技术特征:
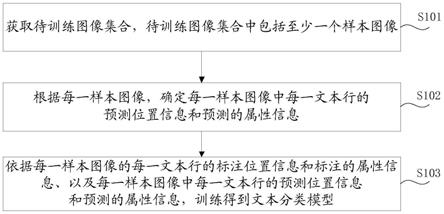
1.一种文本分类模型的训练方法,包括:获取待训练图像集合,所述待训练图像集合中包括至少一个样本图像,每一样本图像的每一文本行具有标注位置信息和标注的属性信息,所述属性信息表征文本行中的文本为手写文本或者印刷文本;根据每一样本图像,确定每一样本图像中每一文本行的预测位置信息和预测的属性信息;依据每一样本图像的每一文本行的标注位置信息和标注的属性信息、以及每一样本图像中每一文本行的预测位置信息和预测的属性信息,训练得到文本分类模型,其中,所述文本分类模型用于检测待识别图像中每一文本行的属性信息。2.根据权利要求1所述的方法,其中,根据每一样本图像,确定每一样本图像中每一文本行的预测位置信息和预测的属性信息,包括:根据每一样本图像,确定每一样本图像的特征图,并根据每一样本图像的特征图生成每一样本图像的各文本框,其中,文本框中包括样本图像中的文本行中的文本内容;根据每一文本行的文本框确定每一文本行的预测位置信息,并根据每一文本行所归属的样本图像的特征图、以及每一文本行的预测位置信息确定每一文本行的预测的属性信息。3.根据权利要求2所述的方法,其中,根据每一文本行所归属的样本图像的特征图、以及每一文本行的预测位置信息确定每一文本行的预测的属性信息,包括:根据每一文本行的预测位置信息确定每一文本行的初始属性信息;根据每一文本行所归属的样本图像的特征图确定每一文本行的前景区域和背景区域,并根据每一文本行的前景区域和背景区域,对每一文本行的初始属性信息进行修正处理,得到每一文本行的预测的属性信息。4.根据权利要求3所述的方法,其中,前景区域中包括前景像素信息,背景区域中包括背景像素信息;根据每一文本行的前景区域和背景区域,对每一文本行的初始属性信息进行修正处理,得到每一文本行的预测的属性信息,包括:根据每一文本行的前景像素信息和背景像素信息,对每一文本行的背景区域进行背景区域抑制处理,得到每一文本行的抑制处理后的背景像素信息;根据每一文本行的前景像素信息以及抑制处理后的背景像素信息,对每一文本行的初始属性信息进行修正处理,得到每一文本行的预测的属性信息。5.根据权利要求2至4中任一项所述的方法,其中,根据每一文本行的文本框确定每一文本行的预测位置信息,包括:获取每一文本行的文本框的每一角点的角点位置信息;根据每一文本行的各角点位置信息确定每一文本行的文本框的中心位置信息,并确定每一文本行的文本框的中心位置信息为每一文本行的预测位置信息。6.根据权利要求1至5中任一项所述的方法,其中,依据每一样本图像的每一文本行的标注位置信息和标注的属性信息、以及每一样本图像中每一文本行的预测位置信息和预测的属性信息,训练得到文本分类模型,包括:获取每一样本图像的每一文本行的标注位置信息与预测位置信息两者之间的损失信息,并获取每一样本图像的每一文本行的标注的属性信息与预测的属性信息两者之间的损
失信息;根据每一样本图像的每一文本行的标注位置信息与预测位置信息两者之间的损失信息、以及每一样本图像的每一文本行的标注的属性信息与预测的属性信息两者之间的损失信息,进行监督学习处理,训练得到所述分类模型。7.根据权利要求1至6中任一项所述的方法,其中,获取待训练图像集合,包括:获取采集到的每一样本图像的像素信息,并确定各样本图像的像素信息的共同像素;根据所述共同像素对每一样本图像的像素进行归一化处理,并基于归一化处理后的各样本图像构建所述待训练图像集合。8.一种文本类型的分类方法,包括:获取待分类图像,基于预先训练的文本分类模型对所述待分类图像进行分类处理,得到所述待分类图像中每一文本行的属性信息;其中,所述属性信息表征文本行中的文本为手写文本或者印刷文本,所述文本分类模型是基于如权利要求1-7中任一项所述的方法训练生成的。