1.本公开总体上涉及可以提供改进的计算机性能、特征和用途的用于计算机学习的系统和方法。更具体地,本公开涉及用于分类的系统和方法。
背景技术:
2.最近的神经网络模型在英语和其他语言的情感分类上取得了显着的性能。但是,它们的成功在很大程度上取决于大量标签的数据或平行语料库的可用性。实际上,某些资源缺乏的语言或应用具有有限的标签的数据,甚至没有任何标签或平行语料库,这可能会阻碍训练强大且准确的分类器。
3.为了建立用于资源缺乏的语言的分类模型(诸如情感分类模型),最近,研究人员开发了跨语言文本分类(cross
‑
lingual text classification,cltc)模型(参见xuochen xu和yiming yang,“cross
‑
lingual distillation for text classification”,计算语言学协会(acl)第55届年会论文集,第1415至1425页,加拿大温哥华(2017年)(以下称xu和yang(2017))和akiko eriguchi,melvin johnson,orhan firat,hideto kazawa,以及wolfgang macherey,技术报告“zero
‑
shot cross
‑
lingual classification using multilingual neural machine translation”,arxiv:1809.04686(2018)(在下文中称为eriguchi等(2018)),其将来自资源丰富的(源)语言的知识迁移到资源较少的(目标)语言。这些模型的核心是学习共享的语言不变的特征空间,所述空间表示两种语言的分类。因此,从源语言训练而来的模型可以应用于目标语言。根据如何学习共享特征空间,通常分为三类,即单词级对齐、句子级对齐和文档级对齐。这些模型可以很好地捕获两种语言之间的语义相似性。但是,它们需要平行资源,诸如双语词典、平行句子和平行维基百科(wikipedia)文章。这样的限制可能会阻止这些模型在没有任何平行资源的情况下在语言中应用。
4.近来,已经进行了一些尝试来开发“零资源”模型。最值得注意的是,yftah ziser和roi reichart,“deep pivot
‑
based modeling for cross
‑
language cross
‑
domain transfer with minimal guidance”,自然语言处理经验方法(emnlp)2018年会议会议论文集,第238
–
249页,比利时布鲁塞尔(2018)(以下称为ziser和reichart(2018))提出了一种跨语言和跨域(cross
‑
lingual&cross
‑
domain,clcd)模型,所述模型建立在基于枢轴的学习和双语单词嵌入的基础上。尽管clcd不直接需要标签的数据或平行语料库,但它需要双语单词嵌入(bilingual word embeddings,bwe),这需要成千上万个已翻译的单词作为监督信号。xilun chen,yu sun,ben athiwaratkun,claire cardie和kilian q.weinberger,“adversarial deep averaging networks for cross
‑
lingual sentiment classification”,trans.assoc.comput.linguistics,6:557
–
570(2018)(以下称chen等(2018))开发了对抗性深度平均网络来学习用于分类的潜在句子表示,但它隐式地依赖bwe,bwe需要对大型双语平行语料库进行预训练。zhuang chen和tieyun qian,“transfer capsule network for aspect level sentiment classification”,第57届计算语言学协会(acl)会议论文集,第547
‑
556页,意大利佛罗伦萨(2019年)(以下称为chen和qian
(2019))通过使用无监督的bwe,(guillaume lample,alexis conneau,marc'aurelio ranzato,ludovic denoyer和herv
é
j
é
gou,“word translation without parallel data”,第六届国际学习表示会议(iclr)论文集,加拿大温哥华(2018b)(以下称lample等(2018b)),并为每种源语言添加单独的特征提取器从而消除对平行语料库的依赖,而将chen等(2018)的跨语言模型扩展到多个源语言。然而,如他们的实验研究所示,他们的模型对bwe的质量非常敏感,并且在诸如英语
‑
日语之类的相距较远的语言对上表现不佳。
5.并行地,从原始维基百科(wikipedia)文本训练的跨语言的语言模型(language model,lm),诸如多语言bert(jacob devlin,ming
‑
wei chang,kenton lee和kristina toutanova,“pre
‑
training of deep bidirectional transformers for language understanding”,2019年计算语言学协会北美分会会议论文集:人类语言技术(naacl
‑
hlt),第4171
–
4186页,明尼苏达州明尼阿波利斯(2019))(以下称为devlin等(2019))和xlm(alexis conneau和guillaume lample,“cross
‑
lingual language model pretraining”,神经信息处理系统(neurips)的发展,第7057
–
7067页,加拿大温哥华(2019年))(以下称为conneau和lample(2019))已经普遍用于解决零样本分类问题(shijie wu和mark dredze,“beto,bentz,becas:the surprising cross
‑
lingual effectiveness of bert”,2019年自然语言处理经验方法会议和第9届国际自然语言处理联合会议(emnlp
‑
ijcnlp)的会议记录中,第833
‑
844页,中国香港(2019年)(以下称wu和dredze(2019))。这些模型使用同时从多种语言训练的bert样式的transformer架构(基于自注意力机制的全新神经网络架构)(ashish vaswani,noam shazeer,niki parmar,jakob uszkoreit,llion jones,aidan n.gomez,lukasz kaiser和illia polosukhin,“attention is all you need”,神经信息学(nips)的进展,第6000
‑
6010页,long beach,ca,(2017))(以下简称vaswani等(2017))以构造句子编码器,并基于来自源语言的标签的训练数据对编码器和分类器进行微调,如图1中所示。
6.图1是用于无监督分类的原始的基于lm的跨语言微调方法的示意图。虚线表示预训练过程,实线表示微调过程。如图所示,经过微调的模型被应用于目标语言。整个过程可以被认为不需要任何标签的数据或平行语料库。但是,在“零平行资源”设置下,从每种语言内的自监督掩码语言建模训练的编码器可能无法很好地捕获语言之间的语义相似性,这可能会损害微调模型的泛化性能。
7.因此,需要提供改进的跨语言分类的系统和方法。
技术实现要素:
8.在第一方面中,提供一种用于训练多视图编码器
‑
分类器系统的方法,包括:
9.从以下中选择文本文档:(1)包括第一语言的文本文档的第一数据集,其中第一数据集的子集形成标签的数据集,对于所述子集的每个文本文档,所述标签的数据集包括与所述文本文档相关联的标签;(2)包括第二语言的文本文档的第二数据集,或(3)两者;
10.将选择的文本文档翻译成另一种语言;
11.将选择的文本文档及其翻译输入到多视图编码器
‑
分类器系统中,所述多视图编码器
‑
分类器系统包括:
12.编码器,将文本文档转换为潜在表示;以及
13.文本分类器,接收文本文档的潜在表示作为输入并输出所述文本文档的标签;
14.对于以其原语言输入的文本文档,确定与使用编码器和解码器将文本文档重构到其原语言中的重构误差有关的域内正则化,所述解码器将来自编码器的潜在表示解码到文本文档的重构中;
15.对于作为翻译输入的文本文档,确定与使用文本文档的翻译版本作为编码器的输入而将文本文档重构到其原语言中的重构误差相关的跨域正则化;
16.对于来自标签的数据集的文本文档,确定多视图分类损失,所述多视图分类损失包括:(1)与文本分类器正确预测文本文档的标签的能力有关的分类损失分量,以及(2)与使用第一语言的文本文档的潜在表示获得的文本分类器的标签概率和使用翻译成第二语言的文本文档的潜在表示获得的分类标签概率的比较相关的视图共识分量;
17.对于至少一些文本文档,无论数据集来源如何:
18.确定用于训练编码器生成文本文档的潜在表示的对抗性编码器损失,文本文档的潜在表示增加语言鉴别器正确预测从其生成潜在表示的文本文档的语言的难度,语言鉴别器接收潜在表示并输出从其生成潜在表示的文本文档是第一语言还是第二语言的预测;以及
19.确定用于训练语言鉴别器正确预测从其生成潜在表示的文本文档的语言的语言鉴别器损失;
20.使用语言鉴别器损失来更新语言鉴别器的参数;以及
21.使用多视图分类损失、域内正则化和跨域正则化来更新编码器、解码器和文本分类器的参数。
22.在第二方面中,提供一种经训练的分类器系统,包括:
23.编码器,包括一个或多个神经网络层,接收以目标语言编写的文本文档并将文本文档转换为编码的表示;以及
24.文本分类器,包括一个或多个神经网络层,接收编码的表示并输出文本文档的类别标签;
25.其中,通过执行以下步骤,将经训练的分类器系统的编码器和文本分类器作为多视图编码器
‑
分类器系统的一部分进行训练:
26.使用编码器从训练文档生成文本文档的两个视图表示,第一视图表示包括文本文档的编码表示,使用以其原言的文本文档作为编码器的输入,第二视图表示包括文本文档的编码的回译表示,使用从其原语言翻译成另一种语言的文本文档作为编码器的输入;以及
27.使用损失来更新至少编码器和文本分类器,所述损失包括:
28.与使用第一视图表示和解码器重构文本文档的重构误差相关的域内正则化;
29.与使用第二视图表示和解码器重构文本文档的重构误差有关的跨域正则化;以及对于具有相关联的真相标签的文本文档,包括与文本分类器对这些文本文档的标签的预测有关的分类分量以及与减少文本分类器的第一视图表示的预测分布和文本分类器的第二视图表示的预测分布之间的差相关的共识分量的多视图分类损失。
30.在第三方面中,提供一种非暂时性计算机可读介质,包括一个或多个指令序列,当由至少一个处理器执行时,所述指令序列使得如第一方面所述的方法的步骤被执行。
guidance.in proceedings of the 2018conference on empirical methods in natural language processing(emnlp),pages 238
–
249,brussels,belgium.)
