1.本发明涉及人工智能技术领域,尤其涉及一种低延迟闪存应用于模型的迁移学习系统及方法。
背景技术:
2.近年来,自然语言处理(nlp)中基于transformer的语言模型在大规模计算、大型数据集以及用于训练这些模型的高级算法和软件的推动下,取得了快速的进步。具有大量参数、更多数据和更多训练时间的语言模型可以获得更丰富、更细致的语言理解,能在许多nlp任务和数据集上获得了较高的准确性,具体应用包括摘要、自动对话生成、翻译、语义搜索和代码自动完成。
3.但是,这些nlp的代表大模型中的参数数量以指数速度增长,模型大小从2018年的elmo(376mb)到2021年的megatron-turningnlg(2.1tb),三年时间模型大小增加了5000多倍,而目前单个gpu最大的内存是英伟达a100的80gb,远远小于megatron-turningnlg的模型大小。
4.现有技术中的做法是把模型进行切分,在节点内进行张量切片,在节点间进行管道并行,在280台以上的dgxa100服务器上进行并行训练。一台dgxa100的零售价格大概为20万美金,总硬件成本达到了5600万美金,价格十分昂贵,而且这样的方法还有另外两个缺点,跨节点之间的通信降低了总的计算效率;管道并行需要大批量、粗粒度并行和完美的负载平衡,这在现有技术中是难以达到的。
技术实现要素:
5.本发明的技术问题是提供一种低延迟闪存应用于模型的迁移学习系统及方法,能够利用外部存储器存储大模型权重,在单节点内实现大模型的迁移学习。
6.为实现上述目的,本发明采取的技术方案为:
7.低延迟闪存应用于模型的迁移学习系统,包括:第一外部存储器、第二外部存储器、总处理器和若干数据处理器;第一外部存储器和第二外部存储器通过总处理器中的连接装置连接数据处理器;或第一外部存储器和第二外部存储器直接连接数据处理器;第一外部存储器,用于存储模型训练数据;第二外部存储器,用于存储模型权重;数据处理器,用于进行模型训练。
8.进一步地,数据处理器内设置有内部存储单元,内部存储单元用于存储训练中的中间数据,中间数据包括激活和梯度。
9.进一步地,低延迟闪存应用于模型的迁移学习系统还包括交换机,第一外部存储器和第二外部存储器通过交换机直接连接数据处理器。
10.进一步地,第一外部存储器为mlcnand;第二外部存储器为低延迟ssd。
11.进一步地,数据处理器为gpu,gpu的数量为八个。
12.低延迟闪存应用于模型的迁移学习方法,包括以下步骤:s1获取输入数据,输入数
据包括模型训练数据和模型权重;s2通过前向计算与后向计算更新第二外部存储器中的权重并迭代进行模型训练;s3在迭代的次数超过预设的阈值时,迭代结束。
13.进一步地,s2包括:s21 gpu获取第i层(i=1,2,3
……
j)的权重和输入后,计算得到第i层的激活,并存入内部存储单元;s22 gpu获得第i 1层的权重后,从内部存储单元读取第i层的激活作为第i 1层的输入,gpu计算得到第i 1层的激活,依次类推完成一次前向计算;s23 gpu获得第j层的权重,从内部存储单元读取第j层的激活,计算得到第j层的梯度和第j层更新后的权重,将第j层梯度存入内部存储单元,将第j层更新后的权重写入低延迟ssd;s24 gpu获得第j-1层的权重后,从内部存储单元读取第j-1层的激活和第j层的梯度,计算得到第j-1层的梯度和第j-1层更新后的权重,将第j-1层梯度存入内部存储单元,将第j-1层更新后的权重写入低延迟ssd,依次类推,完成一次后向计算;s25根据更新后的权重,迭代执行s21至s24。
14.进一步地,单次迭代的时间由gpu的算力和低延迟ssd的读带宽决定。
15.进一步地,gpu之间采用数据并行的方式连接。
附图说明
16.通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明及其特征、外形和优点将会变得更加明显。在全部附图中相同的标记指示相同的部分。并未刻意按照比例绘制附图,重点在于示出本发明的主旨。
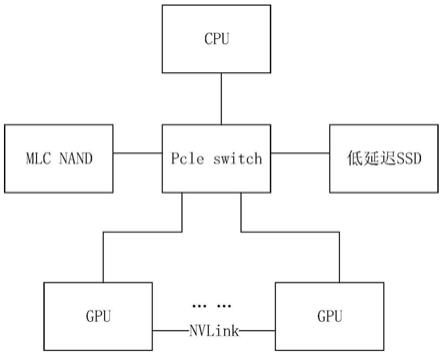
17.图1是本发明提供的低闪存应用于大模型的迁移学习系统的简要结构示意图;
18.图2是本发明提供的内部存储单元与模型的batch size关系图;
19.图3是本发明提供的低延迟ssd的读带宽最大需求与模型的batch size的关系图
