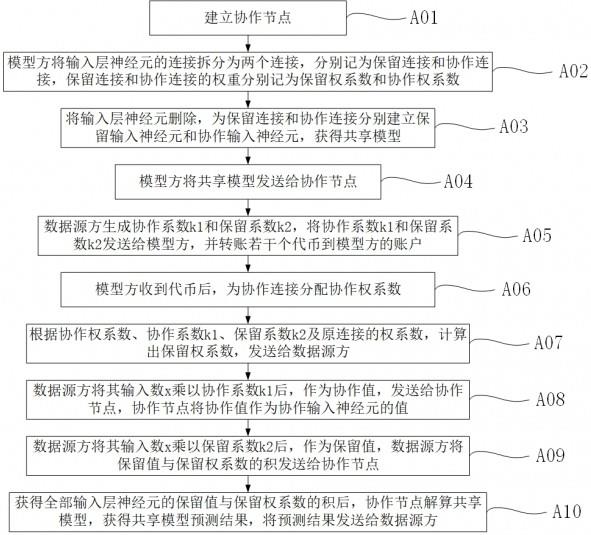
1.本发明涉及大规模集成电路技术领域,尤其涉及自适应的可重构处理阵列与主控交互方法及装置。
背景技术:
2.本部分旨在为权利要求书中陈述的本发明实施例提供背景或上下文。此处的描述不因为包括在本部分中就承认是现有技术。
3.协处理器接口模块是主控和可重构处理阵列交互的桥梁,协处理器接口除了可以读写可重构处理阵列上的共享全局寄存器之外,还有10个面向可重构处理阵列功能控制的全局寄存器,这10个寄存器对可重构处理阵列中的处理单元不可见。协处理器接口模块通过解析这10个寄存器的数值,生成使能信号,对可重构处理阵列计算、数据搬运、配置搬运等任务进行控制。
4.在增加控制型处理单元之前,这些面向控制的特殊全局寄存器的数值是由主控负责写入的。主控每次向一个全局寄存器写入数值都会浪费大量的时钟周期,而每发起一次可重构处理阵列启动任务或者发起一次数据搬运任务,会向多个特殊全局寄存器写值。当一个应用在执行的时候,这些任务会迭代多次,所以产生的时间开销将会呈现数量级的增长。
技术实现要素:
5.本发明实施例提供一种自适应的可重构处理阵列与主控交互方法,该方法包括:
6.在可重构处理阵列上增加一个控制型处理单元,用来代替主控对协处理器接口中的全局寄存器gr的读写,实现数据的搬运和阵列的执行。
7.本发明实施例还提供一种自适应的可重构处理阵列与主控交互装置,该装置包括:控制型处理单元,设置在可重构处理阵列上,用来代替主控对协处理器接口中的全局寄存器gr的读写,实现数据的搬运和阵列的执行。
8.本发明实施例中,与现有技术中对可重构处理阵列计算、数据搬运、配置搬运等任务进行控制全部由主控来完成的技术方案相比,通过在可重构处理阵列上设置控制型处理单元,用来代替主控对协处理器接口中的全局寄存器gr的读写,实现数据的搬运和阵列的执行。可以大大降低阵列与主控的耦合度,缩短应用的执行时间,极大地提高计算能力和计算性能,满足应用计算性能的需求,针对数据密集型和计算密集型应用,很适合应用到硬件加速设计。
附图说明
9.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以
根据这些附图获得其他的附图。在附图中:
10.图1为可重构处理器块rpu(reconfigurable processor unit)的架构图;
11.图2为搬运配置的任务执行前主控所需的操作流程示意图;
12.图3为在向share memory搬运数据之前,主控需要做的操作流程示意图;
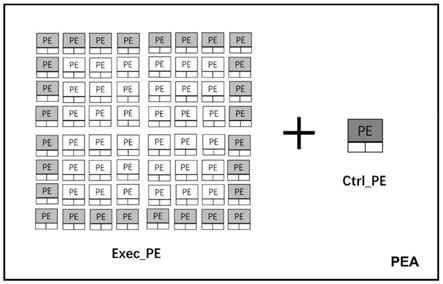
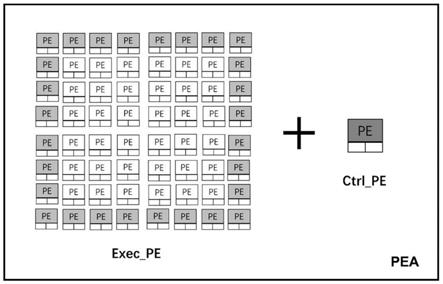
13.图4为本发明实施例中自适应的可重构处理阵列与主控交互装置架构图,即增加控制型pe后可重构阵列架构图;
14.图5为本发明实施例中控制型pe架构图;
15.图6为本发明实施例中控制型pe配置信息格式示意图;
16.图7为原版512点fft的执行过程示意图;
17.图8为本发明实施例中新版512点fft执行过程示意图;
18.图9为本发明实施例中控制型pe执行的配置信息示意图。
具体实施方式
19.为使本发明实施例的目的、技术方案和优点更加清楚明白,下面结合附图对本发明实施例做进一步详细说明。在此,本发明的示意性实施例及其说明用于解释本发明,但并不作为对本发明的限定。
