识别带口音的语音
1.分案说明
2.本技术属于申请日为2014年1月24日的中国发明专利申请201480013019.8的分案申请。
背景技术:
3.在识别带口音说出时的语音方面,当前的语音识别技术是相当差的。为了解决这一问题,一个部分解决方案跟踪由用户响应于当前技术未能正确地识别词语所做出的校正。这一部分解决方案可能对于带口音的用户来说是令人沮丧的,因为在这些当前技术改善它们的识别之前,用户往往必须校正许多未正确识别的词语,往往如此多次以至于用户完全放弃声音识别。即使对于那些花时间和经得起挫折的用户,当该用户带有口音时,当前的许多技术仍然未充分地识别用户的语音。
4.用于解决这一问题的另一部分解决方案要求用户去向专用用户接口并且说出特定词语的列表。要求带口音的用户找到这一专用用户接口并且说出词语列表无法提供优越的用户体验,并且因而往往将根本不会被用户执行。进一步地,要求来自用户的这一努力无法使得当前技术能够足够好地识别口音。再进一步地,即使拥有设备的用户向这方面努力,也不太可能由借用所有者的设备的另一用户来执行,诸如当设备的所有者在开车并且乘客使用所有者的设备时。
附图说明
5.参照附图描述用于识别带口音的语音的技术和装置。贯穿附图,相同的数字用于引用同样的特征和部件:
6.图1图示其中可以实现用于识别带口音的语音的技术的示例环境。
7.图2图示图1的示例语言和口音库。
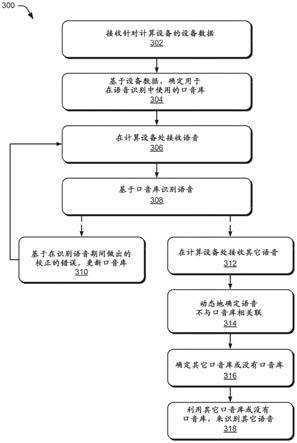
8.图3图示用于使用基于设备数据确定的口音库来识别带口音的语音的示例方法。
9.图4图示用于更改口音库以更准确地识别带口音的语音的示例方法。
10.图5图示用于在基于应用字段的语音识别水平下识别语音的示例方法,其可以使用口音库。
11.图6图示具有应用字段的示例应用。
12.图7图示其可以实现用于识别带口音的语音的技术的示例装置的各种部件。
具体实施方式
13.在识别带口音说出时的语音方面,用于识别带口音的语音的当前技术往往是相当差的。本公开描述用于使用口音库来识别带口音的语音的技术和装置,并且在一些实施例中,使用基于应用字段的不同语音识别校正水平,识别的词语被设置为提供到该应用字段中。
14.以下讨论首先描述操作环境,其后是可以在这一环境中采用的技术、具有应用字
段的示例应用、并且继续进行到示例装置。
15.图1图示其中可以实现用于识别带口音的语音的技术的示例环境100。示例环境100包括计算设备102,计算设备102具有一个或多个处理器104、计算机可读存储介质(存储介质)106、显示器108和输入机制110。
16.计算设备102被示出为具有集成麦克风112作为输入机制110的一个示例的智能电话。然而,可以使用各种类型的计算设备和输入机制,诸如具有分立独立麦克风的个人计算机、连接到具有麦克风的微微网(例如,bluetooth
tm
)耳机的蜂窝电话、或者具有集成立体声麦克风的平板和膝上型计算机(仅举几例)。
17.计算机可读存储介质106包括口音模块114、设备数据116、挖掘数据118和应用120。口音模块114包括语言库122和一个或多个口音库124。口音模块114可以在有语音识别引擎(未示出)的情况下操作、在无语音识别引擎的情况下操作、包括语音识别引擎、与语音识别引擎集成、和/或补充语音识别引擎。口音模块114能够识别带口音的语音,诸如通过基于设备数据116确定与语言库122结合用于识别语音的口音库124中的口音库。
18.语言库122与语言或其方言相关联,诸如澳大利亚英语、美国(us)英语、英国(皇家)英语等。语言库122和已知的语音识别引擎可以操作为执行已知的语音识别,虽然不要求使用任一者或两者。因而,在一些实施例中,口音模块114使用口音库124之一来补充使用已知类型的语言库122的已知语音识别引擎。
19.通过示例的方式,考虑图2,其图示图1的示例语言库122和口音库124。这里示出两个示例语言库:澳大利亚英语204和us英语206。与这些语言库204和206中的每个相关联的分别是众多口音库208和210。
20.口音库208包括八个示例(虽然本技术设想更多),包括澳大利亚(au)英语
‑
国语208
‑
1、au英语
‑
新南(n.s.)威尔士208
‑
2、au英语
‑
新西兰(nz)奥克兰208
