1.本说明书一个或多个实施例涉及计算机领域,尤其涉及训练命名实体识别模型的方法和装置。
背景技术:
2.隐私数据(private data)或秘密数据,是指不想被他人或无关人等获知的信息,从隐私的所有者的角度,可以将隐私数据分为个人隐私数据和共同隐私数据,其中个人隐私数据包括可以用来定位或者识别个人的信息(如电话号码、地址、信用卡号等)和敏感信息(如个人健康情况、财务信息、公司重要文件等)。共同隐私数据主要以家庭隐私为主,如家庭年收入情况等。隐私数据的泄露和滥用极易引起各种个人和公共安全问题。
3.命名实体识别(named entity recognition,ner)是指识别文中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。目前主流的ner模型都是基于深度学习(deep learning)方法的,需要大量的标注语料进行学习。深度学习是机器学习的分支,是一种以人工神经网络为架构,对资料进行表征学习的算法。当将命名实体识别模型用于识别文本中包括的隐私信息时,存在模型训练需要大量的标注语料的问题,人工标注成本高。
技术实现要素:
4.本说明书一个或多个实施例描述了一种训练命名实体识别模型的方法和装置,能够显著降低模型训练所需的标注语料数量,降低人工标注成本。
5.第一方面,提供了一种训练命名实体识别模型的方法,所述命名实体识别模型用于确定目标文本中包括的隐私信息的隐私类别及其位置,方法包括:
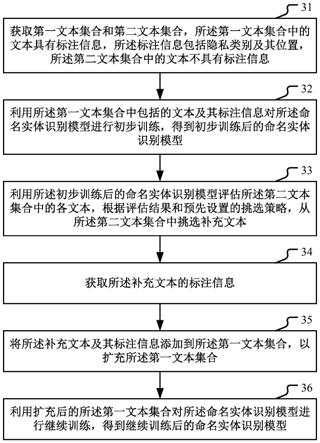
6.获取第一文本集合和第二文本集合,所述第一文本集合中的文本具有标注信息,所述标注信息包括隐私类别及其位置,所述第二文本集合中的文本不具有标注信息;
7.利用所述第一文本集合中包括的文本及其标注信息对所述命名实体识别模型进行初步训练,得到初步训练后的命名实体识别模型;
8.利用所述初步训练后的命名实体识别模型评估所述第二文本集合中的各文本,根据评估结果和预先设置的挑选策略,从所述第二文本集合中挑选补充文本;
9.获取所述补充文本的标注信息;
10.将所述补充文本及其标注信息添加到所述第一文本集合,以扩充所述第一文本集合;
11.利用扩充后的所述第一文本集合对所述命名实体识别模型进行继续训练,得到继续训练后的命名实体识别模型。
12.在一种可能的实施方式中,所述获取所述补充文本的标注信息,包括:
13.利用所述初始训练后的命名实体识别模型确定所述补充文本中包括的隐私信息的预测类别及其预测位置;
14.对所述补充文本中包括的隐私信息的预测类别及其预测位置进行人工校验后,得
到所述标注信息。
15.在一种可能的实施方式中,所述目标文本为应用程序的隐私声明文本,所述命名实体识别模型用于确定隐私声明文本中声明采集的隐私信息的隐私类别及其位置。
16.在一种可能的实施方式中,所述标注信息采用bioe标记法,所述bioe标记法用于标记文本中属于隐私信息的若干连续字符的隐私类别,其起始位置、中间位置和结束位置,以及标记文本中不属于隐私信息的字符。
17.在一种可能的实施方式中,所述评估结果包括,对各文本进行预测的置信度;所述挑选策略包括,选择置信度最低的文本作为所述补充文本。
18.在一种可能的实施方式中,所述评估结果包括,对文本中的各字符进行预测的置信度;所述挑选策略包括,选择置信度最低的字符所在的文本作为所述补充文本。
19.在一种可能的实施方式中,所述评估结果包括,对文本中的字符预测为任一标记类别的置信度;所述挑选策略包括,选择包含的各字符的平均信息熵最大的文本作为所述补充文本。
20.在一种可能的实施方式中,所述继续训练具有终止条件,所述终止条件为继续训练后的命名实体识别模型的效果评估符合要求,所述效果评估通过准确率、召回率中的至少一个指标来衡量。
21.第二方面,提供了一种应用程序的合规性判别方法,所述方法基于第一方面所述的方法得到的继续训练后的命名实体识别模型实现,包括:
22.获取应用程序的代码分析结果,所述代码分析结果指示出所述应用程序实际采集的隐私信息的隐私类别构成的第一类别集合;
23.利用所述继续训练后的命名实体识别模型,确定所述应用程序的隐私声明文本声明采集的隐私信息的隐私类别构成的第二类别集合;
24.当所述第一类别集合与所述第二类别集合一致,且包括的隐私类别均属于法律法规中允许所述应用程序采集的隐私信息的隐私类别时,确定所述应用程序合规。
25.在一种可能的实施方式中,所述利用所述继续训练后的命名实体识别模型,确定所述应用程序的隐私声明文本声明采集的隐私信息的隐私类别构成的第二类别集合,包括:
26.将所述应用程序的隐私声明文本以句子为单位进行拆分,得到多个分句;
27.将所述多个分句分别输入所述继续训练后的命名实体识别模型,得到各分句中分别包括的隐私信息的隐私类别;
28.合并各分句中分别包括的隐私类别,得到所述应用程序的隐私声明文本声明采集的隐私信息的隐私类别构成的第二类别集合。
