1.本技术涉及气象水文技术领域,特别是涉及一种洪水预测方法、装置、计算机设备和存储介质。
背景技术:
2.随着水利技术的发展,在对防洪水工建筑物进行设计时,需要考虑可能发生的洪水大小来作为重要设计依据,因此需要对流域的洪水进行预测。但目前全球范围内径流观测站点空间分布稀疏、覆盖年限短,中国境内中小河流的观测尤为缺乏,洪水预测较为困难。
3.传统技术中,采用区域洪水频率分析法,对无洪水资料或洪水资料匮乏的流域的洪水频率进行预测。该分析法首先根据流域的气象特征以及下垫面特征将不同流域划分为多个水文同质性区域。针对某一个水文同质性区域建立一个以流域气象(如降水)、下垫面特征(如流域平均高程)作为输入的洪水预测模型,最后使用该模型,对该水文同质性区域内,无洪水资料或洪水资料匮乏的流域进行洪水预测。
4.然而,传统技术中仅考虑了不同流域之间在气象及下垫面方面的相似度,但气象及下垫面并不能完全、严格地代表对应流域的洪水特征的实际情况,基于此实现的洪水预测模型的预测准确度较低。
技术实现要素:
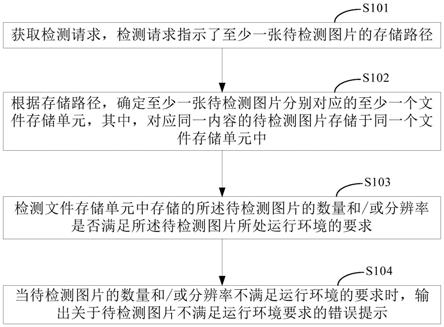
5.基于此,有必要针对上述技术问题,提供一种能够提升洪水预测准确度的洪水预测方法、装置、计算机设备和存储介质。
6.一种洪水预测方法,所述方法包括:
7.将研究范围内包含的多个流域在地理上进行网格化处理,确定每个网格中心的季节性指标;季节性指标包括网格中心的洪水平均发生时间以及网格中心的洪水发生集中度;
8.根据所有网格中心的季节性指标两两之间的相似度,将所有网格划分为多个同质性区域;
9.针对每一个同质性区域,基于同质性区域内第一类流域的历史洪水数据训练同质性区域的洪水预测模型;第一类流域为多个流域中,满足历史数据记录量条件的流域;
10.将第二类流域的气象特征以及下垫面特征输入与第二类流域所属同质性区域对应的洪水预测模型,获得第二类流域的洪水频率;第二类流域为多个流域中,不满足历史数据记录量条件的流域。
11.在其中一个实施例中,确定每个网格中心的季节性指标,包括:根据第一类流域的历史洪水记录计算第一类流域的几何中心的季节性指标;根据第一类流域的几何中心的季节性指标计算所有网格中心的季节性指标。
12.在其中一个实施例中,根据第一类流域的历史洪水记录计算第一类流域的几何中
心的季节性指标,包括:基于弧度制数值处理算法对第一类流域的多个实际洪水发生时间进行转化,获得多个弧度制数值,并根据多个弧度制数值确定第一类流域的几何中心的的洪水平均发生时间;根据多个弧度制数值确定第一类流域的几何中心的洪水发生集中度;洪水发生集中度用于表征一个观测周期内第一类流域在单个时间点内发生洪水的概率。
13.在其中一个实施例中,根据多个弧度制数值确定第一类流域的几何中心的洪水平均发生时间,包括:分别对多个弧度制数值进行余弦运算,获得多个余弦值,对多个余弦值进行求和运算,获得第一运算值;分别对多个弧度制数值进行正弦运算,获得多个正弦值,对多个正弦值进行求和运算,获得第二运算值;根据第一运算值和第二运算值确定第三运算值,对第三运算值进行反正切运算,获得第一类流域的几何中心的洪水平均发生时间。
14.在其中一个实施例中,根据多个弧度制数值确定第一类流域的几何中心的洪水发生集中度,包括:分别对第一运算值、第二运算值进行平方运算,根据运算结果以及观测周期内的单位时段的数量计算第一类流域的几何中心的洪水发生集中度。
15.在其中一个实施例中,根据第一类流域的几何中心的季节性指标计算所有网格中心的季节性指标,包括:对第一流域的几何中心的季节性指标进行空间插值运算,获得所有网格的季节性指标。
16.在其中一个实施例中,根据所有网格中心的季节性指标两两之间的相似度,将所有网格划分为多个同质性区域,包括:确定所有网格中心的季节性指标两两之间的相似度,获得多个相似度参数;确定多个相似度参数中小于预设门限的相似度中,最大的相似度参数为目标相似度参数;基于目标相似度参数以及群集识别算法对各个季节性指标进行聚类,根据聚类结果将所有网格划分为多个同质性区域。
17.在其中一个实施例中,确定所有网格中心的季节性指标两两之间的相似度,包括:计算第一季节性指标中的洪水平均发生时间与第二季节性指标中的洪水平均发生时间的相似度,获得第一相似度数值;计算第一季节性指标中的洪水发生集中度与第二季节性指标中的洪水发生集中度的相似度,获得第二相似度数值;计算第一季节性指标对应的网格的地理位置与第二季节性指标对应的网格的地理位置之间的相似度,获得第三相似度数值;根据第一相似度数值、第二相似度数值以及第三相似度数值确定第一季节性指标与第二季节性指标的相似度;其中,所述第一季节性指标、所述第二季节性指标为所有网格中心的季节性指标中的任意两个。
18.一种洪水预测装置,所述装置包括:
19.确定模块,用于将研究范围内包含的多个流域在地理上进行网格化处理,确定每个网格中心的季节性指标;季节性指标包括网格中心的洪水平均发生时间以及网格中心的洪水发生集中度;
20.划分模块,用于根据所有网格中心的季节性指标两两之间的相似度,将所有网格划分为多个同质性区域;
21.训练模块,用于针对每一个同质性区域,基于同质性区域内第一类流域的历史洪水数据训练同质性区域的洪水预测模型;第一类流域为多个流域中,满足历史数据记录量条件的流域;
22.预测模块,用于将第二类流域的气象特征以及下垫面特征输入与第二类流域所属同质性区域对应的洪水预测模型,获得第二类流域的洪水频率;第二类流域为多个流域中,
不满足历史数据记录量条件的流域。
23.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
