74例如是用户23d的图标,说话人75例如是用户23e的图标,收听者60例如是用户23f的图标。
129.此外,说话人71a是在以第1墙壁41为镜面时的镜面位置上虚拟地存在的说话人71的镜像,说话人74a是在以第2墙壁42为镜面时的镜面位置上虚拟地存在的说话人74的镜
像。
130.如图5所示,在虚拟空间90,例如第1说话人71发出的声音,通过以2个实线示出的传递路径,直接到达收听者60的双耳。此外,第1说话人71发出的声音,通过以2个虚线示出的传递路径,在第1墙壁41反射而到达收听者的双耳。
131.因此,在虚拟空间90中,针对第1说话人71发出的声音,利用与2个实线示出的传递路径的各自对应的第1头部传递函数进行卷积而生成2个信号,以及利用与2个虚线示出的传递路径的各自对应的第2头部传递函数进行卷积而生成2个信号,进而对于将这些信号进行相加的信号,收听者60例如使用头戴式耳机收听时,收听者60听到好像是第1说话人71在第1声像位置发出的声音。这时收听者60,因为还听到在第1墙壁41反射的声音,收听者60能够感觉到虚拟空间90是具有墙壁的虚拟空间。
132.如图5所示,在虚拟空间90中,例如,第4说话人74发出的声音,通过以2个实线示出的传递路径,直接到达收听者60的双耳。此外,第4说话人74发出的声音,通过以2个虚线示出的传递路径,在第2墙壁42反射而到达收听者的双耳。
133.因此,在虚拟空间90中,针对第4说话人74发出的声音,利用与2个实线示出的传递路径的各自对应的第1头部传递函数进行卷积而生成2个信号,以及利用与2个虚线示出的传递路径的各自对应的第2头部传递函数进行卷积而生成2个信号,进而对于将这些信号进行相加的信号,收听者60例如使用头戴式耳机收听时,收听者60听到好像是第4说话人74在第4声像位置发出的声音。这时收听者60,因为还听到在第2墙壁42反射的声音,收听者60能够感觉到虚拟空间90是具有墙壁的虚拟空间。
134.这时,声像定位部13,可以以能够自由变更第1墙壁41的声波的反射率与第2墙壁42的声波的反射率的至少一方的方式,进行声像定位处理。通过变更反射率,能够变更在虚拟空间90中的声音的回声程度。
135.此外,这时声像定位部13,可以以能够自由变更第1墙壁41的位置与第2墙壁42的位置的至少一方的方式,进行声像定位处理。通过变更墙壁的位置,能够变更在虚拟空间90中的空间的扩展程度。
136.另外,声像位置决定部12当然可以进一步利用第3头部传递函数,进行声音处理,该第3头部传递函数是对从由声像位置决定部12决定的声像位置放出的声波,在第1墙壁41和第2墙壁42中的离该声像位置远的一方的墙壁反射而到达收听者60的双耳进行了模拟的函数。
137.再回到图3,继续说明声音通信装置10。
138.加法运算部14,与n个声像定位部13和输出部15连接,对从n个声像定位部13输出的n个声像定位声音信号进行相加,输出相加声像定位声音信号。
139.通过所述声音通信装置10,能够提供这样的氛围,从n个(这里是5个)输入部11的各自输入的n名(这里是5个人)说话人的声音,好像是从具有第1墙壁41和第2墙壁42的虚拟空间90中发出的声音一样。此外,通过所述声音通信装置10,听到n名说话人的声音的收听者60,能够比较容易掌握在虚拟空间90中的说话人与墙壁的位置关系。因此,收听者60,能够比较容易区分n名说话人的声音的传来方向。从而,通过所述声音通信装置10,能够比以往提高利用声音通信装置举行的远程会议、网络聚餐等中参加者获得的临场感。
140.如上所述,关于通常的声像定位的听觉锐度,已知的是越是在收听者的正面越敏
感,越是在左右侧越迟钝。通过所述声音通信装置10,从收听者60看时,比起位于正面方向的说话人之间的角度,位于左右方向的说话人之间的角度大。因此,收听者60,能够比较容易区分n名说话人的声音的传来方向。从而,通过所述声音通信装置10,能够比以往提高利用声音通信装置举行的远程会议、网络聚餐等中参加者获得的临场感。
141.(实施方式2)
142.下面说明从实施方式1涉及的声音通信装置10,将其构成变更一部分而构成的实施方式2涉及的声音通信装置。
143.以下关于实施方式2涉及的声音通信装置,将与声音通信装置10的构成要素相同的构成要素作为已经说明的部分,赋予相同的符号,省略详细说明,并且以与声音通信装置10不同点为中心进行说明。
