技术特征:
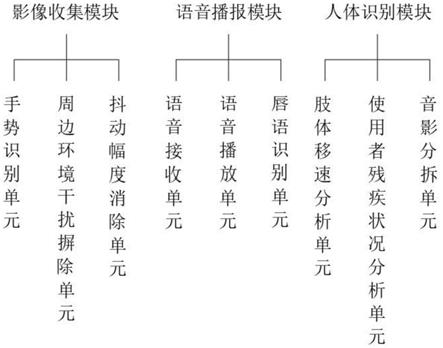
1.一种基于多协议的语言和图像理解系统,包括影像收集模块、语音播报模块和人体识别模块,其特征在于:所述人体识别模块包括有肢体移速分析单元、使用者残疾状况分析单元和音影分拆单元,所述肢体移速分析单元用于测量使用者肢体伸出至接触机器人期间的肢体移动速度以此判定使用者的肢体灵活层级,若是肢体灵活层级高则机器人显示屏显示画面播放速度快以此节约时间,避免后续聋哑人等待时间过长,所述使用者残疾状况分析单元用于检测使用者是听力故障还是语言故障,亦或是两者均出现故障,所述音影分拆单元用于根据使用者的残疾分析报告分时间段启用语音功能和影像功能以减少机器人电池不必要的消耗。2.根据权利要求1所述的一种基于多协议的语言和图像理解系统,其特征在于:使用者肢体移动速度检测流程:机器人在公众区域运行,使用者需要机器人帮助则站立在机器人正面即机器人立即停止运行,检测当前使用者,扫描得出当前使用者的身高和人体形态,计算得出人体距离机器人显示屏的水平距离记为l
水平
,计算得出人体距离机器人显示屏最近点到人体手部的距离记为l
垂直
,继而通过勾股定理计算得出人体手部到机器人显示屏的距离为l
手
;机器人的有效扫描距离为l
有效距离
,若是l
水平
大于l
有效距离
则机器人发出语音播报提醒使用者靠近,若是l
水平
小于等于l
有效距离
则机器人计算得出使用者的肢体移动速度v
手
,v
手
=l
手
/t
接触时间
,式中,t
接触时间
为机器人停止运行到使用者肢体接触机器人显示屏的时间,设定额定使用者移动速度为v
额
,将v
额
分为v1-v6六个层级,v1表示使用者的肢体移动速度最慢,v6表示使用者肢体移动速度最快,将v
手
与v
额
进行比较判定得出相应的语音播报速度层级和影像播放速度层级,设定语音播报速度层级为a1-a6,a1表示语音播报速度最慢,a6表示语音播报速度最快,设定影像播放速度层级b1-b6,b1表示影像播放速度最慢,b6表示影响播放速度最快,达到根据人体肢体移动速度判定信息接受速度的效果,在有效传递信息的同时做到个人服务定制化,使得使用者求助时更加舒服。3.根据权利要求2所述的一种基于多协议的语言和图像理解系统,其特征在于:判定聋哑人残疾程度流程:设定单一听力障碍的使用者为一级残疾,记为c1人员,设定单一语言障碍的使用者为二级残疾,记为c2人员,设定听力和语言均障碍的使用者为三级残疾,记为c3人员,机器人显示屏上显示,本机器人可接受语音服务,若是机器人3秒内无法接受到使用者的信息则自动判定使用者为语言障碍者,同时机器人内发出语音播报,可进行手语操作,点击显示屏以确定,若是机器人3秒内无法接受到使用者的信息则自动判定使用者为听力障碍者,上述判定流程为同时进行,以3秒时间结束判定流程,分析出结果,若是使用者可说话则机器人接受语音信息,音影分拆单元此时驱动影像播放功能和语音播放功能,使用者能从影像播放中得出有效求助信息,同时判定使用者的语言组织是否流畅,若是流畅度不达标则提醒使用者使用手语,若是流畅度达标则无需提醒,若是使用者不能进行说话,听力尚可则音影分拆单元此时只驱动影像播放功能和语音播放功能,若是使用者既不能说话听力也有障碍则音影分拆单元此时只驱动影像播放功能,立即执行手语服务功能。4.根据权利要求3所述的一种基于多协议的语言和图像理解系统,其特征在于:所述影像收集模块包括有手势识别单元、周边环境干扰摒除单元和抖动幅度消除单元,所述手势识别单元用于监测使用者的手势变化以识别使用者的用意,所述周边环境干扰摒除单元用
于将机器人周边的杂音和另类动态行为遮蔽,增加使用者与机器人之间的交流流畅度,所述抖动幅度消除单元用于消除手势变化过程中的轻微抖动,增加手语的精准度。5.根据权利要求4所述的一种基于多协议的语言和图像理解系统,其特征在于:所述语音播报模块包括有语音接收单元、语音播放单元和唇语识别单元,所述语音接受单元用于接收使用者的语音信息,所述语音播放单元用于播放设定的语音信息给与使用者帮助,所述唇语识别单元用于针对不会手语的聋哑人提供唇语服务。6.