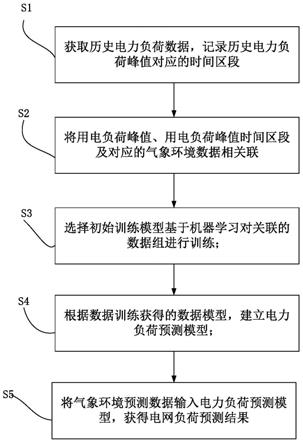
1.本发明涉及一种电子装置,且特别涉及一种池化装置与池化方法。
背景技术:
2.在图形处理单元上的通用计算(general-purpose computing on graphics processing units,gpgpu)是利用处理图形任务的图形处理器来计算原本由中央处理器(central processing unit,cpu)处理的通用计算任务。这些通用计算任务可以与图形处理没有关系。由于图形处理器有强大的并列处理能力和可程序化管线(pipeline),图形处理器也可以处理非图形数据。特别是单指令流多数据流(single instruction multiple data,simd),gpgpu在效能上大大超越了传统的cpu应用程序。在gpgpu的设计中,每个执行单元(execution unit,eu)有一个属于自己的寄存器堆(register file)。在执行卷积神经网络(convolutional neural network, cnn)运算或是其他运算中,执行单元会将数据从内存(或其他运算模块)加载至寄存器堆,然后使用在寄存器堆中的数据去进行运算。
3.卷积神经网络运算会进行卷积(convolution)、激活(activation)、池化(pooling)等计算工作。池化是卷积神经网络运算中的一种非线性降采样(non-linear downsampling)。常见的池化操作包括最大池化(max pooling)、平均池化(average pooling)或是其他池化演算方法。池化操作是根据步幅(stride)将池化窗口(或称depth slice)移动至数据矩阵(data matrix,例如张量、图像)的不同位置,然后在每次移动池化窗口后对在池化窗口中的多个数据元素(data element)进行计算(例如取最大值或进行平均)以获得经池化矩阵的一个数据元素。在池化窗口根据步幅完整扫描整个数据矩阵后,执行单元可以将经池化矩阵存储到存储器中。池化操作会不断减少数据矩阵的大小,进而降低卷积神经网络运算的参数数量和计算量。池化操作可以在一定程度上控制过拟合(overfitting)。
4.为了进行池化操作,完整的数据矩阵必须被加载至寄存器堆。再将完整的数据矩阵加载至寄存器堆后,执行单元才能对在寄存器堆中的完整数据矩阵进行池化操作。无论如何,寄存器堆的空间是有限的。当数据矩阵的大小越来越大时,寄存器堆的空间将不敷使用。如何更有效率地管理与使用寄存器堆的空间以便于进行池化操作,是本领域的重要技术课题之一。
技术实现要素:
5.本发明提供一种池化装置与池化方法,以有效率地使用寄存器堆(register file)的空间去进行池化操作。
6.在根据本发明的实施例中,所述池化装置用以对数据矩阵(data matrix)进行池化操作。数据矩阵被划分为多个区块。所述池化装置包括寄存器堆以及执行单元(execution unit,eu)。寄存器堆用以在池化操作的第一批次期间加载数据矩阵的所述多个区块中的至少一个第一区块与至少一个第二区块。执行单元耦接至寄存器堆。寄存器堆
用以在第一批次期间对在寄存器堆中的所述至少一个第一区块与所述至少一个第二区块进行池化操作的第一批次操作。在完成第一批次操作后,寄存器堆在池化操作的第二批次期间舍弃所述至少一个第一区块并且保留所述至少一个第二区块。寄存器堆在第二批次期间加载数据矩阵的所述多个区块中的至少一个第三区块。执行单元在第二批次期间对在寄存器堆中的所述至少一个第二区块与所述至少一个第三区块进行池化操作的第二批次操作。
7.在根据本发明的实施例中,所述池化方法用以对数据矩阵进行池化操作。数据矩阵被划分为多个区块。所述池化方法包括:在池化操作的第一批次期间将数据矩阵的所述多个区块中的至少一个第一区块与至少一个第二区块加载至寄存器堆;在第一批次期间对在寄存器堆中的所述至少一个第一区块与所述至少一个第二区块进行池化操作的第一批次操作;在完成第一批次操作后,在池化操作的第二批次期间舍弃所述至少一个第一区块并且保留所述至少一个第二区块;在第二批次期间将数据矩阵的所述多个区块中的至少一个第三区块加载至寄存器堆;以及在第二批次期间对在寄存器堆中的所述至少一个第二区块与所述至少一个第三区块进行池化操作的第二批次操作。
