1.本发明涉及风储联合系统优化领域,具体涉及一种基于储能技术 特性的风储联合系统日前优化调度方法。
背景技术:
2.储能设备运行具有很大的灵活性,可实现在长时间尺度上的出力 平移,因此,目前有很多研究将储能与风电组合成联合系统,以实现 对风电出力波动的平抑,大大提高了风电的利用率。例如,利用抽水 蓄能电站建立优化模型,能够缓解风电场功率的波动;采用风电功率 分解的思想,将功率分解为2个不同频率成分并使用混合储能进行出 力补偿,能够平抑风电波动;在考虑风电不确定性引起失负荷概率的 基础上,以风储联合系统收益最大化建立调度模型,可以有效降低失 负荷风险;以储能收益最大化为目标建立优化模型,采用混合整数规 划进行求解,可以最大化风储联合系统收益,但风电的不确定性会对 收益产生影响。
3.
技术实现要素:
4.有鉴于此,本发明的目的在于提供一种基于储能技术特性的风储 联合系统日前优化调度方法,保证储能设备可调控容量的基础上,有 效平抑风电出力的波动性,提升电力系统可靠性,实现风储联合系统 的效能最大化。
5.为实现上述目的,本发明采用如下技术方案:
6.一种基于储能技术特性的风储联合系统日前优化调度方法,包括 以下步骤:
7.步骤s1:获取风储联合系统相关数据,并分析风储联合系统运行方 式;
8.步骤s2:基于步骤s1得到的分析结果,构建风储联合系统日前调 度模型;
9.步骤s3:基于改进k-means算法对风储联合系统进行储能聚类分组;
10.步骤s4:根据储能聚类分组,采用maddpg算法求解风储联合系统 日前调度模型,得到最优的调度方案。
11.进一步的,所述步骤s1具体为:
12.设风电功率预测值p
w,t
服从正态分布,f
w,t
(p
w,t
)和σ
w,t
为标准化后 的概率密度函数和标准差;[p
w,t-βσ
w,t
,p
w,t
ασ
w,t
]为预测区间;α、 β为置信系数;
[0013]
风电场若将风电预测值作为上报功率值,储能需要提供的上调、 下调备用容量即分别为βσ
w,t
、ασ
w,t
;
[0014]
将风电建模为多智能体中的一个智能体,通过深度强化学习找到 最佳上报值假设此时储能需要提供的上调、下调备用容量分别为量分别为
[0015]
在风储联合系统中设t时段储能计划充电、放电功率分别为p
ch,t
、 p
dis,t
,若利用储能作为风电备用,其实际充放电功率应为:
[0016][0017][0018]
式中,为储能实际的充电、放电功率;为储能为风电所提供的下调、上调备用容量。联合系统t时段的出力 p
sys,t
为:
[0019][0020]
风储联合系统需要根据当前状态对风电与储能的实际出力进行 决策,以使得联合系统的收益最大化。
[0021]
进一步的,所述风储联合系统日前调度模型,具体为:
[0022]
目标函数为:日前调度目标函数综合考虑售电收益、出力偏差惩 罚以及储能越限惩罚等因素的风储联合系统收益最大化,见下式:
[0023][0024]
式中,t为调度周期内时段个数,本发明取为24h;λ
t
为t时段 的电价;c
1,t
为t时段出力偏差惩罚;c
2,t
为t时段储能越限惩罚;
[0025]
风储联合系统日前调度模型满足预设约束包括功率平衡约束、出 力限制约束以及储能运行特性约束。
[0026]
进一步的,所述目标函数中:
[0027]
1)出力偏差惩罚
[0028]
若上调备用不足,出力偏差的惩罚费用为:
[0029][0030]
若下调备用不足,出力偏差的惩罚费用为:
[0031][0032]
式中,ρ
dev,t
为联合系统出力偏差惩罚价格。上式表示当储能作为 风电出力备用时,若备用不足,则会面临惩罚;
[0033]
(2)储能状态越限惩罚
[0034]
若t-1时段结束时储能荷电状态为soc
