1.本发明涉及机器学习研究领域,特别是涉及一种基于深度学习的监所行为规范检测装置及方法。
背景技术:
2.随着信息技术的飞速发展,计算机视觉伴随着vr、ar以及人工智能等概念的出现迎来了最好的发展时期,作为计算机视觉领域最重要的视频行为分析也越来越受到国内外学者的青睐。视频监控、人机交互、医疗看护、视频检索等一系列的领域中,视频行为分析占据了很大的比重。例如现在比较流行的无人驾驶汽车项目,视频行为分析非常具有挑战性。由于人体动作的复杂性和多样性的特点,再加上多个视角下人体自遮挡、多尺度以及视角旋转、平移等因素的影响,使得视频行为识别的难度非常大。如何能够精确地识别实际生活中多个角度下人体行为,并对人体行为进行分析,一直都是非常重要的研究课题,并且社会对行为分析的要求也越来越高。
3.传统的研究方法包含以下几种:
4.基于视频流特征点:对提取到的视频帧图像提取其中的时空特征点,然后时空特征点建模、分析,最后进行分类。
5.基于单帧图像特征:通过算法或者深度相机提取到单帧图像中人的行为特征,然后通过对行为特征进行描述、建模,训练继而对视频行为分类。
6.基于视频流特征点和单帧图像特征的行为分析方法,在传统单视角下或者单人模式下取得了显著地成果,但是针对现在像大街、机场、车站等行人流量比较大的地区或者人体遮挡、光照变化、视角变换等一系列复杂问题的出现,单纯的使用这两种分析方法在实际生活中效果往往达不到人们的要求,有时算法的鲁棒性也很差。
技术实现要素:
7.为了解决以上现有技术存在的缺陷,本发明提出一种基于深度学习的监所行为规范检测装置及方法,采用深度学习网络对人体行为进行分析,提升分类模型的鲁棒性;尤其深度学习网络适合基于大数据进行训练、学习,能够很好地发挥出其的优点。
8.本发明的技术方案是这样实现的:
9.本发明实施例提供了一种基于深度学习的监所行为规范检测装置,完全依照看守所在押人员行为规范守则进行相应的行为检测算法设计,所述检测流程包括设定各项规范行为检测的检测触发时间段与检测区域,只在设定的时间段与设定的检测区域内触发行为检测,其他时间段与其他区域不进行相应的识别算法。降低系统的执行复杂性,提高系统的稳定性。检测时间段与检测区域完全由用户自定义,依照标准行为规范设定,能够很好地满足行为规范检测的需求。
10.具体地,本发明提出了一种基于深度学习的监所行为规范检测装置,包括:人头计数检测模块和行为规范检测模块;其中:
11.所述人头计数检测模块,用于无感点名和/或人群密度识别;所述人头计数检测模块包括目标检测分割过程;
12.所述行为规范检测模块,用于对人员行为进行实时计算判别;所述行为规范检测模块包括利用训练样本集获得分类器的训练过程,以及利用分类器识别测试样本的识别过程。
13.具体地,本发明实施例还提出了一种基于深度学习的监所行为规范检测方法,其特征在于,所述方法包括如下步骤:
14.人头计数检测,用于无感点名和/或人群密度识别;所述人头计数检测包括目标检测分割过程;
15.行为规范检测,用于对人员行为进行实时计算判别;所述行为规范检测包括利用训练样本集获得分类器的训练过程,以及利用分类器识别测试样本的识别过程。
16.本发明的优点在于:使用cnn的方法得出的是全局高级特征,经过stn的特征强化,对实际生活中的视频具有很好的鲁棒性,然后使用sppe得到人体姿态信息,经过sdtn回归到人体检测框,优化自身网络,使用pp-nms来解决冗余检测问题,基于姿态估计结果进行相应的分类器训练,全局特征得到的特征更全面,使得行为描述地更加完整,适用性更强。
附图说明
17.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
18.图1是本发明人头技术检测模块的目标检测分割过程的流程示意图;
19.图2是本发明行为规范检测模块的训练过程的流程示意图;
20.图3是本发明行为规范检测模块的判别过程的流程示意图;