29.第三方面,提供了一种训练命名实体识别模型的装置,所述命名实体识别模型用于确定目标文本中包括的隐私信息的隐私类别及其位置,装置包括:
30.第一获取单元,用于获取第一文本集合和第二文本集合,所述第一文本集合中的文本具有标注信息,所述标注信息包括隐私类别及其位置,所述第二文本集合中的文本不具有标注信息;
31.第一训练单元,用于利用所述第一获取单元获取的第一文本集合中包括的文本及其标注信息对所述命名实体识别模型进行初步训练,得到初步训练后的命名实体识别模
型;
32.选择单元,用于利用所述第一训练单元得到的初步训练后的命名实体识别模型评估所述第一获取单元获取的第二文本集合中的各文本,根据评估结果和预先设置的挑选策略,从所述第二文本集合中挑选补充文本;
33.第二获取单元,用于获取所述选择单元挑选的补充文本的标注信息;
34.扩充单元,用于将所述选择单元挑选的补充文本及所述第二获取单元获取的其标注信息添加到所述第一文本集合,以扩充所述第一文本集合;
35.第二训练单元,用于利用所述扩充单元扩充后的所述第一文本集合对所述第一训练单元得到的命名实体识别模型进行继续训练,得到继续训练后的命名实体识别模型。
36.第四方面,提供了一种应用程序的合规性判别装置,所述装置基于第三方面所述的装置得到的继续训练后的命名实体识别模型实现,包括:
37.获取单元,用于获取应用程序的代码分析结果,所述代码分析结果指示出所述应用程序实际采集的隐私信息的隐私类别构成的第一类别集合;
38.确定单元,用于利用所述继续训练后的命名实体识别模型,确定所述应用程序的隐私声明文本声明采集的隐私信息的隐私类别构成的第二类别集合;
39.判别单元,用于当所述获取单元获取的第一类别集合与所述确定单元确定的第二类别集合一致,且包括的隐私类别均属于法律法规中允许所述应用程序采集的隐私信息的隐私类别时,确定所述应用程序合规。
40.第五方面,提供了一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行第一方面或第二方面的方法。
41.第六方面,提供了一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现第一方面或第二方面的方法。
42.通过本说明书实施例提供的训练命名实体识别模型的方法和装置,首先获取第一文本集合和第二文本集合,所述第一文本集合中的文本具有标注信息,所述标注信息包括隐私类别及其位置,所述第二文本集合中的文本不具有标注信息;然后利用所述第一文本集合中包括的文本及其标注信息对所述命名实体识别模型进行初步训练,得到初步训练后的命名实体识别模型;接着利用所述初步训练后的命名实体识别模型评估所述第二文本集合中的各文本,根据评估结果和预先设置的挑选策略,从所述第二文本集合中挑选补充文本;再获取所述补充文本的标注信息;将所述补充文本及其标注信息添加到所述第一文本集合,以扩充所述第一文本集合;最后利用扩充后的所述第一文本集合对所述命名实体识别模型进行继续训练,得到继续训练后的命名实体识别模型。由上可见,本说明书实施例,不是直接获取大量的有标注文本用于模型训练,而是先获取少量的有标注文本对命名实体识别模型进行初步训练,然后利用初步训练后的命名实体识别模型和预先设置的挑选策略,从未标注的文本中挑选出文本,加入标注信息后放入训练集,可以用更少的有标注文本训练模型,有效地降低训练的代价并同时提高模型的识别能力,相比解析效果类似的其他深度学习方法,能够显著降低模型训练所需的标注语料数量,降低人工标注成本。
43.通过本说明书实施例提供的应用程序的合规性判别方法和装置,基于本说明书实施例提供的训练命名实体识别模型的方法得到的继续训练后的命名实体识别模型实现,首先获取应用程序的代码分析结果,所述代码分析结果指示出所述应用程序实际采集的隐私
信息的隐私类别构成的第一类别集合;然后利用所述继续训练后的命名实体识别模型,确定所述应用程序的隐私声明文本声明采集的隐私信息的隐私类别构成的第二类别集合;最后当所述第一类别集合与所述第二类别集合一致,且包括的隐私类别均属于法律法规中允许所述应用程序采集的隐私信息的隐私类别时,确定所述应用程序合规。由上可见,本说明书实施例,由于所述继续训练后的命名实体识别模型识别能力高,并且可以在得知文本包含的隐私类别的同时,也能获得隐私类别出现的位置,精细化程度高,从而基于该模型得到的第二类别集合,能够有效的判别出应用程序是否合规。
附图说明
44.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
45.图1为本说明书披露的一个实施例的实施场景示意图;
46.图2为本说明书披露的另一个实施例的实施场景示意图;
47.图3示出根据一个实施例的训练命名实体识别模型的方法流程图;
48.图4示出根据一个实施例的标注方法示意图;
