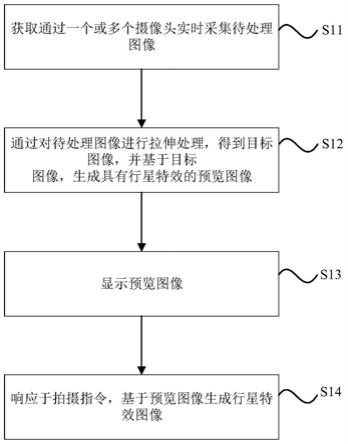
1.本技术涉及基于块的预测的领域。实施例涉及用于确定预测向量的有利的方式。
背景技术:
2.现今存在不同的基于块的内预测(intra predection)和间预测(inter prediction)模式。邻近的待预测的块的样本或者从其他图像获得的样本可以形成样本向量,其可以经历矩阵乘法以确定用于待预测的块的预测信号。
3.矩阵乘法应优选地以整数算术执行,并且应将通过某种基于机器学习的训练算法导出的矩阵用于矩阵乘法。
4.然而,这种训练算法通常仅产生以浮点精确度给定的矩阵。因此,面临以下问题:要指定整数运算,以便这些整数运算被良好地用于近似矩阵乘法,和/或实现计算效率的改良,和/或在实施方面使预测更有效。
技术实现要素:
5.这是通过本技术的独立技术方案的主题来达成的。
6.根据本发明的其他实施例是由本技术的从属权利要求的主题限定的。
7.根据本发明的第一方面,本技术的发明人意识到当尝试通过编码器或者解码器确定预测向量时遇到的一个问题是可能缺少使用整数算术来计算用于预定块的预测向量。根据本技术的第一方面,该困难是通过从样本值向量导出另一向量来解决的,所述样本值向量通过预定可逆线性变换而被映射到所述另一向量上,使得样本值向量不直接应用于计算预测向量的矩阵向量乘积。代之以,计算另一向量与预定预测矩阵之间的矩阵向量乘积以计算预测向量。举例而言,另一向量被导出使得可以通过所述装置使用整数算术运算和/或定点算术运算来预测预定块的样本。这是基于以下想法:样本值向量的分量是相关的,其中可以使用有利的预定可逆线性变换例如以获得具有主要为较小项的另一向量,从而使得能够使用整数矩阵和/或具有定点值的矩阵和/或具有较小的预期量化错误的矩阵作为预定预测矩阵。
8.因此,根据本技术的第一方面,一种用于使用多个参考样本预测图像的预定块的装置被配置为从多个参考样本形成样本值向量。举例而言,所述参考样本为邻近内预测处的预定块的样本或者间预测处的另一图像中的样本。根据一实施例,例如,可以通过平均来缩减参考样本以获得具有经缩减数目的值的样本值向量。此外,所述装置被配置为:从样本值向量导出另一向量,所述样本值向量通过预定可逆线性变换而被映射到另一向量上;计算另一向量与预定预测矩阵之间的矩阵向量乘积以获得预测向量;以及基于预测向量预测预定块的样本。基于另一向量,预定块的样本的预测可以表示样本值向量与矩阵之间的直接矩阵向量乘积的整数近似以获得预定块的经预测样本。
9.样本值向量与矩阵之间的直接矩阵向量乘积可以等于另一向量与第二矩阵之间的第二矩阵向量乘积。第二矩阵和/或矩阵例如为机器学习预测矩阵。根据一实施例,第二
矩阵可以基于预定预测矩阵和整数矩阵。举例而言,第二矩阵等于预定预测矩阵与整数矩阵的总和。换言之,另一向量与第二矩阵之间的第二矩阵向量乘积可以由另一向量与预定预测矩阵之间的矩阵向量乘积和整数矩阵与另一向量之间的另一矩阵向量乘积来表示。举例而言,整数矩阵为具有由一组成的预定列i0和为零的列i≠i0的矩阵。因此,可以通过所述装置来实现第一和/或第二矩阵向量乘积的良好整数近似和/或良好定点值近似。这是基于以下想法:预定预测矩阵可以被量化,或者是经量化的矩阵,这是由于另一向量主要包括较小的值,从而导致第一和/或第二矩阵向量乘积的近似中的可能量化错误的轻微影响。
10.根据一实施例,可逆线性变换乘以预定预测向量与整数矩阵的总和可以对应于机器学习预测矩阵的经量化版本。举例而言,整数矩阵是具有由一组成的预定列i0和为零的列i≠i0的矩阵。
11.根据一实施例,可逆线性变换被限定为使得另一向量的预定分量变为a,且另一向量的除了预定分量之外的其他分量中的每一个等于样本值向量的对应分量减去a,其中a为预定值。因此,可以实现具有较小值的另一向量,从而使得能够量化预定预测矩阵,并且产生预定块的经预测样本中的量化错误的轻微影响(marginal impact)。在此另一向量的情况下,有可能通过整数算术运算和/或定点算术运算预测预定块的样本。
12.根据一实施例,预定值为样本值向量的分量的平均值(诸如算术平均值或者加权平均值)、默认值、在图像编码而成的数据流中用信号通知的值、以及样本值向量的对应于预定分量的分量中的一项。举例而言,样本值向量包括多个参考样本或者多个参考样本之中的各组参考样本的平均值。举例而言,一组参考样本包括至少两个参考样本,优选地为相邻参考样本。
13.举例而言,预定值为样本值向量的一些分量(例如,至少两个分量)或者样本值向量的所有分量的算术平均值或者加权平均值。这是基于以下想法:样本值向量的分量是相关的,亦即分量的值可以是类似的和/或分量中的至少一些可以具有相等值,其中另一向量的分量不等于另一向量的预定分量,亦即i≠i0的分量i,其中i0表示预定分量,可能具有小于样本值向量的对应分量的绝对值。因此,可以实现具有较小值的另一向量。
14.预定值可以是默认值,其中默认值例如选自默认值的列表或者对于所有块大小、预测模式等等是相同的。默认值的列表的分量可以与不同块大小、预测模式、样本值向量大小、样本值向量的值的平均值等等相关联。因此,例如,取决于预定块,亦即取决于与预定块相关联的解码或者编码设置,经优化的默认值是由所述装置从默认值的列表中选择的。
15.替代地,预定值可以是在图像编码而成的数据流中用信号通知的值。在此情形下,例如,用于编码的装置确定预定值。预定值的确定可以基于与如上文在默认值的上下文中所描述相同的考虑。
16.另一向量的分量不等于另一向量的预定分量,亦即i≠i0的分量i,其中i0表示预定分量,所述另一向量的所述分量具有例如小于样本值向量的对应分量的绝对值,其中使用默认值或者在数据流中用信号通知的值作为预定值。
17.根据一实施例,所述预定值可以是样本值向量的对应于预定分量的分量。换言之,通过应用可逆线性变换,样本值向量的对应于预定分量的分量的值不会改变。因此,样本值向量的对应于预定分量的分量的值等于例如另一向量的预定分量的值。
18.预定分量例如是默认选择的,如例如上文关于作为默认值的预定值所描述。清楚
的是,可以通过替代过程选择预定分量。预定分量例如被选择为类似于预定值。根据一实施例,选择预定分量使得样本值向量的对应分量的值等于或者仅具有与样本值向量的值的平均值的轻微偏差。
19.根据一实施例,预定预测矩阵的在预定预测矩阵的一列内的与另一向量的预定分量对应的矩阵分量均为零。所述装置被配置为通过计算通过舍弃列(亦即由零组成的列)而从预定预测矩阵产生的经缩减预测矩阵与通过舍弃预定分量而从另一向量产生的又一向量之间的矩阵向量乘积的方式执行乘法,来计算矩阵向量乘积,亦即另一向量与预定预测矩阵之间的矩阵向量乘积。这是基于以下想法:另一向量的预定分量被设置为预定值,并且如果样本值向量的值是相关的,则此预定值精确地是用于预定块的预测信号中的样本值或者接近于该样本值。因此,预定块的样本的预测是可选地基于预定预测矩阵乘以另一向量,或者实际上是基于经缩减预测矩阵乘以又一向量以及整数矩阵乘以另一向量,所述整数矩阵的对应于预定分量的列i0由一组成,且所述整数矩阵的所有其他列i≠i0是零。换言之,经变换机器学习预测矩阵例如通过预定可逆线性变换的逆变换可以基于另一向量拆分成预定预测矩阵或者实际上经缩减预测矩阵和整数矩阵。因此,仅预测矩阵应被量化以获得机器学习预测矩阵和/或经变换机器学习预测矩阵的整数近似,这是有利的,这是由于又一向量不包括预定分量且所有其他分量具有比样本值向量的对应分量小得多的绝对值,从而允许机器学习预测矩阵和/或经变换机器学习预测矩阵的所得量化中的量化错误的轻微影响。此外,在经缩减预测矩阵和又一向量的情况下,几乎不需要执行乘法来获得预测向量,从而降低复杂性并且产生较高计算效率。可选地,所有分量均为预定值的向量可以在预测预定块的样本时添加至预测向量。如上文所描述,可以通过整数矩阵与另一矩阵之间的矩阵向量乘积来获得此向量。
20.根据一实施例,通过将预定预测矩阵的在预定预测矩阵的一列内的与另一向量的预定分量对应的每一矩阵分量与一进行求和而产生的矩阵乘以预定可逆线性变换对应于机器学习预测矩阵的经量化版本。预定预测矩阵的在预定预测矩阵的一列内的与另一向量的预定分量对应的每一矩阵分量与一进行求和表示例如经变换的机器学习预测矩阵。经变换的机器学习预测矩阵表示例如通过预定可逆线性变换的逆变换而变换的机器学习预测矩阵。所述求和可以对应于预定预测矩阵与整数矩阵的求和,所述整数矩阵的对应于预定分量的列i0由一组成且其所有其他列i≠i0是零。
21.根据一实施例,所述装置被配置为使用预测参数来表示预定预测矩阵,并且通过对另一向量的分量和预测参数以及从其产生的中间结果执行乘法以及求和来计算矩阵向量乘积。预测参数的绝对值可以通过n位定点数表示来表示,其中n是等于或者低于14,或者替代地等于或者低于10,或者替代地等于或者低于8。换言之,预测参数乘以矩阵向量乘积的元素(如另一向量、预定预测矩阵和/或预测向量)和/或与其进行求和。通过乘法以及求和运算,可以获得例如预定预测矩阵、预测向量和/或预定块的经预测样本的定点格式。
22.根据本发明的实施例涉及一种用于对图像进行编码的装置,包括根据本文中所描述的实施例中的任一个的用于使用多个参考样本预测图像的预定块的装置,以获得预测信号。此外,所述装置包括熵编码器,被配置为对用于预定块的预测残差进行编码以用于校正预测信号。为了预测预定块以获得预测信号,所述装置例如被配置为:从多个参考样本形成样本值向量;从样本值向量导出另一向量,所述样本值向量通过预定可逆线性变换而被映
射到另一向量上;计算另一向量与预定预测矩阵之间的矩阵向量乘积以获得预测向量;以及基于预测向量预测预定块的样本。
23.根据本发明的实施例涉及一种用于对图像进行解码的装置,包括根据本文中所描述的实施例中的任一个的用于使用多个参考样本预测图像的预定块的装置,以获得预测信号。此外,所述装置包括:熵解码器,被配置为对用于预定块的预测残差进行解码;以及预测校正器,被配置为使用预测残差校正预测信号。为了预测预定块以获得预测信号,所述装置例如被配置为:从多个参考样本形成样本值向量;从样本值向量导出另一向量,所述样本值向量通过预定可逆线性变换而被映射到另一向量上;计算另一向量与预定预测矩阵之间的矩阵向量乘积以获得预测向量;以及基于预测向量预测预定块的样本。
24.根据本发明的实施例涉及一种用于使用多个参考样本预测图像的预定块的方法,包括:从多个参考样本形成样本值向量;从样本值向量导出另一向量,所述样本值向量通过预定可逆线性变换而被映射到所述另一向量上;计算另一向量与预定预测矩阵之间的矩阵向量乘积以获得预测向量;以及基于预测向量预测预定块的样本。
25.根据本发明的实施例涉及一种用于对图像进行编码的方法,包括根据上文所描述的方法使用多个参考样本预测图像的预定块,以获得预测信号,以及对用于预定块的预测残差进行熵编码以用于校正预测信号。
26.根据本发明的实施例涉及一种用于对图像进行解码的方法,包括根据上文所描述的方法中的一个使用多个参考样本预测图像的预定块,以获得预测信号,对用于预定块的预测残差进行熵解码,以及使用预测残差校正预测信号。
27.根据本发明的实施例涉及一种使用本文中所描述的对图像进行编码的方法将图像编码而成的数据流。
28.根据本发明的实施例涉及一种具有程序代码的计算机程序,当所述程序代码在计算机上运行时用于执行本文中所描述的实施例中的任一个的方法。
附图说明
29.附图未必按比例绘制,实际上重点一般放在说明本发明的原理上。在以下描述中,参看以下附图描述本发明的各种实施例,其中:
30.图1示出编码成数据流的实施例;
31.图2示出编码器的实施例;
32.图3示出图像的重构的实施例;
33.图4示出解码器的实施例;
34.图5示出根据一实施例的用于编码和/或解码的块的预测的示意图;
35.图6示出根据一实施例的用于编码和/或解码的块的预测的矩阵运算;
36.图7.1示出根据一实施例的具有经缩减样本值的块的预测;
37.图7.2示出根据一实施例的使用样本的内插的块的预测;
38.图7.3示出根据一实施例的具有经缩减样本值向量的块的预测,其中仅平均一些边界样本;
39.图7.4示出根据一实施例的具有经缩减样本值向量的块的预测,其中平均四个边界样本的组;
40.图8示出根据一实施例的用于预测块的装置的示意图;
41.图9示出根据一实施例的由装置执行的矩阵运算;
42.图10a至图10c示出根据一实施例的由装置执行的详细矩阵运算;
43.图11示出根据一实施例的由装置使用偏移量和缩放参数执行的详细矩阵运算;
44.图12示出根据不同实施例的由装置使用偏移量和缩放参数执行的详细矩阵运算;且
45.图13示出根据一实施例的用于预测预定块的方法的框图。
具体实施方式
46.即使出现于不同图中,以下描述中仍通过相等或者等效附图标记表示具有相等或者等效功能性的相等或者等效(若干)元件。
47.在以下描述中,阐述多个细节以提供对本发明的实施例的更透彻解释。然而,本领域技术人员将显而易见,可以在无这些特定细节的情况下实践本发明的实施例。在其他情况下,以框图形式而非详细地示出公知结构和设备以便避免混淆本发明的实施例。另外,除非另外特定地指出,否则可以将本文中所描述的不同实施例的特征彼此组合。
48.1.介绍
49.在下文中,将描述不同的本发明示例、实施例和方面。这些示例、实施例和方面中的至少一些尤其是指用于视频编码和/或用于例如使用线性或者仿射变换和邻近样本缩减基于块的预测技术和/或用于优化视频递送(例如,广播、流式传输、文件播放等)(例如,用于视频应用程序和/或用于虚拟现实应用程序)的方法和/或装置。
50.此外,示例、实施例和方面可以表示高效率视频编码(hevc)或者后继者。而且,其他实施例、示例和方面将由所附权利要求限定。
51.应注意,如权利要求所限定的任何实施例、示例和方面可以由以下章节中所描述的细节(特征和功能性)中的任一个补充。
52.而且,以下章节中所描述的实施例、示例和方面可以个别地使用,且也可以由另一章节中的特征中的任一个或者由权利要求中所包括的任一特征补充。
53.而且,应注意,本文中所描述的个体、示例、实施例和方面可以个别地或者组合地使用。因此,细节可以被添加至所述各个方面中的每一个而无需将细节添加至所述示例、实施例和方面中的另一个。
54.也应注意,本公开明确地或者隐含地描述解码和/或编码系统和/或方法的特征。
55.此外,本文中关于一种方法所公开的特征和功能性也可用于装置中。此外,本文中关于装置所公开的任何特征和功能性也可用于对应方法中。换言之,本文中所公开的方法可以通过关于装置所描述的特征和功能性中的任一个加以补充。
56.而且,本文中所描述的特征和功能性中的任一个可以以硬件或者软件实施,或者使用硬件与软件的组合实施,如将在章节“实施替代方案”中所描述。
57.此外,在一些示例、实施例或者方面中,括号(“(
…
)”或者“[
…
]”)中所描述的特征中的任一个可以被视为可选的。
[0058]
2.编码器,解码器
[0059]
在下文中,描述各种示例,所述示例可以辅助当使用基于块的预测技术时实现更
有效压缩。一些示例通过使用一组内预测模式来实现高压缩效率。后面的示例可以添加至例如经探索性设计的其他内预测模式,或者可以专门地提供。而且甚至其他示例同时利用刚刚论述的特例两者。然而,作为这些实施例的变型,可以通过使用另一图像中的参考样本将内预测变为间预测。
[0060]
为了易于理解本技术的以下示例,本说明书开始呈现可以在其中构建随后概述的本技术的示例的可能的编码器和适合其的解码器。图1示出用于将图像10逐块编码成数据流12的装置。所述装置使用附图标记14指示且可以是静止图像编码器或者视频编码器。换言之,当编码器14被配置为将包括图像10的视频16编码成数据流12、或者编码器14可以专门地将图像10编码成数据流12时,图像10可以是视频16之中的当前图像。
