1.本发明基于机器学习领域,进一步说是基于正则化的变分深度聚类模型。
背景技术:
2.在机器学习实际应用中,无监督聚类仍是非常重要的一个领域分支。传统的聚类算法都会面临维数灾难的问题,所以利用深度学习方法来学习聚类成为该领域的一个重要方向。深度生成模型在数据生成能力上表现很好,但是无法完成聚类任务。于是本发明提出了一种基于正则化的变分深度聚类模型。
3.深层生成模型是一种利用低维隐向量对高维数据进行建模的模型。变分自编码模型是结合了变分贝叶斯方法和神经网络结构的生成模型,包括生成网络和推理网络,均利用神经网络结构实现。联合训练两个网络,最大化数据似然的变分下界。不同于传统的自编码模型,变分自编码利用重参数技巧获得隐向量,然后隐向量利用生成网络重构出数据。这里采用的变分方法将变量求和的推理问题转化为优化问题,再通过随机梯度下降方法和反向传播算法求解该优化问题。
4.变分自编码模型无法对数据进行聚类,所以本发明提出基于正则化的变分深度聚类模型。
技术实现要素:
5.本发明提供了基于正则化的变分深度聚类模型,不仅生成高质量的数据,而且可以在数据的隐空间学习聚类信息。
6.基于正则化的变分深度模型,包括:模型建模模块、构建优化目标模块、
7.基于正则化的变分深度模型,包括:模型建模模块、构建优化目标模块、及优化问题求解模块。
8.模型建模模块是在变分自编码模型的数据隐空间中使用高斯混合模型,将数据描述为由离散的隐向量y与连续的隐向量z联合生成。p(y)表示蕴含分类信息的隐向量y的先验概率分布,z表示数据在隐空间中的特征隐向量。q
φ
(y,z|x)表示近似后验概率分布,p
β
(z|y)、p
θ
(x|z)表示两个条件概率分布。在模型中,样本数据x利用后验概率分布进行采样重参后得到隐向量z,z利用概率分布计算聚类分配概率,同时利用条件概率分布p
θ
(x|z)生成观测数据x。模型的联合概率分布为:p(x,y,z)=p(y)p
β
(z|y)p
θ
(x|z)。
9.构建优化目标对于数据集是x={x
(1)
,x
(2)
…
,x
(n)
},其中n表示数据集的大小。数据集x似然为对其中一个数据点x求边缘似然:
10.log p(x)=elbo d
kl
(q(z,y|x)||p(z,y|x))
11.由于d
kl
(q(z,y|x)||p(z,y|x))≥0,所以log p(x)≥elbo,elbo是数据点x的证据似然下界:
[0012][0013]
对每个隐向量z和y都引入一个推理模型分别为多元高斯分布和多项式分布。在上式中,等式右边分别为:重构项、先验项和条件项。为了提升模型的稳定性,加入了样本熵与批量样本熵作为模型的正则化项。样本熵为:
[0014][0015]
其中,k为高斯混合模型组件的个数。批量样本熵为:
[0016][0017]
其中b为批量样本集的大小,z(i)为第i个隐向量样本。此时在批量大小为b的样本集xb上,损失函数表达式为:
[0018][0019]
其中,l为蒙特卡洛采样次数,z
(i,l)
表示第i个样本的第l次蒙特卡洛采样得到的隐向量样本,ρ、η与γ分别对应重构项,样本熵与批量样本上的权重,{θ,φ,β}为模型参数。
[0020]
最小化上述损失函数,求解出模型参数{θ,φ,β}。采用重参化技巧采样,再用随机梯度下降方法进行参数更新。
附图说明
[0021]
为了更清楚的说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单介绍,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0022]
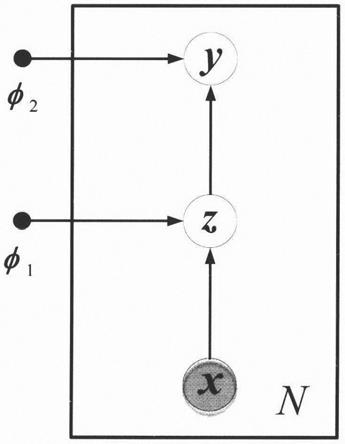
图1附图是基于正则化的变分深度聚类模型的推理模型示意图,图2附图是生成模型的示意图。
具体实施方式
[0023]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0024]
本发明实施例公开了基于正则化的变分深度聚类模型,具体包括包括:模型建模模块、构建优化目标模块、及优化问题求解模块。
[0025]
模型建模模块对变分自编码模型的隐空间使用高斯混合模型,来学习数据的聚类信息。p(y)表示多项式分布,假设隐向量z由随机向量y生成,观测向量x由隐向量z生成,生成过程为:
[0026]
p(y)=mult(y;π),
[0027][0028][0029]
其中p(y)表示表示离散向量y的先验概率分布,为多项式分布,即参数为π={π1,π2,...,πk},满足yk∈{0,1},且y=(y1,y2,...,yk)
t
为独热编码向量。p
β
(z|y)表示隐向量z的条件概率分布,与均有神经网络学习。p
θ
(x|z)表示x的条件概率分布,分为两种情况:x为离散型随机向量时,为伯努利分布;x为连续性随机变量时,为高斯分布。模型的联合概率分布为:p(x,y,z)=p(y)p
β
(z|y)p
θ
(x|z)。
[0030]
构建优化目标对于数据集是x={x
(1)
,x
(2)
…
,x
(n)
},其中n表示数据集的大小。对每个隐向量z和y都引入一个推理模型分别为多元高斯分布和多项式分布。数据集x似然为其中一个数据点x的证据似然下界为:
[0031][0032]
数据x通过近似后验概率采样z
(l)
,即:ε
(l)
:n(0,i),z
(l)
利用概率分布计算聚类分配概率,同时利用条件概率分布p
θ
(x|z
(l)
)生成观测数据x,得到证据似然下界elbo。
[0033]
模型有两项正则化项,第一项为样本熵,即对于一个样本数据x,样本熵为:
[0034][0035]
第二项为批量样本熵,即对于一个批量大小为b的样本集xb上,批量样本熵为:
[0036][0037]
其中则在批量大小为b的样本集xb上,模型损失函数为:
[0038][0039]
其中,η和γ为调节正则化强度的超参数。
[0040]
最小化上述损失函数,求解出模型参数{θ,φ,β}。采用重参化技巧采样,再用随机梯度下降方法进行参数更新。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。