根据权利要求5所述的一种基于多协议的语言和图像理解系统,其特征在于:手语信息交互流程:机器人扫描使用者的动态手势,实时动态手势与数据存储库的手势记录进行匹配,将使用者的手语含义翻译出来,并根据翻译内容进行相应回答,为使用者解决问题,翻译手语过程中对使用者所表达的语句意思进行预判,提供与使用者所表达含义的最接近的十条语句,显示在显示屏上,由使用者挑选,减少使用者展示手语的时间,手语动作复杂,语言和图像理解系统以预判的形式提供的多种选择,提高效率的同时减少手语表达信息误差,增加正确率,使用者在十条预判语句中挑选含义最接近的一条,若是使用者成功挑选则语言和图像理解系统回答问题,解决使用者疑惑,若是十条语句中没有使用者满意的预判语句则可以点击退出继续展示手语,手势识别单元继续接收手语信息,接收手语信息的同时翻译手语信息,翻译手语信息得到相较于上一次预判差异大的翻译信息时再次进行语句预判,提供十条预判语句供使用者挑选,重复预判直至预判成功,若是一直无法预判成功则完整翻译使用者的手语信息,针对完整信息进行回答。7.根据权利要求6所述的一种基于多协议的语言和图像理解系统,其特征在于:语言和图像理解系统回答流程:回答问题的过程可选择图片回答、语音播报和影像展示,语言和图像理解系统根据使用者残疾状况分析单元检测信息做出选择,针对c1人员可提供图片回答和影像展示,优先选择影像展示,影像展示信息具体,使用者易于理解,针对c2人员可提供图片回答、语音播报和影像展示,优先选择语音播报,语音播报效率高,针对c3人员可提供图片回答和影像展示,优先选择影像展示,影像展示即用手语表示回答信息在显示屏上播放出来;在使用者手语展示过程中的,若是使用者在语句预判的过程中不对其做出选择,预判语句在显示屏上滞留时间长达6秒则判定使用者识字能力弱,在语言和图像理解系统回应过程中调整回应方式,均以图片回答优先,图片回答文字少,避免使用者理解出现误差,每种回答方式均会出现图片回答、语音播报和影像展示三种回答方式,优先回答方式若是不能满足使用者,则使用者可手动挑选回答方式直至满意。8.根据权利要求7所述的一种基于多协议的语言和图像理解系统,其特征在于:特殊情况分析:先天性耳聋的人都会成为哑巴,这是因为人的语言是靠后天学来的,生来就听不到人的语言,对于此种情况,按照上述流程完成,后天耳聋的人是具有语言能力基础的,针对此种情况,可在机器人显示的屏幕上选择唇语识别模式,唇语识别单元按照人体识别模块扫描的人脸信息寻找到嘴唇部位,根据唇部动态预判使用者所要表达的信息,唇语识别精准性差,给出预判语句为六句,缩小选择范围,加快使用者的选择速度,若是预判语句均不选择,则继续收集唇语信息,再次进行语句预判,两次唇语信息预判之后语言和图像理解系统
建议使用者使用手语进行语义输出,若是语句预判成功则同时给出语音播报和影像展示。9.根据权利要求8所述的一种基于多协议的语言和图像理解系统,其特征在于:环境摒除和抖动幅度消除流程:老年人手抖症常见,手势识别过程中除了展示手语时手发生动态变化,还有手抖症带来的手部轻微动态幅度,抖动幅度消除单元将手部动态幅度分为y1-y12共计12个层级,y1表示手部动态幅度最小,y12表示手部动态幅度最大,将y1-y2层级的动态幅度自动摒除,减小语言和图像理解系统识别手语时的误差;由于此空间可能为公共空间,具有人员流动性,周边环境干扰摒除单元只接受机器人正前方的展示信息,保证信息来源唯一性。10.根据权利要求9所述的一种基于多协议的语言和图像理解系统,其特征在于:影像展示的信息存储来源:由人为录制手语信息,交由动画制作公司制作统一制式的手语影像,手语影像和手语逻辑均存储在语言和图像理解系统中。
技术总结
本发明公开了一种基于多协议的语言和图像理解系统,包括影像收集模块、语音播报模块和人体识别模块,所述人体识别模块包括有肢体移速分析单元、使用者残疾状况分析单元和音影分拆单元,所述肢体移速分析单元用于测量使用者肢体伸出至接触机器人期间的肢体移动速度以此判定使用者的肢体灵活层级,若是肢体灵活层级高则机器人显示屏显示画面播放速度快以此节约时间,避免后续聋哑人等待时间过长,所述使用者残疾状况分析单元用于检测使用者是听力故障还是语言故障,亦或是两者均出现故障,所述音影分拆单元用于根据使用者的残疾分析报告分时间段启用语音功能和影像功能,本发明,具有实用性强和自动识别手语并用多种回应方式解决问题的特点。方式解决问题的特点。方式解决问题的特点。
技术研发人员:周超
受保护的技术使用者:周超
技术研发日:2021.11.10
技术公布日:2022/2/18
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。