1.本发明涉及声音数据库领域,特别涉及一种声音数据库的创建技术。
背景技术:
2.在监控领域,监控系统大多数仅通过视频监控来检测异常情况,视频监控系统主要由视频摄像头和监控显示终端组成,而没有设置声音采集和分析预警的功能。声音作为人类感知环境最重要的媒介,具有不受光线影响,探测距离较远,信息量丰富等特点,并且由于声音信号的采集过程相对简单,存储需求较小,因此系统的计算复杂度相对较低,运行效率能够得到有效的提高。将声音监测功能加入现有的监控系统,可以降低环境噪声污染,促进“智慧城市”“智慧城镇”“智慧小区”的建设。要想推进监控的智能升级,智能地识别环境中的声音,首先必须有一个数据种类和数量丰富的环境声音数据库。
3.按声音的产生方式和所携带信息的特性分类,可听声又分为语音声、音乐声和环境声三大类。环境声是除语音声和音乐声之外的所有可听声的总称。所谓的环境声,是由自然环境、机械设备产生的,或者由人或动物发出的声音。
4.目前,声音数据库主要以单通道语音数据库为主,相应的音频预处理方法局限于简单解码并分段单通道语音音频数据。对于现有的声音获取及预处理方法,缺乏针对多通道环境声音数据有效的获取和处理,并且相关装置缺少存储录音相关的其他模态信息。
5.公开号为cn111524563a的专利申请涉及一种生理音数据库的建立方法及其数据库,采用数字听诊设备对生理音进行收集,并将采集的生理音转化生成代表声学振动的电子信号进行保存来进行数据库的构建。该数据库构建过程中,其使用的数据标记方法只是进行人工标注、人工智能标注的简单组合,可靠性低,存在污染数据库的风险。
6.公开号为cn109544352a的专利申请涉及基于随机数的抽检方法、装置、计算机设备及存储介质,该发明公开了一种基于随机数的抽检方法。对于不同种类的环境声音抽检比例和抽检概率应当不同。但上述方法并不适用于不同环境声音类别声音数据的抽检,并且可能漏检不合格的多通道声音数据,进而导致数据库污染。
技术实现要素:
7.为了克服现有技术的不足,本发明提供一种环境声音数据库的创建方法,能够简单可靠的构建环境声音数据库,减小数据污染的风险。
8.本发明解决其技术问题所采用的技术方案是:一种环境声音数据库创建方法,包括以下步骤:
9.(1)获取环境声音数据与录音信息,将单个多通道环境声音数据拆分为多个单通道的环境声音音频文件;
10.(2)进行环境声音数据预处理,删除不满足设定条件的音频文件;将满足条件的环境声音音频文件剪切为指定长度;
11.(3)对剪切后的音频文件进行人工分类和人工智能分类;所述的人工智能分类是
对音频文件进行特征提取,提取时频域的声谱图作为特征,通过基于深度学习的环境声音分类算法识别音频文件的环境声音类别;每个音频进行至少一次人工分类和至少一次人工智能分类;对人工分类结果以及人工智能分类结果取交集,交集内的音频被划分到相应环境声音类别,交集之外的音频文件划分为未标定类别。
12.所述的步骤(1)获取的录音信息包括采样率、采样深度、录音时间、录音地点、和总通道数。
13.所述的步骤(2)设定条件包括不缺少通道音频、音频文件可读、各音频文件为单通道、音频文件采样率与录音信息一致、音频信号平均绝对幅度不为0,对不满足以上任一条件的音频文件,删除该音频文件对应的所有通道的环境声音音频文件。
14.所述的步骤(2)指定长度为1秒、2秒、5秒或10秒。
15.所述时频域的特征包括但不限于短时傅里叶变换谱、梅尔谱、对数梅尔谱、梅尔倒谱,所述基于深度学习的环境声音分类算法包括但不限于卷积神经网络、循环神经网络、卷积循环神经网络、全连接神经网络、transformer、对抗神经网络。
16.所述的人工分类由至少1位环境声音标记人员进行分类,人工智能分类由至少1种环境声音分类算法进行分类;若环境声音标记人员大于1位,人工分类结果为所有标记人员分类结果的并集;若环境声音分类算法大于1种,人工分类结果为所有环境声音分类算法结果的并集。