[0047]6‑
chen和qian(2019)(zhuang chen and tieyun qian.2019.transfer capsule network for aspect level sentiment classification.in proceedings of the 57th conference of the association for computational linguistics(acl),pages 547
–
556,florence,italy.)
[0048]7‑
devlin等(2019)(jacob devlin,ming
‑
wei chang,kenton lee,and kristina toutanova.2019.bert:pre
‑
training of deep bidirectional transformers for language understanding.in proceedings of the 2019conference of the north american chapter of the association for computational linguistics:human language technologies(naacl
‑
hlt),pages 4171
–
4186,minneapolis,mn.)
[0049]8‑
conneau和lample(2019)(alexis conneau and guillaume lample.2019.cross
‑
lingual language model pretraining.in advances in neural information processing systems(neurips),pages 7057
–
7067,vancouver,canada.)
[0050]
图9描绘了根据本公开的实施例的关于法语数据集1的训练期的验证和测试准确性,其中,曲线图905描绘了测试mvec实施例的结果,曲线图910描绘了xlm
‑
ft的结果。
[0051]
图10描绘了根据本公开的实施例的xlm
‑
ft的各个层的t
‑
分布随机邻居嵌入(t
‑
distributed stochastic neighbor embedding,t
‑
sne)可视化和用于英
‑
法的mvec实施例。圆圈和正方形分别表示来自英语的文档及其目标语言的相应译文。数字表示文档索引,并具有一对一的映射。 /
‑
表示标签,为简单起见,仅注释了英文文档。左上方(图1005):xlm
‑
ft的编码器输出。右上角(图1010):xlm
‑
ft的softmax函数之前的最后一层。左下方(图1015):本公开的实施例的编码器输出。右下方(图1020):本公开的实施例的softmax函数之前的最后一层。
[0052]
图11描绘了根据本公开的实施例的计算设备/信息处理系统的简化框图。
具体实施方式
[0053]
在以下描述中,出于解释的目的,阐述了具体细节以便提供对本公开的理解。然而,对于本领域的技术人员将显而易见的是,可以在没有这些细节的情况下实践本公开。此外,本领域的技术人员将认识到,下面描述的本公开的实施例可以以多种方式来实现,诸如过程、装置、系统、设备或有形计算机可读介质上的方法。
[0054]
在图中示出的组件或模块是本公开的示例性实施例的说明,并且意在避免使本公开模糊。还应该理解的是,在整个讨论中,组件可以被描述为单独的功能单元,其可以包括子单元,但是本领域技术人员将认识到,各种组件或其部分可以被划分为单独的组件或可以集成在一起,包括例如在单个系统或组件中。应当注意,本文讨论的功能或操作可以被实现为组件。组件可以以软件、硬件或其组合来实现。
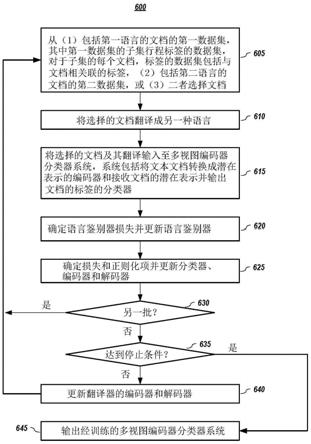
[0055]
此外,附图内的组件或系统之间的连接不旨在限于直接连接。而是,这些组件之间的数据可以被修正、重新格式化或通过中间组件更改。同样,可以使用附加的或更少的连接。还应注意,术语“耦接”、“连接”、“通信耦接”、“接合”、“接口”或其任何派生应理解为包括直接连接,通过一个或多个中间设备的间接连接以及无线连接。还应注意,任何通信,诸
如信号、响应、答复、确认、消息、查询等,可包括信息的一个或多个交换。
[0056]
在说明书中对“一个或多个实施例”、“优选实施例”、“一个实施例”、“实施例”等的引用是指结合所述实施例描述的特定特征、结构、特性或功能被包括在本公开的至少一个实施例中,并且可以在多于一个的实施例中。同样,上述短语在说明书中各个地方的出现不一定全部指代相同的一个或多个实施例。
[0057]
在说明书中的各个地方使用某些术语是为了说明,而不应解释为限制性的。服务、功能或资源不限于单个服务、功能或资源;这些术语的使用可能是指相关服务、功能或资源的分组,它们可以是分布式的或聚合的。术语“包括”、“具有”、“包含”和“含有”应被理解为开放术语,并且以下的任何列表都是示例,并不意味着限于所列出的项目。“层”可以包括一个或多个操作。词语“最佳”、“优化”、“最优化”等是指结果或过程的改进,不需要特定的结果或过程已达到“最佳”或峰值状态。存储器、数据库、信息库、数据存储、表、硬件、高速缓存等的使用在本文中可以用来指其中可以输入信息或以其他方式记录信息的一个或多个系统组件。
[0058]
在一个或多个实施例中,停止条件可以包括:(1)已经执行了设定数量的迭代;(2)已达到一定的处理时间;(3)收敛性(例如,连续迭代之间的差小于第一阈值);(4)发散(例如,性能下降);(5)已经达到可接受的结果;(6)所有数据已被处理。
[0059]
本领域技术人员将认识到:(1)可以可选地执行某些步骤;(2)步骤可以不限于本文列出的特定顺序;(3)某些步骤可以以不同的顺序执行;以及(4)某些步骤可以同时进行。
[0060]
本文使用的任何标题仅出于组织目的,并且不应被用来限制说明书或权利要求的范围。此专利文件中提到的每个参考文献/文件都通过引用整体并入本文。
[0061]
还应当注意,尽管本文描述的实施例可以在情感分类的上下文内,但是本公开的各方面不限于此。因此,本公开的各方面可以被应用于其他情况或适于在其他情况下使用。
[0062]
应当注意,本文提供的任何实验和结果均以举例说明的方式提供,并且是使用一个或多个特定实施例在特定条件下进行的;因此,这些实验及其结果均不用于限制当前专利文件的公开范围。
[0063]
1.概述
[0064]
最近的神经网络模型在英语以及其他语言的情感分类上取得了令人印象深刻的表现。它们的成功在很大程度上取决于大量标签的数据或平行语料库的可用性。在此专利文件中,提出了甚至可以处理跨语言情感分类的极端情形的实施例,其中,资源缺乏的语言没有任何标签或平行语料库。
[0065]
本文提出的是在无监督的设置下的分类模型的实施例(为了方便起见,其通常被称为多视图编码器
‑
分类器(mvec)),其中存在来自两种语言的单语语料库和源语言中的标签。与仅基于训练数据的分类误差来调整参数的先前的基于语言模型(lm)的微调方法不同,实施例利用来自无监督机器翻译(unsupervised machine translation,umt)的编码器
‑
解码器网络来正则化和完善共享的潜在空间。在一个或多个实施例中,由语言鉴别器正则化的基于transformer的编码器学习共享的但更精确的语言不变表示,这对于由解码器从两种语言重构句子以及从输入文件生成用于分类的多视图特征表示都是有效的。在一个或多个实施例中,构造了来自编码器的两个视图:(i)源语言中的编码的句子;(ii)目标语言中源句子的编码的翻译。
