tanh和sigmoid函数执行
相关技术
1.机器学习在解决许多种类的任务方面已经是成功的。当训练和使用机器学习算法(例如,神经网络)时产生的计算自然地适合于高效的并行实现。因此,诸如通用图形处理单元(gpgpu)之类的并行处理器已在深度神经网络的实际实现中扮演了重要角色。具有单指令多线程(simt)架构的并行图形处理器被设计成使图形流水线中的并行处理的量最大化。在simt架构中,成组的并行线程尝试尽可能频繁地一起同步地执行程序指令以增加处理效率。由并行机器学习算法实现方式提供的效率允许使用高容量网络并且使得可对较大的数据集训练那些网络。
2.深度学习神经网络(dnn)典型地被构造为某种类型的卷积神经网络,并且被用来执行复杂的联结式任务。在使用已知输入的训练阶段之后,dnn能够识别与原始训练输入类似的新输入。这有助于对象检测技术、自动语音识别、用户认证、图像理解、以及机器视觉使用等等。
3.新兴的网络演变趋于使用较少的矩阵计算操作,诸如,用于卷积的小型片(1x1)或依赖于较简单的2d卷积,例如,在efficientnet(高效网络)中的逐深度可分离卷积。结果是性能瓶颈将转移到复杂的激活函数。
附图说明
4.图1是根据实施例的处理系统的框图。
5.图2a-图2d图示由本文中描述的实施例提供的计算系统和图形处理器。
6.图3a-图3c图示由本文中描述的实施例提供的附加的图形处理器和计算加速器架构的框图。
7.图4是根据一些实施例的图形处理器的图形处理引擎的框图。
8.图5a-图5b图示根据本文中描述的实施例的线程执行逻辑,该线程执行逻辑包括在图形处理器核中采用的处理元件的阵列。
9.图6图示根据实施例的附加的执行单元。
10.图7是图示根据一些实施例的图形处理器指令格式的框图。
11.图8是图形处理器的另一实施例的框图。
12.图9a是图示根据一些实施例的图形处理器命令格式的框图。
13.图9b是图示根据实施例的图形处理器命令序列的框图。
14.图10图示根据一些实施例的数据处理系统的示例性图形软件架构。
15.图11a是图示根据实施例的可用于制造集成电路以执行操作的ip核开发系统的框图。
16.图11b图示根据本文中描述的一些实施例的集成电路封装组件的截面侧视图。
17.图11c图示封装组件,该封装组件包括连接到衬底的多个单元的硬件逻辑小芯片。
18.图11d图示根据实施例的包括可互换小芯片的封装组件。
19.图12、图13a和图13b图示根据本文中所述的各实施例的可以使用一个或多个ip核
制造的示例性集成电路和相关联的图形处理器。
20.图14描绘线性变换的示例,该线性变换后跟激活函数。
21.图15描绘示例系统,在该示例系统中,编译器可生成用于至少tanh和sigmoid的指令以供由着色器执行单元执行。
22.图16描绘可由各实施例使用的示例系统。
23.图17描绘用于执行tanh指令的数学流水线的操作的示例。
24.图18a和图18b描绘可在各实施例中被使用以执行二次方程的示例系统。
25.图19描绘根据各实施例的用于tanh计算的输入范围和输出范围的示例。
26.图20描绘用于执行tanh操作的示例过程。
27.图21描绘根据各实施例的用于sigmoid计算的输入范围和输出范围的示例。
28.图22描绘用于执行sigmoid操作的示例过程。
具体实施方式
29.在以下描述中,出于解释的目的,阐述了众多特定细节以提供对下文所描述的本发明的实施例的透彻理解。然而,对本领域技术人员将显而易见的是,可在没有这些特定细节中的一些细节的情况下实施本发明的实施例。在其他实例中,以框图形式示出公知的结构和设备,以避免使本发明的实施例的基本原理变得模糊。
30.各实施例为开发人员提供了请求tanh指令和sigmoid指令的执行的指令。例如,编译器可生成原生tanh指令以执行tanh。在一些实施例中,tanh函数可被编译为三条指令,包括:用于取决于输入的值而执行tanh(输入)或tanh(输入)/输入以生成中间输出的指令;用于基于输入而引起执行比例因子的生成的指令;以及用于引起执行对中间结果与比例因子的乘法操作的指令。对于sigmoid函数,可生成并执行专用指令以使数学流水线执行范围校验,并基于范围来执行操作。例如,数学流水线对于范围[2-20
,16)和范围(-16,-2-20
]可执行二次逼近。对于其余范围,输出可被钳制到固定值,以在不损害准确度的情况下节省成本。系统概览
[0031]
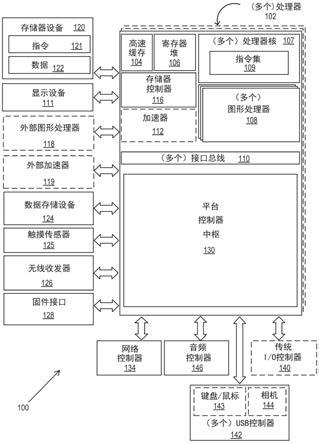
图1是根据实施例的处理系统100的框图。系统100可被用在以下各项中:单处理器台式机系统、多处理器工作站系统、或具有大量处理器102或处理器核107的服务器系统。在一个实施例中,系统100是被并入在芯片上系统(soc)集成电路内的处理平台,该芯片上系统(soc)集成电路用于在移动设备、手持式设备或嵌入式设备中使用,诸如,用于在具有至局域网或广域网的有线或无线连接性的物联网(iot)设备内使用。
[0032]
在一个实施例中,系统100可包括以下各项,可与以下各项耦合,或可并入在以下各项内:基于服务器的游戏平台、包括游戏和媒体控制台的游戏控制台、移动游戏控制台、手持式游戏控制台或在线游戏控制台。在一些实施例中,系统100是移动电话、智能电话、平板计算设备或移动互联网连接的设备(诸如,具有低内部存储容量的笔记本)的部分。处理系统100也可包括以下各项,与以下各项耦合,或被集成在以下各项内:可穿戴设备,诸如,智能手表可穿戴设备;利用增强现实(ar)或虚拟现实(vr)特征来增强以提供视觉、音频或触觉输出来补充现实世界视觉、音频或触觉体验或以其他方式提供文本、音频、图形、视频、全息图像或视频、或触觉反馈的智能眼镜或服装;其他增强现实(ar)设备;或其他虚拟现实(vr)设备。在一些实施例中,处理系统100包括电视机或机顶盒设备,或者是电视机或机顶
盒设备的部分。在一个实施例中,系统100可包括自动驾驶运载工具,与自动驾驶运载工具耦合,或集成在自动驾驶运载工具中,该自动驾驶运载工具诸如,公共汽车、拖拉机拖车、汽车、电机或电力循环、飞机或滑翔机(或其任何组合)。自动驾驶运载工具可使用系统100来处理在该运载工具周围感测到的环境。
[0033]
在一些实施例中,一个或多个处理器102各自都包括用于处理器指令的一个或多个处理器核107,这些指令当被执行时,执行用于系统或用户软件的操作。在一些实施例中,一个或多个处理器核107中的至少一个被配置成处理特定的指令集109。在一些实施例中,指令集109可促进复杂指令集计算(cisc)、精简指令集计算(risc)或经由超长指令字(vliw)的计算。一个或多个处理器核107可处理不同的指令集109,不同的指令集109可包括用于促进对其他指令集的仿真的指令。处理器核107也可包括其他处理设备,诸如,数字信号处理器(dsp)。
[0034]
在一些实施例中,处理器102包括高速缓存存储器104。取决于架构,处理器102可具有单个内部高速缓存或多级的内部高速缓存。在一些实施例中,高速缓存存储器在处理器102的各种组件之间被共享。在一些实施例中,处理器102也使用外部高速缓存(例如,第3级(l3)高速缓存或末级高速缓存(llc))(未示出),可使用已知的高速缓存一致性技术在处理器核107之间共享该外部高速缓存。寄存器堆106可附加地被包括在处理器102中,并且寄存器堆106可包括用于存储不同类型的数据的不同类型的寄存器(例如,整数寄存器、浮点寄存器、状态寄存器以及指令指针寄存器)。一些寄存器可以是通用寄存器,而其他寄存器可专用于处理器102的设计。
[0035]
在一些实施例中,一个或多个处理器102与一个或多个接口总线110耦合,以在处理器102与系统100中的其他组件之间传输通信信号,诸如,地址、数据、或控制信号。在一个实施例中,接口总线110可以是处理器总线,诸如,直接媒体接口(dmi)总线的某个版本。然而,处理器总线不限于dmi总线,并且可包括一个或多个外围组件互连总线(例如,pci、pci express)、存储器总线或其他类型的接口总线。在一个实施例中,(多个)处理器102包括集成存储器控制器116和平台控制器中枢130。存储器控制器116促进存储器设备与系统100的其他组件之间的通信,而平台控制器中枢(pch)130提供经由本地i/o总线至i/o设备的连接。
[0036]
存储器设备120可以是动态随机存取存储器(dram)设备、静态随机存取存储器(sram)设备、闪存设备、相变存储器设备、或具有适当的性能以充当进程存储器的某个其他存储器设备。在一个实施例中,存储器设备120可以作为用于系统100的系统存储器来操作,以存储数据122和指令121供在一个或多个处理器102执行应用或进程时使用。存储器控制器116也与任选的外部图形处理器118耦合,该任选的外部图形处理器118可与处理器102中的一个或多个图形处理器108通信以执行图形操作和媒体操作。在一些实施例中,可由加速器112辅助图形操作、媒体操作或计算操作,该加速器112是可被配置用于执行专业的图形操作、媒体操作或计算操作的集合的协处理器。例如,在一个实施例中,加速器112是用于优化机器学习或计算操作的矩阵乘法加速器。在一个实施例中,加速器112是光线追踪加速器,该光线追踪加速器可用于与图形处理器108一致地执行光线追踪操作。在一个实施例中,可替代加速器112使用外部加速器119,或可与加速器112一致地使用外部加速器119。
[0037]
在一些实施例中,显示设备111可以连接至(多个)处理器102。显示设备111可以是
以下各项中的一项或多项:内部显示设备,如在移动电子设备或膝上型设备中;或经由显示接口(例如,显示端口、嵌入式显示端口、mipi、hdmi等)附接的外部显示设备。在一个实施例中,显示设备111可以是头戴式显示器(hmd),诸如,用于在虚拟现实(vr)应用或增强现实(ar)应用中使用的立体显示设备。
[0038]
在一些实施例中,平台控制器中枢130使外围设备能够经由高速i/o总线而连接至存储器设备120和处理器102。i/o外围设备包括但不限于音频控制器146、网络控制器134、固件接口134、无线收发器126、触摸传感器125、数据存储设备124(例如,非易失性存储器、易失性存器、硬盘驱动器、闪存、nand、3d nand、3d xpoint等)。数据存储设备124可以经由存储接口(例如,sata)或经由如外围组件互连总线(例如,pci、pci express)之类的外围总线来进行连接。触摸传感器125可以包括触摸屏传感器、压力传感器、或指纹传感器。无线收发器126可以是wi-fi收发器、蓝牙收发器、或移动网络收发器,该移动网络收发器诸如3g、4g、5g或长期演进(lte)收发器。固件接口134使得能够与系统固件进行通信,并且可以例如是统一可扩展固件接口(uefi)。网络控制器134可启用到有线网络的网络连接。在一些实施例中,高性能网络控制器(未示出)与接口总线110耦合。在一个实施例中,音频控制器146是多声道高清音频控制器。在一个实施例中,系统100包括用于将传统(例如,个人系统2(ps/2))设备耦合至系统的任选的传统i/o控制器140。平台控制器中枢130还可以连接至一个或多个通用串行总线(usb)控制器142连接输入设备,诸如,键盘和鼠标143组合、相机144、或其他usb输入设备。
[0039]
将会理解,所示的系统100是示例性的而非限制性的,因为也可以使用以不同方式配置的其他类型的数据处理系统。例如,存储器控制器116和平台控制器中枢130的实例可以集成到分立的外部图形处理器中,该分立的外部图形处理器诸如外部图形处理器118。在一个实施例中,平台控制器中枢130和/或存储器控制器116可以在一个或多个处理器102外部。例如,系统100可包括外部存储器控制器116和平台控制器中枢130,该外部存储器控制器116和平台控制器中枢130可以被配置为在与(多个)处理器102通信的系统芯片组内的存储器控制器中枢和外围控制器中枢。
[0040]
例如,可使用电路板(“橇板(sled)”),在该电路板上被放置的组件(诸如,cpu、存储器和其他组件)经设计以实现提升的热性能。在一些示例中,诸如处理器之类的处理组件位于橇板的顶侧上,而诸如dimm之类的附近存储器位于橇板的底侧上。作为由该设计提供的增强的气流的结果,组件能以比典型系统更高的频率和功率等级来操作,由此增加性能。此外,橇板配置成盲配机架中的功率和数据通信线缆,由此增强它们被快速地移除、升级、重新安装和/或替换的能力。类似地,位于橇板上的各个组件(诸如,处理器、加速器、存储器和数据存储设备)由于它们相对于彼此增加的间距而被配置成易于升级。在说明性实施例中,组件附加地包括用于证明它们的真实性的硬件认证特征。
[0041]
数据中心可利用支持多个其他网络架构的单个网络结构(“结构”),多个其他网络架构包括以太网和全方位路径。橇板可经由光纤耦合至交换机,这提供比典型的双绞线布线(例如,5类、5e类、6类等)更高的带宽和更低的等待时间。由于高带宽、低等待时间的互连和网络架构,数据中心在使用中可集中在物理上解散的诸如存储器、加速器(例如,gpu、图形加速器、fpga、asic、神经网络和/或人工智能加速器等)和数据存储驱动器之类的资源,并且根据需要将它们提供给计算资源(例如,处理器),从而使计算资源能够就好像被集中
的资源在本地那样访问这些被集中的资源。
[0042]
功率供应或功率源可将电压和/或电流提供给系统100或本文中描述的任何组件或系统。在一个示例中,功率供应包括用于插入到墙壁插座中的ac-dc(交流-直流)适配器。此类ac功率可以是可再生能量(例如,太阳能)功率源。在一个示例中,功率源包括dc功率源,诸如,外部ac-dc转换器。在一个示例中,功率源或功率供应包括用于通过接近充电场来充电的无线充电硬件。在一个示例中,功率源可包括内部电池、交流供应、基于动作的功率供应、太阳能功率供应、或燃料电池源。
[0043]
图2a-图2d图示由本文中描述的实施例提供的计算系统和图形处理器。图2a-图2d的具有与本文中的任何其他附图的元件相同的附图标记(或名称)的那些元件能以类似于本文中其他地方描述的任何方式操作或起作用,但不限于此。
[0044]
图2a是处理器200的实施例的框图,该处理器200具有一个或多个处理器核202a-202n、集成存储器控制器214以及集成图形处理器208。处理器200可包括附加的核,这些附加的核多至由虚线框表示的附加核202n并包括由虚线框表示的附加核202n。处理器核202a-202n中的每一个包括一个或多个内部高速缓存单元204a-204n。在一些实施例中,每一个处理器核也具有对一个或多个共享高速缓存单元206的访问权。内部高速缓存单元204a-204n和共享高速缓存单元206表示处理器200内的高速缓存存储器层级结构。高速缓存存储器层级结构可包括每个处理器核内的至少一个级别的指令和数据高速缓存以及一级或多级共享的中级高速缓存,诸如,第2级(l2)、第3级(l3)、第4级(l4)、或其他级别的高速缓存,其中,在外部存储器之前的最高级别的高速缓存被分类为llc。在一些实施例中,高速缓存一致性逻辑维持各高速缓存单元206与204a-204n之间的一致性。
[0045]
在一些实施例中,处理器200还可包括一个或多个总线控制器单元的集合216和系统代理核210。一个或多个总线控制器单元216管理外围总线的集合,诸如,一个或多个pci总线或pci express总线。系统代理核210提供对各处理器组件的管理功能。在一些实施例中,系统代理核210包括用于管理对各种外部存储器设备(未示出)的访问的一个或多个集成存储器控制器214。
[0046]
