1.本发明属于车牌识别技术领域,具体涉及一种用于车牌识别的车牌定位方法、装置及存储介质。
背景技术:
2.随着计算机视觉、数字图像处理技术以及智能交通技术的发展,车牌识别技术在智能交通领域中的应用越来越广泛,如停车场闸口、高速公路收费站以及交通违规识别等场景,而在车牌识别技术中,车牌定位以及车牌矫正是首要问题,也是影响车牌识别精度的重要因素。
3.现有的车牌定位技术中,主要以传统图像处理算法和基于深度学习的目标检测算法为主,其中,基于传统图像处理算法的车牌识别技术,主要以图像二值化、车牌颜色特征以及车牌边缘特征等手段定位分割出车牌,进而通过车牌字符倾斜特征矫正车牌;而基于深度学习的目标检测算法,如yolo(you only look once,是joseph redmon和ali farhadi等人于2015年提出的基于单个神经网络的目标检测系统)、ssd(single shot multibox detector,物体检测网络)以及r-cnn(region-cnn(convolutional neural networks,卷积神经网络),是第一个成功将深度学习应用到目标检测上的算法)等目标检测算法,在检测领域发展迅猛,应用于车牌定位已有丰富的理论支撑和经验参考,该方法具有适应车牌广、召回率高以及定位精确等优点。
4.但是前述两种定位方法存在以下不足:由于中国车牌样式以及颜色众多,存在渐变绿色、蓝色、黑色以及白色等样式,同时受到实际场景下光照等因素的影响,传统的图像处理算法定位车牌难度较大,精度不够,鲁棒性不足;另外,在实际场景中,车牌识别摄像头与车之间存在不确定的角度,目标检测算法定位出的车牌存在倾斜问题,需要再结合图像技术或深度学习技术进行倾斜矫正,干扰过滤等后处理,且由于干扰影响,实际中很难做到高精度的车牌定位,从而也导致车牌识别精度不高;由此,提供一种精度高的车牌定位方法迫在眉睫。
技术实现要素:
5.本发明的目的是提供一种用于车牌识别的车牌定位方法、装置及存储介质,以解决现有车牌定位方法所存在的精度低的问题。
6.为了实现上述目的,本发明采用以下技术方案:
7.本发明提供了一种用于车牌识别的车牌定位方法,包括:
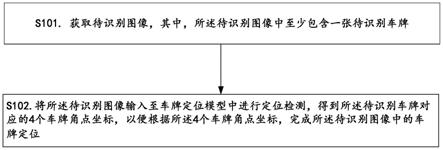
8.获取待识别图像,其中,所述待识别图像中至少包含一张待识别车牌;
9.将所述待识别图像输入至车牌定位模型中进行定位检测,得到所述待识别车牌对应的4个车牌角点坐标,以便根据所述4个车牌角点坐标,完成所述待识别图像中的车牌定位,其中,所述车牌定位模型包括mobilenetv1-0.25网络、fpn网络、ssh网络以及head网络;
10.所述mobilenetv1-0.25网络作为所述车牌定位模型的主干特征提取网络,用于在
三种感受野条件下对所述待识别图像进行特征提取,得到三个第一特征图;
11.所述fpn网络用于对三个第一特征图进行上采样以及特征融合,得到三个第二特征图;
12.所述ssh网络包括三个并行的卷积层,用于利用所述三个并行的卷积层对三个第二特征图进行卷积处理,得到三个第三特征图;
13.所述head网络用于对三个第三特征图进行车牌关键点预测,以输出8维的关键点向量,以便根据所述关键点向量得到所述4个车牌角点坐标。
14.基于上述公开的内容,本发明通过利用mobilenetv1-0.25网络、fpn网络、ssh网络以及head网络预先构建车牌定位模型,从而将待识别图像输入至模型中进行特征提取,即先利用mobilenetv1-0.25网络进行主干特征提取,然后利用fpn网络对提取的主干特征进行特征融合,得到具有更为丰富特征信息的特征图,接着,再利用ssh网络中三个并行的卷积层对fpn网络输出的特征图进行多尺度检测,进一步的加强特征提取,以增强提取的特征的上下文信息,从而提高提取的车牌特征质量,达到提高车牌定位精度的目的,最后,利用head网络进行关键点预测,输出8维关键点向量,即本发明将模型中的关键点分支输出维度由10维更改为8维,以便匹配车牌的4个角点,由此,本发明可直接获取车牌的4个角点,实现了端到端的车牌定位,避免目标检测以及图像处理技术所存在的误差大以及精度低问题,进一步的提高了车牌定位精度。