49.图5示出根据一个实施例的模型训练框架示意图;
50.图6示出根据一个实施例的模型训练过程示意图;
51.图7示出根据一个实施例的应用程序的合规性判别方法流程图;
52.图8示出根据一个实施例的app隐私声明文本解析示意图;
53.图9示出根据一个实施例的训练命名实体识别模型的装置的示意性框图;
54.图10示出根据一个实施例的应用程序的合规性判别装置的示意性框图。
具体实施方式
55.下面结合附图,对本说明书提供的方案进行描述。
56.图1为本说明书披露的一个实施例的实施场景示意图,该实施场景体现了隐私合规的整体架构,在应用程序的合规性判别中,涉及训练命名实体识别(named entity recognition,ner)模型。参照图1,决策模块会输入来自三方的数据分析,包括应用程序(application,app)隐私声明文本中提取出的声明采集的隐私信息,app代码解析结果指示的实际采集的隐私信息,法律法规解析结果指示的允许采集的隐私信息,最终通过比对三者得出合规报告。本说明书实施例主要针对隐私声明文本的解析提出解决方案,利用了命名实体识别模型实现文本解析,主要分为两个阶段,训练阶段先利用少量的提前标注好的数据初步训练命名实体识别模型,再利用所述初步训练后的命名实体识别模型和预先设置的挑选策略,从未标注的文本集合中挑选补充文本,对补充文本进行数据标注,并基于标注后的补充文本继续训练命名实体识别模型,以获得完成训练的命名实体识别模型。测试阶段,给定某个app的隐私声明文本,首先对文本进行分句,将分句之后的结果依次输入到训练好的模型中进行预测,将预测的结果汇总到声明采集的隐私数据集合中,声明采集的隐私数据集合维护了该app隐私声明文本中声明采集的所有隐私信息及相应位置。
57.图2为本说明书披露的另一个实施例的实施场景示意图,该实施场景体现了文本解析的具体要求。参照图2,通过解析隐私声明文本,可以获知该隐私声明文本声明采集的隐私信息的隐私类别,以及相应隐私信息出现的位置。隐私声明文本通常为长文本,包括多个语句,例如,图2中以句号分隔的多个语句,各语句中可能包括隐私信息以及非隐私信息,为了突出表示文本中的隐私信息,图中非隐私信息用*表示,通过解析隐私声明文本,可以获知该隐私声明文本声明采集的隐私信息包括隐私信息1、隐私信息2、隐私信息3、隐私信息4和隐私信息5,其中,隐私信息1属于隐私类别1,其在隐私声明文本中的位置为位置1,隐私信息2属于隐私类别2,其在隐私声明文本中的位置为位置2,隐私信息3属于隐私类别3,其在隐私声明文本中的位置为位置3,隐私信息4属于隐私类别1,其在隐私声明文本中的位置为位置4,隐私信息5属于隐私类别2,其在隐私声明文本中的位置为位置5。可以理解的是,不同的隐私信息可以具有相同的隐私类别,比如隐私信息1和隐私信息4均属于隐私类别1,隐私信息2和隐私信息5均属于隐私类别2,该隐私声明文本声明采集的隐私类别包括隐私类别1、隐私类别2和隐私类别3,后续可以根据隐私声明文本的解析结果判断相应的应用程序是否合规,上述合规包括符合法律法规中允许所述应用程序采集的隐私类别。
58.隐私信息通常比较具体,隐私类别相对于隐私信息范围更广,通常地,一个隐私类别对应有多个隐私信息。表一为本说明书实施例提供的隐私信息与隐私类别的对应关系表。
59.表一:隐私信息与隐私类别的对应关系表
60.[0061][0062]
需要说明的是,本说明书中除了提取隐私声明文本中的隐私信息之外,还可以提取隐私声明文本中的隐私声明合规信息,上述隐私声明合规信息为法律法规中规定的隐私声明文本中应当声明的信息,例如,隐私信息存储期限、隐私信息超期处理方式、隐私信息存放地域、申诉和反馈渠道、app运营者基本情况、隐私信息保护负责人联系方式等,根据上述隐私声明合规信息可以判断隐私声明文本是否合规。
[0063]
图3示出根据一个实施例的训练命名实体识别模型的方法流程图,该方法可以基于图1和图2所示的实施场景,所述命名实体识别模型用于确定目标文本中包括的隐私信息的隐私类别及其位置。如图3所示,该实施例中训练命名实体识别模型的方法包括以下步
骤:步骤31,获取第一文本集合和第二文本集合,所述第一文本集合中的文本具有标注信息,所述标注信息包括隐私类别及其位置,所述第二文本集合中的文本不具有标注信息;步骤32,利用所述第一文本集合中包括的文本及其标注信息对所述命名实体识别模型进行初步训练,得到初步训练后的命名实体识别模型;步骤33,利用所述初步训练后的命名实体识别模型评估所述第二文本集合中的各文本,根据评估结果和预先设置的挑选策略,从所述第二文本集合中挑选补充文本;步骤34,获取所述补充文本的标注信息;步骤35,将所述补充文本及其标注信息添加到所述第一文本集合,以扩充所述第一文本集合;步骤36,利用扩充后的所述第一文本集合对所述命名实体识别模型进行继续训练,得到继续训练后的命名实体识别模型。下面描述以上各个步骤的具体执行方式。