具体实施方式
20.下面结合附图和具体的实施例对本发明作进一步的说明,但是不作为本发明的限定。
21.本发明提供的低闪存应用于模型的迁移学习系统,主要针对大模型,如图1所示,包括:第一外部存储器、第二外部存储器、总处理器、交换机和若干数据处理器;第一外部存储器为mlcnand,第二外部存储器为低延迟ssd,数据处理器为gpu,具体有8个gpu。mlc nand和cpu均通过交换机pcle switch连接gpu,gpu之间通过nvlink高速通信,低延迟ssd通过交换机pcle switch直接连接gpu,在gpu和低延迟ssd之间构建了一条直接的通路,从而避免额外的存储复制开销,提高gpu内存的使用寿命,降低模型的训练时间,提高gpu的运算速度。
22.我们将大模型的权重存储在定制的低延迟ssd中,作为迁移学习的训练数据存放在高密度的mlc nand中,这部分数据将以读操作为主,不需要额外增加endurance。在训练的前向计算中,大模型的权重会从第一层到最后一层开始从低延迟nand向gpu streaming,与此同时,gpu通过gpudirect从mlc nand读取数据样本。其中gpu之间采用数据并行的方式,这样从mlc nand读到的8*n个数据样本会被平分给8个gpu,每个gpu一次获取n个数据样本。在训练的后向计算中,大模型的权重会从最后一层到第一层向gpu stream。具体实施时,首先获取输入数据,输入数据包括模型训练数据和模型权重;接着,gpu获取第i层(i=
1,2,3
……
j)的权重和输入后,计算得到第i层的激活,并存入内部存储单元;gpu获得第i 1层的权重后,从内部存储单元读取第i层的激活作为第i 1层的输入,gpu计算得到第i 1层的激活,依次类推完成一次前向计算;然后gpu获得第j层的权重,从内部存储单元读取第j层的激活,计算得到第j层的梯度和第j层更新后的权重,将第j层梯度存入内部存储单元,将第j层更新后的权重写入低延迟ssd;gpu获得第j-1层的权重后,从内部存储单元读取第j-1层的激活和第j层的梯度,计算得到第j-1层的梯度和第j-1层更新后的权重,将第j-1层梯度存入内部存储单元,将第j-1层更新后的权重写入低延迟ssd,依次类推,完成一次后向计算;最后根据更新后的权重,迭代执行上述操作,直到迭代的次数超过预设的阈值时,迭代结束。单次迭代的时间由gpu的算力和低延迟ssd的读带宽决定。
23.由图2可知,gpu中内部存储单元的大小是由训练的batch size(训练数据量)所决定的,batch size越大,需要存储的激活越多,内部存储单元就越大。由于带宽=模型权重/(batch size/算力),batch size的大小同样会影响对低延迟ssd读带宽的要求,此外batch size太小又会影响模型的精度。根据图2与图3,本发明能够取到合适的batch size,使gpu内部存储单元的容量足够运行,又能满足带宽需求,且batch size不会过小,从而影响模型的精度,即本发明能够在单节点内实现大模型的迁移学习。例如,系统使用a100的gpu,单个gpu最大内存80gb,8个gpu最大内存为640gb,最大算力312teraflop/s,对于1trillion model,若batch size取值为64,则满足上述要求。
24.本发明通过利用低延迟闪存存储大模型权重,牺牲一部分数据retention来换取更高的endurance方法,从而在单节点内实现大模型的迁移学习(训练),将硬件需求从几百台多卡gpu服务器降低到单台服务器,硬件成本从几千万美金降低到十万美金左右,仅仅通过单台8卡a100 gpu服务器就能实现万亿模型的训练。此外,因为没有分布式计算的需求,通信的开销大大降低,算力的利用率显著提升。
25.以上对本发明的较佳实施例进行了描述;需要理解的是,本发明并不局限于上述特定实施方式,其中未尽详细描述的设备和结构应该理解为用本领域中的普通方式予以实施;任何熟悉本领域的技术人员,在不脱离本发明技术方案作出许多可能的变动和修饰,或修改为等同变化的等效实施例,这并不影响本发明的实质内容;因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均仍属于本发明技术方案保护的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。