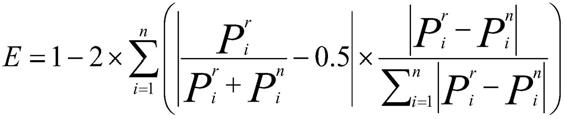1.本发明属于自然语言处理领域,涉及一种基于特征评估与关键词相似度分析的地理语料标注方法。
背景技术:
2.目前大部分语料主要来源于互联网上的相关新闻报道以及一些专业知识网站,比如公开的中英文关系抽取知识库ace2005、semeval
‑
2010task8和中文关系抽取知识库chinese
‑
literature
‑
ner
‑
re
‑
dataset等,这些知识库中的数据类型基本包含了现实生活中的各个领域,是一种开放领域知识库,而对于专业领域,由于专业领域需要根据各领域的特点对语料标注方法进行针对性的设计,所以并不能使用这些优秀的开放领域标注方法和语料进行应用,导致目前并没有非常优秀的语料标注方法以及标注语料。本专利的研究是限定在地理这个专业的领域内,所以这些开放领域的知识库就不能直接作为本文的数据来源,需要根据本文研究领域的实际情况进行知识库和语料库的构建。
技术实现要素:
3.为了解决目前的地理语料库系统构建效率差,且系统数据精度不高,容易因语料数据错误影响工作的正常进行等问题。本发明提供一种基于特征评估和关键词相似度的地理文本语料标注方法,弥补地理领域标注语料数据的不足,且不需要耗费大量人力资源,成本低。
4.本专利解决其技术问题所采用的技术方案包括以下步骤:
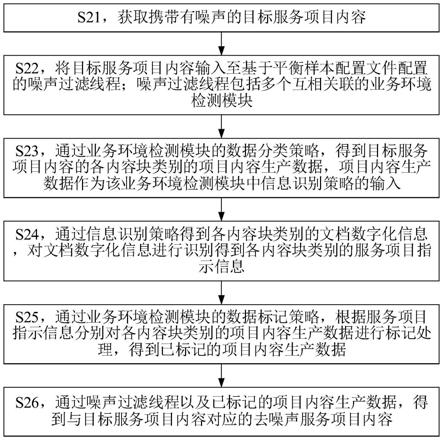
5.s1:利用爬虫技术爬取百度百科地理相关页面的结构化文本信息作为知识库,爬取百度百科地理相关页面的非结构化文本信息作为原始语料库;
6.s2:对原始语料库进行预处理,得到清洗过的语料;
7.s3:根据文本中的实体对将知识库和语料库对齐;
8.s4:使用df(document frequency)特征选择方法计算句子特征词;
9.s5:利用权重计算公式计算词语t在地理实体对中的权值;
10.s6:按照t的权值大小降序排列,选取权值最大的词作为关系词;
11.s7:采用训练好的word2vec模型生成词向量,得到s6输出关系词和知识库中的关系词的词向量;
12.s8:计算句子中关系词与知识库中关系词的相似度;
13.s9:找出相似度最大的关系词并进行语料标注,最终得到标注实体和关系类型的语句。
14.所述语料库预处理为:以哈工大停用词表为基础,构建一个地理领域的停用词表,再结合正则表达式对文本中的无用字符以及无意义字词进行清理,并删除无效的超链接以及广告。
15.所述知识库与语料库对齐方法为如果目标实体对出现在句子中,则将这个句子提
取出来,得到共实体对的句子集。
16.所述词语t在地理实体对中的权值是根据词语的词性、相对位置和距离等特征计算得到。
17.所述关系词相似度计算方法为向量夹角余弦值计算方法。
18.本发明的有益效果是:
19.第一,本专利提出的标注方法针对地理领域,填补了地理领域标注语料库不足的缺陷,并且标注方法为自动标注,减少了大量人力物力。
20.第二,本专利考虑句中词语特征的差异与关键词相似度对于标注语料时选择关系词的影响,提出的基于特征评估和关键词相似度的语料标注方法能够提高语料标注的准确率和召回率,进一步提高构建标注语料库的质量。
附图说明
21.图1为基于特征评估和关键词相似度的语料标注流程
22.图2为语料标注部分结果
具体实施方式
23.下面结合附图和实施例对本发明进一步说明,本发明包括但不仅限于下述实施例。
