技术特征:
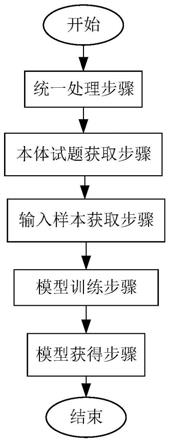
1.一种知识点自动标注建模方法,其特征在于,包括以下步骤:(1)统一处理步骤:对初始试题集中的所有知识点加以知识点标签,所有的知识点标签组成知识点集;所述初始试题集由小学几何试题组成;对于初始试题集中的每个试题,将其包含的所有的知识点标签进行全排列,对每一种知识点标签排列方式生成其对应的有序集合,所有的有序集合组成该试题的标签组集合;所有试题的标签组集合组成标签组总集;(2)本体试题获取步骤:对所述初始试题集中的每个试题,根据匹配模板,获得其对应的本体试题;所有试题的本体试题组成本体试题集;所述匹配模板由本体库中的所有本体及其对应的正则表达式和本体标识符组成;(3)输入样本获取步骤:根据所述本体试题集和所述标签组总集,获得统一预训练语言模型的输入样本;(4)模型训练步骤:将所述输入样本输入到统一预训练语言模型中,并按设定的轮数epoch和批输入量batch_size进行训练;每一轮训练结束之后得到一个该轮训练的标注模型;(5)模型获得步骤:根据所有的所述标注模型,获得知识点自动标注模型。2.如权利要求1所述的知识点自动标注建模方法,其特征在于,所述本体试题获取步骤包括以下子步骤:(1)实体识别子步骤:对所述初始试题集中每个试题的每个实体,在所述匹配模板中查找与该实体相匹配的正则表达式,匹配成功的正则表达式对应的本体为该实体对应的本体;对所有的实体进行编号操作,所述编号操作的目的是使得下述同一试题的不同实体的本体标识互不相同;(2)本体替换子步骤:根据两个实体中出现的重复字符,来确定其对应的两个本体之间的属性关系;将每个实体替换为对应的本体的本体标识,核心本体的本体标识由本体标识符和对应的实体的编号组成;属性本体的本体标识依次由其所属的核心本体的本体标识符、该属性本体的本体标识符和该属性本体对应的实体的编号组成。3.如权利要求1所述的知识点自动标注建模方法,其特征在于,所述输入样本获取步骤包括以下子步骤:(1)数据集划分子步骤:将所述本体试题集按设定的比例划分为训练集和测试集;在所述标签组总集中查找所述训练集中的每个本体试题对应的标签组集合,并将查找到的标签组集合加入到所述训练集中;在所述标签组总集中查找所述测试集中的每个本体试题对应的标签组集合,并将查找到的标签组集合加入到所述测试集中;(2)分词子步骤:
使用python分词工具对所述训练集中的所有的本体试题进行分词,得到一个分词词典;(3)短文本替换子步骤:在python分词工具自带的词典中查找得到不属于所述分词词典的多个互不相同的词,组成短文本集,所述短文本集与知识点集里的元素总数相等;建立从所述短文本集到所述知识点集的短文本映射:将所述短文本集中的所有元素随机映射到所述知识点集里的所有元素;所述短文本映射为满映射;以所述训练集中的每个标签组集合为原像集,根据所述短文本映射,得到一个子映射,并将其像集中的每个像依次用至少一个连接符连接起来,形成一个标签集合文本;(4)拼接子步骤:对所述训练集中的每个本体试题,依次将该本体试题和其对应的所有标签集合文本进行头尾拼接得到单个样本;在拼接时需要在本体试题的头部增加头部标记,在本体试题的尾部增加尾部标记,在标签集合文本的尾部增加尾部标记;所述训练集的所有样本组成所述输入样本。4.如权利要求1所述的知识点自动标注建模方法,其特征在于,所述模型训练步骤的具体过程为:将所述输入样本输入到统一预训练语言模型中按设定的轮数epoch和批输入量batch_size进行训练;在每一轮训练中,使用bert预训练模型和seq-to-seq掩码方式进行微调训练,并使用优化器adam不断更新统一预训练语言模型的超参数直到交叉熵损失趋于稳定值,此时得到该轮训练的标注模型。5.如权利要求1所述的知识点自动标注建模方法,其特征在于,所述模型获得步骤的具体过程为:将所述测试集依次输入所有的所述标注模型,统计每个标注模型输出的试题预测知识点标签与数学试题真实知识点标签,并以此计算每个标注模型的汉明损失,选取汉明损失的值最小的标注模型作为知识点自动标注模型。6.一种知识点自动标注建模系统,其特征在于,包括:统一处理模块:用于对初始试题集中的所有知识点加以知识点标签,所有的知识点标签组成知识点集;所述初始试题集由小学几何试题组成;对于初始试题集中的每个试题,将其包含的所有的知识点标签进行全排列,对每一种知识点标签排列方式生成其对应的有序集合,所有的有序集合组成该试题的标签组集合;所有试题的标签组集合组成标签组总集;本体试题获取模块:用于对所述初始试题集中的每个试题,根据匹配模板,获得其对应的本体试题;所有试题的本体试题组成本体试题集;所述匹配模板由本体库中的所有本体及其对应的正则表达式和本体标识符组成;输入样本获取模块:用于根据所述本体试题集和所述标签组总集,获得统一预训练语言模型的输入样本;模型训练模块:
用于将所述输入样本输入到统一预训练语言模型中,并按设定的轮数epoch和批输入量batch_size进行训练;每一轮训练结束之后得到一个该轮训练的标注模型;模型获得模块:用于根据所有的所述标注模型,获得知识点自动标注模型。7.如权利要求5所述的知识点自动标注建模系统,其特征在于,所述本体试题获取模块包括以下子模块:实体识别子模块:用于对所述初始试题集中每个试题的每个实体,在所述匹配模板中查找与该实体相匹配的正则表达式,匹配成功的正则表达式对应的本体为该实体对应的本体;对所有的实体进行编号操作,所述编号操作的目的是使得下述同一试题的不同实体的本体标识互不相同;本体替换子模块:用于根据两个实体中出现的重复字符,来确定其对应的两个本体之间的属性关系;将每个实体替换为对应的本体的本体标识,核心本体的本体标识由本体标识符和对应的实体的编号组成;属性本体的本体标识依次由其所属的核心本体的本体标识符、该属性本体的本体标识符和该属性本体对应的实体的编号组成;所述输入样本获取模块包括以下子模块:数据集划分子模块:将所述本体试题集按设定的比例划分为训练集和测试集;在所述标签组总集中查找所述训练集中的每个本体试题对应的标签组集合,并将查找到的标签组集合加入到所述训练集中;在所述标签组总集中查找所述测试集中的每个本体试题对应的标签组集合,并将查找到的标签组集合加入到所述测试集中;分词子模块:使用python分词工具对所述训练集中的所有的本体试题进行分词,得到一个分词词典;短文本替换子模块:在python分词工具自带的词典中查找得到不属于所述分词词典的多个互不相同的词,组成短文本集,所述短文本集与知识点集里的元素总数相等;建立从所述短文本集到所述知识点集的短文本映射:将所述短文本集中的所有元素随机映射到所述知识点集里的所有元素;所述短文本映射为满映射;以所述训练集中的每个标签组集合为原像集,根据所述短文本映射,得到一个子映射,并将其像集中的每个像依次用至少一个连接符连接起来,形成一个标签集合文本;拼接子模块:对所述训练集中的每个本体试题,依次将该本体试题和其对应的所有标签集合文本进行头尾拼接得到单个样本;在拼接时需要在本体试题的头部增加头部标记,在本体试题的尾部增加尾部标记,在标签集合文本的尾部增加尾部标记;所述训练集的所有样本组成所述输入样本。8.如权利要求5所述的知识点自动标注建模系统,其特征在于,
所述模型训练模块包含的具体操作为:将所述输入样本输入到统一预训练语言模型中按设定的轮数epoch和批输入量batch_size进行训练;在每一轮训练中,使用bert预训练模型和seq-to-seq掩码方式进行微调训练,并使用优化器adam不断更新统一预训练语言模型的超参数直到交叉熵损失趋于稳定值,此时得到该轮训练的标注模型;所述模型获得模块包含的具体操作为:将所述测试集依次输入所有的所述标注模型,统计每个标注模型输出的试题预测知识点标签与数学试题真实知识点标签,并以此计算每个标注模型的汉明损失,选取汉明损失的值最小的标注模型作为知识点自动标注模型。9.一种知识点自动标注建模装置,其特征在于,包括存储器和处理器;所述存储器,用于存储计算机程序;所述处理器,用于当执行所述计算机程序时,实现如权利要求1-4任一项所述的知识点自动标注建模方法。10.一种计算机可读存储介质,其特征在于,所述存储介质上存储有计算机程序,当所述计算机程序被处理器执行时,实现如权利要求1-4任一项所述的知识点自动标注建模方法。
技术总结
本发明公开了一种知识点自动标注建模方法及系统,其中,标注方法包括统一处理步骤、本体试题获取步骤、输入样本获取步骤、模型训练步骤和模型获得步骤。本发明对统一预训练语言模型UniLM进行训练得到知识点自动标注模型,该模型在提取丰富的数学试题文本语义信息的前提下,能够考虑到标签之间的关联关系,高效的完成小学几何试题知识点的预测,提高了知识点自动标注的可信度;本发明提出基于匹配模板的实体识别和本体替换方法,以缓解小学几何试题文本在模型训练中的数据稀疏问题;本发明对于试题中包含的所有的知识点标签进行了全排列处理,以避免知识点标签生成顺序的不一致造成训练过程中的错误反馈。成训练过程中的错误反馈。成训练过程中的错误反馈。
技术研发人员:刘三女牙 黄涛 胡盛泽 林柯柯 杨华利 王胜明 杨宗凯
受保护的技术使用者:华中师范大学
技术研发日:2021.11.05
技术公布日:2022/3/7
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。