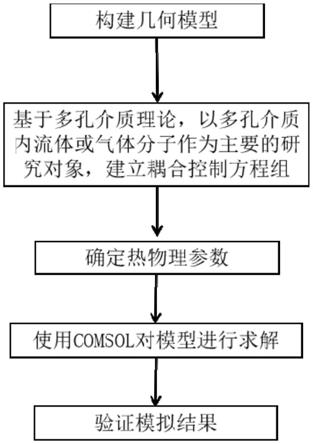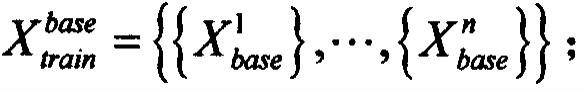
1.本发明涉及表面缺陷分类技术领域,尤其涉及一种基于轻量化网络的小样本钢材表面缺陷分类方法。
背景技术:
2.热轧带钢等钢材在制造生产过程中会不同程度的出现夹渣、划痕、氧化皮等缺陷。其表面缺陷不仅直接降低生产效率,影响生产效益,更会导致最终成品的耐腐蚀性和耐磨性变差。因此,实时高效表面缺陷检测任务已成为钢材生产领域的重要研究课题。
3.钢材表面产品质量检测,通常涉及多个类别的缺陷检测,属于多类别分类任务。传统的缺陷检测方法包含人工目检法和抽样检测。但在高速生产且复杂板面的情况下,质检人员难以有效抓取识别重点、关注有效缺陷,并因视觉疲劳而产生误检、漏检。
4.机器视觉以非接触式、无损检测技术,具有分辨率高、普适性强,成本低等特点,在钢材表面缺陷检测中受到极大关注,成为当前领域的热门研究方案。基于传统的机器学习算法通过人工特征提取,利用svm(support vector machine)等分类器判别缺陷种类。但传统机器学习算法对人工特征依赖性强、表征能力弱,受环境、复杂纹理背景影响较大,检测效率低下。随着深度学习算法的成熟,基于cnn(convolutional neural network)的分类网络已成为表面缺陷检测领域的主流方案。
5.但在实际工业生产中,仍存在着卷积神经网络参数量大,计算成本高,模型难以部署等问题。同时缺陷样本难以采集,样本数据量少,缺陷类别不均衡等实际问题也亟待解决。
技术实现要素:
6.针对现有技术的以上缺陷或改进需求,本发明提出一种基于轻量化网络的小样本钢材表面缺陷分类方法。其目的在于通过改进后的轻量化网络解决模型参数量大的问题,满足实际工业部署和识别分类实时性需求,提高缺陷分类精度。同时,提出离线随机数据增强算法,扩充缺陷数据,解决样本数据量小、类别不均衡等问题。
7.本发明综合检测方式的实现,包括以下步骤:
8.步骤1:原始小样本数据集划分为训练集x
train
={{x1},
…
,{xn}}和测试集x
test
={{x1},
…
,{xn}},对训练集x
train
进行离线随机数据增强,获得钢材缺陷分类扩充数据集x
′
train
,其中n为缺陷类别个数。
9.进一步地,所述离线随机数据增强具体方法为:
10.步骤1.1:将训练集x
train
={{x1},
…
,{xn}}中的每一类缺陷数据分类采样,采样区域在图像p*p范围内随机生成且不超出,采用随机多尺度采样,采样大小在至中随机选取,生成子样本集其中m,k分别为样本个数,p为原始样本尺寸;
11.步骤1.2:将训练集x
train
中的样本分别以概率p1,p2执行水平翻转和垂直翻转,获得增强后的基础数据集
12.步骤1.3:子样本集中的各类别样本分别在基础数据集的相应类别中执行叠加操作,覆盖原始样本的任意区域,进而获得缺陷分类扩充数据集x
′
train
={{x1′
},
…
{xn′
}};
13.步骤2:缺陷样本数据预处理;
14.进一步地,所述数据预处理将扩充数据集x
′
train
和原始数据集x
train
执行同类别混合,生成可训练数据集生成的数据集中不同类别之间的缺陷样本量相同,可有效解决样本不均衡问题,表达式为:
[0015][0016]
步骤3:选取轻量化基准网络,搭建基于通道混洗和注意力加权的缺陷分类网络模型;
[0017]
进一步地,所述轻量化基准网络选取了以倒残差结构单元为基础的mobilenetv2,网络输入大小为320*320。
[0018]
进一步地,所述基于通道混洗和注意力加权的缺陷分类网络模型包含两部分,带有通道混洗的倒残差网络优化单元和psa注意力加权模块;通道混洗操作连接于每个倒残差模块之后;psa注意力加权模块置于最后一层特征提取层与全局池化网络层中间,输出通道级的加权特征。
[0019]
进一步地,所述带有通道混洗的倒残差网络优化单元的具体构成是:倒残差模块输出特征f
inver
经通道混洗单元获得特征图f
shuffle
,特征流入组卷积层并输出f
out
,设置组卷积的卷积核k和分组数g;
[0020]
进一步地,所述psa注意力加权模块由spc多尺度特征提取模块和seweight权重模块组成。spc多尺度特征提取模块经提取获得特征f
spc
,seweight权重模块生成通道加权权重att
se
,输出加权特征为out
psa
:
[0021]
out
psa
=f
spc
⊙
att
se
[0022]
其中,
⊙