8.基于上述,依据寄存器堆的有限空间,数据矩阵可以被划分为多个区块,而且一个完整的池化操作可以被划分为多个批次操作。在池化操作的第一批次操作中,第一批次操作所对应的一个或多个区块可以被加载至寄存器堆。考虑到不同批次操作可能会使用到相同的区块(数据元素),在每一个批次操作后,被使用过的一个或多个区块(数据元素)会被保留在寄存器堆中。举例来说,在完成第一批次操作后,第一批次操作与第二批次操作都会用到的一个或多个第二区块会被保留在寄存器堆中,以节省数据传输带宽。然后,第二批次操作会用到的其他区块(一个或多个第三区块)可以被加载至寄存器堆。在寄存器堆中,经第一批次操作使用但是第二批次操作不再需要的一个或多个第一区块会被舍弃,以节省寄存器堆的空间。因此,所述池化装置可以有效率地管理与使用寄存器堆的空间去进行池化操作。
附图说明
9.图1是依照本发明的一实施例的一种池化装置的电路方块(circuit block)示意图。
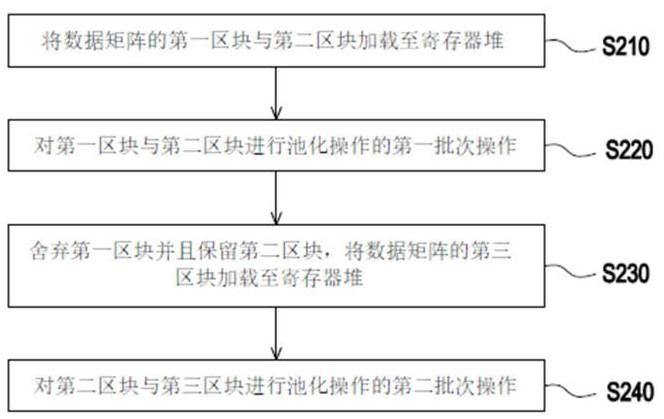
10.图2是依照本发明的一实施例的一种池化方法的流程示意图。
11.图3是依照本发明的另一实施例的一种池化方法的流程示意图。
12.图4是依照本发明的又一实施例的一种池化方法的流程示意图。
13.图5a至图5h是依照本发明的一实施例所绘示,在图4所示流程的不同步骤中池化装置100对的数据矩阵进行池化操作的操作情境示意图。
14.附图标记说明10:系统100:池化装置110:寄存器堆120:执行单元dm:数据矩阵
dm1、dm2、dm3:区块pm:经池化矩阵pw:池化窗口r1~r24:寄存器s210~s240、s310~s350、s410~s470:步骤。
具体实施方式
15.现将详细地参考本发明的示范性实施例,示范性实施例的实例说明于附图中。只要有可能,相同组件符号在附图和描述中用来表示相同或相似部分。
16.在本案说明书全文(包括权利要求)中所使用的“耦接(或连接)”一词可指任何直接或间接的连接手段。举例而言,若文中描述第一装置耦接(或连接)于第二装置,则应该被解释成该第一装置可以直接连接于该第二装置,或者该第一装置可以透过其他装置或某种连接手段而间接地连接至该第二装置。本案说明书全文(包括权利要求)中提及的“第一”、“第二”等用语是用以命名组件(element)的名称,而并非用来限制组件数量的上限或下限,亦非用来限制组件的次序。另外,凡可能之处,在附图及实施方式中使用相同标号的组件/构件/步骤代表相同或类似部分。不同实施例中使用相同标号或使用相同用语的组件/构件/步骤可以相互参照相关说明。
17.作为实例,下述诸实施例可以应用于在图形处理单元上的通用计算(general-purpose computing on graphics processing units,gpgpu)的寄存器堆(register file)的数据管理。举例来说(但不限于此),下述诸实施例可以适用于人工智能(artificial intelligence, ai)的应用场景。下述诸实施例将说明一种池化装置对寄存器堆的数据管理方式,提高了寄存器堆的使用效率,减少了寄存器堆的访问带宽。
18.图1是依照本发明的一实施例的一种池化装置100的电路方块(circuit block)示意图。池化装置100可以对数据矩阵(data matrix,例如张量、图像等)进行池化操作。图1所示池化装置100包括寄存器堆110以及执行单元(execution unit,eu)120。依据寄存器堆110的空间,待池化的数据矩阵可以被划分为多个区块,而且一个完整的池化操作可以被划分为多个批次操作。在所述池化操作的第一批次期间,来自于系统10的数据矩阵的所述多个区块中的至少一个第一区块与至少一个第二区块可以被加载至寄存器堆110。依照实际设计,供数据矩阵的数据元素的来源可以是,系统10的内存(memory)或是其他运算模块(例如另一个执行单元)。
