1.本发明涉及大数据技术领域,具体涉及一种三角式隐私计算方法。
背景技术:
2.数据常被比作是数字时代的石油,又有资料将数据称为和土地、劳动力、资本、技术并列的第五大生产要素。但数据资源拥有其特殊性。与其他传统生产要素相比,数据的独特性在于,一旦被使用或被看见,就会导致数据包含的信息被泄露。而且就能被无限地传播或者复制,造成数据大量传播,降低了数据的价值。数据的价值发挥和隐私保护成了一对矛盾。数据发挥价值时,就会导致数据的泄露。数据一旦被泄露传播,数据源方就难以再次利用数据获取价值,带来十分不利的结果。同时,由于数据泄露难以追溯泄露源,泄露者和滥用者的责任就难以追究。加之部分机构及企业的数据还涉及用户的隐私,为了保护用户隐私,更加限制了数据的流通和价值的发挥。虽然本领域提出了同态加密技术,用于实现数据价值的挖掘和隐私保护的兼顾。但同态加密技术目前仅能够实现加法和乘法运算,应用范围十分有限。因而需要继续研究隐私计算的技术。
3.如中国专利cn111047450a,公开日2020年4月21日,一种链上数据的链下隐私计算方法及装置,该方法包括:区块链节点根据客户端提交的交易,确定用于隐私计算的链上数据;上述区块链节点将经过加密的链上数据传输至链下隐私计算节点,该链下隐私计算节点处部署了用于对上述链上数据执行隐私计算的链下可信执行环境;上述区块链节点获取上述链下隐私计算节点在链下可信执行环境内生成并加密后反馈的计算结果,并根据该计算结果更新区块链账本数据。通过其技术方案可以在链下隐私计算的过程中实现隐私保护。但其并不能解决不同机构、企业之间进行数据流通和价值挖掘的问题。
技术实现要素:
4.本发明要解决的技术问题是:目前隐私计算的应用范围窄的技术问题。提出了一种三角式隐私计算方法,能够扩大隐私计算的应用范围。
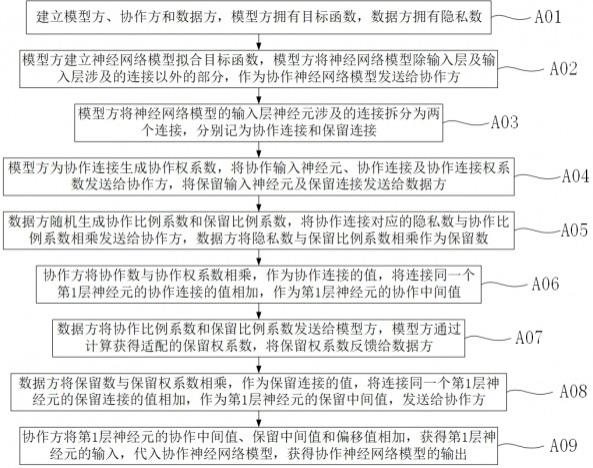
5.为解决上述技术问题,本发明所采取的技术方案为:一种三角式隐私计算方法,包括以下步骤:建立模型方、协作方和数据方,模型方拥有目标函数,数据方拥有隐私数;模型方建立神经网络模型拟合目标函数,模型方将神经网络模型除输入层及输入层涉及的连接以外的部分,作为协作神经网络模型发送给协作方;模型方将神经网络模型的输入层神经元涉及的连接拆分为两个连接,分别记为协作连接和保留连接,协作连接和保留连接的权系数分别记为协作权系数和保留权系数,为每个协作连接建立协作输入神经元,为每个保留连接建立保留输入神经元;模型方为协作连接生成协作权系数,将协作输入神经元、协作连接及协作连接权系数发送给协作方,将保留输入神经元及保留连接发送给数据方;数据方随机生成协作比例系数和保留比例系数,将协作连接对应的隐私数与协作比例系数相乘,作为协作数,发送给协作方,数据方将隐私数与保留比例系数相乘,作为保留数;协作方将协作数与协作权系数相乘,作为协作连接的值,将连接同一个第1层神经元的协作连接的
值相加,作为第1层神经元的协作中间值;数据方将协作比例系数和保留比例系数发送给模型方,模型方通过计算获得适配的保留权系数,将保留权系数反馈给数据方;数据方将保留数与保留权系数相乘,作为保留连接的值,将连接同一个第1层神经元的保留连接的值相加,作为第1层神经元的保留中间值,发送给协作方;协作方将第1层神经元的协作中间值、保留中间值和偏移值相加,获得第1层神经元的输入,代入协作神经网络模型,获得协作神经网络模型的输出,即为隐私计算的结果,将结果发送给模型方。
6.作为优选,所述目标函数为多元函数或不具有反函数的一元函数。
