基于yolov3改进的复杂环境下的行人检测方法及装置
技术领域
1.本公开属于人工智能技术领域,具体涉及一种基于yolov3改进的复杂环境下的行人检测方法及装置。
背景技术:
2.近年来,计算机视觉技术在深度学习的支持下取得了飞速的发展,吸引了众多研究者投身其中,成千上万的科研人员尽管关注的焦点各不相同,但是最终的目标是一样的:让技术为人服务,或者说解放生产力,因此与人相关的研究就显得必不可缺。
3.行人检测在智能监控和安防领域发挥着重大作用,为了防止财产安全和安放部署等,大部分公众场所都装备了监控设备。但是,尽管如此,监控设备中出现的大量行人数据时,仅仅依据专人的查看,会导致以下问题的出现,一方面长时间的监控信息,人与计算机相比,肯定会出现疲惫而导致的信息错误或者遗漏,另一方面有限的处理信息的能力,不能充分将监控信息充分利用。然而人工处理问题的不足,可以通过行人检测的相关技术很好的弥补,既节省了人力也可在遇到紧急状况时及时做出预警。
4.行人检测技术同时也是无人驾驶领域所要攻克完善的一个重要难题。从无人驾驶技术开始发展,行人检测就一直作为一个亟待解决和完善的问题困扰着众多的研究者。尽管2005年以来行人检测进入了一个快速的发展阶段,但是依旧存在着许多问题有待解决,主要还是两方面,即速度与准确性还不能达到一个权衡。近年来,以谷歌为首的自动驾驶技术研发,正如火如荼地进行着,这也迫切需要能对行人进行有效的快速的检测方法的出现,以保证自动驾驶期间对行人的安全不会产生威胁。因此,行人检测问题的解决能从根本上优化现有的无人驾驶技术。在复杂场景下,行人存在相互遮挡,尺寸不一现象,会导致大量的漏检。
技术实现要素:
5.本公开旨在至少解决现有技术中存在的技术问题之一,提供一种基于yolov3改进的复杂环境下的行人检测方法及装置。
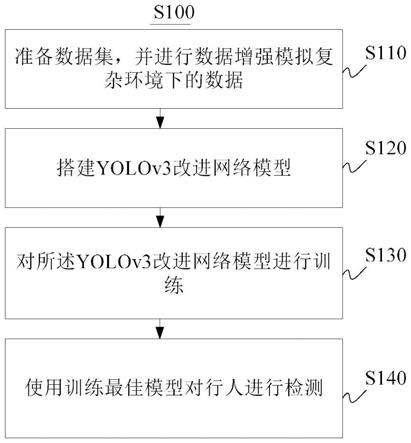
6.本公开的一方面,提供一种基于yolov3改进的复杂环境下的行人检测方法,所述方法包括:
7.准备数据集,并进行数据增强模拟复杂环境下的数据;
8.搭建yolov3改进网络模型;
9.对所述yolov3改进网络模型进行训练;
10.使用训练最佳模型对行人进行检测。
11.在一些实施方式中,所述准备数据集,并进行数据增强模拟复杂环境下的数据,包括:
12.准备yolo网络所需图像和标签数据,得到训练集;
13.对所述训练集进行数据增强,具体包括:
14.选择mixup数据增强,将所述训练集中随机两张图片进行数据混合,利用线性插值将两张图片按照不同的权重混合生成新图像,新样本的标签由原来标签混合而来。
15.在一些实施方式中,所述新图像满足下述关系式:
16.(xn,yn)=λ(xi,yi) (1-λ)(xj,yj)
17.式中,(xn,yn)为新图像,λ∈[0,1],其取值符合beta分布β(α,α),参数α满足α∈(0,∞);(xi,yi)和(xj,yj)是从需要增广数据中随机抽取的两个样本。
[0018]
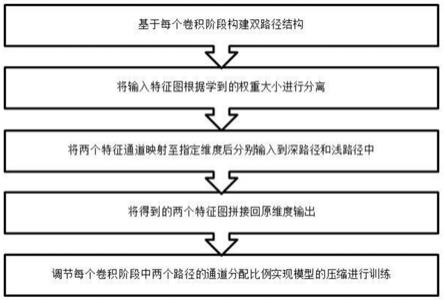
在一些实施方式中,所述搭建yolov3改进网络模型,包括:
[0019]
对yolov3主干进行改进,将darknet53替换为efficientnet-b0;
[0020]
对efficientnet网络进行了优化,将efficientnet中用于分类部分的最后一个卷积模块和池化部分去掉,分别输出经过主干网络5次,4次,3次下采样后的部分,将原来的多尺度输入修改为608输入尺寸用来检测复杂情况下的行人检测;
[0021]
在检测头部分加入空间池化金字塔模块,并采用三种不同的池化核对输出特征图分别进行池化,将池化后的三个特征图和原始输入进行通道合并,其中最大池化核的尺寸分别为5*5,9*9,13*13,对输入填充的大小padding为:
[0022]
padding=(kernel
size-1)/2
[0023]
使用diou算法作为边界损失函数,其中diou的计算公式如下:
[0024]
diou=iou-(ρ2(b,b
gt
))/c2[0025]
l
diou
=1-diou
[0026]
式中:b,b
gt
分别代表了预测框和真实框的中心点,且ρ代表的是计算两个中心点间的欧式距离;c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离,l
diou
则作为边界框损失函数;
[0027]
soft-nms的计算公式如下:
[0028][0029]
式中,m为当前得分最高框,bi为待处理框,当bi和m的重叠度超过重叠阈值n
t