[0064]
首先在步骤31,获取第一文本集合和第二文本集合,所述第一文本集合中的文本具有标注信息,所述标注信息包括隐私类别及其位置,所述第二文本集合中的文本不具有标注信息。可以理解的是,第一文本集合可以直接应用于有监督学习中,对模型进行训练,有监督学习是机器学习的一种方法,指给定事先标记过的训练示例,对输入的数据进行分类或拟合。
[0065]
在一个示例中,所述目标文本为应用程序的隐私声明文本,所述命名实体识别模型用于确定隐私声明文本中声明采集的隐私信息的隐私类别及其位置。
[0066]
在一个示例中,所述标注信息采用bioe标记法,所述bioe标记法用于标记文本中属于隐私信息的若干连续字符的隐私类别,其起始位置、中间位置和结束位置,以及标记文本中不属于隐私信息的字符。
[0067]
图4示出根据一个实施例的标注方法示意图,该实施例遵照序列标注的方式,采用了bioe标记法,bioe分别代表意义:b,即begin,表示识别出的隐私信息的开始字符;i,即intermediate,表示识别出的隐私信息的中间字符;e,即end,表示识别出的隐私信息的结尾字符;o,即other,表示其他,用于标记无关字符。参照图4,待标注文本为“需要提供您的姓名、电话号码等。”,这句话中的“姓名”和“电话号码”属于隐私信息,其他均属于无关字符,对该句话进行标注,可以得到如下的标注结果:[o,o,o,o,o,o,b-name,e-name,o,b-phone,i-phone,i-phone,e-phone,o,o],其中name代表隐私类别为姓名,phone代表隐私类别为手机号码。可以理解的是,隐私类别的划分标准不唯一,例如,姓名和手机号码可以归为个人基本资料这一个隐私类别,也可以更细粒度的划分为两个隐私类别。
[0068]
归纳来说,假定隐私类别有m种,分别记为c1、c2、c3、
……
、cm,给定一个字符长度为n的待识别数据记录w={w1,w2,w3,
……
,wn},由w中若干个连续的字符组成的序列s=[w
k-i
,w
k-i 1
,
……
,wk],如果s是属于cj类型的隐私信息,那么ner模型的任务是要把w
k-i
标记为b-cj,从w
k-i 1
开始到w
k-1
标记i-cj,把wk标记为e-cj。
[0069]
然后在步骤32,利用所述第一文本集合中包括的文本及其标注信息对所述命名实体识别模型进行初步训练,得到初步训练后的命名实体识别模型。可以理解的是,由于第一文本集合中包括的文本数量有限,经过初步训练后的命名实体识别模型识别效果还不够好,需要继续训练。
[0070]
接着在步骤33,利用所述初步训练后的命名实体识别模型评估所述第二文本集合中的各文本,根据评估结果和预先设置的挑选策略,从所述第二文本集合中挑选补充文本。可以理解的是,第二文本集合中的文本不具有标注信息,而给文本添加标注信息需要耗费
大量的人工,因此通过有选择性的挑选补充文本进行标注,从而实现用更少的有标注文本,使得模型得到更好的训练效果。
[0071]
在一个示例中,所述评估结果包括,对各文本进行预测的置信度;所述挑选策略包括,选择置信度最低的文本作为所述补充文本。
[0072]
举例来说,令x=(x1,x2,
…
,xn)表示一串长度为n的字符串,ner模型的目标是预测对应的标签序列y=(y1,y2,
…
,yn),其中这些标签为bioe标注,由c表示标签类别数量;m表示ner模型中的参数,用y*表示模型预测出的最有可能的标签序列,则有如下等式成立:
[0073]
可以理解的是,p代表预测概率,也就是代表预测出的标签序列的置信度。
[0074]
前述示例中的挑选策略可以称为最低置信度策略(least confidence strategy),可以表示如下:
[0075]flc
(x)=1-p(y*\{x;m}),也就是说,要挑选出p最小的文本作为补充文本,相当于要挑选出f
lc
(x)最大的文本作为补充文本。
[0076]
在另一个示例中,所述评估结果包括,对文本中的各字符进行预测的置信度;所述挑选策略包括,选择置信度最低的字符所在的文本作为所述补充文本。
[0077]
该示例中的挑选策略可以称为最低符号概率策略(lowest token probability strategy),可以表示如下:
[0078]
也就是说,要挑选出最可能的标签序列中针对字符进行预测的置信度最小的文本作为补充文本,相当于要挑选出f
ltp
(x)最大的文本作为补充文本。
[0079]
在另一个示例中,所述评估结果包括,对文本中的字符预测为任一标记类别的置信度;所述挑选策略包括,选择包含的各字符的平均信息熵最大的文本作为所述补充文本。
[0080]
该示例中的挑选策略可以称为符号熵策略(token entropy strategy),可以表示如下:
[0081]
