1.本发明涉及网络控制技术领域,特别涉及一种社交辟谣用户交流平台系统。
背景技术:
2.当今社会互联网飞速发展,由于不受时间、空间的影响,其海量信息的传输能力给人们的工作和生活带来极大便利。然而,在我们享受互联网带来的便利的同时,网络谣言的广泛传播阻碍了人们获得可靠信息的途径,尽管政府和各大网络平台都采取了相应的措施以防谣言的出现,但是由于监管不到位、信息发布不及时等原因,谣言问题仍层出不穷。
3.如今社交媒体上的谣言已成为一个严肃的关注点,谣言的识别不仅为控制谣言传播提供了前提,也有助于发现现实生活中人们所关心的问题和潜在的社会现象或社会问题,同时,谣言识别对金融市场、紧急事务处理以及社交媒体上的信息质量等都能产生积极作用。
技术实现要素:
4.本发明要解决的技术问题是克服现有技术的缺陷,提供一种社交辟谣用户交流平台系统。
5.为了解决上述技术问题,本发明提供了如下的技术方案:
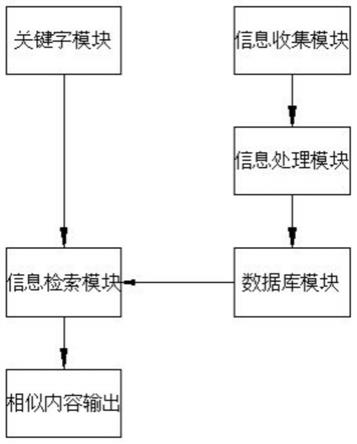
6.本发明一种社交辟谣用户交流平台系统,包括检索系统和交流系统,其特征在于,所述检索系统包含有关键字模块、信息检索模块、信息收集模块、信息处理模块和数据库模块,具体包括如下步骤:
7.a.利用网络爬虫技术或通过网络api平台获取数据源,形成信息收集模块;
8.b.将步骤a信息收集模块所收集的信息置入信息处理模块内,进行预处理;
9.c.使预处理后的信息处理模块的信息置入数据库模块中,并根据数据库内的模型进行分类处理;
10.d.在关键字模块中输入目标字符串,并置入信息检索模块;
11.e.信息检索模块将目标字符串在步骤c中的数据库模块内检索,最后输出相似内容。
12.作为本发明的一种优选技术方案,所述信息处理模块包含有抽取和去噪算法,所述去噪算法的处理方式包括有正态分布3σ原则,用于复杂数据转化为单一构型后,将没有意义的字符进行过滤。
13.作为本发明的一种优选技术方案,所述数据库模块包含有lda模型算法,用于将步骤c中已预处理的信息进行分类,所述步骤c包括:
14.c1.利用lda模型算法将信息处理模块信息形成有序词组序列,如d=(m1,m2,
……
,mn);
15.c2.将有序序列d分为多份(1~sn),从1开始依次取一份数据作为测试数据,其他s
n-1份数据作为训练数据,将多份序列中的元素mn单个提取进行分别训练,直至形成n个模
型,每个模型具有自身的超参数;
16.c3.采用贝叶斯算法对超参数进行优化;
17.c4.通过n次训练测试,得到了n个超参数,将n个超参数组中选取多组识别正确率高的值,对每个超参数取平均值,得到最后的超参数值k,将k置入信息检索模块内。
18.作为本发明的一种优选技术方案,所述信息检索模块包含有dssm算法,用于在数据库模块进行字符匹配检索,所述步骤e包含有:
19.e1.接收用户输入的目标串t,将目标串在数据莫模块内匹配长度相同的字符串s;
20.e2.将目标串t形成如步骤c1中的有序词组序列,将目标串t可形成的有序词组序列进行匹配提取;
21.e3.将e2中的步骤进行k次编辑操作后,将得到集合h,取集合h中k最小字符串,自上而下排列输出。
22.与现有技术相比,本发明的有益效果如下:
23.本发明通过设置数据库和检索模块,能够方便使用者在输入关键字后,可自行在抓取后的数据库内检索相应的信息,并显示出与关键字有关的谣言信息,同时可能够指向性的标识信息来源,更真实的显示谣言信息动态。
附图说明
24.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
25.图1是本发明的整体模块结构示意图;
26.图2是本发明的数据库模块流程图;
27.图3是本发明的信息检索模块流程图;
具体实施方式
28.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
