1.本发明涉及数据处理技术领域,具体涉及一种强化自注意力的债券交易意图识别系统。
背景技术:
2.文本意图识别在深度学习领域已经是一个成熟的算法技术。它也成功的在各种业务场景应用落地。在金融的债券交易行业中,往往是需要精确且高效的沟通才能完成每笔订单的成交。因此通过文本意图识别的技术,对交易员的文本话术进行理解并解析,可以辅助他们更好更有效的沟通,从而提升他们的业务效率。
3.现有技术,文本意图识别的算法有很多种类,较为传统的深度学习算法有textcnn、lstm、gru以及他们之间的组合模型等,这些模型通常在语意的深度理解上有一定的局限性。近年来比较流行的算法主要有bert、gpt等预训练模型,这些算法通过预训练学习了海量的文本信息,能够大大提升模型对句子的表征能力,有效的提高了模型对文本的语义理解,但仍存在以下几点不足:
4.在金融债券交易等私有领域,有很多约定俗成的隐性逻辑,现有的技术(是按照通用的规范文本数据来训练的;往往不能很好理解和识别这种私有域的文本意图。首先是语法结构问题,交易文本大部分不是标准的含主谓宾结构的常规文本。如质押式回购中的押券信息交易文本:“押111796821 15南山集scp001 6110w 74%810w”。不带标准的语法结构,基于通用的规范文本训练的模型很难理解这句话的意图。
5.其次是在意图识别任务中,经常将会出现一句话中,大部分文本为非重要文本,仅少量字符对整句意图起决定性的作用,一个字的差别即改变文本意图。如交易中的文本信息:【隔夜改押:111893544 16xx港scp002】和【隔夜押111893544 16xx港scp002】。两句话只差一个“改”字,但是两句话是不同的意图,第一句是“改券”意图,第二句是“押券”意图。
6.现有的深度学习算法和预训练模型,都无法很好地对这种类型的文本进行embedding,也很难学习训练泛化性较好的模型。采用收集大量基于业务领域的文本进行fine
‑
tune训练的方案,则需要相当大的成本。
技术实现要素:
7.本发明的目的在于针对现有技术中不足与缺点,提供一种强化自注意力的债券交易意图识别系统,实现了对金融债券交易信息的意图识别任务,在金融业务中达到98%以上的准确率,基本满足商用要求。
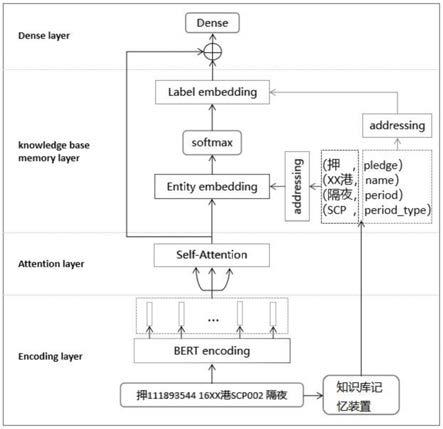
8.为实现上述目的,本发明采用以下技术方案是:一种强化自注意力的债券交易意图识别系统,它包括以下具体流程:构建一个知识库模块来存储预处理的关系库,针对债券交易的预料特点,主要存储债券要素和意图的关系信息;在编码阶段利用预训练的encoding给文本一个初始化编码,并在后续连接一个self
‑
attention的自注意力模块,让模型学习文本中各个字词成分不同的权重;通过寻址在知识库存储记忆模块找到相关的词
或字的关系作为先验知识加入到模型训练,引导神经网络学习更深层次结构关系;将提取的结果分别进行实体部分寻址编码以及标签寻址编码,然后结果同attention的输出进行加权,得到的embedding结果连接到全连接层输出结果。
9.进一步的,所述知识库存储编码模块具体包括以下流程:基于操作人员的梳理,建立关系知识库,包括并不限于[实体—意图]、[实体—类别]的要素关系对,同时构建数据存储装置,存储相应的关系信息;采用word2vec等预训练模型对关系对的信息进行编码,转化为固定维度的字和词向量;建立索引信息对,通过字符和词可以直接获取字符和对应意图/类别的向量编码。
[0010]
进一步的,所述编码层模块具体包括以下流程:采用bert的预训练模型对文本进行字符的特征编码,转化为固定维度的字向量;同时对文本进行字符和结合金融业务逻辑的分词切割,利用知识库存储编码模块获的索引信息对,获取字符和分词对应的字符/词编码和对应关系编码。
[0011]
进一步的,所述自注意力层模块:采用已有的self
‑
attention模块,为了模型能够学习token之间的权重分布,在得到文本encoding之后,连接一个self
‑
attention网络,计算公式为:其中query
‑
key
‑
value的值相等且都为输入的文本编码。
[0012]
进一步的,所述知识编码和注意力的融合层模块:在没有大量训练数据的情况下,attention对关联词权重的学习能力是有限的;首先将编码层知识库存储编码模块获得的实体的字符和分词编码,得到的结果乘以一个可训练的随机初始化矩阵,得到的结果再与自注意力层attention的结果进行dot softmax计算,得到一个相关性概率矩阵,用于增强attention对先验知识的训练学习,其次将知识库存储编码模块获得的实体对应关系的分词编码和相关性概率矩阵进行multiply计算,获得蕴含文本相关的先验知识的向量编码。
