1.本发明涉及一种物流园入园作业车辆的调度方法,特别是一种基于层次分析法的物流园车辆动态排队方法。
背景技术:
2.在传统的物流园车辆调度系统中,车辆的入园排队顺序是由操作人员现场进行人工安排,遵循先到先排的准则,同时需要考虑入场的取货点,特殊用户的优先安排等因素。因此传统的物流园车辆入园顺序依赖现场工作人员的工作经验,效率低下,错误率高,缺乏整体安排,时常造成园区车辆入园顺序混乱。传统的物流园车辆排队顺序安排,客户满意度低,由于没有完备的排队规范,人为支配权高,插队现象严重。同时由于先到先排的机制,造成物流厂区入口经常为了抢位产生堵塞现象,同时也大大加大了客户的等待时间,需要对现有的模式进行优化,将车辆分配到不同时间段,提高取货效率和客户满意度。
3.申请号为:cn201910832747.6,名称为:运粮车辆作业队列融合及复合提醒的方法。该方法是运粮车辆预约排队,利用权重排队法结合预约时间顺序计算车辆的排队顺序。根据粮库的出入库作业流程。对于权重排队法,是根据车辆的登记类型、车辆类型、客户类型、粮食类型等设置权重,由实际值乘以权重得到车辆的排队顺序。该方法权重是单一的,不能适应复杂的取货情况。申请号为:cn201811060342.7,名称为:物流在线调度方法及系统。该方法是实时获取车辆和货物的位置信息,形成提货单,根据所述车辆类别对应的车辆考核排名确定出车名单。提升物流质量和客户满意度。该方法没有考虑到时间序列,造成货单派发时效性不足。
技术实现要素:
4.本发明的目的在于克服上述现有技术中的不足之处,提出一种基于层次分析法的物流园车辆动态排队的方法。
5.本发明是通过如下方式实现的:
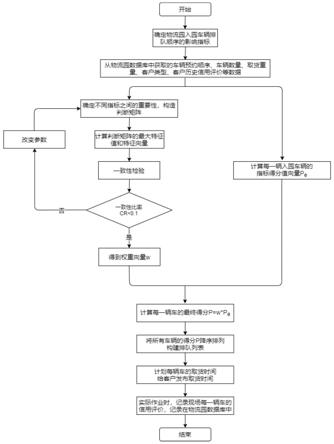
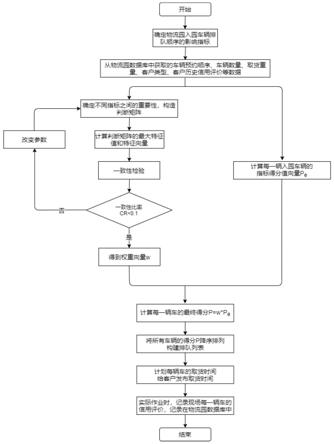
6.一种基于层次分析法的物流园车辆动态排队的方法,包括以下步骤:
7.s1获取数据:从物流园数据库中获取当天物流园入园的车辆预约顺序,车辆数量、当天车辆取货重量的变异系数、客户类型、客户信用评价数据;
8.s2构建指标:根据物流园实际作业情况,选取预约顺序、客户类型、当天车辆取货重量的变异系数、客户信用评价作为影响排队顺序的四个指标;
9.s3构造两两比较判断矩阵,对比不同指标之间的重要程度,采用1
‑
9互反性标度理论量化;
10.s4:构建两两比较判断矩阵为:
[0011][0012]
判断矩阵表示与该层因素对上一层因素的相对重要性,其中a
11
表示自身重要性的比较,所以a
11
等于1,及判断矩阵对角线元素均为1,a矩阵为预约顺序、客户类型、当天车辆取货重量的变异系数、客户信用评价矩阵,其中,a
21
表示客户类型对比预约顺序的重要性,a
31
表示当天车辆取货重量的变异系数对比预约顺序的重要性,a
41
表示客户信用评价对比预约顺序的重要性,其他系数以此类推;
[0013]
s5:根据从物流园数据库获取的数据,构建一个动态的判断矩阵,计算最大特征值和最大特征向量,获得权重向量,进行一致性检验,确定每个指标的权重;
[0014]
s6:确定每个指标的权重后,根据物流园数据库的数据,设定每个指标的得分值计算;
[0015]
s7:最后将所有车辆的排队顺序得分进行降序排列,得到车辆排队顺序表sc,按顺序给每辆车分配不同的时间段入园取货。
[0016]
进一步,所述s3的所述采用1
‑
9互反性标度理论量化为:1:同等重要,3:稍微重要,5:比较重要,7:很重要,9:绝对重要,2、4、6和8:对应中间状态的值。
[0017]
进一步,所述s5具体步骤如下:
[0018]