在一些实施例中,处理器核202a-202n中的一个或多个处理器核包括对同步多线程的支持。在此类实施例中,系统代理核210包括用于在多线程处理期间协调并操作核202a-202n的组件。系统代理核210可附加地包括功率控制单元(pcu),该功率控制单元包括用于调节处理器核202a-202n和图形处理器208的功率状态的逻辑和组件。
[0047]
在一些实施例中,处理器200附加地包括用于执行图形处理操作的图形处理器208。在一些实施例中,图形处理器208与共享高速缓存单元的集合206以及与系统代理核210耦合,该系统代理核210包括一个或多个集成存储器控制器214。在一些实施例中,系统代理核210还包括用于将图形处理器输出驱动到一个或多个经耦合的显示器的显示控制器211。在一些实施例中,显示控制器211还可以是经由至少一个互连与图形处理器耦合的单独模块,或者可以集成在图形处理器208内。
[0048]
在一些实施例中,基于环的互连单元212用于耦合处理器200的内部组件。然而,可以使用替代的互连单元,诸如,点到点互连、交换式互连、或其他技术,包括本领域中公知的技术。在一些实施例中,图形处理器208经由i/o链路213与环形互连212耦合。
[0049]
示例性i/o链路213表示多个各种各样的i/o互连中的至少一种,包括促进各处理
器组件与高性能嵌入式存储器模块218(诸如,edram模块)之间的通信的封装上i/o互连。在一些实施例中,处理器核202a-202n中的每个处理器核以及图形处理器208可将嵌入式存储器模块218用作共享的末级高速缓存。
[0050]
在一些实施例中,处理器核202a-202n是执行相同指令集架构的同构核。在另一实施例中,处理器核202a-202n在指令集架构(isa)方面是异构的,其中,处理器核202a-202n中的一个或多个执行第一指令集,而其他核中的至少一个执行第一指令集的子集或不同的指令集。在一个实施例中,处理器核202a-202n在微架构方面是异构的,其中,具有相对较高功耗的一个或多个核与具有较低功耗的一个或多个功率核耦合。在一个事实中,处理器核202a-202n在计算能力方面是异构的。此外,处理器200可实现在一个或多个芯片上,或者除其他组件之外还被实现为具有所图示的组件的soc集成电路。
[0051]
图2b是根据本文中所描述的一些实施例的图形处理器核219的硬件逻辑的框图。图2b的具有与本文中的任何其他附图的元件相同的附图标记(或名称)的那些元件能以类似于本文中其他地方描述的任何方式操作或起作用,但不限于此。图形处理器核219(有时称为核切片)可以是模块化图形处理器内的一个或多个图形核。图形处理器核219的示例是一个图形核切片,并且基于目标功率包络和性能包络,如本文中所描述的图形处理器可以包括多个图形核切片。每个图形处理器核219可包括固定功能块230,该固定功能块230与多个子核221a-221f(也称为子切片)耦合,多个子核221a-221f包括模块化的通用和固定功能逻辑的块。
[0052]
在一些实施例中,固定功能块230包括几何/固定功能流水线231,该几何/固定功能流水线231例如在较低性能和/或较低功率的图形处理器实现中可由图形处理器核219中的所有子核共享。在各实施例中,几何/固定功能流水线231包括3d固定功能流水线(例如,如在下文描述的图3和图4中的3d流水线312)、视频前端单元、线程生成器和线程分派器、以及统一返回缓冲器管理器,该统一返回缓冲器管理器统一返回缓冲器(例如,如下文所描述的在图4中的统一返回缓冲器418)。
[0053]
在一个实施例中,固定功能块230还包括图形soc接口232、图形微控制器233和媒体流水线234。图形soc接口232提供图形处理器核219与芯片上系统集成电路内的其他处理器核之间的接口。图形微控制器233是可配置成管理图形处理器核219的各种功能的可编程子处理器,这些功能包括线程分派、调度和抢占。媒体流水线234(例如,图3和图4的媒体流水线316)包括用于促进对包括图像数据和视频数据的多媒体数据进行解码、编码、预处理和/或后处理的逻辑。媒体流水线234经由对子核221a-221f内的计算或采样逻辑的请求来实现媒体操作。
[0054]
在一个实施例中,soc接口232使图形处理器核219能够与通用应用处理器核(例如,cpu)和/或soc内的其他组件进行通信,其他组件包括诸如共享的末级高速缓存存储器的存储器层级结构元件、系统ram、和/或嵌入式芯片上或封装上dram。soc接口232还可启用与soc内的诸如相机成像流水线的固定功能设备的通信,并且启用全局存储器原子性的使用和/或实现全局存储器原子性,该全局存储器原子性可在图形处理器核219与soc内的cpu之间被共享。soc接口232还可实现针对图形处理器核219的功率管理控制,并且启用图形核219的时钟域与soc内的其他时钟域之间的接口。在一个实施例中,soc接口232使得能够从命令流转化器和全局线程分派器接收命令缓冲器,该命令流转化器和全局线程分派器被配
置成将命令和指令提供给图形处理器内的一个或多个图形核中的每一个图形核。当媒体操作将要执行时,这些命令和指令可以被分派给媒体流水线234,或者当图形处理操作将要执行时,这些命令和指令可以被分派给几何和固定功能流水线(例如,几何和固定功能流水线231、几何和固定功能流水线237)。
[0055]
图形微控制器233可被配置成执行针对图形处理器核219的各种调度任务和管理任务。在一个实施例中,图形微控制器233可对子核221a-221f内的执行单元(eu)阵列222a-222f、224a-224f内的各个图形并行引擎执行图形和/或计算工作负载调度。在该调度模型中,在包括图形处理器核219的soc的cpu核上执行的主机软件可以经由多个图形处理器门铃(doorbell)中的一个图形处理器门铃来提交工作负载,这调用了对适当的图形引擎的调度操作。调度操作包括:确定接下来要运行哪个工作负载,将工作负载提交到命令流转化器,抢占在引擎上运行的现有工作负载,监测工作负载的进度,以及当工作负载完成时通知主机软件。在一个实施例中,图形微控制器233还可促进图形处理器核219的低功率或空闲状态,从而向图形处理器核219提供独立于操作系统和/或系统上的图形驱动器软件跨低功率状态转变来保存和恢复图形处理器核219内的寄存器的能力。
[0056]
图形处理器核219可具有多于或少于所图示的子核221a-221f,多达n个模块化子核。对于每组n个子核,图形处理器核219还可包括共享功能逻辑235、共享和/或高速缓存存储器236、几何/固定功能流水线237、以及用于加速各种图形和计算处理操作的附加的固定功能逻辑238。共享功能逻辑235可以包括与可由图形处理器核219内的每n个子核共享的、与图4的共享功能逻辑420(例如,采样器逻辑、数学逻辑、和/或线程间通信逻辑)相关联的逻辑单元。共享和/或高速缓存存储器236可以是用于图形处理器核219内的n个子核的集合221a-221f的末级高速缓存,并且还可以充当可由多个子核访问的共享存储器。几何/固定功能流水线237而不是几何/固定功能流水线231可被包括在固定功能块230内,并且几何/固定功能流水线237可包括相同或类似的逻辑单元。
[0057]
在一个实施例中,图形处理器核219包括附加的固定功能逻辑238,该附加的固定功能逻辑238可包括供由图形处理器核219使用的各种固定功能加速逻辑。在一个实施例中,附加的固定功能逻辑238包括供在仅位置着色中使用的附加的几何流水线。在仅位置着色中,存在两个几何流水线:几何/固定功能流水线238、231内的完全几何流水线;以及剔除流水线,其是可被包括在附加的固定功能逻辑238内的附加的几何流水线。在一个实施例中,剔除流水线是完全几何流水线的精简版本。完全流水线和剔除流水线可以执行同一应用的不同实例,每个实例具有单独的上下文。仅位置着色可以隐藏被丢弃三角形的长剔除运行,从而在一些实例中使得能够更早地完成着色。例如并且在一个实施例中,附加的固定功能逻辑238内的剔除流水线逻辑可以与主应用并行地执行位置着色器,并且通常比完全流水线更快地生成关键结果,因为剔除流水线仅取出顶点的位置属性并对顶点的位置属性进行着色,而不向帧缓冲器执行对像素的栅格化和渲染。剔除流水线可以使用所生成的关键结果来计算所有三角形的可见性信息,而无需考虑那些三角形是否被剔除。完全流水线(其在本实例中可以被称为重放(replay)流水线)可以消耗该可见性信息以跳过被剔除的三角形,从而仅对最终被传递到栅格化阶段的可见的三角形进行着色。
[0058]
在一个实施例中,附加的固定功能逻辑238还可包括机器学习加速逻辑,诸如,固定功能矩阵乘法逻辑,该机器学习加速逻辑用于包括针对机器学习训练或推断的优化的实
现方式。
[0059]
在每个图形子核221a-221f内包括可用于响应于由图形流水线、媒体流水线、或着色器程序作出的请求而执行图形操作、媒体操作和计算操作的执行资源的集合。图形子核221a-221f包括:多个eu阵列222a-222f、224a-224f;线程分派和线程间通信(td/ic)逻辑223a-223f;3d(例如,纹理)采样器225a-225f;媒体采样器206a-206f;着色器处理器227a-227f;以及共享的本地存储器(slm)228a-228f。eu阵列222a-222f、224a-224f各自包括多个执行单元,这些执行单元是能够执行浮点和整数/定点逻辑操作以服务于图形操作、媒体操作或计算操作(包括图形程序、媒体程序或计算着色器程序)的通用图形处理单元。td/ic逻辑223a-223f执行针对子核内的执行单元的本地线程分派和线程控制操作,并且促进在子核的执行单元上执行的线程之间的通信。3d采样器225a-225f可将纹理或其他3d图形相关的数据读取到存储器中。3d采样器可以基于所配置的样本状态以及与给定纹理相关联的纹理格式以不同方式读取纹理数据。媒体采样器206a-206f可基于与媒体数据相关联的类型和格式来执行类似的读取操作。在一个实施例中,每个图形子核221a-221f可以交替地包括统一3d和媒体采样器。在子核221a-221f中的每一个子核内的执行单元上执行的线程可利用每个子核内的共享的本地存储器228a-228f,以使在线程组内执行的线程能够使用芯片上存储器的公共池来执行。
[0060]
图2c图示图形处理单元(gpu)239,该gpu 239包括布置为多核组240a-240n的专用的图形处理资源的集合。虽然提供仅单个多核组240a的细节,但是将理解,其他多核组240b-240n可配备有相同或类似集合的图形处理资源。
[0061]
如所图示,多核组240a可包括图形核的集合243、张量核的集合244以及光线追踪核的集合245。调度器/分派器241调度和分派图形线程用于在各个核243、244、245上执行。寄存器堆的集合242存储在执行图形线程时由核243、244、245使用的操作数值。这些寄存器堆可包括例如用于存储整数值的整数寄存器、用于存储浮点值的浮点寄存器、用于存储紧缩数据元素(整数和/或浮点数据元素)的向量寄存器以及用于存储张量/矩阵值的操作数矩阵寄存器。在一个实施例中,操作数矩阵寄存器被实现为组合的向量寄存器的集合。
[0062]
一个或多个组合的第一级(l1)高速缓存和共享存储器单元247在本地将图形数据存储在每个多核组240a内,图形数据诸如纹理数据、顶点数据、像素数据、光线数据、包围体数据等。一个或多个纹理单元247也可用于执行纹理操作,诸如,纹理映射和采样。由所有多核组240a-240n或多核组240a-240n的子集共享的第二级(l2)高速缓存253存储用于多个并发的图形线程的图形数据和/或指令。如所图示,可跨多个多核组240a-240n共享l2高速缓存253。一个或多个存储器控制器248将gpu 239耦合至存储器249,该存储器249可以是系统存储器(例如,dram)和/或专用图形存储器(例如,gddr6存储器)。
[0063]
输入/输出(i/o)电路250将gpu 239耦合至一个或多个i/o设备252,这一个或多个i/o设备252诸如数字信号处理器(dsp)、网络控制器或用户输入设备。芯片上互连可用于将i/o设备252耦合至gpu 239和存储器249。i/o电路250的一个或多个存储器管理单元(iommu)251直接将i/o设备252耦合至系统存储器249。在一个实施例中,iommu 251管理用于将虚拟地址映射到系统存储器249中的物理地址的多个集合的页表。在该实施例中,i/o设备252、(多个)cpu 246和(多个)gpu 239可共享相同的虚拟地址空间。
[0064]
在一个实现方式中,iommu 251支持虚拟化。在这种情况下,iommu 251管理用于将
宾客/图形虚拟地址映射到宾客/图形物理地址的第一集合的页表以及用于将宾客/图形物理地址映射到(例如,系统存储器249内的)系统/主机物理地址的第二集合的页表。第一集合的页表和第二集合的页表中的每一个的基址可被存储在控制寄存器中,并且在上下文切换时被换出(例如,使得新上下文被提供有对相关集合的页表的访问权)。虽然未在图2c中图示,但是核243、244、245和/或多核组240a-240n中的每一个可包括转换后备缓冲器(tlb),这些tlb用于对宾客虚拟至宾客物理转换、宾客物理至主机物理转换以及宾客虚拟至主机物理转换进行高速缓存。
[0065]
在一个实施例中,cpu 246、gpu 239和i/o设备252被集成在单个半导体芯片和/或芯片封装上。所图示的存储器249可集成在同一芯片上,或者可经由片外接口被耦合至存储器控制器248。在一个实现方式中,存储器249包括与其他物理系统级存储器共享同一虚拟地址空间的gddr6存储器,但是本发明的根本性原理不限于该特定的实现方式。
[0066]
在一个实施例中,张量核244包括专门设计成用于执行矩阵操作的多个执行单元,这些矩阵操作是用于执行深度学习操作的基本计算操作。例如,可将同步矩阵乘法操作用于神经网络训练和推断。张量核244可使用各种操作数精度来执行矩阵处理,操作数精度包括单精度浮点(例如,32位)、半精度浮点(例如,16位)、整数字(16位)、字节(8位)和半字节(4位)。在一个实施例中,神经网络实现方式提取每个经渲染场景的特征,从而潜在地组合来自多个帧的细节,以构建高质量的最终图像。
[0067]
在深度学习实现方式中,可调度并行的矩阵乘法工作用于在张量核244上执行。神经网络的训练尤其需要大量矩阵点积操作。为了处理n x n x n矩阵乘法的内积公式化,张量核244可包括至少n个点积处理元件。在矩阵乘法开始之前,一个完整的矩阵被加载到操作数矩阵寄存器中,并且对于n个循环中的每个循环,第二矩阵的至少一列被加载。对于每个循环,存在被处理的n个点积。
[0068]
取决于特定的实现方式,能以不同精度来存储矩阵元素,包括16位的字、8位的字节(例如,int8)以及4位的半字节(例如,int4)。可为张量核244指定不同的精度模式以确保将最高效的精度用于不同的工作负载(例如,诸如推断工作负载,其可容忍至字节和半字节的离散化(quantization))。
[0069]
在一个实施例中,光线追踪核245加速用于实时光线追踪实现方式和非实时光线追踪实现方式两者的光线追踪操作。具体而言,光线追踪核245包括光线遍历/相交电路,该光线遍历/相交电路用于使用包围体层级结构(bvh)来执行光线遍历并识别封围在bvh容体内的光线与基元之间的相交。光线追踪核245还可包括用于执行深度测试和剔除(例如,使用z缓冲器或类似布置)的电路。在一个实现方式中,光线追踪核245与本文中描述的图像降噪技术一致地执行遍历和相交操作,该图像降噪技术的至少部分可在张量核244上执行。例如,在一个实施例中,张量核244实现深度学习神经网络以执行对由光线追踪核245生成的帧的降噪。然而,(多个)cpu 246、图形核243和/或光线追踪核245还可实现降噪和/或深度学习算法的全部或部分。
[0070]
