嵌入式现场可编程门阵列时序签发
1.相关申请的交叉引用
2.本技术是于2019年3月25日提交的美国专利申请第16/363,434号的继续申请,并要求该美国专利申请第16/363,434号的优先权,该美国专利申请的内容通过引用整体并入本文。
背景技术:
3.专用集成电路(asic)是针对特定应用构建的定制电路。许多asic是通过将多个分立电路设计进行组合来设计的。例如,asic可以与执行通用功能的现有电路设计组合来利用用于定制应用的新电路设计。
4.现场可编程门阵列(fpga)是在生产之后进行定制的电路。asic可以包括fpga,并且可以通过将定制的电路设计与现有的fpga设计进行组合来设计asic。
5.在制造集成设计之前,进行签发检查。签发检查对集成设计进行测试,以确定所制造的电路是否将按预期执行。签发检查中的一个是静态时序分析。静态时序分析验证设计中的所有逻辑路径在预期的时钟频率下按照预期操作。
6.确保静态时序分析成功的一个方法是在主asic与集成fpga之间添加接口集群,使得使用寄存器来保持在设计之间传输的每个数据值。这种方法需要用于寄存器的附加的电路系统,并且为寄存器值的设置和读取添加了延迟。
附图说明
7.在附图的图中以示例而非限制的方式示出了所公开的技术的一些实施方式。
8.图1是根据一些示例实施方式的时序模式的高层级示意图。
9.图2是根据一些示例实施方式的使用具有内部发散的时钟主干输入的时序场景的示意图。
10.图3是根据一些示例实施方式的使用具有外部发散的时钟主干输入的时序场景的示意图。
11.图4是根据一些示例实施方式的使用边界时钟输入的时序场景的示意图。
12.图5是示出根据一些示例实施方式的用于执行本文所述方法的系统的部件的框图。
13.图6是示出根据本发明的各实施方式的用于将第一电路设计与第二电路设计集成的方法的操作的流程图。
14.图7是根据一些示例实施方式的将时钟信号和数据提供至嵌入式fpga的电路的示意图。
15.图8是根据一些示例实施方式的将时钟信号提供至嵌入式fpga并且接收来自该嵌入式fpga的数据的电路的示意图。
16.图9是根据一些示例实施方式的将数据提供至嵌入式fpga并且接收来自该嵌入式fpga的时钟信号的电路的示意图。
17.图10是根据一些示例实施方式的接收来自嵌入式fpga的时钟信号和数据的电路的示意图。
具体实施方式
18.现在将描述用于嵌入式fpga签发的示例方法、系统和电路。在以下描述中,阐述了具有特定于示例的细节的许多示例以提供对示例实施方式的理解。然而,对于本领域普通技术人员将明显的是,可以在没有这些特定于示例的细节的情况下以及/或者在与此处给出的细节的组合不同的情况下实践这些示例。因此,给出具体实施方式是为了简化说明的目的,而不是限制性的。
19.高级时序模式具有源于主asic并且终止于嵌入式fpga内的寄存器处的路径,从而将接口集群寄存器旁路。终止寄存器可以存在于主asic与嵌入式fpga之间的边界处或者嵌入式fpga的内部深处。路径可以包括逻辑元件。这样的路径在集成asic时序签发期间不能被精确地建模,这是因为这样的路径取决于特定设计的放置与布线实现。因此,这种模式使用时序预算以对静态时序分析期间的延迟进行建模。
20.在具有内部发散的时钟主干输入的时序场景中,通过时钟主干将来自主asic中的锁相环(pll)的时钟输出驱动至嵌入式fpga中,并且从该嵌入式fpga中发散至接口集群寄存器和asic边界中。结果是时钟发散点在时钟树中较晚发生。因此,发散时钟路径短并且具有相对小的延迟。
21.除了时钟发散在时钟进入嵌入式fpga主干之前出现之外,具有外部发散的时钟主干输入的时序场景与内部发散场景类似。
22.在边界时钟输入场景中,pll驱动主asic和嵌入式fpga接口集群两者。每个接口集群驱动嵌入式fpga的相关联的逻辑集群中的逻辑。pll还驱动嵌入式fpga的时钟主干。这种场景允许时钟发散点在时钟树中晚出现,减少了时钟偏移和片上变化的影响。然而,当在来自不同边界时钟分支(例如,时钟主干和接口集群时钟)的两个寄存器之间创建路径时,这种场景可能导致边界时钟偏移。因此,在将主asic与嵌入式fpga集成时,考虑边界约束。
23.在这些所描述的场景中的每一个场景中,避免了由现有技术解决方案所需要的接口寄存器中的至少一部分接口寄存器,允许得到的asic更小,消耗更少功率,或者更快地执行操作。
24.图1是根据本发明的各实施方式的时序模式100的高层级示意图。时序模式100使用接口集群120将包含在库(或.lib)文件中的用于主asic 110的第一电路设计与用于嵌入式fpga 130(也称为fpga结构)的第二电路设计集成。fpga设计通常由重复的构建块例如查找表(lut)、加法器和触发器构成。
25.主asic包括寄存器140。嵌入式fpga包括寄存器160。接口集群120包括一组接口集群寄存器和对应的多路复用器。为清楚起见,仅示出了单个接口集群寄存器150和对应的多路复用器170。接口集群120使数据能够在主asic 110与嵌入式fpga 130之间传输。
26.多路复用器170使得能够在两个数据路径之间进行选择。在一个数据路径中,数据直接从寄存器140传输至寄存器160,而不需要从寄存器150中检索。这个数据路径避免了存储和检索寄存器数据中固有的延迟。然而,如果从寄存器140至寄存器160的路径无法满足时序约束(例如,太长),则由寄存器160接收到的数据将不总是准确的,并且计算误差将会
430包括多个逻辑集群例如逻辑集群460a、460b和460c,以及时钟主干450。接口集群440包括一个或更多个寄存器。
37.pll 420生成提供至时钟主干450、asic ip 410以及接口集群440的寄存器的时钟信号。时钟信号从时钟主干450提供至逻辑集群460a至460c。将时钟信号从逻辑集群460a至460c提供至接口集群440的对应部分。因此,接口集群440访问逻辑集群460a至460c以及pll 420两者的时钟。如果在由不同时钟分支驱动的两个寄存器之间存在数据路径,则时序场景400可能导致时钟交叉问题,这可能需要同步电路。
38.逻辑集群460a至460c中的每一个逻辑集群的接口时钟可以以低偏移驱动其自身集群以及接口集群的对应部分。附加地或替选地,逻辑集群460a至460c中的每一个逻辑集群的接口时钟可以以高偏移驱动其自身集群以及接口集群的对应部分。因此,在各实施方式中,对于每个时钟在具有较多接口时钟与较低偏斜或者具有较少接口时钟与较高偏斜之间进行权衡。
39.图5是示出根据一些示例实施方式的对fpga进行编程的计算机500的部件的框图。无需在各实施方式中使用所有部件。例如,客户端、服务器、自主系统和基于云的网络资源可以均使用不同组的部件,或者在服务器的情况下,使用例如较大的存储装置。
40.计算机500(也称为计算装置500和计算机系统500)形式的一个示例计算装置可以包括全部通过总线540连接的处理器505、存储器存储装置510、可移除存储装置515和不可移除存储装置520。尽管示例计算装置被示出并被描述为计算机500,但是在不同的实施方式中,计算装置可以具有不同的形式。例如,计算装置可以替代地为智能电话、平板电脑、智能手表或者包括与关于图5示出和描述的元件相同或相似的元件的其他计算装置。诸如智能电话、平板电脑和智能手表的装置统称为“移动装置”。此外,尽管各种数据存储元件被示为计算机500的一部分,但该存储装置还可以或替选地包括可经由诸如因特网的网络访问的基于云的存储装置,或基于服务器的存储装置。