24.将研究范围内包含的多个流域在地理上进行网格化处理,确定每个网格中心的季节性指标;季节性指标包括网格中心的洪水平均发生时间以及网格中心的洪水发生集中度;
25.根据所有网格中心的季节性指标两两之间的相似度,将所有网格划分为多个同质性区域;
26.针对每一个同质性区域,基于同质性区域内第一类流域的历史洪水数据训练同质性区域的洪水预测模型;第一类流域为多个流域中,满足历史数据记录量条件的流域;
27.将第二类流域的气象特征以及下垫面特征输入与第二类流域所属同质性区域对应的洪水预测模型,获得第二类流域的洪水频率;第二类流域为多个流域中,不满足历史数据记录量条件的流域。
28.一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
29.将研究范围内包含的多个流域在地理上进行网格化处理,确定每个网格中心的季节性指标;季节性指标包括网格中心的洪水平均发生时间以及网格中心的洪水发生集中度;
30.根据所有网格中心的季节性指标两两之间的相似度,将所有网格划分为多个同质性区域;
31.针对每一个同质性区域,基于同质性区域内第一类流域的历史洪水数据训练同质性区域的洪水预测模型;第一类流域为多个流域中,满足历史数据记录量条件的流域;
32.将第二类流域的气象特征以及下垫面特征输入与第二类流域所属同质性区域对应的洪水预测模型,获得第二类流域的洪水频率;第二类流域为多个流域中,不满足历史数据记录量条件的流域。
33.上述洪水预测方法、装置、计算机设备和存储介质,通过将研究区域内包含的多个流域在地理上进行网格化处理,确定每个网格中心的季节性指标,进而根据所有网格中心的季节性指标之间的相似度,将所有网格划分为多个同质性区域,而后针对每一个同质性区域,基于同质性区域内第一类流域的历史洪水数据,训练出同质性区域的洪水预测模型,最后,将第二类流域的气象特征以及下垫面特征输入与待预测流域所属同质性区域对应的洪水预测模型,获得第二类流域的洪水频率。本方法中的季节性指标,能够表征洪水发生的机理,因此,以季节性指标为基准划分同质性区域时,能够更加准确地划分出同质性区域,基于同质性区域中的洪水数据所训练出的模型也就更加准确,从而提升了洪水预测模型的预测结果的准确性。
附图说明
34.图1为一个实施例中计算机设备的结构图;
35.图2为一个实施例中洪水预测方法的流程示意图;
36.图3为一个实施例中洪水预测方法的流程示意图;
37.图4为一个实施例中洪水预测方法的流程示意图;
38.图5为一个实施例中洪水预测方法的流程示意图;
39.图6为一个实施例中洪水预测方法的流程示意图;
40.图7为一个实施例中复杂网络与群集结构图;
41.图8为一个实施例中洪水预测方法的流程示意图;
42.图9为一个实施例中洪水预测方法的流程示意图;
43.图10为一个实施例中流域几何中心分布图;
44.图11为一个实施例中洪水季节性指标等值线图;
45.图12为一个实施例中同质性区域划分结果示意图;
46.图13为一个实施例中洪水频率预测准确度评估示意图;
47.图14为一个实施例中洪水预测装置的结构框图;
48.图15为一个实施例中洪水预测装置的结构框图。
具体实施方式
49.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
50.本技术提供的洪水预测方法,可以应用于如图1所示的计算机设备中。该计算机设备可以是服务器,该计算机设备中的处理器可以执行计算机程序进行洪水预测。其中该计算机程序被处理器执行时可以获取存储在计算机中的洪水资料,还可以针对洪水资料训练出相应的洪水预测模型,还可以通过洪水模型进行洪水预测。
51.在一个实施例中,如图2所示,提供了一种洪水预测方法,以该方法应用于图1中的计算机设备为例进行说明,包括以下步骤:
52.s202、将研究范围内包含的多个流域在地理上进行网格化处理,确定每个网格中心的季节性指标;季节性指标包括网格中心的洪水平均发生时间以及网格中心的洪水发生集中度。
53.示例性地,本方法可以应用于对大空间尺度区域范围内(如全国、全省、一级流域)任意流域的洪水预测。尤其适用于,没有显著的大坝调节、大规模灌溉、流域调水、土地覆盖变化等,受人类活动影响较小的中小流域。其中,中小流域可以是集水面积小于10000km2的流域。为了方便表述,以研究范围来代替上述大空间尺度区域范围。
54.其中,网格化处理可以是指将研究范围在地理上划分为同样大小的若干网格,网格分辨率可以由本领域技术人员根据流域大小来设置,示例性,网格分辨率可以为10km2~100km2。研究范围内的各个流域的位置可以是其地理中心的位置。可以理解的是,每个流域的地理中心所在的网格,可以是指该流域对应的网格。季节性指标可以用于表征洪水的季节性特征。本技术实施例中某个网格中心的季节性指标可以是该网格中心的洪水平均发生时间,也可以是洪水发生集中度。
55.在一种可能的实现方式中,洪水平均发生时间可以表征一个地理位置在单位时段内的平均洪水发生时间。例如,可以是该位置各个单位时段内洪水发生时的时间的平均值。示例性的,流域x的观测周期是3年,单位时段为1年,其中,第一年洪水发生在3月份,第二年
发生在4月份,第三年发生在5月份,则流域x的几何中心的洪水平均发生时间为4月份,上述洪水发生时的时间也可以以日、旬、季度为单位,在此不做限定。
56.在一种可能的实现方式中,洪水发生集中度可以用于表征一个地理位置集中在单个时间点内发生洪水的概率。该位置的洪水发生集中度越高,说明该位置的洪水发生的时间越集中于同一时间点。示例性的,在上述流域x的例子的基础上,流域y的观测周期也是3年,每年洪水发生的时间都是4月份,因此,流域y的洪水平均发生时间与流域x相同,我们从数据中可以直观地发现,流域y的洪水发生时间全部集中在4月,相对于流域x,流域y的几何中心的洪水发生的集中度更高。