[0061]
如所提及,编码器14以逐块方式或者基于块执行编码。为此,编码器14将图像10细分成块,所述编码器14的单元将图像10编码成数据流12。在下文更详细地阐述将图像10细分成块18的可能细分的示例。通常,细分可能诸如通过使用分层多树细分而最终变成具有恒定大小的块18,诸如以行和列配置的块的阵列,或者可能最终变成具有不同块大小的块18,其中多树细分起始于图像10的整个图像区域或者开始于图像10预分割成树型块的阵列,其中这些示例不应被视为排除将图像10细分成块18的其他可能方式。
[0062]
此外,编码器14是被配置为将图像10预测性地编码成数据流12的预测性编码器。对于特定块18,这意味着编码器14确定用于块18的预测信号且将预测残差(亦即,预测信号偏离块18内的实际图像内容的预测误差)编码成数据流12。
[0063]
编码器14可以支持不同预测模式以便导出用于特定块18的预测信号。在以下示例中具有重要性的预测模式为内预测模式,根据所述内预测模式,块18的内部根据图像10的相邻已经编码样本而在空间上预测。将图像10编码成数据流12以及因此对应的解码过程可以基于在块18之中定义的特定编码次序20。举例而言,编码次序20可以以光栅扫描次序(诸如从上而下逐行)遍历块18,其中例如从左至右遍历每一行。在基于分层多树的细分的情形下,光栅扫描排序可以应用在每一层级层次内,其中可以应用深度优先遍历次序,亦即,特定层级层次的块内的叶节点可以根据编码次序20在同一层级层次的具有相同父块的块之前。取决于编码次序20,块18的相邻已经编码样本通常可以定位在块18的一侧或多侧处。在本文中所呈现的示例的情形下,例如块18的相邻已经编码样本定位在块18的顶部和左边。
[0064]
内预测模式可能并非编码器14支持的仅有模式。在编码器14为视频编码器的情形下,例如编码器14也可以支持间预测模式,根据所述间预测模式,块18暂时根据视频16的先前编码的图像来预测。该间预测模式可以是运动补偿预测模式,根据所述运动补偿预测模式,将运动向量用信号通知给此块18,从而指示块18的预测信号将从其导出作为副本的部分的相对空间偏移量。额外地或者替代地,其他非内预测模式也可以是可用的,诸如在编码器14是多视图编码器的情形下的间预测模式,或者非预测性模式,根据所述非预测性模式,块18的内部按原样,亦即无任何预测的情况下,被编码。
[0065]
在开始将本技术的描述集中于内预测模式之前,用于可能的基于块的编码器(亦即用于编码器14的可能实施)的更特定示例,如关于图2所描述,其中随后分别呈现适合图1和图2的解码器的两个对应的示例。
[0066]
图2示出图1的编码器14的可能实施,亦即其中编码器被配置为使用变换编码以用于编码预测残差的实施,但此近似示例且本技术并不限于该类别的预测残差编码。根据图
2,编码器14包括减法器22,被配置为从入站信号(inbound signal)(亦即图像10,或者以块为基础时的当前块18)减去对应的预测信号24以获得预测残差信号26,所述预测残差信号随后由预测残差编码器28编码成数据流12。预测残差编码器28由有损编码级28a和无损编码级28b构成。有损级28a接收预测残差信号26且包括量化器30,所述量化器量化预测残差信号26的样本。如上文已经提及,本发明示例使用预测残差信号26的变换编码,且因此有损编码级28a包括连接在减法器22与量化器30之间的变换级32以便变换这种经频谱分解的预测残差26,并且对呈现残差信号26的经变换系数进行量化器30的量化。所述变换可以是dct、dst、fft、哈达马德(hadamard)变换等等。经变换且经量化的预测残差信号34随后通过无损编码级28b进行无损编码,所述无损编码级是将经量化的预测残差信号34熵编码成数据流12的熵编码器。编码器14进一步包括预测残差信号重构级36,其连接至量化器30的输出以便以也可用在解码器处的方式从经变换且经量化的预测残差信号34重构预测残差信号,亦即考虑到编码损失为量化器30。为此目的,预测残差重构级36包括反量化器38,其执行量化器30的量化的逆操作,随后包括反变换器40,其相对于由变换器32执行的变换执行反变换,诸如频谱分解的逆操作,诸如以上提及的具体变换示例中的任一个的逆操作。编码器14包括加法器42,其使由反变换器40输出的经重构的预测残差信号和预测信号24相加以便输出经重构信号,亦即经重构样本。此输出被馈送至编码器14的预测器44中,所述预测器随后基于该输出来确定预测信号24。预测器44支持上文已经关于图1所论述的所有预测模式。图2也图示了在编码器14为视频编码器的情形下,编码器14也可以包括环内(in-loop)滤波器46,其对经重构图像进行完全滤波,所述经重构图像在已经滤波之后相对于经间预测的块而形成用于预测器44的参考图像。
[0067]
如上文已提及,编码器14基于块操作。对于后续描述,所关注的块基础是将图像10细分成块的基础,针对所述块而从分别由预测器44或者编码器14支持的一组或者多个内预测模式之中选择内预测模式,且单独地执行所选择的内预测模式。然而,也可以存在将图像10细分成其他类别的块。举例而言,无论图像10被间编码或者内编码,以上提及的决策均可以以从块18偏离的块的粒度或者单位来进行。举例而言,间/内模式决策可以以图像10细分成的编码块的级别来执行,且每一编码块细分成预测块。具有已经决定对其使用内预测的编码块的预测块的每一个被细分至内预测模式决策。为此,对于这些预测块中的每一个,决定相应预测块应使用哪种所支持的内预测模式。这些预测块将形成此处感兴趣的块18。与间预测相关联的编码块内的预测块将由预测器44以不同方式处理。将通过确定运动向量且从参考图片中由运动向量指向的位置复制用于此块的预测信号,从参考图像来间预测所述预测块。另一种块细分是关于细分成变换块,其中由变换器32和反向变换器40以所述变换块为单位执行变换。经变换的块可以例如是进一步细分编码块的结果。当然,本文中所阐述的示例不应被视为限制性的,且也存在其他示例。仅出于完整性起见,应注意,细分成编码块可以例如使用多树细分,且预测块和/或变换块也可以通过使用多树细分进一步细分编码块而获得。
[0068]
图3中描绘适合图1的编码器14的用于逐块解码的解码器54或者装置。此解码器54与编码器14相反,即,它以块方式从数据流12解码图像10,并为此支持多种内预测模式。举例而言,解码器54可以包括残差提供器156。上文关于图1所论述的所有其他可能性对于解码器54也有效。为此,解码器54可以是静止图像解码器或者视频解码器且所有预测模式和
预测可能性也由解码器54支持。编码器14与解码器54之间的差异主要在于以下事实:编码器14根据某种优化选择或选定编码决策,诸如例如为了最小化可取决于编码速率和/或编码失真的某种成本函数。这些编码选项或者编码参数中的一个可涉及可用的或者所支持的内预测模式之中的待用于当前块18的一系列内预测模式。选定的内预测模式随后可以在数据流12内由编码器14用信号通知给当前块18,其中解码器54使用用于块18的数据流12中的该信号通知而重新进行选择。同样地,图像10细分成块18可以在编码器14内进行优化,且对应的细分信息可以在数据流12内传送,其中解码器54基于细分信息恢复将图像10细分成块18。综上所述,解码器54可以是基于块进行操作的预测性解码器,且除内预测模式之外,解码器54可以支持其他预测模式,诸如在例如解码器54为视频解码器的情形下的间预测模式。在解码时,解码器54也可以使用关于图1论述的编码次序20,且因为编码器14和解码器54均遵守此编码次序20,所以相同相邻样本可用于编码器14和解码器54处的当前块18。因此,为了避免不必要的重复,就图像10细分成块而言,例如就预测而言和就预测残差的编码而言,编码器14的操作模式的描述也应适用于解码器54。差异在于以下事实:编码器14通过优化选择一些编码选项或者编码参数,且在数据流12内用信号发送编码参数或者将编码参数插入至数据流12中,所述编码参数随后通过解码器54从数据流12导出以便重新进行预测、细分等等。
[0069]
图4示出图3的解码器54的可能实施,亦即适合如图2中所示出的图1的编码器14的实施的实施。由于图4的编码器54的许多元件与图2的对应编码器中出现的那些元件相同,因此在图4中使用具备撇号的相同附图标记以便指示这些元件。具体来讲,加法器42'、可选的环内滤波器46'和预测器44'以与其在图2的编码器中相同的方式连接至预测回路中。应用于加法器42'的经重构的、即经去量化和经再变换的预测残差信号通过以下部件的序列导出:熵解码器56,其进行熵编码器28b的熵编码的逆操作;随后是残差信号重构级36',其由反量化器38'和反变换器40'构成,与编码侧的情形相同。解码器的输出为图像10的重构。图像10的重构可以直接在加法器42'的输出处或者替代地在环内滤波器46'的输出处获得。一些后置滤波器可以配置在解码器的输出处以便对图像10的重构进行一些后置滤波,以便改良图像质量,但图4中并未描绘此选项。
[0070]
再次,关于图4,上面关于图2提出的描述对于图4也应有效,但除了仅编码器执行优化任务和关于编码选项的相关联决策之外。然而,关于块细分、预测、反量化和再变换的所有描述对于图4的解码器54也有效。
[0071]
3.alwip(仿射线性加权内预测器)
[0072]
特此论述关于alwip的一些非限制性示例,即使alwip并非一直必需具体实施此处论述的技术。
[0073]
本技术尤其涉及用于逐块图像编码的经改良的基于块的预测模式概念,所述概念诸如可用在诸如hevc或者hevc的任何后续者的视频编解码器中。预测模式可以是内预测模式,但理论上本文中所描述的概念也可以传递至间预测模式上,其中参考样本是另一图像的一部分。
[0074]
寻求基于块的预测概念,其允许诸如硬件友好实施的高效实施。
[0075]
此目的是通过本技术的独立技术方案的主题来达成的。
[0076]
内预测模式广泛地用于图像和视频编码中。在视频编码中,内预测模式与诸如间
预测模式的其他预测模式竞争,所述间预测模式诸如运动补偿预测模式。在内预测模式中,基于相邻样本预测当前块,所述相邻样本亦即就编码器侧而言已经编码且就解码器侧而言已经解码的样本。相邻样本值被外推(extrapolate)至当前块中,以便形成用于当前块的预测信号,其中预测残差在用于当前块的数据流中传输。预测信号越佳,则预测残差越低,且相应地需要较低数目的位对预测残差进行编码。
[0077]
为了有效,应考虑若干方面以便在逐块图像编码环境中形成用于内预测的有效框架。举例而言,由编解码器支持的内预测模式的数目越大,则侧信息速率消耗越大,以便将选择用信号通知给解码器。另一方面,所支持的内预测模式的组应能够提供良好预测信号,亦即导致低预测残差的预测信号。
[0078]
在下文中,作为比较实施例或者基础示例,公开了用于从数据流逐块解码图像的装置(编码器或者解码器),所述装置支持至少一种内预测模式,根据所述内预测模式,通过将邻近当前块的样本的第一模板应用至仿射线性预测器来确定用于图像的预定大小的块的内预测信号,所述仿射线性预测器在后续中将被称作仿射线性加权内预测器(alwip)。
[0079]
所述装置可以具有以下属性中的至少一个(其可以适用于例如实施于非暂时性存储单元中的方法或者另一技术,所述非暂时性存储单元存储在由处理器执行时使所述处理器实施所述方法和/或用作所述装置的指令):
[0080]
3.1预测器可以与其他预测器互补
[0081]
可以形成下文进一步描述在实施改良的主题的内预测模式可以与编解码器的其他内预测模式互补。因此,这些内预测模式可以与在hevc编码解码器中、相应地在jem参考软件中定义的dc预测模式、平面预测模式和角度预测模式互补。内预测模式的后三种类型今后将被称作传统内预测模式。因此,对于内模式中的给定块,需要由解码器解析标志,从而指示将使用或者不使用所述装置支持的内预测模式中的一种。
[0082]
3.2多于一种的所提议的预测模式
[0083]
所述装置可以包含多于一种的alwip模式。因此,在解码器已知将使用所述装置所支持的alwip模式中的一种的情形下,所述解码器需要解析额外信息,所述额外信息指示将使用所述装置所支持的alwip模式中的哪一种alwip模式。
[0084]
所支持模式的信号通知可以具有如下属性:一些alwip模式的编码可能需要比其他alwip模式少的位格(bin)。这些模式中的哪些模式需要较少位格且哪些模式需要较多位格可以取决于可从已解码的位流提取的信息,或者可以预先固定。
[0085]
4.一些方面
[0086]
图2示出用于从数据流12解码图像的解码器54。解码器54可以被配置为解码图像的预定块18。具体来讲,预测器44可以被配置为使用线性或者仿射线性变换[例如,alwip]将与预定块18相邻的p个相邻样本的集合映射至预定块的样本的q个预测值的集合上。
[0087]
如图5中所示出,预定块18包括待预测的q个值(在操作结束时,其将为“预测值”)。如果块18具有m行和n列,则q=m
·
n。块18的q个值可以在空间域(例如,像素)中或者在变换域(例如,dct,离散小波变换等)中。可以基于从一般邻近于块18的相邻块17a至17c获取的p个值来预测块18的q个值。相邻块17a至17c的p个值可以在最接近(例如,邻近)块18的位置中。相邻块17a至17c的p个值已被处理和预测。所述p个值被指示作为部分17'a至17'c中的值,以将所述部分与它们所属于的块区分开(在一些示例中,不使用17'b)。
[0088]
如图6中所示出,为了执行预测,有可能与具有p个项(每一项与相邻部分17'a至17'c中的特定位置相关联)的第一向量17p、具有q个项(每一项与块18中的特定位置相关联)的第二向量18q和映射矩阵17m(每一行与块18中的特定位置相关联,每一列与相邻部分17'a至17'c中的特定位置相关联)一起操作。因此,映射矩阵17m根据预定模式执行将相邻部分17'a至17'c的p个值预测成块18的值。映射矩阵17m中的项可以因此理解为加权因子。在以下段落中,我们将使用符号17a至17c代替17'a至17'c来表示边界的相邻部分。
[0089]
在此项技术中,已知若干传统模式,诸如dc模式、平面模式和65种方向性预测模式。可能已知例如67种模式。
[0090]
然而,已注意到,也有可能利用不同模式,其在此处被称作线性或者仿射线性变换。线性或者仿射线性变换包括p
·
q个加权因子,在所述加权因子之中,至少1/4 p
·
q个加权因子是非零加权值,其针对q个经预测值中的每一个,包括与相应经预测值有关的一系列p个加权因子。该系列当在预定块的样本之中根据光栅扫描次序而一个接一个地被配置时,形成全向非线性的包络。
[0091]
有可能映射相邻值17'a至17'c(模板)的p个位置、相邻样本17'a至17'c的q个位置,且在矩阵17m的p*q个加权因子的值处进行映射。平面是用于dc变换的系列的包络的示例(其为用于dc变换的平面)。包络明显为平面的,且因此被线性或者仿射线性变换(alwip)的定义所排除。另一示例为产生角度模式的仿真的矩阵:包络将从alwip定义排除,且直白来讲,将看起来像沿着p/q平面中的方向从上而下倾斜的山丘。平面模式和65种方向预测模式将具有不同包络,然而,其将在至少一个方向上为线性的,亦即例如用于所例示的dc的所有方向和例如用于角度模式的山丘方向。
[0092]
相反,线性或者仿射变换的包络将并非全向线性的。已理解,在一些情形中,这种变换对于执行块18的预测可以是最佳的。已注意,优选地,加权因子的至少1/4不同于零(亦即,p*q个加权因子中的至少25%不同于0)。