21.图4是简化的底层特征的提取与建模流程图;
22.图5是一般cnn的处理流程图。
具体实施方式
23.鉴于现有技术中的不足,本案发明人经长期研究和大量实践,得以提出本发明的技术方案。如下将对该技术方案、其实施过程及原理等作进一步的解释说明。
24.本发明实施例提供的一种基于深度学习的监所行为规范检测装置,使用cnn的方法对底层特征进行特征提取,得到全局的特征而不是传统方法所得到的关键点,以及,本发明实施例提供的一种基于深度学习的监所行为规范检测装置,使用stn方法对得到的全局特征进行特征强化,而不是对得到的特征直接进行建模;并且,本发明实施例提供的一种基于深度学习的监所行为规范检测装置,使用了sdtn方法对得到的姿态特征进行重新映射,进一步加强检测框的准确度,另外地,对于多尺度下的关键点,经过一层反卷积层进行关键点回归操作,能够有效提升多人关键点检测的精度,本发明实施例提供的一种基于深度学习的监所行为规范检测装置还考虑到多个关键点的连通性,建立连接关键点的有向场。根据人体关键点的连通性和人体结构明确匹配连接的关键点对。
25.本发明一实施例提供了一种基于深度学习的监所行为规范检测装置,包括:人头计数检测模块和行为规范检测模块;其中:
26.所述人头计数检测模块,用于无感点名和/或人群密度识别;所述人头计数检测模块包括目标检测分割过程;
27.所述行为规范检测模块,用于对人员行为进行实时计算判别;所述行为规范检测模块包括利用训练样本集获得分类器的训练过程,以及利用分类器识别测试样本的识别过程。
28.进一步的,所述人头计数检测模块的目标检测分割过程包括以下步骤:
29.s1)利用标注工具,对图像进行人头的标注,每个图片产生一个json文件,经过卷积神经网络提取图像标注的特征信息;
30.s2)将步骤s1)得到的特征信息使用区域生成网络提取出roi,即感兴趣区域,然后使用感兴趣区域池化将这些roi全部变成固定尺寸;
31.s3)对步骤s2)得到的roi通过全连接层进行bounding box回归和分类预测,在特征图的不同点采样,并应用双线性插值;
32.s4)最后进行分割掩码网络,取roi分类器选择的正区域为输入,并生成它们的掩码;将预测的掩码放大为roi边框的尺寸以给出最终的掩码结果,每个目标有一个掩码;将预测分割的掩模添加到每个roi,输出结果为图像上现有目标和高质量的分割掩模。
33.进一步的,所述人头计数检测模块具体包括:
34.目标检测单元,用于对在押人员的无感实时检测和统计;
35.密度分析单元,用于监舍及放风圈的实时精准密度检测和异常报警;
36.所述目标检测单元包括以下步骤:首先采集五个组分别按规范要求在不同环境中暴露出头在视频图像中,其中四个组的视频作为训练数据集,一个组视频作为验证数据集;然后将四组的视频帧图像按照所述步骤s1)至s5)进行操作,得到人头检测模型;最后对剩下那组的视频帧图像加载该人头检测模型,进行最终的人员实时检测和统计;
37.进一步的,所述行为规范检测模块的训练过程包括以下步骤:
38.s5)将某一行为的视频帧图像输入,让图片经过卷积神经网络提取特征,对网络中6个特定的卷积层的输出分别用两个3*3的卷积核进行卷积,然后将生成的所有边界框都集合起来,全部丢到nms,即非极大值抑制,得到一系列的目标检测框。
39.s6)将步骤s5)得到的目标检测框输入到stn,即空间变换网络,进行强化操作,从不准确的候选框中提取高质量的单人区域;
40.s7)对步骤s6)强化后的单人区域框使用sppe,即单人姿态估计器,估计此人的姿态骨架;
41.s8)将步骤s7)得到的单人姿态通过sdtn,即空间逆变换网络,重新映射到图像坐标系下,从而得到更加精确的人体目标检测框,并再次进行人体姿态估计操作;然后通过pp-nms,即参数化非极大值抑制,解决冗余检测问题,得到该行为下的人体骨架信息;
