1.本发明属于智能变电站技术领域,具体为基于mapreduce大数据平台和改进遗传算法的智能变电站故障诊断与跟踪方法。
背景技术:
2.智能变电站作为智能电网的核心枢纽,近年来发展迅速,具有设备智能化、全站信息化、数据网络化的特点。随着变电站智能化程度的不断提高,各个环节的自动化程度越来越高,出现了大规模、超大规模海量状态数据的管理和处理问题。由于实时数据量的爆炸式增长,传统的技术手段已不能满足系统的可靠性和经济性要求。
3.变电站的故障诊断则要求运行人员能够依据警报信息快速并准确地判断出故障,并对其进行故障定位和恢复,从而最大程度的降低经济损失,并快速恢复供电可靠性。由于海量警报信息的不精确性和不确定,使得运行人员难以快速、准确根据故障警报信息进行故障诊断。
4.基于此,提供了一种智能变电站故障诊断与跟踪方法。
技术实现要素:
5.本发明的目的在于提供了一种智能变电站故障诊断与跟踪方法,以克服海量警报信息的不精确性和不确定,使得运行人员难以快速、准确根据故障警报信息进行故障诊断的问题。
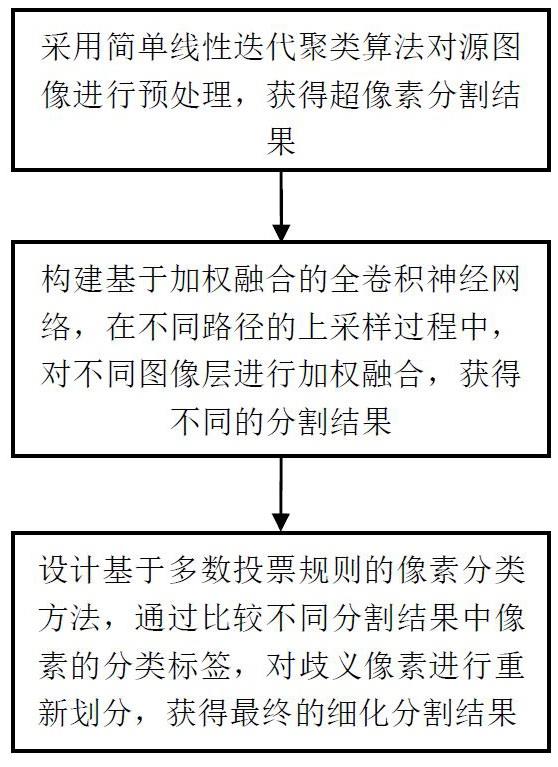
6.实现本发明目的的技术解决方案为:一种智能变电站故障诊断与跟踪方法,具体包括以下步骤:
7.s1、建立基于mapreduce并行大数据架构的故障状态信息处理框架;
8.s2、将智能变电站数据采集与故障状态信息处理框架相结合,将变电站信息分成多个数据块,再将多个数据块并行处理,提取故障数据;
9.s3、将粗糙集和遗传算法相融合后对故障数据进行约简;
10.s4、基于mapreduce大数据平台,采用故障诊断算法进行故障诊断与故障跟踪定位。
11.进一步地,所述故障状态信息处理框架的故障诊断算法采用mapreduce框架,mapreduce框架中的变电站侧采用分布式存储技术用于获取和管理变电站信息数据。
12.进一步地,所述智能变电站数据采集与故障状态信息处理框架相结合包括数据采集、数据存储、数据分析和数据接入。
13.进一步地,所述数据采集由sac和传感器采集;
14.数据存储层集成了hdfs和mysql;
15.数据分析采用hive-to-mapreduce,对变电站设备状态监测数据进行分布式olap分析。
16.进一步地,所述数据接入包括数据挖掘、改进遗传算法等功能组件。
17.进一步地,所述约简包括如下步骤:
18.(1)粗糙集对智能变电站采集的实时数据或历史数据进行预处理;
19.(2)若得到的结果满足决策要求,则直接输出结果;
20.(3)若得到的结果不满足决策要求,则通过遗传算法生成新个体,并通过粗糙集再次获得适应度最高的搜索结果。
21.进一步地,所述若得到的结果不满足决策要求,则通过遗传算法生成新个体,并通过粗糙集再次获得适应度最高的搜索结果的具体步骤如下:
22.(31)s
count
(d)-sc(d)的值小于0时产生初始染色体,初始染色体通过随机均匀交叉算法进行交叉变异,交叉产生的新个体;
23.(32)对新个体和初始染色体计算重要度和决策度;
24.(33)计算适应度函数f(x);
25.(34)对适应度函数f(x)计算结果进行判断是否需要持续交叉变异,需要时将适应度函数计算结果作为初始染色体进行再计算,不需要时输出结果。
26.进一步地,所述粗糙集决策属性对条件属性的决策度sc(d)定义如下:
[0027][0028]
其中,u为非空有限集,c={c1,c2,...,cm}表示条件属性集,d={d1,d2,...,dm}为决策属性集,u/c={a1,a2,...,am},u/d={b1,b2,...,bm},posc(bi)是bi的条件属性c的下近似值;
[0029]scount
(d)表示决策属性d对count(c)的决策度;
[0030]
条件属性集c中任意属性c的重要度定义为:条件属性集c中任意属性c的重要度定义为:
[0031]sc-{c}
(d)表示c中缺少属性c后,条件属性与决策属性的依赖度。
[0032]
进一步地,所述遗传算法的数据编码采用二进制一维编码;条件属性集合中任何条件属性的子集对应于长度为m的唯一二进制代码;染色体的每一位对应一个条件属性;
[0033]
遗传算法的数学表达式为适应度函数f(x),适应度函数f(x)定义为:
[0034][0035]
其中,f(x)为适应度函数,α是惩罚因子,f(x)为目标函数,表示个体x中未包含的属性比例,m为染色体长度,count(x)用于检测染色体中为1的个数;q(x)是一个惩罚函数;s0是支持阈值;β是调整系数。
[0036]
进一步地,所述适应度函数f(x)下,对于个体x大小为n的组,单个选择概率可表示为:
[0037]
[0038]
选择后产生的个体集用于交叉操作,以产生具有优良基因的后代个体;交叉操作使用固定概率的随机均匀交叉算法;新生成个体的每一条染色体都有以下表达:
[0039][0040]
其中,cross表示交叉函数,p
x
是一个均匀分布在0和1之间的随机变量;p
x
是交叉发生的概率;a
1old
、a
1new
表示一致交叉产生的两个新个体,b
1old
表示非一致交叉新个体。
[0041]
本发明与现有技术相比,其显著优点为:
[0042]
本发明根据智能变电站设备状态监测系统的结构特点,提出了一种基于mapreduce并行处理架构的变电站故障大数据平台体系结构,提出了一种基于粗糙集与遗传算法相结合的数据约简方法,设计了故障诊断与跟踪程序,提高故障诊断的速度,有效地进行故障跟踪定位;再利用所设计的平台和故障诊断跟踪方法对变电站监测数据进行提取和分析,仿真表明,所设计的大数据平台和故障诊断方法能够实现海量数据中的故障信息提取,减少了提取时间,获取故障数据有助于值班人员及时分析和处理故障,确保系统安全运行。
[0043]
下面结合附图对本发明作进一步详细描述。
附图说明
[0044]
图1为本发明智能变电站数据采集与mapreduce框架相结合。
[0045]
图2为本发明基于大数据平台的智能变电站故障诊断可追溯流程。
[0046]
图3为本发明融合粗糙集遗传约简算法流程图。
[0047]
图4为本发明大数据下的智能变电站设备监控平台。
[0048]
图5为本发明变电站变压器和相关ied。
具体实施方式
[0049]
为了更加清楚地描述本发明的思想,技术方案和优点,具体实施方式通过实施例和附图来表明。显然地,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在未付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0050]
实施例
[0051]
如图1所示,一种智能变电站故障诊断与跟踪方法,具体包括以下步骤:
[0052]
s1、建立基于mapreduce并行大数据架构的故障状态信息处理框架;
[0053]
所述故障状态信息处理框架的故障诊断算法采用mapreduce框架,mapreduce框架中的变电站侧采用分布式存储技术用于获取和管理变电站信息数据。针对故障数据,为了避免调度过程中过的数据堵塞提供与上层故障诊断程序稳定高效的数据接口。
[0054]
s2、将智能变电站数据采集与故障状态信息处理框架相结合,将变电站信息分成多个数据块,再将多个数据块并行处理,提取故障数据;
[0055]
所述智能变电站数据采集与故障状态信息处理框架相结合包括数据采集、数据存储、数据分析和数据接入。
[0056]
所述数据采集由sac和传感器采集;
[0057]
数据存储层集成了hdfs和mysql;
[0058]
数据分析采用hive-to-mapreduce,对变电站设备状态监测数据进行分布式olap分析。
[0059]
所述数据接入包括数据挖掘、改进遗传算法等功能组件。
[0060]
如图3所示,s3、将粗糙集和遗传算法相融合后对故障数据进行约简;
[0061]
所述约简包括如下步骤:
[0062]
(1)粗糙集对智能变电站采集的实时数据或历史数据进行预处理,得到sc(d)和s
count
(d),再计算s
count
(d)-sc(d)的值;
[0063]
(2)若s
count
(d)-sc(d)的值为0时,得到的结果满足决策要求,则直接输出结果;
[0064]
(3)若s
count
(d)-sc(d)的值小于0时,得到的结果不满足决策要求,则通过遗传算法生成新个体,并通过粗糙集再次获得适应度最高的搜索结果;
[0065]
(31)s
count
(d)-sc(d)的值小于0时产生初始染色体,初始染色体通过随机均匀交叉算法进行交叉变异,交叉产生的新个体;
[0066]
(32)对新个体和初始染色体计算重要度和决策度;
[0067]
(33)计算适应度函数f(x);
[0068]
(34)对适应度函数f(x)计算结果进行判断是否需要持续交叉变异,需要时将适应度函数计算结果作为初始染色体进行再计算,不需要时输出结果。
[0069]
粗糙集决策属性对条件属性的决策度sc(d)定义如下:
[0070][0071]
其中,u为非空有限集,c={c1,c2,...,cm}表示条件属性集,d={d1,d2,...,dm}为决策属性集,u/c={a1,a2,...,am},u/d={b1,b2,...,bm},posc(bi)是bi的条件属性c的下近似值;
