基于麻雀搜索算法优化elman神经网络的短期负荷预测方法
技术领域
1.本发明涉及短期负荷预测技术领域,具体涉及一种基于麻雀搜索算法优化elman神经网络的短期负荷预测方法。
背景技术:
2.在互联网与物联网迅猛发展的趋势下,各个行业都在不断地通过高新技术革新来提高行业竞争力。不论什么行业都离不开电能的使用,企业作为用电耗能大户,对企业用电进行科学合理的管理也越来越受到企业的关注。因此,如何能够更加精确的在企业中基于用电历史数据进而预测出未来某一时刻的用电信息来对企业用电进行科学合理的管理尤为重要。
3.由于负荷预测使用的方法不一,预测精度相应会各有差异。
技术实现要素:
4.为了解决上述技术问题,本发明提出了一种基于麻雀搜索算法优化elman神经网络的短期负荷预测方法;能提高企业负荷预测的精确度,可有效的解决上述技术问题。
5.本发明通过以下技术方案实现:
6.一种基于麻雀搜索算法优化elman神经网络的短期负荷预测方法,该方法包括建立短期负荷预测模型;具体为建立基于麻雀搜索算法优化的elman神经网络预测模型,通过基于麻雀搜索算法优化的elman神经网络预测模型进行训练,输出最佳预测值;具体的优化步骤如下:
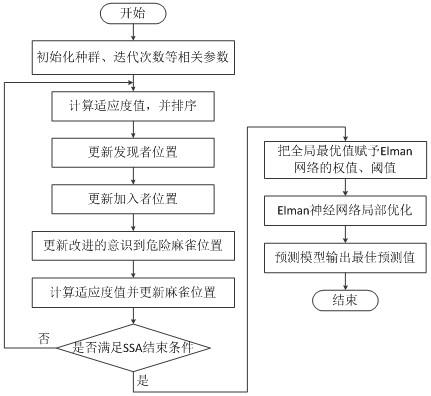
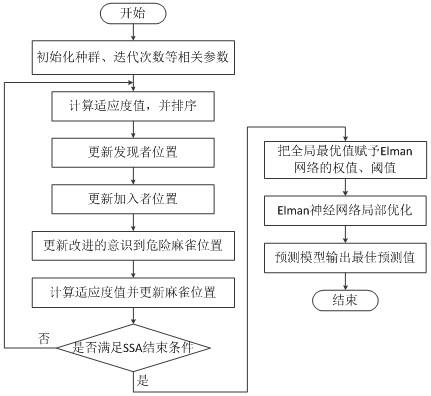
7.步骤一:开始操作,建立短期负荷预测模型,获得训练样本;
8.步骤二:建立基于麻雀搜索算法优化的elman神经网络预测模型;
9.步骤三:将训练样本带入到基于麻雀搜索算法优化的elman神经网络预测模型进行训练;
10.步骤四:将全局最优值赋予elman网络的权值和阈值;
11.步骤五:elman神经网络进行局部优化;
12.步骤六:最终预测模型输出最佳预测值;结束操作。
13.进一步的,步骤一所述的建立短期负荷预测模型的具体方式为:将限定时间段内每隔2小时测得的历史负荷数据作为训练样本,将训练样本分别采用原始的elman神经网络预测模型和基于麻雀搜索算法优化的elman神经网络预测模型进行训练,预测限定时间段后一日的企业电力负荷数值;模型中将每3天的负荷作为输入向量,第4天的负荷作为目标向量,这样可以得到多组训练样本,并将限定时间段后一日的数据作为网络的测试样本。
14.进一步的,步骤二所述的建立基于麻雀搜索算法优化的elman神经网络预测模型,是在经典的elman动态网络中引入麻雀搜索算法,对经典的elman动态网络的训练过程做进一步的优化。
15.进一步的,所述的麻雀搜索算法是一种群智能优化算法,主要受麻雀的觅食行为
和反捕食行为而启发;麻雀搜索算法中m只麻雀组成的种群可表示为:
[0016][0017]
其中,n为待优化问题变量的维数,m为麻雀的数量,f表示适应度值,则所有麻雀的适应度值可以表示为:
[0018][0019]
进一步的,所述的麻雀搜索算法中,在每次迭代麻雀通常可被分为发现者和加入者两种类型,在每次迭代的过程中,发现者的位置更新描述如下:
[0020][0021]
其中,t为当前迭代数;iter
max
为常数,表示最大的迭代次数;j可取值1,2,3,...,n;α属于(0,1]的一个随机数;x
i,j
为第i只麻雀在第j维中的位置信息;c
warn
为预警值(c
warn
∈[0,1]);c
safe
为安全值(c
safe
∈[0.5,1]);n为服从正态分布的随机数;l为1
×
n的矩阵,每个元素均为1;
[0022]
加入者的位置更新描述如下:
[0023][0024]
其中,x
p
为目前发现者所占据的最优位置;x
worst
为当前的全局最差位置;a为1
×
n的矩阵,每个元素随机赋值为1或
‑
1,且a
=a
t
(aa
t
)
‑1;
[0025]
假设意识到危险的麻雀初始位置在种群中随机产生,则改进意识到危险麻雀的位置更新公式为:
[0026][0027]
其中,x
best
为当前的全局最优位置;b为1
×
n的矩阵,每个元素随机赋值为1或
‑
1,且b
=b
t
(bb
t
)
‑1;ε为最小的常数,以避免分母出现零;p属于[
‑
1,1]的一个随机数,表示麻雀移动的方向;f
i
为当前麻雀个体的适应度值;f
b
为当前全局最佳适应度值;f