15.通过上述设计,本发明可直接获取车牌的4个角点,实现了端到端的车牌定位,避免了目标检测以及图像处理技术所存在的误差大以及精度低问题,且本发明采用mobilenetv1-0.25网络为骨干网络,在精度几乎没有损失的情况下,实现了车牌定位,降低了整体模型的参数量和计算量,为终端部署车牌识别系统提供了条件,适用于大规模推广与应用。
16.在一个可能的设计中,所述车牌定位模型的损失函数为:
[0017][0018]
上述式中,l表示所述车牌定位模型的损失函数,l
cls
表示目标分类损失函数,l
box
表示检测框回归损失函数,l
pts
表示关键点回归损失函数,pi表示锚点i被预测为车牌角点的概率,为1时表示为正锚点的真实标签,为0时表示负锚点的真实标签,ti表示锚点框中的预测框的预测坐标,表示锚点框中的预测框的真实坐标,li表示锚点框中预测的车牌角点坐标,表示车牌标注角点坐标,λ1、λ2、λ3和λ4表示权重系数,为常数;
[0019]
l
pts1
表示角点距离约束函数,用于约束待识别车牌的两平行边的距离;
[0020]
l
pts2
表示角点距离比例约束函数,用于约束待识别车牌的长度与宽度的比例。
[0021]
在一个可能的设计中,所述角点距离约束函数为:
[0022]
l
pts1
(li)=|||l0l1|-|l2l3||| |||l0l2|-|l1l3|||
[0023]
上述式中,l0l1表示第一个车牌角点与第二个车牌角点之间的距离,l2l3表示第三个车牌角点与第四个车牌角点之间的距离,l0l2表示第一个车牌角点与第三个车牌角点之间的距离,l1l3表示第二个车牌角点与第四个车牌角点之间的距离,其中,所述待识别车牌的左上角为第一个车牌角点,右上角为第二个车牌角点,左下角为第三个车牌角点,右下角为第四个车牌角点。
[0024]
在一个可能的设计中,所述角点距离比例约束函数为:
[0025][0026]
前述式中,表示第一个车牌标注角点到第二个车牌标注角点之间的距离,表示第一个车牌标注角点到第三个车牌标注角点之间的距离。
[0027]
基于前述公开的内容,本发明在传统的retinaface网络的基础上,增加了角点距离约束函数以及角点距离比例约束函数,其中,角点距离约束函数用来约束待识别的车牌的平行边的距离,即两平行边的距离应该相等,也就是将角点距离约束函数的值约束到0或趋近于0,而角点距离比例约束函数则是使用标注点来约束预测点,即根据车牌标注角点得出的车牌的长和宽的比例,与根据车牌角点坐标得出的车牌的长和宽的比例应该相等,也就是将角点距离比例约束函数约束为0或趋近于0;由此,可进一步的提高车牌角点的定位精度。
[0028]
在一个可能的设计中,权重系数λ1、λ2、λ3和λ4的值依次为0.25、0.5、0.01以及0.01。
[0029]
通过上述设计,本发明通过加大各个损失函数的权重,使得角点迭代更加精确,进一步的提高了角点定位精度。
[0030]
在一个可能的设计中,所述车牌定位模型的先验anchor的尺寸为:16*8、32*16、64*32、128*64、256*128以及512*256,其中,所述先验anchor用于表征定位车牌的锚点框。
[0031]
基于上述公开的内容,本发明通过改进锚点框的长度和宽度,可使锚点框更贴近于车牌的实际尺寸,由此,可进一步的提高角点定位精度。
[0032]
在一个可能的设计中,在将所述待识别图像输入至车牌定位模型中进行定位检测,得到所述待识别车牌对应的4个车牌角点坐标后,所述方法还包括:
[0033]
获取所述待识别图像中的车牌标准角点坐标;
[0034]
利用所述车牌标准角点坐标和所述4个车牌角点坐标对所述待识别图像进行透视变换处理,得到矫正后的待识别图像,其中,所述矫正后的待识别图像仅包含所述待识别车牌;
[0035]
将所述矫正后的待识别图像输入至车牌识别模型中,得到车牌识别结果。
[0036]
