一种基于lightgbm的月用气量预测方法及装置
技术领域
1.本发明属于燃气用气量预测技术领域,具体涉及一种基于lightgbm的月用气量预测方法及装置。
背景技术:
2.在燃气业务经营中,用户的购气和缴费行为不定期(一个月或数月)发生,同时燃气公司查表和生成账单的行为周期不完全固定,而财务收入确认以自然月为统计周期,需根据用户的购气数据和查表数据,结合外部数据,对每月每个用户的用气量和金额进行估计。传统方案是对销售数据使用统计分析法进行人工核算得到每个用户当月的用气量和金额。该方法存在以下缺陷:时间周期较长,人力负担较大;且由于燃气查表数据中存在较多的缺失和异常的情况,传统统计分析法很难保证其科学性,估计误差较高。
技术实现要素:
3.为了解决现有技术中存在的上述问题,本发明提供一种基于lightgbm的月用气量预测方法及装置。
4.为了实现上述目的,本发明采用以下技术方案。
5.第一方面,本发明提供一种基于lightgbm的月用气量预测方法,包括以下步骤:
6.初步确定与燃气用户月用气量有关的特征;
7.基于所述特征之间的相关性及所述特征与用户月用气量的相关性对所述特征进行筛选;
8.以筛选后的特征为输入、分别以壁挂炉用户月用气量和非壁挂炉用户月用气量为输出,构建基于lightgbm的预测模型;
9.获取历史数据,构建训练数据集,用训练好的模型对用户的月用气量进行预测。
10.进一步地,所述方法还包括:以同一特征的不同统计量以及不同统计量的组合作为新的特征,与其它特征一起进行筛选,所述统计量包括最大值、最小值、中值和平均值。
11.进一步地,对初步确定的特征进行筛选的方法包括:
12.计算任意一个特征与用户月用气量的相关系数,并按照相关系数从大到小的顺序排序;
13.删除相关系数小于第一阈值的特征;
14.计算剩余特征中任意两个特征之间的相关系数,对于相关系数大于第二阈值的两个特征,删除排序靠后的一个特征。
15.进一步地,所述方法还包括对历史数据进行重构的步骤:
16.根据用户每次购气的时间和购气量,计算每次购气时间对应的累计购气量;
17.默认每次购气时前一次购气用已用完,得到每次购气时间对应的累计用气量;
18.根据每次购气时间对应的累计用气量,采用插值法计算每月月末的累计用气量;
19.计算每相邻两个月末累计用气量的差,得到用户每个自然月的用气量。
20.进一步地,所述方法还包括对历史数据的缺失值进行补全的步骤:
21.获取查表数据缺失月份前一次和后一次的查表时间和燃气表读数;
22.计算两次燃气表读数的差值得到查表期间的用气量;
23.根据两次的查表时间和查表期间的用气量,按比例将所述用气量分配到缺失月份,从而得到缺失月份的用气量;可根据历史年份12个月用气量的比例进行分配,也可以按平均比例进行分配。
24.进一步地,所述方法还包括对历史用气量数据标准化的步骤,按下式计算每个用气量的标准化值:
[0025][0026]
式中,为第i个用气量x
i
的标准化值,i=1,2,
…
,n,n为用气量的数量。
[0027]
第二方面,本发明提供一种基于lightgbm的月用气量预测装置,包括:
[0028]
特征确定模块,用于初步确定与燃气用户月用气量有关的特征;
[0029]
特征筛选模块,用于基于所述特征之间的相关性及所述特征与用户月用气量的相关性对所述特征进行筛选;
[0030]
模型构建模块,用于以筛选后的特征为输入、分别以壁挂炉用户月用气量和非壁挂炉用户月用气量为输出,构建基于lightgbm的预测模型;
[0031]
用气量预测模块,用于获取历史数据,构建训练数据集,用训练好的模型对用户的月用气量进行预测。
[0032]
进一步地,所述装置还包括特征扩展模块,用于以同一特征的不同统计量以及不同统计量的组合作为新的特征,与其它特征一起进行筛选,所述统计量包括最大值、最小值、中值和平均值。
[0033]
进一步地,对初步确定的特征进行筛选的方法包括:
[0034]
计算任意一个特征与用户月用气量的相关系数,并按照相关系数从大到小的顺序排序;
[0035]
删除相关系数小于第一阈值的特征;
[0036]
计算剩余特征中任意两个特征之间的相关系数,对于相关系数大于第二阈值的两个特征,删除排序靠后的一个特征。
[0037]