w
为当前全局最差的适应度值。
[0028]
进一步的,所述的elman动态网络是一种典型的递归神经网络,elman神经网络的学习算法如下:
[0029]
y(k)=g(ω3x(k))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0030]
x(k)=f(ω1x
c
(k) ω2(u(k
‑
1)))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0031]
x
c
(k)=x(k
‑
1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0032]
elman神经网络的学习指标函数采用误差平方和函数,即:
[0033][0034]
其中,u为r维输入向量;x
c
为n维反馈向量;y为m维的输出节点向量;x为n维的隐含层节点向量;w1为承接层到隐含层的连接权值;w2为输入层到隐含层的连接权值;w3隐含层到输出层的连接权值;f(*)为隐含层神经元的传递函数,常用s函数;g(*)为输出神经元的传递函数,是隐含层输出的线性组合。
[0035]
进一步的,步骤三所述的将训练样本带入到基于麻雀搜索算法优化的elman神经网络预测模型进行训练;训练流程的具体步骤如下:
[0036]
步骤3.1:创建elman神经网络模型,将用于训练神经网络的历史样本数据进行归一化预处理;归一化公式为:
[0037][0038]
得到的预测值再进行反归一化处理,反归一化公式如下:
[0039][0040]
其中,为归一化后的负荷值,x
i
为原始负荷值,x
min
、x
max
分别为最小值和最大值;为归一化的输出预测值,y
i
为反归一化的实际预测值;
[0041]
步骤3.2:初始化种群、迭代次数等相关参数,如设定麻雀种群中发现者的数量、意识到危险的麻雀所占种群的比例,以及麻雀搜索算法中安全阈值的设置;
[0042]
步骤3.3:选择适应度函数,对每个麻雀的适应度值进行排序。将发现者、加入者以及意识到危险的麻雀的位置按照公式(3)、(4)和(5)进行更新;
[0043]
适应度函数设计为测试集的绝对误差和:
[0044][0045]
步骤3.4:计算适应度值并更新麻雀位置;
[0046]
步骤3.5:如果优化算法满足结束条件,则将全局最优值赋予elman神经网络的权值、阈值,再对网络的局部进行优化;若未满足算法要求,则返回步骤3.3重新进行运算。
[0047]
有益效果
[0048]
本发明提出的一种基于麻雀搜索算法优化elman神经网络的短期负荷预测方法,与传统的现有技术相比较,其具有以下有益效果:
[0049]
(1)本技术方案经过麻雀搜索算法优化后的elman神经网络模型预测精度更优于原始elman神经网络的预测模型。原始elman神经网络是一种典型的递归神经网络,因其内部具有前馈、反馈结构,使其比普通神经网络具有更强的学习能力,非常适合于构建负荷预
测的非线性模型。然而神经网络初始参数的选取对于网络性能具有较大影响,利用麻雀搜索算法对神经网络的初始权值、阈值进行调整,可以使网络输出的误差减小,达到提高神经网络预测模型预测精度的目的。
[0050]
(2)本技术方案中的利用麻雀搜索算法对神经网络的初始权值、阈值进行调整,避免elman神经网络在训练过程中陷入局部最优,进一步提高e1man神经网络的泛化能力和适应能力,可以缩短elman神经网络对于权值和阈值的选定,加速预测进度。
[0051]
(3)本技术方案对原始麻雀搜索算法中的意识到危险麻雀位置更新公式进行改进,可使正处于种群边缘的意识到危险的麻雀更加快速且集中地向安全区域移动,使得算法完成寻优过程的迭代次数减小,同时提高预测精度。
附图说明
[0052]
图1是本发明中麻雀搜索算法训练流程图。
[0053]
图2是本发明中elman神经网络结构图。
[0054]
图3是本发明中elman神经网络训练流程图。
[0055]
图4是基于麻雀搜索算法优化elman神经网络的训练流程图。
[0056]
图5是原始elman和ssa
‑
elman预测绝对误差比较图。
[0057]
图6(a)是原始麻雀收敛曲线图。
[0058]
图6(b)是改进麻雀收敛曲线图。