表示乘积操作;
[0023]
进一步地,所述spc多尺度特征提取将输入特征f
in
分成s组别,不同组别使用多尺度卷积核生成多尺度特征最后级联方式输出总特征f
spc
,表达如下:
[0024][0025][0026]
其中,表示f
in
中的一组特征;
[0027]
进一步地,所述seweight权重模块表达式为:
[0028][0029][0030]
步骤4:选取交叉熵损失函数为缺陷分类网络的分类损失函数;
[0031]
步骤5:搭建整体分类网络,设置网络训练超参数,包括优化器、学习率、权重衰减系数、动量系数、权重初始化方式。
[0032]
进一步地,所述网络训练超参数中,优化器选择sgd算法,学习率lr随迭代次数epoch更新,学习率计算表达式为:
[0033]
lr=lr
src
*0.1
(epoch//30)
[0034]
其中,lr
src
表示学习率初始值,//表示取余操作;
[0035]
进一步地,权重衰减系数为0.0001、动量系数为0.9、网络层以xavier方法实现权重初始化。
[0036]
步骤6:训练网络,执行缺陷分类任务,评估网络分类性能,计算准确率、召回率、f1指数、模型参数量和计算复杂度,输出缺陷图像对应的缺陷分类结果。
[0037]
进一步地,所述网络分类性能通过准确率p,召回率r和f1指数f1评估网络模型在测试集的分类效果,通过模型参数量params和计算复杂度macs评估模型复杂度,表达式如下:
[0038]
p=tp/(tp fp)
[0039]
r=tp/(tp fn)
[0040][0041]
其中,tp为真正例,fp为假正例,fn为假负例。
[0042]
由上述技术方案可知,本发明的有益效果在于:本发明提出的基于轻量化的小样本钢材表面缺陷分类方法提出了离线数据增强算法,扩充缺陷数据集,使不同类别缺陷样本平衡化。同时,针对轻量化网络提出的带有通道混洗和注意力加权的缺陷分类网络模型,增加组间信息交流,自适应标定特征权重,促使网络聚焦于关键的缺陷特征,执行速度快,检测精度高,模型计算量小,满足实际场景中的工业化需求。
附图说明
[0043]
为更好的解释说明本发明的技术流程,下面使用一些附图对技术进行简单的介绍。
[0044]
图1为本发明总体流程图;
[0045]
图2为离线数据增强样本数据示意图;
[0046]
图3为基于通道混洗和注意力加权的缺陷分类网络模型示意图;
[0047]
图4为psa注意力加权模块示意图;
[0048]
图5为spc多尺度特征提取模块示意图;
具体实施方式
[0049]
下面结合附图对本发明的技术方案进一步详细描述。
[0050]
首先就本发明的技术术语进行解释和说明:
[0051]
mobilenetv2:2018年提出的高效移动端部署网络,引入线性瓶颈和倒残差来提高网络表征能力,显著减少推理期间所需的内存占用,实时性和精度得到较好的平衡。
[0052]
通道混洗:提出于旷视科技的一种计算高效的shufflenet模型,主要解决通道稀
疏连接方式,对特征进行重组,促进组间信息流转,增强信息交流。
[0053]
seweight:imagenet 2017竞赛image classification任务冠军使用的senet中首次提出,通过学习自动获取每个特征通道的权重值,提升重要特征通道比重,抑制无效通道比重,实现特征重标定。
[0054]
psa注意力加权:于2021年epsanet网络首次提出,充分利用多尺度特征图的空间信息,丰富特征空间,提供强有力的多尺度特征表征能力,轻量且高效。
[0055]
参照图1,本实施例提供的一种基于轻量化网络的小样本钢材表面缺陷分类方法包括以下步骤:
[0056]
本实施例中,以x-sdd带钢缺陷数据集为基础开展实验,共有1360幅图像,7种缺陷类别。其中精轧辊印203幅、杂质238幅、铁皮灰122幅,板块系氧化铁皮63幅,温度系氧化铁皮203幅,红铁皮397幅,划痕134幅,为典型的小样本不均衡数据集。
[0057]
步骤1:原始小样本数据集划分为训练集x
train
={{x1},
…
,{xn}}和测试集x
test
={{x1},
…
,{xn}},对训练集x
train
进行离线随机数据增强,获得钢材缺陷分类扩充数据集x
′
train
,其中n为7个缺陷类别;
[0058]
本实施例中,训练集与测试集按照8∶2比例划分,x
train
包含1086幅图像,x
test
包含274幅。
[0059]
步骤1.1:将训练集x
train
={{x1},
…