20.图1为可重构处理器块rpu(reconfigurable processor unit)的架构图,如图1所示为可重构处理器块rpu(reconfigurable processor unit)的架构图。一个rpu有四个pea(processing elemment array,处理单元阵列)。主控riscv(riscv处理器)通过协处理器接口与pea做交互。data cache(数据cache)存放的是数据,通过ahb总线将数据发送到pea阵列上的共享存储模块(share memory)。context cache存放的是配置信息,通过ahb总线(cache和pea阵列的桥梁)以及pea阵列上的配置控制模块(config_control),将配置信息分发到pea阵列上的每一个处理单元中(processing element)中。gr:全局寄存器。pe:processing element,处理单元。cm:context memory,配置信息存储器,存放pe的配置信息。
21.存放pea功能控制的全局寄存器gr(global register)位于协处理器接口(corprocessor interface)中。其中gr32存放启动控制信号,gr35存放数据在cache中的基地址,gr36存放从cache中搬运的数据的长度,gr33存放配置信息在cache中的基地址,gr34存放从cache中搬运的配置信息长度,gr37存放读写share memory的基地址,gr39存放数据搬运完成、配置搬运完成、pea计算完成的finish信号。
22.如图2所示,是搬运配置的任务执行前主控所需的操作。主控需要通过协处理器接口向gr33写入配置信息在cache的基地址,向gr34写入搬运的配置信息的长度,向gr32写入启动配置信息搬运的使能信号。写完这些全局寄存器后,启动配置信息的搬运。
23.如图3所示,是在向share memory搬运数据之前,主控需要做的操作。主控需要通过协处理器接口向gr35写入数据在cache的基地址,向gr36写入搬运的数据的长度,向gr37写入读写share memory的基地址,向gr32写入启动数据搬运的使能信号。写完这些全局寄存器后,启动数据的搬运。
24.主控每次向gr写入数据的时候都将花费数千个时钟周期,而一次任务又需要写多个gr。由此可见,执行一次任务所花费的时间开销是巨大的。
25.由于上述问题,本发明为了降低阵列与主控的耦合度,如图4所示,在pea(processing elemment array,处理单元阵列)阵列上增加一个控制型pe(ctrl_pe),用来代替主控对gr的读写,自动计算地址偏移以及搬运长度等信息,进而控制各种任务的执行(exec_pe)。
26.图5为控制型pe的架构图,配置信息存储模块(config_memory)最多存储16条配置信息,本地寄存器(local_regfile)可存放8个数据。控制型pe支持读配置(control)、译码(decode)、执行(execute)、写回(writeback)四级流水。其中执行(execute)模块包括加、减、与、或、非、异或、相等、移位等常见运算用来支持灵活的地址跳转模式。还包括为控制阵列执行的特殊运算“等待”运算。“等待”运算通过不停地读取gr39中的信号,检测数据搬运、阵列计算等任务是否执行完毕。
27.图6所示为控制型pe的配置信息格式,有两个输入input1和input2,均支持多种数据来源。input1可以访问协处理器接口的gr,上一次的运算结果,以及本地寄存器。input2可以访问pea阵列共享寄存器,上一次的运算结果,以及本地寄存器。而且当imm立即数使能字段置1时,input2字段为立即数,参与运算。输出out1也支持多种输出去向,包括协处理器接口寄存器,pea阵列共享寄存器以及本地寄存器。控制型pe支持迭代、停顿,用以支持灵活复杂的控制功能。
28.本发明技术通过在原有pea阵列基础上增加了一个控制型pe,代替主控完成数据搬运、阵列启动等任务,大大降低了阵列与主控的耦合度,缩短了应用的执行时间,极大地提高了计算能力和计算性能,满足应用计算性能的需求,针对数据密集型和计算密集型应用,很适合应用到硬件加速设计。
29.下面通过实例对本发明提出的自适应的可重构处理阵列与主控交互方法及装置进行分析。