144.图6是示出实施方式2涉及的声音通信装置10a的构成的一例的方框图。
145.如图6所示,实施方式2涉及的声音通信装置10a被构成为如下,针对声音通信装置10,追加了第2加法运算部16、背景噪声信号存储部17、选择部18,此外输出部15被变更为输出部15a。
146.背景噪声信号存储部17,与选择部18连接,存储示出在虚拟空间90中的背景噪声的1个以上的背景噪声信号。
147.背景噪声信号示出的背景噪声,例如是在真实的会议室中预先录音的背景噪声。此外,背景噪声信号示出的背景噪声,例如在真实的酒吧、居酒屋、音乐演奏厅等预先录音的喧嚣声。此外,背景噪声信号示出的背景噪声,例如可以是真实的爵士乐茶馆中播放的爵士乐。此外,背景噪声信号示出的背景噪声,例如可以是人工合成的信号,例如可以是将在真实的空间预先录音的多个喧嚣声进行合成来生成的人工信号。
148.选择部18,与背景噪声信号存储部17和第2加法运算部16连接,在背景噪声信号存储部17存储的1个以上的背景噪声信号中选择1个以上的背景噪声信号。
149.选择部18,例如可以随着时间的经过,变更选择的背景噪声信号。
150.第2加法运算部16,与加法运算部14和选择部18和输出部15a连接,对从加法运算部14输出的相加声像定位声音信号,和由选择部18选择的背景噪声信号进行相加,输出第2相加声像定位声音信号。
151.输出部15a,与第2加法运算部16连接,将从第2加法运算部16输出的第2相加声像定位声音信号,输出到终端20中的任一个。这里说明输出部15a,将第2相加声像定位声音信号,输入到终端20f。
152.通过所述声音通信装置10a能够提供这样的氛围,将从n个(这里是5个)输入部11的各自输入的n名(这里是5个人)说话人的声音,好像是在充满背景噪声的虚拟空间90内发出声音一样。从而,例如在选择部18,选择示出在真实的会议室中预先录音的背景噪声的背景噪声信号的情况下,能够呈现好像虚拟空间90是真实的会议室一样的氛围。此外,例如在选择部18,选择示出在真实的酒吧、居酒屋、音乐演奏厅等预先录音的喧嚣声的背景噪声信号的情况下,能够呈现好像虚拟空间90是真实的酒吧、居酒屋、音乐演奏厅等一样的氛围。此外,例如在选择部18,选择示出在真实的爵士乐茶馆播放的爵士乐的背景噪声信号的情况下,能够呈现好像虚拟空间90是真实的爵士乐茶馆一样的氛围。从而,通过所述声音通信装置10a,能够比以往提高利用声音通信装置举行的远程会议、网络聚餐等中参加者获得的
临场感。
153.此外,通过所述声音通信装置10a,能够按照想要呈现的虚拟空间90的氛围,选择背景噪声。
154.此外,通过所述声音通信装置10a,能够随着时间的经过,变更所呈现的虚拟空间90的氛围。
155.(其他实施方式)
156.以上关于本公开的声音通信装置,根据实施方式1、实施方式2进行了说明,但是本公开并非被这些实施方式所限定。例如,也可以将任意组合本说明书中记载的构成要素,以及排除构成要素中的几个要素来实现的另外的实施方式,作为本公开的实施方式。此外,针对所述实施方式,在不脱离本公开的主旨,即记载技术方案的文字所示出的含义的范围内,实施本领域技术人员想出的各种变形而获得的变形例,也包括在本公开中。
157.(1)在实施方式1以及实施方式2中,声音通信装置10以及声音通信装置10a,是n为5的情况的构成例。然而,本公开涉及的声音通信装置,只要是n为2以上的整数,没有必要限定为n为5的情况的构成例。
158.(2)在实施方式1中,声音通信装置10被说明为,第1声音信号~第5声音信号,分别输入到终端20a~终端20e,相加声像定位声音信号输出到终端20f。对于此,声音通信装置10,可以变形为如下的第1变形声音通信装置~第5变形声音通信装置。第1变形声音通信装置的构成为,第1声音信号~第5声音信号,分别从终端20b~终端20f输入,相加声像定位声音信号,输出到终端20a。第2变形声音通信装置的构成为,第1声音信号~第5声音信号,分别从终端20c~终端20f、终端20a输入,相加声像定位声音信号,输出到终端20b。第3变形声音通信装置的构成为,第1声音信号~第5声音信号,分别从终端20d~终端20f、终端20a~终端20b输入,相加声像定位声音信号,输出到终端20c。第4变形声音通信装置的构成为,第1声音信号~第5声音信号,分别从终端20e~终端20f、终端20a~终端20c输入,相加声像定位声音信号,输出到终端20d。第5变形声音通信装置的构成为,第1声音信号~第5声音信号,分别从终端20f、终端20a~终端20d输入,相加声像定位声音信号,输出到终端20e。