7.作为优选,模型方建立神经网络模型拟合目标函数的方法包括:模型方将目标函数涉及的输入字段发送给相关的数据方;数据方提供输入字段的输入数的取值范围和分布概率;模型方根据按照分布概率在输入数的取值范围内随机生成输入数;将输入数代入目标函数获得目标函数的结果,结果作为标签,形成样本数据;使用样本数据训练神经网络模型,获得神经网络模型。
8.作为优选,数据方计算输入数分布概率的方法为:数据方将输入数的取值范围划分为若干个区间,计算每个区间的分布概率。
9.作为优选,模型方建立历史记录表,历史记录表记录每对协作连接和保留连接收到的协作比例系数和保留比例系数,并记录模型方分配的协作权系数和计算所得保留权系数;当再次收到历史表中记录的协作比例系数和保留比例系数时,为协作连接分配同样的协作权系数;将同样的保留权系数发送给数据源方。
10.作为优选,模型方为输入层神经元涉及的连接的权系数生成一个随机的干扰量,干扰量与权系数的比值小于预设阈值,根据协作权系数、协作比例系数、保留比例系数及添加干扰量后的原连接权系数,计算出保留权系数,发送给数据源方。
11.作为优选,模型方根据目标函数,选择划分量,所述划分量为目标函数中涉及指数函数的输入数,模型方根据划分量的取值范围,为划分量设置若干个区间,为每个区间建立一个神经网络模型,并将神经网络模型关联对应的区间,进行安全多方计算时,由划分量对应的数据方选择对应的神经网络模型并通知其他数据方、协作方和模型方。
12.作为优选,模型方构建神经网络模型时,执行以下步骤:设定阈值n,n为正整数;模型方分别计算目标函数对每个输入数的1阶偏导至n阶偏导;对于输入数,若目标函数的m阶偏导非常数,则模型方添加所述输入数的m次方作为神经网络模型的输入神经元。
13.一种三角式隐私计算方法,包括以下步骤:建立模型方、协作方和数据方,模型方拥有目标函数,数据方拥有隐私数;模型方建立神经网络模型拟合目标函数,模型方将神经网络模型除输入层及输入层涉及的连接以外的部分,作为协作神经网络模型发送给协作方;模型方将神经网络模型的输入层神经元涉及的连接拆分为两个连接,分别记为协作连接和保留连接,协作连接和保留连接的权系数分别记为协作权系数和保留权系数,为每个协作连接建立协作输入神经元,为每个保留连接建立保留输入神经元;模型方为协作连接生成协作权系数,将协作输入神经元、协作连接及协作连接权系数发送给协作方;模型方根据原连接权系数及协作权系数,建立保留权系数与比例系数的多项式拟合函数;将多项式拟合函数、保留输入神经元及保留连接发送给数据方;数据方将协作连接对应的隐私数拆分为两个加数,分别作为协作数和保留数,将协作数发送给协作方;协作方将协作数与协作权系数相乘,作为协作连接的值,将连接同一个第1层神经元的协作连接的值相加,作为第1
层神经元的协作中间值;数据方计算保留数与协作数的比值,即为比例系数,根据多项式拟合函数,获得保留权系数;数据方将保留数与保留权系数相乘,作为保留连接的值,将连接同一个第1层神经元的保留连接的值相加,作为第1层神经元的保留中间值,发送给协作方;协作方将第1层神经元的协作中间值、保留中间值和偏移值相加,获得第1层神经元的输入,代入协作神经网络模型,获得协作神经网络模型的输出,即为隐私计算的结果,将结果发送给模型方。
14.本发明的实质性效果是:通过神经网络模型能够拟合任意函数,提高隐私计算的应用范围,理论上任何目标函数都能够进行隐私计算;神经网络的计算效率较高,提高了安全多方计算的计算效率;不仅能够使隐私数据保密,同时还能够使神经网络模型保密。
附图说明
15.图1为实施例一隐私计算方法示意图。
16.图2为实施例一单一输入数的神经网络模型示意图。
17.图3为实施例一协作神经网络模型示意图。
18.图4为实施例一拟合目标函数方法示意图。