9.一种文本内容的识别方法,包括:获取待识别图像,基于预先训练的文本分类模型对所述待识别图像中的每一文本行进行分类处理,得到所述每一文本行的属性信息,其中,所述属性信息表征文本行中的文本为手写文本或者印刷文本,所述文本分类模型是基于如权利要求1-7中任一项所述的方法训练生成的;根据所述每一文本行的属性信息获取用于识别所述每一文本行的文本识别模型,并基于所述每一文本行的文本识别模型对所述每一文本行进行文本识别处理,得到并输出所述待识别图像的文本内容。10.根据权利要求9所述的方法,其中,所述文本识别模型包括手写文本识别模型和印刷文本识别模型;属性信息为手写文本的文本行的文本识别模型为手写文本识别模型;属性信息为印刷文本的文本行的文本识别模型为印刷文本识别模型。11.一种文本分类模型的训练装置,包括:第一获取单元,用于获取待训练图像集合,所述待训练图像集合中包括至少一个样本图像,每一样本图像的每一文本行具有标注位置信息和标注的属性信息,所述属性信息表征文本行中的文本为手写文本或者印刷文本;确定单元,用于根据每一样本图像,确定每一样本图像中每一文本行的预测位置信息和预测的属性信息;训练单元,用于依据每一样本图像的每一文本行的标注位置信息和标注的属性信息、以及每一样本图像中每一文本行的预测位置信息和预测的属性信息,训练得到文本分类模型,其中,所述文本分类模型用于检测待识别图像中每一文本行的属性信息。12.根据权利要求11所述的装置,其中,所述确定单元,包括:第一确定子单元,用于根据每一样本图像,确定每一样本图像的特征图;生成子单元,用于根据每一样本图像的特征图生成每一样本图像的各文本框,其中,文本框中包括样本图像中的文本行中的文本内容;第二确定子单元,用于根据每一文本行的文本框确定每一文本行的预测位置信息;第三确定子单元,用于根据每一文本行所归属的样本图像的特征图、以及每一文本行
的预测位置信息确定每一文本行的预测的属性信息。13.根据权利要求12所述的装置,其中,所述第三确定子单元,包括:获取模块,用于根据每一文本行的预测位置信息确定每一文本行的初始属性信息;第三确定模块,用于根据每一文本行所归属的样本图像的特征图确定每一文本行的前景区域和背景区域;修正模块,用于根据每一文本行的前景区域和背景区域,对每一文本行的初始属性信息进行修正处理,得到每一文本行的预测的属性信息。14.根据权利要求13所述的装置,其中,前景区域中包括前景像素信息,背景区域中包括背景像素信息;所述修正模块,包括:抑制子模块,用于根据每一文本行的前景像素信息和背景像素信息,对每一文本行的背景区域进行背景区域抑制处理,得到每一文本行的抑制处理后的背景像素信息;修正子模块,用于根据每一文本行的前景像素信息以及抑制处理后的背景像素信息,对每一文本行的初始属性信息进行修正处理,得到每一文本行的预测的属性信息。15.根据权利要求12至14中任一项所述的装置,其中,所述第二确定子单元,包括:获取模块,用于获取每一文本行的文本框的每一角点的角点位置信息;第三确定模块,用于根据每一文本行的各角点位置信息确定每一文本行的文本框的中心位置信息;第四确定模块,用于确定每一文本行的文本框的中心位置信息为每一文本行的预测位置信息。16.根据权利要求11至15中任一项所述的装置,其中,所述训练单元,包括:第一获取子单元,用于获取每一样本图像的每一文本行的标注位置信息与预测位置信息两者之间的损失信息;第二获取子单元,用于获取每一样本图像的每一文本行的标注的属性信息与预测的属性信息两者之间的损失信息;学习子单元,用于根据每一样本图像的每一文本行的标注位置信息与预测位置信息两者之间的损失信息、以及每一样本图像的每一文本行的标注的属性信息与预测的属性信息两者之间的损失信息,进行监督学习处理,训练得到所述分类模型。