[0093]
根据任何常规的映射规则,所述加权因子可能彼此不相关。因此,矩阵17m可以使得它的各项的值不具有明显可辨识的关系。举例而言,加权因子无法由任何分析或者差分函数描述。
[0094]
在示例中,alwip变换使得有关于相应经预测值的第一系列加权因子与有关于除相应经预测值以外的经预测值的第二系列加权因子或者后一系列的反转版本-无论哪种导致较高的最大值-之间的交叉相关的最大值的均值可以低于预定阈值(例如,0.2或者0.3或者0.35或者0.1,例如,在0.05与0.035之间的范围内的阈值)。举例而言,对于alwip矩阵17m的每一对行(i1,i2),可以通过将第i1行的p个值乘以第i2行的p个值来计算交叉相关。对于每一获得的交叉相关,可以获得最大值。因此,可以针对整个矩阵17m获得均值(平均值)(亦即,对所有组合中的交叉相关的最大值进行平均)。此后,阈值可以是例如0.2或者0.3或者0.35或者0.1,例如,在0.05与0.035之间的范围内的阈值。
[0095]
块17a至17c的p个相邻样本可以沿着一维路径定位,所述一维路径沿着预定块18的边界(例如,18c,18a)延伸。对于预定块18的q个经预测值中的每一个,有关于相应经预测值的p个加权因子的系列可以以在预定方向(例如,从左至右,从上至下等)上遍历一维路径的方式排序。
[0096]
在示例中,alwip矩阵17m可以是非对角或者非块对角的。
[0097]
用于从4个已预测的相邻样本预测4
×
4块18的alwip矩阵17m的示例可以是:
[0098]
{
[0099]
{37,59,77,28},
[0100]
{32,92,85,25},
[0101]
{31,69,100,24},
[0102]
{33,36,106,29},
[0103]
{24,49,104,48},
[0104]
{24,21,94,59},
[0105]
{29,0,80,72},
[0106]
{35,2,66,84},
[0107]
{32,13,35,99},
[0108]
{39,11,34,103},
[0109]
{45,21,34,106},
[0110]
{51,24,40,105},
[0111]
{50,28,43,101},
[0112]
{56,32,49,101},
[0113]
{61,31,53,102},
[0114]
{61,32,54,100}
[0115]
}。
[0116]
(此处,{37,59,77,28}为矩阵17m的第一行;{32,92,85,25}为第二行;且{61,32,54,100}为第16行)。矩阵17m具有尺寸16
×
4,且包括64个加权因子(由于16*4=64)。这是因为矩阵17m具有尺寸q
×
p,其中q=m*n,其为待预测的块18的样本数目(块18为4
×
4块),且p为已预测样本的样本数目。此处,m=4,n=4,q=16(由于m*n=4*4=16),p=4。所述矩阵为非对角和非块对角的,且不由特定规则描述。
[0117]
如可以看出的,少于1/4的加权因子是0(在上文所示出的矩阵的情形下,六十四个之中的一个加权因子为零)。当根据光栅扫描次序一个接一个地配置时,由这些值形成的包络形成全向非线性的包络。
[0118]
即使主要参考解码器(例如,解码器54)论述以上解释,但所述解释可以在编码器(例如,编码器14)处执行。
[0119]
在一些示例中,对于每一块大小(在块大小的集合中),用于相应块大小的内预测模式的第二集合内的内预测模式的alwip变换为相互不同的。额外地或者替代地,用于块大小的集合中的块大小的内预测模式的第二集合的基数(cardinality)可以一致,但用于不同块大小的内预测模式的第二集合内的内预测模式的相关联的线性或者仿射线性变换不可以通过按比例调整来彼此转换。
[0120]
在一些示例中,可以定义alwip变换,其方式为使得其与传统变换“无共享部分”(例如,alwip变换可能与对应传统变换“无”共享部分,即使所述变换已经由以上映射中的一个映射)。
[0121]
在示例中,alwip模式用于亮度分量和色度分量两者,但在其他示例中,alwip模式用于亮度分量但不用于色度分量。
[0122]
5.具有编码器加速的仿射线性加权内预测模式(例如,测试ce3-1.2.1)
[0123]
5.1方法或者装置的描述
[0124]
在ce3-1.2.1中测试的仿射线性加权内预测(alwip)模式可以与在测试ce3-2.2.2下在jvet-l0199中提议的模式相同,除了以下改变以外:
[0125]
·
与多个参考线(mrl)内预测(尤其编码器估计和信号通知)的协调,亦即mrl不与alwip组合且传输mrl索引被限于非alwip块。
[0126]
·
现在必须对所有w
×
h≥32
×
32的块进行次采样(以前对于32
×
32是可选的);因此,已删除了编码器处的发送次采样标志的额外测试。
[0127]
·
通过分别下采样至32
×
n和n
×
32并应用对应的alwip模式,已添加了用于64
×
n和n
×
64块(其中n≤32)的alwip。
[0128]
此外,测试ce3-1.2.1包括用于alwip的以下编码器优化:
[0129]
·
组合模式估计:传统和alwip模式使用用于全部rd估计的共享哈达马德候选者列表,亦即alwip模式候选者基于哈达马德成本添加至与传统(和mrl)模式候选者相同的列表。
[0130]
·
针对组合模式列表支持emt内快速和pb内快速,其中额外优化用于缩减全部rd检查的数目。
[0131]
·
按照与传统模式相同的方法,仅将可用的左侧和上方块的mpm添加至所述列表,以进行alwip的完整rd估计。
[0132]
5.2复杂性评估
[0133]
在测试ce3-1.2.1中,不包括调用离散余弦变换的计算,每个样本最多需要12次乘法才能生成预测信号。此外,总共需要136492个参数,每一参数16个位。这对应于0.273兆字节的存储器。
[0134]
5.3实验结果
[0135]
根据共同测试条件jvet-j1010[2]对具有vtm软件3.0.1版本的仅内(ai,intra-only)和随机存取(ra,random-access)配置执行测试评估。在具有linux os和gcc 7.2.1编译程序的intel xeon集群(e5-2697a v4,avx2打开,英特尔睿频加速技术(turbo boost)关闭)上进行了对应的模拟。
[0136]
表1.针对vtm ai配置的ce3-1.2.1的结果
[0137][0138][0139]
表2.针对vtm ra配置的ce3-1.2.1的结果
[0140] yuv编码时间解码时间类别a1-1,25%-1,80%-1,95%113%100%类别a2-0,68%-0,54%-0,21%111%100%类别b-0,82%-0,72%-0,97%113%100%类别c-0,70%-0,79%-0,82%113%99%类别e
ꢀꢀꢀꢀꢀ
总计-0,85%-0,92%-0,98%113%100%类别d-0,65%-1,06%-0,51%113%102%类别f(可选的)-1,07%-1,04%-0,96%117%99%
[0141]
5.4复杂性降低的仿射线性加权内预测(例如测试ce3-1.2.2)
[0142]
ce2中所测试的技术涉及jvet-l0199[1]中所描述的“仿射线性内预测”,但就存储器要求和计算复杂度而言简化了所述预测:
[0143]
·
可以仅存在三组不同的预测矩阵(例如s0,s1,s2,也参见下文)和偏差向量(例如用于提供偏移量值)覆盖所有块形状。因此,参数的数量缩减至14400个10位值,此比在128
×
128 ctu中存储的存储量要少。
[0144]
·
预测器的输入和输出大小被进一步缩减。此外,代替经由dct变换边界,可以对边界样本执行平均或者下采样,并且预测信号的生成可以使用线性内插代替逆dct。因此,为了生成预测信号,每个样本最多可以需要四次乘法。
[0145]
6.示例
[0146]
此处论述如何利用alwip预测执行一些预测(例如,如图6中所示出)。
[0147]
原则上,参考图6,为了获得待预测的m
×
n块18的q=m*n个值,应执行将q
×
p alwip预测矩阵17m的q*p个样本乘以p
×
1相邻向量17p的p个样本。因此,通常,为了获得待预测的m
×
n块18的q=m*n个值中的每一个,至少需要p=m n值乘法。
[0148]
这些乘法具有极其不想要的效果。边界向量17p的尺寸p通常取决于与待预测的m
×
n块18邻近(例如,与的相邻)的边界样本(位格或者像素)17a、17c的数量m n。这意味着,如果待预测的块18的大小较大,则边界像素(17a,17c)的数量m n相应地较大,因此增加了p
×
1边界向量17p的尺寸p=m n,和q
×
p alwip预测矩阵17m的每一行的长度,以及相应地,也增加了必需的乘数的数量(一般而言,q=m*n=w*h,其中宽度(w)是n的另一符号且高度(h)是m的另一符号;在边界向量仅由一行和/或一列样本形成的情形下,p为p=m n=h w)。
[0149]
通常,以下事实会加剧此问题:在基于微处理器的系统(或者其他数字处理系统)中,乘法通常为消耗功率的运算。可以想象,针对大量块的极大量样本进行的大量乘法会导致计算功率的浪费,这通常是不想要的。
[0150]
因此,优选地,缩减预测m
×
n块18所必需的乘法的数量q*p。
[0151]
已理解,有可能通过智能型地选择替代乘法并且更易于处理的运算,来在某种程度上缩减待预测的每一块18的每一内预测所必需的计算功率。
[0152]
具体来讲,参考图7.1至图7.4,已理解,编码器或者解码器可以使用多个相邻样本(例如17a,17c)通过以下操作来预测图片的预定块(例如18):
[0153]
缩减(例如在步骤811处)(例如通过平均或者下采样)多个相邻样本(例如17a,17c)以获得相较于多个相邻样本在样本数目上较低的经缩减样本值集合,
[0154]
对经缩减样本值集合进行(例如在步骤812处)线性或者仿射线性变换,以获得预定块的预定样本的经预测值。
[0155]
在一些情形下,解码器或者编码器也可以例如通过内插基于用于预定样本和多个相邻样本的经预测值导出用于预定块的其他样本的预测值。因此,可以获得上采样策略。
[0156]
在示例中,有可能对边界17的样本执行(例如,在步骤811处)一些平均值,以获得具有经缩减的样本数目的经缩减样本集合102(图7.1至图7.4)(经缩减的样本数目102的样本中的至少一个可以是原始边界样本或者一系列原始边界样本中的两个样本的平均值)。举例而言,如果原始边界具有p=m n个样本,则经缩减样本集合可以具有p
red
=m
red
n
red
,其中具有m
red
《m和n
red
《n中的至少一个,使得p
red
《p。因此,将实际上用于预测(例如在步骤812b处)的边界向量17p将不具有p
×
1个项,而是具有p
red
×
1个项,其中p
red
《p。类似地,针对预测所选择的alwip预测矩阵17m将不具有q
×
p尺寸,而是具有q
×
p
red
(或者q
red
×
p
red
,参见下文),其具有矩阵的经缩减数目个元素,至少因为p
red
《p(借助于m
red
《m和n
red
《n中的至少一个)。
[0157]
在一些示例中(例如图7.2,图7.3),如果通过alwip获得(在步骤812处)的块为具有大小m
′
red
×n′
red
(其中m
′
red
《m和/或n
′
red
《n),则甚至有可能进一步缩减乘法的数目(亦即通过alwip直接预测的样本在数目上少于实际上经预测的块18的样本)。因此,设置成q
red
=m
′
red
*n
′
red
,这将通过不使用q*p
red
个乘法而代之以使用q
red
*p
red
个乘法(其中q
red
*p
red
《q*p
red
《q*p)而获得alwip预测。此乘法将预测经缩减块,其中尺寸m
′
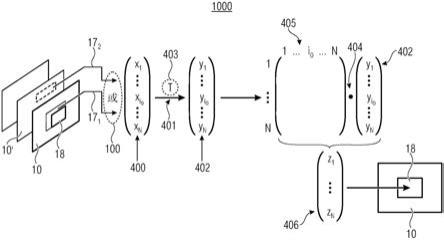
red
×n′
red
。尽管如此,将有可能执行(例如在后续步骤813处)从经缩减m
′
red
×n′
red
的经预测块至最终的经m
×
n预测的块中的上采样(例如,通过内插获得)。
[0158]
这些技术可以是有利的,这是由于虽然矩阵乘法涉及经缩减的乘法数目(q
red
*p
red
或者q*p
red
),但初始缩减(例如,平均或者下采样)和最终变换(例如内插)两者均可以通过缩减(或者甚至避免)乘法来执行。举例而言,下采样、平均和/或内插可以通过采用计算上不需要功率的二进制运算(诸如加法和移位)来执行(例如在步骤811和/或813处)。
[0159]
而且,所述加法是极容易的运算,其无需大量的计算工作即可以容易地执行。
[0160]
此移位运算可以例如用于平均两个边界样本和/或用于内插(或者从边界取得的)经缩减的经预测块的两个样本(支持值),以获得最终的经预测块。(对于内插,必须有两个样本值。在所述块内,我们一直具有两个预定值,但对于沿块的左边界和上方边界内插样本,我们仅具有一个预定值,如图7.2中,因此我们使用边界样本作为内插的支持值。)
[0161]
可以使用两步骤过程,诸如:
[0162]
首先对两个样本的值求和;
[0163]
随后将总和的值减半(例如,通过向右移位)。
[0164]
替代地,有可能:
[0165]
首先将样本中的每一个减半(例如,通过向左移位);
[0166]
随后对两个经减半样本的值求和。
[0167]
当下采样(例如,在步骤811处)时,可以执行甚至更容易的操作,因为仅需要在样本(例如,彼此邻近的样本)的组中选择一个样本量。
[0168]
因此,现在有可能限定用于缩减待执行的乘法的数目的技术。这些技术中的一些可以尤其基于以下原理中的至少一个:
[0169]
即使实际上经预测的块18具有大小m
×
n,但可以缩减块(在二维中的至少一个中),且可以应用具有经缩减的大小q
red
×
p
red
的alwip矩阵(其中q
red
=m
′
red
*n
′
red
,p
red
=n
red
m
red
,其中m
′
red
《m和/或n
′
red
《n和/或m
red
《m和/或n
red
《n)。因此,边界向量17p将具有大小p
red
×
1,仅意指p
red
《p乘法(其中p
red
=m
red
n
red
且p=m n)。
[0170]
p
red
×
1边界向量17p可以从原始边界17容易地获得,例如:
[0171]
通过下采样(例如通过仅选择边界的一些样本);和/或
[0172]
通过平均边界的多个样本(所述边界可以通过加法和移位而不使用乘法的情况下容易地获得)。
[0173]
额外地或者替代地,代替通过乘法预测待预测的块18的所有q=m*n值,有可能仅预测具有经缩减尺寸的经缩减块(例如,q
red
=m
′
red
*n
′
red
,其中m
′
red
《m和/或n
′
red
《n)。将通过内插例如使用q
red
个样本作为用于待预测的剩余的q-q
red
个值的支持值来获得待预测的块18的剩余的样本。
[0174]
根据图7.1中所说明的示例,将预测4
×
4块18(m=4,n=4,q=m*n=16),且样本17a(具有四个已经预测的样本的垂直行列)和17c(具有四个已经预测的样本的水平行)的邻域17(邻域17a和17c可以共同由17指示)已经在先前迭代处预测。先验地,通过使用图5中所示出的等式,预测矩阵17m应为q
×
p=16
×