19.执行单元120耦接至寄存器堆110。执行单元120可以在所述第一批次期间对在寄存器堆110中的所述至少一个第一区块与所述至少一个第二区块进行池化操作的第一批次操作。
20.图2是依照本发明的一实施例的一种池化方法的流程示意图。请参照图1与图2。在步骤s210中,基于执行单元120的要求,系统10可以在所述池化操作的第一批次期间将数据矩阵的至少一个第一区块与至少一个第二区块加载至寄存器堆110。待池化的数据矩阵可以被划分为多个区块,而且这些区块的大小可以依据寄存器堆110的空间来决定。在完成加载后,执行单元120可以在所述第一批次期间对在寄存器堆110中的所述至少一个第一区块与所述至少一个第二区块进行池化操作的第一批次操作(步骤s220)。在完成所述第一批次
操作后,寄存器堆110可以在池化操作的第二批次期间舍弃所述至少一个第一区块并且保留所述至少一个第二区块,以及在所述第二批次期间将数据矩阵的至少一个第三区块加载至寄存器堆110(步骤s230)。在步骤s240中,执行单元120可以在所述第二批次期间对在寄存器堆110中的所述至少一个第二区块与所述至少一个第三区块进行池化操作的第二批次操作。若两个批次操作即可完成一个完整的池化操作,则在完成所述第二批次操作后,执行单元120可以产生经池化矩阵(亦即迭代已完整)。若迭代尚未完整,则池化装置100可以对数据矩阵的其他部份进行池化操作的其他批次操作。“对数据矩阵的其他部份进行池化操作的其他批次操作”可以参照步骤s230至步骤s240的相关说明加以类推,故不再赘述。
21.基于上述,依据寄存器堆110的有限空间,数据矩阵可以被划分为多个区块(每一个区块包含一个或多个数据元素),而且一个完整的池化操作可以被划分为多个批次操作。在池化操作的第一批次操作中,第一批次操作所对应的一个或多个区块可以被加载至寄存器堆110。考虑到不同批次操作可能会使用到相同的区块,在每一个批次操作后,被使用过的一个或多个区块可以被保留在寄存器堆110中。举例来说,在完成第一批次操作后,第一批次操作与第二批次操作都会用到的第二区块会被保留在寄存器堆110中,以节省数据传输带宽。然后,第二批次操作会用到的一个或多个其他区块(第三区块)可以被加载至寄存器堆110。在寄存器堆110中,经第一批次操作使用但是第二批次操作不再需要的第一区块会被舍弃(例如,被第三区块所取代/覆写),以节省寄存器堆110的空间。因此,所述池化装置100可以有效率地管理与使用寄存器堆110的空间去进行池化操作。
22.图3是依照本发明的另一实施例的一种池化方法的流程示意图。请参照图1与图3。在进行池化操作前,执行单元120可以先依照数据矩阵的大小、寄存器堆110的大小、池化操作的池化窗口(或称depth slice)的大小以及池化操作的步幅(stride)去计算工坊(workshop)大小,以及依据所述工坊大小分配寄存器堆110的空间给池化操作(步骤s310)。工坊的大小可以依据实际设计来决定。举例来说,在一些实施例中,所述工坊大小的行(row)数大于等于池化操作的池化窗口的行数,以及所述工坊大小的列(column)数大于池化窗口的列数。在另一些实施例中,所述工坊大小的列数大于等于池化窗口的列数,以及所述工坊大小的行数大于池化窗口的行数。在又一些实施例中,工坊的大小可以使用下述等式1来决定。其中,单个寄存器容量取决于硬件设计指标,填充区域数据量取决于池化窗口大小以及计算步长,总数据量或单次加载数据量可以根据硬件资源进行合理规划。在完成工坊大小的计算后,执行单元120可以进行池化操作(步骤s320~s340)。
23.工坊大小=
ꢀꢀꢀꢀꢀꢀ
等式1在步骤s320中,执行单元120可以加载数据至寄存器堆110。举例来说,执行单元120可以将数据矩阵的至少一个第一区块与至少一个第二区块加载至寄存器堆110。在步骤s330中,执行单元120可以对在寄存器堆110中的数据进行池化计算。举例来说,在完成加载后,执行单元120可以在池化操作的第一批次期间对在寄存器堆110中的第一区块与第二区块进行池化操作的第一批次操作。在步骤s340中,执行单元120可以判断迭代是否完整。举例来说,执行单元120可以检查对一个数据矩阵的池化操作的所有批次操作是否完成。当池化操作尚有批次操作未被进行时(步骤s340的判断结果为“否”),执行单元120可以回到步骤s320,以将下一个(或下一批)区块加载至寄存器堆110。当池化操作的所有批次操作都已