基于上述公开的内容,本发明结合车牌定位模型输出的车牌角点坐标与车牌标准角点坐标(即用户预设的坐标,可根据要变换的尺寸而具体设定),对待识别图像进行透视变换处理,可实现车牌的倾斜矫正,使矫正后的图像仅包含待识别车牌,由此,可提高车牌识别精度。
[0037]
第二方面,本发明提供了一种用于车牌识别的车牌定位装置,包括:
[0038]
获取单元,用于获取待识别图像,其中,所述待识别图像中至少包含一张待识别车牌;
[0039]
车牌定位单元,用于将所述待识别图像输入至车牌定位模型中进行定位检测,得到所述待识别车牌对应的4个车牌角点坐标,以便根据所述4个车牌角点坐标,完成所述待识别图像中的车牌定位,其中,所述车牌定位模型包括mobilenetv1-0.25网络、fpn网络、ssh网络以及head网络。
[0040]
第三方面,本发明提供了另一种用于车牌识别的车牌定位装置,以装置为计算机主设备为例,包括依次通信相连的存储器、处理器和收发器,其中,所述存储器用于存储计算机程序,所述收发器用于收发消息,所述处理器用于读取所述计算机程序,执行如第一方面或第一方面中任意一种可能设计的所述用于车牌识别的车牌定位方法。
[0041]
第四方面,本发明提供了一种存储介质,所述存储介质上存储有指令,当所述指令在计算机上运行时,执行如第一方面或第一方面中任意一种可能设计的所述用于车牌识别的车牌定位方法。
[0042]
第五方面,本发明提供了一种包含指令的计算机程序产品,当所述指令在计算机上运行时,使所述计算机执行如第一方面或第一方面中任意一种可能设计的所述用于车牌识别的车牌定位方法。
附图说明
[0043]
图1为本发明提供的车牌定位模型的结构示意图;
[0044]
图2为本发明提供的用于车牌识别的车牌定位方法的步骤流程示意图;
[0045]
图3为本发明提供的ssh网络的结构示意图;
[0046]
图4为本发明提供的待识别车牌上的4个车牌角点的标注示意图;
[0047]
图5为本发明提供的待识别车牌的车牌定位效果示意图;
[0048]
图6为本发明提供的车牌识别的步骤流程示意图;
[0049]
图7为本发明提供的用于车牌识别的车牌定位装置的结构示意图;
[0050]
图8为本发明提供的计算机主设备的结构示意图。
具体实施方式
[0051]
下面结合附图及具体实施例来对本发明作进一步阐述。在此需要说明的是,对于这些实施例方式的说明虽然是用于帮助理解本发明,但并不构成对本发明的限定。本文公开的特定结构和功能细节仅用于描述本发明的示例实施例。然而,可用很多备选的形式来体现本发明,并且不应当理解为本发明限制在本文阐述的实施例中。
[0052]
应当理解,尽管本文可能使用术语第一、第二等等来描述各种单元,但是这些单元不应当受到这些术语的限制。这些术语仅用于区分一个单元和另一个单元。例如可以将第一单元称作第二单元,并且类似地可以将第二单元称作第一单元,同时不脱离本发明的示例实施例的范围。
[0053]
应当理解,对于本文中可能出现的术语“和/或”,其仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,单独存在b,同时存在a和b三种情况;对于本文中可能出现的术语“/和”,其是描述另一种关联对象关系,表示可以存在两种关系,例如,a/和b,可以表示:单独存在a,单独存在a和b两种情况;另外,对于本文中可能出现的字符“/”,一般表示前后关联对象是一种“或”关系。
[0054]
实施例
[0055]
参见图1所示,为申请提供一种车牌定位模型,该车牌定位模型是在传统的retinaface检测网络上进行了改进,其包括:mobilenetv1-0.25网络、fpn网络、ssh网络以及head网络,其中,本车牌定位模型采用mobilenetv1-0.25网络作为主干特征提取网络,用