8矩阵(借助于q=m*n=4*4且p=m n=4 4=8),边界向量17p应具有8
×
1尺寸(借助于p=8)。然而,这将驱使对于待预测的4
×
4块18的16个样本中的每一个执行8次乘法的必要性,因此导致总共需要执行16*8=128次乘法。(应注意,每个样本的乘法的平均数量是计算复杂度的良好评估。对于传统内预测,每个样本需要四次乘法,且这增加了所要涉及的计算工作。因此,可以使用这作为alwip的上限,将确保复杂性是合理的并且不超过传统内预测的复杂性。)
[0175]
尽管如此,已理解,通过使用本发明技术,有可能在步骤811处将与待预测的块18相邻的样本17a和17c的数目从p缩减至p
red
《p。具体来讲,已理解,有可能平均(例如在图7.1中的100处)彼此邻近的边界样本(17a,17c),以获得具有两个水平行和两个垂直列的经缩
减边界102,因此2
×
2块用作块18(该经缩减边界是通过平均值形成的)。替代地,有可能执行下采样,因此选择用于行17c的两个样本和用于列17a的两个样本。因此,并不是具有四个原始样本的水平行17c被处理为具有两个样本(例如经平均样本),而代之以,最初具有四个样本的垂直列17a被处理为具有两个样本(例如经平均样本)。也有可能理解,在细分每两个样本的组110中的行17c和列17a之后,维持单个样本(例如,组110的样本的平均值或者组110的样本之中的简单选择)。因此,借助于仅具有四个样本的集合102而获得所谓的经缩减样本值集合102(m
red
=2,n
red
=2,p
red
=m
red
n
red
=4,其中p
red
《p)。
[0176]
已理解,有可能执行操作(诸如平均或者下采样100)而无需在处理器层级下执行太多的乘法:在步骤811执行的平均或者下采样100可以简单地通过直接的且计算上不消耗功率的运算(诸如加法和移位)来获得。
[0177]
已理解,此时,可以对经缩减样本值集合102进行线性或者仿射线性(alwip)变换19(例如,使用诸如图5的矩阵17m的预测矩阵)。在此情形下,alwip变换19直接将四个样本102映射至块18的样本值104上。在当前情形下,不需要内插。
[0178]
在此情形下,alwip矩阵17m具有尺q
×
p
red
=16
×
4:此遵循以下事实:待预测的块18的所有q=16个样本均通过alwip乘法直接获得(不需要内插)。
[0179]
因此,在步骤812a处,选择具有尺寸q
×
pred的合适的alwip矩阵17m。所述选择可以至少部分地基于例如来自数据流12的信号通知。选定的alwip矩阵17m也可以利用ak来指示,其中k可以理解为索引,其可以在数据流12中用信号通知(在一些情形下,所述矩阵也指示为参见下文)。所述选择可以根据以下方案执行:对于每一尺寸(例如,待预测的块18的高度/宽度配对),在例如矩阵的三个集合s0、s1、s2中的一个之中选择alwip矩阵17m(三个集合s0、s1、s2中的每一个可以对具有相同尺寸的多个alwip矩阵17m进行分组,且所要针对预测选择的alwip矩阵将是其中的一个)。
[0180]
在步骤812b处,执行选定的q
×
p
red alwip矩阵17m(也被指示为a
k)
与p
red
×
1边界向量17p之间的乘法。
[0181]
在步骤812c处,可以将偏移量值(例如,bk)添加至例如通过alwip获得的向量18q的所有获得值104。偏移量的值(bk或者在一些情形下也利用指示,参见下文)可以与特定的选定alwip矩阵(ak)相关联,且可以基于索引(例如,其可以在数据流12中用信号通知)。
[0182]
因此,此处继续进行对使用本发明技术与不使用本发明技术之间的比较:
[0183]
在不具有本发明技术的情况下:
[0184]
待预测的块18,所述块具有尺寸m=4,n=4;
[0185]
待预测的q=m*n=4*4=16个值;
[0186]
p=m n=4 4=8个边界样本
[0187]
用于待预测的q=16个值中的每一个的p=8乘法
[0188]
p*q=8*16=128乘法的总数目;
[0189]
在本发明技术的情况下,我们具有:
[0190]
待预测的块18,所述块具有尺寸m=4,n=4;
[0191]
待结束时预测的q=m*n=4*4=16个值;
[0192]
边界向量的经缩减尺寸:p
red
=m
red
n
red
=2 2=4;
[0193]
用于待通过alwip预测的q=16个值中的每一个的p
red
=4次乘法,
[0194]
p
red
*q=4*16=64次乘法的总数目(128的一半!)
[0195]
乘法的数目和待获得的最终值的数目之间的比率为p
red
*q/q=4,亦即用于每一待预测的样本的p=8次乘法的不到一半!
[0196]
如可以理解的,通过依赖于诸如平均(且,假使,加法和/或移位和/或下采样)的直接且计算上不需要功率的运算,有可能在步骤812处获得适当的值。
[0197]
参考图7.2,待预测的块18此处为64个样本的8
×
8块(m=8,n=8)。此处,先验地,预测矩阵17m应具有大小q
×
p=64
×
16(q=64,借助于q=m*n=8*8=64,m=8且n=8并且借助于p=m n=8 8=16)。因此,先验地,将需要用于待预测的8
×
8块18的q=64个样本中的每一个的p=16次乘法,以得到用于整个8
×
8块18的64*16=1024次乘法!
[0198]
然而,如图7.2中可见,可以提供方法820,根据所述方法,代替使用边界的所有16个样本,仅使用8个值(例如,边界的原始样本之间的水平边界行17c中的4和垂直边界列17a中的4)。从边界行17c,可以使用4个样本代替8个样本(例如,4个样本可以是二乘二的平均值和/或从两个样本选择一个样本)。因此,边界向量并非p
×
1=16
×
1向量,而仅为p
red
×
1=8
×
1向量(p
red
=m
red
n
red
=4 4)。已理解,有可能选择或者平均(例如,二乘二)水平行17c的样本和垂直列17a的样本以仅具有p
red
=8个边界值,而非原始的p=16个样本,从而形成经缩减样本值集合102。经缩减集合102将准许获得块18的经缩减版本,经缩减版本具有q
red
=m
red
*n
red
=4*4=16个样本(而非q=m*n=8*8=64)。有可能应用alwip矩阵以用于预测具有大小m
red
×nred
=4
×
4的块。块18的经缩减版本包括在图7.2的方案106中利用灰色指示的样本:利用灰色正方形指示的样本(包括样本118'和118”)形成4
×
4经缩减块,其具有在进行步骤812获得的q
red
=16个值。通过在进行步骤812时应用线性变换19而获得4
×
4经缩减块。在获得4
×
4经缩减块的值之后,有可能例如通过内插获得剩余的样本(在方案106中利用白色样本指示的样本)的值。
[0199]
关于图7.1的方法810,此方法820可以额外包括例如通过内插导出用于待预测的m
×
n=8
×
8块18的剩余的q-q
red
=64-16=48个样本(白色正方形)的预测值的步骤813。剩余的q-q
red
=64-16=48个样本可以通过内插从q
red
=16个直接获得的样本获得(所述内插也可以利用例如边界样本的值)。如图7.2中可见,虽然在步骤812处已经获得样本118'和118”(如由灰色正方形指示),但样本108'(在样本118'与118”中间且利用白色正方形指示)在步骤813处通过样本118'与118”之间的内插获得。已理解,内插也可以通过类似于用于平均的运算(诸如,移位和加法)的运算来获得。因此,在图7.2中,通常可以将值108'确定为样本118'的值与样本118”的值之间的中间值(其可以是平均值)。
[0200]
通过执行内插,在步骤813处,也有可能基于在104中指示的多个样本值而得到m
×
n=8
×
8块18的最终版本。
[0201]
因此,使用本发明技术与不使用本发明技术之间的比较是:
[0202]
在不具有本发明技术的情况下:
[0203]
待预测的块18,所述块具有尺寸m=8,n=8,和块18中的待预测的q=m*n=8*8=64个样本;
[0204]
边界17中的p=m n=8 8=16个样本;
[0205]
用于待预测的q=64个值中的每一个的p=16次乘法,
[0206]
p*q=16*64=1028次乘法的总数目
[0207]
乘法的数目与待获得的最终值的数目之间的比率是p*q/q=16
[0208]
在具有本发明技术的情况下:
[0209]
待预测的块18,其具有尺寸m=8,n=8
[0210]
待结束时预测的q=m*n=8*8=64个值;
[0211]
但是将使用q
red
×
p
red
alwip矩阵,其中p
red
=m
red
n
red
,q
red
=m
red
*n
red
,m
red
=4,n
red
=4
[0212]
边界中的p
red
=m
red
n
red
=4 4=8个样本,其中p
red
《p
[0213]
用于待预测的4
×
4经缩减块(在方案106中由灰色正方形形成)的q
red
=16个值中的每一个的p
red
=8次乘法,
[0214]
p
red
*q
red
=8*16=128次乘法的总数目(比1024小得多!)
[0215]
乘法的数目与待获得的最终值的数目之间的比率是p
red
*q
red
/q=128/64=2(比在不具有本发明技术的情况下获得的16小得多!)。
[0216]
因此,此处呈现的技术对功率的需求比前一个技术少8倍。
[0217]
图7.3示出另一示例(其可以基于方法820),其中待预测的块18为矩形4
×
8块(m=8,n=4),其具有待预测的q=4*8=32个样本。边界17是通过具有n=8个样本的水平行17c和具有m=4个样本的垂直列17a形成。因此,先验地,边界向量17p将具有尺寸p
×
1=12
×
1,而预测alwip矩阵应为q
×
p=32
×
12矩阵,因此使得需要q*p=32*12=384次乘法。
[0218]
然而,有可能例如对水平行17c的至少8个样本进行平均或者下采样,以获得仅具有4个样本(例如,经平均样本)的经缩减水平行。在一些示例中,垂直列17a将保持原样(例如不进行平均)。总而言之,经缩减边界将具有尺寸p
red
=8,其中p
red
《p。因此,边界向量17p将具有尺寸p
red
×
1=8
×
1。alwip预测矩阵17m将为具有尺寸m*n
red
*p
red
=4*4*8=64的矩阵。直接在进行步骤812时获得的4
×
4经缩减块(在方案107中通过灰色列形成)将具有大小q
red
=m*n
red
=4*4=16个样本(而非待预测的原始4
×
8块18的q=4*8=32)。一旦通过alwip获得经缩减4
×
4块,则有可能在步骤813处添加偏移量值bk(步骤812c)且执行内插。如可以在图7.3中的步骤813处看出,经缩减的4
×
4块扩增至4
×
8块18,其中未在步骤812处获得的值108'通过内插在步骤812处获得的值118'和118”(灰色正方形)而在步骤813处获得。
[0219]
因此,使用本发明技术与不使用本发明技术之间的比较是:
[0220]
在不具有本发明技术的情况下:
[0221]
待预测的块18,所述块具有尺寸m=4,n=8
[0222]
待预测的q=m*n=4*8=32个值;
[0223]
边界中的p=m n=4 8=12个样本;
[0224]
用于待预测的q=32个值中的每一个的p=12次乘法,
[0225]
p*q=12*32=384次的总数目
[0226]
乘法的数目与待获得的最终值的数目之间的比率是p*q/q=12
[0227]
在具有本发明技术的情况下:
[0228]
待预测的块18,所述块具有尺寸m=4,n=8
[0229]
待结束时预测的q=m*n=4*8=32个值;
[0230]
但可以使用q
red
×
p
red
=16
×
8 alwip矩阵,其中m=4,n
red
=4,q
red
=m*n
red
=16,p
red
=m n
red
=4 4=8
[0231]
边界中的p
red
=m n
red
=4 4=8个样本,其中p
red
《p
[0232]
用于待预测的经缩减块的q
red
=16个值中的每一个的p
red
=8次乘法,
[0233]qred
*p
red
=16*8=128次乘法的的总数目(小于384!)
[0234]
乘法的数目与待获得的最终值的数目之间的比率是p
red
*q
red
/q=128/32=4(比在不具有本发明技术的情况下获得的12小得多)。
[0235]
因此,在具有本发明技术的情况下,计算工作被缩减至三分之一。
[0236]
图7.4示出待预测的具有尺寸m
×
n=16
×
16且待在结束时预测的具有q=m*n=16*16=256个值的块18的情形,所述块具有p=m n=16 16=32个边界样本。此将产生具有尺寸q
×
p=256
×
32的预测矩阵,其将暗示256*32=8192次乘法!
[0237]
然而,通过应用方法820,有可能在步骤811处(例如通过平均或者下采样)将边界样本的数目例如从32缩减至8:例如,对于行17a的四个连续样本的每一组120,仍存在单个样本(例如,在四个样本之中选择的,或者样本的平均值)。同样,对于列17c的四个连续样本的每一组,仍存在单个样本(例如,在四个样本之中选择的,或者样本的平均值)。
[0238]
此处,alwip矩阵17m为q
red
×
p
red
=64
×
8矩阵:这是由于选择了p
red
=8(通过使用来自边界的32个样本的8个经平均或者选择的样本)的事实和待在步骤812处预测的经缩减块为8
×
8块(在方案109中,灰色正方形是64)的事实。
[0239]
因此,一旦在步骤812处获得经缩减8
×
8块的64个样本,则有可能在步骤813处导出待预测的块18的剩余的q-q
red
=256-64=192个值104。
[0240]
在此情形下,为了执行内插,已经选择使用边界列17a的所有样本和边界行17c中的仅替代的样本。可以进行其他选择。
[0241]
在具有本发明方法时,乘法的数目与最终获得值的数目之间的比率是q
red
*p
red
/q=8*64/256=2,其比在不具有本发明技术的情况下用于每一值的32次乘法小得多!
[0242]
使用本发明技术与不使用本发明技术之间的比较是:
[0243]
在不具有本发明技术的情况下:
[0244]
待预测的块18,所述块具有尺寸m=16,n=16
[0245]
待预测的q=m*n=16*16=256个值;
[0246]
边界中的p=m n=16*16=32个样本;
[0247]
用于待预测的q=256个值中的每一个的p=32次乘法,
[0248]
p*q=32*256=8192次乘法的总数目;
[0249]
乘法的数目与待获得的最终值的数目之间的比率是p*q/q=32
[0250]
在具有本发明技术的情况下:
[0251]
待预测的块18,所述块具有尺寸m=16,n=16
[0252]
待结束时预测的q=m*n=16*16=256个值;
[0253]
但是将使用q
red
×
p
red
=64
×
8 alwip矩阵,其中m
red
=4,n
red
=4,待通过alwip预测的q
red
=8*8=64个样本,p
red
=m
red
n
red
=4 4=8
[0254]
边界中的p
red
=m
red
n
red
=4 4=8个样本,其中p
red
《p
[0255]
用于待预测的经缩减块的q
red
=64个值中的每一个的p
red
=8次乘法,
[0256]qred
*p
red
=64*4=256次乘法的总数目(少于8192!)