41.存储器存储装置510可以包括易失性存储器545和非易失性存储器550,并且可以存储程序555。计算机500可以包括或访问计算环境,该计算环境包括各种计算机可读介质,例如易失性存储器545、非易失性存储器550、可移除存储装置515和不可移除存储装置520。计算机存储装置包括随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom)和电可擦除可编程只读存储器(eeprom)、闪存或其他存储器技术、致密盘只读存储器(cd rom)、数字多功能盘(dvd)或其他光盘存储器、磁带盒、磁带、磁盘存储装置或其他磁存储装置、或任何其他能够存储计算机可读指令的介质。
42.计算机500可以包括或访问计算环境,该计算环境包括输入接口525、输出接口530和通信接口535。输出接口530可以接口至或包括诸如触摸屏的显示装置,显示装置也可以用作输入装置。输入接口525可以接口至或包括以下中的一个或更多个:触摸屏、触摸板、鼠标、键盘、摄像装置、一个或更多个特定于装置的按钮、集成在计算机500内或者经由有线或无线数据连接耦接至计算机500的一个或更多个传感器以及其他输入装置。计算机500可以使用通信接口535在联网环境中操作,以连接至一个或更多个远程计算机例如数据库服务器。远程计算机可以包括个人计算机(pc)、服务器、路由器、网络pc、对等装置或其他公共网络节点等。通信接口535可以连接至局域网(lan)、广域网(wan)、蜂窝网络、wifi网络、蓝牙网络或其他网络。
43.存储在计算机可读介质上的计算机指令(例如,存储在存储器存储装置510中的程序555)可由计算机500的处理器505执行。硬盘驱动器、cd-rom以及ram是包括非暂态计算机可读介质例如存储装置的物品的一些示例。在载波被认为过暂态的程度上,术语“计算机可读介质”和“存储装置”不包括载波。“计算机可读非暂态介质”包括所有类型的计算机可读介质,包括磁存储介质、光存储介质、闪存介质和固态存储介质。应当理解,软件可以安装在计算机中并且与计算机一起销售。替选地,可以获得软件并且将其加载至计算机中,包括通过物理介质或分发系统来获得软件,例如包括从由软件创建者所拥有的服务器或者从并非由软件创建者拥有但由软件创建者使用的服务器来获得软件。例如,软件可以存储在服务器上以通过因特网分发。
44.程序555被示出为包括配置模块560以及放置与布线模块565。本文描述的模块中的任何一个或更多个模块可以使用硬件(例如,机器的处理器、asic、fpga或其任何合适的组合)来实现。此外,这些模块中的任何两个或更多个模块可以被组合成单个模块,并且本文中针对单个模块描述的功能可以在多个模块之中细分。此外,根据各示例实施方式,本文中描述为在单个机器、数据库或装置内实现的模块可以跨多个机器、数据库或装置分布。
45.时序模块560生成时序模式的选择。例如,时序模块560可以提供用户接口以允许用户从多个时序模式中选择时序模式。基于所选择的时序模式,时序模块560为与第二电路设计集成的第一电路设计生成边界条件。
46.基于第一电路设计、第二电路设计和时序模式,放置与布线模块565确定得到的集成电路的物理布局。例如,包括asic ip形式的第一电路、efpga形式的第二电路的集成电路和接口集群可以基于时序场景200、时序场景300或时序场景400的选择在物理层级处进行布局。
47.图6是示出根据本发明的各实施方式的用于将第一电路设计与第二电路设计集成的方法600的操作的流程图。方法600包括操作610和620。作为示例而非限制,方法600被描述为由图5的计算机500执行。
48.在操作610中,基于时序模式,时序模块560通过在第二电路内的一个或更多个寄存器处终止第一电路设计与第二电路设计的第二电路之间的时序来为第一电路(例如,asic)的第一电路设计生成边界条件,第二电路是可编程逻辑电路(例如,efpga)。例如,时序场景200至400中的一个或更多个时序场景可以在时序模式100下使用以确定边界条件。
49.在操作620中,基于所生成的边界条件,放置与布线模块565将第一电路设计与第二电路设计集成为集成电路设计。集成电路设计可以被制造成集成电路。当与使用现有技术时序模式制造的集成电路相比时,通过使用时序模式100得到的集成电路具有优越的性能,这是因为在第一电路设计与第二电路设计之间的接口处减少了时钟延迟。
50.在一些示例实施方式中,边界条件的生成包括执行第一电路的时序分析。例如,可以确定第一电路的输出中的每一个输出处相对于第一电路的时钟信号的延迟。在一些示例实施方式中,第一电路设计与第二电路设计的集成包括基于第一电路的时序分析来确定第二电路中寄存器的位置。
51.考虑来自第一电路的单个输出,通过将第一电路边界处的延迟与到第二电路中的一组寄存器中的每一个寄存器的延迟进行组合,可以确定到每个寄存器的总延迟,并且将总延迟与预定阈值(例如,最大允许延迟)进行比较。寄存器中满足时序要求的一个寄存器
被选择为用于存储来自第一电路的输出的寄存器。对来自第一电路的每个输出重复这一处理,使用于第一电路的终止寄存器被放置在第二电路内的适当位置处。
52.可以在第一电路设计与第二电路设计的集成之前制造第一电路。例如,可以制造将第一电路的asic与未编程的fpga结构进行组合的电路。在操作620中确定的集成电路设计是通过对现有的fpga结构进行编程来实现的。
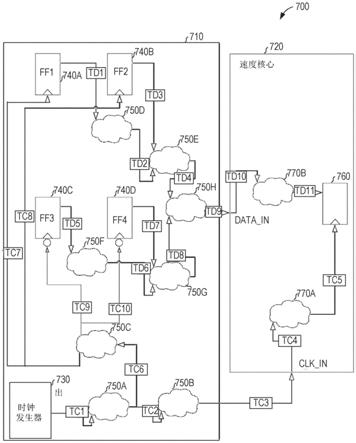
53.图7是根据一些示例实施方式的将来自第一电路710的时钟信号和数据提供至嵌入式fpga 720的电路700的示意图。第一电路710包括时钟发生器730;寄存器(也称为触发器)740a、740b、740c和740d;以及逻辑块750a、750b、750c、750d、750e、750f、750g和750h。嵌入式fpga 720包括寄存器760以及逻辑块770a和770b。
54.逻辑块750a至750h以及770a至770b可以包括任意数量的基本电路元件。因此,在时钟信号或数据信号至逻辑元件的输入与来自逻辑元件的输出之间存在时间滞后。这在图7中示出为tc1至tc10,其指示由时钟发生器730生成的时钟信号上的10种不同的延迟;以及td1至td11,其指示数据信号上的11个不同的延迟。如果至逻辑块的时钟信号和数据信号不同步,则数据信号必须存储在寄存器中,使得该数据信号可以在逻辑元件准备好访问数据时由逻辑块访问。
55.因此,时序约束协助寄存器740a至740d以及寄存器760的放置。如果满足针对逻辑块的时序约束并且时钟信号和数据信号同步(在误差裕度内),则无需插入寄存器。如果时钟信号和数据信号不同步,则添加寄存器以满足时序约束。在读取寄存器的值之前,由于该值设置在时钟周期中,因此寄存器的添加在电路中引入延迟。
56.在电路700中,将时钟和数据两者输入至嵌入式fpga 720,但是由时钟信号和数据所采用的路由是不同的。因此,延迟td9与tc3可能不相等。附加地,逻辑块770a和770b可以具有不相等的延迟,从而增加或减少寄存器760处的时序差。
57.为了确定针对电路700的时序约束,限定了裕度。在一些示例实施方式中,启动时钟具有用于建立的 5%片上变化(ocv)的裕度和用于保持的-5%ocv的裕度;数据路径具有用于建立的 5%ocv的裕度和用于保持的-5%ocv的裕度;并且捕获时钟具有用于建立的-5%ocv的裕度和用于保持的 5%ocv的裕度。附加地,进行了假设,以使得能够执行计算。在一些示例实施方式中,假设:建立来自ff1(寄存器740a)的路径对于正沿启动时钟是关键的;保持来自ff2(寄存器740b)的路径对于正沿启动时钟是关键的;建立来自ff3(寄存器740c)的路径对于负沿启动时钟是关键的;保持来自ff4(寄存器740d)的路径对于负沿启动时钟是关键的;并且每个延迟具有最大值和最小值以及上升值和下降值。附加值包括启动时钟延迟值、数据路径延迟值和捕获时钟延迟值。启动时钟延迟值、数据路径延迟值和捕获时钟延迟值通过第一电路710的分析确定。例如,通过模拟时钟发生器730、寄存器740a至740d和逻辑元件750a至750h,确定了标称时钟时序与时钟信号和数据信号至第一电路710的边缘或嵌入式fpga 720的传播之间的各种延迟值。基于这些裕度和值,定义了以下变量:
58.ta_mr
–
最大上升延迟
59.ta_mf
–
最大下降延迟
60.ta_m
–
最大延迟
61.ta_mr
–
最小上升延迟
62.ta_mf
–
最小下降延迟
63.ta_m
–
最小延迟
64.ts
–
捕获时钟的建立时间
65.th
–
捕获时钟的保持时间
66.tp
–
启动时钟的周期
67.使用裕度、所定义的变量和通过逻辑块的延迟,限定了使得能够求解时序约束的式。
68.对于通过data_in上升的数据的正沿建立关键时序:
69.1.05*(tc1_mr tc6_mr tc7_mr) 1.05*(td1_mr td2_mf td4_mf td9_mr td10_mr td11_mf)《=0.95*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) tp-ts crpr1
70.对于通过data_in下降的数据的正沿建立关键时序:
71.1.05*(tc1_mr tc6_mr tc7_mr) 1.05*(td1_mr td2_mf td4_mf td9_mf td10_mf td11_mf)《=0.95*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) tp-ts crpr2
72.对于通过data_in上升的数据的负沿建立关键时序:
73.1.05*(tc1_mf tc6_mf tc9_mf) 1.05*(td5_mr td6_mf td8_mf td9_mr td10_mr td11_mf) tp/2《=0.95*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) tp-ts
74.crpr3
75.对于通过data_in下降的数据的负沿建立关键时序:
76.1.05*(tc1_mf tc6_mf tc9_mf) 1.05*(td5_mr td6_mf td8_mf td9_mf td10_mf td11_mf) tp/2《=0.95*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) tp-ts crpr4
77.对于通过data_in上升的数据的正沿保持关键时序:
78.0.95*(tc1_mr tc6_mr tc8_mr) 0.95*(td3_mr td4_mf td9_mr td10_mr td11_mf)》=1.05*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) th crpr5
79.对于通过data_in下降的数据的正沿保持关键时序:
80.0.95*(tc1_mr tc6_mr tc8_mr) 0.95*(td3_mr td4_mf td9_mf td10_mf td11_mf)》=1.05*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) th crpr6
81.对于通过data_in上升的数据的负沿保持关键时序:
82.0.95*(tc1_mf tc6_mf tc10_mf) 0.95*(td7_mr td8_mf td9_mr td10_mr td11_mf) tp/2》=1.05*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) th crpr7
83.对于通过data_in下降的数据的负沿保持关键时序:
84.0.95*(tc1_mf tc6_mf tc10_mf) 0.95*(td7_mr td8_mf td9_mf td10_mf td11_mf) tp/2》=1.05*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) th crpr8
85.在求解八个时钟再收敛悲观移除(clock reconvergence pessimism removal,crpr)值之后,定义时钟和延迟:
86.##时钟定义与延迟
87.create_clock clk-period tp[get_ports clk_in]create_clock vclk-period tp
[0088]
set_clock_latency-source-late-rise[expr 1.05*(tc1_mr tc2_mr tc3_mr)][get_clocks clk]
[0089]
set_clock_latency-source-late-fall[expr 1.05*(tc1_mf tc2_mf tc3_mf)]
[get_clocks clk]
[0090]
set_clock_latency-source-early-rise[expr 0.95*(tc1_mr tc2_mr tc3_mr)][get_clocks clk]
[0091]
set_clock_latency-source-early-fall[expr 0.95*(tc1_mf tc2_mf tc3_mf)][get_clocks clk]
[0092]
##数据延迟
[0093]
set_input_delay-clock vclk-rise-max-add_delay[expr 1.05*(tc1_mr tc6_mr tc7_mr) 1.05*(td1_mr td2_mf td4_mf td9_mr)-crpr1][get_ports data_in]
[0094]
set_input_delay-clock vclk-fall-max-add_delay[expr 1.05*(tc1_mr tc6_mr tc7_mr) 1.05*(td1_mr td2_mf td4_mf td9_mf)-crpr2][get_ports data_in]
[0095]
set_input_delay-clock vclk-clock_fall-rise-max-add_delay[expr 1.05*(tc1_mf tc6_mf tc9_mf) 1.05*(td5_mr td6_mf td8_mf td9_mr)-crpr3][get_ports data_in]
[0096]
set_input_delay-clock vclk-clock_fall-fall-max-add_delay[expr 1.05*(tc1_mf tc6_mf tc9_mf) 1.05*(td5_mr td6_mf td8_mf td9_mf)-crpr4][get_ports data_in]
[0097]
set_input_delay-clock vclk-rise-min-add_delay[expr 0.95*(tc1_mr tc6_mr tc7_mr) 0.95*(td3_mr td4_mf td9_mr)-crpr5][get_ports data_in]
[0098]
set_input_delay-clock vclk-fall-min-add_delay[expr 0.95*(tc1_mr tc6_mr tc7_mr) 0.95*(td3_mr td4_mf td9_mf)-crpr6][get_ports data_in]
[0099]
