低信噪比下基于spp和nmf的环境音噪声抑制方法
技术领域
1.本发明涉及声音信号噪声抑制处理技术领域,具体是一种低信噪比下基于声音存在概率(sound prescence probability,简称spp)和非负矩阵分解(non-negative matrix factorization,简称nmf)的环境音噪声抑制方法。
背景技术:
2.环境音的检测与识别逐渐成为声音领域中的研究热点。然而,在实际应用中存在着这样一个问题,即感兴趣的环境音是被叠加到背景噪声上的,这导致需要忽略的噪声和所要研究的环境音之间的区分变得困难。因此,噪声抑制作为有效提高环境音检测算法灵敏度、提升环境音识别的准确性的有效措施,将会持续成为相关研究人员的研究热点。
3.在过去的研究中,基于信号处理、统计估计和线性代数理论的维纳滤波、最小均方误差和子空间等传统算法被提出,具有计算量小、易于实现的优点。然而,该类算法通常假设噪声是平稳的,因此对实际噪声环境中的非平稳噪声应用算法时,算法往往只能提供有限的噪声抑制性能。结合噪声估计的降噪算法的提出解决了传统算法处理非平稳噪声的局限性,该类算法在感兴趣的声音存在时仍可对噪声进行估计,为后续增益函数设计提供有效的噪声先验信息,以获取高质量的降噪输出。但在低信噪比条件下,该类方法仍然存在由于无法追踪噪声水平的瞬时上升而导致算法性能不佳的问题。此外,考虑到非语音的环境音的类内声音种类多,当感兴趣的非语音环境音的变化比噪声缓慢时,该类算法将失效。随着深度学习技术的发展,基于深度神经网络的噪声抑制算法在抑制非平稳噪声时,尤其是在低信噪比条件下,也显示出了显著的降噪性能提升。从带噪环境音信号中提取声学特征来构建模型的非线性映射函数,深度神经网络通过完成从输入特征到目标输出的映射,得到降噪后的信号。然而作为数据驱动的方法,深度神经网络模型往往需要提供大量的训练数据以换取良好的学习能力。并且,其监督的学习方式依赖数据的可用性,因此该类算法需要对环境中存在的噪声类型进行预设。
4.考虑到实际环境中的噪声类型主要为非平稳噪声,因此对非平稳噪声的抑制,尤其是在低信噪比条件下,一直是本领域的重难点问题。此外,由于环境具有复杂性,因此噪声抑制算法在未知噪声条件下的鲁棒性也十分重要。
技术实现要素:
5.本发明的目的是针对现有技术的不足,而提供一种低信噪比下基于spp和nmf的环境音噪声抑制方法。这种方法能提升在不同环境下对噪声抑制的鲁棒性,同时可以实现无时延的非平稳噪声估计,可以在低信噪比条件下从环境音和噪声高度重叠的谱带中准确地估计分离噪声,获得带噪环境音中的非平稳噪声信息,还能有效解决干扰噪声残留问题。
6.实现本发明目的的技术方案是:
7.低信噪比下基于spp和nmf的环境音噪声抑制方法,所述方法采用声音预处理单元、自适应噪声处理单元和环境音重建单元处理完成,其中声音预处理单元用于对声音信
号的高频部分进行增强,减少声音信号的冗余,便于后续的分析处理;自适应噪声处理单元用于对nmf分离出的噪声进行泄露环境音成分抑制,为后续谱估计器提供可靠的噪声先验信息;环境音重建单元用于获取噪声抑制后的纯净环境音,具体包括如下步骤:
8.1)声音预处理单元处理过程:
9.1.1)归一化,将声音信号幅值归一化到[-1,1]之间,便于后续数据处理;
[0010]
1.2)预加重,提升声音信号的高频部分;
[0011]
1.3)分帧加窗,利用短时平稳性将声音信号按帧进行处理,加窗使成帧的信号变得连续并具周期性;
[0012]
1.4)快速傅里叶变换,得到每一帧信号的时频谱表示;
[0013]
2)自适应噪声处理单元处理过程:
[0014]
2.1)训练环境音基矩阵,从环境音数据集中采用无监督nmf离线获取环境音基矩阵;
[0015]
2.2)在线更新噪声基矩阵,从噪声缓冲区中获取噪声基矩阵;
[0016]
2.3)初次获取分离噪声,使用预先训练的环境音基矩阵和在线更新的噪声基矩阵,通过半监督nmf从带噪环境音中分离出噪声;
[0017]
