1.本发明涉及阵列信号处理技术领域,更具体的说是涉及一种用于远距离语音识别的麦克风阵列拾音方法及系统。
背景技术:
2.语音是人类日常生活中使用极为频繁、作用极为重要的工具。但在实际环境中,语音总是会受到环境噪声、室内混响和干扰说话人的影响,大大降低语音质量,影响语音的可懂度和识别率,因此,我们有必要对被噪声干扰的信号进行增强,以得到干净的信号。语音增强技术在很多应用领域都有广泛的应用,如音视频通话、音视频录制与播放、人机交互、语音识别等等。
3.在现有技术中,语音增强方法分为单通道增强算法和阵列增强算法两大类。这两类算法各有优劣,互为补充,在多数环境都能同时使用,共同提高增强性能。经典的单通道语音增强算法有谱减法、维纳滤波法、统计方法以及基于深度学习的单通道语音增强算法等。而经典的多通道语音增强算法有延迟求和波束形成算法、最小方差无失真响应波束形成算法、线性约束最小方差波束形成算法、广义旁瓣相消波束形成算法、多通道维纳滤波算法等。其中最小方差无失真响应波束形成(mvdr)算法已经成为当前应用最为广泛的自适应波束形成算法之一。
4.但是,当我们需要录制的目标语音距离较远、或能量较小,以至于语音信噪比极低的时候,自适应算法的性能也往往不尽如人意。首先,由于目标语音能量较小,很难准确区分噪声段和语音段,所以对目标语音的方向难以估计的准确,会带来目标语音的失真。其次,人耳和听神经本身的抗噪的能力也较强,但对抗人声干扰的能力较弱,但是自适应算法并不能区分人声干扰和稳定噪声干扰,对其进行相同权重的压制,使得剩余的人声干扰会对处理后的目标语音的可懂度造成较大的影响。
5.因此,如何提供一种用于远距离语音识别的麦克风阵列拾音方法及系统是本领域技术人员亟需解决的问题。
技术实现要素:
6.有鉴于此,本发明提供了一种用于远距离语音识别的麦克风阵列拾音方法及系统,
7.为了实现上述目的,本发明提供如下技术方案:
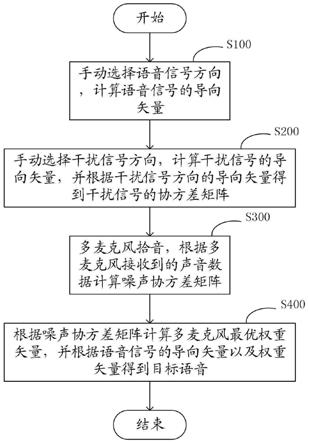
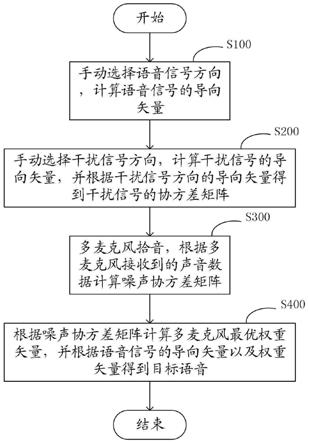
8.一方面,一种用于远距离语音识别的麦克风阵列拾音方法,具体步骤为:
9.s100:手动选择语音信号方向,计算所述语音信号的导向矢量;
10.s200:手动选择干扰信号方向,计算所述干扰信号的导向矢量,并根据所述干扰信号方向的导向矢量得到干扰信号的协方差矩阵;
11.s300:多麦克风拾音,根据多麦克风接收到的声音数据计算噪声协方差矩阵;
12.s400:根据噪声协方差矩阵计算多麦克风最优权重矢量,并根据所述语音信号的
导向矢量以及所述权重矢量得到目标语音。
13.优选的,所述s100中,计算语音信号方向的导向矢量如下:
14.手动选择语音信号方向,并获取多个麦克风的位置和声速,根据所述语音信号方向、各个所述麦克风的位置和声速,算出声音到达各个所述麦克风的延时,得到语音信号的导向矢量:
[0015][0016]
式中,τ
n
为声音到达各个所述麦克风的延时,其中n=1,2,
…
,n,d(ω)即为语音信号的导向矢量。
[0017]
优选的,所述s200中,计算干扰信号的协方差矩阵步骤如下:
[0018]
s210:手动选择干扰信号方向,根据所述干扰信号方向、各个所述麦克风的位置和声速,算出声音到达各个所述麦克风的延时,得到干扰信号的导向矢量:
[0019][0020]
式中,τ
n
为声音到达各个所述麦克风的延时,n=1,2,
…
,n,d
i
(ω)即为干扰信号的导向矢量;
[0021]
s220:按照协方差矩阵的定义,可以得到干扰信号的协方差矩阵
[0022][0023]
式中,d
i
(ω)为干扰信号的导向矢量,为导向矢量d
i
(ω)的共轭转置,φ
ii