进一步地,所述装置还包括数据重构模块,用于:
[0038]
根据用户每次购气的时间和购气量,计算每次购气时间对应的累计购气量;
[0039]
默认每次购气时前一次购气用已用完,得到每次购气时间对应的累计用气量;
[0040]
根据每次购气时间对应的累计用气量,采用插值法计算每月月末的累计用气量;
[0041]
计算每相邻两个月末累计用气量的差,得到用户每个自然月的用气量。
[0042]
与现有技术相比,本发明具有以下有益效果。
[0043]
本发明通过初步确定与燃气用户月用气量有关的特征,基于所述特征之间的相关性及所述特征与用户月用气量的相关性对所述特征进行筛选,以筛选后的特征为输入、分别以壁挂炉用户月用气量和非壁挂炉用户月用气量为输出,构建基于lightgbm的预测模
型,获取历史数据,构建训练数据集,用训练好的模型对用户的月用气量进行预测,实现了燃气用户月用气量的自动预测。本发明通过基于相关性对与用气量有关的特征进行筛选,并分别以壁挂炉用户月用气量和非壁挂炉用户月用气量为输出,建立预测模型,提高了预测模型的精度;通过构建基于lightgbm的预测模型,可提高模型的训练速度,进一步提高预测模型精度。
附图说明
[0044]
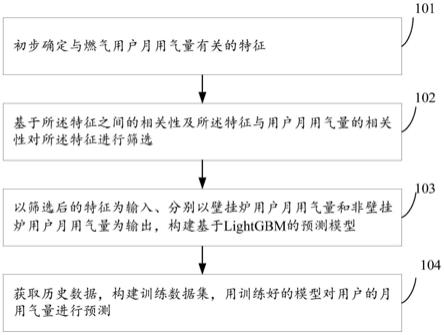
图1为本发明实施例一种基于lightgbm的月用气量预测方法的流程图。
[0045]
图2为本发明实施例一种基于lightgbm的月用气量预测装置的方框图。
具体实施方式
[0046]
为使本发明的目的、技术方案及优点更加清楚、明白,以下结合附图及具体实施方式对本发明作进一步说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0047]
图1为本发明实施例一种基于lightgbm的月用气量预测方法的流程图,包括以下步骤:
[0048]
步骤101,初步确定与燃气用户月用气量有关的特征;
[0049]
步骤102,基于所述特征之间的相关性及所述特征与用户月用气量的相关性对所述特征进行筛选;
[0050]
步骤103,以筛选后的特征为输入、分别以壁挂炉用户月用气量和非壁挂炉用户月用气量为输出,构建基于lightgbm的预测模型;
[0051]
步骤104,获取历史数据,构建训练数据集,用训练好的模型对用户的月用气量进行预测。
[0052]
本实施例中,步骤101主要用于初步确定与燃气用户月用气量有关的特征。要构建用气量的预测模型,须选取对用气量有影响的特征作为输入变量。为了不遗漏对用气量影响较大的特征,最初选取特征时,应尽量多地选取所有可能对用气量有影响的特征,比如当地气象(环境)因素、消费水平、居民生活习惯、用气类别、节假日和能源价格变化等。其中气象对用气量的影响最为明显,比如在冬季用气高峰期间气温的变化幅度。
[0053]
本实施例中,步骤102主要用于对初步确定的与用气量有关的特征进行筛选。由于与用气量有关的特征很多,不可能将所有特征都作为模型的输入变量,如果将对用气量影响不大的特征作为输入变量,不仅会使模型结构变得更加复杂,而且还会降低预测精度,因此需要进行特征筛选,删除大量影响不大的特征,只保留少数影响明显的特征。可通过计算各种特征与用气量的相关系数衡量它们对用气量的影响程度,相关系数的绝对值越大,表示相关程度越高;相关系数为负数时,表示该特征值的变化可能引起用气量相反方向的变化,这种关系叫做负相关。相关系数的绝对值与影响程度关系为:0.8
‑
1.0为极强相关,0.6
‑
0.8为强相关,0.4
‑
0.6为中等程度相关,0.2
‑
0.4为弱相关,0.0
‑
0.2为极弱相关或无相关。另外,还要考察各个特征之间的相关性,如果存在两个或多个特征的相关性较大,可只保留其中一个特征,删除其它几个特征。现有技术在进行特征筛选时,一般只考虑模型输入变量
与输出变量的相关性,没有考虑输入变量之间的相关性,使最后构建的模型不能达到最简、最有效。
[0054]
