技术特征:
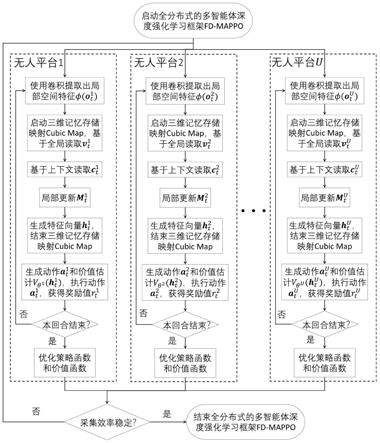
1.一种基于多智能体时空建模与决策的人机协同感知方法,其特征在于,包括:步骤1,启动全分布式的多智能体深度强化学习框架fd
‑
mappo,各无人平台清空各自的样本库,随机初始化各自的数据采集策略,以完全分布式的方式与人群协同开始数据采集任务;步骤2,各无人平台使用各自的卷积神经网络提取出各自局部观察中的空间特征;步骤3,各无人平台启动三维记忆存储映射cubic map,使用基于全局的卷积读取操作,从各自的三维记忆存储映射中提取全局历史信息;步骤4,各无人平台基于各自局部观察中的空间特征和从各自的三维记忆存储映射中提取的全局历史信息,使用基于上下文互相关的读取操作,根据三维记忆存储映射中的信息与局部空间特征和全局历史信息之间的互相关系数,对三维记忆存储映射中的信息进行加权;步骤5,各无人平台基于当前局部观察中的空间特征对三维记忆存储映射进行局部更新;步骤6,各无人平台基于当前局部观察中的空间特征、从各自的三维记忆存储映射中提取的全局历史信息和上下文信息,使用卷积操作生成特征向量,各无人平台结束三维记忆存储映射cubic map;步骤7,各无人平台基于特征向量,使用策略函数生成动作,使用价值函数生成价值估计,各无人平台执行产生的动作,获得奖励值;步骤8,反复执行步骤2
‑
7,直到本次数据采集任务结束,各无人平台基于各自的轨迹数据优化策略函数和价值函数;步骤9,反复执行步骤1
‑
8,直到人机协同数据采集效率保持稳定,结束全分布式的多智能体深度强化学习框架fd
‑
mappo。2.根据权利要求1所述的基于多智能体时空建模与决策的人机协同感知方法,其特征在于,步骤1中包括:步骤1.1,无人平台集群中各无人平台u清空样本库随机初始化参数θ
u
;步骤1.2,初始化时间步t=0,开始和人机协同群智感知环境交互。3.根据权利要求1所述的基于多智能体时空建模与决策的人机协同感知方法,其特征在于,步骤2包括:步骤2.1,对于当前时间步t,人机协同群智感知环境有全局状态s
t
,各无人平台u根据其在全局空间中的位置获得相应的局部观察步骤2.2,各无人平台u使用卷积神经网络φ(
·
)提取出各自局部观察中的空间特征4.根据权利要求1所述的基于多智能体时空建模与决策的人机协同感知方法,其特征在于,步骤3中,全局历史时空信息被存储在三维记忆存储映射当中,使用基于全局的卷积读取操作,将全部存储数据视为一个整体,使用卷积神经网络来提取全局信息,如下式(1):
式(1)中:φ
read
(
·
)代表卷积神经网络。5.根据权利要求1所述的基于多智能体时空建模与决策的人机协同感知方法,其特征在于,步骤4包括:步骤4.1、用可学习参数矩阵从当前局部空间特征和全局特征中通过卷积操作提取一个查询向量如下式(2):式(2)中:*表示矩阵乘法,[;]表示向量的连接;步骤4.2、计算查询向量与三维记忆存储映射之间的互相关系数矩阵,如下式(3):式(3)中:σ表示sigmod激活函数,表示计算互相关系数;步骤4.3、使用互相关系数矩阵为三维记忆存储映射加权,并通过卷积加权的结果产生一个上下文向量如下式(4):式(4)中:f
c
(
·
)通过第三维复制数据将二维向量扩展为三维向量f
c
(
·
),如下式(5):式(5)中:
⊙
表示按元素乘法。6.根据权利要求1所述的基于多智能体时空建模与决策的人机协同感知方法,其特征在于,步骤5包括:步骤5.1、从三维记忆存储映射中根据当前无人平台位置选择需要被更新的立方区域决定了写入特征向量的空间粒度;步骤5.2、用可学习参数矩阵从输入和中通过卷积操作生成重置门向量,如下式(6):步骤5.3、用可学习参数矩阵从输入和中通过卷积操作生成更新门向量,如下式(7):步骤5.4、用可学习参数矩阵和从输入和中通过卷积操作,使用重置
门生成候选向量如下式(8):步骤5.5、用更新门整合和候选向量生成如下式(9)的生成如下式(9)的步骤5.6、使用来替换中的生成下一时间步的三维记忆存储映射7.根据权利要求1所述的基于多智能体时空建模与决策的人机协同感知方法,其特征在于,步骤6中,对当前空间特征信息存储概况和上下文信息使用卷积生成特征向量如下式(10):式(10)中:φ
output
(
·
)表示卷积操作,[;]表示向量的连接。8.根据权利要求1所述的基于多智能体时空建模与决策的人机协同感知方法,其特征在于,步骤7包括:步骤7.1、无人平台u使用特征向量分别输入策略函数和价值函数生成动作和价值估计步骤7.2、各无人平台u执行动作获得奖励值进入下一个时间步。9.根据权利要求1所述的基于多智能体时空建模与决策的人机协同感知方法,其特征在于,步骤8包括:步骤8.1、反复执行步骤2
‑
7,直到本次数据采集任务结束;步骤8.2、各无人平台u收集轨迹数据并根据计算累积回报估计和优势估计对某个时间步i计算累积回报估计如下式(11):式(11)中:γ∈[0,1为折扣因子,使用gae的方式计算优势估计如下式(12):式(12)中:λ∈[0,1]为折扣因子,时间差分偏差如下式(13):步骤8.3、各无人平台u对在时间维度上按照长度k进行切片处理,将生成的序列样本加入样本库步骤8.4、各无人平台u以批学习的方式从样本库采集m个序列样本,基于ppo中的联
合损失函数对参数θu进行更新,之后进入下一回合,其中是策略函数的损失函数,是价值函数的损失函数,是策略函数相关的正则项,的计算公式如下式(14)
‑
(16):(16):(16):式(14)中:s为策略熵,c1,c2,∈1,∈2均为常量。
技术总结
本发明提出一种基于多智能体时空建模与决策的人机协同感知方法,包括:步骤1,启动全分布式的多智能体深度强化学习框架FD
技术研发人员:刘驰 王宇 朴成哲
受保护的技术使用者:北京理工大学
技术研发日:2021.08.17
技术公布日:2021/12/16
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。