1.本公开涉及一种电子设备和用于控制电子设备的方法,并且例如涉及一种基于语音数据和通过对语音数据应用用于增强声音质量的算法而获得的数据来确定要输入到特定模型的数据的电子设备以及用于控制电子设备的方法。
背景技术:
2.传统上已开发和使用了各种算法(例如,用于滤除语音信号中包含的噪声的算法、基于波束成形的算法、基于神经网络的映射特征的算法等),以增强语音的声音质量。
3.当将用于增强声音质量的算法应用于正常嘈杂环境中输入的用户语音时,可以增强语音的声音质量。然而,如果将用于增强声音质量的算法应用于在噪声相对较小或基本没有噪声的干净环境中输入的用户语音,则语音的声音质量可能会劣化。
4.换句话说,传统的增强算法将输入数据映射到目标数据以最小化或最大化确定的目标函数,但是不测量映射的输出数据的可靠性程度。因此,增强算法在特定情况下可能会劣化而不是增强语音的声音质量。
技术实现要素:
5.技术问题
6.鉴于上述需要做出本公开,并且本公开提供了一种基于语音数据和通过将语音数据输入到用于增强声音质量的模型而获得的输出数据来确定要输入到特定模型的输入数据的电子设备以及用于控制电子设备的方法。
7.问题的解决方案
8.本公开的实施例提供了一种基于语音数据和通过将语音数据输入到用于增强声音质量的模型而获得的输出数据来确定要输入到特定模型的输入数据的电子设备以及用于控制电子设备的方法。
9.根据本公开的示例实施例,提供了一种电子设备,该电子设备包括:麦克风、存储至少一个指令的存储器、以及处理器,被配置为执行所述至少一个指令,其中,处理器通过执行所述至少一个指令被配置为:通过将经由麦克风输入的第一语音数据输入到被训练为增强声音质量的第一模型来获得第二语音数据,通过将第一语音数据和第二语音数据输入到第二模型来获得权重,以及使用权重识别要输入到第三模型的输入数据。
10.处理器可以使用第一语音数据、第二语音数据、以及第二语音数据与对应于第一语音数据的干净语音数据之间的误差的估计值来获得权重。
11.处理器可以基于权重将第一语音数据和第二语音数据线性组合;以及识别线性组合的值作为输入数据。
12.处理器可以基于权重识别第一语音数据和第二语音数据中的一个作为输入数据。
13.处理器可以基于权重大于阈值,识别第二语音数据作为输入数据,以及基于权重小于阈值,识别第一语音数据作为输入数据。
14.处理器可以基于权重大于第一阈值,识别第二语音数据作为输入数据,基于权重大于第二阈值且小于第一阈值,基于权重将第一语音数据和第二语音数据线性组合并识别线性组合的值作为输入数据,以及基于权重小于第二阈值,识别第一语音数据作为输入数据,其中,第一阈值可以是大于第二阈值的值。
15.第三模型可以是唤醒模型或自动语音识别模型中的至少一个。
16.处理器可以基于第一语音数据、对应于第一语音数据的干净语音数据和第二语音数据来训练第一模型和第二模型。
17.处理器可以通过向第三模型输入第一语音数据和第二语音数据中的每一个,获得与第一语音数据对应的第一得分并获得与第二语音数据对应的第二得分,以及基于第一语音数据、第二语音数据、第一得分和第二得分来训练第二模型。
18.处理器可以通过将第一语音数据和第二语音数据输入到第二模型,获得第一得分与第二得分之间的差的估计值,以及基于第一得分与第二得分之间的差的估计值获得权重。
19.根据本公开的另一示例实施例,一种用于控制包括麦克风的电子设备的方法,该方法包括:通过将经由麦克风输入的第一语音数据输入到被训练为增强声音质量的第一模型来获得第二语音数据;通过将第一语音数据和第二语音数据输入到第二模型来获得权重;以及使用权重识别要输入到第三模型的输入数据。
20.获得可以包括基于第一语音数据、第二语音数据、以及第二语音数据与对应于第一语音数据的干净语音数据之间的误差的估计值来获得权重。
21.识别可以包括基于权重将第一语音数据和第二语音数据线性组合,以及识别线性组合的值作为输入数据。
22.识别可以包括基于权重识别第一语音数据和第二语音数据中的一个作为输入数据。
23.识别可以包括基于权重大于阈值,识别第二语音数据作为输入数据,以及基于权重小于阈值,识别第一语音数据作为输入数据。
24.确定可以包括基于权重大于第一阈值,识别第二语音数据作为输入数据,基于权重大于第二阈值且小于第一阈值,基于权重将第一语音数据和第二语音数据线性组合,并识别线性组合的值作为输入数据,以及基于权重小于第二阈值,识别第一语音数据作为输入数据,其中,第一阈值是大于第二阈值的值。
25.第三模型可以是唤醒模型或自动语音识别模型中的至少一个。
26.该方法还可以包括基于第一语音数据、对应于第一语音数据的干净语音数据和第二语音数据来训练第一模型和第二模型。
27.该方法还可以包括通过向第三模型输入第一语音数据和第二语音数据中的每一个,获得与第一语音数据对应的第一得分并获得与第二语音数据对应的第二得分,以及基于第一语音数据、第二语音数据、第一得分和第二得分来训练第二模型。
28.获得权重可以包括通过将第一语音数据和第二语音数据输入到第二模型,获得第一得分与第二得分之间的差的估计值,以及基于第一得分与第二得分之间的差的估计值获得权重。
29.发明的有利效果
30.如上所述,根据本公开的实施例,用户可以更有效地使用语音识别系统,因为电子设备基于语音数据和通过对语音数据应用用于增强声音质量的算法而获得的数据来确定(例如,识别)要输入到特定模型的数据。
附图说明
31.从以下结合附图的详细描述中,本公开的某些实施例的上述和其他方面、特征和优点将更加清晰,在附图中:
32.图1是示出根据实施例的电子设备的示例配置和操作的框图;
33.图2a和图2b是示出根据实施例的电子设备训练第二模型的示例过程的框图;
34.图3和图4是示出根据实施例的电子设备使用获得的权重确定输入数据的示例过程的流程图;
35.图5是示出根据实施例的电子设备的示例配置的框图;以及
36.图6是示出根据实施例的用于控制电子设备的示例方法的流程图。
具体实施方式
37.鉴于上述需要做出本公开,并且本公开提供了一种基于语音数据和通过将语音数据输入到用于增强声音质量的模型而获得的输出数据来确定要输入到特定模型的输入数据的电子设备以及用于控制电子设备的方法。