‑
3、au英语
‑
na克赖斯特彻奇208
‑
4、au英语
‑
水肺
‑
潜水员208
‑
5、au英语
‑
内陆208
‑
6、au英语
‑
佩斯208
‑
7和au英语
‑
印度尼西亚208
‑
8。如从名字清楚的,这些口音库中的每个口音库与大的语言组(澳大利亚英语)和该语言组内存在的口音相关联,无论其是最近说国语的移民还是参与水肺潜水的人。
21.相似地,口音库210包括八个示例:us英语
‑
国语210
‑
1、us英语
‑
粤语210
‑
2、us英语
‑
波士顿210
‑
3、us英语
‑
冲浪者210
‑
4、us英语
‑
听力障碍210
‑
5、us英语
‑
农村210
‑
6、us英语
‑
南部210
‑
7和us英语
‑
阿拉斯加210
‑
8。注意,国语口音库208
‑
1和210
‑
1可以不同,因为每个与不同语言库相关联。然而,无论以澳大利亚方言或us方言说出英语,由于说国语者的共同品质,在口音库之间可能存在一些共同元素。注意,这些口音库在数目和处理的口音方面几乎是无限的。地区口音,小的移民群体或大的移民群体、兴趣和亚文化、以及甚至共同的物理特性所共有的口音,诸如听力障碍的人在口音方面具有一些共性。
22.在图2的示例中,口音库124中的每个包含用于由语言库122使用的补充信息和算法。这里语言库122用于大语言组(例如,对于更大数目的人,其具有更多的、平均值或中值),其由口音库124中的一个或多个来补充。尽管图2的这一示例使口音库与语言库相关联,但是口音模块114可以放弃使用语言库或已知的语音识别引擎。代之,口音模块114可以提供其自己的算法和引擎,而不使用其它引擎或库,代之依靠口音库124而非语言库122,但是包括对于识别大量人的语音有用的算法或信息。
23.口音模块114可以基于设备数据116和/或挖掘数据118(图1的两者)来确定口音库124中的哪个要用于识别带口音的语音。设备数据116可以包括设备个人数据126以及特定于计算设备102的数据。特定于计算设备102的数据可以包括计算设备102的制造或购买日期(例如,最近发布的移动电话或平板)以及诸如制造商、硬件能力等之类的关于计算设备102的信息。
24.设备个人数据126包括基于用户与计算设备102的交互所创建或确定的数据,诸如联系人的姓名、安装的应用、消息的接收国家或地区、用户的姓名、联系信息、非标准键盘(例如,针对除了计算设备102针对其设置的语言之外的特定语言)、以及上下文应用信息(例如,搜索项)。因而,联系人的姓名可以指示用户的原籍国,或者非标准类型的键盘可以指示除了针对计算设备设置的语言之外的语言是用户的母语。进一步地,消息的接收国家或地区可以包括其中针对计算设备设置的语言不是说得最多的语言的国家中的地址,例如,在设置澳大利亚英语情况下(诸如,图2所示的在澳大利亚英语204和au英语
‑
印度尼西亚208
‑
8的情况下)为印度尼西亚的接收国家。
25.更详细地,用户的联系方式中的电子邮件或地址可以指示用户的国籍或种族本源(例如,斯拉夫人的名或姓)。地址可以指示用户的出生位置或当前位置、以及关于用户的可以用于确定针对用户的口音库124的其它细节。电子邮件地址行中的名称或者那些电子邮件中的正文可以指示用户的朋友的国籍、出身、亚文化、或者用户的业务、或者用户的兴趣。如下面进一步指出的,这些兴趣可以指示口音,诸如用户在冲浪、水肺潜水或烹饪方面的兴趣。一些词语以及如何说出这些词语可以依赖于这些兴趣、并且因而亚文化。
26.例如,参与水肺潜水的人可以使用术语“换气器”和“气压伤”,如果没有与水肺潜水相关联的口音库,这些术语可能不能正确识别。相似地,参与冲浪的人可以使用术语“高飞脚(goofy foot)”、“回冲浪峰”或者“一道浪整个同时踏掉(closed out)”,它们也可能未从用户的语音正确识别。最后,对于烹调爱好者,“la creuset”、“烧烤”和“炖”可能在无当前技术的情况下未正确识别。
27.设备个人数据126还可以包括在确定口音且因而口音库中有用的其它信息,诸如用户的电子书库中的斯拉夫语言的书、斯拉夫语言的新闻文章、关于波兰的文章和书、保存的波兰华沙的天气频道、关于在爱沙尼亚钓鱼的信息、针对手风琴音乐的web搜索条目、在用户的音乐库中的波尔卡音乐等。