时,检测框的检测分数呈线性衰减,与m相邻很近的检测框衰减程度很大,而远离m的检测框并不受影响;
[0030]
使用k-means 算法来进行聚类,随机选中第一个聚类中心,之后通过选取远离这个聚类中心的点作为一个新的聚类中心,依次类推,选取出多个框作为模型的anchor值,通过上述方法,k-means 能够有效的加速模型收敛。
[0031]
在一些实施方式中,所述对所述yolov3改进网络模型进行训练,包括:
[0032]
图片输入尺寸设置为608大小,初始学习率设置为1e-3,将处理好的训练数据集分批次输入到网络中进行正向传播并不断计算损失,通过损失函数来进行反向传播更新网络中的各种参数,经过多次迭代后损失值会趋于稳定,将此时的网络参数保存为模型。
[0033]
本公开的另一方面,提供一种基于yolov3改进的复杂环境下的行人检测装置,所述装置包括:
[0034]
采集模块,用于准备数据集,并进行数据增强模拟复杂环境下的数据;
[0035]
搭建模块,用于搭建yolov3改进网络模型;
[0036]
训练模块,用于对所述yolov3改进网络模型进行训练;
[0037]
检测模块,用于使用训练最佳模型对行人进行检测。
[0038]
在一些实施方式中,所述采集模块,具体用于:
[0039]
准备yolo网络所需图像和标签数据,得到训练集;
[0040]
对所述训练集进行数据增强,具体包括:
[0041]
选择mixup数据增强,将所述训练集中随机两张图片进行数据混合,利用线性插值将两张图片按照不同的权重混合生成新图像,新样本的标签由原来标签混合而来。
[0042]
在一些实施方式中,所述新图像满足下述关系式:
[0043]
(xn,yn)=λ(xi,yi) (1-λ)(xj,yj)
[0044]
式中,(xn,yn)为新图像,λ∈[0,1],其取值符合beta分布β(α,α),参数α满足α∈(0,∞);(xi,yi)和(xj,yj)是从需要增广数据中随机抽取的两个样本。
[0045]
在一些实施方式中,所述搭建模块,具体用于:
[0046]
对yolov3主干进行改进,将darknet53替换为efficientnet-b0;
[0047]
对efficientnet网络进行了优化,将efficientnet中用于分类部分的最后一个卷积模块和池化部分去掉,分别输出经过主干网络5次,4次,3次下采样后的部分,将原来的多尺度输入修改为608输入尺寸用来检测复杂情况下的行人检测;
[0048]
在检测头部分加入空间池化金字塔模块,并采用三种不同的池化核对输出特征图分别进行池化,将池化后的三个特征图和原始输入进行通道合并,其中最大池化核的尺寸分别为5*5,9*9,13*13,对输入填充的大小padding为:
[0049]
padding=(kernel
size-1)/2
[0050]
使用diou算法作为边界损失函数,其中diou的计算公式如下:
[0051]
diou=iou-(ρ2(b,b
gt
))/c2[0052]
l
diou
=1-diou
[0053]
式中:b,b
gt
分别代表了预测框和真实框的中心点,且ρ代表的是计算两个中心点间的欧式距离;c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离,l
diou
则作为边界框损失函数;
[0054]
soft-nms的计算公式如下:
[0055][0056]
式中,m为当前得分最高框,bi为待处理框,当bi和m的重叠度超过重叠阈值n
t
时,检测框的检测分数呈线性衰减,与m相邻很近的检测框衰减程度很大,而远离m的检测框并不受影响;
[0057]
使用k-means 算法来进行聚类,随机选中第一个聚类中心,之后通过选取远离这个聚类中心的点作为一个新的聚类中心,依次类推,选取出多个框作为模型的anchor值,通过上述方法,k-means 能够有效的加速模型收敛。
[0058]
在一些实施方式中,所述训练模块,具体用于:
[0059]
图片输入尺寸设置为608大小,初始学习率设置为1e-3,将处理好的训练数据集分批次输入到网络中进行正向传播并不断计算损失,通过损失函数来进行反向传播更新网络中的各种参数,经过多次迭代后损失值会趋于稳定,将此时的网络参数保存为模型。
[0060]
本公开的基于yolov3改进的复杂环境下的行人检测方法及装置,对yolov3的主干
网络进行了改进,同时在输出特征层方面进行了改进,实现了高分辨图像下对行人的检测,提高了算法识别精度,解决了在复杂环境下行人互相遮挡,尺寸不一导致大量目标漏检的问题。
附图说明
[0061]
图1为本公开一实施例的基于yolov3改进的复杂环境下的行人检测方法的流程图;