38.图1所示的电子设备100可以基于经由麦克风110输入的第一语音数据和通过将用于增强声音质量的算法应用于第一语音数据而获得的第二语音数据来确定(例如,识别)要输入到特定模型的输入数据。如果在干净的环境中将用于增强声音质量的算法应用于经由麦克风110输入的第一语音数据,则第一语音数据的声音质量可能相对劣化。因此,电子设备100可以执行基于第一语音数据和第二语音数据来确定要输入到特定模型的语音数据的过程。下面将更详细地描述由电子设备100确定(例如,识别)要输入到特定模型的语音数据的过程。
39.在下文中,将参照附图更详细地描述本公开的示例实施例。
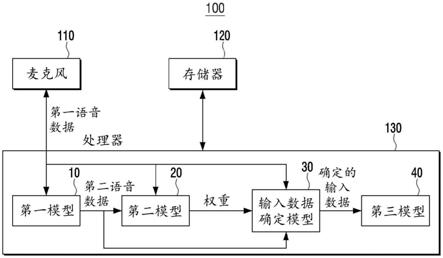
40.图1是示出根据本公开的实施例的示例电子设备的示例配置并且帮助描述电子设备的示例操作的图。如图1所示,电子设备100可以包括麦克风110、存储器120和处理器(例如,包括处理电路)130。然而,图1所示的配置是用于实现本公开的实施例的示例,并且可以向电子设备100附加地添加对本领域技术人员而言明显的合适的硬件或软件组件。
41.麦克风110可以例如是用于从用户接收语音的组件。麦克风110可以从用户接收第一语音数据。第一语音数据可能会受到周围环境的影响,因为它是通过用户从电子设备100外部的话语输入的语音数据。因此,在具有大量噪声的环境中输入的第一语音数据可能具有由于噪声而产生的干扰和混响效应,并且在噪声相对较小的干净环境中输入的第一语音数据可能具有相对较小的由于噪声而产生的干扰和混响效应。术语“用户”可以指使用电子设备的人或使用电子设备的装置(例如,人工智能电子装置)。
42.麦克风110可以被提供在电子设备100中,或者可以被提供在电子设备100的外部并且电连接到电子设备100。另外,如果麦克风110被提供在外部,则麦克风110可以向处理器130发送经由有线或无线接口(例如,wi
‑
fi或蓝牙)生成的用户语音信号。
43.存储器120可以存储与电子设备100的至少另一个组件相关的指令或数据。该指令可以指例如由处理器130以程序编写语言直接执行的动作语句并且可以包括例如程序的执行或动作的最小单位。处理器130可以访问存储器120,并且可以执行处理器130对数据的读取、记录、编辑、删除或更新。
44.存储器120可以存储能够执行各种功能的模型。例如,存储器120可以存储第一模型10、第二模型20、输入数据确定模型30和第三模型40,并且每个模型可以由处理器130控制/执行。这里公开和描述的各种模型可以包括例如处理电路和/或由处理电路执行的可执行程序元素。
45.例如,第一模型10可以是将用于增强声音质量的算法应用于经由麦克风110输入的第一语音数据的模型。因此,第一模型10可以在处理器130的控制下通过将用于增强声音质量的算法应用于经由麦克风110输入的第一语音数据来输出第二语音数据。第一模型10可以被实现为将用于滤除噪声的算法或基于波束成形的算法应用于第一语音数据的模型。在另一个示例中,第一模型10可以被实现为执行用于去除各种噪声和调整混响的算法的神经网络模型(例如,高斯混合模型(gmm))。
46.例如,第二模型20可以是被训练以在处理器130的控制下输入第二语音数据和第一语音数据时输出权重的神经网络模型。权重可以指例如用于调整应用于输出数据的输入数据的效果的参数,并且可以是能够确定(例如,识别)要输入到第三模型40的输入数据的元素。
47.在本公开的实施例中,响应于输入第一语音数据和第二语音数据,训练的第二模型20可以获得例如第二语音数据与对应于第一语音数据的干净语音数据之间的均方误差的估计值。训练的第二模型20可以基于获得的均方误差的估计值、第一语音数据和第二语音数据输出权重。干净语音数据可以指例如在没有诸如噪声的外部影响的干净的环境中输入的语音数据。
48.第二语音数据与对应于第一语音数据的干净语音数据之间的均方误差的估计值可以与第二语音数据的可靠性成反比。均方误差的估计值越大,可能暗示第二语音数据与对应于第一语音数据的干净语音数据之间的差越大,因此,该误差的估计值越大,可能暗示第二语音数据的可靠性越低。
49.可以在处理器130的控制下使用对应于第一语音数据的干净语音数据与第二语音数据之间的均方误差的值作为学习数据来训练第二模型20。下面将参考图2a更详细地描述在处理器130的控制下基于均方误差的值训练第二模型20的过程。
50.在本公开的另一实施例中,响应于输入第一语音数据和第二语音数据,第二模型20可以获得对应于第一语音数据的第一得分与对应于第二语音数据的第二得分之间的差的估计值。此外,第二模型20可以基于所获得的第一得分与第二得分之间的差的估计值来输出权重。例如,第二模型20可以通过将预定义的映射函数应用于第一得分与第二得分之间的差的估计值来获得权重。
51.对应于第一语音数据的第一得分与对应于第二语音数据的第二得分可以包括当第一语音数据和第二语音数据分别输入到第三模型40时要输出的数据。例如,对应于每个语音数据的得分可以根据第三模型40以不同方式实现。例如,如果第三模型40包括自动语音识别(asr)模型(例如,包括处理电路和/或由处理电路执行的可执行程序元素),则得分
可以是语音可靠性或词错误率(wer)。例如,如果第三模型40是唤醒模型,则该得分可以是激活对话系统的可能性。
52.可以在处理器130的控制下使用第一得分与第二得分之间的差的估计值作为学习数据来训练第二模型20。下面将参考图2b更详细地描述在处理器130的控制下基于第一得分与第二得分之间的差的估计值训练第二模型20的过程。
53.例如,输入数据确定模型30可以是使用第一语音数据、第二语音数据和权重中的至少一个来确定(例如,识别)输入数据的模型。例如,输入数据确定模型30可以基于权重将第一语音数据和第二语音数据线性组合,并且确定(例如,识别)线性组合的值作为输入数据。在另一示例中,输入数据确定模型30可以基于权重确定(例如,识别)第一语音数据和第二语音数据中的一个作为输入数据。
54.在又一示例中,如果权重大于第一阈值,则输入数据确定模型30可以确定(例如,识别)第二语音数据作为输入数据。如果权重大于第二阈值并且小于第一阈值,则输入数据确定模型30可以基于权重确定(例如,识别)第一语音数据和第二语音数据的线性组合的值作为输入数据。如果权重小于第二阈值,则输入数据确定模型30可以确定(例如,识别)第一语音数据作为输入数据。第一阈值和第二阈值可以是例如用于确定要输入到第三模型40的数据与第一语音数据和第二语音数据中的哪个数据相似的值,可以是例如通过实验预先确定的值,并且可以例如由用户改变。
