1.本发明涉及多模态处理技术领域,尤其涉及一种基于互补内容感知的多模态事件检测方法。
背景技术:
2.多模态事件检测是指从连续的语料库(例如社交媒体)中自动识别已知事件或未知事件的过程。对于给定的图像和文本,多模态事件检测通过联合挖掘其包含的内容,检测数据所属的事件。由于多模态事件检测可以及时在互联网数据中发现新事件,所以其在应对和处理紧急事件,自动化处理和归类热点新闻以方便人们分析和查阅等方面至关重要。
3.传统的事件检测技术主要包括基于概率图的文本事件检测方法,基于早期特征拼接和晚期投票的多模态融合方法。基于概率图的文本事件检测方法较为依赖单词频率的统计,忽略了单词之间的联系并且不适用于同时包含图像和文本的数据。基于早期特征拼接的多模态融合方法主要依赖特征提取器对输入的图像和文本特征提取,然后将得到的特征向量拼接后送入指定的分类器判断其所属事件类别。而基于晚期投票的多模态融合方法则是先分别对输入的图像和文本分类,然后综合考虑两者的预测结果,采用投票的方法决定多模态数据所属的事件类别。以上两类基于多模态融合的方法较为简单,没有考虑多模态数据之间的语义联系,所以并不能有效地挖掘多模态的互补信息检测事件。
4.近年来,深度学习在事件检测领域展现了令人惊喜的前景。亓帆等人于2020年提出一种多模态编码器,将图像和文本编码到同一特征空间,并施加模态内的约束,使隶属同一事件的数据在特征空间内更紧凑。然而,由于缺少对图像和文本语义的建模,这些基于将多模态特征映射到相同空间的方法无法有效利用图像和文本的互补语义检测事件。mahdi abavisani等人于2020年提出一种基于跨模态注意力的模型,通过抑制模态间负面信息的传递,保留模态间互补信息的方式融合图像和文本数据以检测事件,证明对跨模态的互补语义建模能够有效地识别出图像和文本语义互补的事件。但是这种仅基于多模态融合的方法忽略了同模态之间上下文的信息。在多组多模态数据中,不同组多模态数据对同一个事件描述的视角和内容各不相同,利用这些多视角描述的内容能够得到事件更精确的表示。更具有挑战性的是,在多模态数据中,图像和文本并不总是成对出现,一段文字对应多张图像和一张图像对应多段文本的情况时有发生,而基于深度学习的方法仅针对成对的图像和文本数据建模,并未对多张图像对应多段文字的情况进行研究,无法应对实际场景中图像和文本多对多关系的需求。
5.因此,挖掘图像和文本的互补信息,引入同模态的上下文和对图像和文本多对多的关联建模能够有效提升多模态事件检测的性能。
技术实现要素:
6.有鉴于此,本发明提供了一种基于互补内容感知的多模态事件检测方法,以解决现有技术中没有考虑多模态数据之间的语义联系,不能有效地挖掘多模态的互补信息检测
事件的问题。
7.本发明提供了一种基于互补内容感知的多模态事件检测方法,包括:
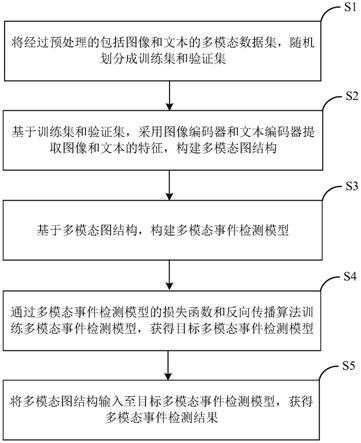
8.s1将经过预处理的包括图像和文本的多模态数据集,随机划分成训练集和验证集;
9.s2基于所述训练集和验证集,采用图像编码器和文本编码器提取图像和文本的特征,构建多模态图结构;
10.s3基于所述多模态图结构,构建多模态事件检测模型;
11.s4通过所述多模态事件检测模型的损失函数和反向传播算法训练所述多模态事件检测模型,获得目标多模态事件检测模型;
12.s5将所述多模态图结构输入至所述目标多模态事件检测模型,获得多模态事件检测结果。
13.进一步地,所述s2,包括:
14.基于所述训练集和验证集,采用图像编码器和文本编码器提取图像和文本的特征;
15.将每个图像或文本看作节点,通过同模态特征之间的相似程度及k近邻算法构建同模态连接的边,通过所述图像和文本之间同时出现的关联关系构建跨模态连接的边;
16.基于所述同模态连接的边和所述跨模态连接的边,构建多模态图结构。
17.进一步地,所述s3,包括:
18.基于所述多模态图结构,上下文建模部分利用预先构建的所述同模态连接的边连接,并提取同模态数据之间的上下文信息,对多模态图中的数据给予同模态的信息补充;
19.基于所述多模态图结构,跨模态互补信息传播部分利用预先构建的跨模态连接的边连接,并提取互补的跨模态语义信息,对所述多模态图中的数据给予跨模态的信息补充;