159.此外,声音通信装置10、第1变形声音通信装置~第5变形声音通信装置,可以由服务器装置100同时实现。例如,服务器装置100,通过分时处理,可以将声音通信装置10、第1变形声音通信装置~第5变形声音通信装置同时实现,可以通过并行处理,同时实现声音通信装置10、第1变形声音通信装置~第5变形声音通信装置。
160.进一步可以由服务器装置100来实现这样的1个声音通信装置,该1个声音通信装置能够实现通过同时实现声音通信装置10、第1变形声音通信装置~第5变形声音通信装置而获得的功能。
161.(3)在实施方式2中,声音通信装置10a被说明为,第1声音信号~第5声音信号分别从终端20b~终端20e输入,第2相加声像定位声音信号输出到终端20f。对于此,可以将声音通信装置10a,变形为如下第6变形声音通信装置~第10变形声音通信装置。第6变形声音通信装置的构成为,第1声音信号~第5声音信号,分别从终端20b~终端20f输入,第2相加声像定位声音信号,输出到终端20a。第7变形声音通信装置的构成为,第1声音信号~第5声音信号,分别从终端20c~终端20f、终端20a输入,第2相加声像定位声音信号,输出到终端20b。第8变形声音通信装置的构成为,第1声音信号~第5声音信号,分别从终端20d~终端
20f、终端20a~终端20b输入,第2相加声像定位声音信号,输出到终端20c。第9变形声音通信装置的构成为,第1声音信号~第5声音信号,分别从终端20e~终端20f、终端20a~终端20c输入,第2相加声像定位声音信号,输出到终端20d。第10变形声音通信装置的构成为,第1声音信号~第5声音信号,分别从终端20f、终端20a~终端20d输入,第2相加声像定位声音信号,输出到终端20e。
162.此外,声音通信装置10a、第6变形声音通信装置~第5变形声音通信装置,可以由服务器装置100同时实现。例如,服务器装置100,可以通过分时处理,同时实现声音通信装置10a、第6变形声音通信装置~第10变形声音通信装置,也可以通过并行处理,同时实现声音通信装置10a、第6变形声音通信装置~第10变形声音通信装置。此时,可以将声音通信装置10a、第6变形声音通信装置~第10变形声音通信装置包括的选择部18,设为选择相同的背景噪声信号。从而,能够比以往更加提高在利用声音通信装置举行的远程会议、网络聚餐等中参加者获得的临场感。
163.进而可以由服务器装置100来实现这样的1个声音通信装置,该声音通信装置能够实现通过同时实现声音通信装置10a、第6变形声音通信装置~第10变形声音通信装置而获得的功能。
164.(4)构成声音通信装置10以及声音通信装置10a的构成要素的一部分或者全部,可以由1个系统lsi(large scale integration:大规模集成电路)来构成。系统lsi,是将多个构成部集成在1个芯片上来制造的超多功能lsi,具体而言是包括微处理机,rom(read only memory),ram(random access memory)等构成的计算机系统。所述rom记录有计算机程序。微处理机,按照计算机程序动作,从而系统lsi达成其功能。
165.此外,在这里称为系统lsi,但是根据集成度的不同,还称为ic、lsi、超大lsi、特大lsi。此外,集成电路化的方法不限于lsi,可以用专用电路或者通用处理器来实现。也可以使用在lsi制造后可编程的fpga(field programmable gate array:现场可编程门阵列)、或者可重构lsi内部的电路单元的连接以及设定的可重构处理器。
166.进而,随着半导体技术的进步或者派生出的别的技术,出现能够替代lsi的集成电路化技术时,当然可以使用该技术进行功能块的集成化。有可能适用生物技术等。
167.(5)声音通信装置10以及声音通信装置10a的各个构成要素可以由专用的硬件来构成,可以由cpu或者处理器等的程序执行部,读出并执行在硬盘或者半导体存储器等记录介质中记录的软件程序来实现。
168.本公开能够广泛利用于远程会议系统等。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
