1.本发明涉及数据处理、计算机视觉等领域,尤其涉及一种条件对抗域泛化的人脸活体检测方法及网络模型架构。
背景技术:
2.人脸识别作为一个备受关注的问题被广泛应用于生物识别领域(例如,智能手机解锁、访问控制、刷脸支付),人脸欺诈攻击(例如,打印攻击、视频攻击、3d面具攻击等)对人脸识别系统造成了极大威胁,曾有研究人员利用合法用户在社交网络上发布的照片轻松的经过了较成熟的商业人脸识别系统的识别认证。人脸活体检测技术可以辨别当前获取的人脸图像是来自活体样本还是攻击样本,可以验证用户的真实性,有效提高人脸识别系统的安全性能。
3.随着高清摄像机的普及和高质量3d面具的应用,人脸活体检测技术面临新的挑战。具体表现在以下几点:假体人脸与活体人脸的区别特征越加细微,类间的特征重叠越加严重,降低了人脸活体检测的精度和泛化性能;由于图像纹理特征、颜色差异以及攻击类型的多样性导致不同数据库的人脸数据分布差异很大,跨场景的、未知欺诈形式的人脸活体检测的泛化性能较差。
4.现有的很多对抗域泛化的方法只是对齐了多个源域的特征分布,而忽略了类层面的对齐,不能保证多个源域的分布差异足够融合,影响系统的泛化性能;此外,域判别器对所有样本给予同样的重要性,那些预测不准确的难迁移样本可能会影响模型的性能。
技术实现要素:
5.本发明提供了一种条件对抗域泛化的人脸活体检测方法,包括:
6.从多源域图像中提取多源域图像特征,将提取的特征输入特征生成器生成特征编码,并将提取的特征输入深度估计网络输出人脸深度损失;
7.将特征编码输入分类器预估分类结果,将特征编码器输出的特征编码和分类器输出的分类结果进行融合,将融合结果输入域判别器,进行域判别器和特征生成器的域对抗网络训练,得到域对抗损失;
8.使用交叉熵损失函数对分类器进行训练,得到分类损失;以及利用非对称三元组训练模型对特征编码进行训练,得到非对称三元组损失;
9.根据人脸深度图损失、非对称三元组损失、分类损失和域对抗损失构造综合优化目标,使用综合优化目标训练特征生成器和分类器;
10.在测试阶段,将测试样本送入特征生成器和分类器进行人脸活体检测。
11.如上所述的条件对抗域泛化的人脸活体检测方法,其中,从多源域图像中提取多源域图像特征,具体为:将多源域图像输入注意力残差网络来提取输入图像的特征,利用注意力机制抑制输入图像中的不相关区域,同时突出特定局部区域的显著特征。
12.如上所述的条件对抗域泛化的人脸活体检测方法,其中,进行域判别器和特征生
成器的域对抗网络训练,具体包括:基于多线性映射的数据融合域对抗训练,通过多线性映射的方式进行数据融合,具体操作是使用特征编码和分类结果两个向量的张量积进行数据融合。
13.如上所述的条件对抗域泛化的人脸活体检测方法,其中,进行域判别器和特征生成器的域对抗网络训练,还包括基于熵加权条件域对抗训练,根据样本的分类预测结果,给予不同的样本以不同的权重,减小预测不准确的难迁移样本对模型性能的影响。
14.如上所述的条件对抗域泛化的人脸活体检测方法,其中,基于熵加权条件域对抗训练,具体包括:
15.采用信息熵来衡量分类器分类的不确定性,式中,c为类别数,gc是样本的分类预测结果;
16.根据信息熵计算得到熵感知权重根据信息熵计算得到熵感知权重被用来对样本重新加权,当分类器预测的不确定性越大时,权重值越小。
17.如上所述的条件对抗域泛化的人脸活体检测方法,其中,在特征生成器和域判别器之间添加了梯度反转层,即在反向传播时,特征生成部分的梯度乘以-λ来训练特征生成器和域判别器,其中,current_iters为模型训练当前迭代次数,total_iters为总迭代次数。
18.如上所述的条件对抗域泛化的人脸活体检测方法,其中,构造的综合优化目标表示如下:
19.l
dg
=λ1l
cls
λ2l
ada
λ3l
dep
λ4l
trip
20.式中,l
cls
、l
ada
、l
dep
、l
trip
分别代表交叉熵分类损失、域对抗损失、人脸深度损失和非对称三元组损失,λ1~λ4是超参数。
21.如上所述的条件对抗域泛化的人脸活体检测方法,其中,人脸深度损失如下:
22.l
dep
(x,dep)=||dep(e(x))-i||