20.基于所述多模态图中的数据给予同模态的信息补充、所述多模态图中的数据给予跨模态的信息补充构成所述多模态事件检测模型。
21.进一步地,所述上下文建模部分上下文建模部分的构建,包括:
22.通道注意力模块接收节点特征和所述上下文信息,并计算所述节点特征和所述上下文信息每个通道之间的注意力;
23.通过对所述节点特征和所述上下文信息的每个通道的注意力打分,获得所述节点特征和所述上下文信息融合特征的结果,并基于所述节点特征和所述上下文信息融合特征的结果,构建所述上下文建模部分;
24.所述上下文信息和所述上下文信息每个通道之间的注意力的计算式分别如下:
25.s
contextual
=ah
[0026][0027]
其中,a表示图像或者是文本的单模态图的邻接矩阵,h表示所拥有节点
[0028]
对应的特征矩阵,表示节点特征和上下文信息每个通道之间的注意力,是节点特征,是上下文特征,σ表示sigmoid激活函数,w1和w2表示维度映射操作,表示偏置向量。
[0029]
进一步地,所述跨模态互补信息传播部分的构建,包括:
[0030]
设定基于所述节点特征计算,获得所述同模态的两个节点之间的相似度;
[0031]
基于所述节点特征的传播,获得跨模态节点之间相似度的传播,并基于所述跨模态节点之间相似度的传播,构建所述跨模态互补信息传播部分。
[0032]
进一步地,所述上下文信息和所述节点融合特征的结果的计算式如下:
[0033][0034]
其中,通道注意力模块接收节点特征,y表示输入上下文信息,w1和w2表示维度映射操作,是偏置向量,表示融合特征的结果,
⊙
表示逐元素乘法。
[0035]
进一步地,所述跨模态互补信息传播部分的构建,包括:
[0036]
设定基于所述节点特征计算,获得所述同模态的两个节点之间的相似度;
[0037]
基于所述节点特征的传播,获得跨模态节点之间相似度的传播,并基于所述跨模态节点之间相似度的传播,构建所述跨模态互补信息传播部分。
[0038]
进一步地,所述跨模态节点之间相似度的传播的近似表达式如下:
[0039][0040][0041][0042][0043]
其中,代表图像模态中第i个节点的特征,表示文本模态中第j个节点的特征,
⊙
表示逐元素乘法,和表示相似度传播的参数,w
α,1
,w
α,2
,w
β,1
,w
β,2
,表示可学习的参数,z
i,x
和z
′
j,y
是矩阵z和z
t
的第(i,x)和第(j,y)个元素,矩阵表示图像到文本的联系矩阵,为z的转置表示文本到图像的联系矩阵,l表示相似度传播迭代的次数,起始值为1,和分别表示第x个文本数据和第y个图像数据在第l-1轮迭代的表示。z
i,x
和z
′
j,y
分别表示关联矩阵z的第(i,x)个元素和z
t
的第(j,y)个元素,若(i,x)或(j,y)相关联,则其值为1,否则为0。
[0044]
进一步地,所述s4,包括:
[0045]
设置模型损失函数,采用反向传播算法,迭代更新优化多模态事件检测模型参数;
[0046]
采用所述训练集训练多模态事件检测模型,直至所述多模态事件检测模型在所述
验证集的损失区域收敛时,获得目标多模态事件检测模型。
[0047]
进一步地,所述模型损失函数,采用的是交叉熵损失函数。
[0048]
进一步地,所述交叉熵损失函数,同时计算图像和文本预测结果与目标结果之间的损失以及所述图像和文本预测结果与目标结果之间的损失平均值,其中,损失平均值的计算式如下:
[0049][0050][0051][0052]
其中,n表示图像或文本的个数,y
ic
表示第i个图像数据的标签,当第i个图像数据标签为c时,y
ic
为1,否则y
ic
为0,m为标签的个数,p
ic
为多模态事件检测方法预测第i个图像数据标签为c的置信度;y
jc
表示第j个文本数据的标签,当第j个文本数据标签为c时,y
jc
为1,否则y
jc
为0,m为标签的个数,p
jc
为多模态事件检测方法预测第j个文本数据标签为c的置信度;和分别为图像,文本和多模态事件检测方法的损失。
[0053]
本发明与现有技术相比存在的有益效果是:
[0054]
