1.本发明涉及网络自然语言处理技术领域,具体来说是一种证券行业敏感公告检测方法。
背景技术:
2.随着信息披露在证券行业领域重要性不断提高,公告披露数量成倍增加,敏感公告的检查复杂度也大大提高。
3.通用做法有人工审查,但人工审查员的效率较低,不足以在短时间内检测大量公告。
4.还有对于关键词做限制的做法,首先要维护一套关键词词库,这种做法一方面受限于低级关键词检测算法的效率,另一方面无法判断上下文及语义上的深层含义,导致漏判敏感公告。
5.低级关键词检测算法:关键词检测技术的底层都涉及字符串的匹配,在字符串匹配问题上,通用的常见方法有以下这些:brute-force 算法、kmp 算法、基于有限状态机的正则表达式匹配等方法,以上方法也应用于现在许多生产场景之下。
6.这些方法在敏感公告检测中有其明显缺陷,在需要匹配的关键词增多时,检测耗时与关键词数量呈线性关系增加,关键词检测效率低。
7.一些深度学习模型的检测方法能够进行词相似性计算和句子的敏感性判别,但计算耗时成本大。
8.采用串行架构有流程阻塞问题,导致全流程总耗时长,影响了应用系统之间的交互效率。
技术实现要素:
9.本发明提供了一种证券行业敏感公告检测方法,以通过算法提升关键词检测效率、机器学习模型补判、提高系统交互效率等手段,旨在高效检测敏感公告,提高应用交互的效率。
10.为了实现上述目的,设计一种证券行业敏感公告检测方法,其特征在于先通过基于前缀树的dfa算法对关键词进行快速检测,检测完毕后先进行发布,满足了信息披露的快速要求,发布后通过机器学习模型进行补判,进行发布后检测处理。
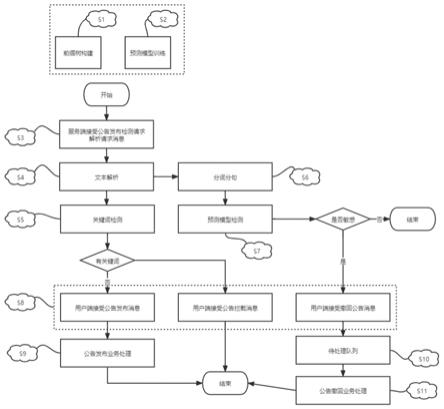
11.方法具体如下:s1: 前缀树构建模块,构建前缀树读取的词典以txt文本格式维护了一套基础关键词词库;s2: 预测模型训练,采用两个预测模型,一个句子级别的预测模型和一个词汇级别的预测模型;s3: 敏感公告检测服务端解析上游应用的公告检测请求,得到公告文件及其他业务信息;
s4:文件解析;s5: 关键词检测,关键词检测基于dfa算法,总体上只做了遍历全文本做状态判定的操作,如果检测通过无关键词,则向消息队列发出公告发布消息,下游应用系统接收消息,执行公告发布业务,如果检测不通过,含有关键词,则向消息队列发出公告拦截消息,下游应用系统接收消息停止公告发布业务,不通过的公告信息被保存用以后续分析和训练;s6: 分词、分句, 文本经过分词,去除停用词,表示为词的集合,将待检测词的集合和敏感词库的词分别生成拼音,用于识别同音不同字的情形;s7:预测模型检测,将词与拼音的集合、句的集合分别输入词汇级别预测模型和语句级别预测模型,若模型都返回非敏感,则检测结束,若任一模型判断为敏感公告,则向消息队列发出撤回公告发布消息,下游应用接收消息,执行撤回公告发布业务,被判断为敏感公告的信息被保存用以后续分析和训练;s8: 消息队列, 在架构上,上下游应用系统通过消息队列接收检测服务端发布的公告检测结果,对于敏感公告,服务端存储公告信息,用于以后的训练与分析,进一步强化服务端的检测能力;s9: 若关键词检测通过则进行公告发布业务;需要执行撤回公告发布的任务,进入待处理队列等待;若模型判断公告不通过,且已通过关键词检测,则进行撤回公告发布业务。
12.进一步地,设计一种上述证券行业敏感公告检测方法的检测系统,包括根据关键词词库构建前缀树、对不同格式的文件做文本解析、对文本做关键词扫描、发送公告检测结果消息、文本分词后输入模型补判、根据补判结果重发结果消息,系统上各应用系统之间,采用消息队列的方式进行通信,实现异步解耦。
13.本发明同现有技术相比,其优点在于:1.相比较已有的敏感词检测方法,既保证了在超长文本、大量敏感词库的情况下的敏感词检测效率,原有的业务快速披露的及时性得到了保证,同时相近语义下敏感词被检测的准确率和覆盖面又得到了提升,兼顾了快速与准确;2.应用采用消息队列作为与其他应用系统的交互方式,降低了应用系统之间的耦合度,提高了系统的可用性,以及多任务的处理能力;3.加入预测模型,提升了语义层面的敏感词检测能力;4.发布事后补判的架构流程保证了检测的时效性;5.对检测出敏感公告的信息收集记录,用于分析和训练,提高以后的检测能力;6.通过算法提升关键词检测效率、机器学习模型补判、提高系统交互效率等手段,实现高效检测敏感公告,提高应用交互的效率。
附图说明
14.图1是本发明敏感公告检测方法及服务端的流程示意图。
具体实施方式