,{xn}}中的每一类缺陷数据分类采样,采样区域在图像128*128范围内随机生成且不超出,并且采用随机多尺度采样,采样大小在40*40、50*50和60*60中随机选取,生成子样本集其中m,k分别为样本个数;
[0060]
步骤1.2:将训练集x
train
中的样本分别以概率0.5,0.5执行水平翻转和垂直翻转,获得增强后的基础数据集
[0061]
步骤1.3:子样本集中的各类别样本分别在基础数据集的相应类别中执行叠加操作,覆盖原始样本的任意区域,进而获得缺陷分类扩充数据集x
′
train
={{x1′
},
…
{xn′
}}。
[0062]
本实施例中,离线数据增强样本数据如图2,构建的数据集s
train
样本为2-1、样本数据为2-2、x
′
train
样本为2-3。
[0063]
步骤2:缺陷样本数据预处理。
[0064]
本实施例中,数据预处理将扩充数据集x
′
train
和原始数据集x
train
的同类别缺陷数据进行混合,生成可训练数据集表达式为:
[0065][0066]
其中,数据集中的7类缺陷样本数量均为300幅,使得缺陷样本平衡化。
[0067]
步骤3:选取轻量化基准网络,搭建基于通道混洗和注意力加权的缺陷分类网络模型。
[0068]
本实施例中,选取以倒残差结构单元为基础的mobilenetv2作为轻量化基础网络,调整网络输入大小为320*320。所述通道混洗和注意力加权的缺陷分类网络模型包含两部分,带有通道混洗的倒残差网络优化单元和psa注意力加权模块;通道混洗操作连接于每个
倒残差模块之后;psa注意力加权模块置于最后一层特征提取层与全局池化网络层中间,输出通道级的加权特征。基于通道混洗和注意力加权的缺陷分类网络模型如图3,其中3-1表示的是步长值为1的带有通道混合的倒残差网络优化单元,3-2表示步长值为2的带有通道混合的倒残差网络优化单元。
[0069]
本实施例中,所述带有通道混洗的倒残差网络优化单元具体构成为:倒残差模块输出特征f
inver
经通道混洗单元获得特征图f
shuffle
,特征流入下一网络组卷积层并输出f
out
,设置组卷积的卷积核大小为3和分组数为2。
[0070]
所述psa注意力加权模块如图4,由spc多尺度特征提取模块(如图5)和seweight权重模块组成。spc多尺度特征提取模块经提取获得特征f
spc
,seweight权重模块生成通道加权权重att
se
,输出加权特征为out
psa
:
[0071]
out
psa
=f
spc
⊙
att
se
[0072]
其中,
⊙
表示乘积操作;
[0073]
所述spc多尺度特征提取将输入特征f
in
分成s=3组,不同组别使用的卷积核分别为3、5和7,生成多尺度特征最后级联方式输出总特征f
spc
,表达如下:
[0074][0075][0076]
其中,表示f
in
中的一组特征;
[0077]
所述seweight权重模块表达式为:
[0078][0079][0080]
步骤4:选取缺陷分类网络的分类损失函数。
[0081]
本实施例中,以交叉熵损失函数作为分类损失函数。
[0082]
步骤5:搭建整体分类网络,设置网络训练超参数,包括优化器、学习率、权重衰减系数、动量系数、权重初始化方式。
[0083]
本实施例中,优化器选择sgd算法,学习率lr随迭代次数epoch更新,学习率计算表达式为:
[0084]
lr=lr
src
*0.1
(epoch//30)
[0085]
其中,学习率初始值lr
src
为0.1,//表示取余操作;
[0086]
权重衰减系数0.0001、动量系数为0.9、网络层以xavier方法实现权重初始化。
[0087]
步骤6:训练网络,执行缺陷分类任务,评估网络分类性能,计算准确率、召回率、f1指数、模型参数量和计算复杂度,输出缺陷图像对应的缺陷分类结果。
[0088]
本实施例中,所述网络分类性能在测试集的分类效果为:准确率p为95.97%,召回率r为95.22%,f1指数为95.47%。在网络模型方面,模型参数量params仅为6.5m,计算复杂度macs为0.54g。
[0089]
p=tp/(tp fp)
[0090]
r=tp/(tp fn)
[0091][0092]
其中,tp为真正例,fp为假正例,fn为假负例。
[0093]
最后应说明的是,以上步骤仅用以说明本发明的技术方案而非限制,但本领域技术人员应当理解,可以在形式上和细节上对其做出相应的改变,但进行的改变,并不应使相应技术方案的本质脱离本发明的技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。