23.其中,e(x)是注意力残差网络输出的特征,dep(e(x))是注意力残差网络模块中深度估计器所估计的深度图,i是用人脸对齐网络估计的深度图。
24.如上所述的条件对抗域泛化的人脸活体检测方法,其中,非对称三元组损失损失函数表示如下:
[0025][0026]
式中,分别是描样本、正样本和负样本,α是边界阈值。
[0027]
如上所述的条件对抗域泛化的人脸活体检测方法,假设有n个源域,分别定义为x=x1,x2,...,xn,域标签定义为y=y1,y2,...,yn,每个域都包含两种类别的样本:活体人脸和假体人脸,,则对抗训练的最终优化目标如下:
[0028][0029]
式中,l
ada
表示域对抗损失,d为域判别器,g为特征生成器,y是样本x的域标签,x,y分别服从x,y分布,1
[n=y]
是指示函数,当n=y时,即判别器判断样本域正确时,指示函数为
1,否则为0;h(x)是融合后的数据,g(x)是样本x的特征编码器输出,g(x)是其分类器输出。
[0030]
本发明还提供一种条件对抗域泛化的人脸活体检测网络模型架构,包括:特征生成模块、条件域对抗训练模块和辅助监督分类模块;采用如权利要求1-9任一项所述的条件对抗域泛化的人脸活体检测方法进行人脸活体检测,在训练阶段,通过人脸深度图损失、非对称三元组损失、分类损失和域对抗损失来训练特征生成网络和分类网络;在测试阶段,将测试样本送入特征生成网络和分类网络,从而进行人脸活体检测。
[0031]
本发明实现的有益效果如下:
[0032]
(1)本发明利用注意力残差网络、度量学习等技术,来提取活体人脸和假体人脸中更具区分性的微特征,提高类内的紧性以及类间的区分性,来提高人脸活体检测的精度。此外,该算法充分利用了活体人脸与假体人脸在深度图像上的差异,利用人脸深度图不随场景变化的特点,来提高人脸活体检测的精度和泛化性能。
[0033]
(2)利用条件域对抗网络来提高跨场景下未知欺诈的检测性能,通过域对抗网络不仅对齐了多个源域的特征分布,还考虑了分类预测信息;通过对样本添加预分类的熵加权,来减小预测不准确样本对模型的影响,有效地提高了跨场景下未知欺诈检测的泛化性能。
附图说明
[0034]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
[0035]
图1是本发明实施例提供的条件对抗域泛化的人脸活体检测方法的网络模型架构示意图;
[0036]
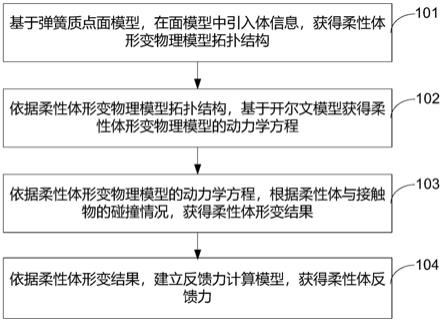
图2是条件对抗域泛化的人脸活体检测方法流程图;
[0037]
图3是attention-unet子模型的网络结构图;
[0038]
图4是非对称三元组样本挖掘策略示意图。
具体实施方式
[0039]
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0040]
实施例一
[0041]
如图1所示,本发明实施例提供一种网络模型架构,整个模型架构分为特征生成模块、条件域对抗训练模块和辅助监督分类模块。采用条件对抗域泛化的人脸活体检测方法进行人脸活体检测,在训练阶段,通过人脸深度图损失、非对称三元组损失、分类损失和域对抗损失来训练特征生成网络和分类网络;在测试阶段,将测试样本送入特征生成网络和分类网络,从而进行人脸活体检测。
[0042]
如图2所示,所述条件对抗域泛化的人脸活体检测方法,包括:
[0043]
步骤210、从多源域图像中提取多源域图像特征,将提取的特征输入特征生成器生成特征编码,并将提取的特征输入深度估计网络输出人脸深度损失;
[0044]
首先使用attention-unet(注意力残差网络)来提取输入图像的特征,利用注意力机制抑制输入图像中的不相关区域,同时突出特定局部区域的显著特征;然后将提取的特征送入特征生成器,特征编码器包括resnet-18的layer2-layer4层以及一个自适应平均池化层、一个具有512个节点的全连接层,进一步对特征进行编码,作为后续网络的输入数据。
[0045]
