1.本发明涉及图像描述生成技术领域,尤其是涉及一种基于编码器-双解码器的图像中文描述生成方法。
背景技术:
2.图像描述生成(image caption)是一个融合计算机视觉、自然语言处理和机器学习的综合问题,它类似于翻译一副图片为一段描述文字,这个任务对于机器来说非常具有挑战性,它不仅需要利用模型去理解图片的内容并且还需要用自然语言去表达它们之间的关系;除此之外,模型还需要能够抓住图像的语义信息,并且生成人类可读的句子。早期的描述生成采用基于简单模板的生成,由对象检测器或属性预测器的输出填充内容。随着深度神经网络的出现,大多数图像描述技术都采用rnn作为语言模型,并使用一层或多层cnn的输出编码视觉信息和条件语言生成。在训练阶段,虽然基于虽然初始方法基于时间交叉熵训练,但引入强化学习取得了显着成就,这使得使用不可微分的标题指标作为优化目标。相反,在图像编码方面,采用单层注意力机制来合并空间知识,最初来自cnn特征网格,然后使用对象检测器提取的图像区域。为了进一步改进对象及其关系的编码,有研究提出在图像编码阶段使用图卷积神经网络来整合对象之间的语义和空间关系;同时使用多模态图卷积网络将场景图调制成视觉表示,但基于rnn的模型容易受到其有限的表示能力和顺序性的影响。
3.卷积语言模型出现后,也被探索用于字幕,新的全注意范式被提出并在机器翻译和语言方面取得了最先进的结果理解任务。因此,现有技术有将transformer模型应用于图像字幕任务中,transformer模型包括一个由一堆自注意力和前馈层组成的编码器,以及一个解码器,该解码器对单词使用自注意力并在最后一个编码器层的输出上使用交叉注意力。目前,使用transformer架构进行图像字幕生成,大多是将类似transformer的编码器与lstm解码器进行配对,但仍存在两个方面的问题:1)无法充分利用编码器获取的特征信息,以用于后续的描述文本生成;2)生成的描述文字描述单一,无法对图像中包含的信息有非常丰富的表达,更遑论去表达图像当中隐含的信息。
技术实现要素:
4.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于编码器-双解码器的图像中文描述生成方法,以充分利用编码器获取的特征信息,能够对图像包含的信息进行丰富描述。
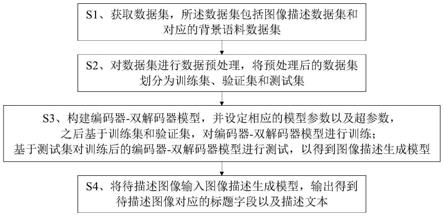
5.本发明的目的可以通过以下技术方案来实现:一种基于编码器-双解码器的图像中文描述生成方法,包括以下步骤:
6.s1、获取数据集,所述数据集包括图像描述数据集和对应的背景语料数据集;
7.s2、对数据集进行数据预处理,将预处理后的数据集划分为训练集、验证集和测试集;
8.s3、构建编码器-双解码器模型,并设定相应的模型参数以及超参数,之后基于训练集和验证集,对编码器-双解码器模型进行训练;
9.基于测试集对训练后的编码器-双解码器模型进行测试,以得到图像描述生成模型;
10.s4、将待描述图像输入图像描述生成模型,输出得到待描述图像对应的标题字段以及描述文本。
11.进一步地,所述步骤s1中图像描述数据集具体为ai-challenger图像描述数据集,所述步骤s1中背景语料数据集具体为wiki2019zh。
12.进一步地,所述步骤s2具体包括以下步骤:
13.s21、对图像描述数据集进行图像格式处理以及图像增强处理;对背景语料数据集进行清洗及分词标注处理;
14.s22、按照设定的比例将预处理后的数据集划分为训练集、验证集和测试集。
15.进一步地,所述步骤s21中对背景语料数据集进行清洗及分词标注处理的具体过程为:首先对句子进行清洗,利用自建的停用词表去除停用词例如句号,逗号、空白字符;
16.之后建立分词词图,获得最大的切分组合;
17.再对中文、英文和数字进行区分并分开处理,最后对分词进行输出和标注。
18.进一步地,所述步骤s22中设定的比例具体为8:1:1。
19.进一步地,所述步骤s3具体包括以下步骤:
20.s31、构建编码器-双解码器模型,其中,编码器用于提取图像中的信息以及信息之间的关联,双解码器用于读取来自编码器输出的信息、并输出对应的描述;
21.s32、基于训练集和验证集,对编码器-双解码器模型进行训练;
22.s33、基于测试集对训练后的编码器-双解码器模型进行测试,并根据设定的评估指标对测试结果进行评估,若评估通过,则当前训练后的编码器-双解码器模型即为图像描述生成模型,否则返回步骤s32。
23.进一步地,所述步骤s31中编码器采用transformer结构,所述双解码器包括依次连接的title-decoder和text-decoder,所述编码器分别与title-decoder、text-decoder相连接,所述title-decoder和text-decoder均采用lstm(long-short term memory,长短期记忆)网络实现。
