1.本发明涉及人工智能领域,尤其涉及一种未成年人的音频识别方法和系统。
背景技术:
2.随着互联网的快速发展以及智能手机、数码相机等设备大规模普及,互联网上的多媒体数据成指数式增长,极大丰富了人们的娱乐方式。图片,语音,短视频也成为了人们的重要交流手段。随之而来的是未成年人对网络的沉迷成为了近几年社会高度关注的焦点问题。因此如何有效识别未成年人成为了监管未成年人上网的重要技术手段。现有基于音频的主流算法是通过提取音频特征做音频识别。此类算法的缺点之一是需要大量的人工标注未成年人数据,在目前的公司数据不共享和信息安全保护的环境下是难以获取的。另外,未成年人的生理发展因人而异,采集出来的音频在不同年龄段的声音存在明显差异,现有的技术方案无法准确有效识别未成年人音频。
技术实现要素:
3.本发明所要解决的技术问题是针对现有技术的不足,提供一种未成年人的音频识别方法和系统。
4.本发明解决上述技术问题的技术方案如下:
5.一种未成年人的音频识别方法,包括:
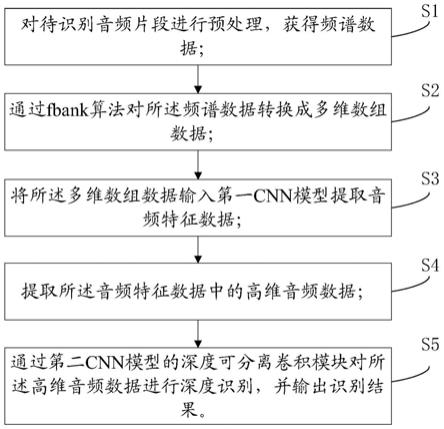
6.s1,对待识别音频片段进行预处理,获得频谱数据;
7.s2,通过fbank算法对所述频谱数据转换成多维数组数据;
8.s3,将所述多维数组数据输入第一cnn模型提取音频特征数据;
9.s4,提取所述音频特征数据中的高维音频数据;
10.s5,通过第二cnn模型的深度可分离卷积模块对所述高维音频数据进行深度识别,并输出识别结果。
11.本发明的有益效果是:本方案通过预处理获得频谱数据,再将频谱数据转换成多维数组数据,有通过第一cnn模型提取音频特征数据,再提取音频特征数据中的高维音频数据,通过第二cnn模型的深度可分离卷积模块对所述高维音频数据进行深度识别,可以有效识别出未成人音频和通过第二 cnn模型的深度可分离卷积模块进行高维音频数据识别大大提升未成年人识别的准确率,识别精度高可以快速应用到相关领域。
12.进一步地,所述s1具体包括:
13.通过预处理算法对待识别音频片段进行加重,分帧和加窗,再通过傅里叶变换将时序特征转换,获得所述频谱数据。
14.进一步地,所述第一cnn模型包括:多个cnn模块;
15.所述s3之前还包括:将多个cnn模块分别进行直接连接和跳跃连接,获得连接后的多个cnn模块,则完成所述第一cnn模型的构建;
16.所述s4具体包括:通过连接后的多个cnn模块将所述音频特征数据的多个位置的
低维特征和声学特征提取出所述高维音频数据。
17.采用上述进一步方案的有益效果是:本方案通过直接连接从上层的模块提取的特征直接输入到下层的模块上,进一步捕获音频的特征;通过跳跃连接关注更早的特征,捕获上下文相关信息。
18.进一步地,所述s5之前还包括:
19.将所述第一cnn模型的多个cnn模块修改为逐通道卷积和逐点卷积的深度可分离卷积模块,完成所述第二cnn模型的构建;
20.所述cnn模块包括:卷积层、归一化层、激活层和池化层;所述卷积层、所述归一化层、所述激活层和所述池化层依次连接;
21.所述深度可分离卷积模块包括:逐通道卷积层、两个归一化层、两个激活层和逐点卷积层;逐通道卷积层、一个所述归一化层、一个所述激活层、逐点卷积层、一个所述归一化层和一个所述激活层依次连接。
22.采用上述进一步方案的有益效果是:本方案通过深度可分离卷积模块,进一步提取到音频的多个上下文相关信息和更加丰富的声学特征和场景信息,最终提升了未成年人识别的准确率。
23.进一步地,所述s5具体包括:
24.通过所述深度可分离卷积模块进行处理;
25.将计算结果输入到所述第二cnn模型的全连接层进行分类;
26.将分类结果通过sigmoid函数计算出所述待识别音频片段属于所述未成年人的概率。
27.采用上述进一步方案的有益效果是:本方案通过所述深度可分离卷积模块进行处理,将多个cnn将音频的多个位置的低维特征和声学特征提取为更抽象的高维信息,最终使用sigmoid函数将高维信息转化为概率并进行评估,实现有效识别未成年人音频。
28.本发明解决上述技术问题的另一种技术方案如下:
29.一种未成年人的音频识别系统,包括:预处理模块、多维转换模块、初步数据提取模块、高维音频数据提取模块和识别模块;
30.所述预处理模块用于对待识别音频片段进行预处理,获得频谱数据;