55.第三模型40可以是例如由输入数据确定模型30确定(例如,识别)的输入数据被输入到的模型。第三模型40可以被实现为例如但不限于唤醒模型、asr模型等。然而,这仅是示例,并且可以根据电子设备100的类型、输入数据的类型和用户命令等不同地实现第三模型。例如,唤醒模型可以是当唤醒模型确定(例如,识别)经由麦克风110输入的用户语音包括唤醒词时,唤醒或激活能够执行自然语言处理的对话系统的模型。例如,自动语音识别模型可以是关于经由麦克风110输入的用户语音执行语音识别并输出与识别出的语音对应的文本的模型。
56.第一模型10、第二模型20、输入数据确定模型30和第三模型40可以存储在非易失性存储器中,并且可以当对话系统被激活时在处理器130的控制下加载到易失性存储器中。在另一个实施例中,当经由麦克风110输入用户语音时,每个模型可以在处理器130的控制下被加载到易失性存储器中。加载可以指例如下述操作:调用非易失性存储器中所存储的数据并将其存储在易失性存储器中,使得处理器130可以访问数据。对话系统被激活的情况可以包括下述情况:其中对话系统被存储在非易失性存储器中并且在处理器130的控制下被加载到易失性存储器中。
57.图1示出了下述示例实施例,其中每个模型从非易失性存储器加载到易失性存储器,并且易失性存储器被包括作为处理器130的组件。然而,这仅是示例,并且易失性存储器可以被实现为与处理器130分开的组件。易失性存储器可以包括例如即使停止供电也能够保持存储的信息的存储器。例如,非易失性存储器120可以包括闪存、可编程只读存储器(prom)、磁阻随机存取存储器(mram)和电阻式ram(rram)中的至少一个。易失性存储器可以包括例如需要持续供电以保持存储的信息的存储器。例如,易失性存储器可以包括动态随机存取存储器(dram)和静态ram(sram)中的至少一个。
58.处理器130可以包括各种处理电路并电连接到存储器120,并且可以控制电子设备
100的一般操作。例如,通过执行存储在存储器120中的至少一个指令,处理器130可以通过将经由麦克风110输入的第一语音数据输入到被训练为增强声音质量的第一模型10来获得第二语音数据。例如,处理器130可以经由第一模型10通过将用于增强声音质量的算法应用于第一语音数据来获得第二语音数据。
59.此外,处理器130可以通过将第一语音数据和第二语音数据输入到预训练的第二模型20来获得权重。
60.在本公开的实施例中,处理器130可以通过第二模型20获得第二语音数据与对应于第一语音数据的干净语音数据之间的均方误差的估计值。通过第二模型20获得的、对应于第一语音数据的干净语音数据与第二语音数据之间的均方误差的估计值可以表示为以下数学公式1。
61.【数学公式1】
[0062][0063]
在数学公式1中,x表示对应于第一语音数据的干净语音数据,hat{x}表示第二语音数据,并且v表示均方误差的估计值。v、x和hat{x}可以以多维矩阵的张量的形式实现,并且数学公式1是张量的第i分量的公式。
[0064]
处理器130可以基于第一语音数据、第二语音数据和误差的估计值来获得权重。例如,处理器130可以通过第二模型20基于第一语音数据、第二语音数据和误差的估计值获得权重。例如,处理器130获得的权重可以是用于最小化和/或减小被确定(例如,识别)要输入到第三模型40的输入数据与对应于第一语音数据的干净语音数据之间的差的权重值,并且用于获得该权重的公式可以被实现为以下数学公式2。权重可以是0到1的值。
[0065]
【数学公式2】
[0066][0067]
在数学公式2中,w表示权重值,y表示第一语音数据,hat{x}表示第二语音数据,并且v表示估计误差值。w、y和hat{x}可以以张量的形式实现,并且数学公式2是张量的第i分量的公式。通过数学公式3,可以导出数学公式2的权重为用于最小化和/或减小被确定(例如,识别)要输入到第三模型的输入数据与对应于第一语音数据的干净语音数据之间的差的权重。
[0068]
【数学公式3】
[0069][0070]
例如,参考数学公式3,ε表示作为被确定(或,识别)要输入到第三模型的输入数据的z与对应于第一语音数据的干净语音数据之间的均方误差的值。输入数据z可以表示为以下将描述的数学公式8中所示的公式。如图3所示,输入数据z可以是通过基于权重将第二语音数据和第一语音数据线性组合而获得的值。ε、z、x、y和hat{x}可以以张量的形式实现,并且数学公式3是张量的第i分量的公式。
[0071]
如果通过无偏估计获得第二语音数据与对应于第一语音数据的干净语音数据之
间的均方误差的估计值,则ε的值可以表示为以下数学公式4。
[0072]
【数学公式4】
[0073][0074]
数学公式4是关于权重的二次公式,并且用于最小化和/或减小ε的值的权重可以表示为数学公式5。
[0075]
【数学公式5】
[0076][0077]
如果不是第一模型10和第二模型20的训练过程,则对应于第一语音数据的干净语音数据未被识别,因此,电子设备100可以使用以下数学公式6中的公式,而不是数学公式5中的公式。以下数学公式6可以用与数学公式2相同的方式表达。
[0078]
【数学公式6】
[0079][0080]
为了导出数学公式6,假设以下数学公式7。
[0081]
【数学公式7】
[0082][0083]
在本公开的另一实施例中,处理器130可通过第二模型20获得第一得分与第二得分之间的差的估计值。第一得分和第二得分中的每一个是当第一语音数据和第二语音数据中的每一个被输入到第三模型40时获得的数据。处理器130可以通过将预定义的映射函数应用于第一得分与第二得分之间的差的估计值来获得权重。
[0084]
例如,第三模型40可以被实现为asr模型并且对应于语音数据的得分可以是例如词错误率(wer)。处理器130可以通过将第一语音数据和第二语音数据输入到第二模型20来获得第一词错误率与第二词错误率之间的差的估计值。第一词错误率和第二词错误率可以是当第一语音数据和第二语音数据中的每一个被输入到asr模型时输出的词错误率。处理器130可以经由第二模型20通过将映射函数应用于第一词错误率与第二词错误率之间的差的估计值来获得权重。
[0085]