于在三种感受野条件下对输入的待识别图像进行特征提取,得到三个第一特征图(即在不同维度下进行特征信息的提取,以得到不同维度下的特征图),而fpn网络则用于对三个第一特征图进行上采样以及特征融合,得到三个第二特征图(即通过特征融合来得到具有更为丰富特征信息的特征图);同时,本模型中的ssh网络设置有三个并行的卷积层,即利用三个并行的卷积层,分别对三个第二特征图进行卷积处理,从而得到三个第三特征图(其实质为:利用卷积处理进行多尺度的特征检测,从而增强提取的特征的上下文信息,以提高提取的特征的质量,进而提高角点定位精度);最后,利用head网络对三个第三特征图进行车牌关键点预测,从而输出8维的关键点向量,以便根据该关键点向量得到4个车牌角点坐标(即每一个车牌角点坐标使用2维向量来表示(也就是横纵坐标),而8维向量正好对应4个角点);由此通过上述设计,本发明可直接获取车牌的4个角点,实现了端到端的车牌定位,避免了目标检测以及图像处理技术所存在的误差大以及精度低问题,且本发明采用mobilenetv1-0.25网络为骨干网络,不仅在精度几乎没有损失的情况下,实现了车牌定位,还降低了整体模型的参数量和计算量,为终端部署车牌识别系统提供了条件,适用于大规模推广与应用。
[0056]
下述结合附图介绍本技术实施例所提供的车牌定位方法,且将该方法应用在图1所示的车牌定位模型结构中进行具体阐述。
[0057]
如图2所示,本实施例第一方面所提供的用于车牌识别的车牌定位方法,适用于任何场景下的车牌定位(例如停车场进出闸、高速公路收费站进出闸以及交通违规抓拍等),其可以但不限于包括如下步骤s101和步骤s102。
[0058]
s101.获取待识别图像,其中,所述待识别图像中至少包含一张待识别车牌。
[0059]
步骤s101则是获取待识别图像的过程,以便后续输入至车牌定位模型中,提取出车牌的四个车牌角点坐标,从而完成图像中车牌的定位;具体实施时,可以但不限于为:在停车场进出闸时拍摄的车牌照片和/或进出高速路收费站时拍摄的车牌照片作为待识别图像,也可为一段车牌视频内的任一图片作为待识别图像(即对视频进行逐帧处理,从而得到多张图像),还可为工作中人员直接上传包含待识别车牌的图像,即待识别图像可根据具体的应用场景而选择不同的获取方式,在此不作具体限定。
[0060]
在得到待识别图像后,即可利用前述图1所示的模型对图像进行图像识别,以实现图像内车牌的定位,如以下步骤s102所示。
[0061]
s102.将所述待识别图像输入至车牌定位模型中进行定位检测,得到所述待识别车牌对应的4个车牌角点坐标,以便根据所述4个车牌角点坐标,完成所述待识别图像中的车牌定位。
[0062]
由于前述就已说明,本实施例所提供的车牌定位模型是在传统的retinaface检测网络上进行了改进,即将mobilenetv1-0.25网络作为retinaface检测网络的主干特征提取网络,并保留传统retinaface检测网络中fpn网络、ssh网络以及head网络,从而实现车牌角点坐标的提取,以完成待识别图像中的车牌定位。
[0063]
参见图1所示,下述对车牌定位模型进行具体的阐述:
[0064]
首先,mobilenet网络是google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想便是深度可分离卷积(depthwise separable convolution),具有v1、v2和v3三种结构,而mobilenetv1-0.25网络则是在mobilenetv1的基础上进行结构
的简化,即将其通道数压缩为mobilenetv1网络的1/4,从而在精度损失微小的条件下,大幅降低模型的计算量以及参数量,以便为模型部署到各个嵌入式设备上提供了有利条件。
[0065]
具体实施时,mobilenetv1-0.25网络会在三种不同感受野的条件下对待识别图像进行特征提取,从而得到三个不同通道数的第一特征图,也就是对待识别图像进行第一次特征提取,而感受野是特征图上的像素点在原始图像(即待识别图像)上映射区域的大小,即感受野越大,表示提取到的原始图像的范围就越大,提取的图像中就包含更为丰富的特征信息;而本实施例中,使用三种感受野进行特征提取,相当于提取了三个维度的特征信息,从而保证了特征信息提取的全面性。
[0066]