[0062]
图2为本公开另一实施例的yolo改进网络的总体框架图;
[0063]
图3a为本公开另一实施例的efficientnet-b0网络结构图;
[0064]
图3b为本公开另一实施例的block模块图;
[0065]
图4为本公开另一实施例的空间池化金字塔模块结构图;
[0066]
图5为本公开另一实施例的基于yolov3改进的复杂环境下的行人检测装置的结构示意图。
具体实施方式
[0067]
为使本领域技术人员更好地理解本公开的技术方案,下面结合附图和具体实施方式对本公开作进一步详细描述。
[0068]
本实施例的一方面,如图1所示,涉及一种基于yolov3改进的复杂环境下的行人检测方法s100,所述方法s100包括:
[0069]
s110、准备数据集,并进行数据增强模拟复杂环境下的数据。
[0070]
具体地,在本步骤中,准备yolo网络所需图像和标签数据,得到训练集。例如,挑选出kitti数据集中存在行人目标的照片共1223张,并将图片统一调整到1024*1024尺寸,对kitti数据集其他类别剔除,仅留下单一行人类别进行行人检测。本实施例将其中80%作为训练集,20%作为测试集。
[0071]
对所述训练集进行数据增强,具体包括:
[0072]
选择mixup数据增强,将所述训练集中随机两张图片进行数据混合,利用线性插值将两张图片按照不同的权重混合生成新图像,新样本的标签由原来标签混合而来,这样可能更好的模拟复杂情况下对行人的检测,提高模型的鲁棒性。其中,
[0073]
所述新图像满足下述关系式:
[0074]
(xn,yn)=λ(xi,yi) (1-λ)(xj,yj)
[0075]
式中,(xn,yn)为新图像,λ∈[0,1],其取值符合beta分布β(α,α),参数α满足α∈(0,∞);(xi,yi)和(xj,yj)是从需要增广数据中随机抽取的两个样本。
[0076]
s120、搭建yolov3改进网络模型。
[0077]
具体地,在本步骤中,如图2所示,即为yolo改进网络的总体框架图。首先,对yolov3主干进行改进,将darknet53替换为efficientnet-b0,其网络结构如图3a所示,图3b为block模块。同时,对efficientnet网络进行了优化,将efficientnet中用于分类部分的最后一个卷积模块和池化部分去掉,分别输出经过主干网络5次,4次,3次下采样后的部分,将原来的多尺度输入修改为608输入尺寸用来检测复杂情况下的行人检测。
[0078]
在检测头部分加入空间池化金字塔模块,其结构如图4所示,并采用三种不同的池
化核对输出特征图分别进行池化,将池化后的三个特征图和原始输入进行通道合并,其中最大池化核的尺寸分别为5*5,9*9,13*13,对输入填充的大小padding为:
[0079]
padding=(kernel
size-1)/2
[0080]
使用diou算法作为边界损失函数,其中diou的计算公式如下:
[0081]
diou=iou-(ρ2(b,b
gt
))/c2[0082]
l
diou
=1-diou
[0083]
式中:b,b
gt
分别代表了预测框和真实框的中心点,且ρ代表的是计算两个中心点间的欧式距离;c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离,l
diou
则作为边界框损失函数;
[0084]
soft-nms的计算公式如下:
[0085][0086]
式中,m为当前得分最高框,bi为待处理框,当bi和m的重叠度超过重叠阈值n
t
时,检测框的检测分数呈线性衰减,与m相邻很近的检测框衰减程度很大,而远离m的检测框并不受影响;
[0087]
使用k-means 算法替代yolov3原文中使用的k-means算法来进行聚类。k-means算法是在一次随机选中k个点作为聚类中心,结果会受到初始点选取的影响。而k-means 算法是随机选中第一个聚类中心,之后通过选取远离这个聚类中心的点作为一个新的聚类中心,依次类推,选取出多个框作为模型的anchor值,通过上述方法,k-means 能够有效的加速模型收敛。
[0088]
s130、对所述yolov3改进网络模型进行训练。
[0089]
具体地,在本步骤中,图片输入尺寸设置为608大小,初始学习率设置为1e-3,将处理好的训练数据集分批次输入到网络中进行正向传播并不断计算损失,通过损失函数来进行反向传播更新网络中的各种参数,经过多次迭代后损失值会趋于稳定,将此时的网络参数保存为模型。
[0090]
s140、使用训练最佳模型对行人进行检测。
[0091]
