1.本发明涉及车辆领域,尤其是涉及一种车载人物情绪展示方法以及一种车载人物情绪展示装置。
背景技术:
2.相关技术中,现有的车辆上的车载人物情绪展示装置是通过摄像头来获取车主的情绪,然而由于人普遍压力较大,比较压抑,情绪并不经常体现在面部表情上,这样通常无法真实的反映车主内心的情绪,仅仅是复制车主的表情,并没有将车主真正的情绪体现在车载屏幕上,使车辆缺少趣味感知,导致车辆科技感降低。
技术实现要素:
3.本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明的一个目的在于提出一种车载人物情绪展示方法,通过本技术的车载人物情绪展示方法,能够在车辆上展示出人物情绪动作,可以更加真实反映出用户内心的情绪,从而可以提升车辆的趣味感知,进而可以提升车辆科技感。
4.本发明进一步地提出了一种计算机可读存储介质。
5.本发明进一步地提出了车载中控设备。
6.本发明进一步地提出了一种车载人物情绪展示装置。
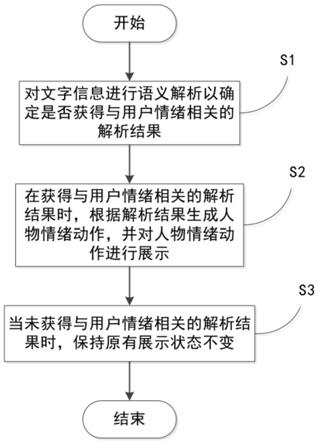
7.根据本发明的车载人物情绪展示方法包括以下步骤:对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果;当获得与用户情绪相关的解析结果时,根据所述解析结果生成人物情绪动作,并对所述人物情绪动作进行展示;当未获得与用户情绪相关的解析结果时,保持原有展示状态不变。
8.根据本发明的车载人物情绪展示方法,通过对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果,在获得与用户情绪相关的解析结果时,根据解析结果生成人物情绪动作,然后对人物情绪动作进行展示,当未获得与用户情绪相关的解析结果时,保持原有展示状态不变,能够在车辆上展示出人物情绪动作,可以更加真实反映出用户内心的情绪,从而可以提升车辆的趣味感知,进而可以提升车辆科技感。
9.在本发明的一些示例中,对所述文字信息进行语义解析,包括:通过本地对所述文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果;如果否,则将所述文字信息发送到云端服务器,以通过所述云端服务器对所述文字信息进行语义解析。
10.在本发明的一些示例中,在未接收到所述云端服务器反馈的解析结果时,对上一次的人物情绪动作进行展示。
11.在本发明的一些示例中,在所述对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果之前,获取用户的语音信息,对所述语音信息进行识别以获得所述文字信息。
12.在本发明的一些示例中,在对所述人物情绪动作进行展示时,还根据所述语音信
息获取音频振幅,根据所述音频振幅对所述人物情绪动作进行调整。
13.在本发明的一些示例中,确定所述音频振幅的变化情况,根据所述音频振幅的变化情况对所述人物情绪动作的深浅进行调整。
14.根据本发明的计算机可读存储介质,其上存储有车载人物情绪展示程序,该车载人物情绪展示程序被处理器执行时实现上述的车载人物情绪展示方法。
15.根据本发明的计算机可读存储介质,存储的车载人物情绪展示程序被处理器执行,能够获取用户的语音信息,并对语音信息进行识别以获得文字信息,然后对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果,在获得与用户情绪相关的解析结果时,根据解析结果生成人物情绪动作,然后对人物情绪动作进行展示,能够在车辆上展示出人物情绪动作,可以更加真实反映出用户内心的情绪,从而可以提升车辆的趣味感知,进而可以提升车辆科技感。
16.根据本发明的车载中控设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的车载人物情绪展示程序,所述处理器执行所述车载人物情绪展示程序时,实现上述的车载人物情绪展示方法。