17.所述的步骤(3)对已标定种类音频文件进行重命名,命名规则包含了分类信息、音频长度、音频序号以及通道信息;根据环境声音录音信息与音频文件名中的信息,生成对应的标记信息,标记信息内包含采样率、采样深度、录音时间、录音地点、通道编号、总通道数、环境声音分类信息、音频长度以及音频编号的字符信息。
18.所述的步骤(3)之后对环境声音音频文件及音频标记文件进行抽检操作,对每种分类结果确定所述环境声音类别的抽检通过概率和抽检比例,随机从该类已标定音频文件中选取音频文件及其对应的标记文件作为待检查文件,检查已标定的音频文件各级分类是否正确分类,若分类错误则该文件所有通道音频文件及其对应标记文件不通过抽检,若分类正确则检查该文件其余通道音频文件是否为同一类别,若其余通道音频文件存在文件与该文件分类不同,则该文件所有通道音频文件及其对应标记文件不通过抽检,若其余通道音频文件与该文件分类相同,则检查该音频文件所有通道标记文件内的标记信息是否正确,若该文件所有通道标记文件存在标记文件信息错误,则该文件所有通道音频文件及其对应标记文件不通过抽检,否则该文件所有通道音频文件及其对应标记文件通过抽检;若上述通过抽检的文件占比大于等于抽检通过概率,则该种环境声音类别下的剩余已标定音频文件及标记文件通过抽检;若通过抽检的文件占比小于抽检通过概率,则该种环境声音类别下的剩余已标定音频文件及标记文件不通过抽检。
19.对于通过抽检的环境声音音频文件与标记文件,储存至环境声音数据库,并进行备份;对于未标定类别的环境声音音频文件以及未通过抽检的环境声音音频文件与标记文件,进行环境声音数据存储与备份,但不纳入环境声音数据库。
20.本发明还提供一种环境声音数据库生成装置,包括:
21.数据获取模块,用于获取多通道环境声音文件及录音信息,拆分多通道环境声音文件为单通道环境声音音频文件,预分类并存储环境声音数据;
22.数据预处理模块,用于预处理环境声音文件及录音信息,确定符合纳入环境声音数据库要求的环境声音音频文件,将符合要求的环境声音音频文件裁剪;
23.数据智能融合标定模块,用于对进行预处理后的环境声音音频文件进行智能融合标定,确定环境声音文件最终分类,并生成标记文件;
24.数据抽检模块,用于对已标定的环境声音音频文件和标记文件进行抽检;
25.数据存储模块,用于将通过抽检的环境声音音频文件及标记文件储存至环境声音数据库并进行备份,将未标定和未通过抽检的环境声音音频文件及标记文件进行存储和备份。
26.本发明的有益效果是:
27.在本发明提供的技术方案中,数据获取模块不仅获取环境声音音频数据,还获取了有关录音信息的文本数据,包括时间、地点、通道数等信息。对于环境声音数据获取了音频以及文本两种模态的信息,不仅极大地丰富了数据库中的信息结构,而且为构建多模态智能环境声音识别算法提供了丰富的数据类型。
28.此外,在本发明提供的技术方案中,对于多通道环境声音文件的数据预处理操作,首先保留了有效的多通道环境声音信息,清洗掉不符合要求的数据;其次,在将音频剪切成标准长度后,不仅保存了多通道的环境声音数据结构,同时提高了环境声音数据库的标准程度。
29.另外,本发明提供了一种环境声音数据智能融合标定方法,该方法融合了专业环境声音标记人员分类以及人工智能分类算法的结果,该结果同时具备了专业标记人员标记的专业性和基于大数据的分类算法的准确性,提高了分类准确率,减少污染环境声音数据库的风险。
30.最后,本发明还对音频文件、标记文件进行抽检操作。该操作由专业标记人员抽检以及相应程序抽检。通过有效的抽检步骤,提高了多通道环境声音数据标定的效率和准确性,保证了环境声音数据库的质量。
附图说明
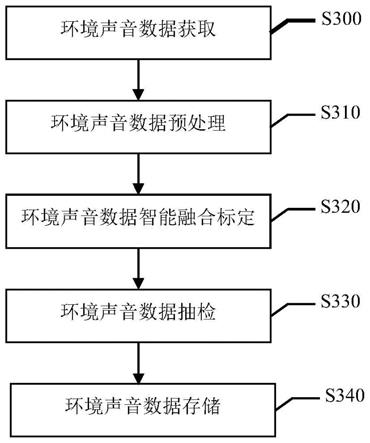
31.图1为本发明实施例的一种环境声音数据库创建方法的总体流程图。
32.图2为本发明实施例的一种环境声音数据获取流程图。