s51:预约顺序和客户类型的两两判断:根据物流园的销售现状,客户类型分为三种,普通客户,优先客户,重要客户;三者的取货优先级依次递增,但为了维持客户排队的相对公平性,当非普通客户n
sp
占总客户数n
num
比重越高时,预约顺序的重要性越大,当非普通客户占比越低时,客户类型的重要性可以提升;物流园能通过设置不同的占比阈值n
set
,来根据实际需要调节两者关系,其表达式为:
[0019][0020][0021]
式中:type为客户类型,order为预约顺序,n
sp
为非普通客户,n
num
为总客户数,n
set
为占比阈值,α,β,b为可变参数,物流园企业可根据实际工作情况调整参数,从而调整预约顺序和客户类型的两两相关程度;表示向上取整。
[0022]
s52:当天车辆取货重量的变异系数与其他指标的两两判断:车辆取货重量的变异系数s
n
,表示整个取货重量的数据离散程度,变异系数越小,数据的离散程度越小,取货重
量集中在一个数据段,此时如果取货重量中存在较偏离均值的数据,对队伍次序的影响程度较高,相反变异系数越大,取货重量分布的较为分散,较为偏离均值的数据对队伍次序影响不大,变异系数和预约顺序、客户类型的两两判断表达式为:
[0023][0024][0025]
式中:distribution为当天车辆取货重量的变异系数,type为客户类型,order为预约顺序,sn为车辆取货重量的变异系数,n
sp
为非普通客户,n
num
为总客户数,n
set
为占比阈值,α,β为可变参数,物流园企业可根据实际工作情况调整参数,从而调整取货重量的变异系数和其他指标的两两相关程度;表示向上取整。
[0026]
s53信用评价指标和其他指标的两两判断表达方式为:
[0027][0028][0029][0030]
式中:credit为客户信用评价,distribution为当天车辆取货重量的变异系数,type为客户类型,order为预约顺序,sn为车辆取货重量的变异系数,α,β,θ为可变参数,物流园企业可根据实际工作情况调整参数,从而调整信用评价指标和其他指标的两两相关程度;表示向上取整。
[0031]
s54通过上述方法构建出了完整的判断矩阵a后,计算得到最大特征值λ
max
和最大特征向量v
t
;
[0032]
av=λ
maxv
[0033]
v
t
=[u
1 u2ꢀ…ꢀ
u
n
],
[0034]
式中,u
i
为最大特征值λ
max
对应的特征向量
[0035]
s55将最大特征向量归一化,得到权重向量w,表达式如下:
[0036][0037]
式中,ui为最大特征值λ
max
对应的特征向量;
[0038]
s56为了验证构建的判断矩阵是否符合逻辑,需要进行一致性检验;计算一致性指标ci,ci=0表示完全一致,ci越大越不一致,具体计算表达式如下:
[0039][0040]
式中,n为判断矩阵的阶数,λmax为最大特征值;
[0041]
s57根据判断矩阵的阶数n,查找对应的平均随机一致性指标ri,n=1,ri=0;n=2,ri=0;n=3,ri=0.58;n=4,ri=0.90;n=5,ri=1.12;n=6,ri=1.24;n=7,ri=1.32;n=8,ri=1.41;n=9,ri=1.45;
[0042]
s58计算一致性比例cr=ci/ri,当cr<0.1,认为矩阵的一致性是可以接受的,当cr>0.1,需要调整上述计算判断矩阵公式中的参数,直到通过一致性检验,确定最后的权重。
[0043]
进一步,所述s6具体为
[0044]
s61:预约顺序p
order
,设置最高得分p
max
和基础得分p
b
,根据每天的车辆入园数量n
num
,按预约位次n
w
越前,得分越高的原则,设定的得分值计算如下:
[0045][0046]
s62:客户类型p
type
,客户类型t分为三种,普通客户p
