1.本发明涉及生物信息技术领域,具体涉及一种基于元学习的生物活性肽预测方法及系统。
背景技术:
2.多肽通常由10-100个氨基酸组成,与传统化疗相比,功能活性肽具有以下优点:生物介体、显著的效力、高选择性和低毒性。从天然肽中提取的药物已经彻底改变了一些疾病的治疗,例如1型糖尿病。此后,越来越多的多肽类药物被发现。例如,一种基于抗血管生成肽(aap)的药物,单克隆抗vegf(血管内皮生长因子)抗体,可以抑制肿瘤血管生长,从而提高癌症患者的生存率。抗菌肽(abps)是先天免疫的效应分子,可以靶向细菌膜,通过细胞凋亡反应杀死细菌,其杀菌速度快于细菌的生长速度。抗结核肽(atps)由于其低免疫原性、低毒性和针对侵袭性病原体的靶向免疫反应的特点,已成为结核病治疗的候选药物。其他肽的生物活性包括抗癌和dpp iv抑制剂等。因此,发现新的潜在多肽生物活性对新药开发具有重要意义。
3.尽管肽类药物具有优异的优势,但全球市场上只有约80种肽类药物,约700种肽仍处于临床试验或临床前研究阶段。限制肽药物开发的主要原因之一是难以识别生物活性肽,这是肽药物发现管道中的关键步骤。为了促进肽类药物的发现,提出了基于机器学习的功能肽预测算法,并取得了一些进展。这种方法使模型能够区分功能性肽和非功能性肽,从而加速肽药物的开发。
4.近年来,已经开发出了几种基于机器学习的方法来识别各种生物活性肽。例如,laengsri等人构建了targetantiangio,一种基于序列的分类器,用于使用传统机器学习预测aap。wei等人开发了一系列预测因子,如acpred fl、pepred suite和acpred fuse,以促进准确预测acp的发展。manavalan等人通过采用ert算法对一个名为atbppred的预测工具进行建模,以识别atp,从而提高了模型的鲁棒性和精度。至于神经肽,有人提出了一种称为neuropipred的工具,通过特征工程来预测、设计和扫描昆虫神经肽。此外,各种用于预测其他种类的功能肽的计算方法相继被提出,如deep antifp、iqsp、iumami scm、preaip、psbp-svm、thpep等。
5.尽管取得了很大进展,但仍然存在以下主要挑战。首先,许多基于机器学习的相关任务都受到样本数较少的影响。低容量标记样本(经实验验证的生物活性肽)无法支持传统的监督学习来训练鲁棒的高性能模型,容易导致过度拟合和泛化能力差的问题。其次,大多数现有的利用工程特性的方法都是针对特定的功能肽设计的;没有通用的计算方法可以同时准确预测不同肽的生物活性。更重要的是,它们不能支持看不见的(新的)肽生物活性发现,这也是监督学习的一个限制。第三,大多数基于机器学习的多肽预测器仍然依赖于人工设计的统计特征,这在很大程度上依赖于研究人员的先验知识。此外,人工设计的的特征无法捕获不同肽功能的高潜在非线性信息。重要的是,人工设计的的特征缺乏对不同肽功能预测任务的适应性。也就是说,他们可能在一项特定任务上表现良好,但在其他任务上表现
不佳。此外,特征工程通常会产生数百维的特征向量,导致维数灾难。
技术实现要素:
6.本发明的目的在于提供一种通过最大化互信息与最小化交叉熵的联合优化改进现有的元学习算法原型网络,不依赖于特征工程,能够通过微调或推断等方式来预测多肽是否具有某种特定的功能活性的基于元学习的生物活性肽预测方法及系统,以解决上述背景技术中存在的至少一项技术问题。
7.为了实现上述目的,本发明采取了如下技术方案:
8.一方面,本发明提供一种基于元学习的生物活性肽预测方法,包括:
9.获取待预测的生物活性肽序列信息;
10.利用通过最大化互信息与最小化交叉熵的联合优化改进的元学习算法预先训练好的预测模型对待预测的生物活性肽序列信息进行处理,获得生物活性肽的功能类型;其中,预先训练好的预测模型使用训练集训练得到,所述训练集包括多个生物活性肽序列以及标注生物活性肽功能类型的标签。
11.优选的,预测模型的训练包括:肽序列被文本卷积神经网络进行样本嵌入;样本嵌入后通过平均属于相应功能类的原型嵌入产生不同肽类的原型;基于所述欧氏距离,确定每个肽序列属于各个功能类的概率分布;通过梯度下降算法对联合目标进行优化,迭代更新模型参数。
12.优选的,最大化互信息包括,在元训练和元测试程序中,在支持集和查询集中最大化肽序列嵌入特征和类别标签之间的互信息,以利用无监督信息。
13.优选的,计算样本嵌入和原型嵌入之间的欧式距离作为分类度量,从而评估嵌入和原型的正确性;将softmax归一化距离视为预测置信度。