处理器130可以使用通过输入数据确定模型30获得的权重来确定(例如,识别)要输入到第三模型40的输入数据。在一个实施例中,处理器130可以基于权重将第一语音数据和第二语音数据线性组合,并通过输入数据确定模型30确定(例如,识别)线性组合的数据作为输入数据。处理器130获得的线性组合的值可以表示为以下数学公式8。在数学公式8中,z表示线性组合的值,w表示权重,y表示第一语音数据,并且hat{x}表示第二语音数据。换言之,处理器130可以使用线性插值获得要输入到第三模型的光输入数据。
[0086]
【数学公式8】
[0087][0088]
电子设备100可以通过数学公式2和数学公式8来确定(例如,识别)要输入到第三
模型的输入数据与第一语音数据和第二语音数据中的哪个数据更相似。例如,当误差的估计值(v)增大时,权重值变得接近于0,则输入的数据值可能是与第一语音数据更相似的数据。例如,如果第二语音数据的可靠性由于估计误差值的增大而降低,则电子设备100可以确定(例如,识别)与第一语音数据相似的数据作为输入数据。当估计误差值减小时,权重值变得接近于1,相应地,输入数据值可能是与第二语音数据更相似的数据。换言之,第二语音数据的可靠性由于估计误差值的减小而增加,相应地,电子设备100可以确定(例如,识别)与第二语音数据相似的数据作为输入数据。
[0089]
在另一示例中,处理器130可以使用输入数据确定模型30基于权重来确定(例如,识别)第一语音数据和第二语音数据中的一个作为输入数据。例如,如果权重大于阈值,则处理器130可以确定(例如,识别)第二语音数据作为输入数据。在另一示例中,如果权重小于阈值,则处理器130可以确定(例如,识别)第一语音数据作为输入数据。
[0090]
在又一示例中,如果权重大于第一阈值,则处理器130可以确定(例如,识别)第二语音数据作为输入数据,并且如果权重小于第二阈值,则处理器130可以使用输入数据确定模型30确定(例如,识别)第一语音数据作为输入数据。如果权重大于第二阈值并且小于第一阈值,则处理器130可以基于权重将第一语音数据和第二语音数据线性组合并且确定(例如,识别)线性组合的值作为输入数据。
[0091]
处理器130可以获得可通过将确定的(例如,识别的)输入数据输入到第三模型40执行特定功能的结果。例如,如果第三模型是识别用户语音中的能够唤醒对话系统的触发语音的唤醒模型并且第一语音数据是与触发语音对应的数据,则处理器130可以通过向唤醒模型输入确定的(例如,识别的)输入数据来获得用于唤醒对话系统的信号。在另一示例中,如果第三模型是asr模型,则处理器130可以通过将确定的(例如,识别的)输入数据输入到asr模型来识别输入给用户的语音。
[0092]
处理器130可以使用学习数据来训练第二模型20。学习数据可以是对应于第一语音数据的干净语音数据与第二语音数据之间的均方误差的估计值。在又一示例中,学习数据可以是第一得分与第二得分之间的差的估计值。下面将参考图2a和图2b更详细地描述处理器130使用学习数据训练第二模型20的过程。
[0093]
在本公开中,处理器130可以包括一个或多个处理器。一个或多个处理器130可以是诸如中央处理单元(cpu)或应用处理器(ap)的通用处理器、诸如图形处理单元(gpu)或视觉处理单元(vpu)的图形专用处理器、或诸如神经处理单元(npu)的人工智能处理器等,但不限于此。
[0094]
根据本公开的与人工智能相关的功能可以由存储器120和处理器130操作。一个或多个处理器130可以执行控制以根据存储在存储器120中的预定义动作规则或人工智能模型来处理输入数据。通过训练形成预定义的动作规则或人工智能模型。这里通过训练形成可以指例如通过将训练算法应用于多条学习数据来形成具有期望特征的人工智能模型或预定义的动作规则。这种训练可以在根据本公开的展示人工智能的设备中执行,或由单独的服务器或系统执行。
[0095]
根据本公开的与人工智能相关的功能可以由处理器和存储器操作。处理器可以包括一个或多个处理器。一个或多个处理器可以是诸如cpu、ap或数字信号处理器(dsp)的通用处理器,诸如gpu或vpu的图形专用处理器,诸如npu的人工智能处理器等,但不限于此。一
个或多个处理器可以执行控制以根据存储在存储器中的预定义的动作规则或人工智能模型来处理输入数据。另外,如果一个或多个处理器是人工智能专用处理器,则人工智能专用处理器可以被设计为具有专门处理特定人工智能模型的硬件结构。
[0096]
可以通过训练形成预定义的动作规则或人工智能模型。这里通过训练形成可以指例如通过训练算法使用多条学习数据训练基本人工智能模型来形成被设置为执行期望的特征(或对象)的人工智能模型或预定义的动作规则。这种训练可以在根据本公开的展示人工智能的设备中执行,或由单独的服务器或系统执行。学习算法的示例包括监督学习、无监督学习、半监督学习或强化学习,但不限于这些示例。
[0097]
人工智能模型可以包括多个神经网络层。多个神经网络层分别具有多个权重值,并且通过前一层的处理结果和多个权重之间的处理执行神经网络处理。多个神经网络层的多个权重可以通过人工智能模型的训练结果进行优化和/或改进。例如,可以更新多个权重以减小或最小化和/或减小人工智能模型在训练过程期间获得的损失值或成本值。人工神经网络可以包括例如但不限于卷积神经网络(cnn)、深度神经网络(dnn)、循环神经网络(rnn)、受限玻尔兹曼机(rbm)、深度信念网络(dbn)、双向循环深度神经网络(brdnn)、深度q网络等,但是不存在对这些示例的限制。
[0098]
图2a和图2b是示出根据本公开的实施例的由电子设备100的处理器130训练第二模型20的示例过程的框图。图2a和图2b是示出每个模型和数据被加载到易失性存储器的情况的图。图2a和图2b示出了易失性存储器被包括作为处理器130的组件的情况,但这仅是示例,并且易失性存储器可以是与处理器130分开的组件。
[0099]
在本公开的实施例中,如图2a所示,处理器130可以基于对应于第一语音数据的干净语音数据50与第二语音数据之间的均方误差的估计值来训练第二模型20。例如,处理器130可以通过将干净语音数据50输入到模拟工具(例如,包括处理电路和/或可执行程序元素)60来获得第一语音数据。干净语音数据50可以是用于训练第二模型20的预定数据,并且可以是没有任何外部影响(诸如噪声)的语音数据。例如,模拟工具60可以是通过将诸如噪声的外部影响应用于干净语音数据50来输出用于训练第二模型20的第一语音数据的模型。因此,由模拟工具60输出的第一语音数据可以类似于经由麦克风110输入的第一语音数据。