19.图5为实施例一取值分布概率示意图。
20.图6为实施例一模型方历史记录表使用示意图。
21.图7为实施例一建立神经网络模型方法示意图。
22.图8为实施例一神经网络模型示意图。
23.图9为实施例一神经网络模型拆分示意图。
24.图10为实施例二隐私计算方法示意图。
25.其中:10、输入数,20、输入层,30、第1层,40、输出层,21、协作连接,22、保留连接,23、保留输入神经元,24、协作输入神经元,100、协作神经网络。
具体实施方式
26.下面通过具体实施例,并结合附图,对本发明的具体实施方式作进一步具体说明。
27.实施例一:一种三角式隐私计算方法,请参阅附图1,本方便包括以下步骤:步骤a01)建立模型方、协作方和数据方,模型方拥有目标函数,数据方拥有隐私数;步骤a02)模型方建立神经网络模型拟合目标函数,模型方将神经网络模型除输入层及输入层涉及的连接以外的部分,作为协作神经网络模型发送给协作方;步骤a03)模型方将神经网络模型的输入层神经元涉及的连接拆分为两个连接,分别记为协作连接21和保留连接22,协作连接21和保留连接22的权系数分别记为协作权系数和保留权系数,为每个协作连接21建立协作输入神经元24,为每个保留连接22建立保留输入神经元23;步骤a04)模型方为协作连接21生成协作权系数,将协作输入神经元24、协作连接21及协作连接21权系数发送给协作方,将保留输入神经元23及保留连接22发送给数据方;步骤a05)数据方随机生成协作比例系数和保留比例系数,将协作连接21对应的隐
私数与协作比例系数相乘,作为协作数,发送给协作方,数据方将隐私数与保留比例系数相乘,作为保留数;步骤a06)协作方将协作数与协作权系数相乘,作为协作连接21的值,将连接同一个第1层神经元的协作连接21的值相加,作为第1层神经元的协作中间值;步骤a07)数据方将协作比例系数和保留比例系数发送给模型方,模型方通过计算获得适配的保留权系数,将保留权系数反馈给数据方;步骤a08)数据方将保留数与保留权系数相乘,作为保留连接22的值,将连接同一个第1层神经元的保留连接22的值相加,作为第1层神经元的保留中间值,发送给协作方;步骤a09)协作方将第1层神经元的协作中间值、保留中间值和偏移值相加,获得第1层神经元的输入,代入协作神经网络模型,获得协作神经网络模型的输出,即为隐私计算的结果,将结果发送给模型方。目标函数为多元函数或不具有反函数的一元函数。
28.本实施例记载技术方案能够实现单个隐私数的隐私计算。请参阅附图2,展示了将隐私数x1与预设的阈值进行对比的隐私计算。例如x1是数据方提供的年龄数据,为隐私数据。模型方想要判断x1是否满18岁,根据结果判断是否进入下一步计算。构建的神经网络模型如图2所示。仅包括一个输入神经元,一个隐藏神经元和一个输出神经元。隐藏神经元的激活函数为relu6(x),函数relu6(x)=min(max(x,0),6),即当x小于或等于0时输出为0,当x大于0小于6时,输出为x,当x大于或等于6时,输出为6,年龄x1的取值为正整数,连接权系数w1为6,偏移值等于b1=
‑
102。隐藏层,即第1层,神经元的输出a= relu6(6*x1
‑
102),输出神经元使用softmax函数,连接权系数为1,但由于仅有一个隐藏层神经元,实际输出神经元将直接输出隐藏层神经元的输出a,即y1=a,该神经网络模型在输入数x1小于等于17时,输出y1为0,当输入数x1大于或等于18时,输出y1为6,不能从结果倒推出输入的年龄的值。但计算过程中,会形成中间值,接触到中间值的一方,是能够获知年龄的值的。因而采用本实施例记载的三角式隐私计算方法。请参阅附图3,模型方将输入神经元与隐藏神经元的连接,拆分成两个连接。连接权系数拆分为w1_1和w1_2。模型方生成w1_2的值,将生成的协作权系数w1_2的值发送给协作方。删除输入神经元后,剩余的隐藏神经元和输出神经元作为协作神经网络100发送给协作方。