57.具体地,计算机设备可以在研究范围内选取受人类活动影响较小的,有洪水资料的中小流域,并将该范围内多个流域的每一个单位时段内最大流量(瞬时流量或日平均流量皆可)确认为洪水事件,随后提取多个流域的洪水发生时的时间。进一步地,计算机设备可以基于上述多个流域各自的洪水发生时的时间,确定每个网格中心的季节性指标。
58.s204、根据所有网格中心的季节性指标两两之间的相似度,将所有网格划分为多个同质性区域。
59.其中,相似度可以用于表征两个网格中心的洪水特征之间的相似性,相似度越高,两个网格中心的洪水发生的规律越相近。同质性区域可以是,以多个网格中心之间的相似度为划分标准,划分出来的多个网格的集合。同质性区域内各网格之间的相似度较高,可以被视为具有同一洪水特征。
60.具体地,计算机设备在确定所有网格中心的季节性指标后,可以根据上述季节性指标,确定所有网格中心的季节性指标两两之间的相似度。进一步地,计算机设备可以依据上述相似度,将所有网格划分为多个同质性区域。在另一种可能的实现方式中,计算机设备还可以根据所有网格中心的季节性指标以及所有网格中心之间的空间位置邻近性,来确定上述相似度,此处对于相似度的确定方式不做限定。在确定网格中心之间的相似度时,同时考虑网格中心之间的空间位置邻近性以及季节性指标,能够使得相似度的计算结果更加准确,提升了划分同质性区域的准确性,从而提升了洪水预测准确度。
61.s206、针对每一个同质性区域,基于同质性区域内第一类流域的历史洪水数据训练同质性区域的洪水预测模型;第一类流域为多个流域中,满足历史数据记录量条件的流域。
62.其中,第一类流域可以是历史洪水数据丰富,满足历史数据记录量条件的流域。上述历史数据记录条件可以由本领域技术人员依据实际情况确认,示例性地,上述历史数据记录条件可以为包括有最近10年的历史洪水数据,此时,若流域x包括有最近11年的历史洪水数据,则流域x可以为第一类流域。该洪水预测模型可以是随机森林模型、线性回归模型等,此处对于洪水预测模型的类型不做限定。流域的历史洪水数据至少包括流域的年平均最大流量、流域日平均降水、流域降雪与总降水的比例、流域面积以及流域平均坡度。
63.示例性地,计算机设备可以建立每个同质性区域的指标洪水的回归方程。指标洪水是一个流域的代表性洪水量级,可选用年平均最大流量μ(m3/s)。对于处于同一同质性区域的流域,计算机设备可以建立气象与下垫面特征与指标洪水的回归关系:
64.65.其中,p
mean
是流域日平均降水(mm),snow
frac
是流域降雪与总降水的比例,area是流域面积(km2),slope是流域平均坡度。β0、β1、β2、β3以及β4为上述回归关系中的五个参数,可以由每个同质性区域内第一类流域的洪水历史数据拟合得到。
66.进一步地,计算机设备可以建立每个同质性区域的洪水频率曲线。具体地,针对第一类流域x,计算机设备可以通过广义极值分布拟合其无因次化每年最大流量的概率分布曲线:
[0067][0068]
其中q
ix
为流域x第i年的年最大流量。假设流域x所拟合得到的曲线参数为流域{u
x
,σ
x
,ξ
x
},该流域有n
x
个年最大流量记录,则同质性区域的洪水频率曲线的参数为:
[0069][0070]
s208、将第二类流域的气象特征以及下垫面特征输入与第二类流域所属同质性区域对应的洪水预测模型,获得第二类流域的洪水频率;第二类流域为多个流域中,不满足历史数据记录量条件的流域。
[0071]
其中,其中,第二类流域可以是历史洪水数据匮乏,不满足历史数据记录量条件的流域。上述历史数据记录条件可以由本领域技术人员依据实际情况确认,示例性地,上述历史数据记录条件可以为包括有最近10年的历史洪水数据,此时,若流域x包括有最近9年的历史洪水数据,则流域x可以为第二类流域。流域的气象特征可以包括流域日平均降水以及流域降雪与总降水的比例,流域的下垫面特征可以包括流域面积、以及流域平均坡度。洪水频率可以是一定重现期(如百年一遇)对应的洪水量级。
[0072]
具体地,对任意一个研究范围内的无资料流域,计算机设备可以依据步骤s202、s204确定该流域的几何中心所属的同质性区域。进一步地,计算机设备可以根据上述表达式(1),输入该流域的流域日平均降水、流域降雪与总降水的比例、流域面积、以及流域平均坡度,即可求得该流域的指标洪水μ
x
。若定义由该同质性区域的频率曲线所求得的该同质性区域t年一遇的洪水流量为q
(r)
(t),则该流域的t年一遇流量q
x
(t)为:
[0073]
q
x
(t)=μ
x
q
(r)
(t)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0074]
上述洪水预测方法,通过将研究区域内包含的多个流域在地理上进行网格化处理,确定每个网格中心的季节性指标,进而根据所有网格中心的季节性指标之间的相似度,将所有网格划分为多个同质性区域,而后针对每一个同质性区域,基于同质性区域内第一类流域的历史洪水数据,训练出同质性区域的洪水预测模型,最后,将第二类流域的气象特征以及下垫面特征输入与待预测流域所属同质性区域对应的洪水预测模型,获得第二类流域的洪水频率。本方法中的季节性指标,能够表征洪水发生的机理,因此,以季节性指标为基准划分同质性区域时,能够更加准确地划分出同质性区域,基于同质性区域中的洪水数
据所训练出的模型也就更加准确,从而提升了洪水预测模型的预测结果的准确性。
[0075]
在一个实施例中,如图3所示,在上述实施例的基础上,s202包括:
[0076]
s302、根据第一类流域的历史洪水记录计算第一类流域的几何中心的季节性指标。
[0077]