28.挖掘数据118也可以或代之由口音模块114用于确定口音库124中的哪个要用于识别语音。挖掘数据118包括挖掘个人数据128,其可以包括可以通过因特网或其他方式找到的关于计算设备102的用户的任何个人数据。因而,挖掘个人数据128可以包括用户的搜索项、所购物、位置、人口统计特征、收入等。
29.如指出的,计算机可读存储介质106还包括应用120,诸如全部图1的电子邮件应用130、社交网络应用132或电子表格应用134。应用120中的每个应用包括一个或多个应用字段136,其在一些实施例中用于确定语音识别校正水平。通过示例的方式,考虑电子表格应用134。这里仅数字单元格138和一般文本单元格140均是应用字段136的示例。仅数字单元格138可以要求比一般文本单元格140更精确的文本、并且因而不同的语音识别校正水平。
30.图3图示用于使用基于设备数据确定的口音库来识别带口音的语音的示例方法300。描述这些和其它方法的块的顺序并不旨在被解释为限制,并且任何数目或组合的本文
和“closet”的其它可能选项,将被认为是用于当前语音识别引擎的低概率选项。这里口音库us英语
‑
冲浪者210
‑
4添加词语、改变词语和短语的概率、并且更改算法,以改变如何解译某些声音(例如,冲浪者具有不同的语音模式,这是口音的一部分,不只是使用的词语)。
39.替代地或附加地,方法300继续进行到块310和/或块312
‑
318。在块310处,基于在识别语音期间做出的校正的错误,更新口音库。块310可以与如下面描述的方法400结合或分立地工作。在上面的示例方法300中,校正识别了molly的语音。如果不正确,通过用户(molly chin)的校正可以被记录并且用于更新口音库。
40.在块312处,在计算设备接收其它语音,接收的该其它语音来自与在302处接收的语音不同的说话者。通过示例的方式,假设molly将她的智能电话递给了她父亲,因为她在开车。假设molly要她父亲请求好的泰国餐厅。还假设她父亲是以国语为母语者,并且英语是他的第二语言。进一步地,假设像许多以国语为母语者那样,molly的父亲使用音调来区分词语,而说英语者使用语调(句子中的音高模式)。进一步地,假设molly的父亲像许多说国语者那样具有在音节的结尾发“i”音的问题。因而,molly的父亲将“why”发音为“wiw”、将“fly”发音为“flew”、并且将“pie”发音为“piw”。因而,当molly的父亲通过讲出“find thai restaurant”来要智能电话找到泰国餐厅时,但是由于他的口音,对于以us英语为母语者(或者仅使用us英语库的语音识别引擎)来说,其听起来像“find tew restaurant”。
41.在块314处,另一语音被动态确定为不与块304处确定的口音库相关联。口音模块114在接收语音“find tew restaurant”时实时地确定说话者不是molly并且因而口音库us英语
‑
冲浪者210
‑
4不适用。口音模块114可以基于“tew”或其它指示符来确定这点,诸如词语“restaurant”内的音调变化,其是说国语者和说粤语者两者所共有的,或者简单地从molly接收的语音历史指示不是molly。这可以以众多方式来执行,诸如molly具有通常高音高声音并且molly的父亲不具有这一高音高、molly和molly的父亲之间的说话速度差异等。
42.在块316处,另一口音库或者没有口音库被确定用于该另一语音。继续这一示例,假设口音模块114基于词语“restaurant”内的音调变化确定molly的父亲是以国语为母语者或者以粤语为母语者。进一步地,假设口音模块114确定molly的个人数据指示她有与其中国语是主导语言的中国地区(例如,北京)(而不是与粤语相关联的地区(例如,香港))更加密切相关联的朋友和地址。如上面指出的,这一信息可能已经在块304处确定。
43.在块318处,在另一口音库或没有口音库(如上面确定的)的情况下识别另一语音。结束进行中的示例,通过使用图2的口音库us英语
‑
国语210
‑
1,口音模块114将molly的父亲的语音“find tew restaurant”识别为“find thai restaurant”,而不是将这一语音不正确地识别为“find two restaurants”。
