一种基于生成对抗网络的ethernet/ip协议模糊测试方法
技术领域
1.本技术属于ethernet/ip协议测试及漏洞挖掘技术领域,具体涉及一种基于生成对抗网络的ethernet/ip协议模糊测试方法。
背景技术:
2.工业控制系统广泛分布于工业、能源、电力、水利、交通等关键基础设施领域,通信协议作为工业控制系统中操作指令传送的载体,其重要性不言而喻。因此,如何有效地挖掘通信协议的潜在漏洞,提高通信协议的抗攻击能力,对于提升工业控制系统的安全性至关重要。
3.工业控制系统的通信协议种类很多,其中,ethernet/ip协议是一种广泛应用于交通、能源等行业工控系统中的通信协议,保证ethernet/ip协议的安全通信是保障工控系统安全运行的基石。
4.模糊测试是一种通过向目标程序提供大量非预期的输入并监视异常结果来发现潜在漏洞的方法,该技术的核心在于如何构造有效的测试数据(输入的非预期数据)。当前测试数据的构造方法主要有两种:1)基于变异的构造方法:通过对输入数据进行针对性的变异,然后将变异后的数据输入到工控系统以触发漏洞;2)基于生成的构造方法:根据已知的协议规则定义测试数据格式,从无到有的生成测试数据。但当前的工控协议模糊测试方法依旧存在一些不足之处:1)测试用例大多依靠人工分析和设计,不仅耗时耗力,而且测试用例质量完全依赖于人的先验知识,因此测试用例的通过率和路径覆盖率参差不齐。2)当前的测试用例生成方法主要根据已公开的漏洞知识库进行构造,对于新漏洞的挖掘有一定的局限性,且在已有的公开漏洞知识库中(包括cnvd,cnnvd,cve等),ethernet/ip协议漏洞非常有限。
技术实现要素:
5.为了解决现有技术中存在的至少一个技术问题,本技术提供了一种基于生成对抗网络的ethernet/ip协议模糊测试方法。
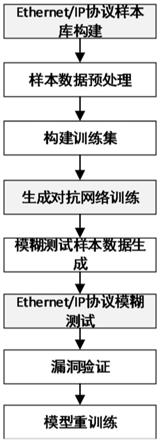
6.本技术公开了一种基于生成对抗网络的ethernet/ip协议模糊测试方法,包括如下步骤:
7.步骤一、构建ethernet/ip协议样本库;
8.步骤二、对ethernet/ip协议样本库中的通信数据包进行处理,得到10进制ethernet/ip协议样本数据;
9.步骤三、利用步骤二处理后的ethernet/ip协议样本数据,并通过多种不同的聚类构建方法来构造对应种类的训练集;
10.步骤四、利用不同种类的训练集分别进行生成对抗网络训练;
11.步骤五、生成模糊测试样本数据,其中,所述模糊测试样本数据中包括多个测试用例;
12.步骤六、将模糊测试样本数据中的所有测试用例逐一输入到工控系统中进行ethernet/ip协议模糊测试,如果某一测试用例引起工控系统运行异常,则记录该测试用例为异常测试用例,最后形成异常测试用例集;
13.步骤七、将异常测试用例集中的所有异常测试用例再次逐一输入到工控系统中进行ethernet/ip协议模糊测试,人工校验每一个异常测试用例引起的工控系统运行异常是否属于误报,如果属于误报,则将该测试用例从异常测试用例集中删除,如果该异常测试用例再次引起异常,则确认该用例为异常测试用例,并记录该异常测试用例及其引起的漏洞情况。
14.根据本技术的至少一个实施方式,所述的ethernet/ip协议模糊测试方法还包括:
15.步骤八、将步骤七最终记录的所有异常测试用例的数据复制后随机进行数值取反或随机取值的数据变异操作,再将变异后的异常测试用例数据返回至步骤四、步骤五,从而生成更易触发ethernet/ip协议漏洞的模糊测试样本数据。
16.根据本技术的至少一个实施方式,在所述步骤一中,是采用人工采集的方式,使用wireshark抓包工具从工控系统中抓取ethernet/ip协议通信数据包,从而得到ethernet/ip协议样本库。
17.根据本技术的至少一个实施方式,在所述步骤二中,是对ethernet/ip协议样本库中的通信数据包进行解析,去除其他协议首部,自动提取16进制的ethernet/ip协议样本数据,再将16进制的ethernet/ip协议样本数据逐比特转换为10进制。
18.根据本技术的至少一个实施方式,在所述步骤三中,多种不同的聚类构建方法包括:
19.按照消息长度分类构建:根据不同的消息长度,将ethernet/ip协议样本数据分成不同的训练集,并对较小的训练集进行数据扩增;
20.按照功能码分类构建:根据ethernet/ip协议功能码种类,构建与不同的功能码相对应的训练集,再分别对不同训练集中的数据进行对齐填充;
21.混合构建:将所有ethernet/ip协议样本数据作为一个训练数据集。
22.根据本技术的至少一个实施方式,所述按照消息长度分类构建方法中,数据扩增包括:
23.将较小训练集中的数据进行复制,再对复制的数据进行特定索引位的数值翻转、数值取反或随机取值的数据变异操作。
24.根据本技术的至少一个实施方式,所述按照功能码分类构建方法中,功能码种类包括8种,并通过如下关系式(1)对不同训练集中的数据进行对齐填充:
[0025][0026]
其中,s0为任意一条原始消息,len()为长度函数,maxlen为当前训练集中消息的最大长度,x为填充字符且x=
′
pad
′
;
[0027]
当len(s0)=maxlen时,说明原始数据不需要填充,将原始数据s0保留在训练集中;
[0028]
当len(s0)《maxlen时,说明原始数据需要填充,填充长度为n=maxlen-len(s0),将原始数据s0从训练集中去除,并将填充后的消息s1加入到训练集中。
[0029]
根据本技术的至少一个实施方式,在所述步骤四中,选择长短期记忆网络lstm作为生成器模型网络,选择卷积神经网络cnn作为判别器模型网络,并采用dropout避免模型过拟合,其中,生成对抗网络训练具备包括:
[0030]
步骤4.1、初始化lstm生成器和cnn判别器网络参数;
[0031]
步骤4.2、将训练集数据输入lstm生成器的输入层,输入层再将数据输入嵌入层和隐藏层,初步学习训练数据的特征分布,并更新lstm生成器的权重参数;
[0032]
步骤4.3、用步骤4.2得到的lstm生成器生成负样本数据,再将真实数据作为正样本数据,利用这些数据训练一个二分类cnn判别器,初步学习区分生成数据与真实数据,并更新cnn判别器的权重参数;
[0033]
步骤4.4、循环对抗训练lstm生成器和cnn判别器。
[0034]
根据本技术的至少一个实施方式,在所述步骤4.4中,循环对抗训练lstm生成器包括:
[0035]
步骤4.51、循环训练lstm生成器,并生成序列数据;
[0036]
步骤4.52、将生成的序列数据输入到cnn判别器,获得相应的奖励reward;
[0037]
步骤4.53、利用policy gradient算法将reward传递给lstm生成器,实现对lstm生成器权重参数的更新;
[0038]
循环对抗训练cnn判别器包括:
[0039]
步骤4.61、利用更新后的lstm生成器生成的负样本数据与真实样本数据集循环训练cnn判别器;
[0040]
步骤4.62、更新权重参数,直到模型收敛。
[0041]
根据本技术的至少一个实施方式,所述步骤五中,生成模糊测试样本数据包括:
[0042]
步骤5.1、在所述步骤4.4的循环对抗训练lstm生成器和cnn判别器过程中,每5个训练周期保存一次lstm生成器模型;
[0043]
步骤5.2、将一次完整的生成对抗训练过程中保存的生成器模型,按照保存时间先后进行排列,并按照1:7:2的比例将生成器模型分为早期模型、中期模型和后期模型;
[0044]
步骤5.3、按照同比例抽取三种不同时期的生成器模型生成的ethernet/ip协议数据作为模糊测试样本数据。
[0045]
本技术至少存在以下有益技术效果:
[0046]
1)本技术的基于生成对抗网络的ethernet/ip协议模糊测试方法中,利用生成对抗网络自主地学习并生成高质量的模糊测试用例,减少了模糊测试过程中协议分析和用例构造的人力,实现了高效智能的模糊测试;
[0047]
2)本技术的基于生成对抗网络的ethernet/ip协议模糊测试方法中,采用了多种不同的聚类策略对协议样本进行分类构建,可以使生成模型生成更多样化和更规范的测试用例,从而增加其路径覆盖率,从而更有利于触发ethernet/ip协议更多的潜在漏洞,提高工控系统的安全性和抗攻击能力;
[0048]
