1.本发明属于图像识别领域,具体设计一种基于对比学习的地外探测图像识别方法及系统。
背景技术:
2.图像识别旨在辨识图像所包含的物体,根据物体将图像分类至一个标签。计算机图像识别方法可以代替人类处理视觉信息,是信息时代的一门重要技术。传统的图像识别模型使用人工设计的特征提取机制及简单的分类器。近年来基于深度学习的图像识别模型采用数据驱动的卷积模型,模型通常在大型数据集上端到端训练。
3.外星地表图像为地外探测车在外星地表通过相机所收集的图像。与通常的图像识别任务不同,在外星地表探索任务中,模型只能使用探测器当前已拍摄的数据作为训练集,未来拍摄的数据则为测试目标。然而,由于探测器的前行与时间推进造成的环境变化与设备老化,以及探测器并不是以稳定的频率均匀地使用每一个设备进行数据采集,新拍摄数据通常与已有数据存在差异,造成了训练
‑
测试的性能差距。现有图像识别方法无法克服这种训练
‑
测试差异的影响,不满足地外探索的应用需求。
技术实现要素:
4.针对上述问题,本发明提出了一种基于对比学习的外星地表图像识别方法及系统,能够在不引入额外人类监督的条件下,使模型自适应学习新样本类型与数据域分布,进而兼容未知环境,更加准确地识别外星地表图像,满足探索应用需求。
5.本发明采用的技术方案如下:
6.一种基于对比学习的外星地表图像识别方法,包括以下步骤:
7.搭建图像识别模型,该图像识别模型包含特征提取器、分类检测器、类间对比学习检测器和相似性学习检测器;
8.搜集有标签和无标签的外星地表图像训练数据集,并输入到图像识别模型进行训练,该图像识别模型通过特征提取器提取外星地表图像的图像特征,通过分类检测器对外星地表图像的图像特征进行分类,通过类间对比学习检测器和相似性学习检测器根据分类后的图像特征分别进行类间对比学习和相似性学习任务目标的预测,以使该图像识别模型自适应学习新样本类型与数据域分布;通过迭代训练优化模型参数,直到该图像识别模型的总损失函数最小为止,得到训练好的图像识别模型;
9.将待检测的外星地表图像输入到该训练好的图像识别模型中进行分类,该训练好的图像识别模型通过特征提取器提取外星地表图像的图像特征,通过分类检测器根据所述图像特征进行分类,输出分类预测结果。
10.进一步地,总损失函数由分类交叉熵损失函数、类间对比学习损失函数和相似度学习损失函数组成。
11.一种基于对比学习的外星地表图像识别系统,包括:
12.数据采集模块,用于采集外星地表图像,输入到图像识别模型中进行识别;
13.图像识别模型,包含特征提取器、分类检测器、类间对比学习检测器和相似性学习检测器;特征提取器用于提取外星地表图像的图像特征;分类检测器用于对外星地表图像的图像特征进行分类;类间对比学习检测器和相似性学习检测器用于在训练过程中根据图像特征分别进行类间对比学习和相似性学习任务目标的预测,以使该图像识别模型自适应学习新样本类型与数据域分布;该图像识别模型经过训练后,用于对待检测的外星地表图像的图像特征进行识别和分类;
14.预训练模块,用于搜集有标签和无标签的外星地表图像训练数据集,并输入到所述图像识别模型进行迭代训练,通过优化模型参数,降低模型的总损失函数,获得训练后的图像识别模型。
15.与现有技术相比,本发明的积极效果为:
16.本发明在分类学习任务的基础上,专门设计了同时进行类间对比学习与相似性学习的学习策略,其中类间对比学习使用标签作为辅助的;相似性学习只考虑正例样本,不考虑负样本。类间对比学习可以扩大不同类之间的特征距离,提升模型对不同类别的区分能力。在类间对比学习的辅助下,即便测试图像与训练图像存在较大差异,样本也能被更准确地识别。类间对比学习可以将top
‑
1准确率由79.28%提升至提升93.82%。相似度学习通过在有标签训练数据的基础上引入额外的无标签数据,扩展模型的泛化性,使得模型对未知测试数据更加鲁棒,由此降低训练
‑
测试的性能差距。在使用类间对比学习的基础上联合使用相似度学习可以将top
‑
1准确率由93.82%进一步提升至95.86%。
附图说明
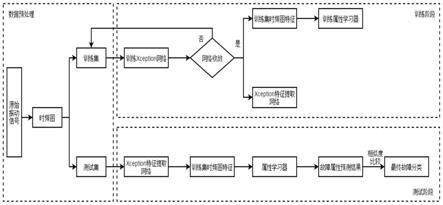
17.图1为本发明实施例所使用的外星地表图像识别网络的训练框架图。
18.图2为本发明实施例所使用的外星地表图像识别网络的使用框架图。
具体实施方式
19.为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。需说明的是,以下实施例所给出的具体层数、模块数、函数数量以及对某些层的设置等都仅是一种较佳的实施方式,而不用于限制,本领域技术人员可以根据实际需要来选取数量和设置某些层,应可理解。