[0072]scount
(d)表示决策属性d对count(c)的决策度;
[0073]
条件属性集c中任意属性c的重要度定义为:条件属性集c中任意属性c的重要度定义为:
[0074]sc-{c}
(d)表示c中缺少属性c后,条件属性与决策属性的依赖度。
[0075]
所述遗传算法的数据编码采用二进制一维编码;条件属性集合中任何条件属性的子集对应于长度为m的唯一二进制代码;染色体的每一位对应一个条件属性;
[0076]
遗传算法的数学表达式为适应度函数f(x),适应度函数f(x)定义为:
[0077][0078]
其中,f(x)为适应度函数,α是惩罚因子,f(x)为目标函数,表示个体x中未包含的属性比例,m为染色体长度,count(x)用于检测染色体中为1的个数;q(x)是一个惩罚函数;s0是支持阈值;β是调整系数。
[0079]
所述适应度函数f(x)下,对于个体x大小为n的组,单个选择概率可表示为:
[0080][0081]
选择后产生的个体集用于交叉操作,以产生具有优良基因的后代个体;交叉操作使用固定概率的随机均匀交叉算法;新生成个体的每一条染色体都有以下表达:
[0082][0083]
其中,cross表示交叉函数,p
x
是一个均匀分布在0和1之间的随机变量;p
x
是交叉发生的概率;a
1old
、a
1new
表示一致交叉产生的两个新个体,b
1old
表示非一致交叉新个体。
[0084]
如图2所示,s4、基于mapreduce大数据平台,采用故障诊断算法进行故障诊断与故障跟踪定位。
[0085]
步骤1:触发:当故障发生时,调度中心服务器收集保护和断路器动作等报警级别信息,触发mapreduce中的每个故障诊断应用程序,应用程序向主群集资源管理器提交任务请求。
[0086]
步骤2:分配:资源管理器为每个任务分配一个任务从属节点。任务节点相当于各模块的执行者,将故障诊断模块、信息查询等模块的程序代码分发到相应节点。
[0087]
步骤3:执行:每个任务节点执行程序代码,其中slave1从hdfs中提取报警信息(结构化数据),使用故障诊断算法查找故障部件,如果诊断结果涉及保护或断路器未正确操作,则使用slave2;数据用于故障追踪;slave2使用mysql查询hdfs中的信息,筛选出与故障诊断和跟踪相关的信息,如完成记录和本地线路监控,并传输保护信息、断路器和通道相关的设备报警信息;slave3根据断路器跳闸信息计算断电面积,输出给slave2;slave4生成故障后的记录文件(非结构化数据)进行离线分析。
[0088]
步骤4:返回:基于大数据平台的故障诊断程序由mapreduce统一部署,计算资源由调度终端的单机操作变为多台变电站服务器的集群运行。
[0089]
仿真实验
[0090]
为了验证该算法,搭建了分布式集群硬件实验平台,模拟大数据下智能变电站设备的监测与故障诊断。实验平台由5台pc机组成,其结构如图4所示。
[0091]
对a、b、c三个变电站的故障信息进行了抽样统计。故障被设置为b变电站t2变压器的短路故障。变电站变压器的ied分布如图5所示。每个变电站有三套变压器,通常在额定功率的30%至40%下运行。故障发生后,b变电站t2变压器退出运行,其他两台变压器的潮流增加到50%~60%。每个ied中未处理的数据如表i所示,其中“1”表示该值高于正常值,“0”表示该值低于正常值,
“‑”
表示该值在正常范围内。由于空间限制,仅列出了典型的ied信息。故障数据经约简算法处理后,在表ii上执行遗传约简算法。在对故障和运行数据进行预处理后,被识别和处理的数据模型进入相应的从机,各从机模块完成对数据模型的解析和计算,最终得到故障诊断的最终信息。融合约简算法在短时间内去除表i中的冗余信息,表ii中显示的最小相对约简为ied21和ied24。
[0092]
表一 典型的未处理运行状态数据
[0093][0094][0095]
表二 简化ied运行状态数据
[0096][0097]
根据表二的故障数据,判断故障类型为短路,故障位置能准确定位到b变电站的变压器t2,故障位置发生在ied21和ied24覆盖的区域。保护装置已正确运行,发生短路的变压器t2已被隔离。
[0098]
上述所举实施例,对本发明的目的、技术方案和优点进行了进一步的详细说明,所应理解的是,以上所举实施例仅为本发明的优选实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内对本发明所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。