具体地,针对满足历史数据记录量条件的第一类流域,其历史洪水数据丰富,计算机设备可以根据第一类流域的历史洪水记录直接计算出该流域的几何中心的季节性指标,历史洪水数据越丰富,计算出的季节性指标就越准确。
[0078]
s304、根据第一类流域对应的几何中心的季节性指标计算所有网格中心的季节性指标。
[0079]
具体地,针对所有网格中心,计算机设备可以使用插值等方式,根据第一类流域的几何中心的季节性指标计算剩余网格的季节性指标,具体插值方法在此不做限定。
[0080]
本实施例中,根据第一类流域的几何中心的季节性指标计算所有网格中心的季节性指标,能够使得洪水的季节性特征覆盖所有网格中心,从而保证任意无洪水资料的流域或洪水资料匮乏的流域也能被划分到其所属的同质性区域,最终实现对无洪水资料的流域或洪水资料匮乏的流域的洪水频率预测。
[0081]
在一个实施例中,如图4所示,在上述实施例的基础上,s302包括:
[0082]
s402、基于弧度制数值处理算法对第一类流域的多个实际洪水发生时间进行转化,获得多个弧度制数值,并根据多个弧度制数值确定第一类流域的几何中心的洪水平均发生时间。
[0083]
其中,弧度制数值处理算法是将洪水的发生时间转化为弧度值的算法。
[0084]
具体地,由于每一年的日期是周期循环的,故通常使用弧度制这种循环制数值来表征洪水的发生时间。示例性地,若流域x为第一类流域,流域x第i年的洪水发生在该年中的第j
i
天,且该年有m
i
天,则流域x的几何中心第i年的洪水发生时间的弧度制数值θ
i
可以表示为:
[0085][0086]
进一步地,计算机设备可以基于弧度制数值处理算法对第一类流域的几何中心的多个实际洪水发生时间进行转化,获得多个弧度制数值,并根据多个弧度制数值确定第一类流域的几何中心的洪水平均发生时间。示例性地,针对上述流域x,若流域x的几何中心包括i个实际洪水发生时间,则计算机设备可以基于弧度制数值处理算法得到θ1、θ2......θ
i
共i个弧度制数值,并根据上述i个弧度制数值确定第一类流域的几何中心在i年中的洪水平均发生时间。
[0087]
s404、根据多个弧度制数值计算第一类流域的几何中心的洪水发生集中度;洪水发生集中度用于表征一个观测周期内第一类流域在单个时间点内发生洪水的概率。
[0088]
其中,单个时间点可以是季度时间,也可以是月度时间,还可以是日期,在此不作限定。
[0089]
具体地,计算机设备可以根据多个弧度制数值计算第一类流域的几何中心的洪水发生集中度,此处对于计算方式不做限定。应当指出的是,对于本领域技术人员来説,在不脱离本方案构思的前提下,还可以对计算方式作出若干变形和改进,任意计算方式得出的
洪水集中度,只要能够表征一个观测周期内第一类流域在单个时间点内发生洪水的概率,都应当包含在本方案的保护范围之内。
[0090]
本实施例中,计算机设备可以基于弧度制数值处理算法对第一类流域的几何中心的多个实际洪水发生时间进行转化,获得多个弧度制数值,并根据多个弧度制数值确定第一类流域的几何中心的洪水平均发生时间以及洪水发生集中度,为同质性区域的划分提供了季节性指标数据基础,以此季节性指标为基准划分同质性区域时,能够提升同质性区域划分结果的准确性,从而提升洪水预测模型的预测结果的准确性。
[0091]
在一个实施例中,如图5所示,在上述实施例的基础上,s402包括:
[0092]
s502、分别对多个弧度制数值进行余弦运算,获得多个余弦值,对多个余弦值进行求和运算,获得第一运算值。
[0093]
具体地,计算机设备可以对第一类流域中的多个弧度制数值分别取余弦后相加,从而得到第一运算值。示例性地,针对流域x,若定义第一运算值为c,则其中,θ
i
为流域x第i年的洪水发生时间的弧度制数值,n为流域x的洪水总数(即年数)。
[0094]
s504、分别对多个弧度制数值进行正弦运算,获得多个正弦值,对多个正弦值进行求和运算,获得第二运算值。
[0095]
具体地,计算机设备可以对第一类流域中的多个弧度制数值分别取正弦后相加,得到第一运算值。示例性地,针对流域x,若定义第二运算值为s,则其中,θ
i
可以为流域x第i年的洪水发生时间的弧度制数值,n可以为流域x的洪水总次数。
[0096]
s506、根据第一运算值和第二运算值确定第三运算值,对第三运算值进行反正切运算,获得第一类流域的几何中心的洪水平均发生时间。
[0097]
示例性地,第三运算值可以定义为第一类流域的几何中心的洪水平均发生时间可以定义为则第一类流域的几何中心的洪水平均发生时间可以为:
[0098][0099]
本实施例中,计算机设备可以分别对多个弧度制数值进行余弦运算,获得多个余弦值,并对多个余弦值进行求和运算,获得第一运算值。计算机设备还可以分别对多个弧度制数值进行正弦运算,获得多个正弦值,并对多个正弦值进行求和运算,获得第二运算值。而后,计算机设备可以根据第一运算值和第二运算值确定第三运算值,并对第三运算值进行反正切运算,获得第一类流域的几何中心的洪水平均发生时间。本实施例通过第一运算值和第二运算值确定第三运算值,为季节性指标中的洪水平均发生时间提供了算法基础,从而为同质性区域的划分提供了季节性指标数据基础。以此季节性指标为基准划分同质性区域时,能够提升同质性区域划分结果的准确性,从而提升洪水预测模型的预测结果的准
确性。
[0100]
在一个实施例中,在上述实施例的基础上,s404包括:
[0101]
分别对第一运算值、第二运算值进行平方运算,根据运算结果以及观测周期内的单位时段的数量计算第一类流域的几何中心的洪水发生集中度。
[0102]
其中,观测周期内的单位时段的数量可以为流域观测周期内的洪水总次数,例如,针对流域x,若观测周期为10年,单位时段为1年,则流域x在10年内的洪水总次数为10次。