[0100]
处理器130可以通过第二模型20获得对应于第一语音数据的干净语音数据与第二语音数据之间的均方误差的值。例如,第二模型20可以使用数学公式1获得均方误差的值。数学公式1中的v可以是对应于第一语音数据的干净语音数据与第二语音数据之间的均方误差的值。
[0101]
处理器130可以通过将第一语音数据和第二语音数据输入到第二模型20来获得对应于第一语音数据的干净语音数据与第二语音数据之间的均方误差的估计值。处理器130可以获得下述两者之间的差:预先获得的均方误差的值;和对应于第一语音数据的干净语音数据与第二语音数据之间的均方误差的估计值。处理器130可以训练第二模型20以输出最佳和/或改进的估计值,以最小化和/或减小所获得的均方误差的值和在对应于第一语音数据的干净语音数据与第二语音数据之间的均方误差的估计值之间的差。
[0102]
当在处理器130的控制下输入第一语音数据和第二语音数据时,预先训练的第二模型20可以获得优化和/或改进的对应于第一语音数据的干净语音数据与第二语音数据之间的均方误差的估计值。
[0103]
在本公开的另一个实施例中,参考图2b,处理器130可以基于第一得分与第二得分之间的差来训练第二模型20。已经参考图2a描述了处理器130通过模拟工具60使用干净语音数据获得第一语音数据的过程,因此将省略重复的描述。例如,处理器130可以通过将第一语音数据和第二语音数据中的每一个单独地输入到第三模型40来获得分别对应于第一语音数据和第二语音数据的第一得分和第二得分。处理器130可以获得第一得分与第二得分之间的差。
[0104]
处理器130可以通过将第一语音数据和第二语音数据输入到第二模型20来获得第一得分与第二得分之间的差的估计值。处理器130可以训练第二模型20以输出最佳和/或改进的估计值以最小化和/或减小下述两者之间的差:1)预先获得的第一得分与第二得分之间的差;和2)第一得分与第二得分之间的差的估计值。因此,当在处理器130的控制下输入第一语音数据和第二语音数据时,训练的第二模型20可以获得优化和/或改进的第一得分与第二得分之间的差的估计值。
[0105]
例如,如果第三模型40被实现为asr模型,则处理器130可以通过将第一语音数据和第二语音数据中的每一个输入到asr模型来获得第一语音数据的语音可靠性值和第二语音数据的第二语音可靠性值。例如,语音可靠性值可以是表示输入语音数据识别和转换为文本的正确程度的值。处理器130可以获得第二语音可靠性值与第一语音可靠性值之间的差。
[0106]
处理器130可以通过将第一语音数据和第二语音数据输入到第二模型20来获得第一语音可靠性值和第二语音可靠性值之间的差的估计值。处理器130可以训练第二模型20以输出最佳和/或改进的估计值,以最小化和/或减小下述两者之间的差:1)预先获得的第一语音可靠性值和第二语音可靠性值之间的差;和2)第一语音可靠性值和第二语音可靠性值之间的差的估计值。因此,当处理器130输入第一语音数据和第二语音数据时,训练的第二模型20可以获得优化和/或改进的第一语音可靠性值和第二语音可靠性值之间的差的估计值。第二模型20可以基于最佳和/或改进的第一语音可靠性值和第二语音可靠性值之间的差的估计值输出权重。权重可以是通过将预定义的映射函数应用于估计值而获得的值。
[0107]
作为负值的、第二语音可靠性值和第一语音可靠性值之间的差的估计值可以指例如高的第一语音可靠性值,并且作为正值的、第二语音可靠性值和第一语音可靠性值之间的差的估计值可以指例如高的第二语音可靠性值。因此,当输出负估计值并且第二模型20基于输出的估计值输出权重时,输入数据确定模型30可以确定(例如,识别)第一语音数据作为要输入到第三模型40的数据。当输出正估计值并且第二模型20基于输出的估计值输出权重时,输入数据确定模型30可以确定(例如,识别)第二语音数据作为要输入到第三模型40的数据。
[0108]
在另一示例中,如果第三模型40被实现为asr模型,则第二模型20可以在处理器130的控制下基于第一语音数据的第一词错误率(例如,wer)和第二语音数据的第二词错误率来训练。例如,词错误率可以是表示asr模型对输入语音的不正确识别的程度的数值。例如,词错误率可以是表示当将实际输入的语音与asr模型的识别结果进行比较时词错误出现的程度的数值。
[0109]
例如,处理器130可以通过将第一语音数据和第二语音数据中的每一个输入到asr模型来获得第一语音数据的第一词错误率和第二语音数据的第二词错误率。处理器130可
以获得第一词错误率和第二词错误率之间的差值。处理器130可以通过将第一语音数据和第二语音数据输入到第二模型20来获得第一词错误率和第二词错误率之间的差的估计值。处理器130可以训练第二模型20以输出最佳和/或改进的估计值,以最小化和/或减小下述两者之间的差:1)预先获得的第一词错误率和第二词错误率之间的差;和2)第一词错误率和第二词错误率之间的差的估计值。相应地,当处理器130输入第一语音数据和第二语音数据时,训练的第二模型20可以获得优化和/或改进的第一词错误率和第二词错误率之间的差的估计值。处理器130可以基于所获得的优化和/或改进的差的估计值来输出最佳和/或改进的权重。
[0110]
作为负值的、第一词错误率与第二词错误率之间的差的估计值可能暗示高的第二词错误率,而作为正值的、第一词错误率与第二词错误率之间的差的估计值可能暗示高的第一词错误率。因此,当输出负估计值并且第二模型20基于估计值输出权重时,输入数据确定模型30可以确定(例如,识别)第一语音数据作为要输入到第三模型40的数据。当输出正估计值并且第二模型20基于输出的估计值输出权重时,输入数据确定模型30可以确定(例如,识别)第二语音数据作为要输入到第三模型40的数据。
[0111]
在又一示例中,如果第三模型40被实现为唤醒模型,则处理器130可以在将包括唤醒词的第一语音数据输入到唤醒模型时,获得唤醒模型激活对话系统的第一可能性值。处理器130可以在将包括唤醒词的第二语音数据输入到唤醒模型时,获得唤醒模型激活对话系统的第二可能性值。例如,唤醒词可以是能够激活对话系统的词,该对话系统是提供存储在存储器120中的对用户语音的回答的人工智能模型,并且可以被表达为例如触发词。第一可能性值和第二可能性值可以是唤醒模型识别包括唤醒词的第一语音数据和第二语音数据并输出用于激活对话系统的信号的可能性的数值。