24.进一步地,所述步骤s33中对训练后的编码器-双解码器模型进行测试时,所述text-decoder的输入包括编码器输出信息、从title-decoder输出中提取得到的关键词信息、来自背景语料库中的信息在attention机制下对于描述文本的整体扩写。
25.进一步地,所述步骤s33中设定的评估指标包括但不限于bleu、meteor、rouge、cider、spice。
26.进一步地,所述步骤s4具体包括以下步骤:
27.s41、输入待描述图像,编码器采用多级自注意力机制提取出图像特征信息;
28.s42、编码器将提取到的所有图像特征信息输入title-decoder中,输出得到待描述图像对应的标题字段;
29.s43、从title-decoder输出的标题字段中提取出关键词信息,结合编码器提取的图像特征信息,共同输入text-decoder中,输出得到待描述图像对应的文本信息;
30.s44、整合title-decoder和text-decoder的输出,以作为待描述图像所包含信息的描述。
31.与现有技术相比,本发明采用编码器-双解码器的架构,其中,编码器引入了transformer中的注意思想进行改进,编码器从图像中提取的特征信息会同时流向双解码器,一方面,编码器能够获取到更加丰富的图像特征信息,另一方面,双编码器能够更加充分地利用从编码器中获取的信息,以用于后续描述文本生成,从而保证描述生成的丰富性和准确性;
32.本发明采用依次连接的title-decoder、text-decoder构造双编码器,并结合背景语料库对训练后的编码器-双解码器模型进行测试,使得text-decoder能够在attention机制的引导下对原始图像信息以及生成的文本关键字进行修正,进而保证输出的文本信息更加丰富,以充分表达出图像中隐含的信息。
附图说明
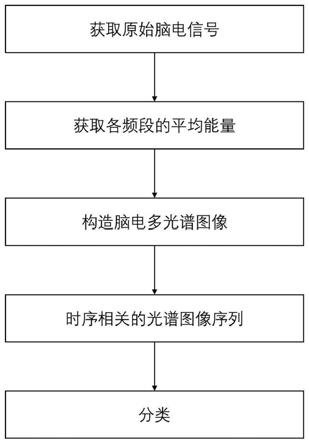
33.图1为本发明的方法流程示意图;
34.图2为本发明中编码器-双解码器的模型结构示意图;
35.图3为实施例中应用过程示意图。
具体实施方式
36.下面结合附图和具体实施例对本发明进行详细说明。
37.实施例
38.如图1所示,一种基于编码器-双解码器的图像中文描述生成方法,包括以下步骤:
39.s1、获取数据集,数据集包括图像描述数据集和对应的背景语料数据集,本实施例中,图像描述数据集具体为ai-challenger图像描述数据集,步骤s1中背景语料数据集具体为wiki2019zh;
40.s2、对数据集进行数据预处理,将预处理后的数据集划分为训练集、验证集和测试集,具体的:
41.对图像描述数据集进行图像格式处理以及图像增强处理;对背景语料数据集进行清洗及分词标注处理(首先对句子进行清洗,利用自建的停用词表去除停用词例如句号,逗号、空白字符;之后建立分词词图,获得最大的切分组合;再对中文、英文和数字进行区分并分开处理,最后对分词进行输出和标注);
42.按照设定的比例将预处理后的数据集划分为训练集、验证集和测试集,本实施例中,设定的比例具体为8:1:1;
43.s3、构建编码器-双解码器模型,并设定相应的模型参数以及超参数,之后基于训练集和验证集,对编码器-双解码器模型进行训练;
44.基于测试集对训练后的编码器-双解码器模型进行测试,以得到图像描述生成模型;
45.具体的:
46.s31、构建编码器-双解码器模型,如图2所示,其中,编码器用于提取图像中的信息以及信息之间的关联,双解码器用于读取来自编码器输出的信息、并输出对应的描述,本实
施例中,编码器采用transformer结构,双解码器包括依次连接的title-decoder和text-decoder,编码器分别与title-decoder、text-decoder相连接,title-decoder和text-decoder均采用lstm网络实现;
47.s32、基于训练集和验证集,对编码器-双解码器模型进行训练;
48.s33、基于测试集对训练后的编码器-双解码器模型进行测试,并根据设定的评估指标对测试结果进行评估,若评估通过,则当前训练后的编码器-双解码器模型即为图像描述生成模型,否则返回步骤s32;
49.在对训练后的编码器-双解码器模型进行测试时,text-decoder的输入包括编码器输出信息、从title-decoder输出中提取得到的关键词信息、来自背景语料库中的信息在attention机制下对于描述文本的整体扩写;