[0103]
示例性的,若定义第一类流域的第一运算值为c,定义第一类流域的第二运算值为s,定义第一类流域的观测周期内的单位时段的数量为n,定义第一类流域对应的网格的洪水发生集中度为r,则r的表达式为:
[0104][0105]
其中,第一类流域的几何中心的洪水发生集中度r∈[0,1]可以表征第一类流域的洪水发生时间的变异性。示例性地,r=0可以表征洪水在第一类流域的一年中任意一天均等可能发生,r=1可以表征第一类流域的所有洪水发生于每年同一天。
[0106]
本实施例中,计算机设备可以分别对第一运算值、第二运算值进行平方运算,而后根据运算结果以及观测周期内的单位时段的数量,计算第一类流域的几何中心的洪水发生集中度,为季节性指标中的洪水发生集中度提供了算法基础,从而为同质性区域的划分提供了季节性指标数据基础。以此季节性指标为基准划分同质性区域时,能够提升同质性区域划分结果的准确性,从而提升洪水预测模型的预测结果的准确性。
[0107]
在一个实施例中,在上述实施例的基础上,s304包括:
[0108]
对第一流域的几何中心的季节性指标进行空间插值运算,获得所有网格中心的季节性指标。
[0109]
其中,空间插值运算可以用于将离散点的季节性数据转换为连续的季节性数据。示例性地,针对本技术中的所有网格,第一类流域的几何中心的季节性指标可以由第一类流域的历史洪水数据直接计算获得,而网格中心的季节性指标可以依据多个第一类流域的几何中心的季节性指标进行加权获得。
[0110]
示例性地,计算机设备可以使用克里金插值公式,对所有网格中心的季节性指标进行数据进行估计,若定义待估计的网格中心的季节性指标数据为z(x0),其中x0为待估计的剩余网格位置,则:
[0111][0112]
其中,λ
i
可以是克里金公式的权重参数,用以表征第一类流域的几何中心位置的权重。λ
i
可以通过多个第一类流域的几何中心的季节性指标数据,进行空间变异函数拟合来估计。x
i
代表与网格中心临近的第一类流域的几何中心的位置,z(x
i
)代表第一类流域的几何中心位置x
i
处的季节性指标数据,n为网格中心位置x0的近邻网格数量。根据泛克里金法可知,z(x
i
)可表达为一个多项式,并包含某些协变量的线性项。本实施例中,z(x
i
)的协变量可以选用空间插值计算时所选取的第一类流域内的平均高程及平均坡度。
[0113]
具体地,计算机设备可以通过上述克里金公式对第一流域的几何中心的季节性指标进行空间插值运算,获得所有网格中心的季节性指标。进一步地,计算机设备也可以通过
样条插值法、反距离加权法等插值方法,对第一流域的几何中心的季节性指标进行空间插值运算,获得所有网格中心的季节性指标,此处对于插值计算的方式不做限定。
[0114]
本实施例中,计算机设备可以对第一流域的几何中心的季节性指标进行空间插值运算,获得与所有网格中心的季节性指标。在空间插值运算中,流域的几何中心的季节性指标数据z(x
i
)的协变量选用了流域内的平均高程及平均坡度,也就是说,本方案在空间插值运算中,既考虑了大尺度气候造成的区域洪水季节性相似,又考虑了地形差异造成的洪水相似性的区别,使得插值运算结果更为准确,提高了计算所有网格中心的季节性指标的准确度。
[0115]
在一个实施例中,如图6所示,在上述实施例的基础上,s204包括:
[0116]
s602、确定所有网格中心的季节性指标两两之间的相似度参数,获得多个相似度。
[0117]
其中,相似度可以用以表征各个网格中心的季节性指标之间的在洪水特征方面的相似性。
[0118]
具体地,计算机设备可以通过各个网格中心的季节性指标数据,确定所有网格中心的季节性指标两两之间的相似度,获得多个相似参数。示例性地,对于网格x、网格y以及网格z,计算机设备可以根据网格x、网格y以及网格z各自中心的洪水平均发生时间以及洪水发生集中度r,确定三个网格中心两两之间的相似度d(x,y)、d(x,z)以及d(y,z)。对于相似度的确定方式在此不做限定。
[0119]
s604、确定多个相似度参数中小于预设门限的相似度中,最大的相似度参数为目标相似度参数。
[0120]
其中,目标相似度参数可以是,表征网格中心之间的洪水季节性特征的相似程度的指标参数。相似度可以与网格中心之间的洪水季节性特征的相似程度正相关,也可以与网格中心之间的洪水季节性特征的相似程度负相关,在此不做限定。预设门限可以是一个由本领域技术人员设置的数值,也可以是计算机设备选取所有相似度数值的某一分位数,所对应的数值。
[0121]
示例性地,以相似度与网格中心之间的洪水季节性特征的相似程度负相关为例,计算机设备可以选取所有相似度数值从小到大排列后的前5%分位数所对应的相似度,作为确定两个网格中心的洪水特征相似的目标相似度参数。进一步地,若两个网格中心之间的相似度小于上述目标相似度,则计算机设备可以在两个网格的中心位置之间进行连线,以表征网格之间的洪水特征相似。
[0122]
s606、基于目标相似度参数以及群集识别算法对各个季节性指标进行聚类,根据聚类结果将所有网格划分为多个同质性区域。
[0123]
其中,聚类可以是指将所有网格的集合,分成由类似的网格组成的,多个类的集合的过程。群集识别算法可以是聚类时所使用的聚类算法,除此之外,还可以使用划分法、密度算法等等,在此不做限定。
[0124]
具体地,计算机设备可以基于目标相似度参数以及群集识别算法对各个季节性指标进行聚类,根据聚类结果将所有网格划分为多个同质性区域。示例性地,在上述s604中的实施例的基础上,计算机设备可以构建网格复杂网络,复杂网络是由数量巨大的节点和节点之间的连接关系构成的网络结构,它是一个描述各网格之间相互关系的工具。本实施例中,计算机设备可以将每一个网格中心都作为一个节点,并根据网格中心两两之间的相似