set_input_delay-clock vclk-clock_fall-rise-min-add_delay[expr 0.95*(tc1_mf tc6_mf tc10_mf) 0.95*(td7_mr td8_mf td9_mr)-crpr7][get_ports data_in]
[0100]
set_input_delay-clock vclk-clock_fall-fall-min-add_delay[expr 0.95*(tc1_mr tc6_mr tc7_mr) 0.95*(td3_mr td4_mf td9_mf)-crpr8][get_ports data_in]
[0101]
使用所定义的时钟执行时序检查:
[0102]
对于通过data_in上升的数据的正沿建立关键时序:
[0103]
《clock_rise_max_rise_input_delay on data_in》 1.05*(td10_mr td11_mf)《=《min_rise_latency on clk_in》 0.95*(tc4_mr tc5_mr) tp-ts
[0104]
=》1.05*(tc1_mr tc6_mr tc7_mr) 1.05*(td1_mr td2_mf td4_mf td9_mr)-crpr1 1.05*(td10_mr td11_mf)《=0.95*(tc1_mr tc2_mr tc3_mr) 0.95*(tc4_mr tc5_mr) tp-ts
[0105]
对于通过data_in下降的数据的正沿建立关键时序:
[0106]
《clock_rise_max_fall_input_delay on data_in》 1.05*(td10_mf td11_mf)《=《min_rise_latency on clk_in》 0.95*(tc4_mr tc5_mr) tp-ts
[0107]
=》1.05*(tc1_mr tc6_mr tc7_mr) 1.05*(td1_mr td2_mf td4_mf td9_mf)-crpr2 1.05*(td10_mf td11_mf)《=0.95*(tc1_mr tc2_mr tc3_mr) 0.95*(tc4_mr tc5_mr) tp-ts
[0108]
对于通过data_in上升的数据的负沿建立关键时序:
[0109]
《clock_fall_max_rise_input_delay on data_in》 1.05*(td10_mr td11_mf)
tp/2《=《min_rise_latency on clk_in》 0.95*(tc4_mr tc5_mr) tp-ts
[0110]
=》1.05*(tc1_mf tc6_mf tc9_mf) 1.05*(td5_mr td6_mf td8_mf td9_mr)-crpr3 1.05*(td10_mr td11_mf) tp/2《=0.95*(tc1_mr tc2_mr tc3_mr) 0.95*(tc4_mr tc5_mr) tp-ts
[0111]
对于通过data_in下降的数据的负沿建立关键时序:
[0112]
《clock_fall_max_fall_input_delay on data_in》 1.05*(td10_mf td11_mf) tp/2《=《min_rise_latency on clk_in》 0.95*(tc4_mr tc5_mr) tp-ts
[0113]
=》1.05*(tc1_mf tc6_mf tc9_mf) 1.05*(td5_mr td6_mf td8_mf td9_mf)-crpr4 1.05*(td10_mf td11_mf) tp/2《=0.95*(tc1_mr tc2_mr tc3_mr) 0.95*(tc4_mr tc5_mr) tp-ts
[0114]
对于通过data_in上升的数据的正沿保持关键时序:
[0115]
《clock_rise_min_rise_input_delay on data_in》 0.95*(td10_mr td11_mf)》=《max_rise_latency on clk_in》 1.05*(tc4_mr tc5_mr) th
[0116]
=》0.95*(tc1_mr tc6_mr tc8_mr) 0.95*(td3_mr td4_mf td9_mr)-crpr5 0.95*(td10_mr td11_mf)》=1.05*(tc1_mr tc2_mr tc3_mr) 1.05*(tc4_mr tc5_mr) th对于通过data_in下降的数据的正沿保持关键时序:
[0117]
《clock_rise_min_fall_input_delay on data_in》 0.95*(td10_mf td11_mf)》=《max_rise_latency on clk_in》 1.05*(tc4_mr tc5_mr) th
[0118]
=》0.95*(tc1_mr tc6_mr tc8_mr) 0.95*(td3_mr td4_mf td9_mf)-crpr6 0.95*(td10_mf td11_mf)》=1.05*(tc1_mr tc2_mr tc3_mr) 1.05*(tc4_mr tc5_mr) th
[0119]
对于通过data_in上升的数据的负沿保持关键时序:
[0120]
《clock_fall_min_rise_input_delay on data_in》 0.95*(td10_mr td11_mf) tp/2》=《max_rise_latency on clk_in》 1.05*(tc4_mr tc5_mr) th
[0121]
=》0.95*(tc1_mf tc6_mf tc10_mf) 0.95*(td7_mr td8_mf td9_mr)-crpr7 0.95*(td10_mr td11_mf) tp/2》=1.05*(tc1_mr tc2_mr tc3_mr) 1.05*(tc4_mr tc5_mr) th
[0122]
对于通过data_in下降的数据的负沿保持关键时序:
[0123]
《clock_fall_min_fall_input_delay on data_in》 0.95*(td10_mf td11_mf) tp/2》=《max_rise_latency on clk_in》 1.05*(tc4_mr tc5_mr) th
[0124]
=》0.95*(tc1_mf tc6_mf tc10_mf) 0.95*(td7_mr td8_mf td9_mf)-crpr8 0.95*(td10_mf td11_mf) tp/2》=1.05*(tc1_mr tc2_mr tc3_mr) 1.05*(tc4_mr tc5_mr) th
[0125]
图8是根据一些示例实施方式的将来自第一电路710的时钟信号提供至嵌入式fpga 720的电路800的示意图,第一电路710接收来自嵌入式fpga 720的数据。第一电路710、嵌入式fpga 720、时钟发生器730以及逻辑块750a至750c是与图7所示的电路相同的电路,但是图8处理从嵌入式fpga 720至第一电路710的返回数据路径。因此,第一电路710还包括逻辑块850a、850b、850c和850d以及支持寄存器840a、840b、840c和840d,这些寄存器在图7中均未示出。类似地,嵌入式fpga 720还包括逻辑块870a和870b以及支持寄存器860,其在图7中未示出。如图7所示,时序约束协助寄存器840a至840d以及寄存器860的放置。
[0126]
为了清楚起见,图7至图8均示出了将第一电路710与嵌入式fpga连接的时钟与数据路径的单个示例,但是应当理解,实际电路可能包括第一电路710与嵌入式fpga 720之间的在两个方向上的许多数据路径。