33.图3为本发明实施例的一种环境声音数据预处理流程图。
34.图4为本发明实施例的一种环境声音数据智能融合标定流程图。
35.图5为本发明实施例的一种环境声音数据抽检流程图。
36.图6为本发明实施例的一种环境声音数据储存流程图。
37.图7为本发明实施例的一种创建环境声音数据库的装置的结构框图。
具体实施方式
38.下面结合附图和实施例对本发明进一步说明,本发明包括但不仅限于下述实施例。
39.本发明提供一种环境声音数据库创建方法,包括如下:
40.获取环境声音数据与录音信息。获取并保存采样率、采样深度、录音时间、录音地
点、总通道数等录音信息,将单个多通道环境声音数据拆分为多个单通道的环境声音音频文件。
41.根据获取的环境声音音频文件及录音信息,进行环境声音数据预处理操作。
42.判断环境声音音频文件是否满足以下条件:不缺少某些通道音频、音频文件可读、各音频文件为单通道、音频文件采样率与录音信息一致、音频信号平均绝对幅度不为0。对不满足以上条件的音频文件,删除该音频文件对应的所有通道的环境声音音频文件。
43.将满足以上条件的环境声音音频文件剪切为声音片段。剪切规则如下:按照指定长度剪切音频,在剪切过程中,指定长度小于等于音频文件长度,若该音频文件的长度不是指定长度的整数倍,则将最后不足指定长度的数据舍去。保留原环境声音数据文件名中的录音时间信息和通道信息,将剪切后的声音片段按照时间顺序在文件名中添加序号信息、添加时间长度信息,保存剪切后的音频。
44.对经过数据预处理后的环境声音音频文件进行智能融合标定操作。该标定过程可分为以下几个操作:
45.音频文件分类操作。音频文件分类方法可分为采用人工分类和人工智能分类两种分类方法。人工分类即经过标准培训的专业环境声音标记人员对音频文件进行分类。人工智能分类则对音频文件进行特征提取,提取时频域的声谱图作为特征,通过预先训练好的基于深度学习的环境声音分类算法识别音频文件的环境声音类别。经过音频文件分类操作,环境声音音频文件被划分到指定类别。在进行音频分类时,每个音频至少进行一次人工分类以及人工智能分类,并保留相应的人工分类结果和人工智能分类结果。
46.音频文件分类结果融合操作,即对经过人工分类以及人工智能分类的分类结果进行融合。融合方法如下所述,对于所有的人工分类结果取并集得到最终的人工分类结果,对于所有的人工智能分类结果取并集得到最终的人工智能分类结果,对最终的人工分类结果以及人工智能分类结果取交集,交集内的音频被划分到相应环境声音类别,对于交集之外的音频文件划分为未标定类别。
47.音频标记文件生成操作。对于已标定种类音频文件进行重命名,命名规则包含了分类信息、音频长度、音频序号以及通道信息,移除环境声音音频文件名中的录音时间信息,保存标记信息到音频标记文件中。根据环境声音录音信息与音频文件名中的信息,生成对应的标记信息。标记信息内包含采样率、采样深度、录音时间、录音地点、通道编号、总通道数、环境声音分类信息、音频长度以及音频编号的字符信息。且标记文件名称与音频文件名称除后缀外保持一致。
48.对智能融合标定后生成的环境声音音频文件及音频标记文件,进行抽检操作。
49.音频文件、标记文件抽检操作。对每种分类结果确定所述环境声音类别的抽检通过概率和抽检比例,根据抽检比例和已标定文件总数确定待抽检文件数目,随机从该类已标定音频文件中选取音频文件及其对应的标记文件作为待检查文件。对待检查文件进行如下操作:
50.首先,对待检查音频文件由专业环境声音标记人员进行检查,检查已标定的音频文件各级分类是否正确分类。对于每个待检查音频文件,若分类错误则该文件所有通道音频文件及其对应标记文件不通过抽检,若分类正确则进行下一步。
51.通过程序检查该文件其余通道音频文件是否为同一类别,若其余通道音频文件存