此外,如上文所描述,可采用对于降噪的分布式方法,在该分布式方法中,gpu 239在通过网络或高速互连而耦合至其他计算设备的计算设备中。在该实施例中,经互连的计算设备共享神经网络学习/训练数据以改善整个系统学习执行用于不同类型的图像帧和/或不同的图形应用的降噪的速度。
[0071]
在一个实施例中,光线追踪核245处理所有的bvh遍历和光线-基元相交,从而挽救图形核243免于被针对每条光线的数千条指令过载。在一个实施例中,每个光线追踪核245包括用于执行包围盒测试(例如,用于遍历操作)的第一集合的专业电路以及用于执行光线-三角形相交测试(例如,使已被遍历的光线相交)的第二集合的专业电路。由此,在一个实施例中,多核组240a可简单地发起光线探测,并且光线追踪核245独立地执行光线遍历和相交,并将命中数据(例如,命中、无命中、多个命中等)返回到线程上下文。当光线追踪核243执行遍历和相交操作时,其他核244、245被释放以执行其他图形或计算工作。
[0072]
在一个实施例中,每个光线追踪核245包括用于执行bvh测试操作的遍历单元以及执行光线-基元相交测试的相交单元。相交单元生成“命中”、“无命中”或“多个命中”响应,该相交单元将这些响应提供给适当的线程。在遍历和相交操作期间,其他核(例如,图形核243和张量核244)的执行资源被释放以执行其他形式的图形工作。
[0073]
在下文描述的一个特定实施例中,使用在其中工作被分布在图形核243与光线追踪核245之间的混合式栅格化/光线追踪方法。
[0074]
在一个实施例中,光线追踪核245(和/或其他核243、244)包括对光线追踪指令集的硬件支持,光线追踪指令集诸如:微软的directx光线追踪(dxr),其包括dispatchrays命令;以及光线生成着色器、最近命中着色器、任何命中着色器和未命中着色器,它们启用为每个对象指派唯一集合的着色器和纹理。可由光线追踪核245、图形核243和张量核244支持的另一光线追踪平台是vulkan 1.1.85。然而,要注意本发明的根本性原理不限于任何特定的光线追踪指令集架构isa。
[0075]
一般而言,各个核245、244、243可支持包括用于以下各项的指令/函数的光线追踪指令集:光线生成、最近命中、任何命中、光线-基元相交、逐基元和层级结构包围盒构建、未命中、拜访、和异常。更具体地,一个实施例包括用于执行以下功能的光线追踪指令:光线生成——可为每个像素、样本或用户定义的工作分配执行光线生成指令。最近命中——可执行最近命中指令以对场景内光线与基元的最近交点定位。任何命中——任何命中指令识别场景内光线与基元的多个相交,从而潜在地识别新的最近交点。相交——相交指令执行光线-基元相交测试并输出结果。逐基元包围盒构建——该指令围绕给定的基元或基元组建立包围盒(例如,当建立新bvh或其他加速数据结构时)。未命中——指示光线未命中场景或场景的指定区域内的全部几何体。拜访——指示光线将遍历的子容体。异常——包括各种类型的异常处置器(例如,为各种错误条件调用)。
[0076]
图2d是根据本文中描述的实施例的通用图形处理器单元(gpgpu)270的框图,该gpgpu 270可被配置为图形处理器和/或计算加速器。gpgpu 270可经由一个或多个系统和/或存储器总线来与主机处理器(例如,一个或多个cpu 246)和存储器271、272互连。在一个实施例中,存储器271是可与一个或多个cpu 246进行共享的系统存储器,而存储器272是专用于gpgpu 270的设备存储器。在一个实施例中,gpgpu 270和设备存储器272内的组件可被映射到可由一个或多个cpu 246访问的存储器地址。可经由存储器控制器268来促进对存储器271和272的访问。在一个实施例中,存储器控制器268包括内部直接存储器访问(dma)控
制器269,或可包括用于执行否则将由dma控制器执行的操作的逻辑。
[0077]
gpgpu 270包括多个高速缓存存储器,包括l2高速缓存253、l1高速缓存254、指令高速缓存255、以及共享存储器256,该共享存储器256的至少部分也可被分区为高速缓存存储器。gpgpu 270还包括多个计算单元260a-260n。每个计算单元260a-260n包括向量寄存器的集合261、标量寄存器的集合262、向量逻辑单元的集合263、以及标量逻辑单元的集合264。计算单元260a-260n还可包括本地共享存储器265和程序计数器266。计算单元260a-260n可与常量高速缓存267耦合,该常量高速缓存267可用于存储常量数据,常量数据是在gpgpu 270上执行的核程序或着色器程序的运行期间将不改变的数据。在一个实施例中,常量高速缓存267是标量数据高速缓存,并且经高速缓存的数据可被直接取出到标量寄存器262中。
[0078]
在操作期间,一个或多个cpu 246可将命令写入到gpgpu 270中的寄存器中,或写入到gpgpu 270中的、已经被映射到可访问地址空间的存储器中。命令处理器257可从寄存器或存储器读取命令,并且确定将如何在gpgpu 270内处理那些命令。随后可使用线程分派器258来将线程分派到计算单元260a-260n以执行那些命令。每个计算单元260a-260n可独立于其他计算单元来执行线程。此外,每个计算单元260a-260n可被独立地配置成用于有条件计算,并且可有条件地将计算的结果输出到存储器。当所提交的命令完成时,命令处理器257可中断一个或多个cpu 246。
[0079]
图3a-图3c图示由本文中描述的实施例提供的附加的图形处理器和计算加速器架构的框图。图3-图3c的具有与本文中的任何其他附图的元件相同的附图标记(或名称)的那些元件能以类似于本文中其他地方描述的任何方式操作或起作用,但不限于此。
[0080]
图3a是图形处理器300的框图,该图形处理器300可以是分立的图形处理单元,或可以是与多个处理核或其他半导体器件集成的图形处理器,其他半导体器件诸如但不限于存储器设备或网络接口。在一些实施例中,图形处理器经由到图形处理器上的寄存器的存储器映射的i/o接口并且利用被放置到处理器存储器中的命令进行通信。在一些实施例中,图形处理器300包括用于访问存储器的存储器接口314。存储器接口314可以是到本地存储器、一个或多个内部高速缓存、一个或多个共享的外部高速缓存、和/或系统存储器的接口。
[0081]
在一些实施例中,图形处理器300还包括显示控制器302,该显示控制器302用于将显示输出数据驱动到显示设备318。显示控制器302包括用于显示器的一个或多个叠加平面以及多层的视频或用户界面元素的合成的硬件。显示设备318可以是内部或外部显示设备。在一个实施例中,显示设备318是头戴式显示设备,诸如,虚拟现实(vr)显示设备或增强现实(ar)显示设备。在一些实施例中,图形处理器300包括用于将媒体编码到一种或多种媒体编码格式,从一种或多种媒体编码格式对媒体解码,或在一种或多种媒体编码格式之间对媒体转码的视频编解码器引擎306,这一种或多种媒体编码格式包括但不限于:移动图像专家组(mpeg)格式(诸如,mpeg-2)、高级视频译码(avc)格式(诸如,h.264/mpeg-4avc、h.265/hevc,开放媒体联盟(aomedia)vp8、vp9)、以及电影和电视工程师协会(smpte)421m/vc-1、和联合图像专家组(jpeg)格式(诸如,jpeg、以及运动jpeg(mjpeg)格式)。
[0082]
在一些实施例中,图形处理器300包括块图像传送(blit)引擎304,用于执行二维(2d)栅格化器操作,包括例如,位边界块传送。然而,在一个实施例中,使用图形处理引擎(gpe)310的一个或多个组件执行2d图形操作。在一些实施例中,gpe 310是用于执行图形操
作的计算引擎,这些图形操作包括三维(3d)图形操作和媒体操作。
[0083]
在一些实施例中,gpe 310包括用于执行3d操作的3d流水线312,3d操作诸如,使用作用于3d基元形状(例如,矩形、三角形等)的处理函数来渲染三维图像和场景。3d流水线312包括可编程和固定功能元件,该可编程和固定功能元件执行到3d/媒体子系统315的元件和/或所生成的执行线程内的各种任务。虽然3d流水线312可用于执行媒体操作,但是gpe 310的实施例还包括媒体流水线316,该媒体流水线316专门用于执行媒体操作,诸如,视频后处理和图像增强。
[0084]
在一些实施例中,媒体流水线316包括固定功能或可编程逻辑单元用于代替、或代表视频编解码器引擎306来执行一个或多个专业的媒体操作,诸如,视频解码加速、视频去隔行、以及视频编码加速。在一些实施例中,媒体流水线316附加地包括线程生成单元以生成用于在3d/媒体子系统315上执行的线程。所生成的线程在3d/媒体子系统315中所包括的一个或多个图形执行单元上执行对媒体操作的计算。
[0085]
在一些实施例中,3d/媒体子系统315包括用于执行由3d流水线312和媒体流水线316生成的线程的逻辑。在一个实施例中,流水线向3d/媒体子系统315发送线程执行请求,该3d/媒体子系统315包括用于对于对可用的线程执行资源的各种请求进行仲裁和分派的线程分派逻辑。执行资源包括用于处理3d线程和媒体线程的图形执行单元的阵列。在一些实施例中,3d/媒体子系统315包括用于线程指令和数据的一个或多个内部高速缓存。在一些实施例中,该子系统还包括用于在线程之间共享数据并用于存储输出数据的共享存储器,其包括寄存器和可寻址存储器。
[0086]
图3b图示根据本文中描述的实施例的具有分片架构的图形处理器320。在一个实施例中,图形处理器320包括图形处理引擎集群322,该图形处理引擎集群322在图形引擎片310a-310d内具有图3中的图形处理器引擎310的多个实例。每个图形引擎片310a-310d可经由片互连的集合323a-323f被互连。每个图形引擎片310a-310d还可经由存储器互连325a-325d被连接到存储器模块或存储器设备326a-326d。存储器设备326a-326d可使用任何图形存储器技术。例如,存储器设备326a-326d可以是图形双倍数据速率(gddr)存储器。在一个实施例中,存储器设备326a-326d是高带宽存储器(hbm)模块,这些高带宽存储器(hbm)模块可与其相应的图形引擎片310a-310d一起在管芯上。在一个实施例中,存储器设备326a-326d是堆叠式存储器设备,这些堆叠式存储器设备可被堆叠在它们相应的图形引擎片310a-310d的顶部上。在一个实施例中,每个图形引擎片310a-310d和相关联的存储器326a-326d驻留在分开的小芯片上,这些分开的小芯片被键合到基管芯或基衬底,如在图11b-图11d中进一步详细地所描述。
[0087]
图形处理引擎集群322可与芯片上或封装上结构互连324连接。结构互连324可启用图形引擎片310a-310d与诸如视频编解码器306和一个或多个副本引擎304之类的组件之间的通信。副本引擎304可用于将数据移出存储器设备326a-326d和在图形处理器320外部的存储器(例如,系统存储器),将数据移入存储器设备326a-326d和在图形处理器320外部的存储器(例如,系统存储器),并且在存储器设备326a-326d与在图形处理器320外部的存储器(例如,系统存储器)之间移动数据。结构互连324还可用于将图形引擎片310a-310d互连。图形处理器320可任选地包括显示控制器302,以启用与外部显示设备318的连接。图形处理器还可被配置为图形加速器或计算加速器。在加速器配置中,显示控制器302和显示设
备318可被省略。
[0088]
图形处理器320可经由主机接口328连接到主机系统。主机接口328可启用图形处理器320、系统存储器和/或系统组件之间的通信。主机接口328可以是例如pci express总线或另一类型的主机系统接口。
[0089]
图3c图示根据本文中描述的实施例的计算加速器330。计算加速器330可包括与图3b中的图形处理器320的架构类似性,并且针对计算加速进行优化。计算引擎集群332可包括计算引擎片的集合340a-340d,计算引擎片的集合340a-340d包括针对并行或基于向量的通用计算操作优化的执行逻辑。在一些实施例中,计算引擎片340a-340d不包括固定功能图形处理逻辑,但是在一个实施例中,计算引擎片340a-340d中的一个或多个可包括用于执行媒体加速的逻辑。计算引擎片340a-340d可经由存储器互连325a-325d连接到存储器326a-326d。存储器326a-326d和存储器互连325a-325d可以是与在图形处理器320中类似的技术,或者可以是不同的技术。图形计算引擎片340a-340d还可经由片互连的集合323a-323f被互连,并且可与结构互连324连接和/或由结构互连324互连。在一个实施例中,计算加速器330包括可被配置为设备范围的高速缓存的大型l3高速缓存336。计算加速器330还能以与图3b中的图形处理器320类似的方式经由主机接口328连接至主机处理器和存储器。图形处理引擎
[0090]
图4是根据一些实施例的图形处理器的图形处理引擎410的框图。在一个实施例中,图形处理引擎(gpe)410是图3a中示出的gpe 310的某个版本,并且还可表示图3b中的图形引擎片310a-310d。图4的具有与本文中的任何其他附图的元件相同的附图标记(或名称)的那些元件能以类似于本文中其他地方描述的任何方式操作或起作用,但不限于此。例如,图示出图3a的3d流水线312和媒体流水线316。媒体流水线316在gpe 410的一些实施例中是任选的,并且可以不被显式地包括在gpe 410内。例如并且在至少一个实施例中,单独的媒体和/或图像处理器被耦合至gpe 410。
[0091]
在一些实施例中,gpe 410与命令流转化器403耦合或包括命令流转化器403,该命令流转化器403将命令流提供给3d流水线1012和/或媒体流水线316。在一些实施例中,命令流转化器403与存储器耦合,该存储器可以是系统存储器、或内部高速缓存存储器和共享高速缓存存储器中的一个或多个。在一些实施例中,命令流转化器403从存储器接收命令,并将这些命令发送至3d流水线1012和/或媒体流水线316。这些命令是从环形缓冲器取出的指示,该环形缓冲器存储用于3d流水线312和媒体流水线316的命令。在一个实施例中,环形缓冲器可附加地包括存储批量的多个命令的批量命令缓冲器。用于3d流水线312的命令还可包括对存储在存储器中的数据的引用,这些数据诸如但不限于用于3d流水线312的顶点数据和几何数据和/或用于媒体流水线316的图像数据和存储器对象。3d流水线312和媒体流水线316通过经由各自流水线内的逻辑执行操作或者通过将一个或多个执行线程分派至图形核阵列414来处理命令和数据。在一个实施例中,图形核阵列414包括一个或多个图形核(例如,(多个)图形核415a、(多个)图形核415b)的块,每个块包括一个或多个图形核。每个图形核包括图形执行资源的集合,该图形执行资源的集合包括:用于执行图形操作和计算操作的通用执行逻辑和图形专用执行逻辑;以及固定功能纹理处理逻辑和/或机器学习和人工智能加速逻辑。
[0092]
在各实施例中,3d流水线312可包括用于通过处理指令以及将执行线程分派到图
形核阵列414来处理一个或多个着色器程序的固定功能和可编程逻辑,这一个或多个着色器程序诸如,顶点着色器、几何着色器、像素着色器、片段着色器、计算着色器、或其他着色器程序。图形核阵列414提供统一的执行资源块供在处理这些着色器程序时使用。图形核阵列414的(多个)图形核415a-415b内的多功能执行逻辑(例如,执行单元)包括对各种3d api着色器语言的支持,并且可执行与多个着色器相关联的多个同步执行线程。
[0093]