[0257]
乘法的数目与待获得的最终值的数目之间的比率是pp
red
*q
red
/q=8*64/256=2
[0258]
(比在不具有本发明技术的情况下获得的32小得多)。
[0259]
因此,本发明技术所需的计算功率比传统技术少16倍。
[0260]
因此,有可能使用多个相邻样本(17)通过以下操作预测图像的预定块(18):
[0261]
缩减(100,813)多个相邻样本以获得相较于多个相邻样本(17)在样本数目上较低的经缩减样本值集合(102),
[0262]
对经缩减样本值集合(102)进行(812)线性或者仿射线性变换(19,17m)以获得用于预定块(18)的预定样本(104,118',188”)的经预测值。
[0263]
特别地,有可能通过下采样多个相邻样本以获得相较于多个相邻样本(17)在样本数目上较低的经缩减样本值集合(102)来执行缩减(100,813)。
[0264]
替代地,有可能通过平均多个相邻样本以获得相较于多个相邻样本(17)在样本数目上较低的经缩减样本值集合(102)来执行缩减(100,813)。
[0265]
此外,有可能通过内插基于用于预定样本(104,118',118”)和多个相邻样本(17)的经预测值来导出(813)用于预定块(18)的其他样本(108,108')的预测值。
[0266]
多个相邻样本(17a,17c)可以沿着预定块(18)的两个侧面(例如图7.1至图7.4中朝向右边和朝向下方)在一维上扩展。预定样本(例如通过alwip在步骤812中获得的样本)也可以以行和列配置,且沿着行和列中的至少一个,预定样本可以定位于从预定样本112的毗邻预定块18的两个侧面的样本(112)开始的每个第n位置处。
[0267]
基于多个相邻样本(17),有可能针对行和列中的至少一个中的每一个确定用于多个相邻位置中的一个(118)的支持值(118),所述支持值与行和列中的至少一个中的相应者对准。也有可能通过内插,基于用于预定样本(104,118',118”)的经预测值和用于相邻样本(118)的与行和列中的至少一个对准的支持值导出用于预定块(18)的其他样本(108,108')的预测值118。
[0268]
预定样本(104)可以沿着行定位于从毗连预定块18的两个侧面的样本(112)开始的每个第n位置处,且预定样本沿着列定位于从毗连预定块(18)的两个侧面的预定样本(112)的样本(112)开始的每个第m位置处,其中n、m》1。在一些情形下,n=m(例如,在图7.2和图7.3中,其中直接通过alwip在812处获得且利用灰色正方形指示的样本104、118'、118”沿着行和列交替至随后在步骤813处获得的样本108、108')。
[0269]
沿着行(17c)和列(17a)中的至少一个,可能例如通过针对每一支持值下采样或者平均(122)多个相邻样本内的相邻样本的组(120)来执行确定支持值,所述组包括确定相应支持值所针对的相邻样本(118)。因此,在图7.4中,在步骤813处,有可能通过使用预定样本118”'(先前在步骤812处获得)和相邻样本118的值作为支持值来获得样本119的值。
[0270]
多个相邻样本可以沿着预定块(18)的两个侧面在一维上扩展。可能通过将多个相邻样本(17)分组成一个或多个连续相邻样本的组(110)且对一个或多个相邻样本的组(110)中的每一个执行下采样或者平均来执行缩减(811),所述组具有两个或者多于两个相邻样本。
[0271]
在示例中,线性或者仿射线性变换可以包括p
red
*q
red
或者p
red
*q个加权因子,其中p
red
是经缩减样本值集合内的样本值(102)的数目,且q
red
或者q为预定块(18)内的预定样本
的数目。至少1/4 p
red
*q
red
或者1/4 p
red
*q个加权因子是非零加权值。p
red
*q
red
或者p
red
*q个加权因子可以针对q或者q
red
预定样本中的每一个包括关于相应预定样本的一系列p
red
个加权因子,其中所述系列当在预定块(18)的预定样本之中根据光栅扫描次序以一个在另一个下方的方式布置时,形成全向非线性的包络。p
red
*q或者p
red
*q
red
个加权因子可以经由任何普通的映射规则而彼此不相关。关于相应预定样本的第一系列的加权因子与关于除相应预定样本之外的预定样本的第二系列的加权因子或者后一系列的反向版本(不论哪种产生较高最大值)之间的交叉相关的最大值的均值低于预定阈值。预定阈值可以是0.3[或者在一些情形下是0.2或者0.1]。p
red
相邻样本(17)可以沿着一维路径(其沿着预定块(18)的两个侧面延伸)定位,且对于q或者q
red
个预定样本中的每一个,关于相应预定样本的所述系列的p
red
个加权因子以在预定方向上遍历一维路径的方式排序。
[0272]
6.1方法和装置的描述
[0273]
为了预测具有宽度w(也利用n指示)和高度h(也利用m指示)的矩形块的样本,仿射线性加权内预测(alwip)可以将在块左边的一列h个经重构相邻边界样本和块上方的一行w个经重构相邻边界样本作为输入。如果经重构样本不可用,则如在传统内预测中所做的那样来生成所述经重构样本。
[0274]
生成预测信号(例如,用于完整的块18的值)可以基于以下三个步骤中的至少一些:
[0275]
1.在边界样本17中,样本102(例如,在w=h=4的情形下的四个样本和/或在其他情形下的八个样本)可以通过平均或者下采样而获取(例如,步骤811)。
[0276]
2.可以利用经平均样本(或者从下采样剩余的样本)作为输入,来执行矩阵向量乘法,其后是添加偏移量。所述结果可以是关于原始块中的样本的次采样集合的经缩减预测信号(例如,步骤812)。
[0277]
3.可以例如通过上采样从关于次采样集合的预测信号例如通过线性内插生成剩余的位置处的预测信号(例如,步骤813)。
[0278]
由于步骤1.(811)和/或3.(813),在计算矩阵向量乘积时所需的乘法的总数目可以使得所述总数目一直小于或者等于4*w*h。此外,仅通过使用加法和位移位来执行对边界的平均操作和经缩减预测信号的线性内插。换言之,在示例中,alwip模式至多需要每个样本四次乘法。
[0279]
在一些示例中,生成预测信号所需的矩阵(例如,17m)和偏移量向量(例如,bk)可以取自矩阵集合(例如,三个集合),例如,s0、s1、s2,所述集合例如存储在解码器和编码器的存储单元中。
[0280]
在一些示例中,所述集合s0可以包括n0(例如,n0=16或者n0=18或者另一数目)矩阵i∈{0,
…
,n0-1}(例如,由其组成),所述矩阵中的每一个可以具有16行和4列以及各自具有大小16的18个偏移量向量i∈{0,
…
,n0-1},以根据图7.1执行所述技术。此集合的矩阵和偏移量向量是用于具有大小4
×
4的块18。一旦边界向量已经缩减至p
red
=4向量(对于图7.1的步骤811),则有可能将经缩减样本集合102的p
red
=4个样本直接映射至待预测的4
×
4块18的q=16样本中。
[0281]
在一些示例中,集合s1可以包括n1(例如,n1=8或者n1=18或者另一数目)矩阵i∈{0,...,n
1-1},(例如,由其组成),所述矩阵中的每一个可以具有16行和8列以及各自具
的块的尺寸四(p
red
=4)(图7.1的示例)和具有用于所有其他形状的块的大小八(p
red
=8)(图7.2至图7.4的示例)。
[0297]
此处,如果mode<18(或者矩阵集合中的矩阵的数目),则有可能限定
[0298][0299]
如果mode≥18,其对应于mode-17的经转置的模式,则有可能限定
[0300][0301]
因此,根据特定状态(一个状态:mode<18;另一状态:mode≥18),有可能沿着不同扫描次序(例如,一个扫描次序:另一扫描次序:)分配输出向量的经预测值。
[0302]
可以执行其他策略。在其他示例中,模式索引“mode”不必在0至35的范围(可以限定其他范围)内。此外,不必三个集合s0、s1、s2中的每一个具有18个矩阵(因此,代替如mode≥18的表达,mode≥n0,n1,n2是可能的,所述mode分别是每一矩阵集合s0、s1、s2的矩阵的数目)。此外,所述集合可以各自具有不同数目个矩阵(例如,s0可以具有16个矩阵、s1可以具有八个矩阵,且s2可以具有六个矩阵)。
[0303]
模式和经转置信息未必作为一个组合模式索引“mode”来存储和/或传输:在一些示例中,有可能作为经转置标志和矩阵索引(用于s0的0-15、用于s1的0-7和用于s2的0-5)明确地用信号通知。
[0304]
在一些情形下,经转置标志和矩阵索引的组合可以被解释为设置索引。举例而言,可以存在作为经转置标志操作的一个位和指示矩阵索引的一些位,所述位被合起来指示为“设置索引”。
[0305]
6.3通过矩阵向量乘法生成经缩减预测信号
[0306]
此处,提供关于步骤812的特征。
[0307]
在经缩减输入向量bdry
red
(边界向量17p)中,我们可以生成经缩减预测信号pred
red
。后者信号可以是关于具有宽度w
red
和高度h
red
的经下采样的块的信号。此处,w
red
和h
red
可以被限定为:
[0308]wred
=4,h
red
=4;如果max(w,h)≤8,
[0309]
否则,w
red
=min(w,8),h
red
=min(h,8)。
[0310]
可以通过计算矩阵向量乘积和添加偏移量来计算经缩减预测信号pred
red
:
[0311]
pred
red
=a
·
bdry
red
b。
[0312]
此处,a为矩阵(例如,预测矩阵17m),其可以具有w
red
*h
red
行和4列(如果w=h=4,且在所有其他情形下为8列),且b是可以具有大小w
red
*h
red
的向量。
[0313]
如果w=h=4,则a可以具有4列和16行,且因此在该情形下可以需要每个样本4次乘法以计算pred
red
。在所有其他情形下,a可以具有8列,且无人可以证实在这些情形下,我们具有8*w
red
*h
red
≤4*w*h,亦即也在这些情形下,至多需要每个样本4次乘法以计算pred
red
。
[0314]
矩阵a和向量b可以如下取自集合s0、s1、s2中的一个。我们通过在w=h=4的情况下设置idx(w,h)=0、在max(w,h)=8的情况下设置idx(w,h)=1、以及在所有情形下设置idx(w,h)=2,我们限定索引idx=idx(w,h)。此外,我们可以在mode<18的情况下使m=mode,
否则使m=mode-17。随后,如果idx≤1或者idx=2且min(w,h)>4,则我们可以使目在idx=2且min(w,h)=4的情形下,我们使a为矩阵,其通过舍弃每一行而产生,所述每一行在w=4的情形下对应于经下采样块中的奇数x坐标或者在h=4的情形下对应于经下采样块中的奇数y坐标。如果mode≥18,则我们通过经缩减预测信号的经转置信号来代替所述经缩减预测信号。在替代性示例中,可以执行不同策略。举例而言,代替缩减较大矩阵的大小(“舍弃”),使用较小矩阵s1(idx=1),其中w
red
=4且h
red
=4。亦即,现在将此类块指派给s1而非s2。
[0315]
可以执行其他策略。在其他示例中,模式索引“mode”不必在0至35的范围内(可以限定其他范围)。此外,不必三个集合s0、s1、s2中的每一个具有18个矩阵(因此,代替如mode<18的表达,mode<n0,n1,n2是可能的,所述mode分别是每一矩阵集合s0、s1、s2的矩阵的数目)。此外,所述集合可以各自具有不同数目个矩阵(例如,s0可以具有16个矩阵、s1可以具有八个矩阵,且s2可以具有六个矩阵)。
[0316]
6.4用于生成最终预测信号的线性内插
[0317]
此处,提供关于步骤812的特征。
[0318]
关于较大块的次采样预测信号的内插,可能需要经平均边界的第二版本。亦即,如果min(w,h)>8且w≥h,则我们撰写w=8*2
l
,且对于0≤i<8,限定
[0319][0320]
如果min(w,h)>8且h>w,则我们类似地限定
[0321]
额外地或者替代地,有可能具有“硬下采样”,其中等于
[0322][0323]
而且,可以类似地限定
[0324]
在生成pred
red
时舍弃的样本位置处,最终预测信号可以通过线性内插从pred
red
产生(例如,图7.2至图7.4的示例中的步骤813)。在一些示例中,如果w=h=4,则此线性内插可以是不必要的(例如,图7.1的示例)。
[0325]
线性内插可以如下给定(尽管如此,其他示例是可能的)。假设w≥h。随后,如果h>h
red
,则可以执行pred
red
的垂直上采样。在该情形下,pred
red
可以如下扩展一列至顶部。如果w=8,则pred
red
可以具有宽度w
red
=4且可以通过经平均边界信号扩展至顶部,例如如上文所限定。如果w>8,则pred
red
具有宽度w
red
=8,且其通过经平均边界信号扩展至顶部,例如如上文所限定。我们可以针对第一列pred
red
写入pred
red
[x][-1]。随后,关于具有宽度w
red
和高度2*h
red
的块的信号可以给定为
[0326][0327][0328]
其中0≤x<w
red
且0≤y<h
red
。后一过程可以执行k次,直至2k*h
red
=h为止。因此,如果h=8或者h=16,则其至多可以执行一次。如果h=32,则其可以执行二次。如果h=64,则其可以执行三次。接下来,水平上采样运算可以应用于所述垂直上采样的结果。后者的上采样运算可以使用预测信号左边的全部边界。最终,如果h>w,则我们可以通过首先在水平
方向上(必要时)且随后在垂直方向上上采样而类似地继续进行。
[0329]
这是使用用于第一内插(水平地或者垂直地)的经缩减边界样本和用于第二内插(垂直地或者水平地)的原始边界样本进行内插的示例。取决于块大小,仅需要第二内插或者不需要内插。如果需要水平和垂直内插,则所述次序取决于块的宽度和高度。
[0330]
然而,可以实施不同技术:例如,原始边界样本可用于第一和第二内插,且所述次序可以是固定的,例如首先水平随后垂直(在其他情形下,首先垂直随后水平)。
[0331]
因此,经缩减/原始边界样本的内插次序(水平/垂直)和使用可以变化。
[0332]
6.5整个alwip过程的示例的说明
[0333]
针对图7.1至图7.4中的不同形状说明平均、矩阵向量乘法和线性内插的整个过程。注意,剩余的形状被视为所描绘情形中的一个。
[0334]
1.给定4
×
4块,alwip可以通过使用图7.1的技术而采用沿着边界的每一轴线的两个平均值。所得四个输入样本进入矩阵向量乘法。矩阵是取自集合s0。在添加偏移量之后,这可以产生16个最终预测样本。线性内插不必生成预测信号。因此,每个样本执行总共(4*16)/(4*4)=4次乘法。参见例如图7.1。
[0335]
2.给定8
×
8块,alwip可以采用沿着边界的每一轴线的四个平均值。所得八个输入样本通过使用图7.2的技术进入矩阵向量乘法。矩阵是取自集合s1。此会在预测块的奇数位置上产生16个样本。因此,每个样本执行总共(8*16)/(8*8)=2次乘法。在添加偏移量之后,可以例如通过使用顶部边界垂直地和例如通过使用左边边界水平地内插这些样本。参见例如图7.2。
[0336]
3.给定8
×
4块,alwip可以通过使用图7.3的技术而采用沿着边界的水平轴线的四个平均值和在左边边界上的四个原始边界值。所得八个输入样本进入矩阵向量乘法。矩阵是取自集合s1。此会在预测块的奇数水平位置和每一垂直位置上产生16个样本。因此,每个样本执行总共(8*16)/(8*4)=4次乘法。在添加偏移量之后,例如通过使用左边边界水平地内插这些样本。参见例如图7.3。
[0337]
相应地处理经转置情形。
[0338]
4.给定16
×