具体实施方式
[0059]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
[0060]
一种基于麻雀搜索算法优化elman神经网络的短期负荷预测方法,该方法包括建立短期负荷预测模型;具体为建立基于麻雀搜索算法优化的elman神经网络预测模型,通过基于麻雀搜索算法优化的elman神经网络预测模型进行训练,输出最佳预测值;具体的优化步骤如下:
[0061]
步骤一:开始操作,建立短期负荷预测模型,获得训练样本;
[0062]
将前9日0
‑
22时每隔2小时测得的的历史负荷数据作为训练样本分别采用原始的elman神经网络预测模型和基于麻雀搜索算法优化的elman神经网络预测模型进行训练,预测第10日的企业电力负荷数值;模型中将每3天的负荷作为输入向量,第4天的负荷作为目标向量,这样可以得到6组训练样本,第10天的数据作为网络的测试样本。
[0063]
步骤二:建立基于麻雀搜索算法优化的elman神经网络预测模型;是在经典的elman动态网络中引入麻雀搜索算法,对经典的elman动态网络的训练过程做进一步的优化。
[0064]
图1为麻雀搜索算法的训练流程图;所述的麻雀搜索算法是一种群智能优化算法,主要受麻雀的觅食行为和反捕食行为而启发;麻雀搜索算法中m只麻雀组成的种群可表示为:
[0065][0066]
其中,n为待优化问题变量的维数,m为麻雀的数量,f表示适应度值,则所有麻雀的适应度值可以表示为:
[0067][0068]
上述麻雀通常可被分为发现者和加入者两种类型,在每次迭代的过程中,发现者的位置更新描述如下:
[0069][0070]
其中,t为当前迭代数;iter
max
为常数,表示最大的迭代次数;j可取值1,2,3,...,n;α属于(0,1]的一个随机数;x
i,j
为第i只麻雀在第j维中的位置信息;c
warn
为预警值(c
warn
∈[0,1]);c
safe
为安全值(c
safe
∈[0.5,1]);n为服从正态分布的随机数;l为1
×
n的矩阵,每个元素均为1。
[0071]
当c
warn
<c
safe
时:此时的觅食环境周围没有捕食者,发现者可以执行广泛的搜索操作。
[0072]
当c
warn
≥c
safe
时:表示种群中的一些麻雀已经发现了捕食者,并发出鸣叫提醒周围麻雀,此时它们都需要迅速飞往其它安全的地方进行觅食。
[0073]
上述加入者的位置更新描述如下:
[0074][0075]
其中,x
p
为目前发现者所占据的最优位置;x
worst
为当前的全局最差位置;a为1
×
n的矩阵,每个元素随机赋值为1或
‑
1,且a
=a
t
(aa
t
)
‑1。
[0076]
当i>m/2时:表明适应度值较低的第i个加入者没有获得食物,为了获得更多的能量,饥肠辘辘的加入者需要飞往其它地方觅食。
[0077]
假设意识到危险的麻雀初始位置在种群中随机产生,则改进意识到危险麻雀的位置更新公式为:
[0078][0079]
原始意识到危险麻雀的位置更新公式为:
[0080][0081]
其中,x
best
为当前的全局最优位置;b为1
×
n的矩阵,每个元素随机赋值为1或
‑
1,且b
=b
t
(bb
t
)
‑1;β为步长控制参数,服从均值为0,方差为1的正态分布的随机数;ε为最小的常数,以避免分母出现零;p属于[
‑
1,1]的一个随机数,表示麻雀移动的方向;f
i
为当前麻雀个体的适应度值;f
b
为当前全局最佳适应度值;f
w
为当前全局最差的适应度值。
[0082]
当f
i
>f
b
时:表示此时意识到危险的麻雀正处于种群的边缘,极易受到捕食者的攻击,为了获得更好的位置则需要迅速向安全区域移动。
[0083]
当f
i
=f
b
时:表示此时意识到危险的麻雀正处于种群的中间,为了尽量减少它们被捕食的风险则需要靠近其它的麻雀。
[0084]
图2为elman神经网络结构图。所述elman神经网络是一种典型的递归神经网络,因其内部具有前馈、反馈结构,使其比普通神经网络具有更强的学习能力,非常适合于构建负荷预测的非线性模型。然而神经网络初始参数的选取对于网络性能具有较大影响,为进一步提高e1man神经网络的泛化能力和适应能力,避免在训练过程中陷入局部最优,因此利用麻雀搜索算法对神经网络的初始权值、阈值进行调整,使网络输出的误差减小,达到提高神经网络预测模型预测精度的目的。