[0066]
在一个或多个实施例中,mvec实现可以通过预训练的lm来部分初始化,但进一步地被微调以更好地对齐来自两种语言的句子,准确地预测源语言中的标签的数据,并促进来自两种视图的预测之间的共识。可以以端到端的方式训练完整模型的实施例,以在每次迭代时更新用于编码器
‑
解码器、语言鉴别器和分类器的参数。一些贡献包括但不限于以下内容:
[0067]
提出了没有针对目标语言的任何标签或平行资源需求的无监督情感分类模型的实施例。通过设计多视图分类器并将其与预训练的lm和umt集成,可以在更精准的潜在空间上构建模型(mvec)实施例,与以前的零样本分类工作相比,对于语言转换具有鲁棒性,具有更好的模型释义。
[0068]
使用涉及十一(11)个情感分类任务的五(5)个语言对对实施例进行了广泛的评估。经过测试的全模型实施例在8/11任务中胜过了最新的无监督微调方法和使用跨语言资源的部分监督方法。因此,与未来半监督或监督方法预期产生的结果相比,结果提供了强大的下界性能。
[0069]
2.一些相关工作
[0070]
2.1.跨语言文本分类(cross
‑
lingual text classification,cltc)
[0071]
cltc旨在学习通用分类器,所述通用分类器可应用于具有有限的标签的数据的语言,这自然适用于情感分析。传统的监督方法利用跨语言工具,诸如机器翻译系统,并在源语言上训练分类器。最新的模型使用平行语料库来学习双语文档表示或进行跨语言模型蒸馏。
[0072]
在无监督设置的情况下,chen等人(2018)通过对抗训练学习了语言不变的潜在跨语言表示。ziser和reichart(2018)使用基于枢轴的学习和结构感知的深度神经网络(deep neural network,dnn)将知识迁移到资源缺乏的语言中。但是,在这两篇论文中,它们对bwe都有隐式依赖性,这需要双语词典来训练。chen和qian(2019)是第一个使用无监督bwe(lample等人(2018b))和多源语言进行对抗训练的完全无监督方法。
[0073]
相反,本文的一个或多个模型实施例是多视图分类模型,其使用对抗训练与预训练的lm(例如conneau和lample(2019))和诸如来自umt的编码器
‑
解码器(例如,guillaume lample,alexis conneau,ludovic denoyer,和marc’aurelio ranzato,“unsupervised machine translation using monolingual corpora only”,第六届国际学习表示大会(iclr)会议记录,加拿大温哥华(2018年)(以下简称lample等人(2018a))无缝集成。因此,更精细的潜在空间被学习,以更好地捕获文档级别的语义并生成表示输入的多个视图。
[0074]
2.2.无监督机器翻译
[0075]
umt不依赖任何平行语料库来执行翻译。在单词级别上,lample等人(2018b)声称通过以无监督的方式对齐单语单词嵌入,从而在两种语言之间建立双语词典。在句子和文档级别,lample等人(2018a)提出通过学习可以在域内和跨域设置下重构两种语言的自动编码器的umt模型。lample等人(2018c)(guillaume lample,myle ott,alexis conneau,ludovic denoyer和marc'aurelio ranzato,“phrase
‑
based&neural unsupervised machine translation”,2018年自然语言处理经验方法会议(emnlp)的会议记录中,第5039
‑
5049页,比利时布鲁塞尔(2018c))使用基于短语的方法扩展了lample等人(2018a)。由于实施例的目的是学习用于分类的更精细的语言不变表示,因此在一个或多个实施例
中,可以采用来自umt系统的编码器来生成输入的多个视图并实现知识转移。
[0076]
2.3.多视图迁移学习
[0077]
多视图迁移学习的任务是同时学习多个表示并将所学知识从源域转移到目标域,目标域具有较少的训练样本。通常,来自不同视图的数据包含补充信息,并且多视图学习利用了来自多个视图的一致性。
[0078]
fu等人(2015年)(yanwei fu,timothy m.hospedales,tao xiang和shaogang gong,“transductive multi
‑
view zero
‑
shot learning”,摘自ieee trans.pattern anal.mach.intell.,37(11):2332
–
2345(2015)),以及zhang等人(2019)(qingheng zhang,zequn sun,wei hu,muhao chen,lingbing guo和yuzhong qu,“multi
‑
view knowledge graph embedding for entity alignment”,第二十八届国际人工智能联合会议(ijcai)会议记录,第5429
‑
5435页,中国澳门(2019)都通过语义空间对齐来利用多个语义表示的互补性。与这些方法不同的是,本文的一个或多个实施例使用编码器
‑
解码器框架从源语言为输入生成多个视图并使他们的预测达成共识。此外,在一个或多个实施例中,可以引入语言鉴别器以支持编码器从输入生成语言不变表示。
[0079]
3.方法实施例
[0080]
在本节中,提出了模型实施例的一般工作流程,包括每个组件和训练方法实施例的细节。
[0081]
3.1.问题设定
[0082]
给定来自源语言和目标语言的单语文本数据{d
src
,d
tgt
},具有源语言中的标签的样本的子集,其中是类别标签的向量,任务旨在建立由θ参数化的通用分类模型f(x;θ)
→
y,所述模型可直接应用于目标语言中未标签的数据,其中x是来自任何语言的输入文档,y是其类别标签。注意,在一个或多个实施例中,可以假设两种语言共享相同的类类型。
[0083]
3.2.模型架构实施例
[0084]
在一个或多个实施例中,多视图编码器
‑
分类器(mvec)包括:编码器
‑
解码器和分类器。在一个或多个替代实施例中,mvec实施例还包括语言鉴别器。
[0085]
图2以图形方式描绘了根据本公开的实施例的跨语言方法。虚线表示预训练和初始化过程,实线表示潜在空间细化和微调过程。在一个或多个实施例中,编码器205和解码器210可以通过现有的预训练的语言模型来初始化,但是随后通过umt的自重构损失、语言鉴别器损失以及来自源语言的标签的训练数据的分类损失来进行微调。
[0086]
由于无监督机器翻译(umt)的成功和自动编码器的重构正则化,各实施例采用编码器
‑
解码器框架215,并引入一种语言内的自重构损失、跨语言的回译重构损失、以及来自分类器225的分类的正常损失。为简单起见,在此将自重构损失称为“域内损失”,并将回译重构损失称为“跨域损失”。
[0087]
尽管来自umt的编码器可以为输入文档生成潜在表示(其中“文档”可以包含一个或多个单词或句子),但是在源语言和目标语言之间仍然可能存在语义鸿沟。实施例可以用语言鉴别器220丰富编码器
‑
解码器框架215,可以产生微调的潜在表示以更好地对准来自两种语言的潜在表示。这样的表示对于训练对语言转换具有鲁棒性的语言不变分类器(例如,分类器225)是有用的。
[0088]