29.数据方将x1拆分为x1_1和x1_2,计算获得使x1_1=k1*x1和x1_2=k2*x1成立的保留比例系数k1和协作比例系数k2,将保留比例系数k1和协作比例系数k2发送给模型方,将x1_2发送给协作方。模型方计算w1=k1*w1_1 k2*w1_2成立的保留权系数w1_1,将保留权系数w1_1发生给数据方。数据方计算x1_1* w1_1,结果发送给协作方。协作方计算x1_2*w1_2,将x1_1* w1_1与x1_2*w1_2相加,所得结果即x1*w1,而后再加上b1。由于协作方不知晓k2和w1_1,因而协作方无法推算出x1的值,同样也无法推算出w1的值,实现数据保密和神经网络模型保密。
30.如表1所示,数据方的输入数x1=16,数据方将x1拆分成x1_1=12和x1_2=4,将x1_2=4发生给协作方。计算获得保留比例系数k1=0.75和协作比例系数k2=0.25。将k1=0.75和k2=0.55发送给模型方。
31.模型方为协作方随机生成协作权系数w1_2=12,将w1_2=12发生给协作方。权系数w1=6,根据w1、k1、k2和w1_2的值,计算获得w1_1=4,将w1_1=4发送给数据方。
32.数据方计算x1_1*w1_1=12*4=48,将48发送给协作方。
33.协作方计算x1_2*w1_2=4*12=48,而后计算a=relu6(x1_1*w1_1 x1_2*w1_2 b1)=relu6(48 48
‑
102)=0,协作方继续计算输出神经元的值,y1=softmax(w2*a)=1*a=0,协作方将神经网络模型的输出结果0发送给模型方。使得模型方知晓输入数的值小于18,但不知晓具体的输入数的值。同样协作方也不知晓具体的输入数x1的值。而数据方和协作方均不知晓模型方判断年龄的阈值是多少。协作方知晓偏移值b1的值,但无法推算出权系数w1,因而无法获得模型方设置的阈值标准。使得模型方、协作方和数据方,没有任何一方同时知晓连接权系数w1和输入数x1。形成了三角式的隐私计算,能够同时保护数据隐私和模型隐私。
34.表1 三角式隐私计算过程表
序号模型方协作方数据方1w1=6,b1=
‑
102 x1=162
ꢀꢀ
x1_1=12,x1_2=4,k1=0.75,k2=0.553 x1_2=4,来自数据方 4w1_2=12
ꢀꢀ
5 w1_2=12,b1=
‑
102,来自模型方,计算x1_2*w1_2=48 6k1=0.75,k2=0.55,来自数据方
ꢀꢀ
7计算获得w1_1=4
ꢀꢀ8ꢀꢀ
w1_1=4,来自模型方9
ꢀꢀ
计算x1_1*w1_1=4810 x1_1*w1_1=48,来自数据方 11 计算a=relu6(x1_1*w1_1 x1_2*w1_2 b1)=0 12 计算y1=softmax(0) 13y1=0,来自协作方
ꢀꢀ
同样的,当输入数x1=17时,y1=0,而当输入数x1=18时,y1=6,输入数x1>18时,y1=6,使得模型方不能根据结果获得具体的x1的值,但能够准确判断输入数x1是否大于或等于18,完成年龄的判断。阈值18可以由模型方根据需要自行更改,训练或者直接赋值适配的连接权系数和偏移值即可。在此隐私计算过程中,输入数x1和阈值都将获得保密。
