1.本发明涉及人工智能的文本处理技术领域,具体来说,涉及一种行业知识图谱的多源构建方法。
背景技术:
2.行业知识图谱中蕴涵着海量结构信息,因常用于分析应用或决策支持,通常对准确度要求较高。大规模知识图谱的构建包括两种方式,分别是与数据库与网络百科同步。第一种方法是运用存储知识图谱的特定结构,下载大量的数据,由人工整合后采用子图融合的方式进行构建。这种方式人为工作量大,耗费大量的计算机资源,并且在构建过程中保证不了数据的安全。第二种方法是采用网络爬虫,对相关类似信息进行数据采集和信息提取,这样做的问题在于大量的网页处理导致碎片化信息过多,并且大多数网站具有封锁爬虫的性能使得数据不完整。而对于多源知识图谱,来源于行业文本、开放链数据集和知识库、百科中的知识有着不同的特征,已有构建方式难以对不同来源的知识区别提取和融合。
技术实现要素:
3.针对相关技术中的上述技术问题,本发明提出一种行业知识图谱的多源构建方法,能够克服现有技术的上述不足。
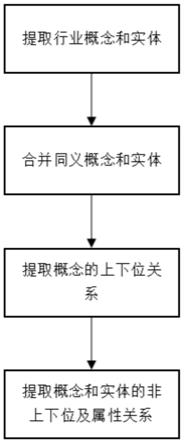
4.为实现上述技术目的,本发明的技术方案是这样实现的:一种行业知识图谱的多源构建方法,包括以下步骤:s1针对开放知识库、在线百科、行业文本、行业结构数据四类知识来源,提取行业概念和实体;s2合并同义概念和实体;s3提取概念的上下位关系;s4提取概念和实体的非上下位及属性关系。
5.进一步的,所述s1包括以下步骤:s11搜集已有开放链接数据集和开放知识库中行业核心概念和实体,所述开放链接数据集和开放知识库包括dbpedia、yago、zhishi.me三种;s12搜集维基百科、百度百科、互动百科中分类系统的类别标签作为概念,百科文章的标题作为实体的候选,并将在线百科中对应的简介文本作为概念或实体的摘要;s13对行业文本语料采用词频统计、rake、textrank、tf-idf方法找出关键词集合,通过行业专家辅助从中初步筛选出行业核心概念;s14对行业结构数据,通过d2r server工具,将关系数据库中的相关表和表中的列分别映射为概念的实体和实体的属性;s15对上述s11-s14中四个途径获取的行业概念和实体进行整合。
6.进一步的,所述s2包括以下步骤:s21开放链接数据中的同义关系明确,dbpedia中使用『owl:sameas』标识同义实
体,yago中使用『means』标识同义实体,zhishi.me中使用『pageredirects』标识同义实体的重定向页面;s22在线百科方面,将同一在线百科中学习到的概念进行合并,遍历百科中的实体页面,把具有同一重定向标记的页面标题标识为同一实体,将实体页面信息中『别称』、『中文别称』字段对应的值标识为同一实体;判断不同在线百科同名实体之间是否同义:对于不同在线百科中的页面文章,标题相同时,文章内容相似度超过80%的文章标识为同一实体或概念对应的页面,文章标题对应的实体或概念标记为同义;s23抽取行业文本同义关系:行业文本方面,首先,定义『x又名y』、『x又叫y』、『x又称y』、『x也名y』、『x也叫y』、『x也称y』、『x亦称y』、『x也叫做y』、『x也叫作y』、『x也称为y』、『x又称为y』、『x简称y』、『x俗称y』、『x原名y』、『x是y的同义词』、『x是y的近义词』、『x古称y』、『x是y的简称』、『x的同义词是y』、『x(y)』、『x又被叫作y』、『x又被称作y』、『x又被称为y』、『x也被叫作y』、『x也被称作y』『x也被称为y』为描述同义关系的句式规则,根据这些规则在行业文本中进行匹配,抽取实体或概念间的同义关系,然后,通过nlp工具对文本进行分词和词性标注,根据已经提取的同义关系得到训练数据,用bilstm-crf算法进行建模,抽取其中的同义关系;s24将上述s21-s23中三个途径得到的同义关系进行合并,不同途径得到的同义关系中有相同概念或实体,则合并两个同义关系。
7.进一步的,所述s22中文章内容相似度是通过无监督学习方法得到,由word2vec算法得到所有词的向量表示,对于任意一篇文章,以文本每个词的tf-idf为权重,对文章中所有词的词向量加权平均,作为文章的向量,再将向量间的余弦相似度作为文章相似度。