1.本发明提出了基于互补内容感知的多模态事件检测方法,弥补了现有算法对跨模态和上下文互补信息建模不充分的缺陷,拓展了多模态事件检测的思路。
[0055]
2.本发明提出基于通道注意力的图神经网络建模同模态的上下文信息,这使得图像或文本能够从其同模态的其他数据中获得上下文信息的补充,提高了事件检测的效果。
[0056]
3.本发明提出了一种基于深度学习的信息传播机制,用于处理图像和文本一对多、多对多的情况,弥补了现有算法对于复杂多模态关系建模不充分的缺陷,适用范围更广。
附图说明
[0057]
为了更清楚地说明本发明中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
[0058]
图1是本发明提供的一种基于互补内容感知的多模态事件检测方法的流程图;
[0059]
图2是本发明提供的构建多模态图结构的流程图;
[0060]
图3是本发明提供的获得目标多模态事件检测模型的流程图;
[0061]
图4为基于互补内容感知的多模态事件检测方法流程示意图;
[0062]
图5是本发明提供的构建多模态结构过程示意图;
[0063]
图6是本发明提供的模型架构示意图。
具体实施方式
[0064]
以下描述中,为了说明而不是为了限定,提出了诸如特定系统结构、技术之类的具体细节,以便透彻理解本发明实施例。然而,本领域的技术人员应当清楚,在没有这些具体细节的其它实施例中也可以实现本发明。在其它情况中,省略对众所周知的系统、装置、电路以及方法的详细说明,以免不必要的细节妨碍本发明的描述。
[0065]
下面将结合附图详细说明根据本发明的一种基于互补内容感知的多模态事件检测方法。
[0066]
图1是本发明公开提供的一种基于互补内容感知的多模态事件检测方法的流程图。
[0067]
如图1所示,该多模态时间检测方法包括:
[0068]
s1,将经过预处理的包括图像和文本的多模态数据集,随机划分成训练集和验证集。
[0069]
将数据集中图像和文本进行预处理,并将包含图像和文本经过预处理的数据集随机分为训练集和验证集。本发明选取多模态事件检测twitter数据集和多模态事件检测flicker数据集为验证集。选取上述两个数据集是基于其数据规模大,覆盖全的特点。
[0070]
s2,基于训练集和验证集,采用图像编码器和文本编码器提取图像和文本的特征,构建多模态图结构。
[0071]
图2是本发明实施例提供的构建多模态图结构的流程图。
[0072]
如图2所示,s2包括:
[0073]
s21,基于训练集和验证集,采用图像编码器和文本编码器提取图像和文本的特征;
[0074]
s22,将每个图像或文本看作节点,通过同模态特征之间的相似程度及k近邻算法构建同模态连接的边,通过图像和文本之间同时出现的关联关系构建跨模态连接的边;
[0075]
将每个图像或文本看作节点,s22中同模态连接通过余弦相似度估计样本之间的相似程度,通过k近邻算法选择每个节点相似程度最大的k个同模态内的节点构建同模态连接的边。
[0076]
s23,基于同模态连接的边和跨模态连接的边,构建多模态图结构。
[0077]
s3,基于多模态图结构,构建多模态事件检测模型。
[0078]
基于多模态图结构,上下文建模部分利用预先构建的同模态连接的边连接,并提取同模态数据之间的上下文信息,对多模态图中的数据给予同模态的信息补充。
[0079]
s31,上下文建模部分的构建,包括:
[0080]
通道注意力模块接收节点特征和上下文信息,并计算节点特征和上下文信息每个通道之间的注意力;
[0081]
通过对节点特征和上下文信息的每个通道的注意力打分,获得节点特征和上下文信息融合特征的结果,并基于节点特征和上下文信息融合特征的结果,构建上下文建模部分。
[0082]
上下文建模部分上下文信息的计算式与节点特征和上下文信息每个通道之间的注意力的计算式分别如下:
[0083]scontextual
=ah
[0084][0085]
其中,a表示图像或者是文本的单模态图的邻接矩阵,h所拥有节点对应的特征矩阵,表示节点特征和上下文信息每个通道之间的注意力,是节点特征,是上下文特征,σ表示sigmoid激活函数,w1和w2表示维度映射操作,表示偏置向量。
[0086]
上下文信息和节点融合特征的结果的计算式如下:
