技术特征:
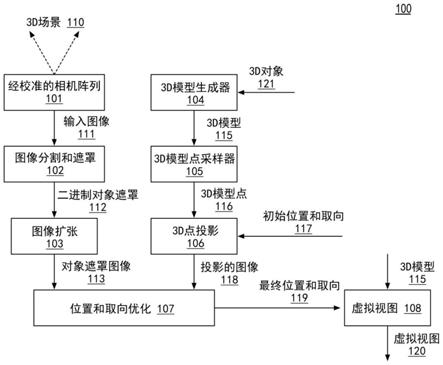
1.一种用于生成3d场景内的虚拟视图的系统,包括:存储器,用于存储所述3d场景内的3d对象的3d模型;以及与所述存储器耦合的一个或多个处理器,所述一个或多个处理器用于:生成第一对象遮罩图像和第二对象遮罩图像,所述第一对象遮罩图像和第二对象遮罩图像的每一者包括所述3d对象的2d表示,并且所述第一对象遮罩图像和第二对象遮罩图像代表在所述3d场景上经训练的第一相机和第二相机的第一图像平面和第二图像平面;基于所述3d场景中的所述3d模型的初始位置和取向,将所述3d模型的多个3d点投影到所述第一图像平面和第二图像平面上;并且基于成本函数的优化来确定所述3d场景中的所述3d模型的最终位置和取向,所述成本函数将所述第一对象遮罩图像和第二对象遮罩图像与所述第一图像平面和第二图像平面上投影的3d点进行比较。2.如权利要求1所述的系统,其中所述成本函数的优化包括分段线性函数的总和的最小化,每个分段线性函数包括以下二者之间的差值的总和:所述第一对象遮罩图像和第二对象遮罩图像的最大值、与所述多个3d点中的每一者在所述第一对象遮罩图像和第二对象遮罩图像上的投影相对应的所述第一对象遮罩图像和第二对象遮罩图像的值。3.如权利要求2所述的系统,其中所述多个3d点中的每一者的投影包括:利用所述3d模型的当前位置和取向对所述3d场景中的所述多个3d点中的每一者的3d位置的确定,以及利用与所述第一图像平面和第二图像平面相对应的第一投影矩阵和第二投影矩阵从所述3d位置到所述第一对象遮罩图像和第二对象遮罩图像上的投影。4.如权利要求1至3中任一项所述的系统,还包括所述一个或多个处理器将所述3d模型的初始位置和取向选择为所述3d场景的先前建模中的所述3d模型的先前最终位置和取向。5.如权利要求1至3中任一项所述的系统,其中所述一个或多个处理器生成所述第一对象遮罩图像和第二对象遮罩图像包括:所述一个或多个处理器确定第一二进制遮罩图像和第二二进制遮罩图像,并且对所述第一二进制遮罩图像和第二二进制遮罩图像进行扩张以生成所述第一对象遮罩图像和第二对象遮罩图像,其中,所述第一二进制遮罩图像和第二二进制遮罩图像包括针对被认为在所述3d对象内的像素的第一像素值以及针对被认为在所述3d对象以外的像素的第二像素值,所述第一对象遮罩图像和第二对象遮罩图像包括灰度图像。6.如权利要求5所述的系统,其中所述一个或多个处理器确定所述第一二进制遮罩图像和第二二进制遮罩图像包括:将卷积神经网络应用到经由所述第一相机和第二相机获得的第一源图像和第二源图像。7.如权利要求5所述的系统,其中所述一个或多个处理器进行扩张包括:所述一个或多个处理器在第一分割图像中,在所述对象以外的一部分像素中生成朝着所述对象内的像素递增的梯度。8.如权利要求7所述的系统,其中所述一个或多个处理器进行扩张包括:所述一个或多个处理器响应于第一初始位置和取向置信度值或者第二初始位置和取向置信度值分别应用第一梯度或第二梯度,所述第二初始位置和取向置信度值小于所述第一初始位置和取向置信度值,其中,所述第一梯度与所述第二梯度相比,随像素距离变化的像素值变化具有更大的斜率。
9.如权利要求1至3中任一项所述的系统,其中所述3d模型包括网格对象模型,所述网格对象模型包括代表所述3d对象的多个索引和所述索引之间的面,并且所述多个3d点包括来自所述网格模型的面的点。10.如权利要求1至3中任一项所述的系统,其中所述3d模型包括非刚性3d模型,所述非刚性3d模型包括针对所述3d模型的3d片段之间的运动的一个或多个自由度,并且所述一个或多个处理器确定所述3d模型的最终位置和取向还包括:所述一个或多个处理器基于所述成本函数的优化来确定针对所述运动的一个或多个自由度的最终参数。11.如权利要求1至3中任一项所述的系统,所述一个或多个处理器用于:至少部分基于所述3d场景中的所述3d模型的最终位置和取向来生成所述3d场景内的虚拟视图。12.