如图3中描绘的实施例所示,编码器用于将源文档和目标文档(一个或多个单词或句子的序列)编码到共享的潜在空间中,而解码器负责将文档从潜在空间解码为源语言或目标语言。在一个或多个实施例中,编码器
‑
解码器为两种语言(域)共享并且在域内和跨域训练。语言鉴别器旨在预测每个文档的语言来源,并且分类器被训练以将每个文档分类为预定义的类别标签。
[0089]
在一个或多个实施例中,在无监督的设置下,mvec实施例观察来自两种语言的未标签的单语语料库和源语言中的一些标签的文档。在一个或多个实施例中,未标签的单语数据通常从应用域(即,未标签的产品评论或社交媒体帖子)采样,其在目标域中采用预训练的lm和训练umt时都使用。如图3中所示,在一个或多个实施例中,未标签的源和目标数据通过编码器
‑
解码器和语言鉴别器,而标签的源数据通过系统中的所有组件,包括情感分类器。为了进行评估,目标语言中具有标签的文档。但是,在一个或多个实施例中,它们仅在测试期间使用。在以下小节中,将详细介绍mvec实施例的每个组件。
[0090]
根据本公开的实施例,线310指示源语言320内的消息流,线315指示目标语言325的消息流。根据本公开的实施例,线305指示从编码器330到文本分类器345的消息流。在一个或多个实施例中,编码器330和解码器335在两种语言之间共享相同的参数。
[0091]
3.3.编码器
‑
解码器实施例
[0092]
令表示来自特定语言l的n个单词的输入文档,其中l∈{src,tgt}。在一个或多个实施例中,编码器是由θ
enc
参数化的神经网络其通过使用的相应单词嵌入,产生n个隐藏状态的序列其中是共享潜在空间中的潜在(或隐藏)表示,θ
enc
是两种语言之间共享的编码器的参数。在一个或多个实施例中,编码器可以是双向长
‑
短期记忆网络(bidirectional long
‑
short term memory,bilstm)或transformer。在一个或多个实施例中,使用transformer,其在最近的文本表示学习任务中已经取得了巨大的成功。在一个或多个实施例中,编码器可执行嵌入,在所述嵌入中,编码器接收输入文本,创建相应的单词嵌入,并产生潜在或隐藏的表示。
[0093]
给定潜在表示(或编码的表示)z
(l)
作为输入,解码器生成输出序列生成输出序列在一个或多个实施例中,可以使用由θ
dec
参数化的基于transformer的解码器,诸如由conneau和lample(2019)提出的,但是也可以采用其他解码器。为了简单起见,编码器和解码器在本文中分别由e(x
(l)
)和d(z
(l)
)表示,而不是由和表示。
[0094]
如果没有强加的约束,则编码器/解码器更有可能仅将每个输入字一一存储。为了提高编码器
‑
解码器的鲁棒性,实施例采用了降噪自动编码器(denoising autoencoder,dae)(pascal vincent,hugo larochelle,yoshua bengio和pierre
‑
antoine manzagol,“extracting and composing robust features with denoising autoencoders”,第二十五届国际机器学习会议(icml)会议记录,第1096
‑
1103页,芬兰赫尔辛基(2008)(以下称
vincent等人(2008)),可从损坏的版本中恢复输入。
[0095]
至少有三种方法可以将噪声注入到输入文档中,包括洗牌、丢弃和用特殊词替换。在一个或多个实施例中,每个单词分别以概率p
d
和p
b
被丢弃和替换,并且通过在输入文档上实施随机置换σ来略微洗牌输入文档,其中p
d
和p
b
可以被看作是用于控制噪声级别的超参数。在一个或多个实施例中,置换σ满足条件|σ(i)
‑
i|≤k,其中n是输入文档的长度,k是另一个超参数。
[0096]
在一个或多个实施例中,将噪声模型应用于用于训练编码器
‑
解码器和鉴别器的未标签的数据,同时将标签的数据保持其原始性以用于所有组件训练。在一个或多个实施例中,g(.)用于表示随机噪声模型,其采用输入文档x
(l)
并生成g(x
(l)
)作为x
(l)
的随机采样噪声版本。
[0097]
为了将编码器
‑
解码器合并为正则化组件,实施例考虑了域内和跨域目标函数。第一目标函数(域内)旨在在语言内从其本身的噪声版本重构文档,而第二目标函数(跨域)以教导模型跨语言翻译输入文档为目标。
[0098]
3.3.1.域内正则化实施例
[0099]
具体地,给定语言l∈{src,tgt},域内目标函数的实施例可以写为:
[0100][0101]
其中θ
ed
=[θ
enc
,θ
dec
],是对从单语数据集d
l
采样的x的损坏版本的重构,δ是标记级别(token
‑
level)交叉熵损失的总和以度量两个序列之间的差异。
[0102]
图4描绘了根据本公开的实施例的用于确定与域内重构有关的正则化的方法。在一个或多个实施例中,编码器(例如,图3中的编码器330)可以是由在两种语言之间共享的一组编码器参数来参数化的神经网络,其接收输入文本文档的版本并产生(405)共享的潜在空间中的一系列隐藏(或潜在)状态。文档的版本可以是原始文档,其以其原语言(源语言320或目标语言325)包括一个或多个单词,或者可以是以其原语言并带有附加的噪声的原始文档。应当注意,在一个或多个实施例中,可以首先将输入文本文档的单词转换为单词嵌入;可替代地,在将嵌入编码到潜在空间之前,编码器还可以将单词转换成嵌入。
[0103]
给定编码的文档(即,由编码器输出的隐藏或潜在状态的序列),使用(410)可以是由在两种语言之间共享的一组解码器参数进行参数化的神经网络的解码器(例如,图3中的解码器335)来重构文本文档,给定隐藏状态的序列作为解码器的输入。
[0104]
给定原语言中的输入文档和相同语言的重构文档,则可以计算(415)域内正则化。如上所述,域内正则化与使用编码器和解码器将文本文档重构为其原语言的重构误差有关,并且可以如上面关于等式(1)所讨论的那样进行计算。
[0105]
3.3.2.跨域正则化实施例
[0106]
类似于教导编码器
‑
解码器框架以在一种语言中重构输入文本文档,实施例考虑教导编码器
‑
解码器从另一种语言中的x的译文重构一种语言中的x,从而导致跨域目标函数。跨域目标函数的实施例可以写为:
[0107][0108]
其中(l1,l2)∈{(src,tgt),(tgt,src)},t(.)是应用于输入文档x的从语言l1到语
言l2的当前umt模型。
[0109]
图5描绘了根据本公开的实施例的用于确定与跨域重构有关的正则化的方法。在一个或多个实施例中,可以将来自单语数据集(例如,源语言数据集320和目标语言数据集325)的一个或多个文本文档翻译成另一种语言。在一个或多个实施例中,可以使用umt来翻译各种文档,但是也可以采用其他翻译装置。使用umt,特别是与mvec的编码器和解码器共享参数的umt,的好处是,它可以作为mvec训练的一部分进行更新。给定包括一个或多个单词的已经被翻译成另一种语言的文本文档,使用(505)编码器(例如,图3中的编码器330)来生成文本文档的翻译的版本的编码的表示。可以将编码的文档(即,由编码器输出的隐藏或潜在状态的序列)输入到解码器(例如,图3中的解码器335),解码器将文本文档重构(510)回到其原语言。
[0110]
给定翻译前其原语言的输入文档和具有相同语言的重构文档(即,回译),则可以计算(515)跨域正则化。如上所述,跨域正则化与使用编码器和解码器将文本文档重构为其原语言的重构误差有关,并且可以如以上关于等式(2)所讨论的那样进行计算。
[0111]
3.4.语言鉴别器实施例