在一些实施例中,图形核阵列414包括用于执行诸如视频和/或图像处理的媒体功能的执行逻辑。在一个实施例中,执行单元包括通用逻辑,该通用逻辑可编程以便除了执行图形处理操作之外还执行并行通用计算操作。通用逻辑可与图1的(多个)处理器核107或图2a中的核202a-202n内的通用逻辑并行地或结合地执行处理操作。
[0094]
由在图形核阵列414上执行的线程生成的输出数据可以将数据输出到统一返回缓冲器(urb)418中的存储器。urb 418可以存储用于多个线程的数据。在一些实施例中,urb 418可用于在图形核阵列414上执行的不同线程之间发送数据。在一些实施例中,urb 418可附加地用于在图形核阵列上的线程与共享功能逻辑420内的固定功能逻辑之间的同步。
[0095]
在一些实施例中,图形核阵列414是可缩放的,使得阵列包括可变数量的图形核,每个图形核都具有基于gpe 410的目标功率和性能等级的可变数量的执行单元。在一个实施例中,执行资源是动态可缩放的,使得可以根据需要启用或禁用执行资源。
[0096]
图形核阵列414与共享功能逻辑420耦合,该共享功能逻辑420包括在图形核阵列中的图形核之间被共享的多个资源。共享功能逻辑420内的共享功能是向图形核阵列414提供专业的补充功能的硬件逻辑单元。在各实施例中,共享功能逻辑420包括但不限于采样器逻辑421、数学逻辑422和线程间通信(itc)逻辑423。另外,一些实施例在共享功能逻辑420内实现一个或多个高速缓存425。
[0097]
至少在其中对于给定的专业功能的需求不足以包括在图形核阵列414中的情况下实现共享功能。相反,那个专业功能的单个实例化被实现为共享功能逻辑420中的独立实体,并且在图形核阵列414内的执行资源之间被共享。在图形核阵列414之间被共享并被包括在图形核阵列414内的确切的功能集因实施例而异。在一些实施例中,共享功能逻辑420内的由图形核阵列414广泛使用的特定共享功能可被包括在图形核阵列414内的共享功能逻辑416内。在各实施例中,图形核阵列414内的共享功能逻辑416可包括共享功能逻辑420内的一些或所有逻辑。在一个实施例中,共享功能逻辑420内的所有逻辑元件可以在图形核阵列414的共享功能逻辑416内被复制。在一个实施例中,共享功能逻辑420被排除以有利于图形核阵列414内的共享功能逻辑416。执行单元
[0098]
图5a-图5b图示根据本文中所描述的实施例的线程执行逻辑500,该线程执行逻辑500包括在图形处理器核中采用的处理元件的阵列。图5a-图5b的具有与本文中的任何其他附图的元件相同的附图标记(或名称)的那些元件能以类似于本文中其他地方描述的任何方式操作或起作用,但不限于此。图5a-图5b图示线程执行逻辑500的概览,该线程执行逻辑500可表示以图2b中的每个子核221a-221f图示的硬件逻辑。图5a表示通用图形处理器内的执行单元,而图5b表示可在计算加速器内被使用的执行单元。
[0099]
如在图5a中所图示,在一些实施例中,线程执行逻辑500包括着色器处理器502、线程分派器504、指令高速缓存506、包括多个执行单元508a-508n的可缩放执行单元阵列、采
样器510、共享本地存储器511、数据高速缓存512、以及数据端口514。在一个实施例中,可缩放执行单元阵列可通过基于工作负载的计算要求启用或禁用一个或多个执行单元(例如,执行单元508a、508b、508c、508d,一直到508n-1和508n中的任一个)来动态地缩放。在一个实施例中,所包括的组件经由互连结构而互连,该互连结构链接到组件中的每个组件。在一些实施例中,线程执行逻辑500包括通过指令高速缓存506、数据端口514、采样器510、以及执行单元508a-508n中的一个或多个到存储器(诸如,系统存储器或高速缓存存储器)的一个或多个连接。在一些实施例中,每个执行单元(例如,508a)是能够执行多个同步硬件线程同时针对每个线程并行地处理多个数据元素的独立式可编程通用计算单元。在各实施例中,执行单元508a-508n的阵列是可缩放的以包括任何数量的单独的执行单元。
[0100]
在一些实施例中,执行单元508a-508n主要用于执行着色器程序。着色器处理器502可处理各种着色器程序,并且可经由线程分派器504分派与着色器程序相关联的执行线程。在一个实施例中,线程分派器包括用于对来自图形流水线和媒体流水线的线程发起请求进行仲裁并在执行单元508a-508n中的一个或多个执行单元上实例化所请求的线程的逻辑。例如,几何流水线可将顶点着色器、曲面细分着色器或几何着色器分派到线程执行逻辑以用于处理。在一些实施例中,线程分派器504还可处理来自执行的着色器程序的运行时线程生成请求。
[0101]
在一些实施例中,执行单元508a-508n支持包括对许多标准3d图形着色器指令的原生支持的指令集,使得以最小的转换执行来自图形库(例如,direct 3d和opengl)的着色器程序。这些执行单元支持顶点和几何处理(例如,顶点程序、几何程序、顶点着色器)、像素处理(例如,像素着色器、片段着色器)以及通用处理(例如,计算和媒体着色器)。执行单元508a-508n中的每个执行单元都能够进行多发布单指令多数据(simd)执行,并且多线程操作在面对较高等待时间的存储器访问时启用高效的执行环境。每个执行单元内的每个硬件线程都具有专用的高带宽寄存器堆和相关的独立线程状态。对于能够进行整数操作、单精度浮点操作和双精度浮点操作、能够具有simd分支能力、能够进行逻辑操作、能够进行超越操作和能够进行其他混杂操作的流水线,执行针对每个时钟是多发布的。在等待来自存储器或共享功能中的一个共享功能的数据时,执行单元508a-508n内的依赖性逻辑使等待的线程休眠,直到所请求的数据已返回。当等待的线程正在休眠时,硬件资源可致力于处理其他线程。例如,在与顶点着色器操作相关联的延迟期间,执行单元可以执行针对像素着色器、片段着色器或包括不同顶点着色器的另一类型的着色器程序的操作。各实施例可应用以使用利用单指令多线程(simt)的执行,作为simd用例的替代,或作为simd用例的附加。对simd核或操作的引用也可应用于simt,或结合simt而应用于simd。
[0102]
执行单元508a-508n中的每个执行单元对数据元素的数组进行操作。数据元素的数量是“执行尺寸”、或用于指令的通道数量。执行通道是用于数据元素访问、掩码、和指令内的流控制的执行的逻辑单元。通道的数量可独立于用于特定图形处理器的物理算术逻辑单元(alu)或浮点单元(fpu)的数量。在一些实施例中,执行单元508a-508n支持整数和浮点数据类型。
[0103]
执行单元指令集包括simd指令。各种数据元素可以作为紧缩数据类型被存储在寄存器中,并且执行单元将基于元素的数据尺寸来处理各个元素。例如,当对256位宽的向量进行操作时,向量的256位被存储在寄存器中,并且执行单元将向量操作为四个单独的64位
紧缩数据元素(四字(qw)尺寸数据元素)、八个单独的32位紧缩数据元素(双字(dw)尺寸数据元素)、十六个单独的16位紧缩数据元素(字(w)尺寸的数据元素)、或三十二个单独的8位数据元素(字节(b)尺寸的数据元素)。然而,不同的向量宽度和寄存器尺寸是可能的。
[0104]
在一个实施例中,可以将一个或多个执行单元组合到融合执行单元509a-509n中,该融合执行单元509a-509n具有对于融合eu而言共同的线程控制逻辑(507a-507n)。可以将多个eu融合到eu组中。融合的eu组中的每个eu可以被配置成执行单独的simd硬件线程。融合的eu组中的eu的数量可以根据实施例而有所不同。另外,可以逐eu地执行各种simd宽度,包括但不限于simd8、simd16和simd32。每个融合图形执行单元509a-509n包括至少两个执行单元。例如,融合执行单元509a包括第一eu 508a、第二eu 508b、以及对于第一eu 508a和第二eu 508b而言共同的线程控制逻辑507a。线程控制逻辑507a控制在融合图形执行单元509a上执行的线程,从而允许融合执行单元509a-509n内的每个eu使用共同的指令指针寄存器来执行。
[0105]
一个或多个内部指令高速缓存(例如,506)被包括在线程执行逻辑500中以对用于执行单元的线程指令进行高速缓存。在一些实施例中,一个或多个数据高速缓存(例如,512)被包括,以在线程执行期间对线程数据进行高速缓存。在执行逻辑500上执行的线程还可将被显式地管理的数据存储在共享本地存储器511中。在一些实施例中,采样器510被包括以为3d操作提供纹理采样并且为媒体操作提供媒体采样。在一些实施例中,采样器510包括专业的纹理或媒体采样功能,以便在向执行单元提供采样数据之前在采样过程期间处理纹理数据或媒体数据。
[0106]
在执行期间,图形流水线和媒体流水线经由线程生成和分派逻辑将线程发起请求发送到线程执行逻辑500。一旦一组几何对象已经被处理并被栅格化为像素数据,着色器处理器502内的像素处理器逻辑(例如,像素着色器逻辑、片段着色器逻辑等)就被调用以进一步计算输出信息,并且使得结果被写入到输出表面(例如,颜色缓冲器、深度缓冲器、模板印刷(stencil)缓冲器等)。在一些实施例中,像素着色器或片段着色器计算各顶点属性的值,各顶点属性的值将跨经栅格化的对象而被内插。在一些实施例中,着色器处理器502内的像素处理器逻辑随后执行应用编程接口(api)供应的像素着色器程序或片段着色器程序。为了执行着色器程序,着色器处理器502经由线程分派器504将线程分派至执行单元(例如,508a)。在一些实施例中,着色器处理器502使用采样器510中的纹理采样逻辑来访问存储在存储器中的纹理图中的纹理数据。对纹理数据和输入几何数据的算术操作计算针对每个几何片段的像素颜色数据,或丢弃一个或多个像素而不进行进一步处理。
[0107]
在一些实施例中,数据端口514提供存储器访问机制,供线程执行逻辑500将经处理的数据输出至存储器以便在图形处理器输出流水线上进一步处理。在一些实施例中,数据端口514包括或耦合至一个或多个高速缓存存储器(例如,数据高速缓存512),以便对数据进行高速缓存供经由数据端口进行存储器访问。
[0108]
在一个实施例中,执行逻辑500还可包括可提供光线追踪加速功能的光线追踪器505。光线追踪器505可支持光线追踪指令集,该光线追踪指令集包括用于光线生成的指令/函数。光线追踪指令集可与图2c中的光线追踪核245所支持的光线追踪指令集类似或不同。
[0109]
图5b图示根据实施例的执行单元508的示例性内部细节。图形执行单元508可包括指令取出单元537、通用寄存器堆阵列(grf)524、架构寄存器堆阵列(arf)526、线程仲裁器
522、发送单元530、分支单元532、simd浮点单元(fpu)的集合534、以及在一个实施例中的专用整数simd alu的集合535。grf 524和arf 526包括与可在图形执行单元508中活跃的每个同步硬件线程相关联的通用寄存器堆和架构寄存器堆的集合。在一个实施例中,每线程架构状态被维持在arf 526中,而在线程执行期间使用的数据被存储在grf 524中。每个线程的执行状态,包括用于每个线程的指令指针,可以被保持在arf 526中的线程专用寄存器中。
[0110]
在一个实施例中,图形执行单元508具有作为同步多线程(smt)与细粒度交织多线程(imt)的组合的架构。该架构具有模块化配置,该模块化配置可以基于同步线程的目标数量和每个执行单元的寄存器的数量而在设计时进行微调,其中跨用于执行多个同步线程的逻辑来划分执行单元资源。可由图形执行单元508执行的逻辑线程的数量不限于硬件线程的数量,并且可将多个逻辑线程指派给每个硬件线程。
[0111]
在一个实施例中,图形执行单元508可协同发布多条指令,这些指令可以各自是不同的指令。图形执行单元线程508的线程仲裁器522可以将指令分派给以下各项中的一项以供执行:发送单元530、分支单元532或(多个)simd fpu 534。每个执行线程可以访问grf 524内的128个通用寄存器,其中,每个寄存器可以存储可作为具有32位数据元素的simd 8元素向量访问的32个字节。在一个实施例中,每个执行单元线程具有对grf 524内的4个千字节的访问权,但是实施例并不限于此,并且在其他实施例中可以提供更多或更少的寄存器资源。在一个实施例中,图形执行单元508被分区为可独立地执行计算操作的七个硬件线程,但是每个执行单元的线程数量也可根据实施例而有所不同。例如,在一个实施例中,支持多达16个硬件线程。在其中七个线程可以访问4个千字节的实施例中,grf 524可以存储总共28个千字节。在16个线程可访问4个千字节的情况下,grf 524可存储总共64个千字节。灵活的寻址模式可以准许对多个寄存器一起进行寻址,从而建立实际上更宽的寄存器或者表示跨步式矩形块数据结构。
[0112]
在一个实施例中,经由通过消息传递发送单元530执行的“发送”指令来分派存储器操作、采样器操作以及其他较长等待时间的系统通信。在一个实施例中,分支指令被分派给专用分支单元532以促进simd发散和最终收敛。
[0113]
在一个实施例中,图形执行单元508包括用于执行浮点操作的一个或多个simd浮点单元(fpu)534。在一个实施例中,(多个)fpu 534还支持整数计算。在一个实施例中,(多个)fpu 534可以simd执行多达数量m个32位浮点(或整数)操作,或者simd执行多达2m个16位整数或16位浮点操作。在一个实施例中,(多个)fpu中的至少一个提供支持高吞吐量超越数学函数和双精度64位浮点的扩展数学能力。在一些实施例中,8位整数simd alu的集合535也存在,并且可专门优化成执行与机器学习计算相关联的操作。
[0114]
在一个实施例中,可以在图形子核分组(例如,子切片)中对图形执行单元508的多个实例的阵列进行实例化。为了可缩放性,产品架构师可以选择每子核分组的执行单元的确切数量。在一个实施例中,执行单元508可以跨多个执行通道来执行指令。在进一步的实施例中,在不同通道上执行在图形执行单元508上执行的每个线程。
[0115]
图6图示根据实施例的附加的执行单元600。执行单元600可以是用于在例如图2c中的计算引擎片340a-340d中使用的计算优化的执行单元,但不限于此。执行单元600的变体也可在如图2b中的图形引擎片210a-210d中使用。在一个实施例中,执行单元600包括线
程控制单元601、线程状态单元602、指令取出/预取单元603、以及指令解码单元604。执行单元600附加地包括寄存器堆606,该寄存器堆606存储可被指派给执行单元内的硬件线程的寄存器。执行单元600附加地包括发送单元607和分支单元608。在一个实施例中,发送单元607和分支单元608能以与图5b中的图形执行单元508的发送单元530和分支单元532类似的方式操作。
[0116]
执行单元600还包括计算单元610,该计算单元610包括多个不同类型的功能单元。在一个实施例中,计算单元610包括alu单元611,该alu单元611包括算术逻辑单元的阵列。alu单元611可配置成执行64位、32位和16位的整数和浮点操作。可同时执行整数和浮点操作。计算单元610还可包括脉动阵列612和数学单元613。脉动阵列612包括数据处理单元的宽w深d的网络,其可用于以脉动方式执行向量或其他数据并行操作。在一个实施例中,脉动阵列612可配置成执行矩阵操作,诸如,矩阵点积操作。在一个实施例中,脉动阵列612支持16位浮点操作以及8位和4位整数操作。在一个实施例中,脉动阵列612可配置成加速机器学习操作。在此类实施例中,脉动阵列612可配置有对bfloat 16位浮点格式的支持。在一个实施例中,数学单元613可被包括以便以高效的且比alu单元611更低功率的方式执行数学操作的特定子集。数学单元613可包括可在由其他实施例提供的图形处理引擎的共享功能逻辑(例如,图4中的共享功能逻辑420的数学逻辑422)中发现的数学逻辑的变体。在一个实施例中,数学单元613可配置成执行32位和64位浮点操作。
