技术特征:
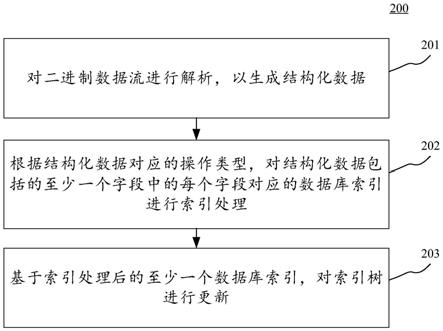
1.对长文本友好的知识图谱表示学习方法,其特征在于,包括如下步骤:步骤一:长文本友好的文本信息抽取;1)针对三元组(h,r,t)的关系r,通过从语料库中抽取同时包含三元组中头实体h、尾实体t的全部句子,作为候选关系提及;2)通过向量空间模型来计算其相似性,假设m表示候选关系提及集,r是对应的关系集,vm代表提及集的空间向量表示,vr代表关系集的向量表示,然后可以用余弦距离表示两者之间的相似度;计算方法如公式1所示:3)在语义级别上对相似性进行进一步过滤,将cnn和skip
‑
gram联合起来,来对语义向量中的候选关系提及句子进行建模,使用两个并行的cnn模型来学习候选关系中提到的句子的向量表示,并使用平均词嵌入方法来学习该关系的向量表示;通过公式2计算两者之间的相似性;如果相似度超过设置的阈值ε,则将该句子作为关系的确切文本提及sim(m,r)=cos(v
m
,v
r
)
ꢀꢀꢀꢀ
(2);步骤二:bcrl的文本表示模型;1)本文标识模型的总体框架:首先由bert模型生成句子序列向量,然后将这些句子级别的特征向量输入到卷积神经网络中以形成最终的整体文本向量;此外,将注意力机制和位置编码添加到cnn中,以进一步丰富实体描述的文本表示形式;2)使用基于关系的注意力机制来获得实体文本表示:公式3给出实体描述的基于关系的注意力机制;假设卷积层的输出为q,则将基于关系的注意力机制的输出定义为可以将其用作池化层的输入;α(r)=softmax(v
1:n
r
d
)
ꢀꢀꢀꢀꢀꢀ
(3);3)实体文本表示中的句子层位置编码:将句子位置编码为位置向量γ
i
,然后通过加法将句子向量v
i
组合成新的向量c
i
;采用vaswani提出的方法计算位置向量γ
i
,如公式4和公式5所示,γ
i
是使用不同频率的位置pos上的正弦和余弦函数生成的;pos对应于输入位置,d是位置向量的维数;γ(pos,2i)=sinpos/10000
2i/d
ꢀꢀꢀ
(4)r(pos,2i 1)=cospos/10000
2i/d
ꢀꢀꢀꢀꢀ
(5)给定一个句子序列向量v1:n=v1,
…
,v
n
,其位置向量γ1:
n
=(γ1,
…
,γ
n
),添加位置信息后cnn的新输入为c
1:n
=(v1 γ1,
…
,v
n
γ
n
);步骤三:基于transe的结构化表示,给定一个三元组(头实体,关系,尾实体),将其表示为(h,r,t);三元组(h,r,t)的对应向量表示为(h,r,t);transe旨在将实体和关系表示为低维连续向量;合法的三元组向量应满足公式h r≈t,而错误的三元组不满足;因此,transe定义了以下得分函数来测量三元组的质量,如公式6所示;定义了以下得分函数来测量三元组的质量,如公式6所示;公式6是向量h r与t之间的l1或l2距离;对于合理的得分函数,合法三元组的得分低于
错误三元组的得分;步骤四:结构
‑
文本联合标识:采用xu等提出的门机制来融合从transe中学习的结构信息和文本信息,即将联合表示vj当作结构表示v
s
和文本表示v
d
加权求和的结果;联合表示的定义如公式7、8所示;其中,g
s
和g
d
是平衡两种信息源的门,
⊙
为元素乘法;v
j
=g
s
⊙
v
s
g
d
⊙
v
d
ꢀꢀꢀꢀ
(7)s.t.g
d
=1
‑
g
s
;g
s
,g
d
∈[0,1]
ꢀꢀꢀꢀꢀꢀ
(8)步骤五:模型训练:根据transe,采用最大间隔方法用于训练模型;公式9给出了三元组(h,r,t)的损失函数,其中f是模型的得分函数,γ>0是正例、负例之间的区间距离,d知识图谱中有效三元组集合,是不在知识图谱中的无效三元组的集合;将关系按照两端连接实体的数目分为1