在文件与该文件分类不同,则该文件所有通道音频文件及其对应标记文件不通过抽检,若其余通道音频文件与该文件分类相同,则进行下一步。通过程序检查该音频文件所有通道标记文件内的标记信息是否正确,若该文件所有通道标记文件存在标记文件信息错误,则该文件所有通道音频文件及其对应标记文件不通过抽检,否则该文件所有通道音频文件及其对应标记文件通过抽检。
52.对于每种环境声音类别下剩余已标定音频文件,若上述通过抽检的文件占比大于等于抽检通过概率,则该种环境声音类别下的剩余已标定音频文件及标记文件通过抽检;若通过抽检的文件占比小于抽检通过概率,则该种环境声音类别下的剩余已标定音频文件及标记文件不通过抽检。
53.根据抽检结果,保存环境声音数据。对于通过抽检的环境声音音频文件与标记文件,储存至环境声音数据库,并进行备份;对于未标定类别的环境声音音频文件以及未通过抽检的环境声音音频文件与标记文件,进行环境声音数据存储与备份,但不纳入环境声音数据库。
54.本发明还提供一种环境声音数据库生成装置,包括:
55.数据获取模块,用于获取多通道环境声音文件及录音信息,拆分多通道环境声音文件为单通道环境声音音频文件,预分类并存储环境声音数据。
56.数据预处理模块,用于预处理环境声音文件及录音信息。确定符合纳入环境声音数据库要求的环境声音音频文件,将符合要求的环境声音音频文件裁剪。
57.数据智能融合标定模块,用于对进行预处理后的环境声音音频文件进行智能融合标定。确定环境声音文件最终分类,并生成标记文件。
58.数据抽检模块,用于对已标定的环境声音音频文件和标记文件进行抽检。
59.数据存储模块,用于将通过抽检的环境声音音频文件及标记文件储存至环境声音数据库并进行备份,将未标定和未通过抽检的环境声音音频文件及标记文件进行存储和备份。
60.本发明的实施例提供一种环境声音数据库创建方法,其总体流程如图1所示,主要包括:
61.步骤s300,环境声音数据获取,包括获取多通道环境声音数据与录音信息和多通道环境声音数据拆分。
62.步骤s310,环境声音数据预处理,根据数据库入库完整性要求,对入库数据进行初步筛选和剪切。
63.步骤s320,环境声音数据智能融合标定,包括音频文件分类、音频文件分类结果融合、音频文件重命名、音频标记文件生成操作。
64.步骤s330,环境声音数据抽检,根据不同环境声音分类的抽检通过概率和抽检比例,随机选取抽检音频文件和标记文件进行抽检。
65.步骤s340,环境声音数据存储,对环境声音音频文件与标记文件进行储存和备份。
66.本实施例的环境声音数据获取流程如图2所示,包括获取多通道环境声音数据与录音信息s301和多通道环境声音数据拆分s302。
67.所述的步骤s301,获取多通道环境声音数据与录音信息,所述环境声音包括但不限于自然环境声音、人类生活声音、工业机械声音以及城市环境声音中的一种,多通道包括
但不限于2通道、4通道、8通道、16通道以及32通道中的一种,录音信息包括但不限于采样率、采样深度、录音时间、录音地点、总通道数信息中的一种。
68.所述的步骤s302,多通道环境声音数据拆分,即将多通道环境声音数据拆分为多个单通道的环境声音音频文件。对于每个单通道的环境声音音频文件,保留原多通道环境声音数据文件名中的录音时间信息,并添加通道信息。要注意的是,若原多通道环境声音数据个数为m,且环境声音录音信息中通道数为c,则每个原始多通道声音数据可解析为c条不同通道的单通道音频数据,则经过多通道环境声音数据拆分后,环境声音音频文件个数为m*c,且均为单通道音频。
69.本实施例的环境声音数据预处理流程如图3所示,包括步骤s311至步骤s319。
70.上接步骤s302,进行步骤s311,根据录音信息判断是否缺少通道音频,若缺少某些通道音频,则接步骤s316删除数据,否则接步骤s312,读取音频判断音频文件是否可读,若音频文件不可读,则接步骤s316删除数据,否则接步骤s313,判断音频文件是否是单通道,若音频文件不为单通道,则接步骤s316删除数据,否则接步骤s314,判断音频文件采样率是否与录音信息一致,若音频文件采样率与录音信息不一致,则接步骤s316删除数据,否则接步骤s315,计算音频信号平均绝对幅度,判断音频信号平均绝对幅度是否为0,若音频信号平均绝对幅度为0,则接步骤s316删除数据,否则接步骤s317。