[0087][0088]
其中,通道注意力模块接收节点特征,表示输入上下文信息,w1和w2表示维度映射操作,是偏置向量,表示融合特征的结果,
⊙
表示逐元素乘法。
[0089]
s32,基于多模态图结构,跨模态互补信息传播部分利用预先构建的跨模态连接的边连接,并提取互补的跨模态语义信息,对多模态图中的数据给予跨模态的信息补充;
[0090]
跨模态互补信息传播部分的构建,包括:
[0091]
设定基于节点特征计算,获得同模态的两个节点之间的相似度;
[0092]
基于节点特征的传播,获得跨模态节点之间相似度的传播,并基于跨模态节点之间相似度的传播,构建跨模态互补信息传播部分。
[0093]
跨模态的跨模态互补信息传播部分用于提取跨模态语义信息,并建模多对多的图像与文本之间的关系。该部分是传统相似度传播到深度学习领域的拓展。对于输入的图像和文本模态的相似度矩阵和传统相似度传播通过图像和文本之间的关联矩阵传递模态内的相似度信息并迭代l次,这使同模态内相似的节点在另一模态内更相似,在同模态不相似的节点在另一模态的相似度距离更远。其具体公式如下:
[0094]
p
(l)
=αp
(0)
(1-α)λzq
(l-1)zt
,
[0095]q(l)
=βq
(0)
(1-β)λz
t
p
(l-1)
z,
[0096]
这里表示图像到文本的关联矩阵,为z的转置表示文本到图像的关联矩阵,α,β和γ为相似度传播的参数。
[0097]
此处使用矩阵内元素替换原始方程中p,q可更好地观察每个相似度的变化。注意,l代表相似度传播的迭代次数,这意味着两个节点之间的相似度仅取决于距离最大l步的节点。此处可通过堆叠多个下述等式获得与传统相似度传播一致的结果:
[0098][0099][0100]
其中,p
i,j
是矩阵p的第(i,j)个元素,q
i,j
是矩阵q的第(i,j)个元素。同理,z
i,x
和z
′
i,x
是矩阵z和z
t
的第(i,x)个元素。此处假设同一模态的两个节点之间的相似度可由其特征计算得出。由此,相似度的传播可推广为节点特征的传播。
[0101]
跨模态节点之间相似度的传播的近似表达式如下:
[0102][0103][0104][0105][0106]
其中,代表图像模态中第i个节点的特征,表示文本模态中第j个节点的特征,
⊙
表示逐元素乘法,和表示相似度传播的参数,w
α,1
,w
α,2
,w
β,1
,w
β,2
,表示可学习的参数,z
i,x
和z
′
j,y
是矩阵z和z
t
的第(i,x)和第(j,y)个元素,矩阵表示图像到文本的联系矩阵,为z的转置表示文本到图像的联系矩阵,l表示相似度传播迭代的次数,起始值为1。和分别表示第x个文本数据和第y个图像数据在第l-1轮迭代的表示。z
i,x
和z
′
j,y
分别表示关联矩阵z的第(i,x)个元素和z
t
的第(j,y)个元素,若(i,x)或(j,y)相关联,则其值为1,否则为0。
[0107]
为了防止训练过程中的梯度消失或梯度爆炸现象,此处使用动态的mean pooling取代λ。由此,相似度传播的深度拓展版可以通过交替堆叠上式和激活函数构建。本发明使用门控模块计算和防止传递跨模态的噪声,保持图像和文本特征传递的互补性。
[0108]
s33,基于多模态图中的数据给予同模态的信息补充、多模态图中的数据给予跨模态的信息补充构成多模态事件检测模型。
[0109]
s4,通过多模态事件检测模型的损失函数和反向传播算法训练多模态事件检测模型,获得目标多模态事件检测模型。
[0110]
图3是本发明提供的获得目标多模态事件检测模型的流程图。
[0111]
如图3所示,s3包括:
[0112]
s41,设置模型损失函数,采用反向传播算法,迭代更新优化多模态事件检测模型参数。
[0113]
其中,模型损失函数,采用的是交叉熵损失函数。
[0114]
交叉熵损失函数,会同时计算图像和文本预测结果与目标结果之间的损失以及图像和文本预测结果与目标结果之间的损失平均值,其中,损失平均值的计算式如下:
[0115]
[0116][0117][0118]
其中,n表示图像或文本的个数,y
ic
表示第i个图像数据的标签,当第i个图像数据标签为c时,y
ic
为1,否则y