30.如图7所示是一个512点fft的执行过程,也是未增加控制型pe时的执行方式。由图中可以看到fft每层迭代都需要由主控控制数据的搬运和阵列的执行,会产生巨大的时间开销。9层fft的执行时间一共是35.8万ns。
31.如图8所示,是增加控制型pe后512点fft的执行过程。相比原版,除了预先在协处理器接口的gr预存了计算所需的数据外,整个执行过程得到了大幅度精简。在搬运完配置,写完全局寄存器之后,主控只需使能控制型pe,便可以由控制型pe控制完成9层fft的迭代,而不需要像之前那样频繁由主控来负责每层数据的搬运和迭代计算的启动,减小了主控和pea阵列的耦合度。控制型pe靠如图9所示的配置信息完成了每层数据的搬运和迭代计算的启动。512点fft的运行时间为1.56万ns,相比之前版本,运算时间缩短了95.648%。
32.本发明实施例中还提供了一种自适应的可重构处理阵列与主控交互方法,如下面的实施例所述。由于该方法解决问题的原理与自适应的可重构处理阵列与主控交互装置相似,因此该装置的实施可以参见自适应的可重构处理阵列与主控交互装置的实施,重复之处不再赘述。
33.该自适应的可重构处理阵列与主控交互方法包括:
34.在可重构处理阵列上增加一个控制型处理单元,用来代替主控对协处理器接口中的全局寄存器gr的读写,实现数据的搬运和阵列的执行。
35.在本发明实施例中,所述控制型处理单元包括配置信息存储模块、本地寄存器、配
置模块、译码模块、执行模块和写回模块;
36.其中,配置信息存储模块用于存储配置信息;
37.本地寄存器用于存放数据;
38.配置模块、译码模块、执行模块和写回模块用于实现读配置、译码、执行、写回四级流水。
39.在本发明实施例中,所述执行模块还用于实现等待运算,其中等待运算通过读取全局寄存器gr39中的finish信号,检测数据搬运、阵列计算等任务是否执行完毕。
40.在本发明实施例中,所述控制型处理单元按照如下方式配置信息格式:
41.信息格式包括两个输入input1和input2,支持多种数据来源;
42.其中,输入input1访问协处理器接口的全局寄存器gr、上一次的运算结果以及本地寄存器;
43.输入input2访问可重构处理阵列pea上的共享寄存器、上一次的运算结果以及本地寄存器;
44.包括立即数使能字段,当立即数使能字段置1时,输入input2字段为立即数,参与运算。
45.在本发明实施例中,所述控制型处理单元按照如下方式配置信息格式:
46.信息格式包括输出out1,支持多种输出去向,包括协处理器接口中的全局寄存器,可重构处理阵列pea阵列上的共享寄存器以及本地寄存器。
47.本发明实施例中,与现有技术中对可重构处理阵列计算、数据搬运、配置搬运等任务进行控制全部由主控来完成的技术方案相比,通过在可重构处理阵列上设置控制型处理单元,用来代替主控对协处理器接口中的全局寄存器gr的读写,实现数据的搬运和阵列的执行。可以大大降低阵列与主控的耦合度,缩短应用的执行时间,极大地提高计算能力和计算性能,满足应用计算性能的需求,针对数据密集型和计算密集型应用,很适合应用到硬件加速设计。
48.本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd
‑
rom、光学存储器等)上实施的计算机程序产品的形式。
49.本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
50.这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
51.这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
52.以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。