[0112]
处理器130可以通过将各自包括唤醒词的第一语音数据和第二语音数据输入到唤醒模型来获得第一可能性值和第二可能性值。处理器130可以获得第一可能性值和第二可能性值之间的差。处理器130可以通过将第一语音数据和第二语音数据输入到第二模型20来获得第一可能性值和第二可能性值之间的差的估计值。处理器130可以训练第二模型20以输出最佳和/或改进的估计值,以最小化和/或减小下述两者之间的差:1)预先获得的第一可能性值和第二可能性值之间的差;和2)第一可能性值和第二可能性值之间的差的估计值。因此,处理器130可以通过将第一语音数据和第二语音数据输入到训练的第二模型20来获得最佳和/或改进的第一可能性值和第二可能性值之间的差的估计值。
[0113]
作为负值的、第一可能性值和第二可能性值之间的差的估计值可能暗示高的第二可能性值,而作为正值的、第一可能性值和第二可能性值之间的差的估计值可能暗示高的第一可能性值。因此,当输出负估计值并且第二模型20基于估计值输出权重时,输入数据确定模型30可以确定(例如,识别)第一语音数据作为要输入到第三模型40的数据。当输出正估计值并且第二模型20基于估计值输出权重时,输入数据确定模型30可以确定(例如,识别)第二语音数据作为要输入到第三模型40的数据。
[0114]
在又一示例中,如果第三模型40被实现为唤醒模型,则处理器130可以在将不包括唤醒词的第一语音数据输入到唤醒模型时获得用于唤醒模型激活对话系统的第三可能性值。当将不包括唤醒词的第二语音数据输入到唤醒模型时,处理器130可以获得用于唤醒模型激活对话系统的第四可能性值。高的第三可能性值或第四可能性值可能暗示没有关于第
一语音数据或第二语音数据正确执行语音识别,因为第一语音数据和第二语音数据不包括唤醒单词。
[0115]
处理器130可以获得第三可能性值和第四可能性值之间的差。处理器130可以通过将不包括唤醒词的第一语音数据和第二语音数据输入到第二模型20来获得第三可能性值和第四可能性值之间的差的估计值。处理器130可以训练第二模型20以输出最佳和/或改进的估计值,以最小化和/或减小下述两者之间的差:1)预先获得的第三可能性值和第四可能性值之间的差;和2)第三可能性值和第四可能性值之间的差的估计值。因此,当处理器130输入第一语音数据和第二语音数据时,训练的第二模型20可以输出最佳和/或改进的第三可能性值和第四可能性值之间的差的估计值。
[0116]
作为负值的、第三可能性值和第四可能性值之间的差的估计值可能暗示高的第四可能性值,并可能暗示与第二语音数据相比,已经关于第一语音数据正确地执行了语音识别。作为正值的、第三可能性值和第四可能性值之间的差的估计值可能暗示高的第三可能性值,并且可能暗示与第一语音数据相比,已经关于第二语音数据正确地执行了语音识别。因此,当输出负估计值并且第二模型20基于输出的估计值输出权重时,输入数据确定模型30可以确定(例如,识别)第一语音数据作为要输入到第三模型40的数据。当输出正估计值并且第二模型20基于输出的估计值输出权重时,输入数据确定模型30可以确定(例如,识别)第二语音数据作为要输入到第三模型40的数据。
[0117]
例如,如果第三模型40被实现为asr模型或唤醒模型,则处理器130可以基于通过将第一语音数据和第二语音数据输入到第三模型40而获得的结果来训练第二模型20。
[0118]
图3和图4是示出根据本公开的实施例的电子设备100使用获得的权重确定输入数据的示例过程的流程图。
[0119]
图3是示出根据本公开的实施例的示例过程的流程图,在该示例过程中电子设备100通过将权重与阈值进行比较来确定(例如,识别)要输入到第三模型的数据。电子设备100可以基于第一语音数据、第二语音数据和误差的估计值来获得权重(s310)。上面已经参考图1详细描述了获得用于最小化和/或减小对应于第一语音数据的干净语音数据与输入数据之间的均方误差的权重的过程,因此此处不再复述重复的描述。
[0120]
电子设备100可以确定(例如,识别)权重是否大于阈值(s320)。阈值可以是预定值或通过实验得出的值,但这仅是示例,并且阈值可以通过用户命令来改变。
[0121]
当确定(例如,识别)出权重大于阈值时,电子设备100可以确定(例如,识别)第二语音数据作为输入数据(s320
‑
y)。例如,大于阈值的权重意味着误差的估计值小,这可能暗示第二语音数据的可靠性值大。因此,如果权重大于阈值,则电子设备100可以确定(例如,识别)第二语音数据作为要输入到第三模型的输入数据。
[0122]
另一方面,当确定(例如,识别)出权重小于阈值时,电子设备100可以确定(例如,识别)第一语音数据作为输入数据(s320
‑
n)。例如,小于阈值的权重可能暗示误差的估计值大,这可能暗示第二语音数据的可靠性值小。因此,如果权重小于阈值,则电子设备100可以确定(例如,识别)第一语音数据作为要输入到第三模型的输入数据。
[0123]
图4是示出根据本公开的实施例的示例过程的流程图,在该示例过程中电子设备100通过将权重与第一阈值和第二阈值进行比较来确定(例如,识别)要输入到第三模型的数据。电子设备100可以获得用于最小化和/或减小对应于第一语音数据的干净语音数据与
输入数据之间的均方误差的权重(s410)。上面已经参考图1详细描了用于获得权重的实施例,因此此处不再复述重复的描述。
[0124]
电子设备100可以将权重值与第一阈值和第二阈值进行比较(s420)。第一阈值可以是大于第二阈值的预定值。然而,这仅是示例,并且第一阈值和第二阈值可以根据用户命令而改变。
[0125]
如果权重值大于第一阈值,则电子设备100可以确定(例如,识别)第二语音数据作为要输入到第三模型的输入数据(s430
‑
1)。另一方面,如果权重值小于第二阈值,则电子设备100可以确定(例如,识别)第一语音数据作为要输入到第一模型的输入数据(s430
‑
3)。
[0126]
如果权重小于第一阈值并且大于第二阈值,则电子设备100可以基于权重将第一语音数据和第二语音数据线性组合,并且确定(例如,识别)线性组合的值作为要输入到第三模型的输入数据(s430