图3展示了attention-unet子模型的网络结构,该子模块使用了se-resnet-50作为预训练的模型,并将它的layer0-layer4层作为attention-unet的编码器部分,对输入的图像进行下采样,在解码器部分,在上采样的过程中添加了空间注意力机制来提取更多的域共享特征和有助于分类的人脸区域特征,然后采用双线性插值法将每次上采样后的特征图变换为相同的尺寸,并对特征图进行拼接。
[0046]
另外,attention-unet模块提取的特征还会送入到一个深度估计网络。人脸深度图作为一种场景不变的信息,可以用来辅助模型的训练,以提取更多的泛化的差异线索。活体人脸的嘴巴、鼻子和额头之间有一定深度,其深度图的灰度值应该不为0,本发明使用人脸对齐网络prnet所估计的深度信息作为假设的活体人脸深度信息;而假体人脸是一个平面,所以其深度图的灰度值被设置为0;
[0047]
具体地,通过有监督学习来训练深度估计网络,对应的人脸深度损失如下:
[0048]
l
dep
(x,dep)=||dep(e(x))-i||
[0049]
其中,e(x)是attention-unet网络输出的特征,dep(e(x))是attention-unet模块中深度估计器所估计的深度图,i是用prnet估计的深度图。
[0050]
步骤220、将特征编码输入分类器预估分类结果,将特征编码器输出的特征编码和分类器输出的分类结果进行融合,将融合结果输入域判别器,进行域判别器和特征生成器的域对抗网络训练,得到域对抗损失;
[0051]
域泛化技术是假设在可见的多个源域和未知的目标域下存在一个泛化的特征空间,本发明通过域判别器和特征生成器的对抗训练实现对抗域泛化,并通过为生成器和判别器添加条件机制可以进一步约束对抗网络的性能,实现条件对抗域泛化,将多个源域的特征映射到未知的目标域下,从而提高模型在跨场景下的泛化性能。
[0052]
本发明实施例中,进行域判别器和特征生成器的域对抗网络训练,具体包括:
[0053]
(1)基于多线性映射的数据融合域对抗训练,通过多线性映射的方式进行数据融合,具体操作是使用特征编码和分类结果两个向量的张量积进行数据融合。假设x表示输入样本,g(x)是样本x的特征编码器输出,g(x)是其分类器输出,则g(x)和g(x)的融合表示成以下公式:
[0054][0055]
h(x)是融合后的数据,将其送入特征生成器参与对抗训练。假设有n个源域,分别定义为x=x1,x2,...,xn,域标签定义为y=y1,y2,...,yn,每个域都包含两种类别的样本:活体人脸和假体人脸。特征生成器g和域判别器d的对抗网络训练是一个极大极小的优化问题:
[0056][0057]
式中,l
ada
表示对抗训练损失,y是样本x的域标签,x,y分别服从x,y分布,1
[n=y]
是指示函数,当n=y时,即判别器判断样本域正确时,指示函数为1,否则为0。在优化过程中,g与d将进行迭代式的对抗训练,g的优化目标是最大化对抗训练的损失,即让域判别器d分不清样本来源于哪一个域,从而提取到更多与域无关的特征;而d希望最小化对抗训练的损失,能够分清样本的来源类型。
[0058]
优选地,本发明在训练模型时,考虑到由于g与d的训练目的是相反的,因此g网络与d网络通常是分别训练的,训练效率低,因此在特征生成器和域判别器之间添加了梯度反转层(gradient reversal layer,grl),也就是反向传播时,特征生成部分的梯度会乘以-λ,通过这种方式可以同时训练g与d,这样可以提高gans训练的效率。其中,current_iters为模型训练当前迭代次数,total_iters为总迭代次数。
[0059]
(2)基于熵加权条件域对抗训练,根据样本的分类预测结果,给予不同的样本以不同的权重,来减小预测不准确的难迁移样本对模型性能的影响。
[0060]
具体地,通过添加条件来关联特征生成器和域判别器,使多个域的分布匹配更好。因此,本模块根据分类预测结果来给域判别器添加条件,给予分类不确定样本以较小的权重,以减小预测不准确样本对模型的影响。本发明采用信息熵来衡量分类器分类的不确定性,式中,c为类别数,gc是样本的分类预测结果。根据信息熵计算得到熵感知权重熵感知权重被用来对样本重新加权,当分类器预测的不确定性越大时,权重值越小,从而在对抗训练时,域判别器被混淆的程度减小。假设有n个源域,分别定义为x=x1,x2,...,xn,域标签定义为y=y1,y2,...,yn,每个域都包含两种类别的样本:活体人脸和假体人脸,加入熵加权调整以后,模型对抗训练的最终优化目标更新如下:
[0061][0062]
式中,l
ada
表示域对抗损失,d为域判别器,g为特征生成器,y是样本x的域标签,x,y分别服从x,y分布,1
[n=y]
是指示函数,当n=y时,即判别器判断样本域正确时,指示函数为1,否则为0;h(x)是融合后的数据,g(x)是样本x的特征编码器输出,g(x)是其分类器输出。
[0063]
步骤230、使用交叉熵损失函数对分类器进行训练,得到分类损失;以及利用非对称三元组训练模型对特征编码进行训练,得到非对称三元组损失;
[0064]
为了保证特征生成器所生成的是本系统需要的区别特征,例如活体与假体的区别特征,而不是其他特征,例如不同个体的人脸区别特征,本模型添加了一个有监督的分类器,使用了交叉熵损失函数作为目标函数,以提高人脸活体检测的精度。
[0065]
此外,为了降低活体人脸与假体人脸特征空间的重叠程度,本算法引入了度量学习技术来提高类内的紧性以及类间的区分性。由于欺诈人脸类型的多样性,其特征空间分布差异较大,因此很难为他们寻找到共同的紧凑特征空间,因此,本发明假设不同类型的欺
诈人脸具有不同的特征分布空间,而活体人脸共享同一个特征分布空间。算法引入了非对称的三元组损失,采用了batch-all的负样本挖掘策略,如图4所示的非对称三元组样本挖掘策略,加黑色边框的样本为描样本。若描样本是活体样本,则正样本可以是同域的,也可以是其他域的活体样本,而负样本通常是同域的假体样本;若描样本是假体样本,则正样本是同域的假体样本而负样本是其他域的活体或假体样本。这样能促使不同域的活体样本紧凑,并促使活体样本与假体样本之间以及不同域的假体样本之间离散;
[0066]
非对称三元组损失损失函数可表示如下:
[0067][0068]
式中,分别是描样本、正样本和负样本,α是边界阈值。
[0069]
步骤240、根据人脸深度图损失、非对称三元组损失、分类损失和域对抗损失构造综合优化目标,使用综合优化目标训练特征生成器和分类器;
[0070]
本发明构造的综合优化目标表示如下:
[0071]
l
dg
=λ1l
cls
λ2l
ada
λ3l
dep
λ4l
trip
[0072]
式中,l
cls
、l
ada
、l
dep
、l
trip
分别代表交叉熵分类损失、域对抗损失、人脸深度损失和非对称三元组损失,λ1~λ4是超参数。本发明采用端到端的方式来训练模型,使其生成更加泛化的域共享特征空间,因此,模型可以泛化到未知的目标域。
[0073]
步骤250、在测试阶段,将测试样本送入特征生成器和分类器进行人脸活体检测。
[0074]
通过以下实验过程验证本发明条件对抗域泛化的人脸活体检测方法的检测效果:
[0075]
(1)搭建实验环境:
[0076]
①
设置性能评价指标:本算法使用auc(area underthe curve)面积和半错误率(half total error rate,hter)作为评价指标。auc是roc(receiver operating characteristic curve)曲线下的面积,roc是不同阈值下的far(false acceptance rate)和frr(false reject rate)所绘制的二维曲线,far是错误接受率,是把假体人脸判断成活体人脸的比率;frr是错误拒绝率,是把活体人脸判断成假体人脸的比率。计算半错误率hter首先需要绘制验证集上的roc曲线,找到frr等于far时的阈值;然后计算测试集上给定阈值的frr与far,frr和far的均值即为hter指标。
[0077]
②
选择数据集:本算法在casia(简写为c)、oulu-npu(简写为o)、msu-mfsd(简写为m)和replay-attack(简写为r)四个公开的数据集,进行了跨数据集的测试。实验时,从四个公开数据集中随机选择三个作为源域(训练集),剩下的一个为目标域(测试集),因此得到了r&c&mtoo、o&c&rtom、o&m&rtoc和o&c&mtor四个跨数据集的实验方案。训练集中每个视频中随机选择一帧图像,而测试集中每个视频中随机选择两帧图像。