[0127]
用于电路700的裕度、假设和变量定义与用于电路800的相同。限定了使得能够求解时序约束的式。
[0128]
对于通过data_in上升的数据的正沿建立关键时序:
[0129]
1.05*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) 1.05*(td11_mf td10_mr td9_mr td4_mf td2_mf td1_mr)《=0.95*(tc1_mr tc6_mr tc7_mr) tp-ts crpr1
[0130]
对于通过data_in下降的数据的正沿建立关键时序:
[0131]
1.05*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) 1.05*(td11_mf td10_mf td9_mf td4_mf td2_mf td1_mr)《=0.95*(tc1_mr tc6_mr tc7_mr) tp-ts crpr2
[0132]
对于通过data_in上升的数据的负沿建立关键时序:
[0133]
1.05*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) 1.05*(td11_mf td10_mr td9_mr td8_mf td6_mf td5_mr)《=0.95*(tc1_mf tc6_mf tc9_mf) tp/2-ts crpr3
[0134]
对于通过data_in下降的数据的负沿建立关键时序:
[0135]
1.05*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) 1.05*(td11_mf td10_mf td9_mf td8_mf td6_mf td5_mr)《=0.95*(tc1_mf tc6_mf tc9_mf) tp/2-ts crpr4
[0136]
对于通过data_in上升的数据的正沿保持关键时序:
[0137]
0.95*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) 0.95*(td11_mf td10_mr td9_mr td4_mf td3_mr)》=1.05*(tc1_mr tc6_mr tc8_mr) th crpr5
[0138]
对于通过data_in下降的数据的正沿保持关键时序:
[0139]
0.95*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) 0.95*(td11_mf td10_mf td9_mf td4_mf td3_mr)》=1.05*(tc1_mr tc6_mr tc8_mr) th crpr6
[0140]
对于通过data_in上升的数据的负沿保持关键时序:
[0141]
0.95*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) 0.95*(td11_mf td10_mr td9_mr td8_mf td7_mr)》=1.05*(tc1_mf tc6_mf tc10_mf) th-tp/2 crpr7
[0142]
对于通过data_in下降的数据的负沿保持关键时序:
[0143]
0.95*(tc1_mr tc2_mr tc3_mr tc4_mr tc5_mr) 0.95*(td11_mf td10_mf td9_mf td8_mf td7_mr)》=1.05*(tc1_mf tc6_mf tc10_mf) th-tp/2 crpr8
[0144]
在求解八个crpr值之后,定义时钟和延迟:
[0145]
##时钟定义与延迟
[0146]
create_clock clk-period tp[get_ports clk_in]
[0147]
create_clock vclk-period tp
[0148]
set_clock_latency-source-late-rise[expr 1.05*(tc1_mr tc2_mr tc3_mr)][get_clocks clk]
[0149]
set_clock_latency-source-late-fall[expr 1.05*(tc1_mf tc2_mf tc3_mf)][get_clocks clk]
[0150]
set_clock_latency-source-early-rise[expr 0.95*(tc1_mr tc2_mr tc3_mr)][get_clocks clk]
[0151]
set_clock_latency-source-early-fall[expr 0.95*(tc1_mf tc2_mf tc3_mf)][get_clocks clk]
[0152]
##数据延迟
[0153]
set_output_delay-clock vclk-rise-max-add_delay[expr 1.05*(td9_mr td4_mf td2_mf td1_mr)-0.95*(tc1_mr tc6_mr tc7_mr) ts-crpr1][get_ports data_out]
[0154]
set_output_delay-clock vclk-fall-max-add_delay[expr 1.05*(td9_mf td4_mf td2_mf td1_mr)-0.95*(tc1_mr tc6_mr tc7_mr) ts-crpr2][get_ports data_out]
[0155]
set_output_delay-clock vclk-clock_fall-rise-max-add_delay[expr 1.05*(td9_mr td8_mf td6_mf td5_mr)-0.95*(tc1_mf tc6_mf tc9_mf) ts-crpr3][get_ports data_out]
[0156]
set_output_delay-clock vclk-clock_fall-fall-max-add_delay[expr 1.05*(td9_mf td8_mf td6_mf td5_mr)-0.95*(tc1_mf tc6_mf tc9_mf) ts-crpr4][get_ports data_out]
[0157]
set_output_delay-clock vclk-rise-min-add_delay[expr 0.95*(td9_mr td4_mf td3_mr)-1.05*(tc1_mr tc6_mr tc8_mr)-th-crpr5][get_ports data_out]
[0158]
set_output_delay-clock vclk-fall-min-add_delay[expr 0.95*(td9_mf td4_mf td3_mr)-1.05*(tc1_mr tc6_mr tc8_mr)-th-crpr6][get_ports data_out]
[0159]
set_output_delay-clock vclk-clock_fall-rise-min-add_delay[expr 0.95*(td9_mr td8_mf td7_mr)-1.05*(tc1_mf tc6_mf tc10_mf)-th-crpr7][get_ports data_out]
[0160]
set_output_delay-clock vclk-clock_fall-fall-min-add_delay[expr 0.95*(td9_mf td8_mf td7_mr)-1.05*(tc1_mf tc6_mf tc10_mf)-th-crpr8][get_ports data_out]