71.上接步骤s315,进行步骤s317,读取音频文件,读取完成后接步骤s318,按照指定长度剪切音频,剪切完成后接步骤s319,保存剪切后的音频,数据剪切操作完成。上述指定长度包括但不限于1秒、2秒、5秒以及10秒。则经过数据剪切后,一个多通道环境声音数据可产生环境音频文件c*n个。
72.其中步骤s316删除数据,可分为以下操作进行:若接步骤s311,则将缺少通道音频的其他通道音频删除;若接步骤s312,则将不可读音频及其他通道音频删除;若接步骤s313,则将该不为单通道音频及其他通道音频删除;若接步骤s314,则将采样率不一致音频及其他通道音频删除;若接步骤s315,则将信号平均绝对幅度为0音频及其他通道音频删除。
73.其中步骤s311至s314,保证音频均为单通道可读音频文件且音频通道数、采样率与采集信息一致。步骤s315,保证音频信号文件不为静音文件。
74.其中步骤s318保证音频长度一致,步骤s319提供时间长度信息和序号信息。经过操作s317至s319,增加了环境声音数据标记信息并保证了环境声音音频长度标准。
75.本实施例的环境声音数据智能融合标定流程如图4所示,包括步骤s321至步骤s325。
76.上接步骤s319,进行步骤s321,音频文件分类。音频文件分类方法可采用人工分类和人工智能分类。人工分类即经过标准培训的专业环境声音标记人员对音频文件进行分类。人工智能分类即对音频文件进行时频域的特征提取,通过预先训练好的基于深度学习的环境声音分类算法识别音频文件的环境声音类别。所述时频域特征包括但不限于短时傅里叶变换谱、梅尔谱、对数梅尔谱、梅尔倒谱,所述基于深度学习的环境声音分类算法包括但不限于卷积神经网络、循环神经网络、卷积循环神经网络、全连接神经网络、transformer、对抗神经网络。经过音频文件分类操作,环境声音音频文件被划分到指定类别。在进行音频分类时,人工分类由至少1位专业环境声音标记人员进行分类,人工智能分
类由至少1种环境声音分类算法进行分类。若环境声音标记人员等于1位,人工分类结果即为该标记人员的分类结果;若环境声音标记人员大于1位,人工分类结果为所有标记人员分类结果的并集,人工智能分类同理。需要注意的是,人工分类时,环境声音标记人员应使用相同的声音标注工具、音频播放软件以及相关设备,保证相同的试听环境,降低由外界条件的差异导致的分类差异。
77.步骤s322,音频文件分类结果融合,即对经过人工分类和人工智能分类的音频文件分类结果进行融合。本步骤对两种分类结果取交集,对交集内的音频文件划分到相应分类下,对于交集外的音频文件则划分为未标定种类音频文件。
78.步骤s323,判断音频文件是否已标定种类。若音频文件已标定种类,则下接步骤s324,否则下接步骤s342。
79.步骤s324,音频文件重命名。对于已标定种类的环境声音音频文件进行重命名,命名规则包含了分类信息、音频长度、音频序号以及通道编号的字符信息,保留原文件名中录音时间信息等待保存到标记文件中。
80.步骤s325,音频标记文件生成。对于重命名后的音频文件,根据环境声音采集信息与音频文件命名中的信息,生成对应的标记信息。标记信息包括采样率、采样深度、录音时间、录音地点、通道编号、环境声音分类信息、音频长度以及音频序号的字符信息。除后缀名外,标记文件名称与音频文件名称保持一致。
81.本实施例的环境声音数据抽检流程如图5所示,包括步骤s331至步骤s338。