完成时(步骤s340的判断结果为“是”),执行单元120可以将池化操作的结果(经池化矩阵)输出给系统10(步骤s350)。
24.图4是依照本发明的又一实施例的一种池化方法的流程示意图。图4所示步骤s410、s420、s440与s450可以参照图3所示步骤s310、s320、s330与s340的相关说明加以类推,故不再赘述。举例来说,执行单元120可以将数据矩阵的至少一个第一区块与至少一个第二区块加载至寄存器堆110。在第一区块与第二区块被加载至寄存器堆110(步骤s420)后,以及在对第一区块与第二区块进行池化操作的第一批次操作(步骤s440)前,寄存器堆110可以对第一区块与第二区块进行数据重排(步骤s430)以符合池化操作的需求。以下将以具体范例说明图4所示池化方法。所谓池化操作的需求包括:硬件在进行池化操作时,需要在行方向或列方向有寄存器编号自增的关系,即成为行连续或者列连续,便于硬件寻址。所述数据重排将以图5c与图5g进行具体范例说明,以便于硬件寻址。
25.图5a至图5h是依照本发明的一实施例所绘示,说明在图4所示流程的不同步骤中池化装置100对的数据矩阵进行池化操作的操作情境示意图。图5a所示系统10以及寄存器堆110可以参照图1所示系统10以及寄存器堆110的相关说明,故不再赘述。请参照图1、图4与图5a。在此假设在系统10中欲进行池化操作的数据矩阵dm是一个6*6矩阵。在数据矩阵dm中,每一个小矩形表示数据矩阵dm的数据元素,而这6*6个小矩形中的数字表示数据矩阵dm的不同位置的数据元素。亦即,这6*6个小矩形中的数字1~36不应限制数据矩阵dm的实际数据元素。待池化的数据矩阵dm可以被划分为多个区块,而且这些区块的大小可以依据寄存器堆110的空间来决定。举例来说,数据矩阵dm可以被划分为区块dm1、区块dm2以及区块dm3,如图5a所示。其中,区块dm1包含数据矩阵dm的第一行与第二行,区块dm2包含数据矩阵dm的第三行与第四行,以及区块dm3包含数据矩阵dm的第五行与第六行。无论如何,数据矩阵dm的划分方式不应受限于图5a所示范例。举例来说,在其他实施例中,区块dm1包含数据矩阵dm的第一列与第二列,区块dm2包含数据矩阵dm的第三列与第四列,以及区块dm3包含数据矩阵dm的第五列与第六列。
26.在进行池化操作前,执行单元120可以先依照数据矩阵dm的大小、寄存器堆110的大小、池化操作的池化窗口的大小以及(或是)池化操作的步幅去计算工坊大小,以及依据所述工坊大小分配寄存器堆110的空间给池化操作(步骤s410)。在图5a至图5h所示实施例中,寄存器堆110被假设依据所述工坊大小将寄存器r1~r24分配给池化操作。
27.请参照图1、图4与图5b。在步骤s420中,执行单元120可以加载数据至寄存器堆110。举例来说,执行单元120可以将数据矩阵dm的至少一个第一区块(例如区块dm1)与至少一个第二区块(例如区块dm2)加载至寄存器堆110的寄存器r1~r24,如图5b所示。在此假设,数据矩阵dm的第一行的数据元素分别被加载至寄存器r1、寄存器r3、寄存器r9、寄存器r11、寄存器r17与寄存器r19,数据矩阵dm的第二行的数据元素分别被加载至寄存器r2、寄存器r4、寄存器r10、寄存器r12、寄存器r18与寄存器r20,数据矩阵dm的第三行的数据元素分别被加载至寄存器r5、寄存器r7、寄存器r13、寄存器r15、寄存器r21与寄存器r23,而数据矩阵dm的第四行的数据元素分别被加载至寄存器r6、寄存器r8、寄存器r14、寄存器r16、寄存器r22与寄存器r24。由于图5b所示寄存器r1~r24的数据摆放方式不适于池化操作的需求,因此寄存器堆110可以在步骤s430中进行数据重排。
28.请参照图1、图4与图5c。寄存器堆110可以在步骤s430对区块dm1与区块dm2进行数