[0161]
使用所定义的时钟执行时序检查:
[0162]
对于通过data_in上升的数据的正沿建立关键时序:
[0163]
《clock_rise_max_rise_input_delay on data_in》 1.05*(td10_mr td11_mf)《=《min_rise_latency on clk_in》 0.95*(tc4_mr tc5_mr) tp-ts
[0164]
=》1.05*(tc1_mr tc6_mr tc7_mr) 1.05*(td1_mr td2_mf td4_mf td9_mr)-crpr1 1.05*(td10_mr td11_mf)《=0.95*(tc1_mr tc2_mr tc3_mr) 0.95*(tc4_mr tc5_mr) tp-ts
[0165]
对于通过data_in下降的数据的正沿建立关键时序:
[0166]
《clock_rise_max_fall_input_delay on data_in》 1.05*(td10_mf td11_mf)《=《min_rise_latency on clk_in》 0.95*(tc4_mr tc5_mr) tp-ts
[0167]
=》1.05*(tc1_mr tc6_mr tc7_mr) 1.05*(td1_mr td2_mf td4_mf td9_mf)-crpr2 1.05*(td10_mf td11_mf)《=0.95*(tc1_mr tc2_mr tc3_mr) 0.95*(tc4_mr tc5_mr) tp-ts
[0168]
对于通过data_in上升的数据的负沿建立关键时序:
[0169]
《clock_fall_max_rise_input_delay on data_in》 1.05*(td10_mr td11_mf) tp/2《=《min_rise_latency on clk_in》 0.95*(tc4_mr tc5_mr) tp-ts
[0170]
=》1.05*(tc1_mf tc6_mf tc9_mf) 1.05*(td5_mr td6_mf td8_mf td9_mr)-crpr3 1.05*(td10_mr td11_mf) tp/2《=0.95*(tc1_mr tc2_mr tc3_mr) 0.95*(tc4_mr tc5_mr) tp-ts
[0171]
对于通过data_in下降的数据的负沿建立关键时序:
[0172]
《clock_fall_max_fall_input_delay on data_in》 1.05*(td10_mf td11_mf) tp/2《=《min_rise_latency on clk_in》 0.95*(tc4_mr tc5_mr) tp-ts
[0173]
=》1.05*(tc1_mf tc6_mf tc9_mf) 1.05*(td5_mr td6_mf td8_mf td9_mf)-crpr4 1.05*(td10_mf td11_mf) tp/2《=0.95*(tc1_mr tc2_mr tc3_mr) 0.95*(tc4_mr tc5_mr) tp-ts
[0174]
对于通过data_in上升的数据的正沿保持关键时序:
[0175]
《clock_rise_min_rise_input_delay on data_in》 0.95*(td10_mr td11_mf)》=《max_rise_latency on clk_in》 1.05*(tc4_mr tc5_mr) th
[0176]
=》0.95*(tc1_mr tc6_mr tc8_mr) 0.95*(td3_mr td4_mf td9_mr)-crpr5 0.95*(td10_mr td11_mf)》=1.05*(tc1_mr tc2_mr tc3_mr) 1.05*(tc4_mr tc5_mr) th对于通过data_in下降的数据的正沿保持关键时序:
[0177]
《clock_rise_min_fall_input_delay on data_in》 0.95*(td10_mf td11_mf)》=《max_rise_latency on clk_in》 1.05*(tc4_mr tc5_mr) th
[0178]
=》0.95*(tc1_mr tc6_mr tc8_mr) 0.95*(td3_mr td4_mf td9_mf)-crpr6 0.95*(td10_mf td11_mf)》=1.05*(tc1_mr tc2_mr tc3_mr) 1.05*(tc4_mr tc5_mr) th对于通过data_in上升的数据的负沿保持关键时序:
[0179]
《clock_fall_min_rise_input_delay on data_in》 0.95*(td10_mr td11_mf) tp/2》=《max_rise_latency on clk_in》 1.05*(tc4_mr tc5_mr) th
[0180]
=》0.95*(tc1_mf tc6_mf tc10_mf) 0.95*(td7_mr td8_mf td9_mr)-crpr7 0.95*(td10_mr td11_mf) tp/2》=1.05*(tc1_mr tc2_mr tc3_mr) 1.05*(tc4_mr tc5_mr) th
[0181]
对于通过data_in下降的数据的负沿保持关键时序:
[0182]
《clock_fall_min_fall_input_delay on data_in》 0.95*(td10_mf td11_mf) tp/2》=《max_rise_latency on clk_in》 1.05*(tc4_mr tc5_mr) th
[0183]
=》0.95*(tc1_mf tc6_mf tc10_mf) 0.95*(td7_mr td8_mf td9_mf)-crpr8 0.95*(td10_mf td11_mf) tp/2》=1.05*(tc1_mr tc2_mr tc3_mr) 1.05*(tc4_mr tc5_mr) th
[0184]
图9是根据一些示例实施方式的将来自第一电路910的数据提供至嵌入式fpga 920的电路900的示意图,第一电路910接收来自嵌入式fpga 920的时钟信号。第一电路910包括寄存器970a和970b以及逻辑块960a、960b、960c和960d。嵌入式fpga 920包括时钟发生器930、寄存器940和逻辑块950。
[0185]
逻辑块950以及960a至960d可以包括任意数量的基本电路元件。因此,在时钟信号或数据信号至逻辑元件的输入与来自逻辑元件的输出之间存在时间滞后。这在图9中示出为tc1至tc5,其指示由时钟发生器930所生成的时钟信号上的五种不同的延迟,以及示出为td1至td6,其指示数据信号上的六种不同的延迟。如图7至图8,如果至逻辑块的时钟信号和
数据信号不同步,则数据信号必须存储在寄存器中,使得该数据信号可以在逻辑元件准备好访问数据时由逻辑块访问。
[0186]
因此,时序约束协助寄存器940以及寄存器970a至970b的放置。在电路900中,时钟信号被输入至第一电路910并且数据从第一电路910输出。因此,tc6(经由嵌入式fpga 920内的路径从时钟发生器930至寄存器940的时间)与td6(经由通过第一电路910(包括用于生成寄存器940的数据的逻辑块)的路径从时钟发生器930至寄存器940的时间)之间的延迟差可能相当大。因此,可以使用中间寄存器970a至970b来满足时序约束。
[0187]