31.所述多维转换模块用于通过fbank算法对所述频谱数据转换成多维数组数据;
32.所述初步数据提取模块用于将所述多维数组数据输入第一cnn模型提取音频特征数据;
33.所述高维音频数据提取模块用于提取所述音频特征数据中的高维音频数据;
34.所述识别模块用于通过第二cnn模型的深度可分离卷积模块对所述高维音频数据进行深度识别,并输出识别结果。
35.本发明的有益效果是:本方案通过预处理获得频谱数据,再将频谱数据转换成多维数组数据,有通过第一cnn模型提取音频特征数据,再提取音频特征数据中的高维音频数据,通过第二cnn模型的深度可分离卷积模块对所述高维音频数据进行深度识别,可以有效识别出未成人音频和通过第二 cnn模型的深度可分离卷积模块进行高维音频数据识别大大提升未成年人识别的准确率,识别精度高可以快速应用到相关领域。
36.进一步地,所述预处理模块具体用于通过预处理算法对待识别音频片段进行加
重,分帧和加窗,再通过傅里叶变换将时序特征转换,获得所述频谱数据。
37.进一步地,所述第一cnn模型包括:多个cnn模块;
38.还包括:第一cnn模型构建模块用于将多个cnn模块分别进行直接连接和跳跃连接,获得连接后的多个cnn模块,则完成所述第一cnn模型的构建;
39.所述高维音频数据提取模块具体用于通过连接后的多个cnn模块将所述音频特征数据的多个位置的低维特征和声学特征提取出所述高维音频数据。
40.采用上述进一步方案的有益效果是:本方案通过直接连接从上层的模块提取的特征直接输入到下层的模块上,进一步捕获音频的特征;通过跳跃连接关注更早的特征,捕获上下文相关信息。
41.进一步地,还包括:第二cnn模型构建模块,用于将所述第一cnn模型的多个cnn模块修改为逐通道卷积和逐点卷积的深度可分离卷积模块,完成所述第二cnn模型的构建;
42.所述cnn模块包括:卷积层、归一化层、激活层和池化层;所述卷积层、所述归一化层、所述激活层和所述池化层依次连接;
43.所述深度可分离卷积模块包括:逐通道卷积层、两个归一化层、两个激活层和逐点卷积层;逐通道卷积层、一个所述归一化层、一个所述激活层、逐点卷积层、一个所述归一化层和一个所述激活层依次连接。
44.采用上述进一步方案的有益效果是:本方案通过深度可分离卷积模块,进一步提取到音频的多个上下文相关信息和更加丰富的声学特征和场景信息,最终提升了未成年人识别的准确率。
45.进一步地,所述识别模块具体用于通过所述深度可分离卷积模块进行处理;
46.将计算结果输入到所述第二cnn模型的全连接层进行分类;
47.将分类结果通过sigmoid函数计算出所述待识别音频片段属于所述未成年人的概率。
48.采用上述进一步方案的有益效果是:本方案通过所述深度可分离卷积模块进行处理,将多个cnn将音频的多个位置的低维特征和声学特征提取为更抽象的高维信息,最终使用sigmoid函数将高维信息转化为概率并进行评估,实现有效识别未成年人音频。
49.本发明附加的方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明实践了解到。
附图说明
50.图1为本发明的实施例提供的一种未成年人的音频识别方法的流程示意图;
51.图2为本发明的实施例提供的一种未成年人的音频识别系统的结构框架图;
52.图3为本发明的其他实施例提供的多个cnn模块的直接连接和分别连接的示意图;
53.图4为本发明的其他实施例提供的一个cnn模块的结构示意图;
54.图5为本发明的其他实施例提供的一个深度可分离卷积模块的结构示意图。
具体实施方式
55.以下结合附图对本发明的原理和特征进行描述,所举实施例只用于解释本发明,并非用于限定本发明的范围。
56.如图1所示,为本发明实施例提供的一种未成年人的音频识别方法,包括:
57.s1,对待识别音频片段进行预处理,获得频谱数据;
58.在某一实施例中,可以包括:通过预处理算法对待识别音频进行加重、分帧和加窗处理,计算出一个音频片段的频谱图,在通过傅里叶变换将频谱图的时序特征转换成频谱特征。即频谱数据。
59.s2,通过fbank算法对频谱数据转换成多维数组数据;
60.在某一实施例中,可以包括:通过fbank算法将频谱特征转换成高维的计算机能处理的多维数组数据特征。
61.s3,将多维数组数据输入第一cnn模型提取音频特征数据;