‑
2)。换言之,除了在权重大于第一阈值或小于第二阈值时之外,电子设备100可以将第一语音数据和第二语音数据线性组合并且确定(例如,识别)线性组合的值作为输入数据。
[0127]
图5是示出根据本公开的实施例的电子设备100的示例配置的框图。参考图5,电子设备100可以包括麦克风110、存储器120、处理器(例如,包括处理电路)130、通信器(例如,包括通信电路)140、显示器150、相机160、输入单元(例如,包括输入电路)170和扬声器180。上面已经参考图1描述了麦克风110、存储器120和处理器130,因此此处不再复述重复的描述。
[0128]
通信器140包括各种通信电路并且可以执行与服务器(未示出)或外部设备(未示出)的通信。例如,处理器130可以向经由通信器140连接的服务器(未示出)或外部设备(未示出)发送或从其接收各种数据或信息。例如,通信器140可以从外部服务器接收存储在存储器120中的各种模型的学习数据。因此,处理器130可以基于经由通信器140接收的学习数据来训练各种模型。
[0129]
通信器140可以包括各种通信模块以执行与外部设备的通信。在示例中,通信器140可以包括各自包括各种通信电路的无线通信模块,并且例如,但不限于,包括蜂窝通信模块,该蜂窝通信模块使用lte、先进lte(lte
‑
a)、码分多址接入(cdma)、宽带cdma(wcdma)、通用移动电信系统(umts)、无线宽带(wibro)、第5代(5g)、全球移动通信系统(gsm)等中的至少一个。在另一示例中,无线通信模块可以例如包括无线保真(wi
‑
fi)、蓝牙、蓝牙低功耗(ble)和zigbee中的至少一个。
[0130]
显示器150可以被实现为例如液晶显示面板(lcd)、有机发光二极管(oled)等,并且在某些情况下也可以被实现为柔性显示器或透明显示器。显示器160可以被实现为具有触摸面板的触摸屏。然而,对上述实施方式没有限制,并且可以根据电子设备100的类型来不同地实现显示器150。
[0131]
相机160可以例如包括用于获得电子设备100的周围环境的一条或多条图像数据的组件。处理器130可以基于由相机160获得的一条或多条图像数据来确定(例如,识别)要输入到特定模型的输入数据。下面将更详细地描述该实施例。相机可以不同地实现为rgb相机、3d相机或深度相机,并且可以位于电子设备100的外部并且电连接到电子设备100。
[0132]
输入单元170可以包括各种输入电路,并且处理器140可以经由输入单元170接收用于控制电子设备100的操作的用户命令。输入单元170可以包括各种输入电路,像例如而
不限于,触摸传感器、(数字)笔传感器、压力传感器、键、麦克风等。触摸传感器可以是例如静电型、压敏型、红外型或超声型中的至少一种。
[0133]
扬声器180可以是除了经受音频处理器(未示出)进行的诸如解码、放大、噪声过滤等各种处理操作的各种音频数据之外还输出各种警报或语音消息的组件。例如,扬声器180可以在处理器130的控制下输出要输入到第三模型的输入数据。另外,扬声器180可以在处理器130的控制下输出通过第三模型输出的结果(例如,与第一语音数据对应的响应消息)。
[0134]
图6是示出根据本公开的实施例的用于控制电子设备100的示例方法的流程图。
[0135]
电子设备100可以通过将经由麦克风110输入的第一语音数据输入到被训练为增强声音质量的第一模型来获得第二语音数据(s610)。第一模型可以是执行用于滤除第一语音数据的噪声等的算法并输出第二语音数据的模型。另外,第一模型可以是基于第一语音数据、第二语音数据和对应于第一语音数据的干净语音数据而训练的神经网络模型。例如,第一模型可以是下述神经网络模型:该模型被训练以在输入第一语音数据时,输出与对应于第一语音数据的干净语音数据相似的第二语音数据。
[0136]
电子设备100可以通过将第一语音数据和第二语音数据输入到第二模型来获得权重(s620)。
[0137]
在本公开的实施例中,电子设备100可以通过将第一语音数据和第二语音数据输入到第二模型来获得第二语音数据和对应于第一语音数据的干净语音数据的均方误差的估计值。已经参考图1、图2a和图2b详细描述了与其相关的公式,因此在此不再复述重复的描述。此外,电子设备100可以基于第一语音数据、第二语音数据以及通过第二模型获得的均方误差的估计值来获得权重。权重可以是用于最小化和/或减小对应于第一语音数据的干净语音数据与要输入到第三模型的输入数据之间的均方误差的值。
[0138]
在本公开的另一实施例中,电子设备100可以通过将第一语音数据和第二语音数据输入到第二模型来获得第一得分和第二得分之间的差的估计值。第一得分和第二得分可以是在将第一语音数据和第二语音数据中的每一个输入到第三模型时获得的数据。例如,如果第三模型是asr模型,则得分可以是语音可靠性值或wer,并且如果第三模型是唤醒模型,则得分可以是用于激活对话系统的可能性值。电子设备100可以通过由第二模型将预定义的映射函数应用于第一得分和第二得分之间的差的估计值来获得权重。
[0139]
电子设备100可以使用获得的权重来确定(例如,识别)要输入到第三模型的输入数据(s630)。在实施例中,电子设备100可以基于权重将第一语音数据和第二语音数据线性组合并且确定(例如,识别)线性组合的值作为输入数据。在另一示例中,如果权重小于阈值,则电子设备100可以确定(例如,识别)第一语音数据作为输入数据,并且如果权重大于阈值,则电子设备100可以确定(例如,识别)第二语音数据作为输入数据。
[0140]
在又一示例中,如果权重大于第二阈值且小于第一阈值,则电子设备100可以基于权重将第一语音数据和第二语音数据线性组合并确定(例如,识别)线性组合的值作为输入数据。如果权重小于第二阈值,则电子设备100可以确定(例如,识别)第一语音数据作为输入数据,并且如果权重大于第一阈值,则电子设备100可以确定(例如,识别)第二语音数据识别作为输入数据。第一阈值可以是大于第二阈值的值。
[0141]
在上文中,已经描述了电子设备100基于第一语音数据和第二语音数据确定(例如,识别)要输入到第三模型的语音数据的实施例,但这仅是示例。例如,在本公开的又一实