42.s9)对步骤s8)得到的多尺度下关键点,经过反卷积层进行关键点回归操作,相当于进行一次向上采样的过程,能够提高目标关键点的精度;考虑多个关键点的连通性,建立连接关键点的有向场,根据人体部位的连通性和结构明确匹配连接的关键点对,减少误连接,得到最终的人体骨架信息;
43.s10)对步骤s9)得到最终人体骨架信息进行特征提取,并将其作为该类行为的训练样本输入到分类器中进行训练;
44.s11)重复以上各步骤,得到各种行为的分类器。
45.进一步的,所述行为规范检测模块的识别过程包括以下步骤:
46.s12)依照看守所在押人员行为规范守则,针对具体的行为检测要求,设定检测触发时间段与检测区域,以json的形式存储在本地;
47.s13)进行检测时,先读取json文件,在设定好的检测触发时间段内,录入某一行为的视频帧图像,只取检测区域内的图像,采用所述步骤s5)至s10)对其进行人体姿态估计,得到检测区域内的人体骨架特征信息;其余时间段只播放视频帧图像,不进行相应的行为识别操作;
48.s14)将步骤s13)得到的人体骨架特征信息输入到分类器中进行识别得到视频行为类别。
49.进一步的,所述识别过程包括设定各项规范行为检测的检测触发时间段与检测区域和利用分类器进行识别,包括人为设定检测时间和检测区域,严格按照看守所在押人员行为规范守则执行,当处于检测触发时间段内,对设定的检测区域内进行相应的行为识别操作,当识别出违规行为需发出警报信息;若未在检测触发时间段内,则不进行相应的行为识别操作;检测时间段与检测区域完全由用户自定义,依照标准行为规范设定,能够很好地满足行为规范检测的需求。
50.进一步的,所述步骤s8)中pp-nms操作具体包括:选取最大置信度的姿态作为参考,并且根据消除标准将靠近该参考的区域框进行消除,多次重复该过程直到冗余的识别框被消除并且每一个识别框都是唯一出现;
51.所述步骤s8)得到的人体骨架信息还包括:使用强化数据集,通过学习输出结果中不同姿态的描述信息,来模仿人体区域框的形成过程,进一步产生一个更大的训练集。
52.本发明又一实施例提供了一种基于深度学习的监所行为规范检测方法,所述方法包括如下步骤:
53.人头计数检测,用于无感点名和/或人群密度识别;所述人头计数检测包括目标检测分割过程;
54.行为规范检测,用于对人员行为进行实时计算判别;所述行为规范检测包括利用训练样本集获得分类器的训练过程,以及利用分类器识别测试样本的识别过程。
55.进一步的,所述目标检测分割过程具体包括以下步骤:
56.s1)利用标注工具,对图像进行人头的标注,每个图片产生一个json文件,经过卷积神经网络提取图像标注的特征信息;
57.s2)将步骤s1)得到的特征信息使用区域生成网络提取出roi,即感兴趣区域,然后使用感兴趣区域池化将这些roi全部变成固定尺寸;
58.s3)对步骤s2)得到的roi通过全连接层进行bounding box回归和分类预测,在特征图的不同点采样,并应用双线性插值;
59.s4)最后进行分割掩码网络,取roi分类器选择的正区域为输入,并生成它们的掩码;将预测的掩码放大为roi边框的尺寸以给出最终的掩码结果,每个目标有一个掩码;将预测分割的掩模添加到每个roi,输出结果为图像上现有目标和高质量的分割掩模。
60.进一步的,所述人头计数检测具体包括以下步骤:
61.目标检测,用于对在押人员的无感实时检测和统计;
62.密度分析,用于监舍及放风圈的实时精准密度检测和异常报警;
63.所述目标检测包括以下步骤:首先采集五个组分别按规范要求在不同环境中暴露出头在视频图像中,其中四个组的视频作为训练数据集,一个组视频作为验证数据集;然后将四组的视频帧图像按照所述步骤s1)至s5)进行操作,得到人头检测模型;最后对剩下那组的视频帧图像加载该人头检测模型,进行最终的人员实时检测和统计。
64.如下将结合附图对该技术方案、其实施过程及原理等作进一步的解释说明。