[0117]
线程控制单元601包括用于控制执行单元内的线程的执行的逻辑。线程控制单元601可包括线程仲裁逻辑,该线程仲裁逻辑用于启动、停止以及抢占执行单元600内线程的执行。线程状态单元602可用于存储用于被指派在执行单元600上执行的线程的线程状态。将线程状态存储在执行单元600能使得能够在线程变得被锁定或空闲时快速抢占那些线程。指令取出/预取单元603可从较高级别执行逻辑的指令高速缓存(例如,如图5a中的指令高速缓存506)取出指令。指令取出/预取单元603还基于对当前执行线程的分析来发布对要被加载到执行高速缓存中的指令的预取请求。指令解码单元604可用于对要由计算单元执行的指令进行解码。在一个实施例中,指令解码单元604可被用作次级解码器以将复杂指令解码为组成的微操作。
[0118]
执行单元600附加地包括寄存器堆606,该寄存器堆可由在执行单元600上执行的硬件线程使用。寄存器堆606中的寄存器可跨用于执行执行单元600的计算单元610内的多个同步线程的逻辑而被划分。可由图形执行单元600执行的逻辑线程的数量不限于硬件线程的数量,并且可将多个逻辑线程指派给每个硬件线程。基于所支持的硬件线程的数量,寄存器堆606的尺寸可因实施例而异。在一个实施例中,可使用寄存器重命名来动态地将寄存器分配给硬件线程。
[0119]
图7是图示根据一些实施例的图形处理器指令格式700的框图。在一个或多个实施例中,图形处理器执行单元支持具有多种格式的指令的指令集。实线框图示通常被包括在执行单元指令中的组成部分,而虚线包括任选的或仅被包括在指令的子集中的组成部分。在一些实施例中,所描述和图示的指令格式700是宏指令,因为它们是供应至执行单元的指令,这与产生自一旦指令被处理就进行的指令解码的微指令相反。
[0120]
在一些实施例中,图形处理器执行单元原生地支持128位指令格式710的指令。基于所选择的指令、指令选项和操作数数量,64位紧凑指令格式730可用于一些指令。原生128
位指令格式710提供对所有指令选项的访问,而一些选项和操作在64位格式730中受限。64位格式730中可用的原生指令因实施例而异。在一些实施例中,使用索引字段713中的索引值的集合将指令部分地压缩。执行单元硬件基于索引值来引用压缩表的集合,并使用压缩表输出来重构128位指令格式710的原生指令。可使用指令的其他尺寸和格式。
[0121]
针对每种格式,指令操作码712限定执行单元要执行的操作。执行单元跨每个操作数的多个数据元素并行地执行每条指令。例如,响应于加法指令,执行单元跨表示纹理元素或图片元素的每个颜色通道执行同步加法操作。默认地,执行单元跨操作数的所有数据通道执行每条指令。在一些实施例中,指令控制字段714启用对某些执行选项的控制,这些执行选项诸如通道选择(例如,断言)以及数据通道顺序(例如,混合)。针对128位指令格式710的指令,执行尺寸字段716限制将被并行地执行的数据通道的数量。在一些实施例中,执行尺寸字段716不可用于64位紧凑指令格式730。
[0122]
一些执行单元指令具有多达三个操作数,包括两个源操作数src0720、src1 722以及一个目的地操作数718。在一些实施例中,执行单元支持双目的地指令,其中,双目的地中的一个目的地是隐式的。数据操纵指令可具有第三源操作数(例如,src2 724),其中,指令操作码712确定源操作数的数量。指令的最后一个源操作数可以是与指令一起传递的立即数(例如,硬编码的)值。
[0123]
在一些实施例中,128位指令格式710包括访问/寻址模式字段726,该访问/寻址模式字段726例如指定使用直接寄存器寻址模式还是间接寄存器寻址模式。当使用直接寄存器寻址模式时,由指令中的位直接提供一个或多个操作数的寄存器地址。
[0124]
在一些实施例中,128位指令格式710包括访问/寻址模式字段726,该访问/寻址模式字段726指定指令的寻址模式和/或访问模式。在一个实施例中,访问模式用于限定针对指令的数据访问对齐。一些实施例支持包括16字节对齐访问模式和1字节对齐访问模式的访问模式,其中,访问模式的字节对齐确定指令操作数的访问对齐。例如,当处于第一模式时,指令可将字节对齐寻址用于源操作数和目的地操作数,并且当处于第二模式时,指令可将16字节对齐寻址用于所有的源操作数和目的地操作数。
[0125]
在一个实施例中,访问/寻址模式字段726的寻址模式部分确定指令要使用直接寻址还是间接寻址。当使用直接寄存器寻址模式时,指令中的位直接提供一个或多个操作数的寄存器地址。当使用间接寄存器寻址模式时,可以基于指令中的地址寄存器值和地址立即数字段来计算一个或多个操作数的寄存器地址。
[0126]
在一些实施例中,基于操作码712位字段对指令进行分组从而简化操作码解码740。针对8位的操作码,位4、位5、和位6允许执行单元确定操作码的类型。所示出的确切的操作码分组仅是示例。在一些实施例中,移动和逻辑操作码组742包括数据移动和逻辑指令(例如,移动(mov)、比较(cmp))。在一些实施例中,移动和逻辑组742共享五个最高有效位(msb),其中,移动(mov)指令采用0000xxxxb的形式,而逻辑指令采用0001xxxxb的形式。流控制指令组744(例如,调用(call)、跳转(jmp))包括0010xxxxb(例如,0x20)形式的指令。混杂指令组746包括指令的混合,包括0011xxxxb(例如,0x30)形式的同步指令(例如,等待(wait)、发送(send))。并行数学指令组748包括0100xxxxb(例如,0x40)形式的逐分量的算术指令(例如,加、乘(mul))。并行数学组748跨数据通道并行地执行算术操作。向量数学组750包括0101xxxxb(例如,0x50)形式的算术指令(例如,dp4)。向量数学组对向量操作数执
行算术,诸如点积计算。在一个实施例中,所图示的操作码解码740可用于确定执行单元的哪个部分将用于执行经解码的指令。例如,一些指令可被指定为将由脉动阵列执行的脉动指令。其他指令,诸如,光线追踪指令(未示出)可被路由到执行逻辑的切片或分区内的光线追踪核或光线追踪逻辑。图形流水线
[0127]
图8是图形处理器800的另一实施例的框图。图8的具有与本文中的任何其他附图的元件相同的附图标记(或名称)的那些元件能以类似于本文中其他地方描述的任何方式操作或起作用,但不限于此。
[0128]
在一些实施例中,图形处理器800包括几何流水线820、媒体流水线830、显示引擎840、线程执行逻辑850、以及渲染输出流水线870。在一些实施例中,图形处理器800是包括一个或多个通用处理核的多核处理系统内的图形处理器。图形处理器通过至一个或多个控制寄存器(未示出)的寄存器写入、或者经由通过环形互连802发布至图形处理器800的命令被控制。在一些实施例中,环形互连802将图形处理器800耦合至其他处理组件,诸如其他图形处理器或通用处理器。来自环形互连802的命令由命令流转化器803解译,该命令流转化器将指令供应至几何流水线820或媒体流水线830的各个组件。
[0129]
在一些实施例中,命令流转化器803引导顶点取出器805的操作,该顶点取出器805从存储器读取顶点数据,并执行由命令流转化器803提供的顶点处理命令。在一些实施例中,顶点取出器805将顶点数据提供给顶点着色器807,该顶点着色器807对每个顶点执行坐标空间变换和照明操作。在一些实施例中,顶点取出器805和顶点着色器807通过经由线程分派器831将执行线程分派至执行单元852a-852b来执行顶点处理指令。
[0130]
在一些实施例中,执行单元852a-852b是具有用于执行图形操作和媒体操作的指令集的向量处理器的阵列。在一些实施例中,执行单元852a-852b具有专用于每个阵列或在阵列之间被共享的所附接的l1高速缓存851。高速缓存可以被配置为数据高速缓存、指令高速缓存、或被分区为在不同分区中包含数据和指令的单个高速缓存。
[0131]
在一些实施例中,几何流水线820包括用于执行3d对象的硬件加速曲面细分的曲面细分组件。在一些实施例中,可编程外壳着色器811配置曲面细分操作。可编程域着色器817提供对曲面细分输出的后端评估。曲面细分器813在外壳着色器811的指示下进行操作,并且包括用于基于粗糙的几何模型来生成详细的几何对象集合的专用逻辑,该粗糙的几何模型作为输入被提供该几何流水线820。在一些实施例中,如果不使用曲面细分,则可以绕过曲面细分组件(例如,外壳着色器811、曲面细分器813和域着色器817)。
[0132]
在一些实施例中,完整的几何对象可由几何着色器819经由被分派至执行单元852a-852b的一个或多个线程来处理,或者可以直接行进至裁剪器829。在一些实施例中,几何着色器对整个几何对象而不是对如在图形流水线的先前的级中那样对顶点或顶点补片进行操作。如果禁用曲面细分,则几何着色器819从顶点着色器807接收输入。在一些实施例中,几何着色器819是可由几何着色器程序编程的以便在曲面细分单元被禁用的情况下执行几何曲面细分。
[0133]
在栅格化之前,裁剪器829处理顶点数据。裁剪器829可以是固定功能裁剪器或具有裁剪和几何着色器功能的可编程裁剪器。在一些实施例中,渲染输出流水线870中的栅格化器和深度测试组件873分派像素着色器以将几何对象转换为逐像素表示。在一些实施例
中,像素着色器逻辑被包括在线程执行逻辑850中。在一些实施例中,应用可绕过栅格化器和深度测试组件873,并且经由流出单元823访问未栅格化的顶点数据。
[0134]
图形处理器800具有互连总线、互连结构、或允许数据和消息在处理器的主要组件之中传递的某个其他互连机制。在一些实施例中,执行单元852a-852b和相关联的逻辑单元(例如,l1高速缓存851、采样器854、纹理高速缓存858等)经由数据端口856进行互连,以便执行存储器访问并且与处理器的渲染输出流水线组件进行通信。在一些实施例中,采样器854、高速缓存851、858以及执行单元852a-852b各自具有单独的存储器访问路径。在一个实施例中,纹理高速缓存858也可被配置为采样器高速缓存。
[0135]
在一些实施例中,渲染输出流水线870包含栅格化器和深度测试组件873,其将基于顶点的对象转换为相关联的基于像素的表示。在一些实施例中,栅格化器逻辑包括用于执行固定功能三角形和线栅格化的窗口器/掩码器单元。相关联的渲染高速缓存878和深度高速缓存879在一些实施例中也是可用的。像素操作组件877对数据进行基于像素的操作,但是在一些实例中,与2d操作相关联的像素操作(例如,利用混合的位块图像传送)由2d引擎841执行,或者在显示时由显示控制器843使用叠加显示平面来代替。在一些实施例中,共享的l3高速缓存875可用于所有的图形组件,从而允许在无需使用主系统存储器的情况下共享数据。
[0136]
在一些实施例中,图形处理器媒体流水线830包括媒体引擎837和视频前端834。在一些实施例中,视频前端834从命令流转化器803接收流水线命令。在一些实施例中,媒体流水线830包括单独的命令流转化器。在一些实施例中,视频前端834在将媒体命令发送至媒体引擎837之前处理该命令。在一些实施例中,媒体引擎837包括用于生成线程以用于经由线程分派器831分派至线程执行逻辑850的线程生成功能。
[0137]
在一些实施例中,图形处理器800包括显示引擎840。在一些实施例中,显示引擎840在处理器800外部,并且经由环形互连802、或某个其他互连总线或结构来与图形处理器耦合。在一些实施例中,显示引擎840包括2d引擎841和显示控制器843。在一些实施例中,显示引擎840包含能够独立于3d流水线进行操作的专用逻辑。在一些实施例中,显示控制器843与显示设备(未示出)耦合,该显示设备可以是系统集成显示设备(如在膝上型计算机中)、或者是经由显示设备连接器附接的外部显示设备。
[0138]
在一些实施例中,几何流水线820和媒体流水线830可被配置成用于基于多个图形和媒体编程接口执行操作,并且并非专用于任何一种应用编程接口(api)。在一些实施例中,图形处理器的驱动器软件将专用于特定图形或媒体库的api调用转换成可由图形处理器处理的命令。在一些实施例中,为全部来自khronos group的开放图形库(opengl)、开放计算语言(opencl)和/或vulkan图形和计算api提供支持。在一些实施例中,也可以为来自微软公司的direct3d库提供支持。在一些实施例中,可以支持这些库的组合。还可以为开源计算机视觉库(opencv)提供支持。如果可进行从未来api的流水线到图形处理器的流水线的映射,则具有兼容3d流水线的未来api也将受到支持。图形流水线编程
[0139]
图9a是图示根据一些实施例的图形处理器命令格式900的框图。图9b是图示根据实施例的图形处理器命令序列910的框图。图9a中的实线框图示一般被包括在图形命令中的组成部分,而虚线包括任选的或仅被包括在图形命令的子集中的组成部分。图9a的示例
性图形处理器命令格式900包括用于标识命令的客户端902、命令操作代码(操作码)904和数据906的数据字段。子操作码905和命令尺寸908也被包括在一些命令中。
[0140]
在一些实施例中,客户端902指定图形设备的处理命令数据的客户端单元。在一些实施例中,图形处理器命令解析器检查每个命令的客户端字段,以调整对命令的进一步处理并将命令数据路由至适当的客户端单元。在一些实施例中,图形处理器客户端单元包括存储器接口单元、渲染单元、2d单元、3d单元、和媒体单元。每个客户端单元具有处理命令的对应的处理流水线。一旦由客户端单元接收到命令,客户端单元就读取操作码904以及子操作码905(如果存在)以确定要执行的操作。客户端单元使用数据字段906内的信息来执行命令。针对一些命令,预期显式的命令尺寸908指定命令的尺寸。在一些实施例中,命令解析器基于命令操作码自动地确定命令中的至少一些命令的尺寸。在一些实施例中,经由双字的倍数来对齐命令。可使用其他命令格式。
[0141]
图9b中的流程图示示例性图形处理器命令序列910。在一些实施例中,以图形处理器的实施例为特征的数据处理系统的软件或固件使用所示出的命令序列的某个版本来建立、执行并终止图形操作的集合。仅出于示例性目的示出并描述了样本命令序列,因为实施例不限于这些特定的命令或者该命令序列。而且,命令可以作为批量的命令以命令序列被发布,使得图形处理器将以至少部分同时的方式处理命令序列。
[0142]
在一些实施例中,图形处理器命令序列910可开始于流水线转储清除命令912,以便使得任何活跃的图形流水线完成流水线的当前未决命令。在一些实施例中,3d流水线922和媒体流水线924不并发地操作。执行流水线转储清除以使得活跃的图形流水线完成任何未决命令。响应于流水线转储清除,用于图形处理器的命令解析器将暂停命令处理,直到活跃的绘画引擎完成未决操作并且相关的读高速缓存被无效。任选地,渲染高速缓存中被标记为“脏”的任何数据可以被转储清除到存储器。在一些实施例中,流水线转储清除命令912可以用于流水线同步,或者在将图形处理器置于低功率状态之前使用。
[0143]
在一些实施例中,当命令序列要求图形处理器在流水线之间明确地切换时,使用流水线选择命令913。在一些实施例中,在发布流水线命令之前在执行上下文中仅需要一次流水线选择命令913,除非上下文将发布针对两条流水线的命令。在一些实施例中,紧接在经由流水线选择命令913的流水线切换之前需要流水线转储清除命令912。
[0144]
在一些实施例中,流水线控制命令914配置用于操作的图形流水线,并且用于对3d流水线922和媒体流水线924进行编程。在一些实施例中,流水线控制命令914配置活跃流水线的流水线状态。在一个实施例中,流水线控制命令914用于流水线同步,并且用于在处理批量的命令之前清除来自活跃流水线内的一个或多个高速缓存存储器的数据。