[0112]
当编码器产生的跨语言分类器的输入是语言不变的时,跨语言分类器可以很好地工作。因此,编码器的实施例将来自两种语言的输入文档映射到独立于语言的共享的特征空间中。在一个或多个实施例中,为了实现此目标,将语言鉴别器(例如,图3中的语言鉴别器340)引入到模型300的实施例中。语言鉴别器可以是具有两个隐藏层和一个softmax层以从编码器的输出中识别语言来源的前馈神经网络。在一个或多个实施例中,以下交叉熵损失函数被最小化:
[0113][0114]
其中,θ
d
表示鉴别器的参数,(l,x
(l)
)对应于从单语数据集(例如,图3中的源语言数据集320和目标语言数据集325)一致采样的语言和文档对,p
d
(.)是softmax层的输出。
[0115]
同样,在一个或多个实施例中,编码器被训练为“欺骗”鉴别器:
[0116][0117]
如果l
i
=l2,则为l
j
=l1,反之亦然。
[0118]
3.5.多视图分类器实施例
[0119]
上面描述了实施例如何获得语言不变的潜在空间来编码两种语言。但是,如果仅针对源语言在编码器的输出上训练分类器,则这些方法可能不足以在各种语言之间很好地泛化。现有方法,诸如chen等人(2018),和本文的实施例之间的一个关键区别是,本文的一个或多个实施例使用umt,其可以从源语言为输入的标签的文档生成多个视图。因此,相比于单视图学习,实施例可受益于多视图学习的优良的泛化能力。
[0120]
在一个或多个实施例中,编码器可用于从训练文档生成用于文本文档的两个视图表示:第一视图表示包括文本文档的编码的表示,使用其原语言的文本文档作为编码器输入,以及第二视图表示包括文本文档的编码的回译表示,使用从原语言翻译成另一种语言的文本文档作为编码器的输入。特别地,就分类器而言,输入的两个视图可以被考虑:(i)来自源语言的编码的标签文档;以及(ii)来自目标语言的源文档的编码的回译。
[0121]
在一个或多个实施例中,学习目标是训练分类器以使预测的文档标签与来自源语言的真相匹配,并支持两个视图上的两个预测分布尽可能相似。在一个或多个实施例中,可以使用以下目标函数:
[0122][0123]
其中d
kl
(.||.)是kl散度,用于测量两个分布之间的差,y是输入文档x的类别标签,θ
c
是分类器的参数,表示分类器的输出概率。在对文本分类的先前的研究之后,实施例可以使用来自transformer编码器的最后隐藏层中的第一标记(token)的表示作为文档表示向量。在一个或多个实施例中,分类器是具有两个隐藏层和一个softmax层的前馈神经网络。
[0124]
在一个或多个实施例中,在学习过程的一次迭代中的最终目标函数是最小化以下损失函数:
[0125][0126]
其中λ
wd
,λ
cd
,λ
adv
分别是在域内损失、跨域损失和对抗性损失之间进行权衡的超参数。
[0127]
3.6.训练方法实施例
[0128]
方法1(下文)提供了实施例方法的详细过程。该过程的输入包括源语言的文档的数据集(d
src
),以及目标语言的文档的数据集(d
tgt
),数据集(d
src
)的子集形成标签的数据集对于子集的每个文本文档,标签的数据集包括与文本文档相关联的标签。
[0129]
模型实施例可以使用初始翻译机t
(0)
,其提供从一种语言到另一种语言的翻译,所述翻译用于生成用于计算等式(2)中的跨域损失和等式(5)中的分类器损失的文本文档的第二视图。为了加速训练,可以通过在单语文本上预训练基于transformer的umt来初始化t
(0)
,基于transformer的umt具有与模型实施例相同的编码器
‑
解码器架构。在预训练之后,可以使用预训练的编码器
‑
解码器网络来初始化模型实施例,并开始训练分类器和鉴别器。同时,在一个或多个实施例中,编码器和解码器关于单语数据集和来自源语言的标签数据被改进。
[0130]
在一个或多个实施例中,在每个训练步骤期间,从更新等式(3)中的θ
d
到更新等式(6)中的θ
ed
和θ
c
,迭代优化。请注意,如果从单语数据中提取的一批文档都未标签,则更新分类器参数被暂停,并且仅语言鉴别器和编码器
‑
解码器的参数被更新。
[0131]
在一个或多个实施例中,更新θ
ed
和θ
c
可发生在每个批次的末尾,并且多视图编码器
‑
分类器训练系统的更新的编码器和解码器可用于更新umt的编码器和解码器,这可以在每个时期的末尾出现,但是它也可以更频繁地发生。
[0132]
此方法可以继续直到达到停止条件,诸如已经达到最大时期数(如下面的方法1的实施例中所示),但是可以额外地或替代地使用其他停止条件。
[0133]
方法1:mvec训练实施例
[0134]
训练数据集:d
src
(源语言的文档的数据集);
[0135]
输入:d
tgt
(目标语言的文档的数据集);和(与源语言中的一组文档相对应的源语言中的标签)
[0136]
输出:经训练的分类器(θ
c
)和经训练的编码器(θ
enc
)
[0137]
1.t
(0)
←
预训练无监督机器翻译器(例如,基于transformer的umt)
[0138]
2.对于t=0,
…
,进行max_epoch
[0139]
3.使用t
(t)
批量翻译文档;
[0140]
4.θ
d
←
argmin等式(3)中的l
d
,同时固定θ
c
和θ
ed
;
[0141]
5.θ
c
和θ
ed
←
argmin等式(6)中的l
all
,同时固定θ
d
;
[0142]
6.更新t
(t 1)
←
{e
(t)
,d
(t)
};
[0143]
7.返回θ
c
和θ
enc
[0144]
8.结束程序
[0145]
图6描绘了根据本公开的实施例的用于训练多视图编码器
‑
分类器系统的替代方法。在一个或多个实施例中,从以下中选择(605)文本文档:(1)包括第一语言的文本文档的第一数据集,其中,第一数据集的子集形成标签的数据集,对于子集的每个文本文档,标签的数据集包括与文本文档相关联的标签;(2)第二数据集,包括第二语言的文本文档;或(3)两者兼有。将所选择的文档从其原语言翻译(610)成另一种语言(例如,将第一语言文档翻译成第二语言,将第二语言文档翻译成第一语言)。
[0146]
所选择的文档及其翻译被输入(615)到多视图编码器
‑
分类器系统中,该系统包括将文本文档转换为潜在表示的编码器,以及接收文档的潜在表示作为输入并输出用于文档的标签的分类器。
[0147]
在一个或多个实施例中,在每批期间,确定语言鉴别器丢失并且更新(620)语言鉴别器。而且,确定损失和正则化项以更新(625)分类器、编码器和解码器。如前所述,可以使用等式(3)来更新语言鉴别器的参数,并且可以使用等式(6)来更新分类器、编码器和解码器的参数。
[0148]
例如,在一个或多个实施例中,对于以其原语言输入的文档,确定与使用编码器和解码器将文本文档重构为其原语言时的重构误差有关的域内正则化,其中解码器将来自编码器的潜在表示解码到文本文档的重构中。对于翻译成另一种语言并输入到系统中的文本文档,确定与使用文本文档的翻译版本作为编码器的输入将文本文档重构为其原语言的重构误差相关的跨域正则化。对于来自标签的数据集的文本文档,确定多视图分类损失,多视图分类损失包括:(1)与文本分类器正确预测文本文档的标签的能力有关的分类损失分量;以及(2)与使用第一语言的文本文档的潜在表示获得的文本分类器的标签概率和使用翻译成第二语言的文本文档的潜在表示获得的分类标签概率的比较相关的视图共识分量。
[0149]