在本实施例中,可以但不限于在8倍(即利用卷积运算对待识别图像进行卷积处理,如使用大小为2*2的卷积核进行卷积运算)、16倍以及32倍条件下进行采样(可以但不限于使用dw(deepthwise)卷积进行特征采样),从而得64通道数、128通道数以及256通道数的第一特征图(即图1中的c3、c4和c5),即输出三个第一特征图至fpn网络中进行特征融合,以进一步的提高提取的特征信息。
[0067]
具体实施时,fpn网络(feature pyramid networks,特征图金字塔网络)在不增加模型的计算量的情况下,可大幅提升对物体的检测性能,即对mobilenetv1-0.25网络输出的第一特征图先进行通道数的改变,然后依次进行上采样以及特征融合,以得到特征信息更为丰富的第二特征图;可选的,fpn网络可以但不限于使用1*1的卷积核对前述64通道数、128通道数以及256通道数的第一特征图进行卷积运算,从而将三者的通道数调整为64通道数,其中,1*1的卷积不需要考虑像素跟周边像素的关系,其可对不同通道上的像素进行线性组合,然后进行非线性化操作,以完成降维的功能(即在降低通道数的同时,不改变图像的宽和高,从而达到降低计算量的目的)。
[0068]
在将三个第一特征图进行通道调整后,则可进行上采样(即进行图像的放大)以及特征融合,具体实施时,可以但不限于使用最临近插值法、双线性插值法、均值插值法或中值插值法进行上采样,且在进行特征融合时,具体操作如下:参见图1所示,第一特征图c5作为底层特征图,经过fpn网络后,直接作为第二特征图p5;接着对第一特征图c5进行上采样,并与第二特征图c4进行特征融合,得到第二特征图p4,最后,第二特征图p4进行上采样,并与第一特征图c3进行特征融合,得到第二特征图p3,由此,即可得到三个第二特征图,从而实现三个维度下特征的融合,不仅避免了特征信息的丢失,还得到了更为丰富的特征信息,进而增加了图像中车牌的定位能力。
[0069]
在本实施例中,是采用通道融合实现前述三个第一特征图的特征融合,通道融合也称:concat通道融合,其是将卷积层的通道数进行合并,是各个神经网络模型中常用的特征融合方式。
[0070]
在得到三个第二特征图后,即可输入至ssh网络(是基于视觉几何群网络(visual geometry group network,vgg-16网络)的改进)进行卷积处理,从而得到信息更为精细的特征;ssh网络设置有三个并行的卷积层,即可以利用三个并行的卷积层对三个第二特征图分别进行卷积处理,以实现多尺度的特征检测,从而加强特征提取,并提高特征图的上下文信息,以提高提取的特征的质量以及角点定位精度。
[0071]
参见图3所示,ssh网络中的三个并行的卷积层分别为,左边的一次3*3的卷积,中间的两次3*3的卷积,以及右边的三次3*3的卷积,图3中的conc2d ks=3filters=32,则代
表使用3*3的卷积核,并进行conv2d卷积,得到通道数为32的特征图;具体实施时,也就是将三个第二特征图分别输入三个并行的卷积层中,从而得到三个第三特征图。
[0072]
在经过前述三个网络的特征提取后,即可利用head网络进行车牌关键点预测,即进行先验框(也称为锚点框或检测框)的检测,head网络是获取网络输出内容的网络,其可利用前述三个网络提取出的特征进行预测,从而得出预测结果。
[0073]
在本实施例中,head网络进行车牌关键点预测包括以下三个方面:(1)分类预测,用于判断先验框内部是否包含目标(即车牌);(2)先验框的回归,其用于对先验框进行调整,从而得到预测框,需要四个参数,前两个用于对先验框的中心进行调整,后两个用于对先验框的宽高进行调整,可以但不限于利用一个1*1的卷积,实现前述先验框的调整;(3)车牌关键点的回归,即用于对先验框内的预测框进行调整,从而获取车牌关键点坐标,需要8个参数,每一个车牌关键点需要两个调整参数(也就是横纵坐标),即对预测框中心的x,y轴进行调整以获取车牌关键点坐标,即会输出8维关键点向量,以根据该8维关键点向量匹配得到4个车牌关键点坐标(也就是4个车牌角点坐标),即每一个车牌角点坐标用(x,y)的二维向量表示,当然,最后输出的结果用坐标进行表示。