2.4)spp计算,得到初次分离噪声中的环境音存在概率,并将其用于初次分离噪声,以获取抑制环境音分量后的分离噪声;
[0018]
2.5)自适应噪声估计,设置自适应因子根据瞬时信噪比的高低自动调整分离噪声中的噪声分量,并将其用于最终的分离噪声估计的计算;
[0019]
3)环境音重建单元处理过程:
[0020]
3.1)omlsa估计器计算,将自适应噪声处理单元的分离噪声作为噪声先验信息输入,得到环境音增强的增益函数;
[0021]
3.2)增益函数应用于带噪环境音信号,得到初步的重建环境音信号;
[0022]
3.3)根据初步的重建环境音信号计算spp的结果,设定环境音在每个频点存在的标志矩阵;
[0023]
3.4)取每帧的标志矩阵与帧判定阈值进行比较,得到时-频加权因子,表示环境音在每帧上的存在概率;
[0024]
3.5)残留噪声抑制,将时-频加权因子用于增强环境音存在率高的帧,同时抑制其余帧中残留噪声,获取最终的降噪输出。
[0025]
本技术方案的有益效果:在所感兴趣的环境音受到干扰噪声破坏时,尤其是在低信噪比和非平稳噪声条件下,能够从带噪环境与中重建纯净的环境音。
[0026]
(1)本技术方案建立噪声缓冲区,采用半监督的nmf分离环境音和噪音,提升了方法在未知噪声环境下的鲁棒性,同时可以实现无时延的非平稳噪声估计;
[0027]
(2)本技术方案使用spp计算分离噪声中的环境音存在概率,通过设置基于sigmod函数的自适应因子对分离噪声中泄露的环境音成分进行抑制,可以在低信噪比条件下从环境音和噪声高度重叠的谱带中准确地估计分离噪声,获得带噪环境音中的非平稳噪声信息;
[0028]
(3)本技术方案通过对omlsa估计器输出的重建环境音进行spp计算,设置基于频点和帧的时-频加权因子,进一步得到可懂度高、质量清晰的环境音输出,同时对感兴趣环
境音不存在的帧进行抑制,有效解决干扰噪声残留问题。
[0029]
这种方法能提升在不同环境下的对噪声抑制的鲁棒性,同时可以实现无时延的非平稳噪声估计,可以在低信噪比条件下从环境音和噪声高度重叠的谱带中准确地估计分离噪声,获得带噪环境音中的非平稳噪声信息,还能有效解决干扰噪声残留问题。
附图说明
[0030]
图1是实施例的系统结构框图;
[0031]
图2是实施例中的声音预处理单元框图;
[0032]
图3是实施例中的自适应噪声处理单元框图;
[0033]
图4是实施例中的半监督nmf用于噪声抑制的流程框图;
[0034]
图5是实施例中的环境音重建单元框图;
[0035]
图6是实施例在语音数据集上的噪声抑制性能对比示意图,(a)为全局信噪比指标的对比结果示意图,(b)为客观语音质量评估指标的对比结果示意图。
具体实施方式
[0036]
下面结合附图及具体实施例对本发明作进一步的详细描述,但不是对本发明的限定。
[0037]
实施例:
[0038]
参照图1,低信噪比下基于spp和nmf的环境音噪声抑制方法,所述方法采用声音预处理单元、自适应噪声处理单元和环境音重建单元处理完成,其中声音预处理单元用于对声音信号的高频部分进行增强,减少声音信号的冗余,便于后续的分析处理;自适应噪声处理单元用于对nmf分离出的噪声进行泄露环境音成分抑制,为后续谱估计器提供可靠的噪声先验信息;环境音重建单元用于获取噪声抑制后的纯净环境音,具体包括如下步骤:
[0039]
1)声音预处理单元处理过程,如图2所示:
[0040]
1.1)归一化,将声音信号幅值通过归一化到[-1,1]之间,便于后续数据处理;
[0041]
1.2)采用滤波器进行预加重,提升声音信号的高频部分;
[0042]
1.3)由于环境音信号一般在10-50ms内可视为近平稳信号,因此将带噪环境音进行分帧加窗,假设采样率为16khz,则每一帧取32ms,即512个采样点,为使相邻两帧之间的特征参数能平滑地变化,采用50%的帧移动,并应用汉明窗,利用短时平稳性将声音信号按帧进行处理,加窗使成帧的信号变得连续并具周期性;
[0043]
1.4)对分帧加窗后的带噪环境音进行快速傅里叶变换,将信号从时域转换到时频域进行表示,即得到每一帧信号的时频谱表示;