35.请参阅附图4,模型方建立神经网络模型拟合目标函数的方法包括:步骤b01)模型方将目标函数涉及的输入字段发送给相关的数据方;步骤b02)数据方提供输入字段的输入数的取值范围和分布概率;步骤b03)模型方根据按照分布概率在输入数的取值范围内随机生成输入数;步骤b04)将输入数代入目标函数获得目标函数的结果,结果作为标签,形成样本数据;步骤b05)使用样本数据训练神经网络模型,获得神经网络模型。参阅附图5,数据方计算输入数分布概率的方法为:数据方将输入数的取值范围划分为若干个区间,计算每个区间的分布概率。将区间划分边界和数值的分布概率发送给模型方。
36.理论上神经网络模型能够拟合任意函数。对多个输入数的一次方进行加法运输的拟合效果最好,甚至能实现精准拟合。对于三角函数等取值范围有限的函数的拟合也具有较高的拟合精度和训练效率。然而对于如2次方、3次方、幂函数、指数函数等,达到较高拟合精度会造成神经网络模型较为复杂。采用将输入数的取值范围划分区间的方式,能够提高神经网络模型拟合的精度,加快神经网络模型训练的效率。
37.请参阅附图6,本实施例中模型方执行以下步骤:步骤c01)模型方建立历史记录表,历史记录表记录每对协作连接21和保留连接22收到的协作比例系数和保留比例系数,并记录模型方分配的协作权系数和计算所得保留权系数;步骤c02)当再次收到历史表中记录的协作比例系数和保留比例系数时,为协作连接21分配同样的协作权系数;步骤c03)将同样的保留权系数发送给数据源方。
38.模型方为输入层神经元涉及的连接的权系数生成一个随机的干扰量,干扰量与权系数的比值小于预设阈值,根据协作权系数、协作比例系数、保留比例系数及添加干扰量后的原连接权系数,计算出保留权系数,发送给数据源方。
39.模型方根据目标函数,选择划分量,划分量为目标函数中涉及指数函数的输入数,模型方根据划分量的取值范围,为划分量设置若干个区间,为每个区间建立一个神经网络模型,并将神经网络模型关联对应的区间,进行安全多方计算时,由划分量对应的数据方选择对应的神经网络模型并通知其他数据方、协作方和模型方。
40.请参阅附图7,模型方构建神经网络模型时,执行以下步骤:步骤d01)设定阈值n,n为正整数;步骤d02)模型方分别计算目标函数对每个输入数的1阶偏导至n阶偏导;步骤d03)对于输入数,若目标函数的m阶偏导非常数,则模型方添加输入数的m次方作为神经网络模型的输入神经元。如目标函数为y=x1^2 3*x2,则目标函数对于x1的一阶偏导、二阶偏导非0,三阶偏导为0,对x2的一阶偏导非0,二阶偏导为0,则为x1建立1次方输入神经元和2次方输入神经元,对x2建立1次方输入神经元。将幂运算转换为加法运算,降低神经网络的复杂度,节省神经网络的训练时长。值得注意的是,即使不建立x1的2次方输入神经元,神经网络模型也能够通过大量样本数据的训练,获得拟合x1的平方的结果。
41.其大致原理为,与x1输入神经元连接的多个隐藏层神经元分别具有不同的权系数。当x1的取值与权系数相当时,x1与权系数的乘积即接近x1的2次方。当这样的隐藏层神经元足够多时,其计算精度将满足要求。同样的,对于x1的3次方,当权系数与x1的平方相当时,权系数与x1的乘积即接近x1的3次方。
42.同样的,对于指数函数、三角函数、对数函数等较为复杂的函数。当隐藏层神经元数量足够多时,使得输入数在其取值范围内,总存在某个隐藏层神经元连接的权系数与输入数的乘积与对应函数值接近。其他不接近的神经元可以通过激活函数的抑制而不再传播。虽然会导致神经网络模型庞大复杂,但能够实施。
