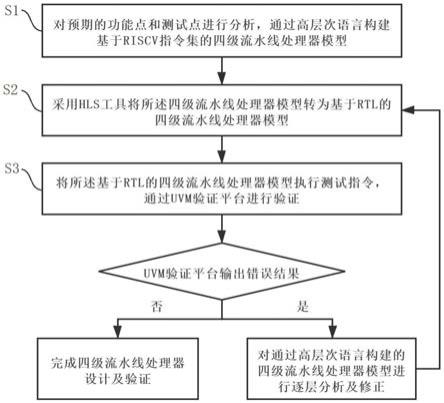
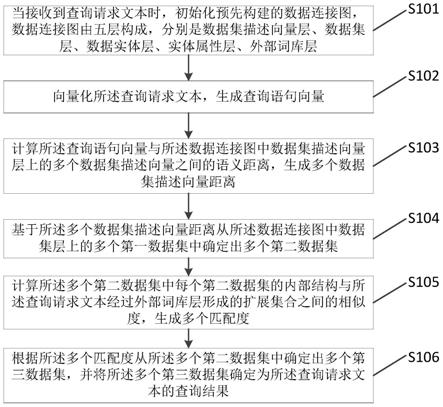
一种基于electra atten bilstm的针对中文短文本情感分类方法
技术领域
1.本发明涉及文本分析技术领域,具体是一种基于electra atten bilstm的针对中文短文本情感分类方法。
背景技术:
2.文本情感分析可以帮助我们从文本中挖掘用户情感信息,自动识别文本的情感极性。近些年,深度学习技术被广泛的应用于文本情感分析任务中。神经网络模型是深度学习技术常用的技术手段。典型的神经网络模型包括卷积神经网络(cnn),循环神经网络(rnn),长短期记忆神经网络(lstm),lstm的变体gru网络模型,以及时序卷积神经网络tcn。因cnn不具备联想上下文信息的能力,rnn被更多的用于文本序列处理过程。lstm不仅可以对词汇的时序关系进行学习,还可以解决rnn存在的梯度消失和梯度爆炸问题。双向长短期记忆网络(bilstm)可以弥补单向lstm无法有效联系上下文信息的缺陷,所以本方法将bilstm与注意力机制(attention)作为模型的一部分。
3.传统的网络模型需要对文本语料分词嵌入,这就会带来分词准确性的依赖程度问题。而使用预训练模型可以在一定程度上解决这个问题。从2016年开始,大多数的研究都开始重视长时的上下文语义在词嵌入中的作用和语言模型在大规模语料上提前预训练这两个核心观点。经典的预训练模型包括elmo,gpt,bert,以及基于bert的改进模型,例如ernie、spanbert、roberta、albert等。由于electra预训练模型可以避免传统预训练模型在mask预训练和fine
‑
tune(微调)过程的不一致问题,进一步减低文本情感分析对分词准确性的依赖程度,并提高训练速度,所以本方法使用electra预训练模型替换bert模型作为整体模型的嵌入层。
4.为了解决传统方法中存在的一些问题,并降低模型的训练成本,综合上述方法的优点,本发明提出一种基于electra atten bilstm的针对中文短文本情感分类方法。
技术实现要素:
5.本发明的目的是提供一种基于electra atten bilstm的针对中文短文本情感分类方法;该方法提出结合electra预训练模型,注意力机制,双向长短期记忆神经网络,构建文本评论语料情感分类模型。
6.本发明实现发明目的采用如下技术方案:
7.本发明提供的一种基于electra atten bilstm的针对中文短文本情感分类方法,其特征在于:在嵌入层用electra预训练模型替换bert模型,减少文本情感分析方法中对分词准确性的依赖程度,避免传统预训练模型在遮盖训练和微调过程过程的不一致问题,通过注意力机制获取上下文信息,通过bilstm获取语料的双向时序信息,训练模型,最后对中文短文本评论语料的情感倾向做出分类。
8.本发明与现有技术相比,其有益效果体现在:提出一种的新的组合模型以减少文
本情感分析方法中对词向量化过程中分词准确性的依赖程度,解决传统预训练模型在mask预训练和微调过程过程的不一致问题,获取评论文本更细粒度的语义表示信息,节约模型的训练成本,经过简单的迭代训练就能训练出准确率更高的模型。
附图说明
9.图1是本方法的总体结构图;
10.图2是electra替换遮盖检测方式图;
11.图3是self
‑
attention权重计算方式图;
12.图4是bilstm结构图;
13.图5是实验数据设置图。
14.图6是数据集1上各模型的准确率对比图
15.图7是数据集2上各模型的准确率对比图
具体实施方式
16.以下结合附图与具体实施步骤从设计与实验对本发明做进一步解释说明,如图1所示,本发明的总体结构包括三个组成部分:electra模型,注意力机制,bilstm。
17.其中,在嵌入层,用electra模型替换一般方法中的bert模型,以提高整体模型的训练效果。electra模型主要训练两个神经网络,分别是一个生成器和一个判定器。一个编码器组成一个神经网络,将输入序列映射成对应的向量。计算对于每一个给定的位置,生成器输出生成的遮罩对应的可能性。其替换遮盖检测方式如图2所示。
18.由于本文的目标语料为中文短句,需要的是获取句子内部的依赖关系和内部结构,所以本文选择transform中的self