62.s4,提取音频特征数据中的高维音频数据;
63.在某一实施例中,可以包括:通过分别进行直接连接和跳跃连接的多个 cnn模块,提取多个位置上的低维特征和声学特征,进一步提取更抽象的高维音频特征。
64.在某一实施例中,构建第一cnn模型可以包括:将多个cnn模块分别进行直接连接和跳跃连接,获得连接后的多个cnn模块,则完成第一cnn 模型的构建;
65.在某一实施例中,如图3所示,多个cnn模块都进行直接连接和跳跃连接。直接连接表示从上层的模块提取的特征直接输入到下层的模块上,进一步捕获音频的特征;而跳跃连接表示关注更早的特征,捕获上下文相关信息。多个cnn模块的直接连接和跳跃连接在建立第一cnn模型的时候就建立好连接,在后续的多次识别都不需要再连接操作。
66.在某一实施例中,第一cnn模型包括多个cnn模块分别进行直接连接和跳跃连接。每个cnn模块,如图4所示,包括卷积层,归一化层,激活层和池化层。所述卷积层、所述归一化层、所述激活层和所述池化层依次连接;从卷积层输入,池化层输出。
67.s5,通过第二cnn模型的深度可分离卷积模块对高维音频数据进行深度识别,并输出识别结果。
68.在某一实施例中,通过深度可分离卷积模块进一步提取到音频的多个上下文相关信息和更加丰富的声学特征和场景信息,再将提取的信息输入到全连接层,接着通过sigmoid函数得到每条音频属于未成年人的概率。音频概率越接近1,说明音频属于未成年人,反之亦然。
69.在某一实施例中,上下文信息可以是一段音频的连续所有相关的音频特征,包括:声学特征和场景信息。而高维音频数据特征可以是声学特征和场景信息的更抽象的表征。
70.在某一实施例中,还包括:将第一cnn模型的多个cnn模块修改为逐通道卷积和逐点卷积的深度可分离卷积模块,完成第二cnn模型的构建;其中一个深度可分离卷积模块,如图5所示,可以包括:逐通道卷积层、归一化层、激活层、逐点卷积层、归一化层和激活层。
71.在某一实施例中,多个cnn模块进行直接连接和跳跃连接,通过多个cnn将音频的多个位置的低维特征和声学特征提取为更抽象的高维信息,最终使用sigmoid函数将高维信息转化为概率并进行评估。
72.本方案通过预处理获得频谱数据,再将频谱数据转换成多维数组数据,有通过第一cnn模型提取音频特征数据,再提取音频特征数据中的高维音频数据,通过第二cnn模型的深度可分离卷积模块对高维音频数据进行深度识别,可以有效识别出未成人音频和通过第二cnn模型的深度可分离卷积模块进行高维音频数据识别大大提升未成年人识别的准确
率,识别精度高可以快速应用到相关领域。
73.优选地,在上述任意实施例中,s1具体包括:
74.通过预处理算法对待识别音频片段进行加重,分帧和加窗,再通过傅里叶变换将时序特征转换,获得频谱数据。
75.在某一实施例中,需要说明的是,通过音频预处理算法对待识别音频进行加重、分帧和加窗处理,计算出一个音频片段的频谱图,在通过傅里叶变换将频谱图的时序特征转换成频谱特征。即频谱数据。其中,音频预处理算法可以是现有可以实现加重、分帧和加窗等处理的算法,可根据实际应用选择,不做具体限制。
76.优选地,在上述任意实施例中,第一cnn模型包括:多个cnn模块;
77.s3之前还包括:将多个cnn模块分别进行直接连接和跳跃连接,获得连接后的多个cnn模块,则完成第一cnn模型的构建;
78.s4具体包括:通过连接后的多个cnn模块将音频特征数据的多个位置的低维特征和声学特征提取出高维音频数据。其中,高维音频数据特征可以是声学特征和场景信息的更抽象的表征。
79.本方案通过直接连接从上层的模块提取的特征直接输入到下层的模块上,进一步捕获音频的特征;通过跳跃连接关注更早的特征,捕获上下文相关信息。
80.优选地,在上述任意实施例中,所述s5之前还包括:
81.将第一cnn模型的多个cnn模块修改为逐通道卷积和逐点卷积的深度可分离卷积模块,完成第二cnn模型的构建;
82.cnn模块包括:卷积层、归一化层、激活层和池化层;所述卷积层、所述归一化层、所述激活层和所述池化层依次连接;
83.深度可分离卷积模块包括:逐通道卷积层、两个归一化层、两个激活层和逐点卷积层;逐通道卷积层、一个所述归一化层、一个所述激活层、逐点卷积层、一个所述归一化层和一个所述激活层依次连接。