(ω)即为干扰信号的协方差矩阵。
[0024]
优选的,所述s300中,计算噪声协方差矩阵如下:
[0025]
多麦克风拾音,根据多麦克风采集到的声音数据计算噪声协方差矩阵:
[0026]
φ
vv
(ω)=e[y(ω)y
h
(ω)];
[0027]
式中,y(ω)为多个麦克风接收到的信号的频域表达式,y
h
(ω)为y(ω)的共轭转置向量。φ
vv
(ω)即为噪声协方差矩阵。
[0028]
优选的,所述s300中计算噪声协方差矩阵后,还对所述噪声协方差矩阵进行修正:
[0029]
计算噪声能量以及干扰能量,所述噪声能量计算公式为:
[0030]
e
v
(ω)=d
h
(ω)φ
vv
(ω)d(ω);
[0031]
式中,φ
vv
(ω)为噪声协方差矩阵,d(ω)为语音信号的导向矢量,d
h
(ω)为导向矢量d(ω)的共轭转置,e
v
(ω)即为噪声能量;
[0032]
干扰信号能量计算公式为:
[0033][0034]
式中,φ
vv
(ω)为噪声协方差矩阵,d
i
(ω)为干扰信号的导向矢量,为导向矢量d
i
(ω)的共轭转置。
[0035]
通过所述噪声能量以及所述干扰能量的能量比确定加权系数,具体公式为:
[0036][0037]
根据所述加权系数,对所述噪声协方差矩阵进行修正,得到修正后的方程如下:
[0038]
h(ω)=arg min(h
h
(ω)(φ
vv
(ω) λ(ω)φ
ii
(ω))h(ω),s.t.h
h
(ω)d(ω)=1;
[0039]
式中,λ(ω)为加权系数,φ
vv
(ω)为噪声协方差矩阵,φ
ii
(ω)即干扰信号的协方差矩阵,d(ω)为语音信号的导向矢量,h
h
(ω)为h(ω)的共轭转置向量,h(ω)为滤波器系数。
[0040]
优选的,所述s400中得到目标语音步骤如下:
[0041]
根据所述修正后的方程,采用拉格朗日乘数法,解得滤波器系数:
[0042][0043]
式中,φ
vv
(ω)为噪声协方差矩阵,λ(ω)为加权系数,φ
ii
(ω)为干扰信号的协方差矩阵,d(ω)为语音信号的导向矢量,h
h
(ω)为h(ω)的共轭转置向量,h(ω)即为求得的滤波器系数;
[0044]
根据所述滤波器系数对多麦克风语音进行加权,得到目标语音:
[0045]
z(ω)=h
h
(ω)y(ω);
[0046]
式中,z(ω)即为我们要录制的清晰的远距离语音。
[0047]
另一方面,一种用于远距离语音识别的麦克风阵列拾音系统,包括:
[0048]
第一选择模块,用于选择语音信号方向;
[0049]
第一计算模块,与所述第一选择模块连接,用于根据语音信号方向计算所述语音信号的导向矢量;
[0050]
第二选择模块,用于选择干扰信号方向;
[0051]
第二计算模块,与所述第二选择模块连接,用于根据干扰信号方向计算所述干扰信号的导向矢量;
[0052]
采集模块,用于采集多麦克风声音数据;
[0053]
第三计算模块,与所述采集模块以及所述第二计算模块连接,用于根据所述声音数据计算噪声协方差矩阵;
[0054]
输出模块,与第三计算模块以及所述第一计算模块连接,用于根据噪声协方差矩阵计算多麦克风最优权重矢量,根据所述语音信号的导向矢量以及所述权重矢量得到目标语音并输出。
[0055]
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种用于远距离语音识别的麦克风阵列拾音方法及系统,通过手动指定语音的方向,减小了目标语音的失真。其次,通过手动指定干扰信号的方向,对人声干扰进行了加权,对人声干扰抑制的更大,而稳定的噪声抑制的更小,从而能够准确的进行拾音,为远距离的语音控制提供了较好的解决方案。
附图说明