43.同时也意味着,未增加m次方作为神经网络模型的输入神经元时,该方案适合输入数的数量多,而目标函数涉及的计算较为简单的情况。增加m次方作为神经网络模型的输入神经元的技术方案时,由于增加了输入数的高次项,则能够计算更为复杂的目标函数。包括含高次项的加权和计算。实际上,对应能够进行泰勒展开的函数,本方案都能够具有较高效率的进行拟合。如e^x、lnx的泰勒展开式中,包括x的1次方至n次方,当n足够大时,能够使误差低于阈值。从而本实施例大幅的扩大了神经网络模型能够高效率拟合的目标函数的范围。扩大了本方案高效率实施的范围。
44.请参阅附图8,神经网络模型通常包括一个输入层、一个输出层和若干个隐藏层,隐藏层也称为中间层,在一些简单的神经网络模型中,也可以没有隐藏层。输出层可以有一个神经元,也可以有多个神经元。较为典型的神经网络模型为全连接神经网络。即每层的神经元与上一层的神经元均连接。输入层也被称为第0层,相应的隐藏层被依次称为第1层、第2层等。图8中所示神经网络模型具有一个输入层20、一个输出层40和一个隐藏层,即第1层30。输入层10的神经元的输出即为输入数10,用于将输入数10导入神经网络模型。图8所示的神经网络模型的目标函数为x1、x2和x3的加权和。使用的激活函数relu在输入数为正数时,是能够根据输出反推出输入数的。因而需要多个输入数才能保证输入数的隐私。
45.请参阅附图9,输入层的神经元有3个,输入数分别为x1、x2和x3,其中x1和x2属于
数据方甲,x3属于数据方乙。以第1层的第1个神经元为例,分别将x1、x2和x3拆分为对应的协作数和保留数。如输入数x1记为协作数x1_c和保留数x1_r,相应的协作权系数wc111和保留权系数xr111。对输入数x2和x3做同样操作。
46.协作权系数由模型方分配并发送给协作节点。数据方甲和数据方乙随机生成协作比例系数和保留比例系数。将协作比例系数和保留比例系数发送给模型方。模型方根据协作权系数、原连接权系数、协作比例系数和保留比例系数,计算获得保留权系数。计算等式为:原连接权系数=协作比例系数*协作权系数 保留比例系数*保留权系数。模型方保留有原连接的权系数,因而能够计算获得保留权系数。协作方因不知晓保留权系数,因而无法计算获得原连接的权系数。数据方因不知晓协作权系数,也无法计算获得原连接的权系数。
47.其中数据方甲和数据方乙分别将协作数x1_c、x2_c和x3_c发送给协作方。数据方甲保留保留数x1_r和x2_r,数据方乙保留保留数x3_r,数据方甲计算保留中间值temp_r_1=x1_r*wr111 x2_r*wr112,数据方乙计算保留中间值temp_r_2=x3_r*wr113,temp_r_1和temp_r_2发送给协作方。协作方计算协作中间值temp_c= x1_c*wc111 x2_c*wc112 x3_c*wc113,协作方获得第1层的第1个神经元对应的保留中间值temp_r_1和保留中间值temp_r_2后,将保留中间值temp_r_1、保留中间值temp_r_2和协作中间值temp_c求和,结果等于x1_r*wr111 x2_r*wr112 x3_r*wr113 x1_c*wc111 x2_c*wc112 x3_c*wc113,即等于x1、x2和x3分别与原连接权系数的乘积的和。再加上偏移值b1后,代入激活函数即可获得第1层的第1个神经元的输出。进而继续获得协作神经网络模型的输出,目标函数的输出。
48.本实施例的有益技术效果是:通过神经网络模型能够拟合任意函数,提高隐私计算的应用范围,理论上任何目标函数都能够进行隐私计算;神经网络的计算效率较高,提高了安全多方计算的计算效率;不仅能够使隐私数据保密,同时还能够使神经网络模型保密。