‑
attention注意力机制作为模型的组成部分。self
‑
attention是注意力机制的一种,它加强的是句子内部的权重。例如,“我是一名学生。”这句话,它加强的是“学生”的权重。计算自注意力权值的过程是使用一个query,计算它和每个key的相似程度,然后对所有的value进行加权求和。它的权重计算方式如图3所示。
19.bilstm是由前向lstm和后向lstm组合而成,因此可以更好的捕捉双向的语义依赖。例如,“这家店的差不行,没有隔壁好”,这里的“不行”是对“差”的一种程度修饰。通过bilstm可以捕捉这种从后往前的语义依赖关系。如图4所示,对于情感分类任务来说,bilstm会从两个方向获取句子各成分间的语义和结构信息,最后进行拼接。
20.以下是本方法的实验验证。
21.本实验包括两组实验数据,都是网上的开源数据集。其中,数据集1是餐饮外卖用户评论的数据语料。它分为训练集和测试集,其中训练集一共有9600条短评语料,测试集有2386条语料数据。训练集中积极的语料评论3200条,消极语料评论6400条,正负比为1:2。数据集2为汽车销售的用户评论语料,其中,训练集包含56700条评论语料,测试集包含6299条评论语料。它的训练集语料中包括28425条积极的数据评论和28275条消极的数据评论,测试集语料中包括3156条积极的数据评论,3143条消极的数据评论。数据集1为实验设计的小规模数据测试,测试本文提出的新的组合模型在小规模数据集上的应用效果。数据集2为实验设计的中等偏大规模数据测试,测试本文提出的新的组合模型在中等偏大规模数据集上的应用效果。实验数据集的设置如图5所示。
22.本方法选择python开发环境,通过anaconda下载torch,sklearn等工具包。并调节bert以及electra的预训练权重。其中bert的注意力概率下降率为0.1,激活函数为gelu,隐藏层dropout下降率为0.1,隐藏层下降率为0.1,隐藏层大小设为768,初始化范围为0.02,升维维度为3072,词典词数大小为21128。相对应的,electra的相关参数设置与bert尽可能的保持了一致。
23.文本实验在相同的环境下设置了4组对照实验,验证本文提出的这种新的electra atten bilstm组合模型的优越性。
24.通过自然语言预训练模型bert和electra与lstm,bilstm的组合可以得到4种组合模型
25.(1)bert atten bilstm
26.(2)bert atten lstm
27.(3)electra atten lstm
28.(4)electra atten bilstm
29.其中,electra atten bilstm为本文提出的模型。每种模型分别经过10轮的神经网络迭代训练,以此验证各个模型分别在小规模,中大规模数据集上表现出的效果。每轮迭代训练后,会通过测试集测试计算该轮训练出的模型的准确率。使用数据集1餐饮外卖用户评论语料,几种模型训练出的准确率如图6所示。从图中可以看出,经过各模型神经网络的迭代训练,其准确率呈现不断上升的趋势。但是,本文提出的electra atten bilstm模型始终位于各模型的上方。于此同时,可以看出基于electra和lstm的模型在节省自然语言处理文本情感分析领域训练资源代价同时,也可以取得比基于bert和lstm的模型更好的准确率。
30.为了更好的探索各种组合模型在不同数据集上的实验效果,验证本文提出的模型的有效性,本文设计了在数据集2汽车销售评论数据集上的实验研究。考虑到数据集1餐饮外卖评论语料集中正负语料比例为1:2,数据集2的正负语料比例设为1:1,由此排除可能存在的正负评论语料的不平衡问题对各模型预测效果的影响。
31.数据集2汽车销售用户评论上,各个模型经过10轮神经网络迭代训练,每轮训练出的模型准确率如图7所示。通过比较10轮迭代训练下来各模型准确率的大小,可以看出本文提出的electra atten bilstm模型在面对中大规模数据集时,模型准确率上仍然占有优越。故本发明提出的这种新的组合模型方式是真实有效的。
32.对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
33.此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。