17.根据本发明的车载中控设备,通过处理器执行储存器上储存的车载人物情绪展示程序,储存的车载人物情绪展示程序被处理器执行,能够获取用户的语音信息,并对语音信息进行识别以获得文字信息,然后对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果,在获得与用户情绪相关的解析结果时,根据解析结果生成人物情绪动作,然后对人物情绪动作进行展示,能够在车辆上展示出人物情绪动作,可以更加真实反映出用户内心的情绪,从而可以提升车辆的趣味感知,进而可以提升车辆科技感。
18.根据本发明实施例的车载人物情绪展示装置包括:语音获取模块,用于获取用户的语音信息;语音识别模块,用于对所述语音信息进行识别以获得文字信息;语音解析模块,用于对所述文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果;展示控制模块,用于在获得与用户情绪相关的解析结果时,根据所述解析结果生成人物情绪动作,并对所述人物情绪动作进行展示,当未获得与用户情绪相关的解析结果时,用于保持原有展示状态不变;所述语音解析模块还用于,通过本地对所述文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果,如果否,则将所述文字信息发送到云端服务器,以通过所述云端服务器对所述文字信息进行语义解析;所述展示控制模块还用于,在未接收到所述云端服务器反馈的解析结果时,对上一次的人物情绪动作进行展示。
19.根据本发明的车载人物情绪展示装置,通过语音获取模块获取用户的语音信息,然后通过语音识别模块对语音信息进行识别以获得文字信息,再然后通过语音解析模块对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果,语音解析模块可以通过本地对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果,如果否,则将文字信息发送到云端服务器,通过云端服务器对文字信息进行语义解析,最后在获得与用户情绪相关的解析结果时,根据解析结果生成人物情绪动作,并对人物情绪动作进行展示,若未获得与用户情绪相关的解析结果,则保持原有展示状态不变,当用户启动车载人物情绪展示装置时,可以获取用户的语音信息并对其进行识别以获得文字信息,对文字信息进行语义解析,根据解析结果生成并展示人物情绪动作,能够在车辆上展示出人物情绪动作,可以更加真实反映出用户内心的情绪,从而可以提升车辆的趣味感知,进而可以提升车
辆科技感。
20.在本发明的一些实施例中,上述的展示装置还包括音频振幅获取模块,用于根据所述语音信息获取音频振幅,并确定所述音频振幅的变化情况,其中,所述展示控制模块还用于在对所述人物情绪动作进行展示时根据所述音频振幅的变化情况对所述人物情绪动作的深浅进行调整。
21.本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
22.本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
23.图1是根据本发明实施例的车载人物情绪展示方法的流程图;
24.图2是根据本发明实施例的人物情绪动作的示意图;
25.图3是根据本发明实施例的人物情绪动作的另一个实施例的示意图;
26.图4是根据本发明实施例的人物情绪动作的另一个实施例的示意图;
27.图5是根据本发明实施例的人物情绪动作的另一个实施例的示意图;
28.图6是根据本发明实施例的车载中控设备的方框示意图;
29.图7是根据本发明实施例的车载人物情绪展示装置的方框示意图。
30.附图标记:
31.车载人物情绪展示装置100;
32.语音获取模块20;麦克风21;
33.语音识别模块30;语音解析模块40;展示控制模块50;音频振幅获取模块70;
34.处理器1201;通信接口1202;存储器1203;通信总线1204。
具体实施方式
35.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
36.下面参考附图来描述根据本发明实施例的车载人物情绪展示装置100,车载人物情绪展示装置100可以设置在车辆上。