ic
为0,m为标签的个数,p
ic
为多模态事件检测方法预测第i个图像数据标签为c的置信度;y
jc
表示第j个文本数据的标签,当第j个文本数据标签为c时,y
jc
为1,否则y
jc
为0,m为标签的个数,p
jc
为多模态事件检测方法预测第j个文本数据标签为c的置信度;和分别为图像,文本和多模态事件检测方法的损失。
[0119]
s42,采用训练集训练多模态事件检测模型,直至多模态事件检测模型在验证集的损失区域收敛时,获得目标多模态事件检测模型。
[0120]
s5,将多模态图结构输入至目标多模态事件检测模型,获得多模态事件检测结果。
[0121]
将待测试和评估的多模态数据依照步骤s1和s2构建多模态图,将得到的多模态图结构输入到训练所得模型中,模型输出结果即为多模态事件检测结果。
[0122]
模型训练完成,进行多模态事件检测以验证模型性能,预处理用于测试的图像和文本对并构建多模态图结构,然后将多模态图结构输入训练所得模型中,通过优化迭代之后,模型共训练完成设定数量的轮数,最终报告在测试集表现最好的模型的结果,即获得多模态事件检测结果。
[0123]
实施例1
[0124]
本发明的一种具体实施方式如下,一种基于互补内容感知的多模态事件检测方法,其步骤为:
[0125]
图4为基于互补内容感知的多模态事件检测方法流程示意图。
[0126]
1.数据集准备。完成数据集选取,数据预处理和数据划分。
[0127]
1.1本实例选取多模态事件检测twitter数据集(crisismmd)和多模态事件检测flicker数据集(sed2014)为验证发明的事件检测数据集。
[0128]
1.2数据预处理包括对图像增强,图像归一化和文本单词处理。具体地,图像增强包括调整大小、随机反转和随机裁剪等,本实例选取调整图像大小为256
×
256像素和50%概率随机水平反转两种增强方式。文本单词处理包括对大写字母小写化,替换文本中的网页链接为单词“link”。
[0129]
1.3数据划分依据各数据集给定的标准划分。对于sed2014数据集,随机选取167,020对图像文本用于训练,32,7070对图像文本用于验证,32,799用于测试。对于crisismmd数据集,其包含两个多模态事件检测任务:informativeness任务和humanitarian categorization任务。这些任务包含多种设定:
[0130]
(1)设定a,数据集中只包含图像和文本对,且它们属于相同的事件,用于验证本发明在处理成对的多模态数据中的性能。此设定下informativeness任务有7,876对图像文本用于训练,553对图像文本用于验证,2,821对图像文本用于测试;此设定下humanitarian categorization任务有1,352对图像文本用于训练,540对图像文本用于验证,1,467对图像文本用于测试。
[0131]
(2)设定a 是在设定a基础上的拓展,用于验证本发明在处理图像和文本拥有复杂
对应关系时的性能。此设定仅放宽了图像和文本的对应关系,即允许出现一段文本对应多张图像的情况。在此设定下,informativeness任务有7,876段文本和8,785张图像用于训练,553段文本和601张图像用于验证,2,821段文本和3,163张图像用于测试;此设定下humanitarian categorization任务有1,352段文本和1,485张图像用于训练,540段文本和584张图像用于验证,1,467段文本和1,612张图像用于测试。
[0132]
(3)设定b放宽了设定a中成对图像文本必须属于相同事件的限制,用于验证本发明在处理不一致的图像和文本数据的性能。此设定下informativeness任务有12,680对图像文本用于训练,533对图像文本用于验证,2,821对图像文本用于测试。
[0133]
(4)设定b 同样是在设定b基础上的拓展,同样放宽了图像和文本的对应关系。在此设定下,informativeness任务有12,680段文本和14,310张图像用于训练,553段文本和626张图片用于验证,2,821段文本和3,161张图像用于测试。
[0134]
2.构建多模态图结构。完成数据特征提取,建立节点的同模态关联和跨模态关联。