29.实施例1
30.如图1-3所示,本发明提供一种社交辟谣用户交流平台系统,包括检索系统和交流系统,其特征在于,所述检索系统包含有关键字模块、信息检索模块、信息收集模块、信息处理模块和数据库模块,具体包括如下步骤:
31.a.利用网络爬虫技术或通过网络api平台获取数据源,形成信息收集模块;
32.b.将步骤a信息收集模块所收集的信息置入信息处理模块内,进行预处理;
33.c.使预处理后的信息处理模块的信息置入数据库模块中,并根据数据库内的模型进行分类处理;
34.d.在关键字模块中输入目标字符串,并置入信息检索模块;
35.e.信息检索模块将目标字符串在步骤c中的数据库模块内检索,最后输出相似内容。
36.进一步的,信息处理模块包含有抽取和去噪算法,所述去噪算法的处理方式包括有正态分布3σ原则,用于复杂数据转化为单一构型后,将没有意义的字符进行过滤。
37.数据库模块包含有lda模型算法,用于将步骤c中已预处理的信息进行分类,步骤c包括:
38.c1.利用lda模型算法将信息处理模块信息形成有序词组序列,如d=(m1,m2,
……
,mn);
39.c2.将有序序列d分为多份(1~sn),从1开始依次取一份数据作为测试数据,其他s
n-1份数据作为训练数据,将多份序列中的元素mn单个提取进行分别训练,直至形成n个模型,每个模型具有自身的超参数;
40.c3.采用贝叶斯算法对超参数进行优化;
41.c4.通过n次训练测试,得到了n个超参数,将n个超参数组中选取多组识别正确率高的值,对每个超参数取平均值,得到最后的超参数值k,将k置入信息检索模块内。
42.信息检索模块包含有dssm算法,用于在数据库模块进行字符匹配检索,步骤e包含有:
43.e1.接收用户输入的目标串t,将目标串在数据莫模块内匹配长度相同的字符串s;
44.e2.将目标串t形成如步骤c1中的有序词组序列,将目标串t可形成的有序词组序列进行匹配提取;
45.e3.将e2中的步骤进行k次编辑操作后,将得到集合h,取集合h中k最小字符串,自上而下排列输出。
46.具体的,检索系统首先通过网络爬虫技术收集网络中的文本信息,随后将文本进行经由信息处理模块进行预处理,处理过程中首先采用抽取方式,因为获取的数据可能具有多种结构和类型,数据的抽取过程可以将这些复杂的数据转化为单一的或者便于处理的构型,以达到快速分析处理的目的,随后利用正太分布3σ原则对单一构型的信息进行去噪,删去无意义的数据,仅保留有用的信息。
47.随后将处理后的信息置入数据库模块中进行分类,数据库模块主要利用lda模型和贝叶斯算法将提取的数据将用于训练lda模型,为了观察谣言识别的正确性,使数据分成多份(1~sn),从1开始依次取一份数据作为测试数据,其他s
n-1份数据作为训练数据,因此我们会训练n个模型,每个模型都有自己的超参数值,然后根据贝叶斯算法对多个超参数值进行调参,最后从中选取多组识别正确率高的值,对每个超参数取平均值,得到最后的超参数值,输出超参数k,并建立正常运行的数据库模块。
48.在使用者使用检索系统时,主要在关键字模块上输入需要检索的信息,关键字模块将信息置入信息检索模块中形成字符串,经信息检索模块将整个字母串置入数据库模块中对比和匹配相同字数的文字,从而形成初匹配效果,随后再次根据不同词组的组合编辑形成关键词匹配,根据数据库模块中lda模型分组产生关键字识别匹配,最后将匹配完毕的集合形成h集,以编辑的次数由小达到在输出端显示,从而达到实时显示的效果,而数据库模块所匹配的内容则设置有信息收集模块所标注的来源信息,能够指向性的寻找到信息源头,使整体检索框架能够更具有即时性和追溯性。
49.最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的
保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。