37.如图1-图7所示,根据本发明实施例的车载人物情绪展示装置100可以包括:语音获取模块20、语音识别模块30、语音解析模块40和展示控制模块50。其中,语音获取模块20可以用于获取用户的语音信息,需要说明的是,语音获取模块20可以包括至少一个麦克风21,当用户启动车载人物情绪展示装置100时,语音获取模块20的麦克风21可以用于获取用户的语音信息,需要解释的是,用户可以通过物理方式控制按键或者通过语音唤醒词启动车载人物情绪展示装置100,从而开启语音获取模块20。语音识别模块30可以用于对语音信息进行识别以获得文字信息,也可以理解为,语音识别模块30可以将语音获取模块20传递来的语音转换成文字信息。语音解析模块40可以用于对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果,展示控制模块50用于在获得与用户情绪相关的解析结果
时,根据解析结果生成人物情绪动作,并对人物情绪动作进行展示。需要说明的是,如果确定获得与用户情绪相关的解析结果,语音解析模块40可以将解析结果传递到展示控制模块50,展示控制模块50可以根据解析结果生成人物情绪动作,并且展示控制模块50对人物情绪动作进行展示,从而使用户看见人物情绪动作,若展示控制模块50未获得与用户情绪相关的解析结果时,展示控制模块50可以保持原有展示状态不变。语音解析模块40还可以用于,通过本地对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果,如果否,则将文字信息发送到云端服务器,以通过云端服务器对所述文字信息进行语义解析,其中,如果语音解析模块40通过本地对文字信息进行解析没有结果,则代表解析失败,解析失败后,语音解析模块40可以将文字信息发送到云端服务器,通过云端服务器对文字信息继续进行语义解析,如果云端服务器对文字信息进行解析并获得解析结果,则云端服务器可以将解析结果传递给展示控制模块50,需要说明的是,语音解析模块40通过本地对语音识别模块30传递来的文字信息进行解析,当语音解析模块40对文字信息进行解析有结果则代表解析成功,解析成功后语音解析模块40可以将解析结果传递给展示控制模块50,以在展示控制模块50上展示人物情绪动作。展示控制模块50还可以用于,在未接收到云端服务器反馈的解析结果时,对上一次的人物情绪动作进行展示。
38.其中,语音获取模块20可以设置在车载中控大屏内,语音获取模块20包括的至少一个麦克风21也可以设置在车载中控大屏内,用户可以通过物理方式控制语音按键启动车载人物情绪展示装置100,进而唤醒语音获取模块20的麦克风21,实现从硬件层面去开启软件的语音获取功能,用户还可以通过事先设置语音唤醒词,然后在需要启动车载人物情绪展示装置100,且唤醒语音获取模块20的麦克风21时,用户说出语音唤醒词,可以实现启动车载人物情绪展示装置100的功能。但本发明不限于此,启动车载人物情绪展示装置100、唤醒语音获取模块20的麦克风21的方式可以但不限于上述两种方式。
39.当用户启动车载人物情绪展示装置100,唤醒语音获取模块20的麦克风21后,语音获取模块20通过麦克风21获取用户的语音信息,语音获取模块20的麦克风21获取到用户的语音信息后,语音获取模块20会将获取的用户的语音信息传递给语音识别模块30。语音识别模块30可以对语音获取模块20传递来的语音信息进行识别,可以获得语音信息的文字信息。然后语音识别模块30将获得的文字信息传递给语音解析模块40,当语音解析模块40收到语音识别模块30传递来的文字信息后,语音解析模块40可以对语音识别模块30传递来的文字信息进行语义解析,可以确定是否获得与用户情绪相关的解析结果,例如,语音识别模块30传递给语音解析模块40的文字信息为“很高兴认识你”,语音解析模块40可以获得解析结果为用户“高兴”,语音识别模块30传递给语音解析模块40的文字信息为“跟你说我感到好伤心”,语音解析模块40可以获得解析结果为用户“伤心”,当语音解析模块40确定获得与用户情绪相关的解析结果后,语音解析模块40可以将解析结果传递给展示控制模块50,当展示控制模块50获得与用户情绪相关的解析结果时,展示控制模块50可以根据语音解析模块40获得的与用户情绪相关的解析结果生成人物情绪动作,并通过中控大屏对人物情绪动作进行展示,例如,语音解析模块40获得解析结果为用户“高兴”,则展示控制模块50生成的人物情绪动作为“微笑”,语音解析模块40获得解析结果为用户“伤心”,则展示控制模块50生成的人物情绪动作为“哭”。当用户启动车载人物情绪展示装置100时,通过语音获取模块20、语音识别模块30、语音解析模块40和展示控制模块50配合工作,能够在车辆上展示出人