一种用于生成3d场景内的虚拟视图的方法,包括:接收所述3d场景内的3d对象的3d模型;生成第一对象遮罩图像和第二对象遮罩图像,所述第一对象遮罩图像和第二对象遮罩图像的每一者包括所述3d对象的2d表示,并且所述第一对象遮罩图像和第二对象遮罩图像代表在所述3d场景上经训练的第一相机和第二相机的第一图像平面和第二图像平面;基于所述3d场景中的所述3d模型的初始位置和取向,将所述3d模型的多个3d点投影到所述第一图像平面和第二图像平面上;并且基于成本函数的优化来确定所述3d场景中的所述3d模型的最终位置和取向,所述成本函数将所述第一对象遮罩图像和第二对象遮罩图像与所述第一图像平面和第二图像平面上投影的3d点进行比较。13.如权利要求12所述的方法,其中所述成本函数的优化包括分段线性函数的总和的最小化,每个分段线性函数包括以下二者之间的差值的总和:所述第一对象遮罩图像和第二对象遮罩图像的最大值、与所述多个3d点中的每一者在所述第一对象遮罩图像和第二对象遮罩图像上的投影相对应的所述第一对象遮罩图像和第二对象遮罩图像的值。14.如权利要求13所述的方法,其中所述多个3d点中的每一者的投影包括:利用所述3d模型的当前位置和取向对所述3d场景中的所述多个3d点中的每一者的3d位置的确定,以及利用与所述第一图像平面和第二图像平面相对应的第一投影矩阵和第二投影矩阵从所述3d位置到所述第一对象遮罩图像和第二对象遮罩图像上的投影。15.如权利要求12所述的方法,还包括:将所述3d模型的初始位置和取向选择为所述3d场景的先前建模中的所述3d模型的先前最终位置和取向。16.如权利要求12至15中任一项所述的方法,其中所述生成所述第一对象遮罩图像和第二对象遮罩图像包括:确定第一二进制遮罩图像和第二二进制遮罩图像,并且扩张所述第一二进制遮罩图像和第二二进制遮罩图像以生成所述第一对象遮罩图像和第二对象遮罩图像,其中,所述第一二进制遮罩图像和第二二进制遮罩图像包括针对被认为在所述3d对象内的像素的第一像素值以及针对被认为在所述3d对象以外的像素的第二像素值,所述第一对象遮罩图像和第二对象遮罩图像包括灰度图像。17.如权利要求16所述的方法,其中所述确定所述第一二进制遮罩图像和第二二进制遮罩图像包括:将卷积神经网络应用到经由所述第一相机和第二相机获得的第一源图像和第二源图像。
18.如权利要求16所述的方法,其中所述扩张包括:在第一分割图像中,在所述对象以外的一部分像素中生成朝着所述对象内的像素递增的梯度。19.如权利要求18所述的方法,其中所述扩张包括:响应于第一初始位置和取向置信度值或者第二初始位置和取向置信度值分别应用第一梯度或第二梯度,所述第二初始位置和取向置信度值小于所述第一初始位置和取向置信度值,其中,所述第一梯度与所述第二梯度相比,随像素距离变化的像素值变化具有更大的斜率。20.如权利要求12至15中任一项所述的方法,其中所述3d模型包括网格对象模型,所述网格对象模型包括代表所述3d对象的多个索引和所述索引之间的面,并且所述多个3d点包括来自所述网格模型的面的点。21.如权利要求12至15中任一项所述的方法,其中所述3d模型包括非刚性3d模型,所述非刚性3d模型包括针对所述3d模型的3d片段之间的运动的一个或多个自由度,并且确定所述3d模型的最终位置和取向还包括:基于所述成本函数的优化来确定针对所述运动的一个或多个自由度的最终参数。22.如权利要求12至15中任一项所述的方法,还包括:至少部分基于所述3d场景中的所述3d模型的最终位置和取向来生成所述3d场景内的虚拟视图。23.至少一个机器可读介质,包括:多个指令,所述多个指令响应于在计算设备上被执行,而使得所述计算设备实现根据权利要求13-22中任一项所述的方法。24.一种装置,包括:用于执行根据权利要求13-22中任一项所述的方法的构件。
技术总结
本申请涉及利用图像分割将复杂的3D对象嵌入到增强现实场景中。论述了与在3D场景内嵌入3D对象模型有关的技术。这种技术包括为在3D场景上训练的两个或更多个相应相机确定两个或更多个对象遮罩图像,将3D点从3D对象模型投影到两个或更多个相机的图像平面,并且利用对象遮罩图像和投影的3D点确定场景中的3D对象模型的位置和取向。模型的位置和取向。模型的位置和取向。
技术研发人员:丹尼
受保护的技术使用者:英特尔公司
技术研发日:2021.07.19
技术公布日:2022/2/23
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。