技术特征:
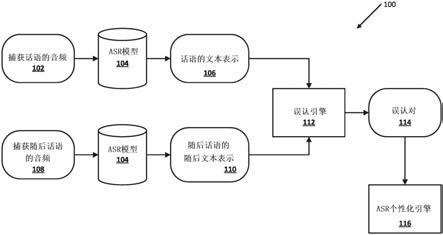
1.一种由一个或多个处理器实现的方法,所述方法包括:使用自动语音识别(“asr”)引擎的asr模型处理捕获由用户说出的话语的音频数据,以生成所述话语的文本表示;使用所述asr模型处理捕获由所述用户在所述话语之后说出的随后话语的随后音频数据,以生成所述随后话语的随后文本表示;基于所述随后话语的所述随后文本表示,确定所述用户是否由于使用所述asr模型生成的所述话语的所述文本表示是所述话语的误认而说出所述随后话语;以及响应于确定所述话语的所述文本表示是所述话语的误认,并且所述用户由于所述误认而说出所述随后话语,使用所述话语的所述文本表示和/或所述随后话语的所述文本表示为所述用户个性化所述asr引擎。2.根据权利要求1所述的方法,其中,使用所述话语的所述文本表示和/或所述随后话语的所述随后文本表示为所述用户个性化所述asr引擎包括:基于(1)捕获所述话语的所述音频数据和(2)所述随后话语的所述随后文本表示训练所述asr模型,以为所述用户个性化所述asr模型。3.根据权利要求1所述的方法,其中,使用所述话语的所述文本表示和/或所述随后话语的所述随后文本表示为所述用户个性化所述asr引擎包括:使用所述随后话语的所述随后文本表示来重写由所述用户说出的进一步话语的进一步文本表示。4.根据权利要求1所述的方法,其中,使用所述话语的所述文本表示和/或所述随后话语的所述随后文本表示为所述用户个性化所述asr引擎包括:使用所述asr模型处理捕获由所述用户说出的进一步话语的进一步音频数据,以生成所述进一步话语的进一步文本表示,其中,使用所述asr模型处理捕获所述进一步话语的进一步音频数据包括:使用所述随后话语的所述随后文本表示来修改所述asr模型的词格的一个或多个部分;以及使用所述asr模型的所述词格的修改后的一个或多个部分生成所述进一步话语的文本表示。5.根据任何前述权利要求所述的方法,其中,基于所述随后话语的所述随后文本表示确定所述用户是否由于使用所述asr模型生成的所述话语的所述文本表示是所述话语的误认而说出所述随后话语包括:确定(1)所述用户说出所述话语和(2)所述用户说出所述随后话语之间的时间间隔;确定所述时间间隔是否满足一个或多个条件;以及基于确定所述时间间隔满足所述一个或多个条件,确定所述用户由于使用所述asr模型生成的所述话语的所述文本表示是所述话语的误认而说出所述随后话语。6.根据权利要求5所述的方法,其中,确定所述时间间隔是否满足一个或多个所述条件包括确定所述时间间隔是否低于时间阈值。7.根据任何前述权利要求所述的方法,其中,基于所述随后话语的所述随后文本表示确定所述用户是否由于使用所述asr模型生成的所述话语的所述文本表示是所述话语的误认而说出所述随后话语包括:
确定(1)所述话语的所述文本表示和(2)所述随后话语的所述文本表示之间的语音相似度度量;确定所述语音相似度度量是否满足一个或多个其他条件;以及基于确定所述语音相似度满足所述一个或多个其他条件,确定所述用户由于使用所述asr模型生成的所述话语的所述文本表示是所述话语的误认而说出所述随后话语。8.根据权利要求7所述的方法,其中,确定所述语音相似度度量是否满足所述一个或多个其他条件包括确定所述语音相似度度量是否高于语音相似度阈值。9.根据任何前述权利要求所述的方法,其中,基于所述随后话语的所述随后文本表示确定所述用户是否由于使用所述asr模型生成的所述话语的所述文本表示是所述话语的误认而说出所述随后话语包括:识别由所述用户先前说出的历史话语的历史文本表示,以及由所述用户在所述历史话语之后先前说出的历史随后话语的历史随后文本表示,其中,所述用户由于使用所述asr模型生成的所述历史话语的所述历史文本表示是所述历史话语的误认而说出所述历史随后话语;确定所述随后话语的所述文本表示是否对应于所述历史话语的所述历史文本表示;以及基于确定所述随后话语不对应于所述历史话语的所述历史文本表示,确定所述用户由于使用所述asr模型生成的所述话语的所述文本表示是所述话语的误认而说出所述随后话语。10.根据任何前述权利要求所述的方法,其中,基于所述随后话语的所述随后文本表示确定所述用户是否由于使用所述asr模型生成的所述话语的所述文本表示是所述话语的误认而说出所述随后话语包括:确定值,所述值指示所述用户已经历史地说出所述话语的至少一部分和所述随后话语的至少对应部分的次数;确定所述值是否满足一个或多个进一步条件;以及基于确定所述值满足所述一个或多个进一步条件,确定所述用户由于使用所述asr模型生成的所述话语的所述文本表示是所述话语的误认而说出所述随后话语。