性是否小于目标相似度参数,对网格中心两两之间进行连边,从而构建网格复杂网络。
[0125]
进一步地,计算机设备可以依据群集识别算法对上述复杂网格网络进行区域划分。网格复杂网络中的群集识别算法是一种针对网络结构的分类方法,且能自动识别最优分类数,适用于区域划分。其中,群集可以是上述网格网络中节点的集合,同一个群集内的点互相之间连接的边数量相对较多,而不同群集内的点互相之间连接的边数量相对较少。群集识别算法可以采用最大化模块度m的值作为指标,来对节点进行分类,m的计算公式可以为:
[0126][0127]
其中l
c
是群集c内部的边数,d
c
是群集c所有节点所拥有的总边数,n
c
是群集数,m是网络的总边数,模块度m是可以表征群集划分效果的指标,m越大,群集划分效果越好。计算机设备可以通过不断优化模块度m的值,获取最优的分类数。以最优分类数将所有节点聚类划分后,节点所对应的网格组成的社团可以表征为最终划分出来的同质性区域。一个网格复杂网络区域划分的例子可以如图7所示,在使用群集识别算法对网格进行区域划分后,每个群集区域可以表征一个同质性区域,每个网格都能够对应一个其所属的同质性区域。
[0128]
本实施例中,计算机设备可以确定各个季节性指标两两之间的相似度,获得多个相似度参数,而后确定多个相似度参数中小于预设门限的相似度中,最大的相似度参数为目标相似度参数,最后基于目标相似度参数以及群集识别算法对各个季节性指标进行聚类,并根据聚类结果将多个流域划分为多个同质性区域。由于群集识别算法不需要预先设置分类数,消除了人为因素的影响,因此聚类的结果更为准确,同质性区域的划分结果也更加准确。
[0129]
在一个实施例中,如图8所示,在上述实施例的基础上,s602包括:
[0130]
s802、计算第一季节性指标中的洪水平均发生时间与第二季节性指标中的洪水平均发生时间的相似度,获得第一相似度数值。
[0131]
其中,第一季节性指标与第二季节性指标可以是任意两个网格中心各自的季节性指标。第一相似度数值可以用于表征,两个网格中心在洪水平均发生时间方面的相似程度。
[0132]
具体地,计算机设备可以获取,两个网格中心各自的季节性指标中的洪水平均发生时间,并计算两个网格中心之间的第一相似度数值。示例性地,对于网格x与网格y,若网格x的中心的洪水平均发生时间为网格y的中心的洪水平均发生时间为则网格x的中心与网格y的中心之间的第一相似度数值可以为:
[0133][0134]
s804、计算第一季节性指标中的洪水发生集中度与第二季节性指标中的洪水发生集中度的相似度,获得第二相似度数值。
[0135]
其中,第二相似度数值可以用于表征,两个网格中心在洪水发生集中度方面的相
似程度。
[0136]
具体地,计算机设备可以获取,两个网格中心各自的季节性指标中的洪水发生集中度,并计算两个网格中心之间的第二相似度数值。示例性地,对于网格x与网格y,若网格x的中心的洪水发生集中度为r
x
,网格y的中心的洪水发生集中度为r
y
,则网格x的中心与网格y的中心之间的第二相似度数值d
r
(x,y)可以为:
[0137]
d
r
(x,y)=r
x
‑
r
y
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0138]
s806、计算第一季节性指标对应的网格的地理位置与第二季节性指标对应的网格的地理位置之间的相似度,获得第三相似度数值。
[0139]
其中,第二相似度数值可以用于表征,两个网格在地理位置方面的相似程度。
[0140]
具体地,计算机设备可以获取,两个网格的中心在地球球面假设下的地理距离,并计算两个网格中心之间的第三相似度数值。示例性地,对于网格x与网格y,若定义两个网格的中心在地球球面假设下的地理距离为geodist(x,y),则网格x的中心与网格y的中心之间的第三相似度数值d
loc
(x,y)可以为:
[0141][0142]
s808、根据第一相似度数值、第二相似度数值以及第三相似度数值确定第一季节性指标与第二季节性指标的相似度。
[0143]
其中,第三相似度数值可以用于表征,两个网格中心之间,综合洪水平均发生时间、洪水发生集中度以及地理位置三个因素之后的相似程度。
[0144]
具体地,计算机设备可以根据第一相似度数值、第二相似度数值以及第三相似度数值之和,来确定第一季节性指标与第二季节性指标的相似度。示例性地,在上述示例的基础上,网格x与网格y的中心之间的相似度d(x,y)可以为:
[0145][0146]
本实施例中,计算机设备可以分别计算两个网格中心之间,在洪水平均发生时间、洪水集中度以及地理位置方面的三种相似度数值,将其加权求和之后求出最终的相似度数值同时考虑了网格中心的空间位置邻近性以及洪水季节性相似性,提升了相似度计算的准确度,提高了基于相似度对同质性区域的划分时的准确度。
[0147]
在一个实施例中,如图9所示,在上述实施例的基础上,以美国全境的历史洪水数据集作为实例,在美国全国范围内推求其无资料流域或洪水资料匮乏的流域的洪水频率。上述数据集包含了美国本土600个中小流域(面积4km2~8268km2)在1980
‑
2014年的每日径流数据。上述600个中小流域的每日径流数据受大坝、调水、土地利用变化等人类活动影响较小,可以较为准确地表征流域的自然径流情况。上述数据集同时还包含流域平均的气象特征数据(如降雨、降雪)以及下垫面特征数据(如高程、坡度)。
[0148]
在本实例中,为了评估本技术中的洪水预测方法,可以随机抽取100个流域作为测试集,即假设其为无资料流域或洪水资料匮乏的流域,余下500个流域作为训练集,预测100个流域的设计洪水并与其实测径流数据推求的设计洪水作对比。上述数据集中的历史洪水数据所对应的流域的几何中心分布图如图10所示,其中,空心圆表征训练集所对相应的流域的的几何中心,实心圆表征测试集所对应的流域的的几何中心。现使用本技术中的洪水