low
,优先客户p
mid
,重要客户p
high
,标号分别为1,2,3;三者的取货优先级依次递增,优先级越高,得分越高,设定的得分值计算如下:
[0047][0048]
s63:当天车辆取货重量的变异系数p
distribution
,计算每一个车辆取货重量q
i
和所以车辆取货重量均值的差,差值越接近0,得分在基础分上下浮动,当差值为正且离0越远时,证明取货重量远大平均数,得分将减少,安排在计划时间的后段,当差值为负数且离0越来越远,证明取货重量远小于平均数,得分将增加,安排在计划周期前段,设定的得分值计算如下:
[0049][0050]
s64:客户信用评价p
credit
,记录的违约的次数n
d
,α为可变参数,物流园企业可根据实际的工作情况调整参数,从而调整客户信用评价得分值基数。设定的得分值计算如下:
[0051][0052]
s65:将每一辆车的得分值p
e
=[p
order p
type p
distribution p
credit
]乘上对应的权重向量w,得到每一辆车的最终排队顺序得分值p,对应如下:
[0053]
p=w*p
e
。
[0054]
本发明的有益效果在于:建立了物流园车辆入园的有序排队顺序,提高了入园取货效率,同时能提前发布给客户取货时间,减少客户等待时间,提升客户满意度。根据动态的权重调整步骤,可以根据物流园的数据进行权重指标的动态调整,增加整个系统的适用性。建立了客户信用评价体系,能规范企业和客户的行为,促进整个产业的良性循环。
附图说明
[0055]
图1为本发明的流程示意图;
[0056]
图2为本发明所述动态权重算法流程图。
具体实施方式
[0057]
下面结合附图和本发明的实例,对本发明作进一步的描述。
[0058]
一种基于层次分析法的物流园车辆动态排队的方法,包括以下步骤:
[0059]
s1获取数据:从物流园数据库中获取当天物流园入园的车辆预约顺序,车辆数量、当天车辆取货重量的变异系数、客户类型、客户信用评价数据;
[0060]
s2构建指标:根据物流园实际作业情况,选取预约顺序、客户类型、当天车辆取货重量的变异系数、客户信用评价作为影响排队顺序的四个指标;
[0061]
s3构造两两比较判断矩阵,对比不同指标之间的重要程度,采用1
‑
9互反性标度理论量化;所述s3的所述采用1
‑
9互反性标度理论量化为:1:同等重要,3:稍微重要,5:比较重要,7:很重要,9:绝对重要,2、4、6和8:对应中间状态的值;
[0062]
s4:构建两两比较判断矩阵为:
[0063][0064]
判断矩阵表示与该层因素对上一层因素的相对重要性,其中a
11
表示自身重要性的比较,所以a
11
等于1,及判断矩阵对角线元素均为1,a矩阵为预约顺序、客户类型、当天车辆取货重量的变异系数、客户信用评价矩阵,其中,a
21
表示客户类型对比预约顺序的重要性,a
31
表示当天车辆取货重量的变异系数对比预约顺序的重要性,a
41
表示客户信用评价对比预约顺序的重要性,其他系数以此类推;
[0065]
s5:根据从物流园数据库获取的数据,构建一个动态的判断矩阵,计算最大特征值和最大特征向量,获得权重向量,进行一致性检验,确定每个指标的权重;
[0066]
,所述s5具体步骤如下:
[0067]
s51:预约顺序和客户类型的两两判断:根据物流园的销售现状,客户类型分为三种,普通客户,优先客户,重要客户;三者的取货优先级依次递增,但为了维持客户排队的相对公平性,当非普通客户n
sp
占总客户数n
num
比重越高时,预约顺序的重要性越大,当非普通客户占比越低时,客户类型的重要性可以提升;物流园能通过设置不同的占比阈值n
set
,来根据实际需要调节两者关系,其表达式为:
[0068]
[0069][0070]
式中:type为客户类型,order为预约顺序,n
sp
为非普通客户,n
num
为总客户数,n
set
为占比阈值,α,β,b为可变参数,物流园企业可根据实际工作情况调整参数,从而调整预约顺序和客户类型的两两相关程度;表示向上取整。
[0071]
s52:当天车辆取货重量的变异系数与其他指标的两两判断:车辆取货重量的变异系数s
n
,表示整个取货重量的数据离散程度,变异系数越小,数据的离散程度越小,取货重量集中在一个数据段,此时如果取货重量中存在较偏离均值的数据,对队伍次序的影响程度较高,相反变异系数越大,取货重量分布的较为分散,较为偏离均值的数据对队伍次序影响不大,变异系数和预约顺序、客户类型的两两判断表达式为:
[0072][0073][0074]
式中:distribution为当天车辆取货重量的变异系数,type为客户类型,order为预约顺序,sn为车辆取货重量的变异系数,n
sp
为非普通客户,n
num
为总客户数,n
set
为占比阈值,α,β为可变参数,物流园企业可根据实际工作情况调整参数,从而调整取货重量的变异系数和其他指标的两两相关程度;表示向上取整。
[0075]
s53信用评价指标和其他指标的两两判断表达方式为:
[0076][0077][0078][0079]
式中:credit为客户信用评价,distribution为当天车辆取货重量的变异系数,type为客户类型,order为预约顺序,sn为车辆取货重量的变异系数,α,β,θ为可变参数,物流园企业可根据实际工作情况调整参数,从而调整信用评价指标和其他指标的两两相关程度;表示向上取整。
[0080]
s54通过上述方法构建出了完整的判断矩阵后,计算得到最大特征值λ
max
和最大特征向量v
t
;
[0081]
av=λ
maxv
[0082]
v
t
=[u
1 u2ꢀ…ꢀ
u
n
],
[0083]
式中,u
i
为最大特征值λ
max
对应的特征向量
[0084]
s55将最大特征向量归一化,得到权重向量w,表达式如下:
[0085][0086]
式中,ui为最大特征值λ
max
对应的特征向量;
[0087]
s56为了验证构建的判断矩阵是否符合逻辑,需要进行一致性检验;计算一致性指标ci,ci=0表示完全一致,ci越大越不一致,具体计算表达式如下:
[0088][0089]
式中,n为判断矩阵的阶数,λmax为最大特征值;
[0090]
s57根据判断矩阵的阶数n,查找对应的平均随机一致性指标ri,n=1,ri=0;n=2,ri=0;n=3,ri=0.58;n=4,ri=0.90;n=5,ri=1.12;n=6,ri=1.24;n=7,ri=1.32;n=8,ri=1.41;n=9,ri=1.45;
[0091]
s58计算一致性比例cr=ci/ri,当cr<0.1,认为矩阵的一致性是可以接受的,当cr>0.1,需要调整上述计算判断矩阵公式中的参数,直到通过一致性检验,确定最后的权重。
[0092]
s6:确定每个指标的权重后,根据物流园数据库的数据,设定每个指标的得分值计算;
[0093]
s61:预约顺序p
order
,设置最高得分p
max
和基础得分p
b
,根据每天的车辆入园数量n
num
,按预约位次n
w
越前,得分越高的原则,设定的得分值计算如下:
[0094][0095]
s62:客户类型p
type
,客户类型t分为三种,普通客户p
low
,优先客户p
mid
,重要客户p
high
,标号分别为1,2,3;三者的取货优先级依次递增,优先级越高,得分越高,设定的得分值计算如下:
[0096][0097]
s63:当天车辆取货重量的变异系数p