[0078]
③
软硬件参数设置:搭建实验硬件环境为nvdia geforce rtx 2080ti显卡,编程语言为python3.7,框架为pytorch。模型的输入采用人脸检测和对齐算法mtcnn进行了预处理,并且将输入大小为256
×
256
×
3的rgb图像随机裁剪为128
×
128
×
3。训练时,batch_size批大小设置为60,模型优化器为随机梯度下降(stochastic gradient descent,sgd),动量参数设置为0.9,权值衰减设为5e-4,初始学习率为0.001,每训练100轮后变为原来的0.1倍。
[0079]
(2)进行算法对比实验:
[0080]
①
与常用人脸活体检测算法的比较:本算法在跨数据集的四种实验方案(r&c&mtoo、o&c&rtom、o&m&rtoc和o&c&mtor)下,与现有常用的一些人脸活体检测算法:ms_lbp、binarycnn、ida、colortexture、lbp-top、auxiliary进行比较,实验结果如表1所示。
[0081]
表1本算法与现有常用人脸活体检测算法在四个公开数据集上的比较
[0082][0083][0084]
表1表明,相较于常用的人脸活体检测算法,本算法的检测精度最高,错误率最低。虽然目前常用的人脸活体检测算法在同一数据库内测试精度都很高,但是在跨数据库测试时精度下降,主要原因是这些方法没有对齐来自不同域的特征分布,没有提取不同域之间共同的模式,削弱了模型从源域到特定域特征的提取,无法削减不同数据库特征的差异。
[0085]
②
与其他域泛化人脸活体检测算法的比较
[0086]
在跨数据集的四种实验方案下,本算法与mmd-aae、maddg、ssdg-m等一些较优秀的域泛化算法做了比较,结果如表2所示。
[0087]
表2本算法与其他域泛化人脸活体检测算法的比较
[0088][0089]
由表2可知,与maddg比较,本算法的hter平均下降了13.6%,auc上升了11.4%,主要原因是maddg算法虽然采用多对抗和双重三元组最小化约束的思想提取了多个源域的共性特征,但它只是在特征上对齐了多个源域的数据分布,而忽略了类分布的对齐。本算法与ssdg-m算法比较,hter平均下降了11.6%,auc上升了7.7%,主要是因为ssdg算法没有考虑观测不准确样本的不利影响。本算法在上采样时将注意力机制嵌入u-net网络以提取更泛化的差异线索,添加类别信息作为条件,在特征和类分布上同时对齐多个源域的分布,并采用信息熵控制样本优先级,提高了跨场景活体检测模型的泛化性能。
[0090]
(3)为验证本算法的各个模块对整个模型的影响程度,开展了消融实验
[0091]
为了验证本算法的各个模块对整个模型的影响程度,实验中分别删去一些子模
块,包括注意力机制(w/o attention)、非对称三元组(w/o triplet)、域判别器(w/o ad)、多线性映射和熵调整(w/o multilinear&entropy)、深度损失(w/o depth)等,然后查看删除这些子模块后系统的性能,以此了解这些子模块对系统的作用,结果如表3所示。
[0092]
表3本算法在四个公开数据集上的消融实验
[0093][0094]
由表3可知,当去掉任何一个模块后,系统性能都会下降,这表明所有模块都有利于模型泛化性能的提高。相比于其他模块,非对称三元组和域判别器模块对系统性能的影响更大。例如,当casia和replay-attack作为测试集时,去掉域判别器模块,将导致hter分别上升9.9%和10.3%,去掉三元组模块后,hter分别上升14.0%和11.5%。去掉多线性映射后模型的hter分别上升6.7%和6.0%,auc分别下降5.8%和4.4%。其主要原因是本算法不仅对齐了多个源域的特征分布,而且通过多线性映射的方法添加了基于类别的语义信息,在类层面对齐了多个源域的分布,使得模型的泛化性能更好。此外,通过添加非对称三元组损失作为辅助监督可以获得更好的分类边界。
[0095]
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。