据重排以符合池化操作的需求。在此假设,数据矩阵dm的第一行的数据元素分别被重排至寄存器r1、寄存器r5、寄存器r9、寄存器r13、寄存器r17与寄存器r21,数据矩阵dm的第二行的数据元素分别被重排至寄存器r2、寄存器r6、寄存器r10、寄存器r14、寄存器r18与寄存器r22,数据矩阵dm的第三行的数据元素分别被重排至寄存器r3、寄存器r7、寄存器r11、寄存器r15、寄存器r19与寄存器r23,而数据矩阵dm的第四行的数据元素分别被重排至寄存器r4、寄存器r8、寄存器r12、寄存器r16、寄存器r20与寄存器r24。
29.图5d所示执行单元120可以参照图1所示执行单元120的相关说明,故不再赘述。请参照图1、图4与图5d。在步骤s440中,执行单元120可以对在寄存器堆110的寄存器r1~r24中的数据进行池化计算。举例来说,在完成数据重排后,执行单元120可以在池化操作的第一批次期间对在寄存器堆110的寄存器r1~r24中的区块dm1与区块dm2进行池化操作的第一批次操作。举例来说(但不限于此),执行单元120所进行的池化操作可以被假设是最大池化(max pooling),池化操作的池化窗口pw的大小可以被假设是3*3窗口,而池化操作的步幅可以被假设是2。执行单元120可以对在寄存器r1~r24中的区块dm1与区块dm2进行池化操作的第一批次操作,以产生经池化矩阵pm的部份数据元素(如图5d所示)。在完成第一批次操作后,第一批次操作与第二批次操作都会用到的区块dm2会被保留在寄存器堆110中,以节省数据传输带宽。在寄存器堆110中,经第一批次操作使用但是第二批次操作不再需要的区块dm1会被弃用(覆写),以节省寄存器堆110的空间。
30.在对区块dm1与区块dm2进行池化操作的第一批次操作(步骤s440)后,执行单元120可以判断迭代是否完整(步骤s450)。举例来说,执行单元120可以检查对一个数据矩阵dm的池化操作的所有批次操作是否完成。当数据矩阵dm尚有部份未被进行池化时(步骤s450的判断结果为“否”),执行单元120可以进行步骤s460。在对区块dm1(第一区块)与区块dm2(第二区块)进行池化操作的所述第一批次操作(步骤s440)后,以及在区块dm3(第三区块)被加载至寄存器堆110(步骤s420)前,寄存器堆110可以对区块dm2进行数据重排(步骤s460)。步骤s460可以舍弃区块dm1并且保留区块dm2。
31.请参照图1、图4与图5e。在步骤s460中,寄存器堆110可以对区块dm2进行数据重排,如图5e所示。在此假设,数据矩阵dm的第三行的数据元素分别被重排至寄存器r1、寄存器r3、寄存器r9、寄存器r11、寄存器r17与寄存器r19,而数据矩阵dm的第四行的数据元素分别被重排至寄存器r2、寄存器r4、寄存器r10、寄存器r12、寄存器r18与寄存器r20。寄存器r5、寄存器r7、寄存器r13、寄存器r15、寄存器r21与寄存器r23被用来加载数据矩阵dm的一个新行的数据元素,而寄存器r6、寄存器r8、寄存器r14、寄存器r16、寄存器r22与寄存器r24被用来加载数据矩阵dm的另一个新行的数据元素。
32.在对区块dm2(第二区块)进行数据重排(步骤s460)后,寄存器堆110在池化操作的第二批次期间加载区块dm3(第三区块)(步骤s420)。请参照图1、图4与图5f。在步骤s420中,寄存器堆110可以将数据矩阵dm的区块dm3加载至寄存器堆110,如图5f所示。在此假设,数据矩阵dm的第五行的数据元素分别被加载至寄存器r5、寄存器r7、寄存器r13、寄存器r15、寄存器r21与寄存器r23,而数据矩阵dm的第六行的数据元素分别被加载至寄存器r6、寄存器r8、寄存器r14、寄存器r16、寄存器r22与寄存器r24。由于图5f所示寄存器r1~r24的数据摆放方式不适于池化操作的需求,因此寄存器堆110可以在步骤s430中进行数据重排。
33.在区块dm3(第三区块)被加载至寄存器堆110(步骤s420)后,以及在对区块dm2(第