t-1
,设t时段需要储能下 调功率,为满足t时段结束时荷电状态不越上限,则储能充电功率最 大值为:
[0035][0036]
式中,eb为储能电池额定容量;η
ch
为储能电池充电效率,此时 储能状态越限的惩罚费用为:
[0037]
[0038]
式中,ρ
lim
为储能状态越限的惩罚价格。若t时段需要储能上调 功率,为满足储能调节完成后其荷电状态高于下限值,则放电功率最 大值为:
[0039][0040]
式中,η
dis
为储能电池放电效率。此时储能状态越限的惩罚费用 为:
[0041][0042]
进一步的,所述预设约束,具体为:
[0043]
功率平衡约束
[0044][0045]
风电出力约束
[0046][0047]
上报容量约束
[0048]
0≤p
sys,t
≤p
w,max
p
dis,max
[0049]
储能荷电状态约束
[0050]
soc
min
≤soc
t
≤soc
max
[0051]
储能充放电功率限制
[0052][0053][0054][0055][0056]idis,t
i
ch,t
≤1
[0057]
式中,p
w,max
为风电场最大发电功率;p
ch,max
、p
dis,max
分别为储 能最大充电、放电功率;soc
min
、soc
max
分别为储能荷电状态的最小 值、最大值,通常以额定容量的百分数表示;i
ch,t
、i
dis,t
分别为储能 处于充放电的0、1状态变量。
[0058]
进一步的,所述步骤s3具体为:基于萤火虫优化的加权k-means 算法,将所有储能电池组依据荷电状态、充放电切换次数分为3组: 优先下调组ess1、优先上调组ess2、中间组ess3,中间组既可上 调也可下调。
[0059]
进一步的,所述基于萤火虫优化的加权k-means算法,具体为:
[0060]
(1)改进的目标函数
[0061]
设有n个储能样本数据,x={x1,x2,x3,
…
,xn},将每个储能电池 组xi的状态表示为一个二维向量,即xi=(x
i1
,x
i2
)
t
,其中x
i1
、x
i2
分 别表示储能的荷电状态、充放电次数,定义权重ω={ω1,ω2,ω3,...,ωn}, 其中ωi=(ω
i1
,ω
i2
)
t
为二维向量,将权值写为:
[0062][0063]
式中,x
id
为第i个样本中的第d个分量;ω
id
为第i个样本中的 第d个分量的权值。设集合v={v1,v2,v3,...,vk}为k个聚类中心的集 合,引入权值ω后,样本数据xi与聚类中心vj的距离最小化的目标函 数写为:
[0064][0065]
式中,gj为第j个组别中样本的集合;vj为gj内样本的聚类中心;
[0066]
(2)基于萤火虫算法的迭代更新公式
[0067]
萤火虫的亮度用目标函数j表示,萤火虫位置更新公式为:
[0068][0069]
式中,xi、x
i 1
分别为更新前、后的位置;β0为最大吸引度;γ 为光强吸收系数;r
ij
为个体i与j间的距离;v0为当前聚类中心最优 解;α
×
(rand-0.5)为扰动项。
[0070]
进一步的,所述储能分组中k值的选择,具体为:
[0071][0072]
式中,min(soci)、max(soci)分别表示n个电池组中soc值的 最小值与最大值;k为1时表示不对储能进行分组处理。
[0073]
进一步的,所述maddpg算法包括策略网络和价值函数网络; 所述策略网络由actor当前网络和actor目标网络组成,价值函数网 络由critic当前网络和critic目标网络组成,具体的:
[0074]
对于第i个agent来说,actor当前网络根据当前状态si做出动 作ai,生成下一状态s
′i和奖励ri,并进行其网络参数的更新;actor 目标网络从经验池中进行采样,将采样值作为下一状态s