50.s4、将待描述图像输入图像描述生成模型,输出得到待描述图像对应的标题字段以及描述文本,具体的:
51.s41、输入待描述图像,编码器采用多级自注意力机制提取出图像特征信息;
52.s42、编码器将提取到的所有图像特征信息输入title-decoder中,输出得到待描述图像对应的标题字段;
53.s43、从title-decoder输出的标题字段中提取出关键词信息,结合编码器提取的图像特征信息,共同输入text-decoder中,输出得到待描述图像对应的文本信息;
54.s44、整合title-decoder和text-decoder的输出,以作为待描述图像所包含信息的描述。
55.本实施例应用上述技术方案,如图3所示,主要包括以下过程:
56.步骤a:准备好数据集,包括图像描述数据集和与之相应的背景语料数据集,分别是ai-challenger图像描述数据集(本实施例选择其中的image-caption数据集)和中文语料维基百科json版(wiki2019zh),考虑到本技术方案针对图像生成短文描述为中文,因此图像描述数据集采用ai-challenger图像描述数据集;与之对应的背景语料库则采用通用的中文语料维基百科json版(wiki2019zh)来做预训练的语料,选用不同的背景语料库,得到的文本描述会有相应语料库语言的风格,因此如果有想要文本描述的风格,可以使用的相应的语料集作为此处的背景语料库,本发明中使用的与图像描述数据集对应的语料集;
57.步骤b:将数据集切分为训练集、验证集和测试集,并作必要的数据预处理,具体为:
58.b1:图像描述数据集包含的预处理包括图像格式处理以及图像增强处理;
59.用于预训练的背景预料数据集的处理包括:首先对句子进行清洗,利用自建的停用词表去除停用词例如句号,逗号、空白字符等,然后建立分词词图,获得最大的切分组合,然后对中文、英文和数字进行区分并分开处理,最后分词进行输出和标注;
60.b2:按照8∶1∶1的比例将数据集划分为训练集、验证集、测试集,这样可使模型首先接受训练集的大量训练,再通过验证集调整参数最后在测试集上进行测试评估;
61.步骤c:设定好模型的参数及超参数,利用训练集和验证集对编码器-双解码器模型进行训练;本发明构建的编码器-双解码器模型总体来说被分为两部分:编码器用于提取图像中的信息以及信息之间的关联,解码器读取来自编码器中的信息并逐字输出描述句子;
62.c1:编码器采用transformer结构来实现,给定从输入图像中提取的一组图像特征i,可以通过transformer中使用的self-attention来获得x的排列不变性编码:
[0063][0064]
q=wqi,k=wki,v=w
vi[0065]
其中,wq,wk,wv均为需要学习的权重矩阵,q是查询向量;《k,v》是一组对应的数据对;d是比例系数因子;self-attention的输出被应用于一个位置前馈层,该层由两个具有单一非线性的仿射变换组成,它们独立地应用于图像集合中的每个元素,利用公式可以表达为:
[0066]
ffn(i)i=uσ(vii b) c
[0067]
其中,ii表示输入集的第i个向量;ffn(i)i就表示第i向量的输出;σ(
·
)表示relu函数;u,v表示需要学习的权重矩阵;b,c表示偏置项。
[0068]
self-attention和位置前馈层作为一个组件被封装在一个残差连接和一个归一化层中,因此一个编码层的完整定义可写为:
[0069]
z=addnorm(self_attention(i))
[0070][0071]
其中,addnorm表示残差连接和归一化层的操作。然后对于整个编码器来说,是由多个上述的编码层依次堆叠而成的,因此第i层的输入是第i-1层计算的输出,这就相当于创建图像特征之间关系的多级编码,其中更高层的编码层可以利用和改进先前层已经识别的关系,最终相当于利用先验知识,可以更充分的综合得出图像的特征信息。因此,n个编码层堆叠的多级输出可以表示为:
[0072]
c2:title-decoder和text-decoder均采用lstm网络来实现,其中title-decoder在每一时间步t的状态可表示为:
[0073][0074][0075]
其中,y
title
表示title-decoder的输出;
[0076]
text-decoder在每一时间步t的状态可表示为:
[0077][0078][0079]
其中,t
t-1
是上一时间状态下从title-decoder输出的title描述提取的关键词信息;c
t-1
是上一时间状态下从预训练背景语料库中获取的权重信息向量;y
title
表示text-decoder的输出。因此模型解码器的输出是整合title-decoder和text-decoder的输出,即