同样,对于至少某些文本文档,无论数据集来源如何,确定用于训练编码器以生成文本文档的潜在表示的对抗性编码器损失,这增加语言鉴别器正确预测从其生成潜在表示的文本文档的语言的难度。语言鉴别器接收潜在表示并输出从其生成潜在表示的文本文档是第一语言还是第二语言的预测。并且,确定语言鉴别器损失用于训练语言鉴别器以正确预测从其生成潜在表示的文本文档的语言。
[0150]
给定损失和正则化,使用语言鉴别器损失来更新语言鉴别器的参数,并使用多视
图分类损失、域内正则化和跨域正则化来更新编码器、解码器和分类器的参数。
[0151]
在一个或多个实施例中,如果要处理(630)另一批文档,方法返回到步骤605;否则,过程可以检查(635)是否已经达到停止条件。如果还没有达到停止条件,则过程可以更新(640)翻译器的编码器和解码器(如果使用了一个),并且返回到步骤605(例如,执行另一个时期)。然而,如果已经达到停止条件,则输出(645)包括经训练的编码器和经训练的分类器的经训练的mvec。
[0152]
3.7.经训练的mvec系统和方法
[0153]
在一个或多个实施例中,经训练的多视图编码器
‑
分类器系统包括编码器和分类器。可以包括一个或多个神经网络层的编码器接收以目标语言编写的文本文档,并将文本文档转换为编码的表示。可以包括一个或多个神经网络层的分类器接收编码的表示并输出文本文档的类别标签。
[0154]
在一个或多个实施例中,通过执行以下步骤来将编码器和分类器作为多视图编码器
‑
分类器训练系统的一部分进行训练:使用编码器从训练文档生成文本文档的两个视图表示,第一视图表示包括文本文档的编码表示,使用以其原语言的文本文档作为编码器的输入,第二视图表示包括文本文档的编码的回译表示,使用从其原语言被翻译成另一种语言的文本文档作为编码器的输入。
[0155]
给定不同的编码的视图,使用损失来更新至少编码器和文本分类器。在一个或多个实施例中,损失包括:与使用第一视图表示和解码器重构文本文档的重构误差相关的域内正则化,以及与使用第二视图表示和解码器重构文本文档的重构误差有关的跨域正则化。在一个或多个实施例中,对于具有相关联的真相标签的文本文档,损失还包括多视图分类损失,所述多视图分类损失包括与文本分类器对那些文本文档的标签的预测有关的分类分量以及与减少文本分类器的第一视图表示的预测分布和文本分类器的第二视图表示的预测分布之间的差相关的共识分量。在一个或多个实施例中,共识分量涉及使用kl散度来测量文本分类器的第一视图表示的预测分布与文本分类器的第二视图表示的预测分布之间的差。
[0156]
在一个或多个实施例中,多视图编码器
‑
分类器训练系统还包括接收文本文档的编码的表示并预测文本文件的语言的语言鉴别器,并且训练多视图编码器
‑
分类器系统的编码器和文本分类器进一步包括在与编码器的对抗训练中使用语言鉴别器,以支持编码器生成对文本文档的语言不变的编码的表示。
[0157]
在一个或多个实施例中,包括编码器和解码器的无监督机器翻译器用于将文本文档从源语言翻译成目标语言,并且从目标语言翻译成源语言。而且,无监督机器翻译器的编码器和解码器可以与多视图编码器
‑
分类器系统的编码器和解码器共享参数,并且无监督机器翻译器的编码器和解码器可以使用多视图编码器
‑
分类器训练系统的编码器和解码器的更新的参数来更新。
[0158]
图7描绘了根据本公开的实施例的用于使用经训练的多视图编码器
‑
分类器系统的示例方法。给定包括经训练的编码器和经训练的分类器的经训练的多视图编码器
‑
分类器(mvec)系统,接收(705)语言的文本文档到系统中。mvec采用输入并将分类标签分配(710)给输入文本。应该注意的是,尽管缺少文本文档的输入语言的训练数据,mvec仍可以分配标签。最后,系统输出分配的标签。在情感分析的情况下,输入文本可以是用户评论,并
且标签可以是排名(例如,差,中,好,很好等)。
[0159]
4.实验结果
[0160]
使用涉及11个任务的五个语言对对跨语言的多类和二元情感分类进行了实验。更具体地说,英语始终是源语言,目标语言分别是法语、德语、日语、汉语和阿拉伯语。
[0161]
应当注意,这些实验和结果是通过说明性的方式提供的,并且是在特定条件下使用一个或多个特定实施例执行的;因此,这些实验及其结果均不应用于限制当前专利文件的公开范围。
[0162]
4.1.数据集
[0163]
数据集1(法语,德语,日语)。这是四种语言的多语言情感分类数据集,包括英语(en),法语(fr),德语(de)和日语(ja),涵盖三种产品。对于每种语言的每种产品,每个训练和测试集中有2000个文档。每个文档包含标题、类别名称、评论和5分制星级。通过在3点处阈值化,将多类别评级转换为二元评级。对于每种产品,由于未使用英语的测试集,因此英语训练和测试集被结合,并随机抽取20%(800)文档作为验证集来调整超参数,其余3200个测试样本用于训练。对于每种目标语言,使用原始的2000个测试样本与先前的方法进行比较。与chen等人(2018)和chen和qian(2019)提出的使用目标语言的标签数据用于模型选择不同,目标语言的评论的标签仅用于测试。分别有针对英语、法语、德语和日语的105k、58k、317k、300k未标签的评论,这些评论可用作单语数据来训练测试的mvec模型实施例的编码器
‑
解码器。
[0164]
数据集2(汉语)。此数据集包括两个组或来源:(i)a组:700k条英语评论,分为五个等级,以及(ii)b组:170k条中文评论,分为并注释为五个等级。第一组评论的全部被分为650k条评论的训练集和50k条评论的验证集。650k评论内容也可用作英语的单语训练数据。对于中文评论数据,将150k条评论被采样作为单语训练集。其余的20k条评论被视为测试集。
[0165]
数据集3(阿拉伯语)。使用阿拉伯语情感数据集,所述数据集包含超过1100个带有三个标签(负,中,正)的文档。数据集被分为一半作为训练,另一半作为测试。由于不需要使用目标语言的验证数据来调整模型,因此随机采样了1000个文档作为测试数据。对于英语资源,使用数据集2的a组的评论,并按照与中国案例相同的划分,但将5级评论转换为3级(即1&2
→“
负”,3
→“
中”,4&5
→“
正”)。此外,从联合国阿拉伯语料库子集中随机采样161k个句子作为用于模型训练的未标签的单语数据。
[0166]
4.2.实验设置
[0167]
对于法语、德语和日语,执行二元分类。对于中文和阿拉伯语,执行多类分类。
[0168]
数据预处理。使用moses(philipp koehn,hieu hoang,alexandra birch,chris callison
‑
burch等人,2007年,moses:open
‑
source toolkit for statistical machine translation,第45届计算语言学协会(acl)年会的会议记录,捷克共和国,布拉格)对每种语言的单语数据进行提取和标记化。然后,将神经机器翻译用于具有子单词单元的稀有单词,分三个步骤命名为fastbpe(rico sennrich,barry haddow和alexandra birch,2016,neural machine translation of rare words with subword units,第54届计算语言学协会(acl)年会的会议记录,德国,柏林)。具体地,从预训练的xlm
‑
100模型中收集bpe代码,然后将bpe代码应用于所有标记化数据,并用于提取训练词汇。为了限制测试的模型实施例
的大小,保留了训练集中前60k个最频繁的子单词单元。最后,将单语数据和标签的数据二值化,以进行模型训练、验证和测试。
[0169]