′i选择最优下 一动作di;critic当前网络根据策略网络中actor当前网络生成的当前 动作状态等信息计算当前q值,并进行网络参数的更新;critic目 标网络则依据actor目标网络得到的下一动作状态等信息计算出目标 q值,
[0075]
设有n个agent,观测状态集合为s={s1,s2,s3,...,sn};动作集合 为a={a1,a2,a3,...,an};策略集合为π={π1,π2,π3,...,πn}。
[0076]
critic当前网络通过最小化每个agent的损失函数来优化更新参 数,损失函数计算公式如下:
[0077][0078]
yi=ri γq
′
(s
′
,a
′1,a
′2,a
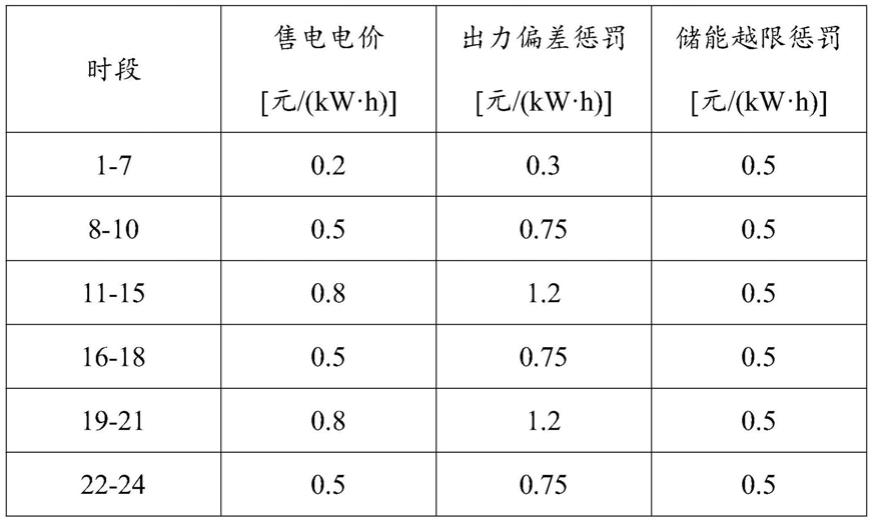
′3,
…
,a
′n,θq′
)
[0079]
式中,a1,a2,a3,...,an为n个agent的动作;ri为奖励值;yi为目 标q值;γ为奖励折扣系数。actor当前网络通过神经网络的梯度反 向传播来更新网络参数,梯度计算公式为:
[0080][0081]
critic目标网络与actor目标网络参数均采用软更新:
[0082][0083][0084]
式中,τ为软更新系数。
[0085]
进一步的,所述步骤s4中:
[0086]
状态空间定义如下:
[0087]st
={s
1,t
,s
2,t
,s
3,t
,s
4,t
}
[0088]s1,t
={p
w,t
,σ
w,t
,α,β}
[0089]si,t
={soc
i,t
,c
i,t
,d
i,t
}
[0090]
式中,c
i,t
、d
i,t
分别为t时段储能组i中储能电池充放电次数的 平均值。式(28)为t时段4个agent的状态集合;式(29)为t时段风电 状态值;式(30)为t时段储能组i的状态值;
[0091]
动作空间定义如下:
[0092]at
={a
1,t
,a
2,t
,a
3,t
,a
4,t
}
[0093]
式中,a
1,t
为t时段风电实际功率a
2,t
、a
3,t
、a
4,t
分别为t 时段为去除风电备用后3组储能组的实际功率
[0094]
奖励函数:
[0095]
风储联合系统日前调度决策的目的是为了使联合系统收益最大 化,对应于强化学习理论中的奖励最大化;因此,将奖励函数设计为 联合系统日前调度模型中的收益最大化函数,定义如下:
[0096]ri,t
(s
i,t
,a
i,t
)=λ
t
p
sys,t
(s
i,t
,a
i,t
)-c
1,t
(s
i,t
,a
i,t
)-c
2,t
(s
i,t
,a
i,t
)。
[0097]
本发明与现有技术相比具有以下有益效果:
[0098]
本发明保证储能设备可调控容量的基础上,有效平抑风电出力的 波动性,提升电力系统可靠性,实现风储联合系统的效能最大化。
附图说明
[0099]
图1是本发明一实施例中风电预测概率分布曲线;
[0100]
图2是本发明一实施例中不同调控策略下储能可调控容量分析;
[0101]
图3是本发明一实施例中改进k-means算法基本流程
[0102]
图4是本发明一实施例中风储联合系统的多智能体模型
[0103]
图5是本发明一实施例中学习过程中奖励值变化曲线
[0104]
图6是本发明一实施例中风电功率的预测值与实际值
[0105]
图7是本发明一实施例中方案1联合系统日前上报出力与实际出 力;
[0106]
图8是本发明一实施例中方案2联合系统日前上报出力与实际出 力
[0107]
图9是本发明一实施例中方案2中所有agent的功率曲线。
具体实施方式
[0108]
下面结合附图及实施例对本发明做进一步说明。