16块,alwip可以采用沿着边界的每一轴线的四个平均值。所得八个输入样本通过使用图7.2的技术进入矩阵向量乘法。矩阵是取自集合s2。此会在预测块的奇数位置上产生64个样本。因此,每个样本执行总共(8*64)/(16*16)=2次乘法。在添加偏移量之后,例如,通过使用顶部边界垂直地和通过使用左边边界水平地内插这些样本。参见例如图7.2。参见例如图7.4。
[0339]
对于较大形状,所述过程可以基本上相同,且容易检查每个样本的乘法的数目小于二。
[0340]
对于w
×
8块,仅水平内插是必需的,因为在奇数水平和每一垂直位置处给定样本。因此,在这些情形下,每个样本至多执行(8*64)/(16*8)=4次乘法。
[0341]
最终对于w
×
4块(其中w>8),使ak为通过舍弃对应于沿着经下采样块的水平轴线的奇数项的每一行而出现的矩阵。因此,所述输出大小可以是32,并且再次,仅剩下水平内插待执行。可以针对每样本至多执行(8*32)/(16*4)=4次乘法。
[0342]
可以相应地处理经转置情形。
[0343]
6.6所需参数的数目和复杂性评估
[0344]
针对所有可能的所提议的内预测模式所需的参数可以包括属于集合s0、s1、s2的矩阵和偏移量向量。所有矩阵系数和偏移量向量可以存储为10位值。因此,根据以上描述,所提议的方法可需要14400个参数的总数目,每一参数的精确度为10位。此对应于0,018兆字节的存储器。指出,当前,标准4:2:0色度次采样中的具有大小128
×
128的ctu由24576个值组成,每一值为10位。因此,所提议的内预测工具的存储器要求不超过在上一次会议上采用的当前图像参考工具的存储器要求。而且,指出,由于pdpc工具或者具有分数角度位置的角预测模式的4抽头内插滤波器,传统内预测模式需要每个样本四次乘法。因此,就可以操作复杂性而言,所提议的方法不超过传统内预测模式。
[0345]
6.7所提议的内预测模式的信号通知
[0346]
对于明度块,例如提议35个alwip模式(可以使用其他数目个模式)。对于内模式中的每一编码单元(cu),在位流中发送指示是否在对应的预测单元(pu)上应用alwip模式。后一索引的信号通知可以以与第一ce测试相同的方式与mrl协调。如果应用alwip模式,则alwip模式的索引predmode可以使用具有3个mpm的mpm列表来信号通知。
[0347]
此处,可以如下使用上方和左边pu的内模式来执行mpm的导出。可以存在表格,例如三个固定表格map_angular_to_alwip
idx
,idx∈{0,1,2},其可以被指派给每一传统内预测模式predmode
angular
、alwip模式
[0348]
predmode
alwip
=map_angular_to_alwip
idx
[predmode
angular
]。
[0349]
对于具有宽度w和高度h的每一pu,我们限定并且索引
[0350]
idx(pu)=idx(w,h)∈{0,1,2}
[0351]
其指示从三个集合中的哪一个获取alwip参数,如以上章节4中所述。如果以上预测单元pu
above
是可用的、属与当前pu相同的ctu并且处于内模式、如果idx(pu)=idx(pu
above
)且如果在具有alwip模式的pu
above
上应用alwip,则我们使得
[0352][0353]
如果以上pu是可用的,则其属与当前pu相同的ctu且处于内模式,且如果在以上pu上应用传统内预测模式则我们使
[0354][0355]
在所有其他情形下,我们使
[0356][0357]
这意味着此模式是不可用的。以相同方式但不限制左边pu需要属于与当前pu相同的ctu,我们导出模式
[0358][0359]
最终,提供三个固定默认列表list
idx
,idx∈{0,1,2},所述列表中的每一个包含三个不同alwip模式。在默认列表list
idx(pu)
和模式和之中,我们通过用默认值替换-1以及去除重复来构建三个不同的mpm。
[0360]
本文中所描述的实施例不受所提议的内预测模式的上文所描述的用信号通知限制。根据替代性实施例,无mpm和/或映射表用于mip(alwip)。
[0361]
6.8用于传统明度(luma)和色度(chroma)内预测模式的经适配mpm列表导出
[0362]
所提议的alwip模式可以如下与传统内预测模式的基于mpm的编码协调。用于传统内预测模式的明度和色度mpm列表导出过程可以使用固定的表格map_lwip_to_angular
idx
,idx∈{0,1,2},从而将给定pu上的alwip模式predmode
lwip
映射至传统内预测模式中的一个
[0363]
predmode
angular
=map_lwip_to_angular
idx(pu)
[predmode
lwip
]。
[0364]
对于明度mpm列表导出,每当遇到使用alwip模式predmode
lwip
的相邻明度块时,此块可以被视为如同其正使用传统内预测模式predmode
angular
。对于色度mpm列表导出,每当当前明度块使用lwip模式时,相同映射可用于将alwip模式转变为传统内预测模式。
[0365]
清楚的是,也可以在不使用mpm和/或映射表的情况下将alwip模式与传统内预测模式相协调。举例而言,可能对于色度块,每当当前明度块使用alwip模式时,alwip模式被映射到平面内预测模式。
[0366]
7.实施有效实施例
[0367]
简要地概述以上示例,因为其可能在下文形成用于进一步扩展本文中所描述的实施例的基础。
[0368]
为了预测图像10的预定块18,在使用多个相邻样本的情况下,使用17a、17c。
[0369]
通过平均,已经进行多个相邻样本的缩减100以获得相较于多个相邻样本在样本数目上较低的经缩减样本值集合102。此缩减在本文中的实施例中是可选的,且会产生在下文中提及的所谓的样本值向量。经缩减样本值集合进行线性或者仿射线性变换19以获得用于预定块的预定样本104的经预测值。此变换稍后使用矩阵a和偏移量向量b指示并且应为效地预先形成的实施,所述矩阵a和偏移量向量b已经通过机器学习(ml)获得。
[0370]
通过内插,基于用于预定样本和多个相邻样本的经预测值导出用于预定块的其他样本108的预测值。应该说,理论上,仿射/线性变换的结果可以与块18的非全像素样本位置相关联,使得根据替代性实施例,可以通过内插获得块18的所有样本。也根本不需要内插。
[0371]
多个相邻样本可能沿着预定块的两个侧面在一维上延伸,预定样本以行和列且沿着行和列中的至少一个配置,其中预定样本可以定位于从预定样本的毗邻预定块的两个侧面的样本(112)开始的每个第n位置处。基于多个相邻样本,对于行和列中的至少一个中的每一个,可以确定用于多个相邻位置中的一个(118)的支持值,所述支持值与行和列中的至少一个中的相应者对准,并且通过内插,可以基于用于预定样本的经预测值和用于相邻样本的与行和列中的至少一个对准的支持值导出用于预定块的其他样本108的预测值。预定样本可以沿着行定位于从预定样本的毗连预定块的两个侧面的样本112开始的每个第n位置处,且预定样本可以沿着列定位于从预定样本的毗连预定块的两个侧面的样本112开始的每个第m位置处,其中n,m》1。可能n=m。沿着行和列中的至少一个,可以通过针对每一支持值平均(122)多个相邻样本内包括确定相应支持值所针对的相邻样本118的相邻样本的组120来确定所述支援值。多个相邻样本可以沿着预定块的两个侧面在一维上扩展,且通过将多个相邻样本分组成一个或多个连续相邻样本的组110并且对具有多于两个相邻样本的一个或多个相邻样本的组中的每一个执行平均而进行缩减。
[0372]
对于预定块,可以在数据流中传输预测残差。预测残差可以从解码器处的数据流导出,且预定块可以使用用于预定样本的预测残差和经预测值来重构。在编码器处,预测残差经编码成编码器处的数据流。
[0373]
所述图像可以细分成具有不同块大小的多个块,所述多个块包括预定块。随后,可
能取决于预定块的宽度w和高度h选择用于块18的线性或者仿射线性变换,使得在第一组线性或者仿射线性变换之中选择针对预定块选择的线性或者仿射线性变换,只要预定块的宽度w和高度h是在第一组宽度/高度配对和第二组线性或者仿射线性变换内,只要预定块的宽度w和高度h是在不与第一组宽度/高度配对相交的第二组宽度/高度配对内。再次,随后变得清楚的是,仿射/线性变换是借助于参数(亦即c的权重,且可选地,偏移量和尺度参数)表示。
[0374]
解码器和编码器可以被配置为:将图像细分成具有不同块大小的多个块,包括预定块;和取决于预定块的宽度w和高度h选择线性或者仿射线性变换,使得在以下各项之中选择针对预定块选择的线性或者仿射线性变换
[0375]
第一组线性或者仿射线性变换,只要预定块的宽度w和高度h是在第一组宽度/高度配对内,
[0376]
第二组线性或者仿射线性变换,只要预定块的宽度w和高度h是在不与第一组宽度/高度配对相交的第二组宽度/高度配对内,和
[0377]
第三组线性或者仿射线性变换,只要预定块的宽度w和高度h是在不与第一组和第二组宽度/高度配对相交的第三组一个或多个宽度/高度配对内。
[0378]
第三组一个或多个宽度/高度配对仅仅包括一个宽度/高度配对w'、h',且第一组线性或者仿射线性变换内的每一线性或者仿射线性变换是用于将n'样本值变换为用于w'
×
h'样本位置阵列的w'*h'经预测值。
[0379]
第一和第二组宽度/高度配对中的每一个可以包括w
p
不等于h
p
的第一宽度/高度配对w
p
、h
p
,和hq=w
p
且wq=h
p
的第二宽度/高度配对wq、hq。
[0380]
第一和第二组宽度/高度配对中的每一个可以额外包括w
p
等于h
p
且h
p
》hq的第三宽度/高度配对w
p
、h
p
。
[0381]
对于预定块,设置索引可以在数据流中传输,所述数据流指示针对块18在一组预定线性或者仿射线性变换之中选择哪一线性或者仿射线性变换。
[0382]
多个相邻样本可以沿着预定块的两个侧面在一维上扩展,且可以通过针对邻接预定块的第一侧面的多个相邻样本的第一子集将第一子集分组成一个或多个连续相邻样本的第一组110,以及针对邻接预定块的第二侧面的多个相邻样本的第二子集将第二子集分组成一个或多个连续相邻样本的第二组110、并且对具有多于两个相邻样本的一个或多个相邻样本的第一和第二组中的每一个执行平均,来进行缩减,以获得来自第一组的第一样本值和来自第二组的第二样本值。随后,可以取决于设置索引而在一组预定线性或者仿射线性变换之中选择线性或者仿射线性变换,使得设置索引的两个不同状态导致选择线性或者仿射线性变换的预定集合中的线性或者仿射线性变换中的一个,在设置索引采用呈第一向量的形式的两个不同状态中的第一状态的情形下,经缩减样本值集合可以进行预定线性或者仿射线性变换以产生经预测值的输出向量,并且沿着第一扫描次序将输出向量的经预测值分配至预定块的预定样本上,且在设置索引采用呈第二向量的形式的两个不同状态中的第二状态的情形下,第一和第二向量不同,使得由第一向量中的第一样本值中的一个填充的分量是由第二向量中的第二样本值中的一个填充,并且由第一向量中的第二样本值中的一个填充的分量是由第二向量中的第一样品值中的一个填充,以便产生经预测值的输出向量,并且沿着第二扫描次序将输出向量的经预测值分配至预定块的预定样本上,所述预
定块相对于第一扫描次序转置。
[0383]
第一组线性或者仿射线性变换内的每一线性或者仿射线性变换可用于针对样本位置的w1×
h1阵列将n1样本值变换为w1*h1个经预测值,且第一组线性或者仿射线性变换内的每一线性或者仿射线性变换是用于针对样本位置的w2×
h2阵列将n2样本值变换为w2*h2个经预测值,其中对于第一组宽度/高度配对中的第一预定宽度/高度配对,w1可以超过第一预定宽度/高度配对的宽度或者h1可以超过第一预定宽度/高度配对的高度,并且对于第一组宽度/高度配对中的第二预定宽度/高度配对,w1无法超过第二预定宽度/高度配对的宽度,h1也无法超过第二预定宽度/高度配对的高度。随后可以通过平均对多个相邻样本进行缩减(100)以获得经缩减样本值集合(102),使得在预定块具有第一预定宽度/高度配对的情况下且在预定块具有第二预定宽度/高度配对的情况下经缩减样本值集合102具有n1个样本值,且在预定块具有第一预定宽度/高度配对的情况下可以在w1超过一个宽度/高度配对的宽度的情况下沿着宽度尺寸或者在h1超过一个宽度/高度配对的高度的情况下沿着高度尺寸通过仅使用与样本位置的w1
×
h1阵列的次采样有关的选定的线性或者仿射线性变换的第一子部分来使经缩减样本值集合进行选定的线性或者仿射线性变换,且在预定块具有第二预定宽度/高度配对的情况下使经缩减样本值集合彻底地进行选定的线性或者仿射线性变换。
[0384]
第一组线性或者仿射线性变换内的每一线性或者仿射线性变换可用于针对w1=h1的样本位置的w1×
h1阵列将n1个样本值变换为w1*h1个经预测值,且第二组线性或者仿射线性变换内的每一线性或者仿射线性变换是用于针对w2=h2的样本位置的w2×
h2阵列将n2个样本值变换为w2*h2个经预测值。
[0385]
所有上文所描述的实施例仅仅为说明性的,因为其可以在下文形成用于本文中所描述的实施例的基础。亦即,以上概念和细节应用于理解以下实施例并且应在下文充当本文中所描述的实施例的可能扩展和修改的储库。具体来讲,许多上文所描述的细节是可选的,诸如相邻样本的平均、相邻样本用作参考样本的事实等等。
[0386]
更一般而言,本文中所描述的实施例假设从已经重构的样本生成关于矩形块的预测信号,诸如从块左边和上方的相邻的已经重构的样本生成关于矩形块的内预测信号。预测信号的生成是基于以下步骤。
[0387]
1.在被称作边界样本的参考样本中,但不排除将描述转移至定位在别处的参考样本,可以通过平均来获得样本。此处,针对块左边和上方的边界样本或者仅针对两个侧面中的一个上的边界样本来执行平均。如果在侧面上不执行平均,则该侧面上的样本保持不变。
[0388]
2.执行矩阵向量乘法,可选地其后是添加偏移量,其中矩阵向量乘法的输入向量是在仅在左侧应用平均的情况下的块左边的经平均边界样本与块上方的原始边界样本的级联,或者在仅在以上侧面上应用平均的情况下的块左边的原始边界样本与块上方的经平均边界样本的级联或者在仅在块的两侧上应用平均的情况下块左边的经平均边界样本与块上方的经平均边界样本的级联。再次,将存在替代方案,诸如完全不使用平均的替代方案。
[0389]
3.矩阵向量乘法和可选的偏移量添加的结果可以可选地是关于原始块中的次采样样本集的经缩减预测信号。剩余的位置处的预测信号可以通过线性内插从关于次采样的集合的预测信号生成。
[0390]
步骤2中的矩阵向量乘积的计算应优选地以整数算术来执行。因此,如果x=(x1,
…
,xn)表示用于矩阵向量乘积的输入,亦即x表示块左边和上方的(经平均)边界样本的级联,则在x之中,应仅使用位移位、添加偏移量向量和整数乘法来计算在步骤2中计算的(经缩减)预测信号。理想地,步骤2中的预测信号将给定为ax b,其中b是可以为零的偏移量向量,且其中a通过某种基于机器学习的训练算法导出。然而,此训练算法通常仅产生以浮点精确度给定的矩阵a=a
float
。因此,我们面临在前述意义上指定整数运算使得表达式a
float
x使用这些整数运算被很好地近似的问题。此处,重要的是要提到,这些整数运算不必被选择为使得其近似假设向量x的均匀分布的表达式a
float
x,但通常考虑到表达式a
float
x将近似的输入向量x为来自自然视频信号的(经平均)边界样本,其中我们可以预期x的分量xi之间的一些相关性。
[0391]
图8示出用于使用多个参考样本17预测图像10的预定块18的装置1000的实施例。多个参考样本17可以取决于由装置1000使用以预测预定块18的预测模式。如果预测模式为例如内预测,则可以使用邻近预定块的参考样本171。换言之,多个参考样本17例如沿着预定块18的外边缘配置于图像10内。如果预测模式为例如间预测,则可以使用另一图像10'之中的参考样本172。