65.如图1-图3所示,本发明的基于深度学习的监所行为规范检测方法,包括人头计数检测模块和行为规范检测模块。
66.所述人头计数检测模块,用于监所内在押人员无感点名和人群密度识别;所述行为规范检测模块,用于监舍洗漱秩序、内务整理、就餐秩序和睡觉秩序、起床秩序、电视教育秩序、安全轮值规范、操行考核规范、三定位监管规范、出监抱头规范的行为进行实时计算判别。
67.其中,所述人头计数检测模块具体包括:目标检测单元,用于对在押人员的无感实时检测和统计。密度分析单元,用于监舍及放风圈的实时精准密度检测和异常报警。
68.其中,所述行为规范检测模块具体包括:
69.洗漱秩序比对单元,用于监舍设定卫生间与排队等候区,实时计算判别卫生间内是否保持只有2人,其他人员是否在规定区域内等候。
70.整理内务规范单元,用于监舍设定床铺与靠墙等候区,实时计算判别床铺是否始终保持4人在整理内务,其他人员是否在靠墙区域内等候。
71.就餐秩序比对单元,用于监舍就餐时间,实时计算判别是否有异常未坐立就餐人员。
72.睡觉秩序比对单元,用于监舍休息时间,实时计算判别是否有蒙头睡觉、违规起身。
73.起床秩序规范单元,用于监舍起床截止时间,实时计算判别是否有人在床铺内。
74.电视教育秩序比对单元,用于监舍电视教育时间,实时计算判别是否有异常未坐立观看电视教育人员,并且走动人数过多将发出警报。
75.安全轮值规范单元,用于监舍设定安全轮值区域,实时计算判别安全轮值区域是否保持2人在场,并且长时间处在同一位置不动判别为违规。
76.操行规范考核单元,用于监舍做操时间,实时计算判别队列整齐度并进行评分。
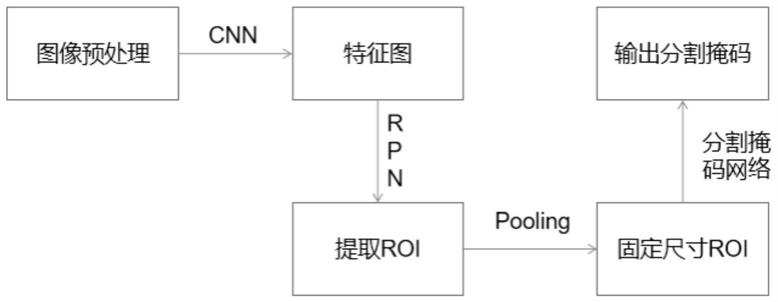
77.三定位监管单元,用于监舍发生打架行为时,实时计算判别人员是否按规定进行“三定位”操作。
78.出监抱头规范单元,用于监舍设定警戒线区域,实时计算判别人员出监舍是否按规定在警戒线区域内进行双手抱头。
79.进一步地,其中人头技术检测模块包括了目标检测分割过程,行为规范检测模块包括利用训练样本集获得分类器的训练过程及利用分类器识别测试样本的识别过程。完全依照看守所在押人员行为规范守则进行相应的行为检测算法设计。所述识别过程包括设定各项规范行为检测的检测触发时间段与检测区域和利用分类器进行识别,包括人为设定检
测时间和检测区域,严格按照看守所在押人员行为规范守则执行,当处于检测触发时间段内,对设定的检测区域内进行相应的行为识别操作,当识别出违规行为需发出警报信息。若未在检测触发时间段内,则不进行相应的行为识别操作。检测时间段与检测区域完全由用户自定义,依照标准行为规范设定,能够很好地满足行为规范检测的需求。只在设定的时间段与设定的检测区域内触发行为检测,其他时间段与其他区域不进行相应的识别算法。降低系统的执行复杂性,提高系统的稳定性。检测时间段与检测区域完全由用户自定义,依照标准行为规范设定,能够很好地满足行为规范检测的需求。
80.进一步地,所述人头技术检测模块的目标检测分割过程如图1所示,包括以下步骤:
81.s1)利用标注工具,对图像进行人头的标注,每个图片产生一个json文件。经过cnn(convolutional neural network,卷积神经网络)提取图像标注的特征信息。
82.s2)将步骤s1)得到的特征信息使用rpn(regionproposal network,区域生成网络)去提取出roi(region of interest,感兴趣区域),然后使用roi pooling(感兴趣区域池化)将这些roi全部变成固定尺寸。
83.s3)对步骤s2)得到的roi通过全连接层进行bounding box回归和分类预测,在特征图的不同点采样,并应用双线性插值。
84.s4)最后进行分割掩码网络,取roi分类器选择的正区域为输入,并生成它们的掩码。将预测的掩码放大为roi边框的尺寸以给出最终的掩码结果,每个目标有一个掩码。将预测分割的掩模添加到每个roi,输出结果为图像上现有目标和高质量的分割掩模。