预训练细节。如前所述,测试的模型实施例使用初始翻译机器来计算重构损失和分类器损失。诸如(lample等人,2018a)中所述,利用预训练的语言模型来初始化基于transformer的umt,并关于文本对其进行训练。特别地,从每种语言对中采样1000万个句子,并使用xlm库训练umt 20万步。所得的编码器
‑
解码器用于初始化测试模型实施例。
[0170]
关于单词嵌入初始化,使用从预训练的语言模型的第一层获得的嵌入,与muse相比,它在许多评估指标上都表现出更好的跨语言性能。
[0171]
训练细节。在实验中,编码器和解码器都是具有8头自注意力的6层transformer。子单词嵌入和隐藏状态维度均设置为1024,并使用贪婪解码生成标记序列。使用adam优化器对编码器
‑
解码器和分类器进行训练,学习速率为10
‑5,最小批量大小为32。分类器和鉴别器的隐藏维度均设置为128。对于去噪自动编码器的参数,p
d
=0.1,p
b
=0.2和k=3。最后,对{0.5,1,2,4,8}上的超参数执行网格搜索,并将λ
wd
和λ
cd
设置为1以及λ
avd
设置为4。为防止梯度爆炸,将梯度l2范数限制为5.0。所述方法在paddlepaddle中实现,所有实验均在nvidia tesla m40(24gb)gpu上进行。
[0172]
竞争方法。将测试的实施例与几个最近发表的结果进行比较。由于篇幅所限,引入几种具有代表性的基准:lr mt通过机器翻译将词袋从目标语言翻译为源语言,然后构建逻辑回归模型。bwe基准依赖于双语单词嵌入(bwe),其中1对1表示它只是从英语转移而来,而3对1则表示来自所有其他三种语言的训练数据。cldfa(ruochen xu和yiming yang.,2017,cross
‑
lingual distillation for text classification,计算语言学协会(acl)第55届年会会议记录,第1415
–
1425页,加拿大温哥华)(以下简称xu和yang(2017))利用对抗性特征自适应技术建立在平行语料库的模型精炼上。pblm(yftah ziser和roireichart,2018年,deep pivot
‑
based modeling for cross
‑
language cross
‑
domain transfer with minimal guidance,2018年自然语言处理经验方法会议(emnlp)的会议记录,第238
‑
249页,布鲁塞尔,比利时)(以下称为ziser和reichart(2018))使用双语词嵌入和基于枢轴的语言建模进行跨域和跨语言分类。mbert(devlin等人,2019)和xlm
‑
ft(conneau和lample(2019))直接基于预训练的lm多语言bert和xlm对单层分类器进行微调。
[0173]
4.3.实验结果
[0174]
在表1(参见图8)和表2(以下)中,基于已发布的结果或从其代码重现的结果,将测试的实施例与其他进行比较。测试的实施例结果是基于5轮实验的平均值,标准偏差在1%
‑
1.5%左右。
[0175]
表1的第一个观察结果是,测试模型实施例以及经微调的多语言lm mbert(devlin等人(2019))和xlm
‑
ft(conneau和lample(2019))的性能大幅度超过所有先前方法,包括用于8/9任务的跨语言资源的方法,这表明零样本设置中预训练的lm带来巨大的好处。与mbert和xlm
‑
ft相比,当目标语言与源语言更相似时,例如德语和法语,以及一项日语任务,测试模型实施例获得更好的性能。
[0176]
表2:5类和3类分类任务在测试集上的预测准确性
[0177][0178]
针对多类设置中的中文和阿拉伯语,表2示出了测试方法实施例与其他一些发表的结果之间的比较,包括adan(xilun chen,yu sun,ben athiwaratkun,claire cardie和kilian q.weinberger,2018,adversarial deep averaging networks for cross
‑
lingual sentiment classification,trans.assoc.comput.linguistics,6:557
–
570)(以下称chen等人(2018))和msda(minmin chen,zhixiang eddie xu,kilian q.weinberger和fei sha,2012,marginalized denoising autoencoders for domain adaptation,第29届国际机器学习会议(icml)会议记录,英国爱丁堡,(以下称chen等人,2012))。类似地,模型实施例在汉语中获得稍微好一些的准确性。总体而言,在预训练的lm和umt的基础上,完整的模型实施例在8/11情感分类任务上实现最先进的性能,尤其是当目标语言与源语言更相似时。
[0179]
此外,示出了基于编码器
‑
解码器的正则化在减少共享潜在空间中的语言转变方面的有效性。直观地,如果微调的潜在空间对语言转变不太敏感,则在训练过程中,验证集和测试集的性能应高度相关。在图9中,报告了关于对法语的数据集1的书评论数据运行超过5次训练时期的验证和测试集的平均准确性。
[0180]
从图9可以看出,尽管在英语中,模型实施例的最佳验证准确度低于xlm
‑
ft,但跨英语和法语,模型实施例具有比xlm
‑
ft更多相关的准确性曲线。例如,xlm
‑
ft的验证准确性在时期10后开始下降,而测试准确性仍在提高。这样的观察表明,仅从自我监督的目标(例如,掩码语言建模)学习的潜在表示可能无法良好地捕获语言之间的语义相似性。因此,结果分类器在源语言中可能很好地工作,但可能无法推广到目标语言。相反,模型实施例牺牲了源语言中的一些准确性,但是可以在跨语言设置中为目标语言选择更好的模型。
[0181]
4.4.消融研究
[0182]
为了理解模型实施例中不同分量对整体性能的影响,进行了消融研究,如表3中所示。显然,通过域内目标或跨域目标训练的编码器/解码器很重要。对于三种语言(德语,法语,日语)的数据集1数据,没有跨域损失的模型获得83.22%、82.40%和72.05%的预测准确性,与完整模型实施例相比下降了5%
‑
7%。当删除对抗性训练分量时,性能也大大降低,因为两种语言之间,潜在文档表示的分布不相似。两视图共识分量也对性能有重大影响,英
‑
日的性能下降5个点。如本文所断言的,这样的结果验证了跨语言模型受益于对输入的多个视图的训练。
[0183]
表3:对五种语言对的消融研究
[0184][0185]
4.5.案例分析
[0186]
为了进一步探索实施例的有效性,针对10个随机抽样的英语数据集1评论及其使用机器翻译为法语的译文,可视化了编码器的输出和softmax之前的最后一层。
[0187]
如在图10的左下面板(1015)中看到的,对于方法实施例,具有相同索引的大多数圆形和正方形非常接近,但是对于左上角的xlm
‑
ft而言相距甚远(1005)。这样的观察表明,结合了umt和语言鉴别器的测试的编码器将输入充分映射到共享的语言不变的潜在空间中,同时保留语义相似性。对于softmax之前的最后一层,即使xlm
‑
ft也生成合理的表示来分离正评论和负评论,但数据点是随机分散的。相反,图10的右下面板(1020)中的模型实施例的输出示出了两个更明显的簇,带有易于分离的相应的标签。左侧的一簇包含所有正的文档,而负的示例仅出现在右侧。
[0188]
5.一些结论
[0189]