预测方法,将美国本土全境从地理上网格化处理后,利用500个空心圆所对应流域的洪水资料,预测剩余100个实心圆所对应的流域的洪水频率。
[0149]
具体地,本实施例可以包括以下步骤:
[0150]
s902、获取研究范围内训练集流域的历史洪水事件。
[0151]
具体地,针对上述500个训练集所对应的流域,计算机设备可以提取每个流域每年最大流量值及其对应的日期作为其洪水事件。
[0152]
s904、计算训练集流域的几何中心的洪水季节性指标。
[0153]
具体地,对上述每个训练集流域的洪水事件,使用公式(5)将其转换为弧度制,再使用公式(6)和(7)分别计算每个训练集流域的几何中心的洪水平均发生时间θ和发生集中度r。
[0154]
s906、使用克里金法对所有网格中心的洪水季节性指标进行空间插值。
[0155]
具体地,计算机设备可以采用美国宇航局(nasa)的航天飞机雷达地形测绘使命(srtm)高程数据,下载其50km2分辨率的高程与坡度数据,即本实例中网格分辨率为50km2。而后,计算机设备可以使用r语言automap包的autokrige函数进行自动参数优选的克里金插值,输入以几何中心代表的训练集流域数据:r、流域平均高程、流域平均坡度,输出50km2下美国本土全境4978个网格的和r。插值后美国本土全境洪水季节性指标等值线如图11所示,其中,(a)图为洪水平均发生时间的等值线图,等值线以月为单位。(b)图为洪水发生集中度的等值线图。
[0156]
s908、利用复杂网络群集识别算法对所有网格进行同质性区域划分。
[0157]
具体地,计算机设备可以针对4978个网格,根据公式(10)、(11)、(12)和(13)计算网格中心两两之间的相似度,并以所有相似度的5%分位数距离作为目标相似度。使用r语言igraph包以4978个网格为节点构建复杂网络,将相似度低于目标相似度的节点对连接一条边,使用igraph包的cluster_louvain函数进行基于模块度贪心优化算法(louvain algorithm)的群集识别,一共划分出r1至r6共6个同质性区域,同质性区域划分结果如图12所示。
[0158]
s910、使用指标洪水法建立同质性区域的洪水预测模型。
[0159]
具体地,针对每个训练集流域,计算机设备可以计算其年平均最大流量,并从数据集中读取每个流域的流域日平均降水p
mean
、流域降雪与总降水的比例snow
frac
、流域面积area和流域平均坡度slope。而后计算机设备可以将所有训练集流域按照其几何中心的位置分配到步骤s1008所划分出的多个同质性区域中。在每一个同质性区域中,以同质性区域内所包含的训练集流域的洪水资料作为样本,使用r语言lm函数拟合回归式(1),从而获得气象特征和下垫面特征与指标洪水μ的回归关系。
[0160]
进一步地,针对每个训练集流域,计算机设备可以通过r语言extremes包中的fevd函数对无因次化的年最大流量样本拟合其极值概率分布曲线(2),并在同质性区域中计算同质性区域整体的频率曲线(3),由此得到区域无因次化的t年一遇流量为q
(r)
(t)。
[0161]
s912、对测试集流域使用对应同质性区域的洪水预测模型进行洪水频率的预测。
[0162]
具体地,针对100个测试集流域中的任意一个流域,计算机设备可以获取其几何中心所在的网格,并通过该网格所属的同质性区域的指标洪水回归式(1),输入该测试集流域
的流域日平均降水p
mean
、流域降雪与总降水的比例snow
frac
、流域面积area和流域平均坡度slope,求得指标洪水μ
x
。
[0163]
进一步地,结合同质性区域的洪水频率曲线,通过公式(4)即可计算出流域x的t年一遇流量q
x
(t)。以上是将无资料流域或洪水资料匮乏的流域视作测试集流域的洪水预测方法。
[0164]
本实施例中,为了与实际设计洪水的值作对比评估,这100个测试集都使用实测径流提取的每年最大流量拟合极值分布(2),来计算每个测试集流域的实际的t年一遇流量。如图13所示,本实例分别选取t=2,10,50,并用决定系数r2评估准确性。结果表示,2年一遇洪水的r2=0.88,10年一遇洪水的r2=0.84,50年一遇洪水的r2=0.73,由此可知,采用本方案对洪水频率进行预测,具有较高的准确性。
[0165]
应该理解的是,虽然图2
‑
6以及图8
‑
9的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图2
‑
6以及图8
‑
9中的至少一部分步骤可以包括多个步骤或者多个阶段,这些步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤中的步骤或者阶段的至少一部分轮流或者交替地执行。
[0166]
在一个实施例中,如图14所示,提供了一种洪水预测装置,所述装置包括:
[0167]
确定模块10,用于将研究范围内包含的多个流域在地理上进行网格化处理,确定每个网格中心的季节性指标;季节性指标包括网格中心的洪水平均发生时间以及网格中心的洪水发生集中度;
[0168]
划分模块20,用于根据所有网格中心的季节性指标两两之间的相似度,将所有网格划分为多个同质性区域;
[0169]
训练模块30,用于针对每一个同质性区域,基于同质性区域内第一类流域的历史洪水数据训练同质性区域的洪水预测模型;第一类流域为多个流域中,满足历史数据记录量条件的流域;
[0170]