[0056]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0057]
图1为本发明提供的方法流程图;
[0058]
图2为本发明提供的系统结构示意图;
[0059]
图3为本实施例2提供的环境设置示意图;
[0060]
图4为传统mvdr方法处理结果示意图;
[0061]
图5为本实施例2提供的本发明处理结果示意图。
具体实施方式
[0062]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0063]
实施例1
[0064]
参见附图1所示,本发明实施例公开了一种用于远距离语音识别的麦克风阵列拾音方法,具体步骤如下:
[0065]
s100:手动选择语音信号方向,计算语音信号的导向矢量;
[0066]
s200:手动选择干扰信号方向,计算干扰信号的导向矢量,并根据干扰信号方向的导向矢量得到干扰信号的协方差矩阵;
[0067]
s300:多麦克风拾音,根据多麦克风接收到的声音数据计算噪声协方差矩阵;
[0068]
s400:根据噪声协方差矩阵计算多麦克风最优权重矢量,并根据语音信号的导向矢量以及权重矢量得到目标语音。
[0069]
在一个具体实施例中,s100中,计算语音信号方向的导向矢量如下:
[0070]
手动选择语音信号方向,并获取多个麦克风的位置和声速,根据语音信号方向、各个麦克风的位置和声速,算出声音到达各个麦克风的延时,得到语音信号的导向矢量:
[0071][0072]
式中,τ
n
为声音到达各个麦克风的延时,其中n=1,2,
…
,n,d(ω)即为语音信号的导向矢量。
[0073]
在一个具体实施例中,s200中,计算干扰信号的协方差矩阵步骤如下:
[0074]
s210:手动选择干扰信号方向,根据干扰信号方向、各个麦克风的位置和声速,算出声音到达各个麦克风的延时,得到干扰信号的导向矢量:
[0075][0076]
式中,τ
n
为声音到达各个麦克风的延时,n=1,2,
…
,n,d
i
(ω)即为语音信号的导向矢量;
[0077]
s220:按照协方差矩阵的定义,可以得到干扰信号的协方差矩阵
[0078][0079]
式中,d
i
(ω)为语音信号的导向矢量,为导向矢量d
i
(ω)的共轭转置,φ
ii
(ω)即为干扰信号的协方差矩阵。
[0080]
在一个具体实施例中,s300中,计算噪声协方差矩阵如下:
[0081]
多麦克风拾音,根据多麦克风采集到的声音数据计算噪声协方差矩阵:
[0082]
φ
vv
(ω)=e[y(ω)y
h
(ω)];
[0083]
式中,y(ω)为多个麦克风接收到的信号的频域表达式,y
h
(ω)为y(ω)的共轭转置向量。φ
vv
(ω)即为噪声协方差矩阵。
[0084]
在一个具体实施例中,s300中计算噪声协方差矩阵后,还对噪声协方差矩阵进行修正:
[0085]
计算噪声能量以及干扰能量,噪声能量计算公式为:
[0086]
e
v
(ω)=d
h
(ω)φ
vv
(ω)d(ω);
[0087]
式中,φ
vv
(ω)为噪声协方差矩阵,d(ω)为语音信号的导向矢量,d
h
(ω)为导向矢量d(ω)的共轭转置,e
v
(ω)即为噪声能量
[0088]
干扰信号能量计算公式为:
[0089][0090]
式中,φ
vv
(ω)为噪声协方差矩阵,d
i
(ω)为语音信号的导向矢量,为导向矢量d
i
(ω)的共轭转置。
[0091]
通过噪声能量以及干扰能量的能量比确定加权系数,具体公式为:
[0092][0093]
根据加权系数,对噪声协方差矩阵进行修正,得到修正后的方程如下:
[0094]
h(ω)=arg min(h
h
(ω)(φ
vv
(ω) λ(ω)φ
ii
(ω))h(ω),s.t.h