20.本实施例公开一种外星地表图像识别方法,具体说明如下:
21.步骤1:搜集外星地表图像,以msl surface火星地表图像识别基准测试集为例,进行数据清洗,并标注分类标签,组成有标签的外星地表图像训练数据集。搜集数量更多的外星地表图像,不需要进行数据清洗和标注,组成无标签的外星地表图像训练数据集。
22.步骤2:搭建图像识别网络框架。
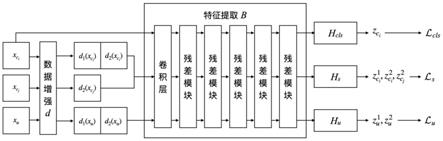
23.网络结构如图1所示,包含分类特征提取器b、分类检测器h
cls
、类间对比学习检测器h
s
和相似性学习检测器h
u
。分类特征提取器由一个卷积层、若干残差模块以及一个全局平均模块组成;分类检测器包含一个全连接层,输出样本所属类别的概率;类间对比学习检测器和相似性学习检测器均由两层全连接网络构成,其中第一个全连接层后跟随一个线性整流函数(relu),最终输出结果为一维特征。
24.步骤3:训练分类特征提取器b、分类检测器h
cls
、类间对比学习检测器h
s
和相似性学习检测器h
u
。模型的总损失函数项为:
25.l=λ
cls
l
cls
λ
s
l
s
λ
u
l
u
,
26.式中,λ
cls
、λ
s
和λ
u
是权重项,通常λ
cls
设置为1,λ
s
设置为1,λ
u
设置为0.2。l
cls
、l
s
和l
u
是子训练损失函数。l
s
的训练批batch大小为24,l
cls
和l
u
的训练批batch大小为16。分类检测器h
cls
的学习率为0.001,训练分类特征提取器b、类间对比学习检测器h
s
和相似性学习检测器h
u
的学习率为0.000001。训练遍历训练数据集30轮,在第25轮时,学习率缩小10倍。
27.1)l
cls
为分类交叉熵损失函数:
[0028][0029]
y
c
为样本x的标签,正确类的值为1,错误类的值为0;p
c
=h
cls
(b(x))为分类检测器所预测的样本x属于类别c的概率,b(x)是特征提取器b在样本x上提取的特征;m为类别总数。
[0030]
2)l
s
为类间对比学习损失函数:
[0031][0032]
温度系数τ设置为0.2。给定数据集中的样本x
i
,对比学习首先生成两个模态d1(x
i
)和d2(x
i
),其中d表示同一个随机数据增强操作。所使用的数据增强包含两种类型:形状和像素。形状增强包括翻转、裁剪、缩放大小和旋转,像素增强包括高斯模糊、颜色抖动和降低饱和度。和度。其中k为1或2。表示在经过了d
k
数据增强的样本x
c
·
上提取的特征。x
ci
和x
cj
分别代表类别标签为ci和cj的样本。sim(
·
,
·
)代表两个归一化向量的相似度:
[0033]
sim(u,v)=u
t
v。
[0034]
3)l
u
为相似度学习损失函数:
[0035][0036]
式中,其中k为1或2。表示在经过了d
k
数据增强的无标签图像x
u
上提取出的特征。
[0037]
步骤4:使用阶段,输入待检测外星地表图像x,输出分类预测结果h
cls
(b(x))。
[0038]
对输出的分类预测结果测试可知,能够将通用图像识别模型resnet
‑
50的top
‑
1准确率由79.28%提升至95.86%。
[0039]
相比较于现有特征提取、自学习训练、相似度判断、分类器分类等方法,本发明方法能更加有效地解决地外探测图像识别的问题,这是因为地外行星图像的训练
‑
测试差异是由于“探测器的前行与时间推进造成的环境变化与设备老化,以及探测器并不是以稳定的频率均匀地使用每一个设备进行数据采集”的原因造成的。与常见图像任务的训练
‑
测试差异相比,地外行星图像任务上的训练
‑
测试差异更加复杂。在msl surface火星地表图像识别基准测试集的实验结果上,经典的图像分类性能提升技术:triplet loss、center loss、focal loss、pseudo labeling,只能分别实现84.87%、82.91%、82.86%、78.64%的top
‑
1识别准确率,而本发明通用图像识别模型resnet
‑
50的top
‑
1准确率由79.28%提升至
95.86%,显著提升外星地表图像识别性能。
[0040]
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。