85.数据集包含四种不同环境、10人分五组,每组按规范要求重复三次。使用其中的四个组作为训练数据集,剩余的一组作为测试数据集。
86.具体的,例如要完成目标检测,首先采集五个组分别按规范要求在不同环境中暴露出头在视频图像中,其中四个组的视频作为训练数据集,一个组视频作为验证数据集。首先将四组的视频帧图像按照上述步骤s1)至s5)进行操作,最终得到的是人头检测的模型;然后对剩下那组的视频帧图像加载该人头检测模型,进行最终的人员实时检测和统计。若要完成密度检测,则需要在最后进行一步密度计算即可。
87.所述行为规范检测模块的训练过程如图2所示,包括以下步骤:
88.s5)将某一行为的视频帧图像输入,让图片经过cnn提取特征,对网络中6个特定的卷积层的输出分别用两个3*3的卷积核进行卷积,然后将生成的所有边界框都集合起来,全部丢到nms(non-maximum-suppression,非极大值抑制)中,得到一系列的目标检测框。
89.s6)将步骤s5)得到的目标检测框输入到stn(spatial transform networks,空间变换网络)进行强化操作,从不准确的候选框中提取高质量的单人区域。
90.s7)对步骤s6)强化后的单人区域框使用sppe(single person pose estimator,单人姿态估计器)来估计此人的姿态骨架。
91.s8)将步骤s7)得到的单人姿态通过sdtn(spatial de-transformer network,空间逆变换网络)重新映射到图像坐标系下,从而得到更加精确的人体目标检测框,并再次进行人体姿态估计操作。然后通过pp-nms(parametric pose non-maximum-suppression,参数化非极大值抑制)来解决冗余检测问题,得到该行为下的人体骨架信息。
92.s9)对步骤s8)得到的多尺度下关键点,经过反卷积层进行关键点回归操作,相当
于进行一次向上采样的过程,能够提高目标关键点的精度。考虑多个关键点的连通性,建立连接关键点的有向场,根据人体部位的连通性和结构明确匹配连接的关键点对,减少误连接,得到最终的人体骨架信息。
93.s10)对步骤s9)得到最终人体骨架信息进行特征提取,并将其作为该类行为的训练样本输入到分类器中进行训练;
94.s11)重复以上各步骤,得到各种行为的分类器。
95.所述行为规范检测模块的识别过程如图2所示,包括以下步骤:
96.s12)依照看守所在押人员行为规范守则,针对具体的行为检测要求,设定检测触发时间段与检测区域,以json的形式存储在本地。
97.s13)进行检测时,先读取json文件,在设定好的检测触发时间段内,录入某一行为的视频帧图像,只取检测区域内的图像,采用上述步骤s5)至s10)对其进行人体姿态估计,得到检测区域内的人体骨架特征信息。其余时间段只播放视频帧图像,不进行相应的行为识别操作。
98.s14)将步骤s13)得到的人体骨架特征信息输入到分类器中进行识别得到视频行为类别。
99.上述技术方案中,步骤s5)优选两层卷积对不同的特征图来进行提取检测结果。
100.上述技术方案中,步骤s8)中pp-nms操作如下:
101.首先选取最大置信度的姿态作为参考,并且根据消除标准将靠近该参考的区域框进行消除,这个过程多次重复直到冗余的识别框被消除并且每一个识别框都是唯一出现。
102.上述技术方案中,步骤s8)得到的人体骨架信息还包括以下操作:
103.使用强化数据集,通过学习输出结果中不同姿态的描述信息,来模仿人体区域框的形成过程,进一步产生一个更大的训练集。
104.本发明优选采用看守所数据集,数据集包含四种不同环境、10人分五组,每组按规范要求重复三次。使用其中的四个组作为训练数据集,剩余的一组作为测试数据集。