84.在某一实施例中,一个深度可分离卷积模块,如图5所示,可以包括:逐通道卷积层、归一化层、激活层、逐点卷积层、归一化层和激活层。
85.本方案通过深度可分离卷积模块,进一步提取到音频的多个上下文相关信息和更加丰富的声学特征和场景信息,最终提升了未成年人识别的准确率。
86.优选地,在上述任意实施例中,s5具体包括:
87.通过深度可分离卷积模块进行处理;
88.将计算结果输入到第二cnn模型的全连接层进行分类;
89.将分类结果通过sigmoid函数计算出待识别音频片段属于未成年人的概率。
90.在某一实施例中,音频概率越接近1,则说明该音频属于未成年人,反之则说明该音频不属于未成年人。
91.本方案通过深度可分离卷积模块进行处理,将多个cnn将音频的多个位置的低维特征和声学特征提取为更抽象的高维信息,最终使用sigmoid函数将高维信息转化为概率并进行评估,实现有效识别未成年人音频。
92.在某一实施例中,如图2所示,一种未成年人的音频识别系统,包括:预处理模块1001、多维转换模块1002、初步数据提取模块1003、高维音频数据提取模块1004和识别模块
1005;
93.预处理模块1001用于对待识别音频片段进行预处理,获得频谱数据;
94.在某一实施例中,可以包括:通过预处理算法对待识别音频进行加重、分帧和加窗处理,计算出一个音频片段的频谱图,在通过傅里叶变换将频谱图的时序特征转换成频谱特征。即频谱数据。
95.多维转换模块1002用于通过fbank算法对频谱数据转换成多维数组数据;
96.在某一实施例中,可以包括:通过fbank算法将频谱特征转换成高维的计算机能处理的多维数组数据特征。
97.初步数据提取模块1003用于将多维数组数据输入第一cnn模型提取音频特征数据;
98.高维音频数据提取模块1004用于提取音频特征数据中的高维音频数据;
99.在某一实施例中,可以包括:通过分别进行直接连接和跳跃连接的多个 cnn模块,提取多个位置上的低维特征和声学特征,进一步提取更抽象的高维音频特征。
100.在某一实施例中,构建第一cnn模型可以包括:将多个cnn模块分别进行直接连接和跳跃连接,获得连接后的多个cnn模块,则完成第一cnn 模型的构建;
101.在某一实施例中,如图3所示,多个cnn模块都进行直接连接和跳跃连接。直接连接表示从上层的模块提取的特征直接输入到下层的模块上,进一步捕获音频的特征;而跳跃连接表示关注更早的特征,捕获上下文相关信息。多个cnn模块的直接连接和跳跃连接在建立第一cnn模型的时候就建立好连接,在后续的多次识别都不需要再连接操作。
102.在某一实施例中,第一cnn模型包括多个cnn模块分别进行直接连接和跳跃连接。每个cnn模块,如图4所示,包括卷积层,归一化层,激活层和池化层。
103.识别模块1005用于通过第二cnn模型的深度可分离卷积模块对高维音频数据进行深度识别,并输出识别结果。
104.在某一实施例中,通过深度可分离卷积模块进一步提取到音频的多个上下文相关信息和更加丰富的声学特征和场景信息,再将提取的信息输入到全连接层,接着通过sigmoid函数得到每条音频属于未成年人的概率。音频概率越接近1,说明音频属于未成年人,反之亦然。
105.在某一实施例中,上下文信息可以是一段音频的连续所有相关的音频特征,包括:声学特征和场景信息。而高维音频数据特征可以是声学特征和场景信息的更抽象的表征。
106.在某一实施例中,还包括:将第一cnn模型的多个cnn模块修改为逐通道卷积和逐点卷积的深度可分离卷积模块,完成第二cnn模型的构建;其中一个深度可分离卷积模块,如图5所示,可以包括:逐通道卷积层、归一化层、激活层、逐点卷积层、归一化层和激活层。
107.在某一实施例中,多个cnn模块进行直接连接和跳跃连接,通过多个 cnn将音频的多个位置的低维特征和声学特征提取为更抽象的高维信息,最终使用sigmoid函数将高维信息转化为概率并进行评估。
108.本方案通过预处理获得频谱数据,再将频谱数据转换成多维数组数据,有通过第一cnn模型提取音频特征数据,再提取音频特征数据中的高维音频数据,通过第二cnn模型的深度可分离卷积模块对高维音频数据进行深度识别,可以有效识别出未成人音频和通过第二cnn模型的深度可分离卷积模块进行高维音频数据识别大大提升未成年人识别的准确
率,识别精度高可以快速应用到相关领域。