14.优选的,对于模型优化,在元训练过程中,根据最大似然估计,优化分类目标,即交叉熵损失,为模型优化参数提供监督信息。
15.优选的,最终的优化目标是使交叉熵损失和最小化互信息损失的加权和最小。
16.优选的,在模型测试过程中,对于每个新任务在获得查询序列的预测之后,根据支持集的监督损失和查询集的无监督损失来调整模型,以利用特定新任务的无监督互信息。
17.第二方面,本发明提供一种基于元学习的生物活性肽预测系统,包括:
18.获取模块,用于获取待预测的生物活性肽序列信息;
19.预测模块,用于利用通过最大化互信息与最小化交叉熵的联合优化改进的元学习算法预先训练好的预测模型对待预测的生物活性肽序列信息进行处理,获得生物活性肽的功能类型;其中,预先训练好的预测模型使用训练集训练得到,所述训练集包括多个生物活性肽序列以及标注生物活性肽功能类型的标签。
20.第三方面,本发明提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质用于存储计算机指令,所述计算机指令被处理器执行时,实现如上所述的基于元学习的生物活性肽预测方法。
21.第四方面,本发明提供一种电子设备,包括:处理器、存储器以及计算机程序;其中,处理器与存储器连接,计算机程序被存储在存储器中,当电子设备运行时,所述处理器执行所述存储器存储的计算机程序,以使电子设备执行实现如上所述的基于元学习的生物
活性肽预测方法的指令。
22.本发明有益效果:
23.通过最大化互信息与最小化交叉熵的联合优化改进现有的元学习算法原型网络(protonet),专门为生物活性肽的挖掘和预测而设计,能够统一预测多种的生物活性肽;基于embedding技术而不基于特征工程和人工设计的特征,能够通过微调或推断等方式来预测多肽是否具有某种特定的功能活性;嵌入使用的主干是textcnn,主干在进行元学习前先在所有基类上进行监督预训练;使用来自各种功能肽的少量样本,通过元学习获取了各种功能之间的区别信息并表征功能差异,并能够在下游功能肽预测任务中表现良好,优于或与现有方法相媲美,尤其是在小样本场景下与传统方法相比性能有显著提升;为生物序列分析中的少数样本学习问题提供了同类解决方案,有利于新功能肽的发现。
24.本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
25.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
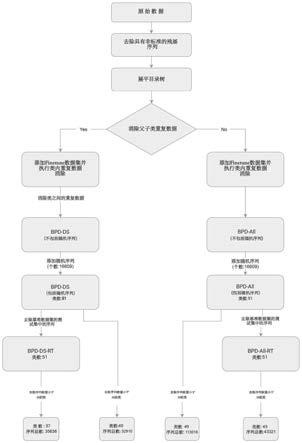
26.图1为本发明实施例所述的bpd数据集的构建流程图。
27.图2为本发明实施例所述的元学习数据集的划分方案图。
28.图3为本发明实施例所述的小样本学习中任务集的构造的说明图。
29.图4为本发明实施例所述的mimml的流程框架图。
30.图5为本发明实施例所述的章节式元学习过程的说明图。
31.图6为本发明实施例所述的小样本场景中生物活性肽预测任务的直推推断性能比较图。
32.图7为本发明实施例所述的mimml与cnn backbone的预测置信度对比图。
33.图8为本发明实施例所述的不同way和shot对元测试性能影响的对比图。
34.图9为本发明实施例所述的消融实验对比图。
35.图10为本发明实施例所述的embedding在不同的适应阶段的可视化对比图。
具体实施方式
36.下面详细叙述本发明的实施方式,所述实施方式的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
37.为便于理解本发明,下面结合附图以具体实施例对本发明作进一步解释说明,且具体实施例并不构成对本发明实施例的限定。
38.本领域技术人员应该理解,附图只是实施例的示意图,附图中的部件并不一定是实施本发明所必须的。
39.实施例1
40.本实施例1中,提供一种基于互信息最大化深度元学习模型的系统,利用该系统实现了基于互信息最大化深度元学习模型的用于统一预测各种功能活性肽的判别方法。
41.通过最大化互信息与最小化交叉熵的联合优化改进现有的元学习算法原型网络(protonet),从而为生物活性肽的挖掘和预测设计出专门的统一预测框架互信息最大化元学习mimml(mutual information maximization meta-learning)。mimml基于embedding技术,不依赖于特征工程,能够通过微调或推断等方式来预测多肽是否具有某种特定的功能活性。
42.本实施例1中,基于互信息最大化深度元学习模型的系统,包括:
43.获取模块,用于获取待预测的生物活性肽序列信息;
44.预测模块,用于利用通过最大化互信息与最小化交叉熵的联合优化改进的元学习算法预先训练好的预测模型对待预测的生物活性肽序列信息进行处理,获得生物活性肽的功能类型;其中,预先训练好的预测模型使用训练集训练得到,所述训练集包括多个生物活性肽序列以及标注生物活性肽功能类型的标签。
45.本实施例1中,利用上述的系统实现的基于元学习的生物活性肽预测方法,包括:
46.获取待预测的生物活性肽序列信息;
47.利用通过最大化互信息与最小化交叉熵的联合优化改进的元学习算法预先训练好的预测模型对待预测的生物活性肽序列信息进行处理,获得生物活性肽的功能类型;其中,预先训练好的预测模型使用训练集训练得到,所述训练集包括多个生物活性肽序列以及标注生物活性肽功能类型的标签。
48.其中,预测模型的训练包括:肽序列被文本卷积神经网络进行样本嵌入;样本嵌入后通过平均属于相应功能类的原型嵌入产生不同肽类的原型;基于所述欧氏距离,确定每个肽序列属于各个功能类的概率分布;通过梯度下降算法对联合目标进行优化,迭代更新模型参数。
49.最大化互信息包括,在元训练和元测试程序中,在支持集和查询集中最大化肽序列嵌入特征和类别标签之间的互信息,以利用无监督信息。计算样本嵌入和原型嵌入之间的欧式距离作为分类度量,从而评估嵌入和原型的正确性;将softmax归一化距离视为预测置信度。
50.对于模型优化,在元训练过程中,根据最大似然估计,优化分类目标,即交叉熵损失,为模型优化参数提供监督信息。最终的优化目标是使交叉熵损失和最小化互信息损失的加权和最小。
51.在模型测试过程中,对于每个新任务在获得查询序列的预测之后,根据支持集的监督损失和查询集的无监督损失来调整模型,以利用特定新任务的无监督互信息。
52.实施例2
53.本实施例2中,提供了基于互信息最大化深度元学习模型的用于统一预测各种功能活性肽的判别方法,该方法包括以下步骤:
54.步骤1:数据集构造以及数据预处理
55.步骤1-1:benchmark基准数据集构建:为了评估我们的模型,从文献中收集了涵盖16种肽功能的24个基准数据集作为评估数据集。为了确保公平比较,这24个数据集中的测试集序列不用于元学习。
56.步骤1-2:bpd数据集构建:通过整合两个最大的生物活性肽数据库(starpepdb和biopep-uwm)以及其他文献中具有功能性生物活性的各种肽的许多现有数据集,构建了元学习和小样本学习的bpd数据集。流程图如图1所示,描述如下:为了不同的研究目的和方便以后的工作,构建了4个版本的bpd。首先,从这两个数据库下载了几乎包含大多数生物活性肽的序列,以构建原始元数据集。其次,去除含有非标准氨基酸残基的序列。然后,展平目录树,也就是说,所有非第一级类别都向上移动到第一级。例如,扁平化操作后,抗血管生成肽和抗癌肽并置,而不是父子节点关系。根据父节点和子节点序列集是否进行重复数据消除,将数据流分为两个分支。通过父子类重复数据消除得出的左分支将在后续步骤中删除类别之间相同的序列,以确保此版本中的每个序列仅具有一个特定功能。右分支不执行跨类重复数据消除以保留尽可能多的肽。然后,这两个分支分别添加上述基准数据集和随机序列。请注意,随机序列是从过去关于生物活性肽预测的研究中衍生和合并而来的,它们都来自swissprot和uniprot,没有提及关于生物活性的关键词,如抗菌、抗菌、抗毒素等。接下来,左分支和右分支根据是否从基准数据集中删除测试集分别得到两个子集。最终,在删除少于50个序列的类别后,总共产生四个最终数据集,即bpd-ds、bpd-ds-rt、bpd-all、bpd-all-rt。bpd-all-rt有45个类别(44个生物活性类别和1个随机序列类别)被选择来训练元模型进行分析,因为它包含尽可能多的序列,并且不包含任何在测试集中的序列。
57.步骤1-3:元学习数据集的构建:为了便于对比实验,为bpd-all-rt设计了六种元数据集划分方案,分别为(8,10)、(16,10)、(24,10)、(8,20)、(16,20)和(24,20)。例如,(24,10)表示在元训练中使用24个类,在元测试中使用10个类。这些类别被随机打乱并分成小组。关于划分方案的详细信息如图2所示。注意,对于下面的所有实验,分别将1000个随机序列作为独立类添加到元训练、元有效和元测试任务集中。选择1000个随机序列的原因是为了使随机序列类的大小与其他类的大小相似。图3说明了小样本学习中任务集的构造。
58.步骤2:基于互信息最大化深度元学习模型mimml:
59.步骤2-1:模型概述。mimml的概述如图4所示。在嵌入模块(图4(a))中,从任务集中随机抽取一个任务作为模型输入。对于每个任务,来自支持集和查询集的肽序列被textcnn(文本卷积神经网络)主干进行嵌入,以表示其潜在特征。在主干模块(图4(b))中,基于多通道卷积机制的特征提取器自动提取局部和全局序列信息,以学习区分性特征,这些特征适用于不同的功能肽分类,而不仅仅适用于特定任务。标准化嵌入模块的输出后,原型模块通过平均属于相应功能类的支持嵌入产生不同肽类的原型(图4(c))。然后计算查询嵌入和原型嵌入之间的欧氏距离,以确定每个查询肽序列属于各个功能类的概率分布。然后,优化模块从交叉熵中获得监督信息,从互信息中获得无监督信息(图4(d))。最后,通过梯度下降算法对联合目标进行优化,迭代更新模型参数。
60.步骤2-2:定义和回顾元学习范式:
61.与传统的监督学习不同,元学习是通过任务而不是样本来训练的。此外,元测试评估模型快速适应新任务的能力,而不是实现最佳性能的能力。具体地说,给定一个带有标签的数据集其中xi和yi分别表示肽序列i及其相应数字标签的原始特征。数据子集之间有以下关系:
62.其中为元训练任务集,用于
学习不同种类生物活性肽的元知识,为元验证集用于调整模型超参数,为用于模型评估的元测试任务集。令和分别表示和的标签集合,他们满足这意味着需要元学习模型需要通过从基类学习来适应以前从未见过的新任务。
63.详细地说,每个任务都以的形式定义,其中,k表示要分类的类数量,表示在特定任务中给定给每个类的训练序列的数量,表示给定给每个类的测试序列的数量。在元训练过程中,每个任务由一个支持集和一个查询集组成,其中的k个类别从中随机抽取。支持集包含个序列(分别从这k类中随机选择个)用于训练或调整元模型,查询集包含(分别从这k类中随机选择个)用于评估模型。在元测试过程中,大多数设置与训练阶段一致,主要区别在于k类是从而不是中随机选择。元学习过程如图5所示。
64.步骤2-3:原型网络:
65.protonet是一种基于度量的元学习方法,其核心思想是确定每个类的原型,测量样本嵌入和原型嵌入之间的距离,以便根据最近的原型对样本进行分类。它假设来自同一功能类的序列应该比嵌入空间中其他功能类的序列更接近彼此。元模型学习的是通过挖掘不同肽类序列之间的区别特征,将肽序列映射到适当的嵌入。测量不同功能类之间差异的公共知识将作为元知识从元训练过程中的大量训练任务中提取,并可应用于元测试过程中的新任务(看不见)。
66.为了更好地了解肽序列的鉴别特征,本实施例中选择textcnn主干作为特征提取器来自动学习肽嵌入。
67.形式地,给定一个在适应阶段(专门指代支持集上的操作),从支持集中对应于同一类的经过主干f
φ
获得的序列嵌入的平均值被视为对应功能类别的原型:
[0068][0069][0070]
其中,zi表示l2规范化后的嵌入特征,ck表示类k的原型。注意,为了提高特征提取器捕获有用信息的能力,在上进行有监督的预训练,而不是使用随机初始化的f
φ
作为元学习的主干。
[0071]
在推理阶段(专门指代查询集上的操作),计算查询嵌入和原型嵌入之间的距离作为分类度量,从而评估嵌入和原型的正确性。将查询序列分类为最近的类,并将softmax
归一化距离视为预测置信度:
[0072][0073][0074]
其中,距离度量d(
·
)是欧几里德距离,τ是温度系数(超参数)。
[0075]
对于模型优化,在元训练过程中,根据最大似然估计(mle),需要优化分类目标,即交叉熵(ce)损失:
[0076][0077][0078]
其中,如果序列属于函数类k,则y
ik
=1,否则y
ik
=0。ce交叉熵损失为模型优化参数提供监督信息。在元测试过程中,原始版本的原型网络在计算上的原型后对中的序列进行归纳推理,而不进行任何调整,因为是不可获取的,即元模型不知道查询样本的标签(这些标签是用于评估的)。
[0079]
步骤2-4:互信息最大化:
[0080]
互信息最大化(mim)的设计是针对生物活性肽挖掘场景的,其中查询集中要挖掘的肽的数量应该很大。基于互信息的直推(transductive)方法可以充分利用待预测肽的无监督信息,提高预测性能,适合于生物活性肽的挖掘。本实施例中,根据shannon的信息理论和相关研究,将样本与支持集和查询集中标签之间互信息的经验估计定义为:
[0081][0082][0083][0084]
其中,和分别表示的经验边际熵和的经验条件熵。和的定义与上述类似。α是非负超参数,设置α=1可恢复为标准互信
