技术特征:
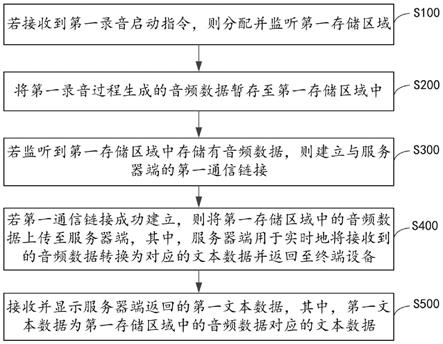
1.一种实时语音识别方法,其特征在于,所述方法包括:若接收到第一录音启动指令,则分配并监听第一存储区域;将第一录音过程生成的音频数据暂存至所述第一存储区域中;若监听到所述第一存储区域中存储有音频数据,则建立与服务器端的第一通信链接;若所述第一通信链接成功建立,则将所述第一存储区域中的音频数据上传至所述服务器端,其中,所述服务器端用于实时地将接收到的音频数据转换为对应的文本数据并返回至终端设备;接收并显示所述服务器端返回的第一文本数据,其中,所述第一文本数据为所述第一存储区域中的音频数据对应的文本数据。2.根据权利要求1所述的方法,其特征在于,在所述接收并显示所述服务器端返回的第一文本数据之后,所述方法还包括:若所述第一通信链接为空闲状态,则断开所述第一通信链接。3.根据权利要求1所述的方法,其特征在于,在所述将第一录音过程生成的音频数据暂存至所述第一存储区域中之后,所述方法还包括:若在所述第一录音结束之后,接收到第二录音启动指令,则分配并监听第二存储区域;将第二录音过程生成的音频数据暂存至所述第二存储区域中;若所述第一通信链接已断开,则若监听到所述第二存储区域中存储有音频数据,建立与所述服务器端的第二通信链接,若所述第二通信链接成功建立,则通过所述第二通信链接将所述第二存储区域中的音频数据上传至所述服务器端,通过所述第二通信链接接收并显示所述服务器端返回的第二文本数据,其中,所述第二文本数据为所述第二存储区域中的音频数据对应的文本数据;若所述第一通信链接未断开,则通过所述第一通信链接将所述第二存储区域中的音频数据上传至所述服务器端,通过所述第一通信链接接收并显示所述服务器端返回的所述第二文本数据。4.根据权利要求1所述的方法,其特征在于,在所述将第一录音过程生成的音频数据暂存至所述第一存储区域中之后,所述方法还包括:若在所述第一录音结束之后,在预设时长内接收到第二录音启动指令,则将第二录音过程生成的音频数据暂存至所述第一存储区域中。5.根据权利要求4所述的方法,其特征在于,所述方法还包括:若在所述第一录音结束之后,在预设时长之后接收到第二录音启动指令,则分配并监听第二存储区域;将第二录音过程生成的音频数据暂存至所述第二存储区域中;若所述第一通信链接未断开,则通过所述第一通信链接将所述第二存储区域中的音频数据上传至所述服务器端,通过所述第一通信链接接收并显示所述服务器端返回的第二文本数据,其中,所述第二文本数据为所述第二存储区域中的音频数据对应的文本数据;若所述第一通信链接已断开,则若监听到所述第二存储区域中存储有音频数据,则建立与所述服务器端的第二通信链接,
若所述第二通信链接成功建立,则通过所述第二通信链接将所述第二存储区域中的音频数据上传至所述服务器端,所述服务器端用于实时地将接收到的音频数据转换为对应的文本数据并返回至所述终端设备,通过所述第二通信链接接收并显示所述服务器端返回的所述第二文本数据。6.根据权利要求1所述的方法,其特征在于,所述将第一录音过程生成的音频数据暂存至所述第一存储区域中,包括:每当录音过程新生成的音频数据的累计数据量达到预设的回调数据量时,调用录音接口,以对达到所述回调数据量的该新生成的音频数据进行一次回调并暂存入所述第一存储区域中。7.根据权利要求1所述的方法,其特征在于,所述建立与服务器端的第一通信链接,包括:将预设的语音转换规则、认证信息以及用户身份信息加密后发送至所述服务器端,以建立与所述服务器端的第一通信链接。8.一种实时语音识别装置,其特征在于,所述装置包括:第一缓存创建模块,用于若接收到第一录音启动指令,则分配并监听第一存储区域;第一缓存模块,用于将第一录音过程生成的音频数据暂存至所述第一存储区域中;第一链接建立模块,用于若监听到所述第一存储区域中存储有音频数据,则建立与服务器端的第一通信链接;第一数据上传模块,用于若所述第一通信链接成功建立,则将所述第一存储区域中的音频数据上传至所述服务器端,其中,所述服务器端用于实时地将接收到的音频数据转换为对应的文本数据并返回至终端设备;接收显示模块,用于接收并显示所述服务器端返回的第一文本数据,其中,所述第一文本数据为所述第一存储区域中的音频数据对应的文本数据。9.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机可读指令,其特征在于,所述处理器执行所述计算机可读指令时执行如权利要求1-7任一项所述的实时语音识别方法的步骤。10.一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机可读指令,其特征在于,所述计算机可读指令被处理器执行时,使得所述处理器执行如权利要求1-7任一项所述的实时语音识别方法的步骤。
技术总结
本申请涉及人工智能技术,提出一种基于人工智能的语音识别方法、装置、设备和存储介质,该方法包括:若接收到录音启动指令,则分配并监听存储区域;将录音过程生成的音频数据暂存至存储区域;若监听到存储区域中存储有音频数据,则建立与服务器端的通信链接;若通信链接成功建立,则将存储区域中的音频数据上传至服务器端;接收并显示服务器端返回的文本数据。本申请通过用户的录音操作仅控制录音的开启和关闭,而通信链接的建立由音频数据的存在与否进行驱动。既保证了用户可以随时按下按钮进行录音,减少录音信息的丢失,实现实时语音识别,同时不会出现空闲链接造成的服务器资源浪费,有效减轻服务器的压力。有效减轻服务器的压力。有效减轻服务器的压力。
技术研发人员:林雨阳
受保护的技术使用者:中国平安人寿保险股份有限公司
技术研发日:2021.11.18
技术公布日:2022/2/24
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。