施例中,电子设备100可以基于经由相机获得的第一图像数据以及通过将用于增强图像质量的算法应用于第一图像数据而获得的第二图像数据,来确定(例如,识别)要输入到特定模型的输入数据或要显示在显示器上的图像数据。
[0142]
例如,电子设备100可以通过将经由相机输入的第一图像数据输入到被训练为增强图像质量的第一模型来获得第二图像数据。此外,电子设备100可以通过将第一图像数据和第二图像数据输入到第二模型来获得第二图像数据和对应于第一图像数据的干净图像数据之间的均方误差的估计值。干净图像数据可以包括在没有从周围环境接收到影响的干净环境中捕获的图像数据。
[0143]
电子设备100可以基于第一图像数据、第二图像数据和误差的估计值来获得权重。电子设备100可以使用第一图像数据、第二图像数据和权重中的至少一个来确定(例如,识别)要输入到第三模型的输入数据。第三模型可以被实现为图像分类器模型等,但这仅是示例,并且第三模型可以不同地实现为能够编辑图像等的模型。
[0144]
电子设备100可以基于对应于第一图像数据的干净图像数据和第二图像数据来训练第三模型。例如,电子设备100可以获得对应于第一图像数据的干净图像数据和第二图像数据之间的均方误差。此外,电子设备100可以通过将第一图像数据和第二图像数据输入到第二模型来获得第二图像数据和对应于第一图像数据的干净图像数据之间的均方误差的估计值。电子设备100可以训练第二模型以最小化和/或减小下述两者之间的差:1)对应于第一图像数据的干净图像数据和第二图像数据之间的均方误差;和2)均方误差的估计值。
[0145]
本公开的附图并非用于将本公开中公开的技术限制于具体实施例,而是应当将其解释为包括本公开的实施例的所有修改、等同和/或替代。关于附图的解释,相似的附图标记可用于相似的元素。
[0146]
在本公开中,诸如“包括”、“可以包括”、“由
……
组成”或“可以由
……
组成”的术语在本文中用于指定对应特征的存在(例如,构成要素,诸如数字、功能、操作或部分),并且不排除附加特征的存在。
[0147]
在本公开中,诸如“a或b”、“a[和/或]b中的至少一个”或“a[和/或]b中的一个或多个”的表述包括列出项目的所有可能的组合。例如,“a或b”、“a和b中的至少一个”、或“a或b中的至少一个”包括下述各项中的任一个:(1)至少一个a、(2)至少一个b、或(3)至少一个a和至少一个b。
[0148]
本公开中使用的表述“第一”、“第二”等可以表示各种元素,而不管顺序和/或重要性如何,并且可以用于将一个元素与另一个元素区分开,并且不限制这些元素。
[0149]
如果描述特定元素(例如,第一元素)“可操作地或通信地与另一个元素(例如,第二元素)耦合/可操作地或通信地耦合到另一个元素(例如,第二元素)”或“连接到”另一个元素(例如,第二元素),则应当理解,该特定元素可以直接或通过又一个元素(例如,第三元素)连接到该另一个元素。另一方面,如果描述特定元素(例如,第一元素)“直接耦合到”或“直接连接到”另一个元素(例如,第二元素),则可以理解在特定元素和另一个元素之间不存在元素(例如,第三元素)。
[0150]
此外,视情况而定,在本公开中使用的表述“配置为”可以与其他表述互换使用,其他表述例如“适合于”、“具有能力”、“设计为”、“适于”、“制造为”和“能够”。同时,表述“配置为”不一定是指在硬件方面“专门设计为
……”
的设备。而是,在某些情况下,表述“配置为
的
……
设备”可以指该设备“能够”与另一设备或组件一起执行操作。例如,短语“配置(或设置)为执行a、b和c的单元或处理器”可以指例如而不限于用于执行对应操作的处理器的专用处理器(例如,嵌入式处理器)、通用处理器(例如,中央处理单元(cpu)或应用处理器)等,其可以通过执行存储在存储器设备中的一个或多个软件程序来执行对应的操作。
[0151]
根据本公开的实施例的电子设备可以包括例如而不限于智能电话、平板pc、台式pc、膝上型pc、上网本计算机、服务器、pda、医疗设备、可穿戴设备等中的至少一种。在一些实施例中,电子设备可以包括例如而不限于电视机、冰箱、空调、空气净化器、机顶盒、媒体盒(例如,三星homesynctm、apple tvtm或google tvtm)等。
[0152]
本公开的各种实施例可以被实现为包括存储在机器(例如,计算机)可读存储介质中的指令的软件。机器是调用存储在存储介质中的指令并根据调用的指令进行操作的设备,并且可以包括根据所公开的实施例的电子设备(例如,电子设备100)。在指令由处理器执行的情况下,处理器可以直接或在处理器的控制下使用其他元件执行与指令对应的功能。指令可以包括由编译器产生的代码或由解释器可执行的代码。机器可读存储介质可以以非暂时性存储介质的形式提供。这里,“非暂时性存储介质”是有形的并可以不包括信号,并且不区分数据是半永久性还是临时存储在存储介质中。例如,“非暂时性存储介质”可以包括临时存储数据的缓冲器。
[0153]
根据实施例,根据本公开中公开的各种实施例的方法可以被提供以被包括在计算机程序产品中。计算机程序产品可以作为市售产品在卖方和买方之间交换。计算机程序产品可以以机器可读存储介质(例如,光盘只读存储器(cd
‑
rom))的形式分发或通过应用商店(例如playstoretm)在线分发。在在线分发的情况下,至少一部分计算机程序产品(例如,可下载的应用)可以至少临时存储或临时生成在存储介质(例如制造商的服务器的存储器、应用商店的服务器或中继服务器)中。
[0154]
根据上述各种实施例的每个元素(例如,模块或程序)可以包括单个实体或多个实体,并且在各种实施例中上述子元素中的一些子元素可以被省略或其他子元素可以进一步被包括。替代地或附加地,一些元素(例如,模块或程序)可以被集成到一个实体中以执行在集成之前由每个相应元素执行的相同或相似的功能。根据各种实施例,由模块、程序或其他元素执行的操作可以顺序地、并行地、重复地或启发式地执行,或者至少一些操作可以以不同的顺序执行、省略或可以添加不同的操作。
[0155]
虽然已经参考各种示例实施例图示和描述了本公开,但是将理解,各种示例实施例旨在是说明性的而非限制性的。本领域普通技术人员将理解,在不脱离包括所附权利要求及其等同物的本公开的真实精神和全部范围的情况下,可以在形式和细节上进行各种改变。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。