17.根据权利要求11至16中任一项所述的装置,其中,所述第一获取单元,包括:第三获取子单元,用于获取采集到的每一样本图像的像素信息;第四确定子单元,用于确定各样本图像的像素信息的共同像素;处理子单元,用于根据所述共同像素对每一样本图像的像素进行归一化处理;构建子单元,用于基于归一化处理后的各样本图像构建所述待训练图像集合。18.一种文本类型的分类装置,包括:第二获取单元,用于获取待分类图像;第一分类单元,用于基于预先训练的文本分类模型对所述待分类图像进行分类处理,得到所述待分类图像中每一文本行的属性信息;其中,所述属性信息表征文本行中的文本为手写文本或者印刷文本,所述文本分类模型是基于如权利要求11至17中任一项所述的装置训练生成的。19.一种文本内容的识别装置,包括:
第三获取单元,用于获取待识别图像;第二分类单元,用于基于预先训练的文本分类模型对所述待识别图像中的每一文本行进行分类处理,得到所述每一文本行的属性信息,其中,所述属性信息表征文本行中的文本为手写文本或者印刷文本,所述文本分类模型是基于如权利要求11-17中任一项所述的装置训练生成的;第四获取单元,用于根据所述每一文本行的属性信息获取用于识别所述每一文本行的文本识别模型;识别单元,用于基于所述每一文本行的文本识别模型对所述每一文本行进行文本识别处理,得到并输出所述待识别图像的文本内容。20.根据权利要求19所述的装置,其中,所述文本识别模型包括手写文本识别模型和印刷文本识别模型;属性信息为手写文本的文本行的文本识别模型为手写文本识别模型;属性信息为印刷文本的文本行的文本识别模型为印刷文本识别模型。21.一种电子设备,包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行权利要求1-7中任一项所述的方法;或者,以使所述至少一个处理器能够执行权利要求8所述的方法;或者,以使所述至少一个处理器能够执行权利要求9或10所述的方法。22.一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行根据权利要求1-7中任一项所述的方法;或者,所述计算机指令用于使所述计算机执行根据权利要求8所述的方法;或者,所述计算机指令用于使所述计算机执行根据权利要求9或10所述的方法。23.一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现权利要求1-7中任一项所述方法的步骤;或者,该计算机程序被处理器执行时实现权利要求8所述方法的步骤;或者,该计算机程序被处理器执行时实现权利要求9或10所述方法的步骤。
技术总结
本公开提供了一种文本分类模型的训练方法、文本内容的识别方法及装置,涉及人工智能技术领域,具体为深度学习、计算机视觉技术领域,可应用于光学字符识别、文字识别等场景,训练方法包括:获取待训练图像集合,待训练图像集合中包括至少一个样本图像,根据每一样本图像,确定每一样本图像中每一文本行的预测位置信息和预测的属性信息,依据每一样本图像的每一文本行的标注位置信息和标注的属性信息、以及每一样本图像中每一文本行的预测位置信息和预测的属性信息,训练得到文本分类模型,文本分类模型用于检测待识别图像中每一文本行的属性信息,提高训练的准确性,使得在基于文本分类模型对文本行的属性信息进行确定时,提高分类的可靠性。高分类的可靠性。高分类的可靠性。
技术研发人员:刘珊珊 乔美娜 吴亮 吕鹏原 范森 章成全 姚锟
受保护的技术使用者:北京百度网讯科技有限公司
技术研发日:2021.11.26
技术公布日:2022/2/28
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。