二区块)与区块dm3(第三区块)进行池化操作的第二批次操作(步骤s440)前,寄存器堆110可以对区块dm2与区块dm3进行数据重排(步骤s430)以符合池化操作的需求。请参照图1、图4与图5g。在此假设,数据矩阵dm的第三行的数据元素分别被重排至寄存器r1、寄存器r5、寄存器r9、寄存器r13、寄存器r17与寄存器r21,数据矩阵dm的第四行的数据元素分别被重排至寄存器r2、寄存器r6、寄存器r10、寄存器r14、寄存器r18与寄存器r22,数据矩阵dm的第五行的数据元素分别被重排至寄存器r3、寄存器r7、寄存器r11、寄存器r15、寄存器r19与寄存器r23,而数据矩阵dm的第六行的数据元素分别被重排至寄存器r4、寄存器r8、寄存器r12、寄存器r16、寄存器r20与寄存器r24。
34.请参照图1、图4与图5h。在完成数据重排(步骤s430)后,执行单元120可以在池化操作的第二批次期间对在寄存器堆110的寄存器r1~r24中的区块dm1与区块dm2进行池化操作的第二批次操作(步骤s440)。执行单元120可以对在寄存器r1~r24中的区块dm2与区块dm3进行池化操作的第二批次操作,以产生经池化矩阵pm的另一部份数据元素(如图5h所示)。在图5a至图5h所示实施例中,在完成第二批次操作后,池化操作的所有批次操作都已完成。当池化操作的所有批次操作都已完成时(步骤s450的判断结果为“是”),执行单元120可以将经池化矩阵pm(池化操作的结果)输出给系统10(步骤s470)。
35.综上所述,数据矩阵dm可以被划分为多个区块(例如区块dm1、dm2与dm3)。依据寄存器堆110的有限空间,一个完整的池化操作可以被划分为多个批次操作。在池化操作的第一批次操作中,第一批次操作所对应的区块dm1与区块dm2可以被加载至寄存器堆110。在对区块dm1与区块dm2完成第一批次操作后,第一批次操作与第二批次操作都会用到的区块dm2会被保留在寄存器堆110中,以节省数据传输带宽。然后,第二批次操作会用到的区块dm3可以被加载至寄存器堆110。在寄存器堆110中,经第一批次操作使用但是第二批次操作不再需要的区块dm1会被舍弃(例如,被区块dm3所取代/覆写),以节省寄存器堆110的空间。因此,所述池化装置100可以有效率地管理与使用寄存器堆110的空间去进行池化操作。
36.依照不同的设计需求,上述执行单元120的实现方式可以是硬件(hardware)、固件(firmware)、软件(software,即程序)或是前述三者中的多者的组合形式。以硬件形式而言,执行单元120可以实现于集成电路(integrated circuit)上的逻辑电路。执行单元120的相关功能可以利用硬件描述语言(hardware description languages,例如verilog hdl或vhdl)或其他合适的编程语言来实现为硬件。举例来说,执行单元120的相关功能可以被实现于一或多个控制器、微控制器、微处理器、特殊应用集成电路(application-specific integrated circuit, asic)、数字信号处理器(digital signal processor, dsp)、场可程序逻辑门阵列(field programmable gate array, fpga)及/或其他处理单元中的各种逻辑区块、模块和电路。以软件形式及/或固件形式而言,执行单元120的相关功能可以被实现为编程码(programming codes)。例如,利用一般的编程语言(programming languages,例如c、c 或汇编语言)或其他合适的编程语言来实现执行单元120。所述编程码可以被记录/存放在「非临时的计算机可读取媒体(non-transitory computer readable medium)」中。在一些实施例中,所述非临时的计算机可读取媒体例如包括带(tape)、碟(disk)、卡(card)、半导体内存、可程序设计的逻辑电路以及(或是)存储装置。所述存储装置包括硬盘(hard disk drive,hdd)、固态硬盘(solid-state drive,ssd)或是其他存储装置。中央处理器(central processing unit,cpu)、控制器、微控制器或微处理器可以从所述非临时的
计算机可读取媒体中读取并执行所述编程码,从而实现执行单元120的相关功能。
37.最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。