109.优选地,在上述任意实施例中,预处理模块1001具体用于通过预处理算法对待识别音频片段进行加重,分帧和加窗,再通过傅里叶变换将时序特征转换,获得频谱数据。
110.在某一实施例中,需要说明的是,通过音频预处理算法对待识别音频进行加重、分帧和加窗处理,计算出一个音频片段的频谱图,在通过傅里叶变换将频谱图的时序特征转换成频谱特征。即频谱数据。其中,音频预处理算法可以是现有可以实现加重、分帧和加窗等处理的算法,可根据实际应用选择,不做具体限制。
111.优选地,在上述任意实施例中,第一cnn模型包括:多个cnn模块;
112.还包括:第一cnn模型构建模块用于将多个cnn模块分别进行直接连接和跳跃连接,获得连接后的多个cnn模块,则完成第一cnn模型的构建;
113.高维音频数据提取模块具体用于通过连接后的多个cnn模块将音频特征数据的多个位置的低维特征和声学特征提取出高维音频数据。其中,高维音频数据特征可以是声学特征和场景信息的更抽象的表征。
114.本方案通过直接连接从上层的模块提取的特征直接输入到下层的模块上,进一步捕获音频的特征;通过跳跃连接关注更早的特征,捕获上下文相关信息。
115.优选地,在上述任意实施例中,还包括:第二cnn模型构建模块,用于将第一cnn模型的多个cnn模块修改为逐通道卷积和逐点卷积的深度可分离卷积模块,完成第二cnn模型的构建;
116.cnn模块包括:卷积层、归一化层、激活层和池化层;所述卷积层、所述归一化层、所述激活层和所述池化层依次连接;
117.深度可分离卷积模块包括:逐通道卷积层、两个归一化层、两个激活层和逐点卷积层;逐通道卷积层、一个所述归一化层、一个所述激活层、逐点卷积层、一个所述归一化层和一个所述激活层依次连接。
118.在某一实施例中,一个深度可分离卷积模块,如图5所示,可以包括:逐通道卷积层、归一化层、激活层、逐点卷积层、归一化层和激活层。
119.本方案通过深度可分离卷积模块,进一步提取到音频的多个上下文相关信息和更加丰富的声学特征和场景信息,最终提升了未成年人识别的准确率。
120.优选地,在上述任意实施例中,识别模块1005具体用于通过深度可分离卷积模块进行处理;
121.将计算结果输入到第二cnn模型的全连接层进行分类;
122.将分类结果通过sigmoid函数计算出待识别音频片段属于未成年人的概率。
123.在某一实施例中,音频概率越接近1,则说明该音频属于未成年人,反之则说明该音频不属于未成年人。
124.本方案通过深度可分离卷积模块进行处理,将多个cnn将音频的多个位置的低维特征和声学特征提取为更抽象的高维信息,最终使用sigmoid函数将高维信息转化为概率并进行评估,实现有效识别未成年人音频。
125.可以理解,在一些实施例中,可以包含如上述各实施例中的部分或全部可选实施方式。
126.需要说明的是,上述各实施例是与在先方法实施例对应的产品实施例,对于产品
实施例中各可选实施方式的说明可以参考上述各方法实施例中的对应说明,在此不再赘述。
127.读者应理解,在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
128.在本技术所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。
129.作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本发明实施例方案的目的。
130.另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以是两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
131.集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分,或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom, read
‑
onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
132.以上,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。