[0145]
在一些实施例中,返回缓冲器状态命令916用于配置用于相应流水线的返回缓冲器的集合以写入数据。一些流水线操作需要分配、选择或配置一个或多个返回缓冲器,在处理期间操作将中间数据写入这一个或多个返回缓冲器中。在一些实施例中,图形处理器还使用一个或多个返回缓冲器来存储输出数据并且执行跨线程通信。在一些实施例中,返回缓冲器状态916包括选择要用于流水线操作的集合的返回缓存器的尺寸和数量。
[0146]
命令序列中的剩余命令基于用于操作的活跃流水线而不同。基于流水线判定920,命令序列被定制用于以3d流水线状态930开始的3d流水线922、或者在媒体流水线状态940处开始的媒体流水线11924。
[0147]
用于配置3d流水线状态930的命令包括用于顶点缓冲器状态、顶点元素状态、常量颜色状态、深度缓冲器状态、以及将在处理3d基元命令之前配置的其他状态变量的3d状态设置命令。这些命令的值至少部分地基于使用中的特定3d api来确定。在一些实施例中,如果将不使用某些流水线元件,则3d流水线状态930命令还能够选择性地禁用或绕过那些元件。
[0148]
在一些实施例中,3d基元932命令用于提交待由3d流水线处理的3d基元。经由3d基元932命令传递给图形处理器的命令和相关联的参数被转发到图形流水线中的顶点取出功能。顶点取出功能使用3d基元932命令数据来生成多个顶点数据结构。顶点数据结构被存储在一个或多个返回缓冲器中。在一些实施例中,3d基元932命令用于经由顶点着色器对3d基元执行顶点操作。为了处理顶点着色器,3d流水线922将着色器执行线程分派至图形处理器执行单元。
[0149]
在一些实施例中,经由执行934命令或事件触发3d流水线922。在一些实施例中,寄存器写入触发命令执行。在一些实施例中,经由命令序列中的“去往(go)”或“踢除(kick)”命令来触发执行。在一个实施例中,使用流水线同步命令来触发命令执行,以便通过图形流水线来转储清除命令序列。3d流水线将执行针对3d基元的几何处理。一旦操作完成,就对所得到的几何对象进行栅格化,并且像素引擎对所得到的像素进行着色。对于那些操作,还可以包括用于控制像素着色和像素后端操作的附加命令。
[0150]
在一些实施例中,当执行媒体操作时,图形处理器命令序列910遵循媒体流水线924路径。一般地,针对媒体流水线924进行编程的特定用途和方式取决于待执行的媒体或计算操作。在媒体解码期间,特定的媒体解码操作可以被转移到媒体流水线。在一些实施例中,还可绕过媒体流水线,并且可使用由一个或多个通用处理核提供的资源来整体地或部分地执行媒体解码。在一个实施例中,媒体流水线还包括用于通用图形处理器单元(gpgpu)操作的元件,其中,图形处理器用于使用计算着色器程序来执行simd向量操作,这些计算着色器程序并不明确地与图形基元的渲染相关。
[0151]
在一些实施例中,以与3d流水线922类似的方式配置媒体流水线924。将用于配置媒体流水线状态940的命令集合分派或放置到命令队列中,在媒体对象命令942之前。在一些实施例中,用于媒体流水线状态的命令940包括用于配置媒体流水线元件的数据,这些媒体流水线元件将用于处理媒体对象。这包括用于在媒体流水线内配置视频解码和视频编码逻辑的数据,诸如编码或解码格式。在一些实施例中,用于媒体流水线状态的命令940还支持使用指向包含批量的状态设置的“间接”状态元件的一个或多个指针。
[0152]
在一些实施例中,媒体对象命令942供应指向用于由媒体流水线处理的媒体对象的指针。媒体对象包括存储器缓冲器,该存储器缓冲器包含待处理的视频数据。在一些实施例中,在发布媒体对象命令942之前,所有的媒体流水线状态必须是有效的。一旦流水线状态被配置并且媒体对象命令942被排队,就经由执行命令944或等效的执行事件(例如,寄存器写入)来触发媒体流水线924。随后可通过由3d流水线922或媒体流水线924提供的操作对来自媒体流水线924的输出进行后处理。在一些实施例中,以与媒体操作类似的方式来配置和执行gpgpu操作。图形软件架构
[0153]
图10图示根据一些实施例的用于数据处理系统1000的示例性图形软件架构。在一
些实施例中,软件架构包括3d图形应用1010、操作系统1020、以及至少一个处理器1030。在一些实施例中,处理器1030包括图形处理器1032以及一个或多个通用处理器核1034。图形应用1010和操作系统1020各自在数据处理系统的系统存储器1050中执行。
[0154]
在一些实施例中,3d图形应用1010包含一个或多个着色器程序,这一个或多个着色器程序包括着色器指令1012。着色器语言指令可以采用高级着色器语言,诸如,directd的高级着色器语言(hlsl)、opengl着色器语言(glsl),等等。应用还包括采用适于由通用处理器核1034执行的机器语言的可执行指令1014。应用还包括由顶点数据限定的图形对象1016。
[0155]
在一些实施例中,操作系统1020是来自微软公司的在一些实施例中,操作系统1020是来自微软公司的操作系统、专属的类unix操作系统、或使用linux内核的变体的开源的类unix操作系统。操作系统1020可支持图形api 1022,诸如direct3d api、opengl api或vulkan api。当direct3d api正在使用时,操作系统1020使用前端着色器编译器1024以将采用hlsl的任何着色器指令1012编译成较低级的着色器语言。编译可以是即时(jit)编译,或者应用可执行着色器预编译。在一些实施例中,在3d图形应用1010的编译期间,将高级着色器编译成低级着色器。在一些实施例中,着色器指令1012以中间形式提供,诸如由vulkan api使用的标准便携式中间表示(spir)的某个版本。
[0156]
在一些实施例中,用户模式图形驱动器1026包含后端着色器编译器1027,该后端着色器编译器1027用于将着色器指令1012转换成硬件专用表示。当opengl api在使用中时,将采用glsl高级语言的着色器指令1012传递至用户模式图形驱动器1026以用于编译。在一些实施例中,用户模式图形驱动器1026使用操作系统内核模式功能1028来与内核模式图形驱动器1029进行通信。在一些实施例中,内核模式图形驱动器1029与图形处理器1032通信以分派命令和指令。ip核实施方式
[0157]
至少一个实施例的一个或多个方面可以由存储在机器可读介质上的代表性代码实现,该机器可读介质表示和/或限定集成电路(诸如,处理器)内的逻辑。例如,机器可读介质可以包括表示处理器内的各种逻辑的指令。当由机器读取时,指令可以使机器制造用于执行本文所述的技术的逻辑。这类表示(被称为“ip核”)是集成电路的逻辑的可重复使用单元,这些可重复使用单元可以作为描述集成电路的结构的硬件模型而被存储在有形的、机器可读介质上。可以将硬件模型供应至在制造集成电路的制造机器上加载硬件模型的各消费者或制造设施。可以制造集成电路,使得电路执行与本文中描述的实施例中的任一实施例相关联地描述的操作。
[0158]
图11a是图示根据实施例的ip核开发系统1100的框图,该ip核开发系统1100可以用于制造集成电路以执行操作。ip核开发系统1100可以用于生成可并入到更大的设计中或用于构建整个集成电路(例如,soc集成电路)的模块化、可重复使用设计。设计设施1130可生成采用高级编程语言(例如,c/c )的ip核设计的软件仿真1110。软件仿真1110可用于使用仿真模型1112来设计、测试并验证ip核的行为。仿真模型1112可以包括功能仿真、行为仿真和/或时序仿真。随后可从仿真模型1112创建或合成寄存器传输级(rtl)设计1115。rtl设计1115是对硬件寄存器之间的数字信号的流进行建模的集成电路(包括使用建模的数字信号执行的相关联的逻辑)的行为的抽象。除了rtl设计1115之外,还可以创建、设计或合成逻
辑级或晶体管级的较低级别设计。由此,初始设计和仿真的特定细节可有所不同。
[0159]
可以由设计设施进一步将rtl设计1115或等效方案合成到硬件模型1120中,该硬件模型1120可以采用硬件描述语言(hdl)或物理设计数据的某种其他表示。可以进一步仿真或测试hdl以验证ip核设计。可使用非易失性存储器1140(例如,硬盘、闪存、或任何非易失性存储介质)来存储ip核设计以用于递送至第三方制造设施1165。替代地,可以通过有线连接1150或无线连接1160(例如,经由因特网)来传输ip核设计。制造设施1165随后可以制造至少部分地基于ip核设计的集成电路。所制造的集成电路可被配置用于执行根据本文中描述的至少一个实施例的操作。
[0160]
图11b图示根据本文中描述的一些实施例的集成电路封装组件1170的截面侧视图。集成电路封装组件1170图示如本文中所描述的一个或多个处理器或加速器设备的实现方式。封装组件1170包括连接至衬底1180的多个硬件逻辑单元1172、1174。逻辑1172、1174可以至少部分地实现在可配置逻辑或固定功能逻辑硬件中,并且可包括本文中描述的(多个)处理器核、(多个)图形处理器或其他加速器设备中的任何处理器核、图形处理器或其他加速器设备的一个或多个部分。每个逻辑单元1172、1174可以实现在半导体管芯内,并且经由互连结构1173与衬底1180耦合。互连结构1173可以被配置成在逻辑1172、1174与衬底1180之间路由电信号,并且可以包括互连,该互连诸如但不限于凸块或支柱。在一些实施例中,互连结构1173可以被配置成路由电信号,诸如例如,与逻辑1172、1174的操作相关联的输入/输出(i/o)信号和/或功率或接地信号。在一些实施例中,衬底1180是基于环氧树脂的层压衬底。在其他实施例中,封装衬底1180可以包括其他合适类型的衬底。封装组件1170可以经由封装互连1183连接至其他电气设备。封装互连1183可以耦合至衬底1180的表面以将电信号路由到其他电气设备,诸如主板、其他芯片组或多芯片模块。
[0161]
在一些实施例中,逻辑单元1172、1174与桥接器1182电耦合,该桥接器1182被配置成在逻辑1172与逻辑1174之间路由电信号。桥接器1182可以是为电信号提供路由的密集互连结构。桥接器1182可以包括由玻璃或合适的半导体材料构成的桥接器衬底。电路由特征可形成在桥接器衬底上以提供逻辑1172与逻辑1174之间的芯片到芯片连接。
[0162]
尽管图示了两个逻辑单元1172、1174和桥接器1182,但是本文中所描述的实施例可以包括在一个或多个管芯上的更多或更少的逻辑单元。这一个或多个管芯可以由零个或更多个桥接器连接,因为当逻辑被包括在单个管芯上时,可以排除桥接器1182。替代地,多个管芯或逻辑单元可以由一个或多个桥接器连接。另外,在其他可能的配置(包括三维配置)中,多个逻辑单元、管芯和桥接器可被连接在一起。
[0163]
图11c图示封装组件1190,该封装组件1190包括连接到衬底1180的多个单元的硬件逻辑小芯片(例如,基础管芯)。如本文中所描述的图形处理单元、并行处理器和/或计算加速器可由分开制造的各种硅小芯片组成。在该上下文中,小芯片是至少部分地被封装的集成电路,该至少部分地被封装的集成电路包括可与其他小芯片一起被组装到更大的封装中的不同的逻辑单元。具有不同ip核逻辑的小芯片的各种集合可被组装到单个器件中。此外,可使用有源插入器技术将小芯片集成到基础管芯或基础小芯片中。本文中描述的概念启用gpu内的不同形式的ip之间的互连和通信。ip核可通过使用不同的工艺技术来制造并在制造期间被组成,这避免了尤其是对于具有若干风格的ip的大型soc的将多个ip聚集到同一制造工艺的复杂性。允许使用多种工艺技术改善了上市时间,并提供具有成本效益的
方法来创建多个产品sku。此外,分解的ip更适于被独立地进行功率门控,可关闭不在给定工作负载上使用的组件,从而降低总功耗。
[0164]
硬件逻辑小芯片可包括专用硬件逻辑小芯片1172、逻辑或i/o小芯片1174、和/或存储器小芯片1175。硬件逻辑小芯片1172以及逻辑或i/o小芯片1174可以至少部分地实现在可配置逻辑或固定功能逻辑硬件中,并且可包括本文中描述的(多个)处理器核、(多个)图形处理器、并行处理器或其他加速器设备中的任何处理器核、图形处理器、并行处理器或其他加速器设备的一个或多个部分。存储器小芯片1175可以是dram(例如,gddr、hbm)存储器或高速缓存(sram)存储器。
[0165]
每个小芯片可被制造为单独的半导体管芯,并且经由互连结构1173与衬底1180耦合。互连结构1173可配置成在衬底1180内的各种小芯片与逻辑之间路由电信号。互连结构1173可包括互连,诸如但不限于凸块或支柱。在一些实施例中,互连结构1173可以被配置成路由电信号,诸如例如,与逻辑小芯片、i/o小芯片和存储器小芯片的操作相关联的输入/输出(i/o)信号和/或功率信号或接地信号。
[0166]
在一些实施例中,衬底1180是基于环氧树脂的层压衬底。在其他实施例中,衬底1180可包括其他合适类型的衬底。封装组件1190可以经由封装互连1183连接至其他电气设备。封装互连1183可以耦合至衬底1180的表面以将电信号路由到其他电气设备,诸如主板、其他芯片组或多芯片模块。
[0167]
在一些实施例中,逻辑或i/o小芯片1174和存储器小芯片1175可经由桥接器1187被电耦合,该桥接器1187配置成在逻辑或i/o小芯片1174与存储器小芯片1175之间路由电信号。桥接器1187可以是为电信号提供路由的密集互连结构。桥接器1187可以包括由玻璃或合适的半导体材料构成的桥接器衬底。电路由特征可形成在桥接器衬底上以提供逻辑或i/o小芯片1174与存储器小芯片1175之间的芯片到芯片连接。桥接器1187还可被称为硅桥接器或互连桥接器。例如,在一些实施例中,桥接器1187是嵌入式多管芯互连桥接器(emib)。在一些实施例中,桥接器1187可以仅是从一个小芯片到另一小芯片的直接连接。
[0168]
衬底1180可包括用于i/o 1191、高速缓存存储器1192和其他硬件逻辑1193的硬件组件。结构1185可被嵌入在衬底1180中以启用衬底1180内的各种逻辑小芯片与逻辑1191、1193之间的通信。在一个实施例中,i/o 1191、结构1185、高速缓存、桥接器和其他硬件逻辑1193可集成在层叠在衬底1180的顶部上的基础管芯中。
[0169]
在各实施例中,封装组件1190可包括由结构1185或一个或多个桥接器1187互连的更少或更多数量的组件和桥接器。封装组件1190内的小芯片能以3d布置或2.5d布置来布置。一般而言,桥接器结构1187可用于促进例如逻辑或i/o小芯片与存储器小芯片之间的点对点互连。结构1185可用于将各种逻辑和/或i/o小芯片(例如,小芯片1172、1174、1191、1193)与其他逻辑和/或i/o小芯片互连。在一个实施例中,衬底内的高速缓存存储器1192可充当用于封装组件1190的全局高速缓存,充当分布式全局高速缓存的部分,或充当用于结构1185的专用高速缓存。
[0170]
图11d图示根据实施例的包括可互换小芯片1195的封装组件1194。可互换小芯片1195可被组装到一个或多个基础小芯片1196、1198上的标准化插槽中。基础小芯片1196、1198可经由桥接器互连1197被耦合,该桥接器互连1197可与本文中描述的其他桥接器互连类似,并且可以是例如emib。存储器小芯片也可经由桥接器互连被连接至逻辑或i/o小芯
片。i/o和逻辑小芯片可经由互连结构进行通信。基础小芯片各自可支持按照用于逻辑或i/o或存器/高速缓存的标准化格式的一个或多个插槽。
[0171]