82.步骤s331,确定抽检通过概率和抽检比例,即根据每种分类结果确定所述环境声音类别对应的抽检通过概率和抽检比例。步骤s332,确定待抽检文件数目,即根据抽检比例和已标定文件总数计算出待抽检文件数目。步骤s333,选取待检查文件,根据待抽检文件数目随机选取音频文件,再选取其对应的标记文件作为待检查文件。步骤s334,标记人员检查,即对待检查音频文件由专业环境声音标记人员进行检查,检查已标定的音频文件各级分类是否正确分类,对于分类错误的文件,其所有通道音频文件及其对应标记文件不通过抽检。步骤s335,抽检程序检查,通过程序检查该文件其余通道音频文件是否为同一类别,检查该音频文件所有通道标记文件内的标记信息是否正确,若其余通道音频文件存在与该文件分类不同或该文件所有通道的标记文件存在信息错误,则该文件所有通道音频文件及其对应标记文件不通过抽检,否则该文件所有通道音频文件及其对应标记文件通过抽检。对于每种环境声音类别下剩余已标定音频文件,进行步骤s336,判断通过抽检文件占比。若通过抽检的文件占比大于等于抽检通过概率,则进行步骤s337,该环境声音类别下的剩余已标定音频文件及标记文件通过抽检;若通过抽检的文件占比小于抽检通过概率,则进行步骤s338,该环境声音类别下的剩余已标定音频文件及标记文件不通过抽检。
83.本实施例的环境声音数据存储流程如图6所示,包括步骤s341至步骤s343。
84.上接步骤s337,进行步骤s341,音频数据入库。对通过抽检的已标定种类音频文件和标记文件纳入环境声音数据库中。
85.上接步骤s341和s323或s338,进行步骤s342音频数据存储。若音频数据来源为s341,即环境声音数据为已纳入环境声音数据库的音频文件和标记文件,则将数据存储到环境声音数据库存储介质中;若音频数据来源为s323或s338,即环境声音数据为未通过抽检的音频文件和标记文件或未标定的环境声音音频文件,则将数据存储到待标记环境声音
数据存储介质中。上接步骤s342,进行步骤s343,音频数据备份,即对步骤s342中存储的环境声音数据进行备份。
86.图7示例性给出一种创建环境声音数据库的装置的结构,包括:
87.数据获取模块350,用于获取多通道环境声音文件及录音信息,即从一个以上的环境声音采集装置组成的阵列或者网络获取多通道环境声音数据和录音信息。每个环境声音采集装置由外壳、麦克风阵列以及数据采集传输模块组成,通过有线(无线)方式进行通信和数据传输,将采集到的多通道环境声音数据实时(非实时)保存到本地存储介质或云存储介质。多通道环境声音数据先以bin文件格式传输到存储介质中,一个bin文件包含多个通道的环境声音信号。之后,拆分多通道环境声音文件为单通道环境声音音频文件,即将bin文件按照规定的格式解析为多个单通道的环境声音信号,并以wave文件的格式存储,文件命名规则中包含了录音时间信息和通道信息。环境声音的录音信息为字符信息,包括采样率、采样深度、录音地点、通道数信息,以json文件格式存储。例如环境声音音频文件20210720t180000_1.wav,其中前15位代表录音时间为2021年7月20日18时00分00秒,下划线后1代表第1通道。
88.数据预处理模块351,用于对获取的多通道环境声音音频文件及录音信息进行预处理操作。对每条环境声音音频文件,搜索文件名前缀相同所有音频文件,根据录音信息中的通道数信息判断是否缺少通道音频;对每个环境声音音频文件进行读取判断是否可读;对读取后的音频判断音频文件是否是单通道;对读取后的音频判断采样率是否与录音信息中的采样率一致;计算音频信号平均绝对幅度,判断音频信号平均绝对幅度是否为0。将环境声音音频文件裁剪成长度符合环境声音数据库要求的音频文件。需要注意的是,在剪切过程中,指定长度需小于等于音频文件长度,且若该音频文件的长度不是指定长度的整数倍,则将最后不足指定长度的数据舍去。保留原环境声音数据文件名中的录音时间信息和通道信息,将剪切后的声音片段按照时间顺序在文件名中添加序号信息(例如1,2,
……