3)本技术的基于生成对抗网络的ethernet/ip协议模糊测试方法中,提出了按比例抽取模糊测试样本数据的方法。将保存的生成器模型按时间先后分为早期、中期和后期模型,并按照特定比例抽取生成的模糊测试样本,仅抽取了少量的早期模型和后期模型的生成数据,很好的平衡了模糊测试中测试用例的通过率和随机性,从而解决模糊测试中测
试用例通过率与随机性的balance问题;
[0049]
4)本技术的基于生成对抗网络的ethernet/ip协议模糊测试方法生成的测试用例具有较高的通过率和漏洞检测率。
附图说明
[0050]
图1是本技术基于生成对抗网络的ethernet/ip协议模糊测试方法的流程图。
具体实施方式
[0051]
为使本技术实施的目的、技术方案和优点更加清楚,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行更加详细的描述。所描述的实施例是本技术一部分实施例,而不是全部的实施例。下面通过参考附图描述的实施例是示例性的,旨在用于解释本技术,而不能理解为对本技术的限制。
[0052]
如图1所示,本技术公开了一种基于生成对抗网络的ethernet/ip协议模糊测试方法,包括如下步骤:
[0053]
步骤一(ethernet/ip协议样本库构建):构建ethernet/ip协议样本库。
[0054]
具体的,本步骤是采用人工采集的方式,使用wireshark抓包工具从工控系统中充分抓取ethernet/ip协议通信数据包,从而得到完备的ethernet/ip协议样本库。
[0055]
步骤二(样本数据预处理):对ethernet/ip协议样本库中的通信数据包进行处理,得到10进制ethernet/ip协议样本数据。
[0056]
具体的,本步骤是对ethernet/ip协议样本库中的通信数据包进行解析,去除其他协议首部,自动提取16进制的ethernet/ip协议样本数据,再进行进制转换操作,将16进制的ethernet/ip协议样本数据逐比特转换为10进制。
[0057]
步骤三(构建训练集):利用步骤二处理后的ethernet/ip协议样本数据,并通过多种不同的聚类构建方法来构造对应种类的训练集。
[0058]
具体的,本步骤中的聚类构建方法包括如下三种:
[0059]
1)按照消息长度分类构建:根据不同的消息长度,将预处理后的协议数据分成不同的训练集,并对较小的训练集进行数据扩增,增加这部分训练集的影响力;该构建方法在保证数据随机性的同时保障了生成测试用例的相似性,从而增加了测试用例的通过率。
[0060]
其中,数据扩增方法是指:将较小训练集中的数据进行复制,之后对复制的数据进行特定索引位的数值翻转、数值取反或随机取值等数据变异操作,从而实现小数据集的数据扩增。
[0061]
2)按照功能码分类构建:根据ethernet/ip协议功能码种类,构建与不同的功能码相对应的训练集,再分别对不同训练集中的数据进行对齐填充。需要说明的是,这样的构建方法可以充分测试ethernet/ip协议各功能的健壮性。
[0062]
本实施例中,除去ethernet/ip协议的保留字段,ethernet/ip协议共有8种功能码,如下表1所示,根据不同的功能码构建8个不同的训练集:
[0063]
表1 ethernet/ip功能码
[0064]
代码名称功能0x0000noptcp开放探测
0x0004listservices列表服务0x0063listidentity列表标识0x0064listinterfaces列表接口0x0065registersession注册会话0x0066unregistersession终止会话0x006fsendrrdata发送封装包0x0070sendunitdata发送单元数据
[0065]
进一步,本步骤中是通过如下关系式(1)对不同训练集中的数据进行对齐填充(即根据关系式(1)对原始数据s0进行对齐填充得到新的数据s1):
[0066][0067]
其中,s0为任意一条原始消息,len()为长度函数,maxlen为当前训练集中消息的最大长度,x为填充字符且x=
′
pad
′
;
[0068]
当len(s0)=maxlen时,说明原始数据不需要填充,将原始数据s0保留在训练集中;
[0069]