也就是说,要挑选出包含的各字符的平均信息熵最大的文本作为所述补充文本,相当于要挑选出f
te
(x)最大的文本作为补充文本,可以理解的是,字符的信息熵与对文本中的字符预测为任一标记类别的置信度有关。
[0082]
本说明书实施例,可以在前述任一挑选策略上进行稍许变化,得到其他的一些挑选策略。
[0083]
举例来说,前述最低置信度策略通常会倾向于选择更长的文本,但是更长的文本意味着更高的标注成本,因此基于文本长度对最低置信度策略进行了改动,得到最大归一化对数概率策略(maximum normalized log-probability strategy),表示如下:
[0084]
也就是说,要挑选出f
mnlp
(x)最小的文本作为补充文本。
[0085]
举例来说,前述符号熵策略基于文本长度对各字符的信息熵做了平均,如果不考虑文本长度的影响,得到最大符号熵策略(maximum token entropy strategy),表示如下:
[0086]
也就是说,要挑选出f
mte
(x)最大的文本作为补充文本,可以理解的是,f
mte
(x)与前述f
te
(x)之间的关系为
[0087]
再在步骤34,获取所述补充文本的标注信息。可以理解的是,补充文本来自于所述第二文本集合,其不具有标注信息,因此还需要针对补充文本添加标注信息。
[0088]
在一个示例中,所述获取所述补充文本的标注信息,包括:
[0089]
利用所述初始训练后的命名实体识别模型确定所述补充文本中包括的隐私信息的预测类别及其预测位置;
[0090]
对所述补充文本中包括的隐私信息的预测类别及其预测位置进行人工校验后,得到所述标注信息。
[0091]
该示例中,利用初始训练后的命名实体识别模型对补充文本进行预标注,进一步降低了整体的标注成本。
[0092]
再在步骤35,将所述补充文本及其标注信息添加到所述第一文本集合,以扩充所述第一文本集合。可以理解的是,通过扩充第一文本集合,增加了后续用于训练模型的标注数据的数量,有利于更好的训练模型。
[0093]
最后在步骤36,利用扩充后的所述第一文本集合对所述命名实体识别模型进行继续训练,得到继续训练后的命名实体识别模型。可以理解的是,继续训练后的命名实体识别模型相对于初始训练后的命名实体识别模型,模型的效果会更佳。
[0094]
在一个示例中,所述继续训练具有终止条件,所述终止条件为继续训练后的命名实体识别模型的效果评估符合要求,所述效果评估通过准确率、召回率中的至少一个指标来衡量。
[0095]
举例来说,对于ner模型的效果评估可以通过准确率(precision,简记为p)、召回率(recall,简记为r)和f-测量度(f-measure,简记为f)3个指标来衡量,计算公式如下:
[0096][0097][0098][0099]
可以理解的是,通常情况下,总的识别实体数小于总的实体数,相应地p大于r。
[0100]
图5示出根据一个实施例的模型训练框架示意图,该模型训练框架属于主动学习框架。参照图5,主动学习通过设计合理的挑选策略,即查询函数f(x),不断从未标记的数据集u中挑选出数据x*,加入标签label(x*)后放入已标记的数据集l。有效的挑选策略可以降低训练的代价并同时提高模型的识别能力。如果允许算法选择从中学习的样本,深度学习
算法可以用更少的标记训练样本获得更好的性能,从而降低样本标注成本。其中挑选策略f(x)是一个用于评估未标记数据集u中每个样本x的函数,一个好的挑选策略通常将选择信息量最大的实例x。
[0101]
图6示出根据一个实施例的模型训练过程示意图。参照图6,其显示的是基于主动学习框架的ner模型训练过程,其中初始标注数据和人工校验模型标注结果的部分为需要人工参与的部分。首先由人工标注少量的初始训练样本构成标注数据集,在该数据集上训练ner模型;然后由模型对未标注的数据集进行评估,根据预先设置的挑选策略挑选最富信息的样本,由模型对挑选出来的样本进行预标注;接着由人工校验模型的标注结果后,获得新的标注数据集,并在此基础上训练新的ner模型;重复上述步骤,直到模型效果符合要求。根据实验发现,利用模型挑选未标注样本可以仅使用60%左右的标注样本获得与在全部样本上训练模型相近的效果,有效降低了标注量;同时通过模型对样本进行预标注,人工仅需进行校验,进一步降低了标注难度和标注成本。
[0102]