[0109]
本发明提供一种基于储能技术特性的风储联合系统日前优化调 度方法,包括以下步骤:
[0110]
步骤s1:获取风储联合系统相关数据,并分析风储联合系统运行方 式;
[0111]
步骤s2:基于步骤s1得到的分析结果,构建风储联合系统日前调 度模型;
[0112]
步骤s3:基于改进k-means算法对风储联合系统进行储能聚类分组;
[0113]
步骤s4:根据储能聚类分组,采用maddpg算法求解风储联合系统 日前调度模型,得到最优的调度方案。
[0114]
在本实施例中,风储联合系统运行方式分析,具体如下:
[0115]
设风电功率预测值p
w,t
服从正态分布,如图1所示,其中f
w,t
(p
w,t
) 和σ
w,t
为标准化后的概率密度函数和标准差;[p
w,t-βσ
w,t
,p
w,t
ασ
w,t
]为预测区间;α、β为置信系数;
[0116]
风电场若将风电预测值作为上报功率值,储能需要提供的上调、 下调备用容量即分别为βσ
w,t
、ασ
w,t
;
[0117]
优选的,本实施例中,将风电建模为多智能体中的一个智能体, 通过深度强化学习找到最佳上报值假设此时储能需要提供的上调、下 调备用容量分别为
[0118]
在风储联合系统中设t时段储能计划充电、放电功率分别为p
ch,t
、 p
dis,t
,若利用储能作为风电备用,其实际充放电功率应为:
[0119][0120][0121]
式中,为储能实际的充电、放电功率;为储能为风电所提供的下调、上调备用容量。联合系统t时段的出力 p
sys,t
为:
[0122][0123]
风储联合系统需要根据当前状态对风电与储能的实际出力进行 决策,以使得联合系统的收益最大化。
[0124]
在本实施例中,风储联合系统日前调度模型构建,具体为:
[0125]
风储联合系统相比单独的风电场具有更高的可调度性,其在电力 市场中可以等效为一个发电厂。联合系统综合考虑风电功率预测、储 能可控容量以及调度中心发布的负荷曲线、电价信息等因素进行日前 优化决策,向调度中心上报次日的出力。若联合系统的实际出力与上 报出力有偏差,则依据偏差量的多少接受惩罚,同时还要考虑对储能 的不合理调度导致其荷电状态越限而带来的惩罚费用。目标函数为: 日前调度目标函数综合考
虑售电收益、出力偏差惩罚以及储能越限惩 罚等因素的风储联合系统收益最大化,见下式:
[0126][0127]
式中,t为调度周期内时段个数,本发明取为24h;λ
t
为t时段 的电价;c
1,t
为t时段出力偏差惩罚;c
2,t
为t时段储能越限惩罚;
[0128]
1)出力偏差惩罚
[0129]
若上调备用不足,出力偏差的惩罚费用为:
[0130][0131]
若下调备用不足,出力偏差的惩罚费用为:
[0132][0133]
式中,ρ
dev,t
为联合系统出力偏差惩罚价格。上式表示当储能作为 风电出力备用时,若备用不足,则会面临惩罚;
[0134]
(2)储能状态越限惩罚
[0135]
若t-1时段结束时储能荷电状态为soc
t-1
,设t时段需要储能下 调功率,为满足t时段结束时荷电状态不越上限,则储能充电功率最 大值为:
[0136][0137]
式中,eb为储能电池额定容量;η
ch
为储能电池充电效率,此时 储能状态越限的惩罚费用为:
[0138][0139]
式中,ρ
lim
为储能状态越限的惩罚价格。若t时段需要储能上调 功率,为满足储能调节完成后其荷电状态高于下限值,则放电功率最 大值为:
[0140][0141]
式中,η
dis
为储能电池放电效率。此时储能状态越限的惩罚费用 为:
[0142][0143]
风储联合系统日前调度模型满足预设约束包括:
[0144]
功率平衡约束
[0145][0146]
风电出力约束