在一个实施例中,sram和功率递送电路可被制造到基础小芯片1196、1198中的一个或多个中,基础小芯片1196、1198可使用相对于可互换小芯片1195不同的工艺技术来制造,可互换小芯片1195堆叠在基础小芯片的顶部上。例如,可使用较大工艺技术来制造基础小芯片1196、1198,同时可使用较小工艺技术来制造可互换小芯片。可互换小芯片1195中的一个或多个可以是存储器(例如,dram)小芯片。可基于针对使用封装组件1194的产品的功率和/或新能来为封装组件1194选择不同的存储器密度。此外,可在组装时基于针对产品的功率和/或性能来选择具有不同数量的类型的功能单元的逻辑小芯片。此外,可将包含具有不同类型的ip逻辑核的小芯片插入到可互换小芯片插槽中,从而启用可混合并匹配不同技术的ip块的混合式存储器设计。示例性芯片上系统集成电路
[0172]
图12以及图13a-图13b图示根据本文中所述的各实施例的可以使用一个或多个ip核制造的示例性集成电路和相关联的图形处理器。除了所图示的内容之外,还可以包括其他逻辑和电路,包括附加的图形处理器/核、外围接口控制器或通用处理器核。
[0173]
图12是图示根据实施例的可使用一个或多个ip核来制造的示例性芯片上系统集成电路1200的框图。示例性集成电路1200包括一个或多个应用处理器1205(例如,cpu)、至少一个图形处理器1210,并且可附加地包括图像处理器1215和/或视频处理器1220,其中的任一个都可以是来自相同设计设施或多个不同的设计设施的模块化ip核。集成电路1200包括外围或总线逻辑,包括usb控制器1225、uart控制器1230、spi/sdio控制器1235和i2s/i2c控制器1240。此外,集成电路可包括显示设备1245,该显示设备1245耦合至高清晰度多媒体接口(hdmi)控制器1250和移动行业处理器接口(mipi)显示接口1255中的一个或多个。可以由闪存子系统1260(包括闪存和闪存控制器)来提供存储。可以经由存储器控制器1265来提供存储器接口以获得对sdram或sram存储器设备的访问。一些集成电路附加地包括嵌入式安全引擎1270。
[0174]
图13a-图13b是图示根据本文中所描述的实施例的用于在soc内使用的示例性图形处理器的框图。图13a图示根据实施例的可以使用一个或多个ip核制造的芯片上系统集成电路的示例性图形处理器1310。图13b图示根据实施例的可以使用一个或多个ip核制造的芯片上系统集成电路的附加示例性图形处理器1340。图13a的图形处理器1310是低功率图形处理器核的示例。图13b的图形处理器1340是较高性能图形处理器核的示例。图形处理器1310、1340中的每一个都可以是图12的图形处理器1310的变体。
[0175]
如图13a中所示,图形处理器1310包括顶点处理器1305以及一个或多个片段处理器1315a-1315n(例如,1315a、1315b、1315c、1315d,一直到1315n-1和1315n)。图形处理器1310可以经由单独的逻辑执行不同的着色器程序,使得顶点处理器1305被优化以执行用于顶点着色器程序的操作,而一个或多个片段处理器1315a-1315n执行用于片段或像素着色器程序的片段(例如,像素)着色操作。顶点处理器1305执行3d图形流水线的顶点处理级,并生成基元数据和顶点数据。(多个)片段处理器1315a-1315n使用由顶点处理器1305生成的基元数据和顶点数据来产生被显示在显示设备上的帧缓冲器。在一个实施例中,(多个)片段处理器1315a-1315n被优化以执行如在opengl api中提供的片段着色器程序,这些片段
着色器程序可以用于执行与如在direct 3d api中提供的像素着色器程序类似的操作。
[0176]
图形处理器1310附加地包括一个或多个存储器管理单元(mmu)1320a-1320b、(多个)高速缓存1325a-1325b以及(多个)电路互连1330a-1330b。这一个或多个mmu 1320a-1320b为图形处理器1310(包括为顶点处理器1305和/或(多个)片段处理器1315a-1315n)提供虚拟到物理地址映射,除了存储在一个或多个高速缓存1325a-1325b中的顶点数据或图像/纹理数据之外,该虚拟到物理地址映射还可以引用存储在存储器中的顶点数据或图像/纹理数据。在一个实施例中,一个或多个mmu 1320a-1320b可以与系统内的其他mmu同步,使得每个处理器1205-1220可以参与共享或统一的虚拟存储器系统,系统内的其他mmu包括与图12的一个或多个应用处理器1205、图像处理器1215和/或视频处理器1220相关联的一个或多个mmu。根据实施例,一个或多个电路互连1330a-1330b使得图形处理器1310能够经由soc的内部总线或经由直接连接来与soc内的其他ip核对接。
[0177]
如图13b中所示,图形处理器1340包括图13a的图形处理器1310的一个或多个mmu 1320a-1320b、高速缓存1325a-1325b、以及电路互连1330a-1330b。图形处理器1340包括一个或多个着色器核1355a-1355n(例如,1355a、1355b、1355c、1355d、1355e、1355f,一直到1355n-1和1355n),这一个或多个着色器核提供统一着色器核架构,在该统一着色器核架构中,单个核或类型或核可以执行所有类型的可编程着色器代码,包括用于实现顶点着色器、片段着色器和/或计算着色器的着色器程序代码。存在的着色器核的确切数量可以因实施例和实现方式而异。另外,图形处理器1340包括核间任务管理器1345,该核间任务管理器1345充当用于将执行线程分派给一个或多个着色器核1355a-1355n的线程分派器和用于加速对基于片的渲染的分片操作的分片单元1358,在基于片的渲染中,针对场景的渲染操作在图像空间中被细分,例如以利用场景内的局部空间一致性或优化内部高速缓存的使用。tanh函数和sigmoid函数的执行
[0178]
图14描绘线性变换的示例,该线性变换后跟激活函数。在系统1400中,计算由现代深度神经网络执行,线性变换可后跟激活函数。激活函数将非线性引入到神经网络中以模拟真实世界行为,这对于训练深度神经网络的成功是关键的。
[0179]
新兴的神经网络正使用更复杂的激活函数而不是典型的轻量型relu(修正线性单元)(relu(x)=max(x,0))以实现更好的准确性和收敛。在激活函数的许多变体之中,tanh函数和sigmoid函数由于其曲线对于整个范围的可微分、单调且界限固定的性质而被广泛使用。将tanh/sigmoid用作激活函数的新兴的深度神经网络的示例是谷歌的神经机器翻译系统(gnmt)、变换器(transformer)、双向编码器表示(bert)、gpt、gpt-2、gpt-3、efficientnet、广义三元连接(gtc),等等。以下描绘tanh和sigmoid的表达式:efficientnet、广义三元连接(gtc),等等。以下描绘tanh和sigmoid的表达式:
[0180]
复杂的激活函数直接使用tanh或sigmoid,或建立在tanh或sigmoid之上。例如,激活函数可包括在efficientnet中使用的swish激活函数(x*sigmoid(x))、或在基于变换器的自然语言处理深度网络中使用的gelu激活函数然而,tanh函数和sigmoid函数是计算密集型的,这对于在训练和部署神经网络时的性能和
功率使用带来挑战。从网络算法的角度看,用类似形状的平滑函数的变体替代tanh函数和sigmoid函数并涉及较少的计算可能是不切实际的。
[0181]
当前的gpu销售商没有原生的硬件指令来加速tanh激活函数和sigmoid激活函数。从功能上讲,可使用通过多条指令的执行对tanh和sigmoid的仿真。复杂度取决于所需的准确度而有所不同,并且一般而言,执行更多条指令以实现tanh和sigmoid的更高的逼近准确度。对于符合opencl规范(例如,5个最小单位(unit in the last place(ulp))的相对误差)的tanh实现方式,需要几十条指令。高准确度仿真实现方式可能需要数百条指令,这在性能和功耗方面对使用而言过于昂贵。ml开发人员可用较少的指令损害准确度以获得更好的速度,但是这将导致另一问题:神经网络花费更多时期(epoch)来收敛,或在训练期间不能够收敛。低准确度仿真在训练时具有收敛问题。
[0182]
各实施例加速tanh激活函数和sigmoid激活函数的执行。各实施例通过分段二次内插向至少用于tanh操作和sigmoid操作(例如,激活函数)的专用指令提供高吞吐量和高准确度两者。例如,可分别将用于tanh函数和sigmoid函数的专用指令命名为math.tanh和math.sigmoid,但是可使用任何名称。例如,tanh函数可用两阶段方法来实现,该两阶段方法具有生成初始中间结果的内插,并且提供算术逻辑单元(alu)指令以供执行,以对初始结果进行后处理来完成结果。
[0183]
例如,sigmoid可由独立式内插操作实现。sigmoid的各实施例能够以对于lut硬件或存储器空间使用的最小额外硬件成本来重用现有的二次内插流水线。
[0184]
各实施例向开发人员提供了请求执行tanh指令和sigmoid指令的指令或api。例如,opencl、cm(c-for-metal)和dpc 可添加对tanh指令和sigmoid指令的支持。例如,当编译器编译api native_tanh(float input)(原生_tanh(浮动输入))时,编译器能够生成用于执行tanh的原生tanh指令。可使用诸如fp32、fp16和bfloat16(bf)之类的输入的浮点格式。在一些实施例中,tanh函数可被编译为三条指令,包括:用于取决于输入的值而执行tanh(输入)或tanh(输入)/输入以生成中间输出的指令;用于基于输入而引起执行比例因子的生成的指令;以及用于引起执行对中间结果与比例因子的乘法操作的指令。
[0185]
数学流水线可执行对tanh(x)或扭曲函数tanh(x)/x的预处理和内插,并且处理器执行的软件可执行对条件乘法的后处理。可使用gpu的执行单元中的数学流水线来执行分段二次内插操作。可使用查找表(lut)或存储器或寄存器的区域来存储在二次操作中使用的值。在本文中描述二次操作的各示例。当然,可执行线性方程或更高阶方程。
[0186]
例如,当编译器编译api native_sigmoid(float input(浮点输入))时,该编译器可生成原生sigmoid指令,该原生sigmoid指令通过以下方式执行sigmoid函数:对于特定范围的输入值,将输出钳制到特定值;或对于特定范围的输入值执行二次计算。可使用gpu的执行单元中的数学流水线来执行二次操作。可使用lut或存储器或寄存器的区域来存储在二次操作中使用的值。在本文中描述二次操作的各示例。当然,可执行线性方程或更高阶方程。在一些示例中,用于负输入值的系数可被存储在lut中,并且可被访问以在二次操作中使用。对于正输入值,可由硬件修改用于负输入值的、存储在lut中的系数,以在二次操作中使用。
[0187]
当对于特定输入范围在数学流水线中执行math.tanh指令或math.sigmoid指令时,输出接近固定值,并且该数学流水线可将输出钳制到固定值。当钳制时,二次内插逻辑
或电路被绕过,这可节省硬件面积和功率使用。
[0188]
图15描绘示例系统,在该示例系统中,编译器可生成用于至少tanh和sigmoid的指令以供由着色器执行单元执行。在系统1500中,gpu的着色器执行单元1502可对来自数据高速缓存1506的数据或输入值执行来自指令高速缓存1504的指令,并将结果存储到存储器1508中。在本文中描述了执行单元、gpu、指令高速缓存、数据高速缓存和存储器的各实施例。
[0189]
图16描绘可由各实施例使用的示例系统。在一些示例中,可对指令tanh和指令sigmoid解码并提供指令tanh和指令sigmoid以由数学流水线1612执行。着色器执行单元1602可从执行高速缓存(未示出)接收指令。指令解码器1606可对来自指令缓冲器1604的指令进行解码,并且仲裁器1608可将指令提供给浮点单元(fpu)流水线1610(例如,具有算术逻辑单元(alu))、数学流水线1612、控制流流水线1614、和加载/存储流水线1616中的一个或多个。
[0190]
在用于tanh或sigmoid的指令被解码器1606解码后,这些指令被分派到数学流水线1612以执行分段二次逼近计算。在一些示例中,数学流水线包括供查找表(lut)执行至少tanh指令和sigmoid指令的专用电路或可配置逻辑。数学流水线1612可包括用于结合执行tanh操作和sigmoid操作来执行二次内插的电路和处理器可执行指令。数学流水线1612可利用lut,该lut被实现为由合成器生成的组合逻辑。合成器可优化大量逻辑以减少门数量。在一些示例中,用于tanh的执行的lut包括256个条目,并且每个条目为64位。在一些示例中,用于sigmoid的lut包括128个条目,并且每个条目为64位。
[0191]
图17描绘用于执行math.tanh指令或math.sigmoid指令的数学流水线的操作的示例。输入值可被提供给数学流水线1702。输入值可以是浮点32(fp32)格式、浮点16(fp16)格式、或bfloat(bf)。在1704处,数学流水线1702可使用电路或处理器执行的软件来处理输入值以执行以下一项或多项:如果输入为fp16或bf,则转换到fp32;特殊输入inf(无穷)或nan(非数)的处置;输入值的范围约简;以及基于输入值计算索引和
△
(delta,增量)值。在1706处,数学流水线1702可使用所生成的索引来访问lut以聚集c0值、c1值和c2值。在一些示例中,c0值、c1值和c2值是定点整数格式。在1708处,数学流水线1702可使用电路或处理器执行的软件以针对所选范围的输入值执行二次计算c0 c1*
△
c2*(
△2)。在1710处,数学流水线1702可使用电路或处理器执行的软件以通过以下一项或多项对来自1708的输出进行后处理:累加器舍入到输出格式精度尾数和指数调整(例如,无界指数钳制到有界指数,无偏置指数转换为有偏置指数);如果输出格式不是fp32,则转换为fp16或bf。
[0192]
图18a和图18b描绘可在各实施例中被使用以对二次表达式求值的示例系统。在一些示例中,输入值和输出值可具有格式:s(符号)、指数(exp)和尾数。图18a描绘用于执行二次计算的数学流水线的示例使用。系数c0、c1、c2可被存储在lut 1802中,并且对于给定的输入,数学流水线1800可执行范围校验以计算索引,并随后使用该索引以从lut 1802选择对应的c0、c1、c2。在一些示例中,c0至c2是固定位整数值。在一些示例中,
△
值可从输入值的尾数的n个最低有效位选择。乘法器1804-0至1804-2和加法器1806可共同执行二次计算c0 c1*
△
c2*
△
*
△
。调整和舍入(rtne)1808可将累加器结果舍入到单精度结果。数学流水线可用于除tanh或sigmoid之外的操作。
[0193]
图18b描绘二次计算的另一示例。在一些示例中,所示数是格式为m.n的固定数,其
中,m是整数宽度,并且n是分数宽度。tanh命令执行
[0194]
各实施例可向用于tanh的输入的范围提供一致的小的相对误差。函数tanh可通过三条指令的执行来实现。第一条math.tanh可引起预处理和二次内插,随后是引起条件乘法的执行的两条fpu指令。由于math.tanh和两条fpu指令可在不同流水线中被并行地执行,因此可通过多个并行线程的执行来隐藏等待时间。
[0195]
开发人员可使用特定tanh api(例如,opencl或英特尔one api)。例如,编译器可利用指令序列从tanh api生成三条指令,以得到如下解:r_intermediate=math.tanh(r_input)r_scale=min(abs(r_input,1.0f)r_out=r_intermediate*r_scale。