[0074]
同时,在具体实施时,本实施例还对前述车牌定位模型的模型参数进行了进一步的优化,具体包括:新增模型关于角点的约束条件、改进先验框的尺寸以及各个约束条件的权重。
[0075]
首先,本实施例设置所述车牌定位模型的先验anchor的尺寸为:16*8(长*宽)、32*16、64*32、128*64、256*128以及512*256,其中,所述先验anchor用于表征定位车牌的锚点框;通过前述设计,可使锚点框更贴近于车牌的实际尺寸,由此,可进一步的提高角点定位精度。
[0076]
其次,本实施例在retinaface检测网络原有的约束条件的基础上,新增了角点距离约束条件以及角点距离比例约束条件,其原因为:传统的retinaface检测网络为人脸识别网络,其只做了关键点回归监督,存在如下弊端:关键点之间是有相对位置的,对于人脸来说,左右眼睛对应的关键点在上,鼻子对应的关键点在中,而左右嘴角点对应的关键点在下,但是,传统的retinaface检测网络并未对关键点的位置进行监督学习,这会导致最终识别出的关键点的位置存在小概率的错位误差,从而影响定位精度,而该弊端在进行车牌定位时,影响甚大,其会直接导致车牌定位以及识别错误;由此,本实施例新增了前述两种关键点的约束条件,以便进行关键点位置的约束;同时,由于车牌的外观在几何上是标准的矩形,即便在倾斜时,也是标准的平行四边形,因此,该约束在倾斜时也可应用。
[0077]
其中,角点距离约束函数用于约束待识别车牌的两平行边的距离(即保证两平行边的距离相等),而角点距离比例约束函数则用于约束待识别车牌的长度与宽度的比例,也就是识别出来的车牌的长度与宽度的比例,与车牌实际的长度与宽度的比例应该相等,具体设置约束条件的函数(也就是整个模型的损失函数)如下所示:
[0078][0079]
上述式中,l表示所述车牌定位模型的损失函数,l
cls
表示目标分类损失函数,l
box
表示检测框回归损失函数,l
pts
表示关键点回归损失函数,pi表示锚点i(表示特征图上的最小单位点)被预测为车牌角点的概率,为1时表示为正锚点的真实标签,为0时表示负
锚点的真实标签,ti表示锚点框中的预测框的预测坐标,表示锚点框中的预测框的真实坐标,li表示锚点框中预测的车牌角点坐标,表示车牌标注角点坐标,λ1、λ2、λ3和λ4表示权重系数,为常数。
[0080]
l
pts1
表示角点距离约束函数,用于约束待识别车牌的两平行边的距离。
[0081]
l
pts2
表示角点距离比例约束函数,用于约束待识别车牌的长度与宽度的比例。
[0082]
而在(1)中,l
pts1
的具体函数表达式为:
[0083]
所述角点距离约束函数为:
[0084]
l
pts1
(li)=|||l0l1|-|l2l3||| |||l0l2|-|l1l3|||
ꢀꢀꢀꢀꢀ
(2)
[0085]
上述式(2)中,l0l1表示第一个车牌角点与第二个车牌角点之间的距离,l2l3表示第三个车牌角点与第四个车牌角点之间的距离,l0l2表示第一个车牌角点与第三个车牌角点之间的距离,l1l3表示第二个车牌角点与第四个车牌角点之间的距离,其中,参见图4所示,所述待识别车牌的左上角为第一个车牌角点(记为p0),右上角为第二个车牌角点(记为p1),左下角为第三个车牌角点(记为p2),右下角为第四个车牌角点(记为p3)。
[0086]
通过图4可知,第一个车牌角点与第二个车牌角点之间的距离,以及第三个车牌角点与第四个车牌角点之间的距离为待识别车牌的两长度边,而第一个车牌角点与第三个车牌角点之间的距离以及第二个车牌角点与第四个车牌角点之间的距离则为待识别车牌的两宽度边;由此,前述式(2)表示的约束含义为:两平行边的距离应该相等,也就是l
pts1
最终的值应该约束为0或趋近于0,这样识别出的角点才是最准确的。
[0087]
同理,所述角点距离比例约束函数为:
[0088][0089]
前述式(3)中,表示第一个车牌标注角点到第二个车牌标注角点之间的距离,表示第一个车牌标注角点到第三个车牌标注角点之间的距离,其中,车牌标注角点代表为车牌的真实角点坐标,由工作人员预先测量得出。