物情绪动作,可以更加真实反映出用户内心的情绪,从而可以提升车辆的趣味感知,进而可以提升车辆科技感。
40.由此,通过语音获取模块20获取用户的语音信息,然后通过语音识别模块30对语音信息进行识别以获得文字信息,然后通过语音解析模块40文字信息进行语义解析并确定是否获得与用户情绪相关的解析结果,最后展示控制模块50在语音解析模块40确定获得与用户情绪相关的解析结果时,根据解析结果生成人物情绪动作,并对人物情绪动作进行展示,从而可以使用户真正的情绪通过人物情绪动作展示出来,从而可以提升车辆的趣味感知,进而可以提升车辆科技感,并且,通过本地和云端服务器对文字信息进行语义解析以获得与用户情绪相关的解析结果,可以增加解析成功的概率,从而可以提高人物情绪展示装置100工作可靠性。
41.作为一个实施例,展示控制模块50可以设置在中控大屏内,在中控大屏内可以设置一个计时装置,计时装置可以设定一个时间段,语音解析模块40通过云端服务器对文字信息解析时进行检验,当在计时装置设定的时间段内,云端服务器对文字信息解析并将解析结果反馈给展示控制模块50,则代表云端服务器对文字信息解析成功,若在计时装置设定的时间段内,云端服务器对文字信息解析但没有将解析结果反馈给展示控制模块50,则代表云端服务器对文字信息解析失败,此时,展示控制模块50将对上一次的人物情绪动作进行展示。优选地,计时装置设定的时间段可以为一秒,当云端服务器对文字信息解析,并在一秒内将解析结果反馈给展示控制模块50,则代表云端服务器对文字信息解析成功,若没有在一秒内将解析结果反馈给展示控制模块50,则代表解析失败,展示控制模块50将对上一次的人物情绪动作进行展示,由此,无论语音解析模块40解析成功或者解析失败,展示控制模块50都能够对人物情绪动作进行展示,从而可以进一步提高人物情绪展示装置100的工作可靠性。
42.在本发明的一些实施例中,人物情绪展示装置100还可以包括音频振幅获取模块70,音频振幅获取模块70可以用于根据语音信息获取音频振幅,并确定音频振幅的变化情况,需要说明的是,语音获取模块20通过麦克风21获取用户的语音信息后,可以将语音信息传递给音频振幅获取模块70,音频振幅获取模块70可以根据语音获取模块20传递来的语音信息获取音频振幅,并确定音频振幅的变化情况,然后将音频振幅的变化情况传递给展示控制模块50,其中,展示控制模块50还可以用于在对人物情绪动作进行展示时根据音频振幅的变化情况对人物情绪动作的深浅进行调整。
43.需要说明的是,无论语音解析模块40通过本地或者云端服务器是否对文字信息解析成功,一段语音信息的音频振幅,从开始到结束都会被音频振幅获取模块70记录并计算出音频的平均振幅或分贝大小,并且在计算平均振幅或分贝大小前,音频振幅获取模块70会事先对音频做降噪以及回声消除,然后在计算平均振幅或分贝大小,并将音频的平均振幅或分贝大小反馈给展示控制模块50,展示控制模块50可以依据语音解析模块40对语义解析并反馈的结果展示用户的主要情绪,展示控制模块50还可以依据音频振幅获取模块70计算并反馈的音频的平均振幅或分贝大小对情绪的深浅进行展示,并且,展示控制模块50还可以依据平均振幅或分贝大小,衍生出情绪动作,例如当语音解析模块40反馈给展示控制模块50的解析结果为“高兴”时,展示控制模块50可以依据平均振幅或分贝大小,衍生出“赞”等情绪动作,并且无论动作图示为2d/3d维度,都可以根据平均振幅或分贝的大小放大
或缩小衍生的情绪动作,优选地,可以对情绪的深浅和衍生的情绪动作分为大、中、小三个级别。