8.进一步的,所述s3包括以下步骤:s31从开放链接数据集和开放知识库中根据对应规则提取行业核心概念间的上下位关系;s32从百科分类体系中直接获取核心概念间的上下位关系;s33抽取行业文本上下位关系:对于行业文本,首先,定义『x是一种y』、『x是一个y』、『x是一类y』、『x如y、z等』、『x包括y、z等』、『x有y、z等』、『x指y、z等』、『x(y、z)』为描述上下位关系的句式规则,根据这些模式在行业文本中进行匹配,抽取实体或概念间的上下位关系,然后,通过nlp工具对文本进行分词和词性标注,根据已经提取的上下位关系得到训练数据,用bilstm-crf算法进行建模,抽取其中的上下位关系三元组;s34对上述s31-s33中三个途径获取的上下位关系进行整合,构造分类树。
9.进一步的,所述s4包括以下步骤:s41从开放链数据的信息模块中可直接提取概念的属性关系;s42编写适配器,从在线百科的信息模块中通过页面解析抽取概念的实体属性关系,对概念所属实体的属性进行统计,一个概念对应实体拥有某属性的数量占比超过30%,则认为该属性较为常见,成为概念的属性;s43抽取行业文本非上下位关系:行业文本方面,首先,在行业专家的辅助下定义描述非上下位关系的常见句式规则,根据这些规则在行业文本中进行匹配,抽取实体或概念间的非上下位关系,然后,通过nlp工具对文本进行分词和词性标注,根据已经提取的非
上下位关系得到训练数据,用bilstm-crf算法进行建模,抽取其中的非上下位关系;s44最终将上述s41-s43中三个途径得到的非上下位关系进行合并。
10.本发明的有益效果:本发明的行业知识图谱的多源构建方法能够解决现有构建方法人为工作量大、耗费大量的计算机资源、碎片化信息过多、数据不完整、难以对不同来源的知识区别提取和融合的问题,从而达到根据数据来源不同,采用针对性的策略构建目标本体、抽取实体和属性,兼顾了不同来源知识的特点,结合机器学习方法对知识图谱进行半自动构建,在确保准确的同时大大减少了大规模知识图谱构建所耗费的人力的目的。
附图说明
11.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
12.图1是根据本发明实施例所述的行业知识图谱的多源构建方法的流程图;图2是根据本发明实施例所述的行业知识图谱的多源构建方法的判断不同在线百科同名实体之间是否同义的流程图;图3是根据本发明实施例所述的行业知识图谱的多源构建方法的抽取行业文本同义、上下位、非上下位关系的流程图。
具体实施方式
13.下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
14.如图1-3所示,根据本发明实施例所述的行业知识图谱的多源构建方法,包括以下步骤:s1针对开放知识库、在线百科、行业文本、行业结构数据四类知识来源,提取行业概念和实体;s2合并同义概念和实体;s3提取概念的上下位关系;s4提取概念和实体的非上下位及属性关系。
15.以上所述s1包括以下步骤:s11搜集已有开放链接数据集和开放知识库中行业核心概念和实体,所述开放链接数据集和开放知识库包括dbpedia、yago、zhishi.me三种;s12搜集维基百科、百度百科、互动百科中分类系统的类别标签作为概念,百科文章的标题作为实体的候选,并将在线百科中对应的简介文本作为概念或实体的摘要;s13对行业文本语料采用词频统计、rake、textrank、tf-idf方法找出关键词集合,通过行业专家辅助从中初步筛选出行业核心概念;s14对行业结构数据,通过d2r server工具,将关系数据库中的相关表和表中的列分别映射为概念的实体和实体的属性;
s15对上述s11-s14中四个途径获取的行业概念和实体进行整合。