本实施例中,步骤103主要用于构建预测模型。经过上一步的特征筛选后,就得到了预测模型的输入变量,即以筛选后剩余的每个特征作为一个输入变量。预测模型的输出变量自然是用户的月用气量,由于不同类别用户用气规律有明显区别,如果对用户类别不加区分,只构建一个模型来预测所有用户的用气量,势必会造成很大的预测误差。为此,应先按照用气规律对用户进行分类,然后针对每个类别的用户分别构建预测模型。本实施例将用户分为壁挂炉用户和非壁挂炉用,分别以壁挂炉用户月用气量和非壁挂炉用户月用气量为输出构建预测模型。另外,要获得高精度的预测模型,需要海量的数据和标签对模型进行训练,耗时很大。为了提高模型的训练速度,减小训练耗时,本实施例基于lightgbm(light gradient boosting machine)构建预测模。lightgbm是由微软亚洲研究院在2017年1月提出的,lightgbm是一个实现gbdt(gradient boosting decision tree,梯度提升决策树)模型的优化框架。gbdt在每一次迭代过程中均需将全部数据遍历多次,实际使用过程中,电脑内存会限制每次读写数据的规模。lightgbm算法的应用确保了gbdt可以对大规模数据进行快速训练,从而大大扩大了gbdt的实际应用范围和应用领域。相较于传统的gbdt模型,lightgbm模型在以下两个方面作了较大改进:一是在划分点搜索上,选用直方图算法;二是在树木生长算法上,选用带深度限制的leaf
‑
wise策略。lightgbm模型具有以下优点:内存占用低;预测精度更高;运行速度快;支持并行化学习;可处理大规模数据。因此,本实施例基于lightgbm构建预测模型,可提高模型训练速度,进一步提高预测精度。
[0055]
本实施例中,步骤104主要用于对用户的月用气量进行预测。本实施例通过获取历史数据构建训练数据集,利用训练数据集对预测模型进行训练,用训练好的模型对用户的月用气量进行预测。
[0056]
作为一可选实施例,所述方法还包括:以同一特征的不同统计量以及不同统计量的组合作为新的特征,与其它特征一起进行筛选,所述统计量包括最大值、最小值、中值和平均值。
[0057]
本实施例给出了对特征进行特征扩展的一种技术方案。实践表明,采用同一特征不同的统计量作为输入变量得到的预测模型的效果并不一样,比如气温,它的统计量可以是日最高温度、日最低温度和日平均温度,这3个统计量与用气量的相关程度并不一致。更有趣儿的是,将这3个统计量中的2个或3个进行组合,将组合后的量作为模型的输入变量比将单个统计量作为输入变量效果更佳。为了得到最有效的输入变量,本实施例对特征进行扩展,将同一特征的不同统计量,以及不同统计量的组合作为新的特征,然后将它们与其它特征一起进行筛选,确定模型最后的输入变量。
[0058]
作为一可选实施例,对初步确定的特征进行筛选的方法包括:
[0059]
计算任意一个特征与用户月用气量的相关系数,并按照相关系数从大到小的顺序排序;
[0060]
删除相关系数小于第一阈值的特征;
[0061]
计算剩余特征中任意两个特征之间的相关系数,对于相关系数大于第二阈值的两个特征,删除排序靠后的一个特征。
[0062]
本实施例给出了特征筛选的一种技术方案。如前述,本实施例基于相关性进行特
征筛选。本实施例涉及的相关性有两种:一种是待筛选特征与用气量的相关性;另一种是待筛选特征之间的相关性。首先,根据待筛选特征与用气量的相关性大小,删除相关性较小的特征,理由是这些特征对用气量的影响较小;然后,根据任意两个筛选后的特征之间的相关性,删除相关性较大的两个特征中的一个特征,因为相关性较大的两个特征是重复的,只保留其中一个即可。本实施例删除的是与用气量相关性较小的一个特征。
[0063]
作为一可选实施例,所述方法还包括对历史数据进行重构的步骤:
[0064]
根据用户每次购气的时间和购气量,计算每次购气时间对应的累计购气量;
[0065]
默认每次购气时前一次购气用已用完,得到每次购气时间对应的累计用气量;
[0066]
根据每次购气时间对应的累计用气量,采用插值法计算每月月末的累计用气量;
[0067]
计算每相邻两个月末累计用气量的差,得到用户每个自然月的用气量。
[0068]
本实施例给出了对历史数据进行重构的一种技术方案。由于用户的缴费时间不固定,而预测模型需要对每个自然月(从月初到月末)的用气量进行预测,因此需要对缴费数据进行重构,得到每个自然月的用气量。本实施例是根据用户每次的购气量,并假设每次购气时前一次购气用已用完,计算每次购气时间对应的累计用气量。有了每次购气时间对应的累计用气量,采用线性插值法就可以计算月末的累计用气量,公式如下:
[0069][0070]
式中,y为相邻两次购气期间的一个月末的累计用气量,a、b分别为相邻两次购气时间对应的累计用气量,δc为所述月末与前面一次购气时间的时间差,为δd相邻两次购气的时间差。
[0071]
有了每个月末的累计用气量,计算每相邻两个月末的累计用气量的差,就可以得到每个自然月的用气量。
[0072]
作为一可选实施例,所述方法还包括对历史数据的缺失值进行补全的步骤:
[0073]
获取查表数据缺失月份前一次和后一次的查表时间和燃气表读数;
[0074]
计算两次燃气表读数的差值得到查表期间的用气量;
[0075]
根据两次的查表时间和查表期间的用气量,按比例将所述用气量分配到缺失月份,从而得到缺失月份的用气量;可根据历史年份12个月用气量的比例进行分配,也可以按平均比例进行分配。
[0076]
本实施例给出了缺失数据补全的一种技术方案。由于部分燃气表依赖于人工查表,因各种情况导致抄表员个别月份无法进行查表,造成数据缺失,故需要对这些月份用户的用气量进行缺失值补全。本实施例采取的方法是:针对查表数据缺失的月份,获取缺失月份前的最后一次查表和缺失月份后的第一次查表数据(查表时间和燃气表读数);然后计算两次燃气表读数的差值得到查表期间的用气量;最后所述用气量按比例分配至缺失月份。如果该用户该用气性质下有完整的12个月的分配比例,则用该用户的比例进行缺失补全;否则,利用该用气性质下的平均比例,对缺失月份的耗气量进行补全。
[0077]
作为一可选实施例,所述方法还包括对历史用气量数据标准化的步骤,按下式计算每个用气量的标准化值:
[0078][0079]
式中,为第i个用气量x
i
的标准化值,i=1,2,
…
,n,n为用气量的数量。
[0080]
本实施例给出了对历史用气量数据进行标准化的一种技术方案。本实施例采用z
‑
score标准化方法,公式如上式,分子是标准化前的单个用气量与平均用气量的差,分母是用气量的标准差。如果采用标准化后的数据进行训练或预测,还要对预测结果进行逆变换。
[0081]
图2为本发明实施例一种基于lightgbm的月用气量预测装置的组成示意图,所述装置包括:
[0082]
特征确定模块11,用于初步确定与燃气用户月用气量有关的特征;
[0083]
特征筛选模块12,用于基于所述特征之间的相关性及所述特征与用户月用气量的相关性对所述特征进行筛选;
[0084]
模型构建模块13,用于以筛选后的特征为输入、分别以壁挂炉用户月用气量和非壁挂炉用户月用气量为输出,构建基于lightgbm的预测模型;
[0085]
用气量预测模块14,用于获取历史数据,构建训练数据集,用训练好的模型对用户的月用气量进行预测。
[0086]
本实施例的装置,可以用于执行图1所示方法实施例的技术方案,其实现原理和技术效果类似,此处不再赘述。后面的实施例也是如此,均不再展开说明。
[0087]
作为一可选实施例,所述装置还包括特征扩展模块,用于以同一特征的不同统计量以及不同统计量的组合作为新的特征,与其它特征一起进行筛选,所述统计量包括最大值、最小值、中值和平均值。
[0088]
作为一可选实施例,对初步确定的特征进行筛选的方法包括:
[0089]
计算任意一个特征与用户月用气量的相关系数,并按照相关系数从大到小的顺序排序;
[0090]
删除相关系数小于第一阈值的特征;
[0091]
计算剩余特征中任意两个特征之间的相关系数,对于相关系数大于第二阈值的两个特征,删除排序靠后的一个特征。
[0092]
作为一可选实施例,所述装置还包括数据重构模块,用于:
[0093]
根据用户每次购气的时间和购气量,计算每次购气时间对应的累计购气量;
[0094]
默认每次购气时前一次购气用已用完,得到每次购气时间对应的累计用气量;
[0095]
根据每次购气时间对应的累计用气量,采用插值法计算每月月末的累计用气量;
[0096]
计算每相邻两个月末累计用气量的差,得到用户每个自然月的用气量。
[0097]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。