[0135]
2.1数据集特征提取依据各数据集给定的标准提取。对于crisismmd数据集,使用在其训练集微调的densenet161和bert分别提取图像特征和文本特征;对于sed2014数据集,使用预训练的densenet161和glove模型分别提取图像特征和文本特征。
[0136]
2.2节点的同模态关联使用余弦相似度和k近邻的算法建立。具体建立方法已在发明内容中讨论,这里不再赘述。对于crisismmd数据集中的informativeness任务,k设置为20;对于humanitarian categorization任务,k设置为15。对于sed2014数据集,k设置为15。
[0137]
2.3跨模态关联使用原始图像和文本间关系建立。在crisismmd数据集中,存在一段文本对应多张图像的情况,此处建立文本和图像一对多的关联;在sed数据集中,文本和图像成对出现,此处建立文本和图像对应的关联。
[0138]
图5是本发明实施例提供的构建多模态结构过程示意图。
[0139]
3.设计多模态事件检测模型。如图5所示,多模态事件检测模型交替使用基于通道注意力的上下文建模部分和跨模态跨模态互补信息传播部分。具体的模型设计已在发明内容中讨论,这里不再赘述。
[0140]
图6是本发明实施例提供的模型架构示意图。
[0141]
4.设计模型训练损失,训练多模态事件检测模型。采用交叉熵损失对模型训练进行约束。具体的约束设计已在发明内容中讨论,这里不再赘述。采用反向传播算法更新优化网络参数权重,直至模型损失区域收敛。在本实例中,图像修复模型训练和评估均在pytorch平台完成。模型被训练在单个nvidia gtx1080ti gpu(11gb),batch size设置为32。使用学习率为2
×
10-3
的adam优化器优化网络,模型共训练300轮,最终报告在测试集表现最好模型的结果。
[0142]
5.模型训练完成,进行多模态事件检测,将构建好的多模态图结构输入训练所得模型中,模型输出结果即为检测结果。其中sed2014数据集的准确率为68.58%,macro-f1为59.39,weighted-f1为68.24。在crisismmd数据集中,模型在informativeness任务的设定a准确率为90.93%,macro-f1为89.63%,weighted-f1为90.92%;设定a 准确率为91.17%,macro-f1为89.87%,weighted-f1为91.15%;设定b在图像上的准确率为83.55%,macro-f1为83.41%,weighted-f1为83.55%,在文本上的准去率为84.19%,macro-f1为79.54%,weighted-f1为84.05%;;设定b 在图像上的准确率为83.87%,macro-f1为83.78%,
weighted-f1为83.90%,在文本上的准确率为84.62%,macro-f1为79.67%,weighted-f1为84.31%。模型在humanitarian categorization任务的设定a准确率为92.03%,macro-f1为80.01%,weighted-f1为91.93%;设定a 准确率为92.50%,macro-f1为82.04%,weighted-f1为92.38%。结果显示,利用本发明可以有效地完成多模态事件检测任务,且在图像和文本一对一,一对多的情况下表现良好。
[0143]
以上实施例仅用于说明本发明的设计思想和特点,其目的在于使本领域内的技术人员能够了解本发明的内容并据以实施,本发明的保护范围不限于上述实施例。所以,凡依据本发明所揭示的原理、设计思路所作的等同变化或修饰,均在本发明的保护范围之内。上述所有可选技术方案,可以采用任意结合形成本技术的可选实施例,在此不再一一赘述。
[0144]
应理解,上述实施例中各步骤的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本发明实施例的实施过程构成任何限定。
[0145]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。