[0013]
进一步的,所述输出层:用知识编码和注意力的融合层模块的向量输出与自注意力层模块的attention向量结果进行加权,即得到了包含相关先验知识的预训练句向量编码,并将结果连接dense层,得到模型意图识别的分类类别。
[0014]
采用上述技术方案后,本发明有益效果为:实现了对金融债券交易信息的意图识别任务,在金融业务中达到98%以上的准确率,基本满足商用要求。
附图说明
[0015]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0016]
图1是本发明的模型整体架构图。
具体实施方式
[0017]
参看图1所示,本具体实施方式采用的技术方案是:它包括以下具体流程:构建一个知识库模块来存储预处理的关系库,针对债券交易的预料特点,主要存储债券要素和意
图的关系信息;在编码阶段利用预训练的encoding给文本一个初始化编码,并在后续连接一个self
‑
attention的自注意力模块,让模型学习文本中各个字词成分不同的权重;通过寻址在知识库存储记忆模块找到相关的词或字的关系作为先验知识加入到模型训练,引导神经网络学习更深层次结构关系;将提取的结果分别进行实体部分寻址编码以及标签寻址编码,然后结果同attention的输出进行加权,得到的embedding结果连接到全连接层输出结果。
[0018]
进一步的,所述知识库存储编码模块具体包括以下流程:基于操作人员的梳理,建立关系知识库,包括并不限于[实体—意图]、[实体—类别]的要素关系对,同时构建数据存储装置,存储相应的关系信息;采用word2vec等预训练模型对关系对的信息进行编码,转化为固定维度的字和词向量;建立索引信息对,通过字符和词可以直接获取字符和对应意图/类别的向量编码。
[0019]
进一步的,所述编码层模块具体包括以下流程:采用bert的预训练模型对文本进行字符的特征编码,转化为固定维度的字向量;同时对文本进行字符和结合金融业务逻辑的分词切割,利用知识库存储编码模块获的索引信息对,获取字符和分词对应的字符/词编码和对应关系编码。
[0020]
进一步的,所述自注意力层模块:采用已有的self
‑
attention模块,为了模型能够学习token之间的权重分布,在得到文本encoding之后,连接一个self
‑
attention网络,计算公式为:其中query
‑
key
‑
value的值相等且都为输入的文本编码。
[0021]
进一步的,所述知识编码和注意力的融合层模块:在没有大量训练数据的情况下,attention对关联词权重的学习能力是有限的;首先将编码层知识库存储编码模块获得的实体的字符和分词编码,得到的结果乘以一个可训练的随机初始化矩阵,得到的结果再与自注意力层attention的结果进行dot softmax计算,得到一个相关性概率矩阵,用于增强attention对先验知识的训练学习,其次将知识库存储编码模块获得的实体对应关系的分词编码和相关性概率矩阵进行multiply计算,获得蕴含文本相关的先验知识的向量编码。
[0022]
进一步的,所述输出层:用知识编码和注意力的融合层模块的向量输出与自注意力层模块的attention向量结果进行加权,即得到了包含相关先验知识的预训练句向量编码,并将结果连接dense层,得到模型意图识别的分类类别。
[0023]
注:拓展技术特征及应用场景:
[0024]
1.本系统采用的是bert预训练模型得到文本编码,可采用其他向量化的方式或未来更新的编码技术。
[0025]
2.当前模型用于金融债券领域的意图识别任务,本方案可以扩展到其他的领域或者类似的实体项目中。
[0026]
3.本系统提供的将经验知识表征为[字符—标签]的形式,并且采用字符编码和标签编码分段融合到attention的机制,能够自动学习文本间的词汇相关性,是基于预训练编码结合先验知识表征的一种联合编码方式,可在其他类似的算法任务上应用。
[0027]
采用上述技术方案后,本发明有益效果为:实现了对金融债券交易信息的意图识别任务,在金融业务中达到98%以上的准确率,基本满足商用要求。
[0028]
以上所述,仅用以说明本发明的技术方案而非限制,本领域普通技术人员对本发明的技术方案所做的其它修改或者等同替换,只要不脱离本发明技术方案的精神和范围,均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。