为了确定针对电路900的时序约束,限定了裕度。在一些示例实施方式中,启动时钟具有用于建立的 5%ocv的裕度和用于保持的-5%ocv的裕度;数据路径具有用于建立的 5%ocv的裕度和用于保持的-5%ocv的裕度;以及捕获时钟具有用于建立的-5%ocv的裕度和用于保持的 5%ocv的裕度。附加地,进行了假设,以使得能够执行计算。在一些示例实施方式中,假设:建立来自ff1(寄存器970a)的路径对于正沿启动时钟是关键的;保持来自ff2(寄存器970b)的路径对于正沿启动时钟是关键的;并且每个延迟具有最大值和最小值以及上升值和下降值。
[0188]
使用裕度、变量和通过逻辑块的延迟,限定了使得能够求解时序约束的式。
[0189]
对于通过data_in上升的数据的正沿建立关键时序:
[0190]
1.05(tc1_mr tc2_mr tc3_mr tc4_mr) 1.05*(td1_mr td3_mr td4_mr td5_mr td6_mr)《=0.95*(tc6_mr) tp-ts crpr1
[0191]
对于通过data_in下降的数据的正沿建立关键时序:
[0192]
1.05(tc1_mr tc2_mr tc3_mr tc4_mr) 1.05*(td1_mr td3_mr td4_mf td5_mf td6_mr)《=0.95*(tc6_mr) tp-ts crpr2
[0193]
对于通过data_in上升的数据的正沿保持关键时序:
[0194]
0.95*(tc1_mr tc2_mr tc3_mr tc5_mr) 0.95*(td2_mr td3_mr td4_mr td5_mr td6_mr)》=1.05*(tc6_mr) th crpr3
[0195]
对于通过data_in下降的数据的正沿保持关键时序:
[0196]
0.95*(tc1_mr tc2_mr tc3_mr tc5_mr) 0.95*(td2_mr td3_mr td4_mf td5_mf td6_mr)》=1.05*(tc6_mr) th crpr4
[0197]
在求解四个crpr值之后,定义时钟和延迟:
[0198]
##时钟定义与延迟
[0199]
create_clock clk-period tp[get_ports clk_out]
[0200]
create_clock vclk-period tp
[0201]
set_clock_latency-source 0.0[get_clocks clk]
[0202]
##数据延迟
[0203]
set_input_delay-clock vclk-rise-max-add_delay[expr 1.05*(tc2_mr tc3_mr tc4_mr) 1.05*(td1_mr td3_mr td4_mr)-crpr1][get_ports data_in]
[0204]
set_input_delay-clock vclk-fall-max-add_delay[expr 1.05*(tc2_mr tc3_mr tc4_mr) 1.05*(td1_mr td3_mr td4_mf)-crpr2][get_ports data_in]
[0205]
set_input_delay-clock vclk-rise-min-add_delay[expr 0.95*(tc2_mr tc3_mr tc5_mr) 0.95*(td2_mr td3_mr td4_mr)-crpr3][get_ports data_in]
[0206]
set_input_delay-clock vclk-fall-min-add_delay[expr 0.95*(tc2_mr tc3_mr tc5_mr) 0.95*(td2_mr td3_mr td4_mf)-crpr4][get_ports data_in]
[0207]
使用所定义的时钟执行时序检查:
[0208]
对于通过data_in上升的数据的正沿建立关键时序:
[0209]
1.05*(tc1_mr) 《clock_rise_max_rise_input_delay on data_in》 1.05*(td5_mr td6_mr)《=《min_rise_latency on clk_in》 0.95*(tc6_mr) tp-ts
[0210]
=》1.05*(tc1_mr) 1.05*(tc2_mr tc3_mr tc4_mr) 1.05*(td1_mr td3_mr td4_mr)-crpr1 1.05*(td5_mr td6_mr)《=0.0 0.95*(tc6_mr) tp-ts
[0211]
对于通过data_in下降的数据的正沿建立关键时序:
[0212]
1.05*(tc1_mr) 《clock_rise_max_fall_input_delay on data_in》 1.05*(td5_mf td6_mr)《=《min_rise_latency on clk_in》 0.95*(tc6_mr) tp-ts
[0213]
=》1.05*(tc1_mr) 1.05*(tc2_mr tc3_mr tc4_mr) 1.05*(td1_mr td3_mr td4_mf)-crpr2 1.05*(td5_mf td6_mr)《=0.0 0.95*(tc6_mr) tp-ts
[0214]
对于通过data_in上升的数据的正沿保持关键时序:
[0215]
0.95*(tc1_mr) 《clock_rise_min_rise_input_delay on data_in》 0.95*(td5_mr td6_mr)》=《max_rise_latency on clk_in》 1.05*(tc6_mr) th
[0216]
=》0.95*(tc1_mr) 0.95*(tc2_mr tc3_mr tc5_mr) 0.95*(td2_mr td3_mr td4_mr)-crpr3 0.95*(td5_mr td6_mr)》=0.0 1.05*(tc6_mr) th
[0217]
对于通过data_in下降的数据的正沿保持关键时序:
[0218]
0.95*(tc1_mr) 《clock_rise_min_fall_input_delay on data_in》 0.95*(td5_mf td6_mr)》=《max_rise_latency on clk_in》 1.05*(tc6_mr) th
[0219]
=》0.95*(tc1_mr) 0.95*(tc2_mr tc3_mr tc5_mr) 0.95*(td2_mr td3_mr td4_mf)-crpr4 0.95*(td5_mf td6_mr)》=0.0 1.05*(tc6_mr) th
[0220]
图10是根据一些示例实施方式的包括第一电路1010和嵌入式fpga1020的电路1000的示意图,第一电路1010将时钟信号提供至嵌入式fpga 1020。第一电路1010包括时钟发生器1030、分频时钟发生器1040、逻辑块1050a和1050b以及寄存器1060。嵌入式fpga 1020包括逻辑块1070和寄存器1080。
[0221]
逻辑块1050a、1050b和1070可以包括任意数量的基本电路元件。因此,在时钟信号或数据信号至逻辑元件的输入与来自逻辑元件的输出之间存在时间滞后。这在图10中示出为tc1至tc4,其指示由时钟发生器1030所生成的时钟信号上的四种不同的延迟,以及示出为td1至td3,其指示数据信号上的三种不同的延迟。如图7至图8,如果至逻辑块的时钟信号和数据信号不同步,则数据信号必须存储在寄存器中,使得该数据信号可以在逻辑元件准备好访问数据时由逻辑块访问。
[0222]