息。有必要设置α《1,以避免支配从而更加强调的正则化,防止模型将大多数样本赌在一个类上。
[0085]
属于功能类k的肽i的预测概率表示为p
ik
是预测矩阵m中的元素m(i,k)。在元训练和元测试程序中,可以在支持集和查询集中最大化肽序列嵌入特征和类别标签之间的互信息,以利用无监督信息。它相当于最小化mi损失和其定义如下:
[0086][0087]
步骤2-5:联合优化:
[0088]
最终的优化目标是使ce损失和mi损失的加权和最小,加权系数为λ。对于元训练过程,ce损失包含来自支持集和查询集的损失,因为查询集中的监督信息可用,并且互信息由原型网络输出的预测矩阵m估计。因此,最终目标定义如下:
[0089][0090]
对于元测试过程,只能使用支持集中的标签来调整模型。同样,元测试的最终损失函数正式表示为:
[0091][0092]
本实施例中,与在计算中的原型后直接预测查询样本标签的原始的原型网络不同,针对最终损失函数调整了元模型,以利用最终预测和评估之前的直推信息,从而利用中的无监督互信息。
[0093]
综上,在元训练过程中,mimml对任务进行采样,并根据从为每个章节计算的原型,然后实现中查询序列的预测。然后,它根据监督损失和无监督损失对模型进行训练。
[0094]
在元测试过程中,对于每个新任务在以与元训练相同的方式获得查询序列的预测之后,需要根据支持集的监督损失和查询集的无监督损失来调整模型,以利用特定新任务的无监督互信息。最后,基于改进的元模型,通过平均中大量新任务的性能来评估元学习的泛化性能。
[0095]
步骤3:确定评估指标:
[0096]
本实施例中,使用常见的分类指标来评估mimml的性能,包括准确性(acc)、敏感性(se)、特异性(sp)和马修相关系数(mcc)。这些指标的公式描述如下:
[0097][0098]
其中tp是真阳性样本数,fp是假阳性样本数,tn是真阴性样本数,fn是假阴性样本数。此外,还使用另一种称为接收器工作特性曲线下面积(auc)的指标进行评估。为了更全面地评估该模型,考虑了其他四个标准,其中一个用于评估元学习在多大程度上优于监督学习,另外三个用于评估元模型在少镜头场景中对特定生物活性肽的挖掘能力。
[0099]
对于第一个设计的指标,定义了标记“f”,如果元模型在acc方面优于监督深度学习方法至少5%。对于其余三个指标,分别定义了“s”、“c”和“e”,以衡量其性能与当前相关方法相比有多好。如果模型优于最先进的(sota)方法,将其表示为“s”,如果模型可与sota方法相比,将其表示为“c”,如果模型可与某些现有竞争方法相比,将其表示为“e”。更准确地说,如果acc差异小于5%,将比较模型定义为可比较。
[0100]
实施例3
[0101]
本实施例3中,提供的一种生物活性肽功能类型预测方法,通过最大化互信息与最小化交叉熵的联合优化改进现有的元学习算法原型网络(protonet),专门为生物活性肽的挖掘和预测而设计,能够统一预测多种的生物活性肽,mimml基于embedding技术而不基于特征工程和人工设计的特征,嵌入使用的主干是textcnn,主干在进行元学习前先在所有基类上进行监督预训练,mimml的训练和测试所使用的数据集是bpd,其中包含了44种不同功能的生物活性肽。
[0102]
本实施例3中,比较了mimml通过fine-tuning的方式与现有方法在相应数据集中的独立测试性能,从整体上证明了该方法在下游任务的泛化优越性。
[0103]
实验结果表明,在所有所有数据集中,该模型在优于现有模型或与之相当。其次,对相应数据集构造tasks,比较mimml以transductive inference的方式与现有方法在相应数据集上小样本场景下的泛化性能。结果表明,mimml在小样本场景下的性能优于传统的监督学习,并且在大部分数据集上mimml仅使用小量样本(1个,5个或10%,25%,50%,75%的训练集样本)进行适应后便能取得与sota方法相差不多的性能。
[0104]
最后,对mimml与protonet进行性能比较以及消融实验,以展现所提出模型的优越性及其对性能具有关键作用的模型要素,并且分析mimml在不同元学习设置下的性能变化。
[0105]
综上所述,能够总结出mimml相比于现有sota方法,传统监督学习,和经典元学习方法protonet的优越性,能够以一种统一的框架准确地预测生物活性肽,仅使用小量样本适应对应的任务便能够取得不错的性能。
[0106]