105.具体的,例如要识别“洗漱”这个行为,首先采集四个组分别按规范要求进入洗漱区域,一个组违规进入洗漱区域,其中四个组的洗漱视频作为训练数据集,一个组的洗漱视频作为验证数据集。首先将某一组的洗漱视频帧图像按照上述步骤s1)至s5)进行操作,最终得到的是“洗漱”视频行为的人体姿态骨架信息特征;将其作为这一组的“洗漱”这一行为规范的训练样本,输入分类器训练;经过多次不同组的训练样本训练后,得到“洗漱”行为分类器。同理,可以构建各种视频行为的分类器。
106.当进行判别时,执行上述步骤s12)至s14),首先设定好检测触发时间段与检测区域,如果当前时间在检测触发时间段内,则将测试样本中的一个组的视频帧图像按照设定好的检测区域进行分割,只将检测区域内的图像按照上述步骤s5)至s10)进行操作,得到该检测区域内的人体姿态骨架信息特征,再经过数据强化集,将其输入分类器中识别出行为类别。其他环境的判别别过程与此同。
107.如图3所示为简化的底层特征提取与建模流程图。
108.本发明的技术方案中,采用的姿态估计框架是rmpe(regional multi-person pose estimation,区域多人姿态检测),如图3所示,首先对输入图像使用cnn进行特征提取,然后对网络中6个特定的卷积层的输出分别用两个3*3的卷积核进行卷积,将生成的所
有边界框集合起来通过nms得到筛选后的目标检测框,然后将该检测框输入到stn和sppe中自动检测人体姿态,再通过sdtn和pp-nms进行回归,建立连接关键点的有向场,减少误连接得到最终的人体姿态骨架特征。
109.本发明的技术方案采用两层卷积操作来提取底层特征,然后通过非极大值抑制方法对检测结果进行冗余消除。将冗余消除之后的检测框输入到stn层中对特征进行强化操作,stn网络的功能是能够使得到的特征具有对平移、旋转和尺度变化具有鲁棒性。然后将stn输出的特征图像进行sppe单人姿态估计,接着通过sdtn将姿态估计结果回归到图像坐标系下,能够在不精准的区域框中提取到高质量的人体区域。然后通过pp-nms解决冗余检测的问题。最后经过反卷积层进行关键点回归,提高关键点精度,建立连接关键点的有向场,减少误连接,从而得到最终的人体骨架信息。
110.上述技术方案中,cnn是近年来发展起来的发展起来、并引起重视的高效识别方法。20世纪60年代,hubel和wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了cnn。现在,cnn已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。
111.一般地,cnn的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。
112.本发明的技术方案中就是使用特征映射层,提取视频帧图像中的全局底层特征,而后对底层特征进行更深层次的处理。
113.cnn的一般化处理流程如图4所示。
114.本发明的技术方案要使用的层就是在经过卷积以后得到的feature map,我们抽取其中六层的feature map大小分别是(38,38),(19,19),(10,10),(5,5),(3,3),(1,1),然后在feature map的每个单元设置多个尺度或者长宽比不同的先验框。这样就形成了特征图。对特征图进行卷积得到检测结果,检测值包括类别置信度和边界框位置。各采用一次3
×
3卷积来进行完成。
115.应当理解,上述实施例仅为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人士能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所作的等效变化或修饰,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。