[0196]
各实施例使用两条现有的指令来执行条件乘法,例如,min和mul。该解决方案可在不牺牲性能和准确度的情况下节省用于条件乘法器的专用逻辑。
[0197]
可在两个阶段中执行tanh(x)计算。第一阶段可由专用math.tanh指令执行,并且第二阶段由两条现有的fpu指令仿真。当x在范围[0,1)中时,第一阶段可用于计算tanh(x)/x;或者当x在[1, inf)时,第一阶段可用于计算tanh(x)。在指令集架构(isa)中被标记为math.tanh的专用指令可用于如下所述地执行第一阶段。
[0198]
由于tanh函数是点对称的,因此二次逼近可应用于正输入。对于负输入,输入的符号位可在二次逼近之前被翻转,并且在二次逼近之后翻转中间结果的符号位。
[0199]
当来自math.tanh(x)的输出接近0且输入接近0时,需要大量lut条目和大量乘法器和累加器位来实现高准确度,这对于硬件实现是不切实际的。替代地计算tanh(x)/x可避免该问题。
[0200]
为了进一步减少硬件使用,当输入在范围[0,2-12
)或[8.0, inf]时,各实施例将math.tanh的输出钳制到1.0f,以在不损害准确性的情况下实现优化。对于其余的输入范围[2-12
,8),可执行二次逼近计算。在数学流水线中执行的操作可以如下。
[0201]
对于输入值x∈[2-12
,8),该输入值将被处理以确定索引和
△
。索引可用于从lut取出系数c0、c1、c2,随后索引和
△
它们一起被提供到二次逼近逻辑中以执行c0 c1*
△
c2*
△
*
△
来计算math.tanh(x)。
[0202]
在一些示例中,输入值可被分为不同的内插范围[0,1)、[1,2)、[2,4)和[4,8],并且为每个范围分配lut,但是不同范围可共享二次内插流水线的使用。
[0203]
来自math.tanh(x)的结果可以是中间结果,并且取决于输入范围,该中间结果可乘以比例因子。例如,以下表达式提供示例条件乘法。条件乘法可使用两条fpu指令来执行,即,最小(min)指令,用于将较小值选为x与
1.0f之间的比例因子;以及乘法指令,用于执行中间结果与比例因子的乘法。fpu指令可在fpu流水线中执行。
[0204]
图19描绘根据各实施例的用于math.tanh指令的输入范围和输出范围的示例。
[0205]
图20描绘用于执行tanh函数的示例过程。编译器可编译tanh api函数并生成三条原生指令:math.tanh指令、最小指令和一条乘法指令。math.tanh指令在数学流水线中执行,而最小指令和乘法指令在fpu流水线中执行。
[0206]
在2002处,图形处理单元的执行单元(eu)的数学流水线执行math.tanh指令,对于输入x,中间结果可通过基于输入x的值执行tanh(x)操作或tanh(x)/x操作来生成。例如,如果x值在范围[0,1)内。则可执行tanh(x)/x操作以生成中间结果。例如,如果x值在1以及更大范围内。则可执行tanh(x)操作以生成中间结果。在一些实施例中,取决于输入范围,中间结果可直接钳制到固定值以减少所使用的硬件量。例如,如果x∈[0,2-12
),则中间结果可直接钳制到1.0。例如,如果x∈[8, inf],则中间结果可直接钳制到1.0。例如,如果x∈[2-12
,8),则可执行二次操作c0 c1*
△
c2*
△
*
△
,其中:c0、c1和c2包括基于值x从查找表选择的恒定值,并且
△
包括x的多个尾数位。在一些实施例中,执行c0 c1*
△
c2*
△
*
△
可使用数学流水线逻辑或电路。
[0207]
在2004处,在fpu流水线中,基于输入值,使用最小指令用于生成比例因子。例如,如果x值在范围[0,1)内,则比例因子是输入的绝对值。例如,如果x值大于或等于1,则比例因子为1。在2006处,在fpu流水线中,可由乘法指令使在框2002中生成的中间结果乘以在框2004中生成的比例因子以生成对输入x生成tanh操作的输出。sigmoid命令执行
[0208]
对于sigmoid函数,可生成并执行标记为math.sigmoid的专用指令。对于给定输入,数学流水线可执行范围校验,并基于输入落在其内的范围来执行操作。例如,数学流水线对于范围[2-20
,16)和范围(-16,-2-20
]能够执行二次逼近。对于其余范围,输出可被钳制到固定值,以在不损害准确度的情况下节省成本。
[0209]
由于sigmoid(x)基于点(0,0.5)是点对称的,因此对于x《0,c0、c1和c2的系数可被存储。对于x》0的情况,系数c0’、c1’、c2’可使用诸如数学流水线之类的硬件逻辑从相应的c0、c1、c2导出。具体地,对于x》0,c0’=1
–
c0,c1’=-c1,c2’=-c2,并且硬件可执行这些操作以便以很小的成本计算这些系数。该方法可在不具有损失的准确度的损害的情况下使用一半lut。
[0210]
固有的api函数native_sigmoid(x)可由编译器编译以生成math.sigmoid指令。数学流水线可为math.sigmoid指令执行以下操作。
[0211]
输入范围可进一步被分为范围[0,2)、[2,4)、[4,8)、[8,16],并且用于每个范围的二次计算访问lut中的不同条目,但是内插二次流水线可由所有输入范围共享。在一些示例
中,钳制操作可发生以:对于输入[16, inf]将输出钳制到1,并对于输入[-inf,-16]将输出钳制到0。
[0212]
图21描绘根据各实施例的用于sigmoid计算的输入范围和输出范围的示例。
[0213]
图22描绘用于执行sigmoid操作的示例过程。math.sigmoid指令可由编译器从sigmoid应用程序接口(api)函数生成,并且可在数学流水线中被执行。在2202处,在图形处理单元的执行单元(eu)的数学流水线中,math.sigmoid指令被执行。基于输入值落在其中的范围,输出被钳制到固定值,或输出使用二次内插计算来计算。在一些示例中,对于二次计算,查找条目的集合仅对于负输入值被存储。对于正输入值,可在数学流水线中通过以下操作导出系数:c0’=1
–
c0,c1’=-c1,c2’=-c2。在一些示例中,sigmoid如下计算:
[0214]
各实施例提供用于tanh和sigmoid的原生指令,这些原生指令相比不同的软件仿真的实现方式可实现大约2.1x(2.1倍)至14.2x(14.2倍)的峰值吞吐量改进。模拟结果示出,对于重要的机器学习核,相比现有的高效仿真版本,端对端性能增益可以是约 3%至 17%。
[0215]
对于单精度浮点输入,对于整个范围,tanh准确度可以是4个ulp的相对误差,这对于opencl库和mkl两者都是足够的。对于sigmoid,当输入在[0, inf]范围内时,相对误差可小于7个ulp,而对于[-inf,-0]的输入,最大误差《3.9e-7。
[0216]
相比之下,具有同等准确度(4个ulp)的用于tanh的mkl软件实现方式使用10个双精度融合乘-加(fma)设备、10个32位操作(包括单精度fma、比较和选择、以及逻辑操作)、以及一个math.inv。
[0217]
短语“一个示例”或“示例”的出现不一定全部指代同一示例或实施例。本文中描述的任何方面可以与本文中描述的任何其他方面或类似方面组合,不论这些方面是否相对于同一附图或要素来描述。
[0218]
可以使用表达“耦合的”和“连接的”以及它们的派生词来描述一些示例。这些术语并不必旨在作为彼此的同义词。例如,使用术语“连接的”和/或“耦合的”的描述可指示两个或更多元件彼此处于直接的物理或电接触。然而,术语“耦合的”还可以意味着两个或更多个元件彼此未直接接触,但仍然彼此进行合作或交互。
[0219]
本文中的术语“第一”、“第二”等不指示任何顺序、数量或重要性,而是用于在要素之间进行区分。本文中的术语“一(“a”和“an”)”不指示对数量的限制,而是指示存在至少一个所引用的项。本文中参考信号使用的术语“断言的”指示信号的状态,其中信号是活跃的,并且这可以通过向信号施加逻辑0或逻辑1的任何逻辑电平来实现。术语“接着”或“在
……
之后”可以指代紧接着或跟在另一个或另一些事件之后。在流程图中,也可以根据替代实施例执行步骤的其他序列。此外,可以取决于特定应用添加或移除附加步骤。可以使用变化的任何组合,并且受益于本公开的本领域普通技术人员将理解本公开的许多变型、修改和替
代实施例。
[0220]
除非专门另外陈述,否则应理解诸如短语“x、y或z中的至少一个”之类的分隔语言在一般用于呈现项、项目等可以是x、y或z或其任何组合(例如,x、y和/或z)的上下文之内。因此,此类分隔语言一般不旨在暗示并且不应暗示某些实施例需要至少一个x、至少一个y或至少一个z各自都存在。此外,除非专门另外陈述,否则还应理解诸如短语“x、y和z中的至少一个”之类的分隔语言意味着x、y、z或其任何组合,包括“x、y和/或z”。
[0221]
本发明的实施例可包括上文已经描述的各步骤。这些步骤可以被具体化为机器可执行指令,这些机器可执行指令可以用于使通用或专用处理器执行这些步骤。替代地,这些步骤可由包含用于执行这些步骤的硬接线逻辑的特定硬件组件来执行,或者由经编程的计算机组件和定制硬件组件的任何组合来执行。
[0222]
如本文中所描述,指令可以指诸如专用集成电路(asic)的硬件的特定配置,该专用集成电路被配置用于执行某些操作或者具有预定功能或存储在被具体化为非暂态计算机可读介质的存储器中的软件指令。因此,可以使用在一个或多个电子设备(例如,端站、网络元件等)上存储并执行的代码和数据来实现附图中示出的技术。此类电子设备使用计算机机器可读介质(在内部和/或通过网络与其他电子设备)存储和传达代码和数据,计算机机器可读介质诸如非暂态计算机机器可读存储介质(例如,磁盘;光盘;随机存取存储器;只读存储器;闪存设备;相变存储器)以及暂态计算机机器可读通信介质(例如,电、光、声或其他形式的传播信号——诸如载波、红外信号、数字信号等)。
[0223]
此外,此类电子设备典型地包括耦合到一个或多个其他组件(诸如,一个或多个存储设备(非暂态机器可读存储介质)、用户输入/输出设备(例如,键盘、触摸屏和/或显示器)、以及网络连接)的一个或多个处理器的集合。处理器的集合和其他组件的耦合典型地通过一个或多个总线和桥接器(也被称为总线控制器)。承载网络通信量的存储设备和信号分别表示一个或多个机器可读存储介质和机器可读通信介质。因此,给定电子设备的存储设备典型地存储用于在该电子设备的一个或多个处理器的集合上执行的代码和/或数据。当然,可以使用软件、固件、和/或硬件的不同组合来实现本发明的实施例的一个或多个部分。贯穿此具体实施方式,出于解释的目的,阐述了众多特定细节以便提供对本发明的透彻理解。然而,对于本领域的技术人员而言将显而易见的是,可以在没有这些特定细节中的一些的情况下实现本发明。在某些实例中,未详细地描述公知结构和功能以避免使本发明的主题模糊。因此,本发明的范围和精神应根据所附权利要求来判定。
[0224]
示例1包括一种计算机实现的方法,该方法包括:通过以下步骤在图形处理单元的执行单元(eu)的数学流水线和浮点单元(fpu)流水线中执行tanh函数:基于输入x的值的范围,通过执行tanh(x)操作或tanh(x)/x操作来生成中间结果;基于输入x的值的范围,使用最小操作来生成比例因子;以及将中间结果与比例因子相乘以对输入x生成tanh函数的输出。
[0225]
示例2包括任何示例,并且包括:如果x的值在第一范围内,则:确定tanh(x)/x以生成中间结果,并将中间结果乘以x;或者如果x的值在第二范围内,则:确定tanh(x)以生成中间结果,并且将中间结果乘以值。
[0226]
示例3包括任何示例,其中,确定tanh(x)包括:执行二次内插操作或钳制到固定值。
[0227]
示例4包括任何示例,其中,执行二次内插操作包括:生成c0 c1*
△
c2*
△
*
△
,其中:c0、c1和c2包括基于x的值从查找表选择的恒定值,并且
△
包括x的尾数的位。
[0228]
示例5包括任何示例,其中,内插逻辑执行生成c0 c1*
△
c2*
△
*
△
。
[0229]
示例6包括任何示例,其中,使用最小操作生成比例因子包括执行以下操作:min(abs(x),1),用于选择x的绝对值和1中的较小者。
[0230]
示例7包括任何示例,其中,tanh操作由编译器从tanh应用程序接口(api)生成,作为tanh指令、最小指令、以及一条乘法指令。
[0231]
示例8包括任何示例,并且包括执行sigmoid的方法,该方法包括:对输入值执行sigmoid操作,包括:基于输入值的范围,将输出钳制到固定值,或执行分段二次内插。
[0232]
示例9包括任何示例,其中,将输出钳制到固定值或执行分段二次内插包括:
[0233]
示例10包括任何示例,并且包括:提供对不同范围的系数的不同查找表条目的访问,其中,仅用于负输入的系数被存储在不同的查找表条目中,并且用于正输入的系数从用于负输入的系数导出。
[0234]
示例11包括任何示例,并且包括一种包括存储在其上的指令的非暂态计算机可读介质,这些指令如果由一个或多个处理器执行,则使一个或多个处理器用于:将tanh应用程序接口(api)执行为tanh指令、最小指令、以及一条乘法指令的组合。
[0235]
示例12包括任何示例,其中,tanh指令包括:如果输入x的值在的[0,1)范围内,则tanh指令的执行引起生成tanh(x)/x操作以生成中间结果以及引起中间结果乘以x的乘法;或者如果输入x的值在1和更大的范围内,则tanh指令的执行引起生成tanh(x)以生成中间结果以及引起中间结果乘以1.0f的乘法。
[0236]
示例13包括任何示例,其中,生成tanh(x)包括执行二次内插操作,或钳制到固定值。
[0237]
示例14包括任何示例,其中执行二次内插操作包括:确定c0 c1*
△
c2*
△
*
△
,其中:c0、c1和c2包括基于输入值x的值从查找表选择的恒定值,并且
△
包括x的尾数的位。
[0238]
示例15包括任何示例,并且包括:一种包括存储在其上的指令的非暂态计算机可读介质,这些指令如果由一个或多个处理器执行,则使一个或多个处理器用于:将sigmoid应用程序接口(api)执行为:基于输入值的范围,将输出钳制到固定值,或执行分段二次内插。
[0239]
示例16包括任何示例,其中执行分段二次内插包括:提供对不同范围的系数的不同查找表条目的访问,其中,仅用于负输入的系数被存储在不同的查找表条目中,并且用于正输入的系数从用于负输入的系数导出。
[0240]
示例17包括任何示例,并且包括一种图形处理装置,其包括:存储器设备;以及图形处理单元(gpu),包括至少一个执行单元,执行单元被配置成用于:将tanh应用操作执行
为tanh指令、最小指令、以及一条乘法指令的组合;以及对输入值执行sigmoid操作,包括:基于输入值的范围,将输出钳制到固定值,或执行分段二次内插。
[0241]
示例18包括任何示例,其中,执行单元包括数学流水线和浮点单元(fpu)流水线。
[0242]
示例19包括任何示例,其中,为了执行tanh应用操作,数学流水线用于:如果x的值在第一范围内,则:确定tanh(x)/x以生成中间结果,并且将中间结果乘以x;或者如果x的值在第二范围内,则:确定tanh(x)以生成中间结果,并且将中间结果乘以值,其中,确定tanh(x)包括:执行二次内插操作,或钳制到固定值。
[0243]
示例20包括任何示例,其中,执行分段二次内插包括:访问不同范围的系数的不同查找表条目,其中,仅用于负输入的系数被存储在不同的查找表条目中,并且用于正输入的系数从用于负输入的系数导出。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。