[0080][0081]
c3:本实施例采用词级交叉熵损失(xe)函数对模型进行预训练,并使用强化学习微调序列生成。当用xe训练时,模型被训练以预测给定先前真实词的下一个标记;在这种情况下,解码器的输入序列立即可用,整个输出序列的计算可以一次性完成,随着时间的推移并行化所有操作;
[0082]
c4:在使用强化学习进行训练时,使用beam-search采样的序列上采用self-critical序列训练方法的变体:为了解码,在每个时间步从解码器概率分布中采样前k个单词,并始终保持最高概率的前k个序列。由于序列解码在此步骤中是迭代的,因此无法利用上述随时间推移的并行性。但是,用于计算时间t输出token的中间键和值可以在下一次迭代中重复使用;
[0083]
c5:使用奖励的平均值所做的贪婪解码来作为奖励的基线,实验证明它稍微提高了最终性能。因此,样本更新的梯度表达式为:
[0084][0085]
其中,wi是beam中第i个句子;r(
·
)是奖励函数;b=(∑ir(wi))/k是baseline,指计算为采样序列获得的奖励的平均值;
[0086]
c6:模型实验中参数的设置:将每层的维数设为512,head数设为8;在每个self-attention和位置前馈层之后使用保持概率0.8的dropout层来避免模型过拟合;使用xe进行预训练时使用下述公式中的学习率的调度策略:
[0087][0088]
其中,warmup_steps初始迭代设为10000;模型中batch-size均为50,beam-size均为5,优化器采用adam。
[0089]
步骤d:利用测试集对训练好的模型进行评估测试;具体地:
[0090]
d1:待模型训练结束之后,会在测试集上进行验证,其中text-decoder模型的输出会受到背景语料数据集的影响;
[0091]
d2:text-decoder模型的预测来源有三部分:1)编码器输出的结构;2)title-decoder模型的输出中提取的关键词信息;3)来自背景语料库中的信息在attention机制下对于描述文本的整体扩写。其中,此处的attention机制的更新由参数来完成,该参数可视为当前关键词的话级重要性权重,此处语义控制单元的输入是一个词语覆盖向量c
t
,初始化为一个k维向量,k是title-decoder层的输出关键词的数量,每个值为1.0,即c0=[1.0,...,1.0],在时间步t时,c
t
的计算方式如下:
[0092][0093]
其中,α
t,j
是在时间步t时当前关键词的权重;
[0094]
d3:模型评估采用的评估指标主要为bleu、meteor、rouge、cider、spice等,在进行模型评估或者模型对比实验时可以选择其中一种或几种来做参考标准。本实施例使用cider-d分数作为评估指标,并在使用其优化期间,使用固定为5
×
10-6
的学习率。
[0095]
步骤e:输入任意图片到模型编码器结构中,通过title-decoder输出该图像的标
题字段,通过text-decoder输出描述短文本,结合两者的输出,作为对该图像所包含信息的短文描述,详细地:
[0096]
e1:输入图像,编码器采用多级自注意力机制提取图像特征信息;
[0097]
e2:提取到的所有特征信息输入title-decoder中,然后输出该图像的标题字段;
[0098]
e3:然后再次从title-decoder中提取关键词信息,结合编码器中提取的图像特征信息,共同输入text-decoder中,生成一段短文;
[0099]
e4:整合title-decoder和text-decoder的输出,作为对该图像所包含信息的标题 描述文本。
[0100]
综上可知,本技术方案设计了一种双层解码器的架构,改进了图像编码器和语言解码器的设计,引入了transformer中的注意思想来对编码器进行改进,获取的特征信息会同时流向两层编码器,具有以下优势:
[0101]
(1)编码器模块采用transformer中的注意思想图像可以比传统cnn网络获取到更丰富的信息;
[0102]
(2)模型采用双解码器模块,一是可以更加充分地利用从编码器中获取的信息用于后续描述文本生成;二是采用背景语料库对模型进行预训练后,在attention机制的引导下对模型原始图像信息以及生成的文本关键字进行修正,最终生成一段比较长的描述文本;
[0103]
(3)经实验证明,本发明中的模型从评估指标上来说可以取得更好的效果,具有准确率高、语句含义丰富通顺、图像与文本相关性强的优点。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。