44.作为一个实施例,当语音解析模块40反馈给展示控制模块50的解析结果为“高兴”,则展示控制模块50可以根据音频振幅获取模块70反馈的音频的平均振幅或分贝大小对情绪深浅进行展示,比如,音频的平均振幅或分贝在39分贝以下判断为小,则展示控制模块50展示为“微笑”,音频的平均振幅或分贝在40分贝以上判断为中,则展示控制模块50展示为“一般笑”,音频的平均振幅或分贝在60分贝以上判断为大,则展示控制模块50展示为“狂笑”,并且可以相应的衍生出“赞、普通赞、大赞”等衍生动作。如果在计时装置设定的时间段内展示控制模块50没有收到语音解析模块40反馈的解析结果,则展示控制模块50展示上一次的人物情绪动作。由此,可以进一步将用户真正的情绪通过展示控制模块50展示出来。
45.需要说明的是,如图2所示,如果音频的平均振幅较小,则可在展示控制模块50展示“倒赞”的图案,且“倒赞”缩小。如图3所示,如果音频的平均振幅为中,则可在展示控制模块50展示“紧紧握拳”的图案,且“紧紧握拳”图案放大。如图4所示,如果音频的平均振幅为大,则可在展示控制模块50展示“闪电”的图案。如图5所示,如果音频的平均振幅非常大,则可在展示控制模块50展示“闪电”变大后的图案。
46.如图1所示,根据本发明实施例的车载人物情绪展示方法包括以下步骤:
47.s1,对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果时,语音解析模块可以用于对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果。需要说明的是,语音解析模块可以对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果,如果确定获得与用户情绪相关的解析结果,则语音解析模块可以将解析结果传递到展示控制模块。
48.s2,当获得与用户情绪相关的解析结果时,根据所述解析结果生成人物情绪动作,并对所述人物情绪动作进行展示。需要解释的是,展示控制模块可以在获得与用户情绪相关的解析结果时,根据解析结果生成人物情绪动作,并对人物情绪动作进行展示。
49.s3,当未获得与用户情绪相关的解析结果时,保持原有展示状态不变,需要解释的是,当车载人物情绪展示装置展示至少一次人物情绪动作时,原有展示状态是指展示控制模块上一次展示的人物情绪动作,当车载人物情绪展示装置初次使用时,原有展示状态可以指车载人物情绪展示装置存储的动作。
50.其中,语音解析模块可以对文字信息进行语义解析,可以确定是否获得与用户情绪相关的解析结果,例如,语音识别模块传递给语音解析模块的文字信息为“很高兴认识你”,语音解析模块可以获得解析结果为用户“高兴”,语音识别模块传递给语音解析模块的文字信息为“跟你说我感到好伤心”,语音解析模块可以获得解析结果为用户“伤心”,当语音解析模块确定获得与用户情绪相关的解析结果后,语音解析模块可以将解析结果传递给展示控制模块,当展示控制模块获得与用户情绪相关的解析结果时,展示控制模块可以根据语音解析模块获得的与用户情绪相关的解析结果生成人物情绪动作,并通过中控大屏对人物情绪动作进行展示,例如,语音解析模块获得解析结果为用户“高兴”,则展示控制模块生成的人物情绪动作为“微笑”,语音解析模块获得解析结果为用户“伤心”,则展示控制模块生成的人物情绪动作为“哭”。当用户启动车载人物情绪展示装置时,若展示控制模块未
获得与用户情绪相关的解析结果,则保持原有展示状态不变。通过语音解析模块和展示控制模块配合工作,能够在车辆上展示出人物情绪动作,可以更加真实反映出用户内心的情绪,从而可以提升车辆的趣味感知,进而可以提升车辆科技感。
51.由此,通过语音解析模块文字信息进行语义解析并确定是否获得与用户情绪相关的解析结果,然后展示控制模块在语音解析模块确定获得与用户情绪相关的解析结果时,根据解析结果生成人物情绪动作,并对人物情绪动作进行展示,展示控制模块在未获得与用户情绪相关的解析结果时,保持原有展示状态不变,从而可以使用户真正的情绪通过人物情绪动作展示出来,从而可以提升车辆的趣味感知,进而可以提升车辆科技感。