本实施例的基于yolov3改进的复杂环境下的行人检测方法,对yolov3的主干网络进行了改进,同时在输出特征层方面进行了改进,实现了高分辨图像下对行人的检测,提高了算法识别精度,解决了在复杂环境下行人互相遮挡,尺寸不一导致大量目标漏检的问题。
[0092]
本公开的另一方面,如图5所示,提供一种基于yolov3改进的复杂环境下的行人检测装置100,该装置100可以适用于前文记载的方法,所述装置100包括:
[0093]
采集模块110,用于准备数据集,并进行数据增强模拟复杂环境下的数据;
[0094]
搭建模块120,用于搭建yolov3改进网络模型;
[0095]
训练模块130,用于对所述yolov3改进网络模型进行训练;
[0096]
检测模块140,用于使用训练最佳模型对行人进行检测。
[0097]
本实施例的基于yolov3改进的复杂环境下的行人检测装置,对yolov3的主干网络进行了改进,同时在输出特征层方面进行了改进,实现了高分辨图像下对行人的检测,提高了算法识别精度,解决了在复杂环境下行人互相遮挡,尺寸不一导致大量目标漏检的问题。
[0098]
在一些实施方式中,所述采集模块110,具体用于:
[0099]
准备yolo网络所需图像和标签数据,得到训练集;
[0100]
对所述训练集进行数据增强,具体包括:
[0101]
选择mixup数据增强,将所述训练集中随机两张图片进行数据混合,利用线性插值将两张图片按照不同的权重混合生成新图像,新样本的标签由原来标签混合而来。
[0102]
在一些实施方式中,所述新图像满足下述关系式:
[0103]
(xn,yn)=λ(xi,yi) (1-λ)(xj,yj)
[0104]
式中,(xn,yn)为新图像,λ∈[0,1],其取值符合beta分布β(α,α),参数α满足α∈(0,∞);(xi,yi)和(xj,yj)是从需要增广数据中随机抽取的两个样本。
[0105]
在一些实施方式中,所述搭建模块120,具体用于:
[0106]
对yolov3主干进行改进,将darknet53替换为efficientnet-b0;
[0107]
对efficientnet网络进行了优化,将efficientnet中用于分类部分的最后一个卷积模块和池化部分去掉,分别输出经过主干网络5次,4次,3次下采样后的部分,将原来的多尺度输入修改为608输入尺寸用来检测复杂情况下的行人检测;
[0108]
在检测头部分加入空间池化金字塔模块,并采用三种不同的池化核对输出特征图分别进行池化,将池化后的三个特征图和原始输入进行通道合并,其中最大池化核的尺寸分别为5*5,9*9,13*13,对输入填充的大小padding为:
[0109]
padding=(kernel
size-1)/2
[0110]
使用diou算法作为边界损失函数,其中diou的计算公式如下:
[0111]
diou=iou-(ρ2(b,b
gt
))/c2[0112]
l
diou
=1-diou
[0113]
式中:b,b
gt
分别代表了预测框和真实框的中心点,且ρ代表的是计算两个中心点间的欧式距离;c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离,l
diou
则作为边界框损失函数;
[0114]
soft-nms的计算公式如下:
[0115][0116]
式中,m为当前得分最高框,bi为待处理框,当bi和m的重叠度超过重叠阈值n
t
时,检测框的检测分数呈线性衰减,与m相邻很近的检测框衰减程度很大,而远离m的检测框并不受影响;
[0117]
使用k-means 算法来进行聚类,随机选中第一个聚类中心,之后通过选取远离这个聚类中心的点作为一个新的聚类中心,依次类推,选取出多个框作为模型的anchor值,通过上述方法,k-means 能够有效的加速模型收敛。
[0118]
在一些实施方式中,所述训练模块130,具体用于:
[0119]
图片输入尺寸设置为608大小,初始学习率设置为1e-3,将处理好的训练数据集分批次输入到网络中进行正向传播并不断计算损失,通过损失函数来进行反向传播更新网络中的各种参数,经过多次迭代后损失值会趋于稳定,将此时的网络参数保存为模型。
[0120]
可以理解的是,以上实施方式仅仅是为了说明本公开的原理而采用的示例性实施方式,然而本公开并不局限于此。对于本领域内的普通技术人员而言,在不脱离本公开的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本公开的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。