为了确定针对电路1000的时序约束,限定了裕度。在一些示例实施方式中,启动时钟具有用于建立的 5%ocv的裕度和用于保持的-5%ocv的裕度;数据路径具有用于建立的 5%ocv的裕度和用于保持的-5%ocv的裕度;以及捕获时钟具有用于建立的-5%ocv的裕度和用于保持的 5%ocv的裕度。附加地,进行了假设,以使得能够执行计算。在一些示例实施方式中,假设:每个延迟具有最大值和最小值以及上升值和下降值。使用裕度、变量和通过逻辑块的延迟,限定了使得能够求解时序约束的式。
[0223]
对于通过data_in上升的数据的正沿建立关键时序:
[0224]
1.05(tc1_mr tc5_mr tc6_mr) 1.05*(td1_mr td2_mr td3_mr)《=0.95*(tc1_mr tc2_mr tc3_mr tc4_mr) 2*tp-ts crpr1
[0225]
对于通过data_in下降的数据的正沿建立关键时序:
[0226]
1.05(tc1_mr tc5_mr tc6_mr) 1.05*(td1_mr td2_mf td3_mf)《=0.95*(tc1_mr tc2_mr tc3_mr tc4_mr) 2*tp-ts crpr2
[0227]
对于通过data_in上升的数据的正沿保持关键时序:
[0228]
0.95*(tc1_mr tc5_mr tc6_mr) 0.95*(td1_mr td2_mr td3_mr)》=1.05*(tc1_mr tc2_mr tc3_mr tc4_mr) th crpr3
[0229]
对于通过data_in下降的数据的正沿保持关键时序:
[0230]
0.95*(tc1_mr tc5_mr tc6_mr) 0.95*(td1_mr td2_mf td3_mf)》=1.05*(tc1_mr tc2_mr tc3_mr tc4_mr) th crpr4
[0231]
在求解四个crpr值之后,定义时钟和延迟:
[0232]
##时钟定义与延迟
[0233]
create_clock clkdiv2-period[expr 2*tp][get_ports clk_in]create_clock vclkdiv2-period[expr 2*tp]
[0234]
set_clock_latency-source-late-rise[expr 1.05*(tc1_mr tc2_mr)][get_clocks clkdiv2]
[0235]
set_clock_latency-source-late-fall[expr 1.05*(tc1_mf tc2_mf)][get_clocks clkdiv2]
[0236]
set_clock_latency-source-early-rise[expr 0.95*(tc1_mr tc2_mr)][get_clocks clkdiv2]
[0237]
set_clock_latency-source-early-fall[expr 0.95*(tc1_mf tc2_mf)][get_clocks clkdiv2]
[0238]
##数据延迟
[0239]
set_input_delay-clock vclkdiv2-rise-max-add_delay[expr 1.05*(tc1_mr tc5_mr tc6_mr) 1.05*(td1_mr td2_mr)-crpr1][get_ports data_in]
[0240]
set_input_delay-clock vclkdiv2-fall-max-add_delay[expr 1.05*(tc1_mr tc5_mr tc6_mr) 1.05*(td1_mr td2_mf)-crpr2][get_ports data_in]
[0241]
set_input_delay-clock vclkdiv2-rise-min-add_delay[expr 0.95*(tc1_mr tc5_mr tc6_mr) 0.95*(td1_mr td2_mr)-crpr3][get_ports data_in]
[0242]
set_input_delay-clock vclkdiv2-fall-min-add_delay[expr 0.95*(tc1_mr tc5_mr tc6_mr) 0.95*(td1_mr td2_mf)-crpr4][get_ports data_in]
[0243]
使用所定义的时钟执行时序检查:
[0244]
对于通过data_in上升的数据的正沿建立关键时序:
[0245]
《clock_rise_max_rise_input_delay on data_in》 1.05*(td3_mr)《=《min_rise_latency on clk_in》 0.95*(tc3_mr tc4_mr) 2*tp-ts
[0246]
=》1.05*(tc1_mr tc5_mr tc6_mr) 1.05*(td1_mr td2_mr)-crpr1 1.05*(td3_mr)《=0.95*(tc1_mr tc2_mr) 0.95*(tc3_mr tc4_mr) 2*tp-ts
[0247]
对于通过data_in下降的数据的正沿建立关键时序:
[0248]
《clock_rise_max_fall_input_delay on data_in》 1.05*(td3_mf)《=《min_rise_latency on clk_in》 0.95*(tc3_mr tc4_mr) 2*tp-ts
[0249]
=》1.05*(tc1_mr tc5_mr tc6_mr) 1.05*(td1_mr td2_mf)-crpr2 1.05*(td3_mf)《=0.95*(tc1_mr tc2_mr)
[0250]
0.95*(tc3_mr tc4_mr) 2*tp-ts
[0251]
对于通过data_in上升的数据的正沿保持关键时序:
[0252]
《clock_rise_min_rise_input_delay on data_in》 0.95*(td3_mr)》=《max_rise_latency on clk_in》 1.05*(tc3_mr tc4_mr) th
[0253]
=》0.95*(tc1_mr tc5_mr tc6_mr) 0.95*(td1_mr td2_mr)-crpr3 0.95*(td3_mr)》=1.05*(tc1_mr tc2_mr) 1.05*(tc3_mr tc4_mr) th
[0254]
对于通过data_in下降的数据的正沿保持关键时序:
[0255]
《clock_rise_min_fall_input_delay on data_in》 0.95*(td3_mf)》=《max_rise_latency on clk_in》 1.05*(tc3_mr tc4_mr) th
[0256]
=》0.95*(tc1_mr tc5_mr tc6_mr) 0.95*(td1_mr td2_mf)-crpr4 0.95*(td3_mf)》=1.05*(tc1_mr tc2_mr) 1.05*(tc3_mr tc4_mr) th
[0257]
提供了本公开内容的摘要以符合37 c.f.r.
§
1.72(b),其要求摘要使得读者能够快速地确定技术性公开内容的性质。提交摘要时将理解,摘要将不用于解释或限制权利要求书。另外,在前述具体实施方式中,可以看到的是,出于使本公开内容精简的目的,各个特征在单个实施方式中被组合在一起。本公开内容的该方法不应被解释为限制权利要求书。因此,所附权利要求书由此被并入具体实施方式中,其中每个权利要求自身独立地作为单独的实施方式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