[0085]
图3为elman神经网络训练流程图。elman神经网络的学习算法如下:
[0086]
y(k)=g(ω3x(k))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0087]
x(k)=f(ω1x
c
(k) ω2(u(k
‑
1)))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0088]
x
c
(k)=x(k
‑
1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0089]
elman神经网络的学习指标函数采用误差平方和函数,即:
[0090][0091]
其中,u为r维输入向量;x
c
为n维反馈向量;y为m维的输出节点向量;x为n维的隐含层节点向量;w1为承接层到隐含层的连接权值;w2为输入层到隐含层的连接权值;w3隐含层到输出层的连接权值;f(*)为隐含层神经元的传递函数,常用s函数;g(*)为输出神经元的传递函数,是隐含层输出的线性组合。
[0092]
步骤三:将训练样本带入到基于麻雀搜索算法优化的elman神经网络预测模型进行训练;
[0093]
图4为基于麻雀搜索算法优化elman神经网络的训练流程图。该流程具体步骤如下:
[0094]
步骤3.1:创建elman神经网络模型,将用于训练神经网络的历史样本数据进行归一化预处理。归一化公式为:
[0095][0096]
得到的预测值再进行反归一化处理,反归一化公式如下:
[0097][0098]
其中,为归一化后的负荷值,x
i
为原始负荷值,x
min
、x
max
分别为最小值和最大值。为归一化的输出预测值,y
i
为反归一化的实际预测值。
[0099]
步骤3.2:初始化种群、迭代次数等相关参数,如设定麻雀种群中发现者的数量、意识到危险的麻雀所占种群的比例,以及麻雀搜索算法中安全阈值的设置。可选的,种群总数量设置为41;最大迭代次数设置为50;安全阈值设置为0.6;发现者占总体的比例设置为0.7,剩下的为加入者;意识到危险的麻雀所占种群的比例设置为0.2。
[0100]
步骤3.3:选择适应度函数,对每个麻雀的适应度值进行排序。将发现者、加入者以及意识到危险的麻雀的位置按照公式(3)、(4)和(5)进行更新。
[0101]
适应度函数设计为测试集的绝对误差和:
[0102][0103]
步骤3.4:计算适应度值并更新麻雀位置。
[0104]
步骤3.5:如果优化算法满足结束条件,则将全局最优值赋予elman神经网络的权值、阈值,再对网络的局部进行优化。若未满足算法要求,则返回步骤3.3重新进行运算。
[0105]
步骤四:将全局最优值赋予elman网络的权值和阈值;
[0106]
步骤五:elman神经网络进行局部优化:样本值以及步骤四中得到的权值和阈值经过输入层、隐含层、承接层以及输出层的计算输出,计算公式如(6)、(7)和(8)所示,其中,输入层的单元仅起信号传输作用,输出层单元起线性加权作用。断误差是否在允许范围内,若否则对权值进行更新,再次计算该步骤,若是则进行下一步。
[0107]
步骤六:最终预测模型输出最佳预测值;结束操作。
[0108]
图5为本技术提供的原始elman和ssa
‑
elman预测绝对误差比较图。可见经过麻雀搜索算法优化后的elman神经网络模型预测效果明显优于原始elman神经网络预测模型。这是因为麻雀搜索算法对elman神经网络的各层连接权值和阈值进行了优化,之后神经网络自身再次局部寻优后,预测模型的运算效率和预测精度得到了显著的提高,因此表现出更高的精确度。
[0109]
图6(a)为本技术提供的原始麻雀收敛曲线图,图6(b)为本技术提供的改进麻雀收敛曲线图。在图6(a)中,第12次迭代时麻雀搜索算法已经完成寻优过程。而在图6(b)中,第4次迭代时改进的麻雀搜索算法已完成寻优过程,因此可见改进后的ssa能够使得算法完成寻优过程的迭代次数减小,加快收敛。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。