通过本说明书实施例提供的训练命名实体识别模型的方法,首先获取第一文本集合和第二文本集合,所述第一文本集合中的文本具有标注信息,所述标注信息包括隐私类别及其位置,所述第二文本集合中的文本不具有标注信息;然后利用所述第一文本集合中包括的文本及其标注信息对所述命名实体识别模型进行初步训练,得到初步训练后的命名实体识别模型;接着利用所述初步训练后的命名实体识别模型评估所述第二文本集合中的各文本,根据评估结果和预先设置的挑选策略,从所述第二文本集合中挑选补充文本;再获取所述补充文本的标注信息;将所述补充文本及其标注信息添加到所述第一文本集合,以扩充所述第一文本集合;最后利用扩充后的所述第一文本集合对所述命名实体识别模型进行继续训练,得到继续训练后的命名实体识别模型。由上可见,本说明书实施例,不是直接获取大量的有标注文本用于模型训练,而是先获取少量的有标注文本对命名实体识别模型进行初步训练,然后利用初步训练后的命名实体识别模型和预先设置的挑选策略,从未标注的文本中挑选出文本,加入标注信息后放入训练集,可以用更少的有标注文本训练模型,有效地降低训练的代价并同时提高模型的识别能力,相比解析效果类似的其他深度学习方法,能够显著降低模型训练所需的标注语料数量,降低人工标注成本。
[0103]
图7示出根据一个实施例的应用程序的合规性判别方法流程图,该方法可以基于图1和图2所示的实施场景,并且基于图3所述的方法得到的继续训练后的命名实体识别模型实现。如图7所示,该实施例中应用程序的合规性判别方法包括以下步骤:步骤71,获取应用程序的代码分析结果,所述代码分析结果指示出所述应用程序实际采集的隐私信息的隐私类别构成的第一类别集合;步骤72,利用所述继续训练后的命名实体识别模型,确定所述应用程序的隐私声明文本声明采集的隐私信息的隐私类别构成的第二类别集合;步骤73,当所述第一类别集合与所述第二类别集合一致,且包括的隐私类别均属于法律法规中允许所述应用程序采集的隐私信息的隐私类别时,确定所述应用程序合规。下面描述以上各个步骤的具体执行方式。
[0104]
首先在步骤71,获取应用程序的代码分析结果,所述代码分析结果指示出所述应用程序实际采集的隐私信息的隐私类别构成的第一类别集合。可以理解的是,第一类别集合中可以包括一个或多个隐私类别。
[0105]
例如,第一类别集合仅包括前述表一中的个人基本资料对应的隐私类别;或者,第
一类别集合包括前述表一中的个人基本资料对应的隐私类别,还包括前述表一中的个人生物识别信息对应的隐私类别。
[0106]
然后在步骤72,利用所述继续训练后的命名实体识别模型,确定所述应用程序的隐私声明文本声明采集的隐私信息的隐私类别构成的第二类别集合。可以理解的是,第二类别集合可能与第一类别集合一致,即第二类别集合与第一类别集合包含的隐私类别完全相同;或者,第二类别集合可能与第一类别集合不一致,通常的情况是第二类别集合中包含的隐私类别少于第一类别集合包含的隐私类别。
[0107]
例如,第一类别集合由隐私类别1和隐私类别2构成,第二类别集合仅包含隐私类别1,则二者不一致。
[0108]
应用程序在发布时,需要配上文字版的隐私声明,也就是隐私声明文本,其中应列出企业宣称采集的各种隐私信息,包括但不限于个人位置信息、个人生物信息等。
[0109]
在一个示例中,所述利用所述继续训练后的命名实体识别模型,确定所述应用程序的隐私声明文本声明采集的隐私信息的隐私类别构成的第二类别集合,包括:
[0110]
将所述应用程序的隐私声明文本以句子为单位进行拆分,得到多个分句;
[0111]
将所述多个分句分别输入所述继续训练后的命名实体识别模型,得到各分句中分别包括的隐私信息的隐私类别;
[0112]
合并各分句中分别包括的隐私类别,得到所述应用程序的隐私声明文本声明采集的隐私信息的隐私类别构成的第二类别集合。
[0113]
可以理解的是,上述隐私声明文本通常为长文本,包括多个语句。
[0114]
本说明书实施例,命名实体识别模型还可以用于识别若干个预设种类的隐私声明合规信息,所述若干个预设种类的隐私声明合规信息包括以下至少一种:
[0115]
隐私信息存储期限、隐私信息超期处理方式、隐私信息存放地域、申诉和反馈渠道、应用程序运营者基本情况、隐私信息保护负责人联系方式。
[0116]
可以理解的是,法律法规中除了对应用程序采集的隐私类别作出规定之外,还可以对隐私声明文本中包括的上述隐私声明合规信息作出规定,例如,法律法规中规定隐私声明文本中应当包括上述至少一种隐私声明合规信息。表二为本说明书实施例提供的隐私声明合规信息与隐私类别的对应关系表。
[0117]
表二:隐私声明合规信息与隐私类别的对应关系表
[0118][0119]
可以理解的是,通常的隐私类别包括表一中所列举的个人基本资料、个人身份信息等具体隐私信息对应的隐私类别,本说明书实施例,在此基础上还可以包括隐私信息存储期限、隐私信息超期处理方式等隐私声明合规信息对应的隐私类别,从而提升了对隐私声明文本解析的全面性,便于后续依据解析结果进行合规性检查的全面性。
[0120]
最后在步骤73,当所述第一类别集合与所述第二类别集合一致,且包括的隐私类别均属于法律法规中允许所述应用程序采集的隐私类别时,确定所述应用程序合规。可以理解的是,第一类别集合与第二类别集合一致,意味着第一类别集合与第二类别集合包含的隐私类别完全相同。
[0121]
在一个示例中,所述方法还包括:
[0122]
利用所述继续训练后的命名实体识别模型,确定所述隐私声明文本包括的隐私声明合规信息的隐私类别构成的第三类别集合;