标准监督学习环境下微调的mimml与现有活性肽预测方法的基准比较:
[0107]
实验设置。为了评估mimml的有效性,首先对其与现有的生物活性肽功能预测方法进行了评估和比较。由于所有现有的肽预测方法都基于传统的监督学习模型,在特定肽基准训练集中微调元模型后,将独立测试性能与相应的sota方法进行比较,以评估元模型的
泛化性。
[0108]
选择了六种具有代表性的生物活性肽进行分析和比较(见表1,在标准监督学习环境中生物活性肽预测任务的性能比较)。
[0109]
表1
[0110][0111]
主干网络(textcnn)优于或可与现有方法相比。如表1所示,对于aap,主干在acc和mcc上的性能分别比targetantiangio好0.0185和0.0398。对于其他肽,可以观察到类似的结果。
[0112]
具体而言,textcnn主干在24个数据集中的20个数据集上优于或可与现有方法相比,证明了嵌入技术和深度学习模型处理生物序列的强大能力。
[0113]
由于textcnn在肽发现方面具有卓越的能力,将其视为有代表性的监督学习基线,并将其与mimml进行比较,以在下面的讨论中指出元学习相对于传统监督学习的优势。mimml优于或可与现有方法相比,并且优于纯粹的主干网络。表1显示了部分结果。
[0114]
总体来说,mimml在24个相应数据集中的15个数据集中的性能优于9种sota方法,即targetantiagio、deep antifp、ibitter fuse、b3pred、idppiv scm、pretp el、iqsp、thpep和iumami scm。此外,对于其余9个数据集,微调mimml可与sota方法相当。这足以证明元模型的良好预测能力。此外,mimml在微调后总体上优于纯主干,这表明通过元训练过程学习的元知识对下游肽预测任务有很大帮助。具体来说,元知识主要体现在auc和mcc的改进上,而不仅仅是acc,这表明元知识将使模型更加健壮,并提高整体性能。例如,与sota方法相比,mimml在mcc上的增益约为0.05。
[0115]
小样本场景下使用直推推断的mimml与现有活性肽预测方法的比较:
[0116]
实验设置。虽然前一部分描述了微调mimml处理下游肽识别任务的出色能力,但它不能证明元学习在适应样本稀缺任务方面的性能。
[0117]
为了评估mimml在小样本场景中的预测能力,将每个肽基准数据集视为一个新任务,选择现有基准训练集的不同比例的序列来构建支持集,同时使用独立测试集中的所有肽来形成查询集。
[0118]
采用训练后的元模型,以适应特定的任务来进行直推推断transductive inference。让“mimml-r%”表示使用r%的样本微调mimml。此外,为了突出元学习与监督学习相比的泛化能力,还对主干在小样本场景下进行对比实验。让“backbone-r%”表示使用r%的样本来训练主干。特别是,“mimml-1/5”(“backbone-1/5”)意味着只有1或5个序列用
于模型未调配(模型训练),用于模拟极为稀缺样本的场景。表2和图6显示了一些生物活性肽的直推推断性能。表2为小样本场景中生物活性肽预测任务的性能比较;为了直观地显示和分析结果,表3、表4总结了上述四个设计指标的统计结果。由于sota和其他竞争方法仅提供auc,而不提供其他指标,因此表3、表4中不包括psbp。
[0119]
表2
[0120][0121]
与小样本场景中的现有方法相比,mimml只需少量训练样本,即可获得相当甚至更好的性能。图6、表2-表4表明,训练样本越少,预测性能越低。一些肽的acc受样品减少的影响较小,并保持良好的性能。
[0122]
具体而言,对于aap和thp两种多肽,mimml仅使用5个样本就可以实现与sota相当的性能,并且仅使用十分之一的训练数据就超过sota方法。从表3可以看出,mimml仅用10%的训练数据即可优于sota方法(“s”)的,在23个数据集中有7个。mimml仅用25%的数据即可与sota方法(“c”)相比的,23个数据集中有8个。mimml仅用10%的训练数据即可与一些现有竞争方法(“e”)相比的,在23个数据集中有7个。特定肽数据集中出现的“s”、“c”、“e”越多(表3中每列的计数越多),出现这些标记时所需的样本越少(表3中每行中的列越左),mimml的性能越好。
[0123]
表3
[0124][0125]
note that
″1″
or
″5″
denotes usingonly 1 or 5samples to adapt the meta-model.