[0090]
由此,前述式(3)的约束含义为:根据模型预测出的4个车牌角点坐标得出的车牌的长度与宽度之比,与车牌真实的长度与宽度之比,应该相等,即角点距离比例约束函数的值最终应该约束为0或趋近于0。
[0091]
在本实施例中,举例根据车牌角点坐标得出距离,可以但不限于使用坐标距离公式得出,于此不多加赘述。
[0092]
由此通过前述对模型约束条件的改进,可提升车牌4个角点的回归精度,降低角点错误风险。
[0093]
最后,在传统的retinaface检测网络中,λ1=0.25,λ2=0.1,关键点回归损失函数的权重较低,而在车牌定位检测中,车牌角点相对于车牌位置框更加重要,所以本实施例设置λ2=0.5,且设置新增约束项的权重系数λ3=0.01,λ4=0.01;由此,可共同约束角点回归,以进一步的提高车牌角点的定位精度。
[0094]
由此通过前述对车牌定位模型的详细阐述,本发明具有如下优点:
[0095]
(1)本发明采用轻量级的mobilenetv1-0.25网络作为骨干网络,不仅可在精度几
乎没有损失的情况下,实现车牌角点定位,还降低了模型的计算量以及参数量,为终端部署车牌识别系统提供了有利条件。
[0096]
(2)关键点分支输出由传统的10维向量改进为8维向量,可直接获取4个车牌角点,实现了端到端的车牌定位,避免目标检测分步定位误差放大问题。
[0097]
(3)通过改进先验框尺寸、增加角点距离约束条件、增加角点距离比例约条件以及增大了关键点回归损失函数的权重,可显著提升车牌角点的定位精度,进一步的提升车牌识别精度。
[0098]
参见图6所示,本实施例第二方面在实施例一第一方面的基础上,提供了基于车牌角点坐标的车牌识别方法,如以下步骤s201~s205所示。
[0099]
s201.获取待识别图像,其中,所述待识别图像中至少包含一张待识别车牌。
[0100]
s202.将所述待识别图像输入至车牌定位模型中进行定位检测,得到所述待识别车牌对应的4个车牌角点坐标。
[0101]
s203.获取所述待识别图像中的车牌标准角点坐标。
[0102]
s204.利用所述车牌标准角点坐标和所述4个车牌角点坐标对所述待识别图像进行透视变换处理,得到矫正后的待识别图像,其中,所述矫正后的待识别图像仅包含所述待识别车牌。
[0103]
s205.将所述矫正后的待识别图像输入至车牌识别模型中,得到车牌识别结果。
[0104]
前述步骤的车牌识别原理为:
[0105]
利用opencv(是一个基于apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库)中的getperspectivetransform函数,并根据4个车牌角点坐标和4个车牌标准角点坐标构建透视变换矩阵m,然后利用opencv中的warpperspective函数,传入待识别图像和矩阵m,即可得到矫正后的待识别图像。
[0106]
具体实施时,4个车牌标准角点坐标可以但不限于为用户根据要变换得到的车牌尺寸进行预设,如,若需变换为94*24大小的车牌,那么前述4个车牌标准角点坐标则为:p0(0,0)、p1(94,0),p2(24,0),p3(94,24),同时,可利用lprnet(license plate recognition via deep neural networks)车牌识别网络来进行车牌识别。
[0107]
参见图5所示,图5为采用本实施例所提供的定位模型以及识别方法进行的车牌定位以及识别效果示意图,从图5中可明显看出,可实现端到端的车牌定位,并进行倾斜矫正,从而得到仅含有待识别车牌的图像,明显提高了车牌的定位以及识别精度。
[0108]
如图7所示,本实施例第三方面提供了一种实现实施例第一方面中所述的用于车牌识别的车牌定位方法的硬件装置,包括:
[0109]
获取单元,用于获取待识别图像,其中,所述待识别图像中至少包含一张待识别车牌。
[0110]