[0123]
当所述第三类别集合与法律法规中规定的第四类别集合相一致时,确定所述隐私声明文本合规,所述第四类别集合为所述隐私声明文本应当包含的隐私声明合规信息的隐私类别构成的。
[0124]
图8示出根据一个实施例的app隐私声明文本解析示意图,其中虚线框中是模型训练的具体过程。训练阶段利用初始已标注数据集训练ner模型,利用该模型评估未标注数据集,依据模型的评估结果标注部分数据,具体地,从未标注数据集中挑选部分样本,进行基于模型的预标注,并在通过人工核验后,与之前的初始已标注数据集合并获得新标注数据集,基于这一新标注数据集训练模型;循环往复,直到模型效果符合要求,至此训练阶段结束获得一个完成训练的ner模型,以应用于测试阶段对app隐私声明文本进行解析,得到其声明采集的隐私数据集合,提供给决策模块。决策模块会输入来自三方的数据分析,包括app隐私声明文本中提取出的声明采集的隐私信息,app代码解析结果指示的实际采集的隐私信息,法律法规解析结果指示的允许采集的隐私信息,最终通过比对三者得出合规报告。
[0125]
通过本说明书实施例提供的应用程序的合规性判别方法,基于本说明书实施例提供的训练命名实体识别模型的方法得到的继续训练后的命名实体识别模型实现,首先获取
应用程序的代码分析结果,所述代码分析结果指示出所述应用程序实际采集的隐私信息的隐私类别构成的第一类别集合;然后利用所述继续训练后的命名实体识别模型,确定所述应用程序的隐私声明文本声明采集的隐私信息的隐私类别构成的第二类别集合;最后当所述第一类别集合与所述第二类别集合一致,且包括的隐私类别均属于法律法规中允许所述应用程序采集的隐私信息的隐私类别时,确定所述应用程序合规。由上可见,本说明书实施例,由于所述继续训练后的命名实体识别模型识别能力高,并且可以在得知文本包含的隐私类别的同时,也能获得隐私类别出现的位置,精细化程度高,从而基于该模型得到的第二类别集合,能够有效的判别出应用程序是否合规。
[0126]
根据另一方面的实施例,还提供一种训练命名实体识别模型的装置,该装置用于执行本说明书实施例提供的训练命名实体识别模型的方法,所述命名实体识别模型用于确定目标文本中包括的隐私信息的隐私类别及其位置。图9示出根据一个实施例的训练命名实体识别模型的装置的示意性框图。如图9所示,该装置900包括:
[0127]
第一获取单元91,用于获取第一文本集合和第二文本集合,所述第一文本集合中的文本具有标注信息,所述标注信息包括隐私类别及其位置,所述第二文本集合中的文本不具有标注信息;
[0128]
第一训练单元92,用于利用所述第一获取单元91获取的第一文本集合中包括的文本及其标注信息对所述命名实体识别模型进行初步训练,得到初步训练后的命名实体识别模型;
[0129]
选择单元93,用于利用所述第一训练单元92得到的初步训练后的命名实体识别模型评估所述第一获取单元91获取的第二文本集合中的各文本,根据评估结果和预先设置的挑选策略,从所述第二文本集合中挑选补充文本;
[0130]
第二获取单元94,用于获取所述选择单元93挑选的补充文本的标注信息;
[0131]
扩充单元95,用于将所述选择单元93挑选的补充文本及所述第二获取单元94获取的其标注信息添加到所述第一文本集合,以扩充所述第一文本集合;
[0132]
第二训练单元96,用于利用所述扩充单元95扩充后的所述第一文本集合对所述第一训练单元92得到的命名实体识别模型进行继续训练,得到继续训练后的命名实体识别模型。
[0133]
可选地,作为一个实施例,所述第二获取单元94包括:
[0134]
预测子单元,用于利用所述初始训练后的命名实体识别模型确定所述补充文本中包括的隐私信息的预测类别及其预测位置;
[0135]
校验子单元,用于对所述预测子单元得到的所述补充文本中包括的隐私信息的预测类别及其预测位置进行人工校验后,得到所述标注信息。
[0136]
可选地,作为一个实施例,所述目标文本为应用程序的隐私声明文本,所述命名实体识别模型用于确定隐私声明文本中声明采集的隐私信息的隐私类别及其位置。
[0137]
可选地,作为一个实施例,所述标注信息采用bioe标记法,所述bioe标记法用于标记文本中属于隐私信息的若干连续字符的隐私类别,其起始位置、中间位置和结束位置,以及标记文本中不属于隐私信息的字符。
[0138]
可选地,作为一个实施例,所述评估结果包括,对各文本进行预测的置信度;所述挑选策略包括,选择置信度最低的文本作为所述补充文本。
[0139]
可选地,作为一个实施例,所述评估结果包括,对文本中的各字符进行预测的置信度;所述挑选策略包括,选择置信度最低的字符所在的文本作为所述补充文本。
[0140]
可选地,作为一个实施例,所述评估结果包括,对文本中的字符预测为任一标记类别的置信度;所述挑选策略包括,选择包含的各字符的平均信息熵最大的文本作为所述补充文本。