distribution
,计算每一个车辆取货重量q
i
和所以车辆取货重量均值的差,差值越接近0,得分在基础分上下浮动,当差值为正且离0越远时,证明取货重量远大平均数,得分将减少,安排在计划时间的后段,当差值为负数且离0越来越远,证明取货重量远小于平均数,得分将增加,安排在计划周期前段,设定的得分值计算如下:
[0098][0099]
s64:客户信用评价p
credit
,记录的违约的次数n
d
,α为可变参数,物流园企业可根据
实际的工作情况调整参数,从而调整客户信用评价得分值基数。设定的得分值计算如下:
[0100][0101]
s65:将每一辆车的得分值p
e
=[p
order p
type p
distribution p
credit
]乘上对应的权重向量w,得到每一辆车的最终排队顺序得分值p,对应如下:
[0102]
p=w*p
e
。
[0103]
s7:最后将所有车辆的排队顺序得分进行降序排列,得到车辆排队顺序表sc,按顺序给每辆车分配不同的时间段入园取货。
[0104]
具体实施例
[0105]
s1和s2从某钢铁厂云平台获取入园车辆总数量n
num
,车辆预约顺序y=(y1,y2,
…
,y
n
),车辆的取货重量k=(k1,k2,
…
,k
n
),客户的类型t=(t1,t2,..,t
n
),客户的信用评价c=(c1,c2,
…
,c
n
)等数据;
[0106]
s3案例获取的数据是总车辆5,车辆预约顺序y=(2,4,1,5,3),车辆取货重量k=(15,50,45,40,70),客户的类型t=(1,3,1,1,2),客户的信用评价c=(1,0,0,3,2);
[0107]
s4设定非普通车辆的占比阈值n
set
,这里设定n
set
=0.3;
[0108]
s4计算预约顺序和客户类型的两两重要性评分
[0109][0110]
s4计算取货重量的变异系数s
n
[0111][0112]
s4计算变异系数和预约顺序、客户类型的两两重要性评分
[0113][0114]
s4计算信用评价和其他指标间的两两重要性评分
[0115][0116]
s4得到的判断矩阵为
[0117][0118]
s5判断矩阵的最大特征值和特征向量为
[0119][0120]
s5验证判断矩阵的逻辑合理性,计算一致性比例cr值
[0121][0122]
通过一致性检验,构建的判断矩阵合理;
[0123]
s5归一化特征向量,得到权重向量w
[0124]
w=[0.5470.28480.11040.0577];
[0125]
s6根据数据,计算每辆车每一项的指标得分值p
e
[0126][0127]
s6计算每一辆车最终的总得分值
[0128]
p=w*pe
=
[83.92,83.87,85.29,73.01,80.71];
[0129]
s7确定最后的排序s
[0130]
s=三号车
→
一号车
→
二号车
→
五号车
→
四号车;
[0131]
s7根据钢铁厂的作业时间,分配每辆车的作业时间段,假设只有一个取货台的情况下:
[0132]
三号车8:00
‑
8:45一号车8:50
‑
9:05二号车9:10
‑
10:00五号车10:05
‑
11:15四号车11:20
‑
12:00
[0133]
本发明的有益效果在于:建立了物流园车辆入园的有序排队顺序,提高了入园取货效率,同时能提前发布给客户取货时间,减少客户等待时间,提升客户满意度。根据动态的权重调整步骤,可以根据物流园的数据进行权重指标的动态调整,增加整个系统的适用性。建立了客户信用评价体系,能规范企业和客户的行为,促进整个产业的良性循环。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。