[0147]
[0148]
上报容量约束
[0149]
0≤p
sys,t
≤p
w,max
p
dis,max
[0150]
储能荷电状态约束
[0151]
soc
min
≤soc
t
≤soc
max
[0152]
储能充放电功率限制
[0153][0154][0155][0156][0157]idis,t
i
ch,t
≤1
[0158]
式中,p
w,max
为风电场最大发电功率;p
ch,max
、p
dis,max
分别为储 能最大充电、放电功率;soc
min
、soc
max
分别为储能荷电状态的最小 值、最大值,通常以额定容量的百分数表示;i
ch,t
、i
dis,t
分别为储能 处于充放电的0、1状态变量。
[0159]
进一步的,所述步骤s3具体为:基于萤火虫优化的加权k-means 算法,将所有储能电池组依据荷电状态、充放电切换次数分为3组: 优先下调组ess1、优先上调组ess2、中间组ess3,中间组既可上 调也可下调。
[0160]
在本实施例中,储能的可调控容量与其荷电状态有着紧密的联系, 如图2所示,由于对储能的无序调控,当某些储能电池组的soc接 近最小值时,便只有充电能力,反之则只有放电能力,使得可调控容 量明显降低。因此在对储能进行调度时,应根据其soc及充放电切 换次数等因素进行聚类分组控制,以使可调控容量最大化。
[0161]
考虑到调度的实际需求和调控算法的计算量,本实施例中将所有 储能电池组依据荷电状态、充放电切换次数分为3组:优先下调组 ess1、优先上调组ess2、中间组ess3,中间组既可上调也可下调。
[0162]
(1)优先下调组:即优先充电组,组内储能电池的特点是soc 低,不宜执行放电操作,且放电次数多,而充电次数少。
[0163]
(2)优先上调组:即优先放电组,组内储能电池的特点是soc 高,不宜执行充电操作,且充电次数多,而放电次数少。
[0164]
(3)中间组:组内储能电池组soc值相对居中,充电次数与 放电次数相近,既可使其充电,也可使其放电。
[0165]
优选的,参考图3,基于萤火虫优化的加权k-means算法分组, 具体为:
[0166]
(1)改进的目标函数
[0167]
设有n个储能样本数据,x={x1,x2,x3,...,xn},将每个储能电池 组xi的状态表示为一个二维向量,即xi=(x
i1
,x
i2
)
t
,其中x
i1
、x
i2
分 别表示储能的荷电状态、充放电次数,定义权重ω={ω1,ω2,ω3,...,ωn}, 其中ωi=(ω
i1
,ω
i2
)
t
为二维向量,将权值写为:
[0168]
[0169]
式中,x
id
为第i个样本中的第d个分量;ω
id
为第i个样本中的 第d个分量的权值。设集合v={v1,v2,v3,...,vk}为k个聚类中心的集 合,引入权值ω后,样本数据xi与聚类中心vj的距离最小化的目标函 数写为:
[0170][0171]
式中,gj为第j个组别中样本的集合;vj为gj内样本的聚类中心;
[0172]
(2)基于萤火虫算法的迭代更新公式
[0173]
亮度与吸引度是萤火虫算法中的两个关键概念。通常认为亮度决 定吸引度,吸引度与它们的亮度成正比,亮度高的萤火虫会吸引亮度 低的萤火虫,诱使亮度低的萤火虫向更亮的位置移动。亮度越高的萤 火虫,其位置越优,对应求解问题中更优的解。
[0174]
萤火虫的亮度用目标函数j表示,萤火虫位置更新公式为:
[0175][0176]
式中,xi、x
i 1
分别为更新前、后的位置;β0为最大吸引度;γ 为光强吸收系数;r
ij
为个体i与j间的距离;v0为当前聚类中心最优 解;α
×
(rand-0.5)为扰动项。
[0177]
,优选的,储能分组中k值的选择,具体为:
[0178][0179]
式中,min(soci)、max(soci)分别表示n个电池组中soc值的 最小值与最大值;k为1时表示不对储能进行分组处理。
[0180]
在本实施例中,步骤s4具体为:将风电、储能建模为多智能体 系统,如图4所示。风储联合系统的基本运行方式为:风电、储能优 先下调组ess1、储能优先上调组ess2及储能中间组ess3为4个 agent,4个agent根据次日各时段的负荷曲线、电价、惩罚费用、风 电预测情况(预测值、标准差及置信系数等)及储能的状态等环境因素 进行决策,以使联合系统的收益最大化。决策内容包括各时段风电最 优上报出力、各个储能小组充放电情况等。
[0181]
优选的,maddpg算法包括策略网络和价值函数网络;所述策 略网络由actor当前网络和actor目标网络组成,价值函数网络由 critic当前网络和critic目标网络组成,具体的:
[0182]
对于第i个agent来说,actor当前网络根据当前状态si做出动 作ai,生成下一状态s
′i和奖励ri,并进行其网络参数的更新;actor 目标网络从经验池中进行采样,将采样值作为下一状态s
′i选择最优下 一动作di;critic当前网络根据策略网络中actor当前网络生成的当前 动作状态等信息计算当前q值,并进行网络参数的更新;critic目 标网络
则依据actor目标网络得到的下一动作状态等信息计算出目标 q值,
[0183]
设有n个agent,观测状态集合为s={s1,s2,s3,...,sn};动作集合 为a={a1,a2,a3,...,an};策略集合为π={π1,π2,π3,...,πn}。
[0184]
critic当前网络通过最小化每个agent的损失函数来优化更新参 数,损失函数计算公式如下:
[0185][0186]
yi=ri γq
′
(s
′
,a
′1,a
′2,a
′3,
…
,a
′n,θq′
)
[0187]
式中,a1,a2,a3,...,an为n个agent的动作;ri为奖励值;yi为目 标q值;γ为奖励折扣系数。actor当前网络通过神经网络的梯度反 向传播来更新网络参数,梯度计算公式为:
[0188][0189]
critic目标网络与actor目标网络参数均采用软更新:
[0190][0191][0192]
式中,τ为软更新系数。
[0193]
状态空间定义如下:
[0194]st
={s
1,t
,s
2,t
,s
3,t
,s
4,t
}
[0195]s1,t
={p
w,t
,σ
w,t
,α,β}
[0196]si,t
={soc
i,t
,c
i,t
,d
i,t
}
[0197]
式中,c
i,t
、d
i,t
分别为t时段储能组i中储能电池充放电次数的 平均值。式(28)为t时段4个agent的状态集合;式(29)为t时段风电 状态值;式(30)为t时段储能组i的状态值;
[0198]
动作空间定义如下:
[0199]at
={a
1,t
,a
2,t
,a
3,t
,a
4,t
}
[0200]
式中,a
1,t
为t时段风电实际功率a
2,t
、a
2,t
、a
4,t
分别为t 时段为去除风电备用后3组储能组的实际功率
[0201]
奖励函数:
[0202]
风储联合系统日前调度决策的目的是为了使联合系统收益最大 化,对应于强化学习理论中的奖励最大化;因此,将奖励函数设计为 联合系统日前调度模型中的收益最大化函数,定义如下:
[0203]ri,t
(s
i,t
,a
i,t
)=λ
t
p
sys,t
(s
i,t
,a
i,t
)-c
1,t
(s
i,t
,a
i,t
)-c
2,t
(s
i,t
,a
i,t
)。
[0204]
实施例1:
[0205]