[0126]
在小样本场景下mimml优于textcnn主干,元学习比监督学习具有更高的预测置信度。图6、表2-表4指出,在相同的少数镜头设置下,mimml始终优于基于纯监督学习的主干。
[0127]
具体而言,表2说明,当仅给出1或5个训练样本时,与所有种类生物活性肽的纯主链相比,mimml的acc至少有5%的改善。随着训练样本的增加,mimml(元学习)和textcnn主干(监督学习)之间的性能差距将逐渐缩小,但mimml的性能仍优于textcnn主干。
[0128]
表4
[0129][0130]
note that
″1″
or
″5″
denotes using only 1or 5samples to adapt the meta-model.
[0131]
为了更微观地分析mimml和textcnn主干之间的差异,可视化了它们的预测置信度,如图7所示。一方面,它证明了传统的监督学习在缺乏足够的训练样本时存在局限性,容易过度拟合,导致泛化能力差。另一方面,它为元学习提供了有利的证据,以适应少数镜头设置的任务,解决样本不足的问题。通过分布,可以看到,与textcnn主干相比,mimml在0.5(中间区域)附近的点明显较少,在0或1(两端)附近的密集点明显较多。这意味着,由于元知识的存在,元模型的预测置信度将更高。
[0132]
标准元测试的性能分析:
[0133]
实验设置。为了进一步评估mimml适应新任务的有效性,了解生物活性肽挖掘场景下元学习的特点,有必要将mimml与典型元学习方法进行比较。选择protonet作为基线,因为mimml是protonet的一个变体,在该变体中引入了互信息最大化。上述六种不同的元序列和元测试数据集划分方案均用于评估。参考常见的几种小样本学习设置,设置=2、5、10和=10、5、1。此外,无论是元训练还是元测试,每个任务的查询数都设置为15。在元训练后,通过平均100个元测试任务的准确度来评估元模型,以获得更多的统计显著性。通过以下控制变量来分析性能如何随这些设置而变化。此外,还进行了消融实验,以研究哪些因素对mimml有重要影响。表5、图8-图10总结了比较结果。此外,为了直观地理解mimml的工作原理,将嵌入维度设置为2,并在带有决策边界的平面中进行描述,如图10所示。
[0134]
表5
[0135][0136]
note:subscripts denote theperformance improvement of mimml relative to protonet in the same setting.
″‑″
denotes the result that is not available in the setting.
[0137]
mimml在所有小样本设置中都优于protonet,并获得了显著的改进。表5所示的比较结果表明,就acc而言,mimml在几乎所有设置中都有约4%的改进。最值得注意的是,在“24meta-trainclasses20meta-test classes”设置中,10-way 1-shot任务的acc增加了16%以上。总的来说,越严格的小样本设置(更多的方式、更多的元测试类、更少的镜头和更少的元训练类),改进就越大,因为可以看到最小的改进出现在表的左上角,而最大的改进出现在表的右下角。总体而言,大幅增长意味着互信息的有效性。
[0138]
元学习任务随着way的增加和shot的减少而变得困难。如图8(a)所示,性能与镜头大小呈正相关,与道路大小呈负相关。从shot角度分析,可以得出这样的结论:训练样本越多,acc越高。从way的角度分析,可以观察到模型需要区分的类越多,性能越低,因为任务变得越困难。
[0139]
所给元训练的类越多,元模型学习的跨任务信息越多,元测试类需要区分的类越多,元测试任务就越困难。在图8(b)中,可以看到,当元测试类是固定的,例如10,为元训练提供的类越多,元模型学习的跨任务信息越多,因此元测试性能越好。直观地说,固定元训练类并增加元测试类,元测试性能将降低。
[0140]
元训练、预训练和任务特定适应对绩效有显著影响。如图9所示,元训练产生了最大的性能改进,acc平均增加8.38%,训练平均增加4.92%,任务特定适应平均增加3.20%。因此,元训练的影响最大,证明通过元学习获得的跨任务元知识是提高绩效的最重要因素。
[0141]