当len(s0)《maxlen时,说明原始数据需要填充,填充长度为n=maxlen-len(s0),将原始数据s0从训练集中去除,并将填充后的消息s1加入到训练集中。
[0070]
3)混合构建:将所有ethernet/ip协议样本数据作为一个训练数据集,充分发挥模糊测试的随机性,使得生成的测试用例具有更高的覆盖率。
[0071]
步骤四(生成对抗网络训练):利用不同种类的训练集分别进行生成对抗网络训练。
[0072]
具体的,本步骤中根据ethernet/ip工控协议帧格式固定和强时序性等特点,选择长短期记忆网络(lstm)作为生成器模型网络,选择卷积神经网络(cnn)作为判别器模型网络,并采用dropout避免模型过拟合。
[0073]
另外,本技术构建的lstm生成器包含两个隐藏层、一个输出层,其中两个隐藏层每层由64个隐状态组成,输出层采用全连接的方式并采用softmax作为激活函数;cnn判别器网络层次结构依次为embedding层、卷积层、池化层、dropout层、输出层,同样,输出层采用全连接的方式并采用sigmoid作为激活函数。
[0074]
进一步的,本步骤中的生成对抗网络训练具备包括如下步骤:
[0075]
步骤4.1:初始化lstm生成器和cnn判别器网络参数;
[0076]
步骤4.2(预训练lstm生成器):将训练集数据输入lstm生成器的输入层,输入层再将数据输入嵌入层和隐藏层,初步学习训练数据的特征分布,并更新lstm生成器的权重参数;
[0077]
步骤4.3(预训练cnn判别器):用步骤4.2得到的lstm生成器生成负样本数据,再将真实数据作为正样本数据,利用这些数据训练一个二分类cnn判别器,初步学习区分生成数据与真实数据,并更新cnn判别器的权重参数;
[0078]
步骤4.4:循环对抗训练lstm生成器和cnn判别器。
[0079]
更进一步的,上述步骤4.4中的循环对抗训练lstm生成器又包括如下步骤:
[0080]
步骤4.51、循环训练lstm生成器,并生成序列数据;
[0081]
步骤4.52、将生成的序列数据输入到cnn判别器,获得相应的奖励reward;
[0082]
步骤4.53、利用policy gradient算法将reward传递给lstm生成器,实现对lstm生成器权重参数的更新;
[0083]
相应的,循环对抗训练cnn判别器又包括如下步骤:
[0084]
步骤4.61、利用更新后的lstm生成器生成的负样本数据与真实样本数据集循环训练cnn判别器;
[0085]
步骤4.62、更新权重参数,直到模型收敛。
[0086]
步骤五(模糊测试样本数据生成):生成模糊测试样本数据,其中,模糊测试样本数据中包括多个测试用例。
[0087]
需要说明的是,经过上述步骤四的生成对抗网络训练后,会得到不同的训练好的lstm生成器,如果仅利用最后训练好的lstm生成器生成测试用例,可以保证生成的测试用例与真实的ethernet/ip通信数据具有较高的相似性,即可以保证生成的测试用例具有较高的通过率;然而这却与模糊测试的理念(输入大量的非预期数据以触发漏洞)背道而驰,训练得较好的lstm生成器生成的测试用例不能充分发挥出模糊测试的非预期性和随机性,从而涉及到模糊测试中测试用例通过率与随机性的balance问题。
[0088]
为此,在本步骤中,生成模糊测试样本数据包括如下步骤:
[0089]
步骤5.1、在步骤4.4的循环对抗训练lstm生成器和cnn判别器过程中,每5个训练周期保存一次lstm生成器模型;
[0090]
步骤5.2、将一次完整的生成对抗训练过程中保存的生成器模型,按照保存时间先后进行排列,并按照1:7:2的比例将生成器模型分为早期模型、中期模型和后期模型;
[0091]
步骤5.3、按照同比例抽取三种不同时期的生成器模型生成的ethernet/ip协议数据作为模糊测试样本数据。
[0092]
综上,由于不同时刻的生成器模型拥有不同的训练程度,所以其生成的测试用例与真实的通信数据具有不同程度的差异,因此整个测试用例集可以维持一个很好的多样性和随机性。
[0093]