16.以上所述s2包括以下步骤:s21开放链接数据中的同义关系明确,dbpedia中使用『owl:sameas』标识同义实体,yago中使用『means』标识同义实体,zhishi.me中使用『pageredirects』标识同义实体的重定向页面;s22在线百科方面,将同一在线百科中学习到的概念进行合并,遍历百科中的实体页面,把具有同一重定向标记的页面标题标识为同一实体,将实体页面信息中『别称』、『中文别称』字段对应的值标识为同一实体;判断不同在线百科同名实体之间是否同义:对于不同在线百科中的页面文章,标题相同时,文章内容相似度超过80%的文章标识为同一实体或概念对应的页面,文章标题对应的实体或概念标记为同义;s23抽取行业文本同义关系:行业文本方面,首先,定义『x又名y』、『x又叫y』、『x又称y』、『x也名y』、『x也叫y』、『x也称y』、『x亦称y』、『x也叫做y』、『x也叫作y』、『x也称为y』、『x又称为y』、『x简称y』、『x俗称y』、『x原名y』、『x是y的同义词』、『x是y的近义词』、『x古称y』、『x是y的简称』、『x的同义词是y』、『x(y)』、『x又被叫作y』、『x又被称作y』、『x又被称为y』、『x也被叫作y』、『x也被称作y』『x也被称为y』为描述同义关系的句式规则,根据这些规则在行业文本中进行匹配,抽取实体或概念间的同义关系,然后,通过nlp工具对文本进行分词和词性标注,根据已经提取的同义关系得到训练数据,用bilstm-crf算法进行建模,抽取其中的同义关系;s24将上述s21-s23中三个途径得到的同义关系进行合并,不同途径得到的同义关系中有相同概念或实体,则合并两个同义关系,如在百科中得到同义关系『计算机、电子计算机』,在行业文本中得到同义关系『计算机、电脑』,合并后的同义关系为『计算机、电子计算机、电脑』。
17.以上所述s22中文章内容相似度是通过无监督学习方法得到,由word2vec算法得到所有词的向量表示,对于任意一篇文章,以文本每个词的tf-idf为权重,对文章中所有词的词向量加权平均,作为文章的向量,再将向量间的余弦相似度作为文章相似度。
18.以上所述s3包括以下步骤:s31从开放链接数据集和开放知识库中根据对应规则提取行业核心概念间的上下位关系;s32从百科分类体系中直接获取核心概念间的上下位关系;s33抽取行业文本上下位关系:对于行业文本,首先,定义『x是一种y』、『x是一个y』、『x是一类y』、『x如y、z等』、『x包括y、z等』、『x有y、z等』、『x指y、z等』、『x(y、z)』为描述上下位关系的句式规则,根据这些模式在行业文本中进行匹配,抽取实体或概念间的上下位关系,然后,通过nlp工具对文本进行分词和词性标注,根据已经提取的上下位关系得到训练数据,用bilstm-crf算法进行建模,抽取其中的上下位关系三元组;s34对上述s31-s33中三个途径获取的上下位关系进行整合,构造分类树。
19.以上所述s4包括以下步骤:s41从开放链数据的信息模块中可直接提取概念的属性关系;s42编写适配器,从在线百科的信息模块中通过页面解析抽取概念的实体属性关
系,对概念所属实体的属性进行统计,一个概念对应实体拥有某属性的数量占比超过30%,则认为该属性较为常见,成为概念的属性;s43抽取行业文本非上下位关系:行业文本方面,首先,在行业专家的辅助下定义描述非上下位关系的常见句式规则,根据这些规则在行业文本中进行匹配,抽取实体或概念间的非上下位关系,然后,通过nlp工具对文本进行分词和词性标注,根据已经提取的非上下位关系得到训练数据,用bilstm-crf算法进行建模,抽取其中的非上下位关系;s44最终将上述s41-s43中三个途径得到的非上下位关系进行合并。
20.为了方便理解本发明的上述技术方案,以下通过具体使用方式上对本发明的上述技术方案进行详细说明。
21.在具体使用时,先针对开放知识库、在线百科、行业文本、行业结构数据四类知识来源,提取行业概念和实体,接着合并同义概念和实体,然后提取概念的上下位关系,最后提取概念和实体的非上下位及属性关系。
22.综上所述,借助于本发明的上述技术方案,能够解决现有构建方法人为工作量大、耗费大量的计算机资源、碎片化信息过多、数据不完整、难以对不同来源的知识区别提取和融合的问题,从而达到根据数据来源不同,采用针对性的策略构建目标本体、抽取实体和属性,兼顾了不同来源知识的特点,结合机器学习方法对知识图谱进行半自动构建,在确保准确的同时大大减少了大规模知识图谱构建所耗费的人力的目的。
23.以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。