24.本发明包括以下步骤:
25.s1:利用爬虫技术爬取百度百科地理相关页面的结构化文本信息作为知识库,爬取百度百科地理相关页面的非结构化文本信息作为原始语料库;
26.s2:对相关网页的信息做进一步的处理,在爬取原始网页数据之后对文本进行(1)删除文本中无法阅读的特殊字符,对文本进行统一编码;(2)文本内的英文字母大写变小写,全角变半角;(3)删除超链接和html代码,去除广告等无关内容,删除角标等无用符号。最终得到清洗过的文本数据;
27.s3:根据文本中的实体对将知识库和语料库对齐,具体指当知识库中存在例如“北京”、“中国”这个实体对时,语料库中的某个句子中也包含这两个实体,那么就将此句子与这个实体对对齐,最终将所有含此实体对的句子集合为共实体对的句子集;
28.s4:使用df(document frequency)特征选择方法计算句子特征词;特征的选择是关系抽取任务中的关键步骤,优秀的特征也有助于减少标注噪声,且能从多个方面揭示关系的本质。本专利基于词语的词性、相对位置和相对距离等特征评估词语的重要性,而词语特征由语料统计决定,本专利用df衡量词语特征的重要性,其计算公式为其中,其中f
t
,s
i
表示实体对类型为s
i
的地理实体周围的词语中词语t的出现频率。s
i
∈ws,ws表示一个规模为n的实体对的类型集合。
29.s5:利用权重计算公式计算词语t在地理实体对中的权值;本专利引入相对位置和相对距离特征,特征随文本的变化而变化,通过统计分析自动从文本中选择相应特征用于关系提取。相对位置特征即在地理实体e1和e2的左边,中间或右边。相对距离特征即当前词
距离句首、e1、e2或句尾的距离。词语t在地理实体对中的权值计算公式为不同词性的t为关系词的概率为在地理实体对周围词的影响下不同位置的t为关系词的概率为t
loc
表示t的位置,tp(
·
)表示括号内词的前一个词语,tn(
·
)表示括号内词的后一个词语。位置不同的词语能够成为关系词的概率为其中dis(
·
)表示t到括号内词语的距离,head表示句首,tail表示句尾;
30.s6:按照t的权值大小降序排列,选取权值最大的词作为关系词;
31.s7:采用训练好的word2vec模型生成词向量,得到s6输出关系词和知识库中的关系词的词向量;word2vec模型的训练方法为cbow和skip
‑
gram,前者使用上下文来预测目标单词,而后者使用单词来预测目标上下文;
32.s8:计算句子中关系词与知识库中关系词的相似度;本专利采用的关系词的词向量计算夹角余弦值作为相似度的方法,本专利采用关系词相似度分析,只在共实体对的情况下计算关系词的相似度大小,这种方法不仅避免了句子相似度的错误,还可以在共实体对有多种关系的情况下选出正确的关系进行标注。比如“北京”和“中国”的关系可以是“首都”,也可以是“直辖市”,在进行本节的分析后得出句子中关系词与“首都”的相似度最高,则将句子中的“北京”和“中国”的关系标注为“首都”。计算方法为其中i=1,2,
…
,k,得到根据特征评估找出的关系词与三元组中各个关系词的相似度;
33.s9:找出相似度最大的关系词并进行语料标注,最终得到标注实体和关系类型的语句,结果如图2所示,前两列为句子中存在的实体对,第三列为标注的实体对关系,最后为实体关系所依存的句子。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。