本文提出的是一种跨语言的多视图编码器
‑
分类器(mvec)的实施例,其既不需要目标语言中的标签的数据,也不需要具有源语言的跨语言资源。在一个或多个实施例中,基于预训练的语言模型,实施例利用编码器
‑
解码器组件和来自无监督机器翻译系统的语言鉴别器来学习语言不变特征空间。本文介绍的方法与仅使用共享的语言不变特征或依赖于平行资源的先前模型有所不同。通过构造微调的潜在特征空间和来自umt的编码器
‑
解码器的输入的两个视图,对于8/11零样本情感分类任务,实施例显著优于先前的方法。
[0190]
6.计算系统实施例
[0191]
在一个或多个实施例中,本专利文件的各方面可以针对,可以包括,或者可以实施于一个或多个信息处理系统(或计算系统)。信息处理系统/计算系统可以包括可操作用于计算、估算、确定、分类、处理、发送、接收、检索、发起、路由、切换、存储、显示、通信、证明、检测、记录、再现、处理或利用任何形式的信息、情报或数据的任何工具或工具的集合。例如,计算系统可以是或可以包括个人计算机(例如,笔记本电脑)、平板计算机、移动设备(例如,个人数字助理(pda)、智能电话、平板手机、平板电脑等)、智能手表、服务器(例如,刀片服务器或机架服务器)、网络存储设备、相机或任何其他合适的设备,它们的大小、形状、性能、功能和价格可以不同。计算系统可以包括随机存取存储器(ram)、一个或多个处理资源,诸如中央处理单元(cpu)或硬件或软件控制逻辑、只读存储器(rom)和/或其他类型的存储器。计
算系统的附加组件可以包括一个或多个磁盘驱动器,用于与外部设备以及各种输入和输出(i/o)设备,诸如键盘、鼠标、手写笔、触摸屏和/或视频显示器通信的一个或多个网络端口。计算系统还可包括可操作以在各种硬件组件之间传输通信的一条或多条总线。
[0192]
图11描绘了根据本公开的实施例的信息处理系统(或计算系统)的简化框图。将理解的是,针对系统1100示出的功能可以操作以支持计算系统的各种实施例
‑
尽管应当理解,计算系统可以被不同地配置并且包括不同的组件,包括具有比图11中所描绘的更少或更多的组件。
[0193]
如图11中所示,计算系统1100包括一个或多个中央处理单元(cpu)1101,其提供计算资源并控制计算机。cpu 1101可以用微处理器等来实现,并且还可以包括一个或多个图形处理单元(gpu)1102和/或用于数学计算的浮点协处理器。在一个或多个实施例中,一个或多个gpu 1102可以被结合在显示控制器1109内,诸如一个或多个图形卡的一部分。系统1100还可包括系统存储器1119,其可包括ram、rom或两者。
[0194]
如图11中所示,还可以提供多个控制器和外围设备。输入控制器1103代表到诸如键盘、鼠标、触摸屏和/或手写笔的各种输入设备1104的接口。计算系统1100还可包括用于与一个或多个存储设备1108接口的存储控制器1107,每个存储设备1108包括诸如磁带或磁盘之类的存储介质,或可用于记录用于操作系统、实用程序和应用的指令的程序(可以包括实现本公开的各个方面的程序的实施例)的光学介质。根据本公开,存储设备1108也可以用于存储处理后的数据或待处理的数据。系统1100还可以包括显示控制器1109,用于提供到显示设备1111的接口,显示设备1111可以是阴极射线管(crt)显示器、薄膜晶体管(tft)显示器、有机发光二极管、电致发光面板、等离子面板或任何其他类型的显示器。计算系统1100还可以包括用于一个或多个外围设备1106的一个或多个外围设备控制器或接口1105。外围设备的示例可以包括一个或多个打印机、扫描仪、输入设备、输出设备、传感器等。通信控制器1114可以与一个或多个通信设备1115对接,这使得系统1100能够通过包括因特网、云资源(例如,以太网云、以太网上的光纤通道(fcoe)/数据中心桥接(dcb)云等)、局域网(lan)、广域网(wan)、存储区域网络(san)的各种网络中的任何一个或通过包括红外信号的任何合适的电磁载波信号来连接到远程设备。如所描绘的实施例中所示,计算系统1100包括一个或多个风扇或风扇托盘1118以及监视系统1100(或其组件)的热温度并操作风扇/风扇托盘1118以帮助调节温度的一个或多个冷却子系统控制器1117。
[0195]
在所示的系统中,所有主要系统组件可以连接到总线1116,总线1116可以代表一个以上的物理总线。但是,各种系统组件可以或可以不在物理上彼此接近。例如,输入数据和/或输出数据可以从一个物理位置远程传输到另一物理位置。另外,可以通过网络从远程位置(例如,服务器)访问实现本公开的各个方面的程序。可以通过各种机器可读介质中的任何一种来传递这样的数据和/或程序,机器可读介质包括例如:诸如硬盘、软盘和磁带的磁性介质;诸如cd
‑
rom和全息设备的光学介质;磁光介质;以及专门配置用于存储或存储并执行程序代码的硬件设备,诸如专用集成电路(asic)、可编程逻辑器件(pld)、闪存设备、其他非易失性存储器(nvm)设备(诸如基于3d xpoint的设备)以及rom和ram设备。
[0196]
本公开的各方面可以利用用于一个或多个处理器或处理单元的指令被编码在一个或多个非暂时性计算机可读介质上,以使步骤被执行。应当注意,一种或多种非暂时性计算机可读介质应包括易失性和/或非易失性存储器。应当注意的是,替代实施方式是可能
的,包括硬件实施方式或软件/硬件实施方式。可以使用asic、可编程阵列、数字信号处理电路等来实现硬件实现的功能。因此,任何权利要求中的“装置”术语旨在涵盖软件和硬件实施方式。类似地,本文所使用的术语“计算机可读介质或媒介”包括其上包含指令的程序的软件和/或硬件,或其组合。考虑到这些实施方式替代方案,应当理解,附图和随附的描述提供了本领域技术人员编写程序代码(即,软件)和/或制造电路(即,硬件)以执行所需的处理所需的功能信息。
[0197]
应当注意,本公开的实施例可以进一步涉及具有非暂时性有形计算机可读介质的计算机产品,其上具有用于执行各种计算机实现的操作的计算机代码。媒介和计算机代码可以是出于本公开的目的而专门设计和构造的那些,或者它们可以是相关领域技术人员已知或可获得的那种。有形计算机可读介质的示例包括,例如:诸如硬盘、软盘和磁带的磁性介质;诸如cd
‑
rom和全息设备的光学介质;磁光介质;以及专门配置用于存储或存储并执行程序代码的硬件设备,诸如专用集成电路(asic)、可编程逻辑设备(pld)、闪存设备、其他非易失性存储器(nvm)设备(诸如基于3d xpoint的设备)以及rom和ram设备。计算机代码的示例包括机器代码,诸如由编译器生成的机器代码以及包含由计算机使用解释器执行的更高级别代码的文件。本公开的实施例可以全部或部分地实现为机器可执行指令,机器可执行指令可以在由处理设备执行的程序模块中。程序模块的示例包括库、程序、例程、对象、组件和数据结构。在分布式计算环境中,程序模块可以物理上位于本地、远程或二者兼有的设置中。
[0198]
本领域技术人员将认识到,没有计算系统或编程语言对于本公开的实践是至关重要的。本领域的技术人员还将认识到,上述许多元件可以在物理上和/或功能上分离为模块和/或子模块或组合在一起。
[0199]
本领域技术人员将理解,前述示例和实施例是示例性的,并且不限制本公开的范围。意图是,对本领域技术人员而言,在阅读说明书和研究附图之后显而易见的所有排列、增强、等同、组合和改进都包括在本公开的真实精神和范围内。还应当注意,任何权利要求的元素可以不同地布置,包括具有多个依赖性、配置和组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。