h
(ω)d(ω)=1;
[0095]
式中,λ(ω)为加权系数,φ
vv
(ω)为噪声协方差矩阵,φ
ii
(ω)即干扰信号的协方差矩阵,d(ω)为语音信号的导向矢量,h
h
(ω)为h(ω)的共轭转置向量,h(ω)为滤波器系数。
[0096]
在一个具体实施例中,s400中得到目标语音步骤如下:
[0097]
根据修正后的方程,采用拉格朗日乘数法,解得滤波器系数:
[0098][0099]
式中,φ
vv
(ω)为噪声协方差矩阵,λ(ω)为加权系数,φ
ii
(ω)为干扰信号的协方差矩阵,d(ω)为语音信号的导向矢量,h
h
(ω)为h(ω)的共轭转置向量,h(ω)即为求得的滤波器系数;
[0100]
具体的,在步骤s300中,得到的是关于滤波器系数h(ω)修正后的方程,在步骤s400中,为求解出来的h(ω)计算公式,计算过程为拉格朗日乘数法。
[0101]
根据滤波器系数对多麦克风语音进行加权,得到目标语音:
[0102]
z(ω)=h
h
(ω)y(ω);
[0103]
式中,z(ω)即为我们要录制的清晰的远距离语音。
[0104]
参见附图2所示,本发明实施例还公开了一种用于远距离语音识别的麦克风阵列拾音系统,包括:
[0105]
第一选择模块,用于选择语音信号方向;
[0106]
第一计算模块,与第一选择模块连接,用于根据语音信号方向计算语音信号的导向矢量;
[0107]
第二选择模块,用于选择干扰信号方向;
[0108]
第二计算模块,与第二选择模块连接,用于根据干扰信号方向计算干扰信号的导向矢量;
[0109]
采集模块,用于采集多麦克风声音数据;
[0110]
第三计算模块,与采集模块以及第二计算模块连接,用于根据多麦克风接收到的声音数据计算噪声协方差矩阵;
[0111]
输出模块,与第三计算模块以及第一计算模块连接,用于根据噪声协方差矩阵计算多麦克风最优权重矢量,根据语音信号的导向矢量以及权重矢量得到目标语音并输出。
[0112]
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种用于远距离语音识别的麦克风阵列拾音方法及系统,通过手动指定语音的方向,减小了目标语音的失真。其次,通过手动指定干扰信号的方向,对人声干扰进行了加权,对人声干扰抑制的更大,而稳定的噪声抑制的更小,从而能够准确的进行拾音,为远距离的语音控制提供了较好的解决方案。
[0113]
实施例2
[0114]
具体应用本发明实施例1的拾音方法实例如下:
[0115]
本发明对阵列的个数、形状、尺寸均无要求,只需要所有麦克风的位置固定且已知即可。
[0116]
如附图3所示,在传统mvdr方法与本发明进行实验中,设置了一个8麦克风圆阵,水平摆放,以测试效果。同时在模拟实验中放置了4个噪声源,一个干扰源,和一个目标语音,它们以60度的间隔,20米的距离摆放在水平面上。
[0117]
本实施例除了噪声源和干扰源,还对每个麦克风都加了独立的白噪声,以模拟真实的录音环境。
[0118]
参见附图4所示,为传统mvdr方法处理结果示意图;
[0119]
参见附图5所示,为实施例2提供的本发明处理结果示意图;
[0120]
由附图4以及附图5可以看出,经过传统的mvdr方法和本发明进行测试后,本发明获得的语音的失真更小,抑制人声干扰,语音更清晰,因此,本发明提高目标语音的可懂度,更容易进行后续处理,从而进行准确的拾音,为远距离的语音控制提供了较好的解决方案。
[0121]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0122]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。