52.在本发明的一些实施例中,对文字信息进行语义解析还可以包括:通过本地对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果,如果否,则将文字信息发送到云端服务器,以通过云端服务器对文字信息进行语义解析。其中,如果语音解析模块通过本地对文字信息进行解析没有结果,则代表解析失败,解析失败后,语音解析模块可以将文字信息发送到云端服务器,通过云端服务器对文字信息继续进行语义解析,如果云端服务器对文字信息进行解析并获得解析结果,则云端服务器可以将解析结果传递给展示控制模块。需要说明的是,语音解析模块40通过本地对文字信息进行解析,当语音解析模块40对文字信息进行解析有结果则代表解析成功,解析成功后语音解析模块40可以将解析结果传递给展示控制模块50,以在展示控制模块50上展示人物情绪动作。由此,通过本地和云端服务器对文字信息进行语义解析以获得与用户情绪相关的解析结果,可以增加解析成功的概率,从而可以提高人物情绪展示装置的工作可靠性。
53.在本发明的一些实施例中,展示控制模块还可以用于,展示控制模块在未接收到云端服务器反馈的解析结果时,展示控制模块对上一次的人物情绪动作进行展示。作为一个实施例,展示控制模块可以设置在中控大屏内,在中控大屏内可以设置一个计时装置,计时装置可以设定一个时间段,语音解析模块通过云端服务器对文字信息解析时进行检验,当在计时装置设定的时间段内,云端服务器对文字信息解析并将解析结果反馈给展示控制模块,则代表云端服务器对文字信息解析成功,若在计时装置设定的时间段内,云端服务器对文字信息解析但没有将解析结果反馈给展示控制模块,则代表云端服务器对文字信息解析失败,此时,展示控制模块将对上一次的人物情绪动作进行展示。优选地,计时装置设定的时间段可以为一秒,当语音解析模块通过云端服务器对文字信息解析,并在一秒内将解析结果反馈给展示控制模块,则代表云端服务器对文字信息解析成功,若没有在一秒内将解析结果反馈给展示控制模块,则代表解析失败,展示控制模块将对上一次的人物情绪动作进行展示,由此,无论语音解析模块解析成功或者解析失败,展示控制模块都能够对人物情绪动作进行展示,从而可以进一步提高人物情绪展示装置的工作可靠性。
54.在本发明的一些实施例中,语音获取模块可以用于,在语音解析模块对文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果之前,获取用户的语音信息,语音识别模块可以用于对所述语音信息进行识别以获得所述文字信息。其中,语音获取模块可以设置在车载中控大屏内,语音获取模块包括的至少一个麦克风也可以设置在车载中控大屏内,用户可以通过物理方式控制语音按键启动车载人物情绪展示装置,进而唤醒语音获取模块的麦克风,实现从硬件层面去开启软件的语音获取功能,用户还可以通过事先设置语音唤醒词,然后在需要启动车载人物情绪展示装置,且唤醒语音获取模块的麦克风时,
说出语音唤醒词,实现启动车载人物情绪展示装置的功能。但本发明不限于此,启动车载人物情绪展示装置功能、唤醒语音获取模块的麦克风的方式可以但不限于上述两种方式。
55.当用户启动车载人物情绪展示装置功能,唤醒语音获取模块的麦克风后,语音获取模块通过麦克风获取用户的语音信息,语音获取模块的麦克风获取到用户的语音信息后,语音获取模块会将获取的用户的语音信息传递给语音识别模块。语音识别模块可以对语音获取模块传递来的语音信息进行识别,可以获得语音信息的文字信息。然后语音识别模块可以将获得的文字信息传递给语音解析模块,以便语音解析模块对语音识别模块传递来的文字信息进行语义解析以确定是否获得与用户情绪相关的解析结果。
56.在本发明的一些实施例中,人物情绪展示装置还可以包括音频振幅获取模块,在对人物情绪动作进行展示时,还根据语音信息获取音频振幅,根据音频振幅对人物情绪动作进行调整,需要说明的是,语音获取模块通过麦克风获取用户的语音信息后,可以将语音信息传递给音频振幅获取模块,音频振幅获取模块可以根据音频振幅通过展示控制模块对人物情绪动作进行调整。
57.在本发明的一些实施例中,音频振幅获取模块还可以用于,确定音频振幅的变化情况,根据音频振幅的变化情况对人物情绪动作的深浅进行调整,需要说明的是,语音获取模块通过麦克风获取用户的语音信息后,可以将语音信息传递给音频振幅获取模块,音频振幅获取模块可以根据语音获取模块传递来的语音信息获取音频振幅,并确定音频振幅的变化情况,然后将音频振幅的变化情况传递给展示控制模块,其中,展示控制模块还可以用于在对人物情绪动作进行展示时根据音频振幅的变化情况对人物情绪动作的深浅进行调整。