本实施例中,采用的数据来自某市的风电场,风电机组装机容量 为30mw,由15台2mw的风机构成,储能系统容量为60mw
·
h, 由60个0.15mw/1mw
·
h的电池组组成,储能系统的部分参数见表1。
[0206]
表1储能系统的部分参数
[0207][0208]
假设联合系统中风电场的功率分布为正态分布,其标准差为预测 值的5%,置信系数α、β均为2.0。各时段市场电价、出力偏差惩罚 费用及储能状态越限惩罚费用见表2。
[0209]
表2设置的市场电价和相应的惩罚费用
[0210][0211]
maddpg算法中4个全连接神经网络结构均相同,网络结构参 数见表3。图5是学习期间平滑处理后的奖励值变化曲线。由图5可 以看出,在训练的初始阶段,联合系统的获得的收益,即奖励值比较 低且无明显升降趋势,这是由于算法对于新环境探索不完全,尚未学 习到最优的动作策略,探索方向具有较强的随机性,随着训练周期的 增加,奖励值呈明显上升趋势,经过16000周期左右的学习后,奖励 值达到最大值并趋于稳定。这表明多agent系统在学习过程中积累了 一定经验,足以对联合系统中的各种情况作出合理的决策。
[0212]
表3 maddpg算法中的网络结构参数
[0213]
结构参数数值每层神经元个数128critic网络学习率0.001actor网络学习率0.0001经验回放池规模50000采样规模256软更新系数0.01
[0214]
在本实施例中,为验证本发明所提方案的优势,设置常规单agent 深度强化学习
调度策略为对比方案。常规深度强化学习调度策略中, 未将风电及储能建模设计为多agent系统,缺乏合作关系。为叙述方 便,将常规方法称为方案1,本发明所提方法称为方案2。所采取的 验证场景中风电出力预测值与实际值如图6所示。
[0215]
方案1下联合系统的日前上报出力与实际出力如图7所示。可以 看出,日前上报出力的趋势与风电预测的趋势相近,但采用方案1得 到的日前上报出力与实际出力在多时段存在明显偏差。造成这样结果 的原因主要有2个,一是由于没有充分考虑到风电与储能的配合关系, 在对风电出力调度时没有计及储能的状态;二是储能的无序充放电使 得储能系统中的储能电池组各自工作,降低了储能系统整体可调控容 量。
[0216]
方案2在每个时段初始时刻采用萤火虫优化的加权k-means算法 将储能系统中的60个电池组分成至多3组,即ess1、ess2和ess3。 方案2下联合系统的日前上报出力与实际出力如图8所示。在方案2 的策略中,由于maddpg算法在做出决策时,充分考虑到所有agent 的动作状态,相比较方案1,会上报更合理的出力值,如图8所示, 仅在第20和第21两个时段内存在较小出力偏差。
[0217]
方案2的策略下,所有agent出力值如图9所示。3个储能组中, 充电时优先对ess1与ess3充电,放电时优先对ess2和ess3放电, 这样通过合理的调控方式使得在19—21的三个时段内,仍有大量属 于ess3的储能电池组可供调控,达到状态下限的储能较少,可调控 容量相较方案1而言更多。
[0218]
采用方案1与方案2的运行收益与其中的惩罚费用见表4。可以 看出,方案2相较方案1而言,各agent之间紧密配合使得出力偏差 更小,尤其是通过对储能更合理地调控使得储能状态更少越限,最终 方案2相较方案1获得更高的收益,惩罚费用也更少。
[0219]
表4两种方案收益与惩罚费用
[0220][0221][0222]
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所 做的均等变化与修饰,皆应属本发明的涵盖范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