,n)、添加时间长度信息(例如1,10),保存剪切后的音频。例如环境声音音频文件20210720t1800001_1_1.wav,其中前15位代表录音时间为2021年7月20日18时00分00秒,第16位1代表音频文件长度1秒,第一个下划线后1代表音频序号1,第二个下划线后1代表第1通道。
89.数据智能融合标定模块352,对进行预处理后的环境声音音频文件进行智能融合标定。具体可分为,使用人工分类和人工智能分类方法对音频文件分类,对分类的结果进行融合确定环境声音文件最终分类结果,对环境声音音频文件重命名并生成标记文件。其中分类阶段按照多级分类方法将环境声音音频文件划分到相应的分类。例如,第一级为城市环境声音,第二级为鸣笛声,引擎声及其他,鸣笛声可进一步分为第三级汽车鸣笛和货车鸣笛。人工分类则由专业环境声音标记人员逐级分类,人工智能分类则由基于深度学习的环境声音分类算法逐级分类。其中重命名操作将文件名中的录音时间信息以字符形式保存到标记文件中,文件名保留分类信息、音频长度、音频序号以及通道信息。标记文件名称除后缀外与音频文件保持一致,标记文件内包含采样率、采样深度、录音时间、录音地点、通道编号、总通道数、环境声音分类信息、音频长度以及音频编号的字符信息。例如,环境声音音频文件010203001_1_1.wav,1至2位01代表第一级分类,3至4位02代表第二级分类,5至6位03代表第三级分类,7至8位00代表第四级分类,第9位1代表音频文件长度1秒,第一个下划线
后1代表音频序号1,第二个下划线后1代表第1通道。
90.数据抽检模块353,用于对所述经过数据标定模块的环境声音音频文件和标记文件进行抽检。具体抽检流程为,确定每种分类对应的抽检通过概率和抽检比例,计算待抽检文件数目并随机选取待检查文件,标记人员检查,抽检程序检查,计算通过抽检文件占比,判断剩余已标定音频文件及标记文件是否通过抽检。例如,对于城市环境声音中汽车鸣笛,抽检通过概率为90%,抽检比例为10%,若计算抽检文件数目不为整数,则向上取整。上述抽检程序检查,即检查同一音频序号所有通道的标记文件信息内容是否完整正确,例如,是否缺失采样率、采样深度、录音时间、录音地点、通道编号、环境声音分类信息、音频长度以及音频序号的字符信息,是否上述字符信息除通道编号外保持一致。
91.数据存储模块354,用于对所述经过数据抽检模块的环境声音音频文件和标记文件进行存储。进一步的,对于所有环境声音数据进行备份。
92.本技术的创建环境声音数据库的方法及装置,可用计算机执行可执行程序实现,也可以结合必要的硬件实现。环境声音音频文件格式可以为但不限于wave、mp3、midi或flac;环境声音的采集信息以及标记文件可以为但不限于json、txt或xls;程序设计语言可以为但不限于java、c 、c、matlab或python以及上述的任意组合;环境声音数据存储及备份可以为但不限于u盘、移动硬盘、磁碟、光盘、计算机存储器、云存储以及上述的任意组合。
93.基于本技术利用上述方法及装置来创建环境声音数据库,保留了多通道的环境声音数据,并进行数据预处理操作,保证多通道环境声音数据的完整、降低了污染环境声音数据库的风险;对于环境声音数据获取了音频以及文本两种模态的信息,极大地丰富了数据库中的信息结构;采用了融合专业环境声音标记人员分类以及基于深度学习的环境声音分类算法分类的标定方法,提高了分类准确率;根据环境声音具体类别,动态地改变抽检通过概率,并且采用人工抽检与程序抽检相结合的方式,进一步减小污染环境声音数据库的可能性。应注意的是,上述示例性实施例仅为本技术的一种,使所属技术领域技术人员能很好地理解和利用本发明,并没有详尽叙述所有的细节,也不限制该发明的具体实施方式。显然,本领域的技术人员进行相关的修改和变化也应属于本技术的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。