[0392]
装置1000被配置为从多个参考样本17形成100样本值向量400。样本值向量可以通过不同技术获得。样本值向量可以例如包括所有参考样本17。可选地,所述参考样本可以被加权。根据另一示例,可以如关于图7.1至图7.4中的一个针对样本值向量102所描述的那样来形成样本值向量400。换言之,样本值向量400可以通过平均或者下采样而形成。因此,例如,参考样本的组可以被平均以获得具有经缩减值集合的样本值向量400。换言之,所述装置例如被配置为通过针对样本值向量400的每一分量采用多个参考样本17中的一个参考样本作为样本值向量的相应分量和/或平均样本值向量400的两个或者多于两个分量,亦即平均多个参考样本17的两个或者多于两个参考样本以获得样本值向量400的相应分量而从多个参考样本17形成100样本值向量102。
[0393]
装置1000被配置为从样本值向量400导出401另一向量402,样本值向量400通过预定可逆线性变换403被映射到所述另一向量上。另一向量402仅包括例如整数和/或定点值。举例而言,选择可逆线性变换403使得通过整数算术或者定点算术执行预定块18的样本的预测。
[0394]
此外,装置1000被配置为计算另一向量402与预定预测矩阵405之间的矩阵向量乘积404以获得预测向量406,并且基于预测向量406预测预定块18的样本。基于有利的另一向量402,预定预测矩阵可以被量化以使得能够进行整数和/或定点运算,其中量化错误仅稍微影响预定块18的经预测样本。
[0395]
根据一实施例,装置1000被配置为使用定点算术运算来计算矩阵向量乘积404。替代地,可以使用整数运算。
[0396]
根据一实施例,装置1000被配置为在不使用浮点算术运算的情况下计算矩阵向量乘积404。
[0397]
根据一实施例,装置1000被配置为存储预定预测矩阵405的定点数表示。额外地或者替代地,可以存储预定预测矩阵405的整数表示。
[0398]
根据一实施例,装置1000被配置为在基于预测向量406预测预定块18的样本时使
用内插以基于预测向量406来计算预定块18的至少一个样本位置,所述预测向量406的每一分量与预定块18内的对应位置相关联。可以如关于图7.1至图7.4中所示出的实施例中的一个所描述那样来执行内插。
[0399]
图9示出本文中所描述的发明的想法。可以基于通过某种基于机器学习的训练算法导出的矩阵a 1100与样本值向量400之间的第一矩阵向量乘积来预测预定块的样本。可选地,可以添加偏移量b 1110。为了实现此第一矩阵向量乘积的整数近似或者定点近似,样本值向量可以进行可逆线性变换403以确定另一向量402。另一矩阵b 1200与另一向量402之间的第二矩阵向量乘积可以等于第一矩阵向量乘积的结果。
[0400]
由于另一向量402的特征,第二矩阵向量乘积可以是通过预定预测矩阵c 405与另一向量402加上另一偏移量408之间的矩阵向量乘积404近似的整数。另一向量402和另一偏移量408可以由整数或者定点值组成。举例而言,另一偏移量的所有分量是相同的。预定预测矩阵405可以是经量化的矩阵或者待量化的矩阵。预定预测矩阵405与另一向量402之间的矩阵向量乘积404的结果可以理解为预测向量406。
[0401]
在下文中,提供关于此整数近似的更多细节。
[0402]
根据实施例i的可能解决方案:减去和加上平均值
[0403]
在以上情境中可使用的表达式a
float
x的整数近似的一种可能整合是通过x的分量的平均值mean(x)(亦即预定值1400)来替换x(亦即样本值向量400)的第i0分量亦即预定分量1500,并且从所有其他分量减去此平均值。换言之,限定如图10a中所示出的可逆线性变换403使得另一向量402的预定分量1500变成a,且另一向量402的其他分量中的每一个(除了预定分量1500之外)等于样本值向量的对应分量减去a,其中a为预定值1400,其例如为样本值向量400的分量的平均值,诸如算术平均值或者加权平均值。对于所述输入的此运算是通过可逆变换t403给定的,所述可逆变换尤其在x的尺寸n为二的幂的情况下具有明显的整数实施。
[0404]
由于a
float
=(a
float
t-1
)t,因此如果我们对输入x进行此变换,则我们必须找到矩阵向量乘积by的积分近似,其中b=(a
float
t-1
)且y=tx。由于矩阵向量乘积a
float
x表示关于矩形块(亦即预定块)的预测,且由于x包括该块的(例如,经平均)边界样本,因此我们应预期在x的所有样本值相等的情形下,亦即在针对所有i,xi=mean(x)的情况下,预测信号a
float
x中的每一样本值应接近mean(x)或者确切地等于mean(x)。这意味着,我们应预期b(亦即另一矩阵1200)的第i0列,亦即对应于预定分量的列,极接近或者等于仅由一组成的列。因此,如果m(i0),亦即整数矩阵1300,是第i0列由一组成且所有其他列为零的矩阵,从而撰写by=cy m(i0)y和c=b-m(i0),则我们应预期c(亦即预定预测矩阵405)的第i0列具有实际上较小项或者为零,如图10b中所示出。此外,由于x的分量相关,因此我们可以预期对于每一i≠i0,y的第i分量yi=x
i-mean(x)常常具有比x的第i分量小得多的绝对值。由于矩阵m(i0)为整数矩阵,因此在给定cy的整数近似的情况下实现by的整数近似,且通过以上自变量,我们可以预期通过以合适方式量化c的每一项而产生的量化错误将仅稍微影响在a
float
x的by响应的结果量化中的错误。
[0405]
预定值1400不必是平均值mean(x)。表达式a
float
x的本文中所描述的整数近似也可以利用预定值1400的以下替代的定义来实现:
[0406]
在表达式a
float
x的整数近似的另一可能整合中,x的第i0分量保持不变,且从所
有其他分量减去同一值亦即,对于每一i≠i0,且换言之,预定值1400可以是样本值向量400的对应于预定分量1500的分量。
[0407]
替代地,预定值1400为默认值或者在图像编码而成的数据流中用信号通知的值。
[0408]
预定值1400等于例如2
bitdepth-1
。在此情形下,另一向量402可以由y0=2
bitdepth-1
和yi=x
i-x0限定,其中i>0。
[0409]
替代地,预定分量1500变为常数减去预定值1400。常数等于例如2
bitdepth-1
。根据一实施例,另一向量y 402的预定分量1500等于2
bitdepth-1
减去样本值向量400对应于预定分量1500的分量且另一向量402的所有其他分量等于样本值向量400的对应分量减去样本值向量400的对应于预定分量1500的分量。
[0410]
举例而言,预定值1400与预定块的样本的预测值具有较小偏差是有利的。
[0411]
根据一实施例,装置1000被配置为包括多个可逆线性变换403,所述可逆线性变换中的每一个与另一向量402的一个分量相关联。此外,所述装置例如被配置为从样本值向量400的分量之中选择预定分量1500并且使用多个可逆线性变换中的与预定分量1500相关联的可逆线性变换403作为预定可逆线性变换。这例如是由于第i0行(亦即对应于预定分量的可逆线性变换403的行)的不同位置,这取决于另一向量402中的预定分量的位置。如果例如另一向量402的第一分量,亦即y1,是预定分量,则第i0行将替代可逆线性变换的第一行。
[0412]
如图10b中所示出,预定预测矩阵405的列412(亦即第i0列)内的预测矩阵c 405的矩阵分量414(其对应于另一向量402的预定分量1500)例如均为零。在此情形下,所述装置例如被配置为通过以计算通过舍弃列412而从预定预测矩阵c 405产生的经缩减预测矩阵c
′
405与通过舍弃预定分量1500而从另一向量402产生的又一向量410之间的矩阵向量乘积407的方式执行乘法,来计算矩阵向量乘积404,如图10c中所示出。因此,预测向量406可以利用较少乘法来计算。
[0413]
如图9、图10b和图10c中所示出,装置1000可以被配置为在基于预测向量406预测预定块的样本时针对预测向量406的每一分量计算相应分量与a(亦即预定值1400)的总和。该求和可以由预测向量406与向量409的总和表示,其中向量409的所有分量等于预定值1400,如图9和图10c中所示出。替代地,所述求和可以由预测向量406同整数矩阵m 1300与另一向量402之间的矩阵向量乘积1310的总和表示,如图10b中所示出,其中整数矩阵1300的矩阵分量为整数矩阵1300的列内的1,亦即第i0列,所述矩阵分量对应于另一向量402的预定分量1500,且所有其他分量例如为零。
[0414]
预定预测矩阵405与整数矩阵1300的求和的结果等于或者近似于例如图9中所示出的另一矩阵1200。
[0415]
换言之,通过将预定预测矩阵c 405的在预定预测矩阵405的一列412(亦即第i0列)内的与另一向量402的预定分量1500对应每一矩阵分量与一进行求和而产生的矩阵(亦即矩阵b),亦即另一矩阵b 1200,乘以可逆线性变换403,对应于例如机器学习预测矩阵a 1100的经量化版本,如图9、图10a和图10b中所示出。预定预测矩阵c 405的第i0列412内的每一矩阵分量与一的求和可以对应于预定预测矩阵405与整数矩阵1300的求和,如图10b中所示出。如图9中所示出,机器学习预测矩阵a 1100可以等于另一矩阵1200乘以可逆线性变换403的结果。这是由于a
·
x=bt
·
yt-1
。预定预测矩阵405例如是经量化矩阵、整数矩阵和/或定点矩阵,由此可以实现机器学习预测矩阵a 1100的经量化版本。
[0416]
仅使用整数运算的矩阵乘法
[0417]
对于低复杂性实施(就加上以及乘以纯量值的复杂性而言,以及就所涉及矩阵的各项所需的存储而言),需要仅使用整数算术来执行矩阵乘法404。
[0418]
为了计算z=cy的近似,亦即
[0419][0420]
在仅使用整数运算的情况下,根据一实施例,实值c
i,j
必须映射至整数值这可以例如通过均一的纯量量化,或者通过考虑值yi之间的特定相关性来进行。整数值表示例如定点数,其每一个可以以固定数目的位n_bit来存储,例如n_bit=8。
[0421]
随后可以如在此伪代码中所示这样执行与具有大小m
×
n的矩阵(亦即预定预测矩阵405)的矩阵向量乘积404,其中<<,>>是算术二进制左移位运算和右移位运算,且 、-和*仅对整数值进行运算。
[0422]
(1)
[0423][0424]
此处,阵列c,亦即预定预测矩阵405,将定点数字存储作为例如整数。final_offset的最终添加和right_shift_result的右移位运算通过舍位来降低精确度,以获得输出处所需的定点格式。
[0425]
为了允许可以由c中的整数表示的实值的增加范围,可以使用两个额外矩阵offset
i,j
和scale
i,j
,如图11和图12的实施例中所示出,使得矩阵向量乘积
[0426][0427]
中的yj的每一系数b
i,j
是由下式给定
[0428][0429]
值offset
i,j
和scale
i,j
自身是整数值。举例而言,这些整数可以表示定点数,其可以各自以固定数目的位(例如8个位)或者以例如相同数目的位n_bit(其用于存储值)来
存储。
[0430]
换言之,装置1000被配置为使用预测参数(例如整数值以及值offset
i,j
和scale
i,j
)表示预定预测矩阵405且通过对另一向量402的分量和预测参数以及从其产生的中间结果执行乘法以及求和而计算矩阵向量乘积404,其中预测参数的绝对值可以由n位定点数表示来表示,其中n等于或者低于14,或者替代地等于或者低于10,或者替代地等于或者低于8。举例而言,另一向量402的分量乘以预测参数以产生作为中间结果的乘积,其又进行求和或者形成求和的加数。
[0431]
根据一实施例,预测参数包括权重,其中的每一个是与预测矩阵的对应矩阵分量相关联。换言之,预定预测矩阵例如由预测参数替代或者表示。所述权重例如为整数和/或定点值。
[0432]
根据一实施例,预测参数进一步包括一个或多个缩放因子,例如值scale
i,j
,所述一个或多个缩放因子中的每一个是与用于缩放权重(例如整数值)的预定预测矩阵405的一个或多个对应矩阵分量相关联,所述一个或多个对应矩阵分量与预定预测矩阵405的一个或多个对应矩阵分量相关联。额外地或者替代地,预测参数包括一个或多个偏移量,例如值offset
i,j
,其中的每一个偏移量与使权重(例如整数值)偏移量的预定预测矩阵405的一个或多个对应矩阵分量相关联,所述一个或多个对应矩阵分量与预定预测矩阵405的一个或多个对应矩阵分量相关联。
[0433]
为了缩减offset
i,j
和scale
i,j
必需的存储量,其值可以被选择为对于索引i,j的特定集合是恒定的。举例而言,它们的项对于每一列可以是恒定的,或者它们可以对于每一行可以是恒定的,或者它们对于所有i,j可以是恒定的,如图11中所示。
[0434]
举例而言,在一个优选实施例中,offset
i,j
和scale
i,j
对于一个预测模式的矩阵的所有值是恒定的,如图12中所示出。因此,当存在k个预测模式时,其中k=0..k-1,仅需要单个值ok和单个值sk来计算用于模式k的预测。
[0435]
根据一实施例,offset
i,j
和scale
i,j
对于所有基于矩阵的内预测模式是恒定的,亦即相同的。额外地或者替代地,offset
i,j
和/或scale
i,j
对于所有块大小可能是恒定的,亦即相同的。
[0436]
在偏移量表示ok并且缩放表示sk的情况下,(1)中的计算可以被修改成:
[0437]
(2)
[0438][0439][0440]
由该解决方案产生的扩展实施例
[0441]
以上解决方案意指以下实施例:
[0442]
1.如在章节i中的预测方法,其中在章节i的步骤2中,以下是针对所涉及矩阵向量乘积的整数近似来进行:在(经平均的)边界样本x=(x1,...,xn)中,对于1≤i0≤n的固定i0,计算向量y=(y1,...,yn),其中对于i≠i0,yi=x
i-mean(x),且其中且其中mean(x)表示x的均值。向量y随后充当用于矩阵向量乘积cy的输入(矩阵向量的整数实现)使得来自章节i的步骤2的(经下采样的)预测信号pred作为pred=cy meanpred(x)给定。在这些式子中,meanpred(x)表示等于mean(x)的用于(经下采样的)预测信号的域中的每一样本位置的信号。(参见例如图10b)
[0443]
2.如在章节i中的预测方法,其中在章节i的步骤2中,以下是针对所涉及矩阵向量乘积的整数近似来进行:在(经平均的)边界样本x=(x1,...,xn)中,对于1≤i0≤n的固定i0,计算向量y=(y1,...,y
n-1
),其中对于i<i0,yi=x
i-mean(x)且其中对于i≥i0,yi=x
i 1-mean(x)且其中mean(x)表示x的均值。向量y随后充当用于矩阵向量乘积cy的输入(矩阵向量的整数实现)使得来自章节i的步骤2的(经下采样的)预测信号pred作为pred=cy meanpred(x)给定。在这些式子中,meanpred(x)表示针对(经下采样的)预测信号的域中的每一样本位置等于mean(x)的的信号。(参见例如图10c)
[0444]
3.如在章节i中的预测方法,其中通过使用矩阵向量乘积zi=∑
jbi,j
*yj中的系数给定矩阵向量乘积cy的整数实现。(参见例如图11)
[0445]
4.如在章节i中的预测方法,其中步骤2使用k个矩阵中的一个,使得可以计算多个预测模式,每一预测模式使用k=0
…
k-1的不同矩阵其中通过使用矩阵向量乘积zi=∑
jbi,j
*yj中的系数给定矩阵向量乘积cky的整数实现。(参见例如图12)
[0446]