58.需要说明的是,无论语音解析模块通过本地或者云端服务器是否对文字信息解析成功,一段语音信息的音频振幅,从开始到结束都会被音频振幅获取模块记录并计算出音频的平均振幅或分贝大小,并且在计算平均振幅或分贝大小前,音频振幅获取模块会事先对音频做降噪以及回声消除,然后在计算平均振幅或分贝大小,并将音频的平均振幅或分贝大小反馈给展示控制模块,展示控制模块可以依据语音解析模块对语义解析并反馈的结果展示用户的主要情绪,展示控制模块还可以依据音频振幅获取模块计算并反馈的音频的平均振幅或分贝大小对情绪的深浅进行展示,并且,展示控制模块还可以依据平均振幅或分贝大小,衍生出情绪动作,例如当语音解析模块反馈给展示控制模块的解析结果为“高兴”时,展示控制模块可以依据平均振幅或分贝大小,衍生出“赞”等情绪动作,并且无论动作图示为2d/3d维度,都可以根据平均振幅或分贝的大小放大或缩小衍生的情绪动作,优选地,可以对情绪的深浅和衍生的情绪动作分为大、中、小三个级别。
59.作为一个实施例,当语音解析模块反馈给展示控制模块的解析结果为“高兴”,则展示控制模块可以根据音频振幅获取模块反馈的音频的平均振幅或分贝大小对情绪深浅进行展示,比如,音频的平均振幅或分贝在39分贝以下判断为小,则展示控制模块展示为“微笑”,音频的平均振幅或分贝在40分贝以上判断为中,则展示控制模块展示为“一般笑”,音频的平均振幅或分贝在60分贝以上判断为大,则展示控制模块展示为“狂笑”,并且可以相应的衍生出“赞、普通赞、大赞”等衍生动作。如果在计时装置设定的时间段内展示控制模块没有收到语音解析模块反馈的解析结果,则展示控制模块展示上一次的人物情绪动作。由此,可以进一步将用户真正的情绪展示出来。
60.需要说明的是,如图2所示,如果音频的平均振幅较小,则可在展示控制模块展示“倒赞”的图案,且“倒赞”缩小。如图3所示,如果音频的平均振幅为中,则可在展示控制模块展示“紧紧握拳”的图案,且“紧紧握拳”图案放大。如图4所示,如果音频的平均振幅为大,则可在展示控制模块展示“闪电”的图案。如图5所示,如果音频的平均振幅非常大,则可在展示控制模块展示“闪电”变大后的图案。
61.具体地,作为本发明的一个具体实施例:
62.s01,用户在车上启动语音虚拟人物头像功能。
63.s02,语音获取模块通过至少一个麦克风获取用户的语音信息。
64.s03,语音识别模块对语音信息进行识别以获得文字信息。
65.s04,语音解析模块通过本地进行语义解析。
66.s05,语音解析模块通过本地进行语义解析是否获得解析结果,若无结果则通过云端服务器对文字信息进行语义解析,若有结果则完成解析。
67.s06,无论本地和/或云端服务器语义解析有无结果,音频振幅获取模块对语音信息进行处理并计算平均振幅或分贝大小。
68.s07,展示控制模块接收解析结果。
69.s08,在计时装置规定的时间内,若展示控制模块接收到解析结果,则对解析结果进行判断,若展示控制模块没有接收到解析结果,则使用上次的人物情绪动作和衍生动作。
70.s09,中控大屏依据语义解析判断主要情绪以及衍生的情绪动作,依据音频平均振幅或分贝大小做深浅(大、中、小)判定。
71.s10,情绪衍生动作可依据音频平均振幅或分贝大小,放大或缩小衍生的情绪动作,无论动作图示为2d/3d维度。
72.s11,判定完成,生成人物情绪动作和衍生动作。
73.为了实现上述实施例,本发明提出计算机可读存储介质,其上存储有车载人物情绪展示程序,该展示程序被处理器执行时,可以实现上述实施例的车载人物情绪展示方法。
74.本发明实施例的计算机可读存储介质,当用户启动车载人物情绪展示功能时,存储的车载人物情绪展示程序被处理器执行,可以获取用户的语音信息,对用户的语音信息进行识别以获得文字信息,对文字信息进行语义解析,根据解析结果生成并展示人物情绪动作,从而将用户更加真实的情绪通过人物情绪动作展示出来。