并且,因为早期模型仅仅训练了5轮,拟合效果较差,为了保证测试用例的通过率,仅在早期模型生成的ethernet/ip协议数据中抽取了1成作为最后的模糊测试样本;同样地,因为后期模型经过多轮的迭代训练后,能够生成与真实ethernet/ip通信数据相似度较高的测试用例,为了保证测试用例的随机性,仅在后期模型生成的ethernet/ip协议数据中抽取了2成作为最后的模糊测试样本;剩余的7成模糊测试样本都在中期模型生成的ethernet/ip协议数据中抽取。本技术的上述方法创新性地采用的按上述比例生成模糊测试样本数据的方法,能够很好的平衡模糊测试中测试用例的通过率和随机性。
[0094]
步骤六(ethernet/ip协议模糊测试):将模糊测试样本数据中的所有测试用例逐一输入到工控系统中进行ethernet/ip协议模糊测试,如果某一测试用例引起工控系统运行异常,则记录该测试用例为异常测试用例,最后形成异常测试用例集。
[0095]
具体地,本步骤中采用python脚本进行ethernet/ip协议模糊测试模块的封装。首先将生成的10进制的模糊测试样本数据转换为16进制的模糊测试用例,之后利用socket.send()命令将模糊测试用例发送到工控系统,并利用ping命令监控工控系统的运行状态,同时利用socket.recvfrom()命令接收工控系统的返回命令,解析返回状态码,若
返回数据包的状态码不为0x0000(成功),则记录该模糊测试用例和相应的状态码,之后用于计算测试用例的通过率以评估生成模型的优劣。若该模糊测试用例引起工控系统运行异常(包括宕机、通信中断、程序崩溃、逻辑异常等)或者解析到返回数据包中包含error、exception等信息,则记录该测试用例为异常测试用例,最后形成一个异常测试用例集。
[0096]
步骤七(漏洞验证):将异常测试用例集中的所有异常测试用例再次逐一输入到工控系统中进行ethernet/ip协议模糊测试,人工校验每一个异常测试用例引起的工控系统运行异常是否属于误报,如果属于误报,则将该测试用例从异常测试用例集中删除,如果该异常测试用例再次引起异常,则确认该用例为异常测试用例,并记录该异常测试用例及其引起的漏洞情况。
[0097]
进一步,本技术的基于生成对抗网络的ethernet/ip协议模糊测试方法还可以包括如下步骤:
[0098]
步骤八(模型重训练):将步骤七最终记录的所有异常测试用例的数据复制后随机进行数值取反或随机取值等数据变异操作,再将变异后的异常测试用例数据返回至步骤四、步骤五;其中,变异后的异常测试用例数据在步骤四生成对抗网络中作为训练数据集,调整模型参数,利用新的数据集重训练生成对抗网络模型,从而在步骤五生成更易触发ethernet/ip协议漏洞的模糊测试样本数据。
[0099]
与之前的步骤四生成对抗网络训练过程中不同的是,步骤四最开始是将正常的经过预处理和聚类之后的ethernet/ip协议数据作为训练数据集;而在模型重训练过程中,步骤四是将经过复制和变异后的异常测试用例数据作为训练数据集。
[0100]
与之前的步骤五模糊测试样本数据生成过程中不同的是,最开始的步骤五为了平衡模糊测试中测试用例的通过率和随机性,需要根据比例抽取按照保存时间先后进行排列的生成模型,并按照同比例生成模糊测试样本数据;而在模型重训练过程中,为了让模型能够充分学习异常测试用例的特征,生成与异常测试用例更相似的模糊测试样本数据,步骤五使用最后一轮训练周期训练后保存的lstm生成器模型生成重训练的测试样本。
[0101]
综上所述,本技术利用生成对抗网络自主学习并生成高质量的模糊测试用例,从而有效减少模糊测试过程中协议分析和用例构造的人力消耗,实现高效、智能化的模糊测试。同时,本技术通过创新性地引入不同的聚类策略,提高生成测试用例的多样性,增加路径覆盖率,从而更有利于触发ethernet/ip协议更多的潜在漏洞,提高工控系统的安全性和抗攻击能力。此外,本技术通过引入按照比例抽取模糊测试样本的思想,解决了模糊测试中测试用例通过率与随机性的balance问题。
[0102]
以上所述,仅为本技术的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应以所述权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。