‑
1、1
‑
n、n
‑
1以及n
‑
n四种不同类型,若是1
‑
n关系增大替换头实体的机会,若是n
‑
1关系则增大替换尾实体的机会,这样能有效提升模型训练效果;对于每一个三元组一个有效三元组(h,r,t)相应的无效三元组定义为2.根据权利要求1所述的对长文本友好的知识图谱表示学习方法,其特征在于,步骤一中3):该模型使用skip
‑
gram模型基于上文的语料库获得关系提及的句子的单词嵌入;在卷积层中使用窗口大小分别为1和2的卷积核,以提取具有不同粒度的局部特征,以最大程度地利用信息;在本文中,卷积层使用relu激活函数,卷积层之后的池化层用于选择各种语义组合,提取主要特征并将可变长度输入更改为固定长度输出;池化层采用最大池化操作,并在每个窗口中选择输入向量的最强值以形成一个新向量;池化操作之后的输出将通过dropout层;dropout以一定的概率将池化层提取的每个特征设置为0;避免由于模型过度依赖某些特征而导致的过度拟合,之后全连接层对提取的主要特征进行非线性重组,以获得输入的提及句子的语义向量表示。3.根据权利要求1所述的对长文本友好的知识图谱表示学习方法,其特征在于,步骤二1)中:bert模型的输入是一系列预处理句子d,其中序列长度为n,每个句子包含m个单词;因此,输入定义为d1:n=d1,d2,
…
,d
n
,其中d
i
∈d
m
表示实体描述文本的第i个句子的m个词;对于句子序列d,为了防止文本处理中的过拟合问题,选择尺寸为768的倒数第二层的输出值作为输出句子向量v;cnn卷积层的输入是前一个bert获得的n个句子向量v,其中每个句子维度为768;卷积层使用大小为j的滑动窗口对这n个句子向量执行卷积运算,然后输出特征图q;由滑动窗口处理的句子向量序列被定义为v
i:i j
‑1=v
i
,v
i 1
,
…
,v
i j
‑1;卷积后第i个输出特征向量由公式10给出,其中w∈r
j
×
m
是过滤器,b∈r是偏置项,f是激活函数;本文选择relu作为激活函数;q
i
=f(w
·
v
i,i j
‑1 b)
ꢀꢀꢀꢀꢀ
(10)这里用到了k
‑
max pooling,即为每个窗口中的输入向量选择前k个最大值以形成一个新向量;可以使用公式11计算窗口大小为n
p
的池化层输出的第i个向量;当过滤器的数量为l时,池化层的输出为p=[p1,
…
,p
l
];
该模型还提供了一个在bernoulli过程中工作的dropout层,以进一步防止过拟合;如公式12所示,dropout层的输出为其中向量的概率为ρ;公式13定义了cnn全连接层的输出,其中w
o
是参数矩阵,而b
o
是可选的偏置项;4.根据权利要求1所述的对长文本友好的知识图谱表示学习方法,其特征在于,步骤四中:门g定义为其中是存储在查找表中的实值向量,服从均匀分布;这里采用softmax函数将门控制的值约束在[0,1]之间;sigmoid函数也可用于计算门;类似于transe系列模型,结构文本联合表示得分函数的定义如公式14所示;
技术总结
本发明公开了对长文本友好的知识图谱表示学习方法,包括如下步骤:步骤一:长文本友好的文本信息抽取;步骤二:BCRL的文本表示模型;骤三:基于TransE的结构化表示;步骤四:结构
技术研发人员:吴刚 武文芳 崔锴倩 李雪玉 李磊磊 韩东红
受保护的技术使用者:东北大学
技术研发日:2021.09.01
技术公布日:2021/12/6
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。