似乎最大化直推互信息可以隐式地最大化类之间的距离,最小化类内的距离。在图10中,可以观察到所有样本都位于圆弧上,并且根据角度区分不同类型的决策区域。在适应(adapt=0)之前,即原始的原型网络,并没有明显的决策边界规律。随着模型的自适应,决策边界变得越来越规则,即逐渐呈现按角度划分的规律,各类的面积逐渐趋于均匀。此外,类内的样本逐渐接近原型,而不同类之间的样本逐渐远离原型。
[0142]
综上,本实施例所述的基于互信息最大化元学习的生物活性肽预测方法,使用来自各种功能肽的少量样本,通过元学习获取了各种功能之间的区别信息并表征功能差异,并能够在下游功能肽预测任务中表现良好,优于或与现有方法相媲美,尤其是在小样本场景下与传统方法相比性能有显著提升。总之,本研究是功能肽挖掘领域的一项开创性工作,为生物序列分析中的少数样本学习问题提供了同类解决方案,加速了新功能肽的发现。
[0143]
实施例4
[0144]
本发明实施例4提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存
储介质用于存储计算机指令,所述计算机指令被处理器执行时,实现如上所述的基于元学习的生物活性肽预测方法,该方法包括:
[0145]
获取待预测的生物活性肽序列信息;
[0146]
利用通过最大化互信息与最小化交叉熵的联合优化改进的元学习算法预先训练好的预测模型对待预测的生物活性肽序列信息进行处理,获得生物活性肽的功能类型;其中,预先训练好的预测模型使用训练集训练得到,所述训练集包括多个生物活性肽序列以及标注生物活性肽功能类型的标签。
[0147]
实施例5
[0148]
本发明实施例5提供一种计算机程序(产品),包括计算机程序,所述计算机程序当在一个或多个处理器上运行时,用于实现如上所述的基于元学习的生物活性肽预测方法,该方法包括:
[0149]
获取待预测的生物活性肽序列信息;
[0150]
利用通过最大化互信息与最小化交叉熵的联合优化改进的元学习算法预先训练好的预测模型对待预测的生物活性肽序列信息进行处理,获得生物活性肽的功能类型;其中,预先训练好的预测模型使用训练集训练得到,所述训练集包括多个生物活性肽序列以及标注生物活性肽功能类型的标签。
[0151]
实施例6
[0152]
本发明实施例6提供一种电子设备,包括:处理器、存储器以及计算机程序;其中,处理器与存储器连接,计算机程序被存储在存储器中,当电子设备运行时,所述处理器执行所述存储器存储的计算机程序,以使电子设备执行实现如上所述的基于元学习的生物活性肽预测方法的指令,该方法包括:
[0153]
获取待预测的生物活性肽序列信息;
[0154]
利用通过最大化互信息与最小化交叉熵的联合优化改进的元学习算法预先训练好的预测模型对待预测的生物活性肽序列信息进行处理,获得生物活性肽的功能类型;其中,预先训练好的预测模型使用训练集训练得到,所述训练集包括多个生物活性肽序列以及标注生物活性肽功能类型的标签。
[0155]
综上所述,本发明实施例所述的基于元学习的生物活性肽预测方法及系统,提出了互信息最大化元学习(mimml),这是一种基于互信息最大化的深度元学习方法,用于预测各种肽的生物活性,包括已知和未知的生物活性。为了解决现有研究中样本不足的问题,首次提出使用元学习,可以在有限的样本下明确地学习如何有效地适应新任务。与传统手工特征的使用不同,mimml利用嵌入(embedding)技术自动学习肽序列与特定肽生物活性相关的适应性特征。值得注意的是,利用卷积来充分增强学习到的嵌入特征的表示能力和可解释性。此外,考虑通过互信息来充分利用多肽嵌入特征与其对应标签的无监督信息,这是专门为多肽挖掘和预测的应用场景而专门设计的,从而促进性能的改进。比较结果表明,mimml在预测性能上优于最先进的方法,并且在不同的肽生物活性功能预测中具有很强的鲁棒性。值得注意的是,mimml即使使用少得多的训练样本也可以实现具有竞争力的性能,并且适合于各种功能肽的挖掘。通过特征分析来研究和揭示不同种类肽之间的潜在关系。
[0156]
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明公开的技术方案的基础上,本领域技术人
员在不需要付出创造性劳动即可做出的各种修改或变形,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。