75.为了实现上述实施例,本发明还提出一种车载中控设备,车载中控设备包括存储器、处理器及存储在存储器上并可在处理器上运行的车载人物情绪展示程序,处理器执行展示程序时,实现上述实施例的车载人物情绪展示方法。
76.本发明实施例的车载中控设备,通过处理器执行存储器上存储的车载人物情绪展示程序,当用户启动语音虚拟人物头像功能时,存储的车载人物情绪展示程序被处理器执行,可以获取用户的语音信息,对用户的语音信息进行识别以获得文字信息,对文字信息进行语义解析,根据解析结果生成并展示人物情绪动作,从而将车主真正的情绪通过人物情绪动作展示出来,让车主有明显的情绪以及趣味感知,进而提醒车主管控情绪或自我检视。
77.如图6所示,该中控设备可以包括至少一个处理器1201,至少一个通信接口1202,至少一个存储器1203和至少一个通信总线1204;在本发明的实施例中,处理器1201、通信接口1202、存储器1203、通信总线1204的数量为至少一个,且处理器1201、通信接口1202、存储
器1203通过通信总线1204完成相互间的通信。
78.其中,存储器1203可以是,但不限于,随机存取存储器(random access memory,ram),只读存储器(read only memory,rom),可编程只读存储器(programmable read-only memory,prom),可擦除只读存储器(erasable programmable read-only memory,eprom),电可擦除只读存储器(electric erasable programmable read-only memory,eeprom)等。其中,存储器1203用于存储程序,处理器1201在接收到执行指令后,执行所述程序,实现上述实施例描述的车载人物情绪展示方法的步骤。
79.处理器1201可能是一种集成电路芯片,具有信号的处理能力。上述的处理器可以是通用处理器,包括中央处理器(central processing unit,cpu)、网络处理器(networkprocessor,np)等;还可以是数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。可以实现或者执行本发明实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
80.需要说明的是,在流程图中表示或在此以其他方式描述的逻辑和/或步骤,例如,可以被认为是用于实现逻辑功能的可执行指令的定序列表,可以具体实现在任何计算机可读介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。就本说明书而言,"计算机可读介质"可以是任何可以包含、存储、通信、传播或传输程序以供指令执行系统、装置或设备或结合这些指令执行系统、装置或设备而使用的装置。计算机可读介质的更具体的示例(非穷尽性列表)包括以下:具有一个或多个布线的电连接部(电子装置),便携式计算机盘盒(磁装置),随机存取存储器(ram),只读存储器(rom),可擦除可编辑只读存储器(eprom或闪速存储器),光纤装置,以及便携式光盘只读存储器(cdrom)。另外,计算机可读介质甚至可以是可在其上打印所述程序的纸或其他合适的介质,因为可以例如通过对纸或其他介质进行光学扫描,接着进行编辑、解译或必要时以其他合适方式进行处理来以电子方式获得所述程序,然后将其存储在计算机存储器中。
81.应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(pga),现场可编程门阵列(fpga)等。
82.在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示意性实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
83.尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本
发明的范围由权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。