亦即,根据本技术的实施例,编码器和解码器如下操作以便预测图像10的预定块18,参见图9。为了预测,使用多个参考样本。如上文所概述,本技术的实施例将不限于内编码并且因此,参考样本将不限于邻近样本,亦即图像10相邻块18的样本。具体来讲,所述参考样本将不限于沿着块18的外边缘配置的参考样本,诸如邻接块的外边缘的样本。然而,此情形当然是本技术的一个实施例。
[0447]
为了执行预测,从诸如参考样本17a和17c的参考样本形成样本值向量400。上文已经描述可能的形成。所述形成可以涉及平均,进而相较于促成形成的参考样本17缩减样本102的数目或者向量400的分量的数目。如上文所描述,所述形成也可以在某种程度上取决于块18的尺寸或者大小,诸如其宽度和高度。
[0448]
应当对此向量400进行仿射或者线性变换以获得块18的预测。上文已经使用不同命名。使用最近的一个命名,旨在通过在执行偏移量向量b的求和内借助于矩阵向量乘积将向量400应用于矩阵a而执行预测。偏移量向量b是可选的。通过a或者a和b确定的仿射或者线性变换可以由编码器和解码器确定,或者更确切而言,为预测起见,基于块18的大小和尺寸来确定所述仿射或者线性变换,如上文已经描述。
[0449]
然而,为了实现上文所概述的计算效率改良或者就实施而言使预测更有效,所述仿射或者线性变换已被量化,且编码器和解码器或者其预测器使用上文所提及的c和t以便表示和执行线性或者仿射变换,其中以上文所描述的方式应用的c和t表示仿射变换的经量化版本。具体来讲,代替将向量400直接应用于矩阵a,编码器和解码器中的预测器应用向量402,向量402是借助于经由预定可逆线性变换t对样本值向量400进行映射而从所述样本值向量400产生的。可能的是,只要向量400具有相同大小,则如此处所使用的变换t是相同的,亦即不取决于块的尺寸,亦即宽度和高度,或者至少对于不同仿射/线性变换是相同的。在上文中,向量402已被标示为y。用于执行如通过机器学习所确定的仿射/线性变换的确切矩阵将为b。然而,代替确切地执行b,编码器和解码器中的预测是借助于其近似或者经量化版本来进行。具体来讲,所述表示是经由以上文所概述的方式适当地表示c来进行的,其中c m表示b的经量化版本。
[0450]
因此,进一步通过计算向量402与以上文所描述的方式在编码器和解码器处适当地表示且存储的预定预测矩阵c之间的矩阵向量乘积404,来进行编码器和解码器中的预测。从此矩阵向量乘积产生的向量406随后被用于预测块18的样本104。如上文所描述,为预测起见,向量406的每一分量可以与如在408处所指示的参数a进行求和,以便补偿c的对应的定义。向量406与偏移量向量b的可选求和也可以被包含在基于向量406导出块18的预测中。如上文所描述,向量406的每一分量且因此向量406、在408处指示的所有a的向量和可选的向量b的求和的每一分量可以直接对应于块18的样本104,且因此,指示样本的经预测值。也可以以该方式仅预测块的样本104的子集并且也可以通过内插导出块18的剩余的样本,诸如108。
[0451]
如上文所描述,设置a存在不同实施例。举例而言,其可以是向量400的分量的算术
平均值。对于该情形,参见图10。可逆线性变换t可以如图10中所指示。i0分别为样本值向量和向量402的预定分量,其由a替代。然而,也如上文所指示,存在其他可能性。然而,就c的表示而言,上文也已指示c可以以不同方式体现。举例而言,矩阵向量乘积404可以在其实际计算中以具有较低维度的较小矩阵向量乘积的实际计算结束。具体来讲,如上文所指示,由于c的定义,c的整个第i0列412可以变为0,使得可以通过向量402的经缩减版本来进行乘积404的实际计算,所述经缩减版本通过省略分量亦即通过将此经缩减向量410乘以经缩减矩阵c'而产生于向量402,所述经缩减矩阵通过舍弃第i0列412而产生于c。
[0452]
c的权重或者c'的权重,亦即此矩阵的分量,可以以定点数表示来表示和存储。然而,这些权重414也可以如上文所描述以与不同缩放和/或偏移量相关的方式存储。缩放和偏移量可以针对整个矩阵c限定,亦即对于矩阵c或者矩阵c'的所有权重414为相等的,或者可以以一方式限定使得对于矩阵c和矩阵c'的相同行的所有权重414或者相同列的所有权重414分别为恒定或者相等的。就此而言,图11示出矩阵向量乘积的计算(亦即乘积的结果)实际上可以稍微不同地执行,亦即例如通过将与缩放的乘法朝向向量402或者404移位,进而缩减必须进一步执行的乘法的数目。图12说明使用用于c或者c'的所有权重414的一个缩放和一个偏移量的情形,诸如在以上计算(2)中进行。
[0453]
根据一实施例,用于预测图像的预定块的本文中所描述的装置可以被配置为使用基于矩阵的内样本预测,包括以下特征:
[0454]
所述装置被配置为从多个参考样本17形成样本值向量ptemp[x]400。假设ptemp[x]为2*boundarysize,可以通过-例如通过直接复制或者通过子采样或者池化-位于预定块的顶部处的邻近样本redt[x](其中x=0..boundarysize-1)、之后是位于预定块左边的邻近样本redl[x](例如在istransposed=0的情形下)来填充ptemp[x],或者在经转置处理的情形下反之亦然(例如在istransposed=1的情形下)。
[0455]
导出x=0..insize-1的输入值p[x],亦即所述装置被配置为从样本值向量ptemp[x]导出另一向量p[x],样本值向量ptemp[x]通过预定可逆线性变换(或者更具体来讲,预定可逆仿射线性变换)映射至所述另一向量,如下:
[0456]-如果mipsizeid等于2,以下适用:
[0457]
p[x]=ptemp[x 1]-ptemp[0]
[0458]-否则(mipsizeid小于2),以下适用:
[0459]
p[0]=(1《《(bitdepth-1))-ptemp[0]
[0460]
p[x]=ptemp[x]-ptemp[0],其中x=1..insize-1
[0461]
此处,变量mipsizeid指示预定块的大小。亦即,根据本实施例,用于从样本值向量导出另一向量的可逆变换取决于预定块的大小。所述依赖性可能根据以下给定
[0462]
mipsizeidboundarysizepredsize024144248
[0463]
其中predsize指示预定块内的经预测样本的数目,2*bondarysize指示样本值向量的大小,且根据insize=(2*boundarysize)-(mipsizeid==2)?1:0,与insize(亦即另一向量的大小)有关。更精确而言,insize指示实际上参与计算的另一向量的那些分量的数
目。insize对于较小块尺寸是与样本值向量的尺寸一样大,并且对于较大块尺寸是较小的一个分量。在前一情形下,可以忽略一个分量,亦即将对应于另一向量的预定分量的分量,如在随后计算的矩阵向量乘积中,对应的向量分量的贡献无论如何将产生零,且因此,实际上不需要计算。在替代实施例的情形下,可以忽略对块尺寸的依赖性,其中仅两个替代方案中的一个不可以避免地使用,亦即,不管块尺寸(对应于mipsizeid的选项小于2,或者对应于mipsizeid的选项等于2)。
[0464]
换言之,例如,限定预定可逆线性变换使得另一向量p的预定分量变为a,而所有其他分量对应于样本值向量的分量减去a,其中例如a=ptemp[0]。在对应于mipsizeid的第一选项等于2的情形下,这是容易地可见的,并且仅仅进一步考虑另一向量的以差分方式形成的分量。亦即,在第一选项的情形下,另一向量实际上为{p[0
…
insize];ptemp[0]},其中ptemp[0]为a,且用于产生矩阵向量乘积的矩阵向量乘法的实际经计算部分,亦即乘法的结果,仅限于另一向量的insize分量和矩阵的对应的列,因为矩阵具有不需要计算的零列。在其他情形下,对应于小于2的mipsizeid,选择a=ptemp[0],作为除了p[0]之外的另一向量的所有分量,亦即另一向量p的除了预定分量p[0]之外的其他分量p[x](其中x=1..insize-1)中的每一个等于样本值向量ptemp[x]的对应分量减去a,但p[0]经选择为常数减去a。随后计算矩阵向量乘积。所述常数是可表示值的均值,亦即2
x-1
(亦即1《《(bitdepth-1)),其中x表示所使用的计算表示的位深度。应注意,如果p[0]代之以被选择为ptemp[0],则经计算乘积将仅与使用如上文所指示的p[0](p[0]=(1《《(bitdepth-1))-ptemp[0])计算的一个乘积偏离一常数向量,该常数向量可能在基于所述乘积预测内部块时予以考虑,亦即预测向量。因此,值a为预定值,例如,ptemp[0]。预定值ptemp[0]在此情形下例如为样本值向量ptemp的对应于预定分量p[0]的分量。其可以是预定块顶部或者预定块左边的最接近预定块的左上角的邻近样本。
[0465]
对于根据predmodeintra的例如指定内预测模式的内样本预测工艺,所述装置例如被配置为应用于下步骤,例如执行至少第一步骤:
[0466]
1.基于矩阵的内预测样本predmip[x][y],其中x=0..predsize-1,y=0..predsize
–
1,被如下导出:
[0467]-变量modeid被设置成等于predmodeintra。
[0468]-通过使用mipsizeid和modeid作为输入调用mip权重矩阵导出过程而导出权重矩阵mweight[x][y],其中x=0..insize-1,y=0..predsize*predsize
–
1。
[0469]-如下导出基于矩阵的内预测样本predmip[x][y],其中x=0..predsize-1,y=0..predsize
–
1:
[0470][0471][0472]
换言之,所述装置被配置为计算矩阵向量乘积,所述矩阵向量乘积是另一向量p[i]或者在mipsizeid等于2的情形下为{p[i];ptemp[0]}、与预定预测矩阵mweight或者在mipsizeid小于2的情形下为具有与p的所省略分量对应的额外零权重列的预测矩阵mweight之间的乘积,以获得预测向量,其在此处已经指派给在预定块的内部分布的块位置
{x,y}的阵列以便产生阵列predmip[x][y]。预测向量将分别对应于predmip[x][y]的行或者predmip[x][y]的列的级联。
[0473]
根据一实施例,或者根据不同解释,仅分量仅分量被理解为预测向量,且所述装置被配置为在基于预测向量预测预定块的样本时针对预测向量的每一分量计算相应分量与a(例如ptemp[0])的总和。
[0474]
所述装置可以可选地被配置为在基于预测向量预测预定块的样本(例如predmip或者时额外执行后续步骤。
[0475]
2.基于矩阵的内预测样本predmip[x][y],其中x=0..predsize
–
1,y=0..predsize-1例如被如下剪裁:
[0476]
predmip[x][y]=clip1(predmip[x][y])
[0477]
3.当istransposed等于true时,predsize
×
predsize阵列predmip[x][y],其中x=0..predsize-1,y=0..predsize
–
1,例如被如下转置:
[0478]
predtemp[y][x]=predmip[x][y]
[0479]
predmip=predtemp
[0480]
4.经预测样本predsamples[x][y],其中x=0..ntbw-1,y=0..ntbh
–
1,例如被如下导出:
[0481]-如果指定变换块宽度的ntbw大于predsize或者指定变换块高度的ntbh大于predsize,则利用输入块大小predsize、基于矩阵的内预测样本predmip[x][y](其中x=0..predsize-1,y=0..predsize-1)、变换块宽度ntbw、变换块高度ntbh、顶部参考样本reft[x](其中x=0..ntbw-1)和作为输入的左边参考样本refl[y](其中y=0..ntbh-1)调用mip预测上采样工艺,且输出是经预测样本阵列predsamples。
[0482]-否则,predsamples[x][y],x=0..ntbw
–
1,y=0..ntbh
–
1,被设置成等于predmip[x][y]。
[0483]
换言之,所述装置被配置为基于预测向量predmip来预测预定块的样本predsamples。
[0484]
图13示出用于使用多个参考样本预测图像的预定块的方法2000,包括:从多个参考样本形成2100样本值向量;从样本值向量导出2200另一向量,样本值向量通过预定可逆线性变换被映射到所述另一向量上;计算2300另一向量与预定预测矩阵之间的矩阵向量乘积以获得预测向量;以及,基于预测向量预测2400预定块的样本。
[0485]
参考文献
[0486]
[1]p.helle et al.,“non-linear weighted intra prediction”,jvet-l0199,macao,china,october 2018.
[0487]
[2]f.bossen,j.boyce,k.suehring,x.li,v.seregin,“jvet common test conditions and software reference configurations for sdr video”,jvet-k1010,ljubljana,si,july 2018.
[0488]
进一步的实施例和示例
[0489]
通常,示例可以实施为具有程序指令的计算机程序产品,当计算机程序产品运行
于计算机上时,程序指令操作性地用于执行所述方法中的一个。程序指令可以例如存储于机器可读介质上。
[0490]
其他示例包括用于执行本文中所描述的方法中的一个、存储于机器可读载体上的计算机程序。
[0491]
换言之,方法的示例因此为计算机程序,其具有用于在计算机程序于计算机上运行时执行本文中所描述的方法中的一个的程序指令。
[0492]
所述方法的另一示例因此为数据载体介质(或者数字存储介质,或者计算机可读介质),包括、上面记录有用于执行本文中所描述的方法中的一个的计算机程序。数据载体介质、数字存储介质或者记录介质为有形和/或非暂时性的,而非无形和暂时性的信号。
[0493]
因此,所述方法的另一示例为表示用于执行本文中所描述的方法中的一个的计算机程序的数据流或者信号序列。所述数据流或者信号序列可以例如经由数据通信连接,例如经由因特网来传送。
[0494]
另一示例包括处理构件,例如计算机或者可编程逻辑器件,其执行本文中所描述的方法中的一个。
[0495]
另一示例包括计算机,所述计算机具有安装于其上的用于执行本文中所描述的方法中的一个的计算机程序。
[0496]
另一示例包括将用于执行本文中所描述的方法中的一个的计算机程序传送(例如,以电子方式或者以光学方式)至接收器的装置或者系统。举例而言,接收器可以是计算机、移动设备、存储器设备等等。所述装置或者系统可以(例如)包括用于将计算机程序传送至接收器的文件服务器。
[0497]
在一些示例中,可编程逻辑器件(例如,场可编程门阵列)可用于执行本文中所描述的方法的功能性中的一些或者全部。在一些示例中,场可编程门阵列可以与微处理器协作,以便执行本文中所描述的方法中的一个。通常,所述方法可以由任何适当的硬件设备执行。
[0498]
上文所描述的示例仅说明上文所论述的原理。应理解,本文中所描述的配置和细节的修改和变化将为显而易见的。因此,其意欲由接下来的权利要求的范畴限制,而非由借助于本文中示例的描述和解释所呈现的特定细节限制。即使出现于不同图中,后续描述中仍通过相等或者等效附图标记表示具有相等或者等效功能性的相等或者等效(若干)元件。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。