49.实施例二:一种三角式隐私计算方法,请参阅附图10,本方法包括以下步骤:步骤e01)建立模型方、协作方和数据方,模型方拥有目标函数,数据方拥有隐私数;步骤e02)模型方建立神经网络模型拟合目标函数,模型方将神经网络模型除输入层及输入层涉及的连接以外的部分,作为协作神经网络模型发送给协作方;步骤e03)模型方将神经网络模型的输入层神经元涉及的连接拆分为两个连接,分别记为协作连接21和保留连接22,协作连接21和保留连接22的权系数分别记为协作权系数和保留权系数,为每个协作连接21建立协作输入神经元24,为每个保留连接22建立保留输入神经元23;步骤e04)模型方为协作连接21生成协作权系数,将协作输入神经元24、协作连接21及协作连接21权系数发送给协作方;步骤e05)模型方根据原连接权系数及协作权系数,建立保留权系数与比例系数的多项式拟合函数;步骤e06)将多项式拟合函数、保留输入神经元23及保留连接22发送给数据方;步骤e07)数据方将协作连接21对应的隐私数拆分为两个加数,分别作为协作数和保留数,将协作数发送给协作方;步骤e08)协作方将协作数与协作权系数相乘,作为协作连接21的值,将连接同一
个第1层神经元的协作连接21的值相加,作为第1层神经元的协作中间值;步骤e09)数据方计算保留数与协作数的比值,即为比例系数,根据多项式拟合函数,获得保留权系数;步骤e10)数据方将保留数与保留权系数相乘,作为保留连接22的值,将连接同一个第1层神经元的保留连接22的值相加,作为第1层神经元的保留中间值,发送给协作方;步骤e11)协作方将第1层神经元的协作中间值、保留中间值和偏移值相加,获得第1层神经元的输入,代入协作神经网络模型,获得协作神经网络模型的输出,即为隐私计算的结果,将结果发送给模型方。
50.本实施例在实施例一的基础上,对保留权系数的获得进行了具体的改进。具体而言:在实施例一中,数据方将协作比例系数和保留比例系数发送给模型方,由模型方计算出适配的保留权系数发送给数据方。本实施例中,限制协作比例系数和保留比例系数的和为1,将协作比例系数用保留比例系数表示,将协作权系数设置为常数。则等式:原连接权系数=协作比例系数*协作权系数 保留比例系数*保留权系数中,仅有保留比例系数和保留权系数两个未知数。穷举大量保留比例系数,计算对应的保留权系数,获得足够数量的(保留比例系数,保留权系数)对,建立多项式拟合,获得保留权系数对保留比例系数的拟合函数。
51.如实施例一中,给定w1=6和w1_2=12,则保留比例系数和保留权系数满足的等式为:6=(1
‑
保留比例系数)*12 保留比例系数*保留权系数。举例保留比例系数={0.2,0.4,0.5,0.8},对应计算获得的保留权系数={
‑
18,
‑
3,9,4.5},相当于4个样本点。这4个样本点拟合出的多项式函数为:f(x)=150*x^2
‑
15*x
‑
21。当样本点足够多时,就可以获得在足够宽的自变量范围内的足够精确的多项式的拟合,使协作权系数和保留权系数的等效权系数与原权系数的误差达到允许范围内。这样数据方就不需要在代入保留输入神经元时,向模型方请求保留权系数,而是由数据方自行计算即可。这样不仅能够减少通信次数,而且能够自然的实现当取值相同的保留比例系数时,产生相同的协作权系数及保留权系数。因为若在相同的保留比例系数下,模型方提供不同的协作权系数及保留权系数,会使数据方有机会获得多个等式,将这些等式联立,即使不知晓协作权系数,数据方也有可能求解出原连接的权系数,存在模型泄露的风险。本实施例的方案不需要建立历史记录表,就能够确保模型的保密。
52.以上的实施例只是本发明的一种较佳的方案,并非对本发明作任何形式上的限制,在不超出权利要求所记载的技术方案的前提下还有其它的变体及改型。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。