11.根据权利要求10所述的方法,其中,确定所述值是否满足所述一个或多个进一步条件包括确定所述值是否高于阈值。12.根据权利要求2所述的方法,其中,基于(1)捕获所述话语的所述音频数据和(2)所述随后话语的所述文本表示训练所述asr模型以为所述用户个性化所述asr模型包括:使用所述asr模型处理捕获所述话语的所述音频数据以生成所述话语的候选文本表示;基于所述话语的所述候选文本表示和所述随后话语的所述文本表示确定损失;以及基于所确定的损失更新所述asr模型的一个或多个部分。13.根据权利要求2所述的方法,其中,基于(1)捕获所述话语的所述音频数据和(2)所述随后话语的所述文本表示训练所述asr模型以为所述用户个性化所述asr模型包括:识别其中客户端设备捕获说出的话语和随后说出的话语的对话会话;确定对应于所述用户的用户简档、所述客户端设备和/或所述对话会话的一个或多个
上下文信号;使用个性化的asr模型处理所述一个或多个上下文信号以及捕获所述话语的所述音频数据,以生成所述话语的所述候选文本表示;基于所述话语的所述候选文本表示和所述随后话语的所述文本表示确定损失;以及基于所确定的损失更新个性化的asr模型的一个或多个部分。14.根据权利要求13所述的方法,其中,确定对应于所述用户的所述用户简档、所述客户端设备和/或所述对话会话的所述一个或多个上下文信号包括:基于短期先前查询历史确定所述一个或多个上下文信号,所述短期先前查询历史包括(1)所述随后话语的主题、(2)在所述对话会话中所述随后话语与一个或多个先前话语之间的语音距离和/或(3)在所述对话会话中所述随后话语与所述一个或多个先前话语之间的文本编辑距离。15.根据权利要求13所述的方法,其中,确定对应于所述用户的所述用户简档、所述客户端设备和/或所述对话会话的所述一个或多个上下文信号包括:基于长期聚合历史确定所述一个或多个上下文信号,所述长期聚合历史包括(1)与所述用户简档对应的多个常用词和/或(2)与所述用户简档对应的附加信息。16.根据权利要求13所述的方法,其中,确定对应于所述用户的所述用户简档、所述客户端设备和/或所述对话会话的所述一个或多个上下文信号包括:基于包括所述客户端设备在所述对话会话期间的一个或多个状态的用户动作内容来确定所述一个或多个上下文信号。17.根据任何前述权利要求所述的方法,其中,所述随后话语由所述用户紧接在所述话语之后说出。18.根据权利要求1-16中的任一项所述的方法,还包括:使用所述asr模型处理捕获由所述用户说出的插入在所述话语和所述随后话语之间的插入话语的插入音频数据,以生成所述插入话语的插入文本表示;基于所述随后话语的所述随后文本表示,确定所述用户是否由于使用所述asr模型生成的所述插入话语的所述插入文本表示是所述插入话语的插入误认而说出所述随后话语;以及响应于确定所述插入话语的所述插入文本表示是所述插入话语的插入误认,并且所述用户由于所述插入误认的结果而说出所述随后话语,使用所述插入话语的所述文本表示和/或所述随后话语的所述文本表示为所述用户个性化所述asr引擎。19.一种包括指令的计算机程序,所述指令在由计算系统的一个或多个处理器执行时使所述计算系统执行根据任何前述权利要求所述的方法。20.一种计算系统,被配置为执行根据权利要求1至18中的任一项所述的方法。21.一种存储指令的计算机可读存储介质,所述指令能够由计算系统的一个或多个处理器执行以执行根据权利要求1至18中的任一项所述的方法。
技术总结
公开了使得能够确定和/或利用口述话语的误认的技术,其中,误认是使用自动语音识别(ASR)模型生成的。各种实现方式包括基于口述话语和在该口述话语之前说出的先前话语来确定误认。附加地或替代地,实现方式包括基于口述话语和该口述话语之前说出的先前话语(例如,基于捕获先前话语和口述话语的文本表示的音频数据)为用户个性化ASR引擎。音频数据)为用户个性化ASR引擎。音频数据)为用户个性化ASR引擎。
技术研发人员:阿戈什顿
受保护的技术使用者:谷歌有限责任公司
技术研发日:2020.07.08
技术公布日:2022/3/7
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。