15.下面结合附图对本发明作进一步说明,本发明的结构和原理对本专业的人来说是非常清楚的。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发
明。
16.本发明为一种证券行业敏感公告检测方法,总体流程是是先通过基于前缀树的dfa算法对关键词进行快速检测,检测完毕后先进行发布,满足了信息披露的快速要求。发布后通过机器学习模型进行补判,进行发布后检测处理。
17.架构上包含多模块,包括根据关键词词库构建前缀树、对不同格式的文件做文本解析、对文本做关键词扫描、发送公告检测结果消息、文本分词后输入模型补判、根据补判结果重发结果消息。
18.具体方法如下:s1:前缀树构建模块构建前缀树读取的词典以txt文本格式维护了一套基础关键词词库。
19.敏感词树是用来存储大量字符串的前缀树,是n叉树的一种特殊形式。前缀树除了根节点,其他每一个节点的状态都是一个字符串或者是一个字符串的前缀,同时每个节点都包含一个字符。从前缀树的根节点到某一节点上,将经过的字符连接起来就是该节点所对应的字符串,并且每个节点包含的字符都不同。
20.前缀树在压缩空间的同时达到了高效查询的目的,相比把每个敏感关键词字符串都做哈希处理存储在内存中,前缀树利用节点保存了公共前缀。在一棵构建完成的前缀树中查询一个长度为m的字符串的复杂度为o(m)。
21.s2:预测模型训练本发明中用到了两个经过微调的(fine-tuned)预测模型,一个句子级别的预测模型和一个词汇级别的预测模型。
22.在本发明的特定场景使用时,做词汇相似度计算和句子敏感性的判断,只需要简单地修改一些输出层,再用已整理的的数据进行一个增量训练,对权重进行一个轻微的调整。
23.随着技术的发展,如有其它的效果好的预测模型也可以随时替换,在输出时遵循事先定义好的接口规范,可以做到无缝切换。
24.s3:敏感公告检测服务端解析上游应用的公告检测请求,得到公告文件及其他业务信息。
25.s4:文件解析文件主要为pdf文件或microsoft的word格式,文件有不同格式、版本和结构,解析模块覆盖多种情况进行文字内容的抽取。
26.解析出来的文本带有一些特殊字符,影响程序判断,故进行清洗过滤操作。
27.s5:关键词检测关键词检测基于dfa算法。dfa(deterministic finite automaton,即确定有穷自动机)。其原理为:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,dfa中不会有从同一状态出发的两条边标志有相同的符号。
28.当前状态记录为是否是某个字符位置开始的后缀,动作为下一字符是不是当前字符的后继字符。
29.对待检测的公告文本,基于关键词已经构造成前缀树,用dfa算法做检测,总体上
只做了遍历全文本做状态判定的操作,大大提升了关键词检测效率。
30.如果检测通过无关键词,则向消息队列发出公告发布消息,下游应用系统接收消息,执行公告发布业务。
31.如果检测不通过,含有关键词,则向消息队列发出公告拦截消息,下游应用系统接收消息停止公告发布业务。
32.不通过的公告信息被保存用以后续分析和训练。
33.s6:分词、分句文本经过分词,去除停用词,表示为词的集合,将待检测词的集合和敏感词库的词分别生成拼音,用于识别同音不同字的情形。
34.对于一些涉及行业及政策的专有名词,可通过人工维护,优化分词效果。
35.通过标点符号、段落分隔符等句子分割的规则将文章的文字进行切分,表示为句的集合。
36.s7:预测模型检测将词与拼音的集合、句的集合分别输入词汇级别预测模型和语句级别预测模型。
37.此部分耗时较关键词检测耗时长。
38.若模型都返回非敏感,则检测结束。
39.若任一模型判断为敏感公告,则向消息队列发出撤回公告发布消息,下游应用接收消息,执行撤回公告发布业务。
40.被判断为敏感公告的信息被保存用以后续分析和训练。
41.s8:消息队列在架构上,上下游应用系统通过消息队列接收检测服务端发布的公告检测结果,对于敏感公告,服务端存储公告信息,用于以后的训练与分析,进一步强化服务端的检测能力。
42.s9:若关键词检测通过则进行公告发布业务。
43.s10:需要执行撤回公告发布的任务,进入待处理队列等待。
44.s11:若模型判断公告不通过,且已通过关键词检测,则进行撤回公告发布业务。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。