44.图4图示用于更改口音库以更准确地识别带口音的语音的示例方法400。
45.在块402处,接收对语音元素的校正。这一校正校正使用口音库未正确识别的语音元素。校正可以从远程计算设备接收,虽然这不是要求的。如块310中指出的,使用口音库的语音识别可能是不正确的,并且然后由用户进行校正。与口音库相关联的一个或多个校正可以诸如从数以千计的远程计算设备(例如,智能电话、膝上型计算机、平板计算机、台式计算机等)接收。计算设备可以是图1的计算设备102,但是在这一实施例中是与计算设备102远程的服务器计算机,并且在该处校正被记录并且口音库124被更新以改善识别。
46.在块404处,口音库被更改以提供更新的口音库,更新的口音库能够更准确地识别
语音元素。为了说明使用上面的示例之一,假设口音库us英语
‑
国语210
‑
1将molly的父亲的语音不正确地识别为“find the restaurant”而非“find thai restaurant”。还假设molly的父亲将不正确的识别校正为“thai”。这一校正以及相同口音库的像它那样的许多其它校正可以被发送到更新实体并且由更新实体接收。更新实体可以是计算设备102上的口音模块114,或者服务器计算机上的另一口音模块或其它实体。
47.在块406处,更新的口音库被提供到一个或多个远程计算设备,以有效使得一个或多个远程计算设备能够更准确地识别语音元素。因而,使用更新的口音库,语音元素“tew”将更有可能被正确地识别为“thai”而非“the”。
48.此外,还可以从一个或多个远程计算设备接收设备数据,该设备数据与远程计算设备的用户相关联,并且基于该设备数据来确定口音库以用于来自用户的语音的语音识别。因而,可以提供关于molly的用于对口音库us英语
‑
冲浪者210
‑
4进行校正的信息或者关于molly的父亲的用于对口音库us英语
‑
国语210
‑
1进行校正的信息。
49.然后可以为某些设备数据或其它数据定制对适当的口音库的更新。实际上,随着时间的推移这可以动作以提供口音库的子类别。因而,诸如与molly chin具有相似性的人之类的说话者可以基于她在年龄(18
‑
30)和地区(南加州)方面的相似性,接收us英语
‑
冲浪者210
‑
4的更新,而使用us英语
‑
冲浪者210
‑
4的另一说话者将不会接收,诸如生活在不同地区(佛罗里达州迈阿密)的男性(年龄45
‑
60)。通过这样做,可以基于用户或他们的计算设备是否具有一个或多个与从其接收校正的远程计算设备的设备或挖掘数据相同的设备或挖掘数据的元素,向用户提供更新。
50.图5图示用于在基于应用字段的语音识别水平下识别语音的示例方法500,其可以使用口音库。
51.在块502处,在计算设备接收语音。这可以如上面各种示例中阐述的那样。
52.在块504处,基于识别的文本被设置为要提供到的应用字段,确定语音识别校正水平。这个的一个示例可以是图1的示例应用字段136,即电子表格应用134的仅数字单元格138和一般文本单元格140。如上面指出的,口音模块114可以基于应用字段来确定语音识别校正水平,诸如它可能需要高度准确的语音识别或者较不准确和/或更快的识别。
53.通过示例的方式,考虑图6,其图示具有应用字段604和606的示例电子邮件应用的用户界面602。应用字段604是地址字段,并且应用字段606是主体字段。例如假设来自上面示例的molly chin讲出“surf girl seven seven seven at gee mail dot com”。
54.当打开要发送给朋友的新电子邮件时,假设电子邮件应用将首先将识别的文本接收到应用字段604处示出的电子邮件地址字段中。当说话时,并且在电子邮件地址完成之后,假设电子邮件应用将会将识别的文本接收到应用字段606处的电子邮件的主体中。在这一示例中,口音模块114确定最大校正水平应该用于地址字段。在这种情况下,口音模块114使用适当的口音库124或者做出改善准确性的其它细化。然而,改善准确性可能以识别文本的时间和计算资源(处理器和电池)方面为代价(仅举几例)。因此,更高的语音校正水平可能并不总是适当的。