[0044]
由于人耳对相位变化不敏感,因此后续处理主要基于其幅度谱展开;
[0045]
2)自适应噪声处理单元处理过程,如图3、图4所示:
[0046]
2.1)训练环境音基矩阵,从环境音数据集中采用无监督nmf离线获取环境音基矩阵;
[0047]
2.2)在线更新噪声基矩阵,从噪声缓冲区中获取噪声基矩阵;
[0048]
2.3)初次获取分离噪声,使用预先训练的环境音基矩阵和在线更新的噪声基矩阵,通过半监督nmf从带噪环境音中分离出噪声,根据初步分离结果对每一个时-频点计算瞬时信噪比,以确定环境音和噪音分量相互泄露严重的频点;
[0049]
2.4)结合spp计算的结果进行分离噪声的重构,得到初次分离噪声中的环境音存在概率,并将其用于初次分离噪声,以获取抑制环境音分量后的分离噪声,在重构阶段引入泄露的环境音分量和噪声分量功率比的自适应加权因子:
[0050][0051]
其中p(f,t)为spp计算结果;
[0052]
2.5)自适应噪声估计,设置自适应因子根据瞬时信噪比的高低自动调整分离噪声中的噪声分量,并将其用于最终的分离噪声估计的计算,即在信噪比较高的条件下,使用较大的α值,以避免分离出的噪声分量被削弱,而导致降噪后的环境音中存在较多噪声残留;在信噪比较低的条件下,使用较小的α值,以避免降噪后的环境音失真,最后,将α应用于初步分离噪声中,得到最终的噪声估计结果;
[0053]
3)环境音重建单元处理过程,如图5所示:
[0054]
3.1)omlsa估计器计算,将自适应噪声处理单元的分离噪声作为噪声先验信息输入,由分离噪声幅度谱提供带噪环境音中的噪声信息以计算后验信噪比,并采用直接判决法进行先验信噪比估计,结合先验和后验信噪比的估计结果计算准确的频谱增益函数,得到重建环境音的增益函数;
[0055]
3.2)增益函数应用于带噪环境音信号,得到初步的重建环境音信号,此时若带噪环境音类型为语音,则omlsa估计器输出为最终重建的环境音时频谱输出;若带噪环境音类型为非语音,则结合声音识别任务,引入时-频加权因子,用于增强环境音存在高概率的帧,同时抑制其余帧中对识别任务噪声干扰的声音频点,以提高环境音识别率;
[0056]
3.3)根据初步的重建环境音信号计算spp的结果,设定环境音在每个频点存在的标志矩阵;
[0057]
3.4)取每帧的标志矩阵与帧判定阈值进行比较,得到时-频加权因子,表示环境音在每帧上的存在概率;
[0058]
3.5)残留噪声抑制,将时-频加权因子用于增强环境音存在率高的帧,同时抑制其余帧中残留噪声,获取最终的降噪输出,经过快速傅里叶逆变换和重叠相加法,完成重建环境音从时频域到时域的还原。
[0059]
为了更直观显示本例对环境音进行噪声抑制的效果,将本例方法在语音数据集上与其他方法进行低信噪比下的非平稳噪声抑制效果的对比,如图6所示为在语音数据集上的噪声抑制性能对比示意图,其中(a)图为全局信噪比指标的对比结果,(b)图为客观语音质量评估指标的对比结果,本例方法在客观语音质量评估指标和全局信噪比指标上均优于对比方法,在三种输入低信噪比条件下与其他方法相比时,本例方法在客观语音质量评估指标下,最少提升0.13,最多提升0.60,平均提升0.26;在全局信噪比指标下,最少提升1.44db,最多提升3.78db,平均提升2.39db。此外,本例方法与异常环境音识别系统相结合
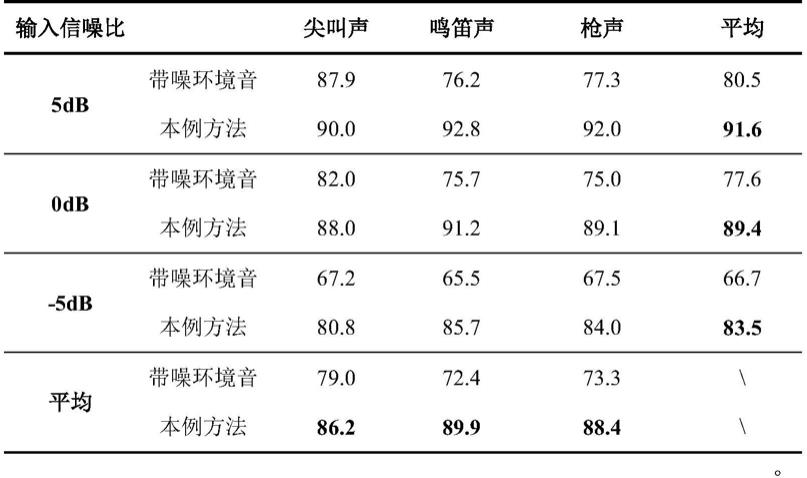
时,如表1所示,可以有效提升在室外干扰噪声下异常环境音识别系统的识别率,表1所示结果基于风声、雨声和babble噪声,但本例可抑制的噪声不限于这三种。在三种低信噪比条件下,f1得分分别提升11.1%、11.8%和16.8%;在-5db下模型提升幅度最大,这表明本例方法在低信噪比下的有效性。
[0060]
表1 识别任务的f1得分
[0061]
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。