车牌定位单元,用于将所述待识别图像输入至车牌定位模型中进行定位检测,得到所述待识别车牌对应的4个车牌角点坐标,以便根据所述4个车牌角点坐标,完成所述待识别图像中的车牌定位,其中,所述车牌定位模型包括mobilenetv1-0.25网络、fpn网络、ssh网络以及head网络。
[0111]
本实施例提供的硬件装置的工作过程、工作细节和技术效果,可以参见实施例第一方面,于此不再赘述。
[0112]
如图8所示,本实施例第四方面提供了另一种用于车牌识别的车牌定位装置,以装置为计算机主设备为例,包括:依次通信相连的存储器、处理器和收发器,其中,所述存储器用于存储计算机程序,所述收发器用于收发消息,所述处理器用于读取所述计算机程序,执行如实施例第一方面所述的用于车牌识别的车牌定位方法。
[0113]
具体举例的,所述存储器可以但不限于包括随机存取存储器(random access memory,ram)、只读存储器(read only memory image,rom)、闪存(flash memory)、先进先出存储器(first input first output,fifo)和/或先进后出存储器(first in last out,filo)等等;具体地,处理器可以包括一个或多个处理核心,比如4核心处理器、8核心处理器等。处理器可以采用dsp(digital signal process ing,数字信号处理)、fpga(field-programmable gate array,现场可编程门阵列)、pla(programmable logic array,可编程逻辑阵列)中的至少一种硬件形式来实现,同时,处理器也可以包括主处理器和协处理器,主处理器是用于对在唤醒状态下的数据进行处理的处理器,也称cpu(central processing unit,中央处理器);协处理器是用于对在待机状态下的数据进行处理的低功耗处理器。
[0114]
在一些实施例中,处理器可以在集成有gpu(graphics processing unit,图像处理器),gpu用于负责显示屏所需要显示的内容的渲染和绘制,例如,所述处理器可以不限于采用型号为stm32f105系列的微处理器、精简指令集计算机(reduced instruction set computer,rsic)微处理器、x86等架构处理器或集成嵌入式神经网络处理器(neural-network processing units,npu)的处理器;所述收发器可以但不限于为无线保真(wifi)无线收发器、蓝牙无线收发器、通用分组无线服务技术(general packet radio service,gprs)无线收发器、紫蜂协议(基于ieee802.15.4标准的低功耗局域网协议,zigbee)无线收发器、3g收发器、4g收发器和/或5g收发器等。此外,所述装置还可以但不限于包括有电源模块、显示屏和其它必要的部件。
[0115]
本实施例提供的计算机主设备的工作过程、工作细节和技术效果,可以参见实施例第一方面,于此不再赘述。
[0116]
本实施例第五方面提供了一种存储包含有实施例第一方面所述的用于车牌识别的车牌定位方法的指令的存储介质,即所述存储介质上存储有指令,当所述指令在计算机上运行时,执行如第一方面所述的用于车牌识别的车牌定位方法。
[0117]
其中,所述存储介质是指存储数据的载体,可以但不限于包括软盘、光盘、硬盘、闪存、优盘和/或记忆棒(memory stick)等,所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。
[0118]
本实施例提供的存储介质的工作过程、工作细节和技术效果,可以参见实施例第一方面,于此不再赘述。
[0119]
本实施例第六方面提供了一种包含指令的计算机程序产品,当所述指令在计算机上运行时,使所述计算机执行如实施例第一方面所述的用于车牌识别的车牌定位方法,其中,所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。
[0120]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。