55.例如,还要注意,通过确定使用零个、一个、或多个口音库114(诸如国语和冲浪者口音库两者),口音模块114可以应用不同的校正水平。进一步地,口音模块114可以确定不使用或缺乏使用口音库124的校正水平。例如,口音模块114可以使用不同的语言库122以用
于一些应用字段,或者使用指向说出的数字而不是正常语音中的口音的口音库124。因而,语言库122之一可以指向识别其是数字或针对地址的语音,并且另一语言库122指向识别其是对话的语音。在本文中阐述的这些和其它方式中,技术可以动作以改善语音识别。
56.在块506处,在语音识别校正水平下识别接收的语音,以产生识别的文本。因而,对于应用字段604(电子邮件地址字段),使用指向预期语音的一个或多个口音库124和/或替代语言库122,口音模块114在确定的语音识别水平下识别语音,这里在最大水平下。
57.在块508处,识别的词语和其它文本被提供到应用字段。结束进行中的针对molly chin的示例,在块508处,口音模块114不是将语音“surf girl seven seven seven at gee mail dot com”识别为词语,而是基于口音库124和/或语言库122识别为词语和文本的组合,并且还因为它是电子邮件的地址字段,“at”被识别为“@”符号。因而,语音被识别为“surfgirl777@gmail.com”。
58.尽管不要求,在一些实施例中,当应用字段是电子邮件、博客、社交联网入口、或文字处理文档的主体时,技术使用低于最大的语音校正水平。相反地,对于地址字段、电子表格中的仅数字字段、电话号码等,技术可以使用最大语音校正水平和/或替代语言库122或口音库124。
59.图7图示包括口音模块114的示例设备700的各种部件,口音模块114包括或具有对其它模块的访问,这些部件以硬件、固件和/或软件来实现,并且如参照先前的图1至图6中的任何一个所描述的。
60.示例设备700可以以作为以下设备之一或组合的固定或移动设备来实现:媒体设备、计算设备(例如,图1的计算设备102)、电视机顶盒、视频处理和/或渲染设备、器具设备(例如,封闭和密封的计算资源,诸如一些数字录像机或者全球定位卫星设备)、游戏设备、电子设备、车辆、和/或工作站。
61.示例设备700可以与运行整个设备所需的电子电路、微处理器、存储器、输入输出(i/o)逻辑控制、通信接口和部件、其它硬件、固件和/或软件集成。示例设备700还可以包括耦合计算设备的各种部件以用于部件之间的数据通信的集成数据总线(未示出)。
62.示例设备700包括各种部件,诸如输入输出(i/o)逻辑控制702(例如,用于包括电子电路)和(多个)微处理器704(例如微控制器或数字信号处理器)。示例设备700还包括存储器706,其可以是任何类型的随机存取存储器(ram)、低延迟非易失性存储器(例如,闪速存储器)、只读存储器(rom)、和/或其他合适的电子数据存储。存储器706包括或具有对口音模块114、语言库122和口音库124以及在一些实施例中对语音识别引擎(未示出)的访问。
63.示例设备700还可以包括各种固件和/或软件,诸如操作系统708,其连同其它部件可以是由存储器706保持并且由微处理器704执行的计算机可执行指令。示例设备700还可以包括其他各种通信接口和部件、无线lan(wlan)或无线pan(wpan)部件、其他硬件、固件和/或软件。
64.这些模块的其它示例性能和功能参照图1和图2所示的元素进行了描述。与其它模块或实体独立地或组合地,这些模块可以实现为由存储器706保持并且由微处理器704执行的计算机可执行指令,以实现本文中描述的各种实施例和/或特征。替代地或附加地,任何或所有这些部件可以实现为硬件、固件、固定逻辑电路、或它们的任何组合,其与i/o逻辑控制702和/或示例设备700的其它信号处理和控制电路结合实现。此外,这些部件中的一些部
件可以与设备700分立地动作,诸如当远程(例如,基于云的)库执行口音模块114的服务时。
65.虽然本发明已经以特定于结构特征和/或方法动作的语言进行了描述,但是要理解的是,在所附权利要求中限定的本发明不必要限于所描述的具体特征或动作。更确切地说,具体特征和动作被公开作为实现所要求保护的发明的示例形式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。