预测模块40,用于将第二类流域的气象特征以及下垫面特征输入与第二类流域所属同质性区域对应的洪水预测模型,获得第二类流域的洪水频率;第二类流域为多个流域中,不满足历史数据记录量条件的流域。
[0171]
在其中一个实施例中,在上述实施例的基础上,如图15所示,所述确定模块10包括:
[0172]
第一计算单元110,用于根据第一类流域的历史洪水记录计算第一类流域的几何中心的季节性指标;
[0173]
第二计算单元120,用于根据第一类流域的几何中心的季节性指标计算所有网格中心的季节性指标。
[0174]
在其中一个实施例中,在上述实施例的基础上,所述第一计算单元110具体用于:基于弧度制数值处理算法对第一类流域的多个实际洪水发生时间进行转化,获得多个弧度制数值,并根据多个弧度制数值确定第一类流域的几何中心的洪水平均发生时间;根据多个弧度制数值确定第一类流域对应的网格的的洪水发生集中度;洪水发生集中度用于表征
一个观测周期内第一类流域在单个时间点内发生洪水的概率。
[0175]
在其中一个实施例中,在上述实施例的基础上,所述第一计算单元110具体用于:分别对多个弧度制数值进行余弦运算,获得多个余弦值,对多个余弦值进行求和运算,获得第一运算值;分别对多个弧度制数值进行正弦运算,获得多个正弦值,对多个正弦值进行求和运算,获得第二运算值;根据第一运算值和第二运算值确定第三运算值,对第三运算值进行反正切运算,获得第一类流域的几何中心的洪水平均发生时间。
[0176]
在其中一个实施例中,在上述实施例的基础上,所述第一计算单元110具体用于:分别对第一运算值、第二运算值进行平方运算,根据运算结果以及观测周期内的单位时段的数量计算第一类流域的几何中心的洪水发生集中度。
[0177]
在其中一个实施例中,在上述实施例的基础上,所述第二计算单元120具体用于:对第一流域的几何中心的季节性指标进行空间插值运算,获得所有网格中心的季节性指标。
[0178]
在其中一个实施例中,在上述实施例的基础上,所述第二计算单元120具体用于:确定所有网格中心的季节性指标两两之间的相似度,获得多个相似度参数;确定多个相似度参数中小于预设门限的相似度中,最大的相似度参数为目标相似度参数;基于目标相似度参数以及群集识别算法对各个季节性指标进行聚类,根据聚类结果将所有网格划分为多个同质性区域。
[0179]
在其中一个实施例中,在上述实施例的基础上,所述第二计算单元120具体用于:计算第一季节性指标中的洪水平均发生时间与第二季节性指标中的洪水平均发生时间的相似度,获得第一相似度数值;计算第一季节性指标中的洪水发生集中度与第二季节性指标中的洪水发生集中度的相似度,获得第二相似度数值;计算第一季节性指标对应的网格的地理位置与第二季节性指标对应的网格的地理位置之间的相似度,获得第三相似度数值;根据第一相似度数值、第二相似度数值以及第三相似度数值确定第一季节性指标与第二季节性指标的相似度;其中,所述第一季节性指标、所述第二季节性指标为所有网格中心的季节性指标中的任意两个。
[0180]
具体地,上述提供的用于洪水预测的装置,可以执行上述洪水预测方法实施例,其实现原理和技术效果类似,在此不再赘述。
[0181]
关于洪水预测装置的具体限定可以参见上文中对于洪水预测方法的限定,在此不再赘述。上述洪水预测装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
[0182]
在一个实施例中,提供了一种计算机设备,该计算机设备可以是服务器,其内部结构图可以如图1所示。该计算机设备包括通过系统总线连接的处理器、存储器和网络接口。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的数据库用于水文数据。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种洪水预测方法。
[0183]
本领域技术人员可以理解,图1中示出的结构,仅仅是与本技术方案相关的部分结
构的框图,并不构成对本技术方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
[0184]
一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时可以实现上述各方法实施例中的步骤。
[0185]
本实施例提供的计算机设备,其实现原理和技术效果与上述方法实施例类似,在此不再赘述。
[0186]
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时可以实现上述各方法实施例中的步骤。
[0187]
本实施例提供的计算机可读存储介质,其实现原理和技术效果与上述方法实施例类似,在此不再赘述。
[0188]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和易失性存储器中的至少一种。非易失性存储器可包括只读存储器(read
‑
only memory,rom)、磁带、软盘、闪存或光存储器等。易失性存储器可包括随机存取存储器(random access memory,ram)或外部高速缓冲存储器。作为说明而非局限,ram可以是多种形式,比如静态随机存取存储器(static random access memory,sram)或动态随机存取存储器(dynamic random access memory,dram)等。
[0189]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0190]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。