[0141]
可选地,作为一个实施例,所述继续训练具有终止条件,所述终止条件为继续训练后的命名实体识别模型的效果评估符合要求,所述效果评估通过准确率、召回率中的至少一个指标来衡量。
[0142]
通过本说明书实施例提供的训练命名实体识别模型的装置,首先第一获取单元91获取第一文本集合和第二文本集合,所述第一文本集合中的文本具有标注信息,所述标注信息包括隐私类别及其位置,所述第二文本集合中的文本不具有标注信息;然后第一训练单元92利用所述第一文本集合中包括的文本及其标注信息对所述命名实体识别模型进行初步训练,得到初步训练后的命名实体识别模型;接着选择单元93利用所述初步训练后的命名实体识别模型评估所述第二文本集合中的各文本,根据评估结果和预先设置的挑选策略,从所述第二文本集合中挑选补充文本;再由第二获取单元94获取所述补充文本的标注信息;由扩充单元95将所述补充文本及其标注信息添加到所述第一文本集合,以扩充所述第一文本集合;最后第二训练单元96利用扩充后的所述第一文本集合对所述命名实体识别模型进行继续训练,得到继续训练后的命名实体识别模型。由上可见,本说明书实施例,不是直接获取大量的有标注文本用于模型训练,而是先获取少量的有标注文本对命名实体识别模型进行初步训练,然后利用初步训练后的命名实体识别模型和预先设置的挑选策略,从未标注的文本中挑选出文本,加入标注信息后放入训练集,可以用更少的有标注文本训练模型,有效地降低训练的代价并同时提高模型的识别能力,相比解析效果类似的其他深度学习方法,能够显著降低模型训练所需的标注语料数量,降低人工标注成本。
[0143]
根据另一方面的实施例,还提供一种应用程序的合规性判别装置,该装置用于执行本说明书实施例提供的应用程序的合规性判别方法,所述装置基于图9所述的装置得到的继续训练后的命名实体识别模型实现。图10示出根据一个实施例的应用程序的合规性判别装置的示意性框图。如图10所示,该装置1000包括:
[0144]
获取单元1001,用于获取应用程序的代码分析结果,所述代码分析结果指示出所述应用程序实际采集的隐私信息的隐私类别构成的第一类别集合;
[0145]
确定单元1002,用于利用所述继续训练后的命名实体识别模型,确定所述应用程序的隐私声明文本声明采集的隐私信息的隐私类别构成的第二类别集合;
[0146]
判别单元1003,用于当所述获取单元1001获取的第一类别集合与所述确定单元1002确定的第二类别集合一致,且包括的隐私类别均属于法律法规中允许所述应用程序采集的隐私信息的隐私类别时,确定所述应用程序合规。
[0147]
可选地,作为一个实施例,所述确定单元1002包括:
[0148]
拆分子单元,用于将所述应用程序的隐私声明文本以句子为单位进行拆分,得到多个分句;
[0149]
识别子单元,用于将所述拆分子单元得到的多个分句分别输入所述继续训练后的命名实体识别模型,得到各分句中分别包括的隐私信息的隐私类别;
[0150]
合并子单元,用于合并所述识别子单元得到的各分句中分别包括的隐私类别,得到所述应用程序的隐私声明文本声明采集的隐私信息的隐私类别构成的第二类别集合。
[0151]
通过本说明书实施例提供的应用程序的合规性判别装置,基于本说明书实施例提供的训练命名实体识别模型的装置得到的继续训练后的命名实体识别模型实现,首先获取单元1001获取应用程序的代码分析结果,所述代码分析结果指示出所述应用程序实际采集的隐私信息的隐私类别构成的第一类别集合;然后确定单元1002利用所述继续训练后的命名实体识别模型,确定所述应用程序的隐私声明文本声明采集的隐私信息的隐私类别构成的第二类别集合;最后判别单元1003当所述第一类别集合与所述第二类别集合一致,且包括的隐私类别均属于法律法规中允许所述应用程序采集的隐私信息的隐私类别时,确定所述应用程序合规。由上可见,本说明书实施例,由于所述继续训练后的命名实体识别模型识别能力高,并且可以在得知文本包含的隐私类别的同时,也能获得隐私类别出现的位置,精细化程度高,从而基于该模型得到的第二类别集合,能够有效的判别出应用程序是否合规。
[0152]
根据另一方面的实施例,还提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行结合图3或图7所描述的方法。
[0153]
根据再一方面的实施例,还提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现结合图3或图7所描述的方法。
[0154]
本领域技术人员应该可以意识到,在上述一个或多个示例中,本发明所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。
[0155]
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。